广州地区GDP的ARIMA模型预测
2010-03-27张林泉
张林泉
(广东女子职业技术学院 信息资源中心,广东广州 511450)
0 引 言
国内生产总值(Gross Domestic Product,GDP)是对一国(地区)经济在核算期内所有常住单位生产的最终产品总量的度量,因此,常被看成显示一个国家(地区)经济状况、经济增长趋势及社会财富的重要指标。GDP还与就业有关,通常GDP越高,表明就业的机会就越多。GDP受投资、消费、出口、银行信贷方面以及政府宏观调控手段和力度等诸多因素的影响,运用传统结构法建立模型进行分析和预测往往比较困难。文中运用ARIMA模型对广州地区国内生产总值数据进行分析预测,为制定经济计划提供具有重要理论与现实意义的依据和参考。
1 ARIMA模型的基本思想及其结构
ARIMA模型又称为自回归移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA),是由 Box and Jenkins(1976)提出的以随机理论为基础的时间序列预测方法,所以又称为Box and Jenkins模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。其中,ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归,p为自回归项数;MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。
ARIMA模型是一种精度较高的时序短期预测模型,其基本思想是:某些时间序列是依赖于时间t的一组随机变量,构成该时序的单个序列值虽然具有不确定性,但整个序列的变化却有一定的规律性,可以用相关的数学模型近似描述。通过对该数学模型的分析研究,能够更本质地认识时间序列的结构与特征,达到最小方差意义下的最优预测[1]。ARMA(p,q)的一般模型为:

令

式(1)可化为:
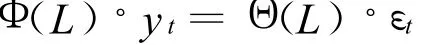
设

式中:L——滞后算子;
Φ(L)——L的p自回归系数多项式;
Θ(L)——L的q阶移动平均系数多项式;
φp——自回归算子;
θq——移动平均算子;
{εt}——零均值白噪声序列。
经过d阶差分变换后的ARMA(p,q)模型称为ARIMA(p,d,q)模型。
将一个非平稳时间序列通过d次差分,将它变为平稳的,然后用一个平稳的ARMA(p,q)模型作为它的生成模型,则该原始时间序列是一个自回归单整移动平均时间序列,记为ARIMA(p,d,q)[2]。ARIMA模型实质是差分运算与ARMA模型的组合[3]。
2 ARIMA模型拟合步骤
2.1 序列平稳性进行检验
首先根据时间序列的散点图(或折线图)、自相关图,或通过ADF单位根检验,判断该序列是否平稳(stationary series)。若含有指数趋势的非平稳,通常可以通过对指数趋势进行对数变换后转化为线性趋势,然后再对其进行差分来消除线性趋势。差分次数即为ARIMA(p,d,q)中的阶数d,实际的经济时间序列差分阶数d一般不超过2。
2.2 模型识别
对差分后平稳序列进行模型定阶,通常遵循如下的经验准则:
1)如果某序列的自相关函数是截尾的,即过了某一滞后项数(设为q)后,自相关函数值变成不显著,接近于0,并且偏自相关函数是拖尾的,则可以把该序列设为MA(q)过程。
2)如果某序列的偏自相关函数是截尾的,即过了某一滞后项数(设为p)后,偏自相关函数值变成不显著,接近0,并且自相关函数是拖尾的,则把该序列设为AR(p)过程。
3)如果某序列的自相关函数、偏自相关函数值都是拖尾的,则把该序列设为ARMA(p,q)过程。再利用自相关函数(ACF)、偏自相关函数(PACF)以及它们的图形来确定p,q的值。
2.3 模型参数估计
估计模型的未知参数,并检验参数的显著性,若有不显著的,表示此参数不需要放在模型中。
2.4 模型诊断
检验模型的有效性就是对所估计的模型是否很好地拟合了数据进行诊断,主要是通过检验残差序列是否为白噪声序列来判断。是否还存在一个更好的模型,能够更好地拟合数据和进行预测,一般的做法是在模型中增加滞后项,然后根据Akaike's(1974)信息准则(AIC),及Schwarz's(1978)信息准则(SBIC)来判断。如果拟合模型通不过检验,重新选择模型进行拟合。
2.5 模型预测
利用已通过检验模型进行预测分析。
3 实证分析
3.1 数据的平稳性检验与处理
数据选取1990-2009年广州地区国内生产总值序列(yt),数据来源于广州市统计年鉴[4]。对于含指数趋势的时间序列,可以通过取对数来将指数趋势转化为线性趋势。作图(图略)可以看出广州地区国内生产总值呈指数变化趋势,特别是从1998年之后,增长趋势强劲,具有很强的非平稳性。经单位根检验,t=10.273 8,P= 1.000 0大于相应临界值,接受原假设,即存在单位根,原始序列没有通过ADF检验,是非平稳的时间序列。对序列yt取对数并做一次差分后(对yt取对数得到lnyt,用Δ lnyt表示lnyt序列一阶差分)再做线图,线图显示序列的增长趋势基本消除,初步判断为平稳序列。单位根检验见表1。

表1 Δlnyt序列ADF检验
说明非平稳序列取对数一阶差分后在5%、10%显著性水平下是平稳的,可以对模型定阶d =1,即对一阶差分以后的平稳序列可以建立ARMA(p,q)模型。
3.2 模型建立与检验
序列取对数一阶差分后的自相关和偏自相关图如图1所示。

