基于ARM的嵌入式Linux网络数据传输性能分析
2010-03-24宋洪治武杰张杰孔阳马毅超
宋洪治 武杰 张杰 孔阳 马毅超
1(中国科学技术大学物理系 合肥 230026)
2(中国科学技术大学近代物理系 合肥 230026)
作为一种通用可靠的网络传输技术,以太网技术几乎存在于所有实验中[1],很多实验采用以太网将读出电子学模块的数据传送到更高级别系统[2–5]。为完成网络数据传输任务,一般需操作系统的支持,采用的操作系统主要有 VxWorks[3]和 Linux[2,6]。其中,Linux系统开源低成本,为研究者所熟知,且有成熟稳定的网络协议栈,非常适合网络通信。
本文基于ARM处理器用Linux 2.4内核构建了用于数据传输的嵌入式系统。结合具体数据分析了系统数据接收过程,给出系统性能变化的原因及优化的方向。
1 系统结构和分析
系统以ARM处理器为核心,使用以太网传输数据。为保证数据传输的可靠性,网络传输使用TCP/IP协议。在不考虑EMAC(Ethernet MAC)和物理层操作情况下,用TCP发送数据消耗的处理器周期为接收数据的~4/5[7]。为测试系统在更大压力下的表现,采用TCP接收数据的方式。
1.1 硬件系统
1.2 Linux网络数据包的接收
系统接收数据包过程[8–11]如图1。网络质量很好而大量接收数据时,可忽略失序的TCP报文。
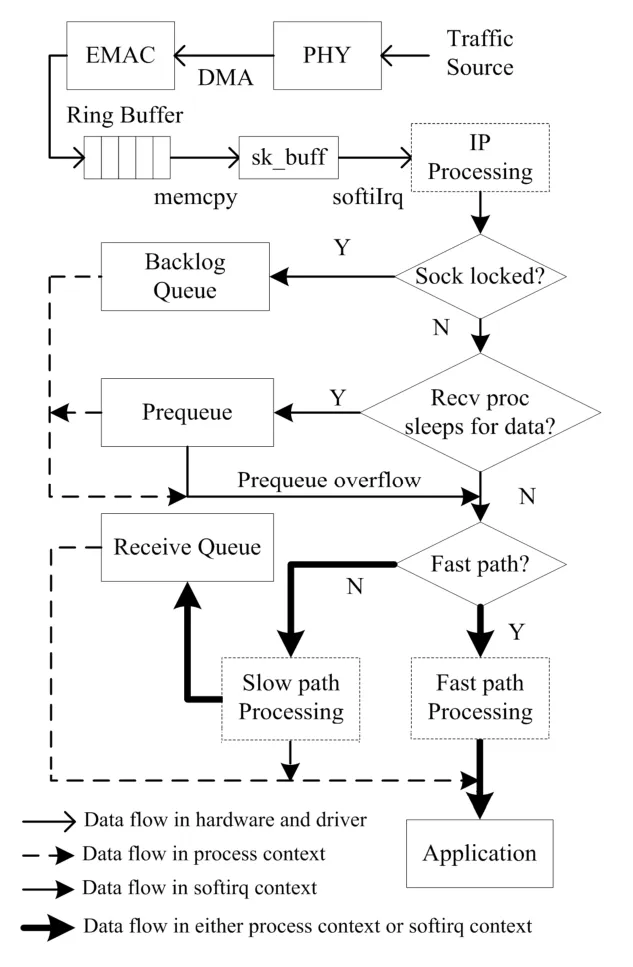
图1 Linux网络子系统TCP协议收包过程Fig.1 The packet receiving process of Linux networking subsystem for TCP.
Linux网络子系统通过软中断[8,9]机制处理接收的数据包。链路层收到的数据帧由 EMAC通过DMA(Direct Memory Access)操作复制到环形缓存。环形缓存由多个能容纳最大链路帧长的接收缓存构成。一个接收缓存有“准备”和“使用”两种状态。EMAC只可向“准备”态的接收缓存复制数据帧;处于“使用”态的接收缓存只有被网络驱动读取,并重置为“准备”态后才能重新被EMAC使用。通常TCP数据包接收分为如下三阶段。
1.2.1 以太网数据帧通过物理层到达MAC层
此时,EMAC自动检查数据帧的前导、目的物理地址和循环冗余校验(CRC),并启动DMA操作将其复制到一个处“准备”态的接收缓存中。如数据帧有效,EMAC会将该接收缓存置为“使用”态,并产生收到数据帧的中断。网络驱动响应这个中断并做如下操作:(1) 分配 sk_buff[8,9,12]对象;(2) 复制接收缓存中内容到sk_buff对象;(3) 根据数据帧封装协议更新sk_buff对象中的控制信息;(4) 将sk_buff对象添加到当前处理器的接收队列中;(5) 产生软中断通知协议栈新数据帧的到来;(6) 重置接收缓存为“准备”态。为避免中断响应不及时,设备驱动在每次收到中断时对所有处于“使用”态的接收缓存使用上述操作。如果没有可用接收缓存,EMAC将丢弃收到的帧。同样,在EMAC成功接收数据帧,但分配 sk_buff失败情况下,设备驱动也会丢弃对应的帧。TCP连接有流量控制[13]机制,所以通常不出现分配 sk_buff失败的情况。出于效率的考虑,一个 sk_buff对象包含足够大空间来容纳协议栈中每一层添加的控制信息,且一直处于内存中同一位置,从而避免了数据的跨层复制操作。
1.2.2 协议栈响应软中断,在系统的中断上下文中处理收到的数据帧
网络层的IP协议处理完数据帧后,将数据包送到传输层交给TCP协议处理。Linux 2.4的TCP用预收队列、接收队列、候补队列或失序队列处理收到的数据包。这里数据包有三种可能的传输路径:
(1) 如果软中断发生时,进程正在内核空间中操作队列接收数据,则数据包会被放到候补队列中等待进程进一步处理。
(最新消息:经过作者修订的第四版《养生三记》,增补了很多精彩篇章,新版已由黑龙江科技出版社出版发行,各地新华书店将陆续到货。办理邮购的地点为:哈尔滨市南岗区人和街93号,收款人:彭祖补品屋。勿寄私人,以免延误。书价40元,免收邮费。免费联系电话:400-609-2883,