图1 Δlnyt序列的相关图
样本自相关函数与偏自相关函数都是拖尾的,故选择ARIMA(p,d,q)模型。从图1可以看出,自相关图在K=1之后都在随机区间内,从偏自相关图可以看出,K=1之后都在随机区间内。经过反复的试验及检验,只有当p=1,q=3时,参数通过检验,考虑建立模型ARIMA(1,1,3)。用Eviews软件建立模型ARIMA(1,1,3),并对参数进行估计,得到结果见表2。

表2 模型参数估计
残差序列自相关图如图2所示。
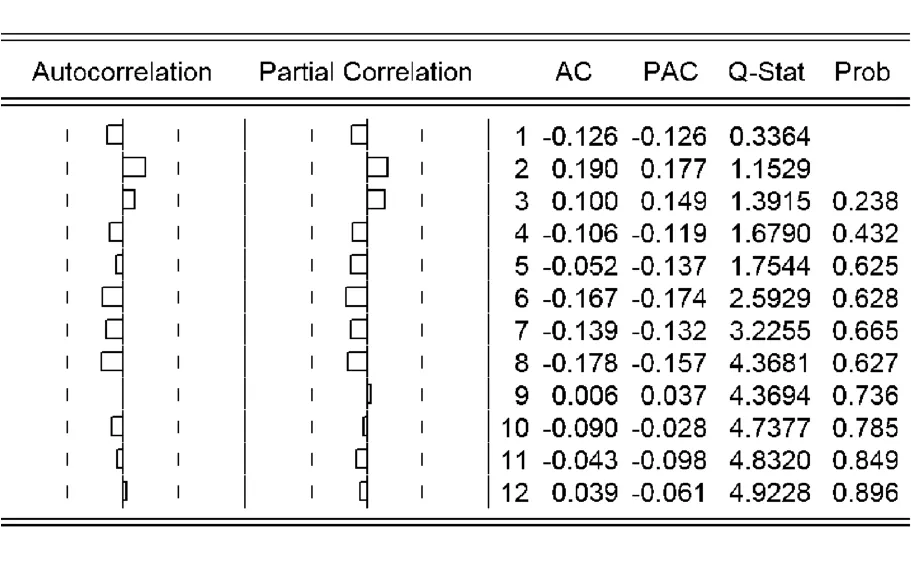
图2 Δlnyt序列ARIMA(1,1,3)模型残差相关图
残差序列的自相关系数都落入随机区间,残差不存在序列相关,在各阶滞后的自相关和偏自相关值都接近于零,所有的Q-统计量不显著,并且有大的P值。
残差值、实际值、拟合值如图3所示。

图3 残差值、实际值、拟合值图
序列相关的Breush-Godfrey LM检验(拉格朗日乘数检验),统计量见表3。

表3 拉格朗日乘数检验
在5%的显著性水平接受原假设,回归方程的残差序列不存在序列相关性,回归方程的估计结果有效。ARIMA(1,1,3)模型的残差图完全符合时间序列模型拟合的条件,根据上述分析,确立模型为ARIMA(1,1,3),可以用来做短期预测。
由表2 AMIMA(1,1,3)模型为:

可得到:

所以有:
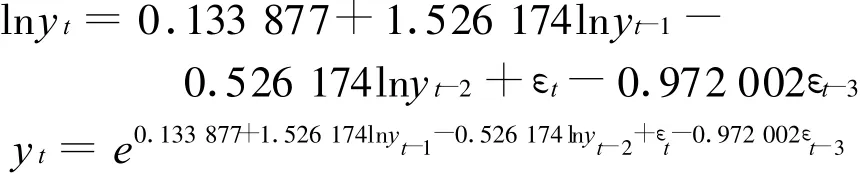
3.3 模型预测
利用建立的模型对2007-2010年广州地区国内生产总值进行预测,预测结果见表4。

表4 预测结果与实际值比较表 亿元
从表4可以看出,预测值与实际值差异不大,预测相对误差较小,说明ARIMA(1,1,3)模型对预测效果较好。
4 讨论分析
运用1990-2009年广州地区经济数据建立ARIMA(1,1,3)模型,通过模型参数估计与诊断检验,以及实证检验发现,预测相对误差较小,预测拟合精度较好,可用于对广州市GDP做短期预测,为制定经济计划提供依据和参考。模型的建立应注意时间序列的连续性,随着预测期的延长,预测误差也会相应增大。
5 结 语
广州2010全年地区生产总值有望突破1万亿元,从广州GDP的产业构成与贡献分析来看,原有的发展模式已不能适应未来城市发展的需要,要合理调整GDP比重,加快经济发展方式转变。注意各次产业的协调发展,避免某一产业的“过热”并产生“瓶颈”,这也是发展经济的一个重要的经验教训[5]。加大金融业、信息传输、计算机服务等现代服务业增加值占服务业增加值的比重;加大制造业实现增加值占规模以上工业增加值的比重,加大新兴产业增加值占GDP的比重;加强对居民消费预期的刺激和基础设施的完善增加社会消费品零售总额,挖掘和培育新的消费增长点,实现以人为本的现代化。
[1] 易丹辉.数据分析与Eviews应用[M].北京:中国统计出版社,2003:106-132.
[2] 李子奈,潘文卿.计量经济学[M].2版.北京:高等教育出版社,2005.
[3] 何书元.应用时间序列分析[M].北京:北京大学出版社,2003.
[4] 佚名.广州统计年鉴2010[M].北京:中国统计出版社,2010.
[5] 张海燕.我国经济发展中基于产业结构因素的计量分析[J].长春工业大学学报:自然科学版,2009,30(5):572-577.
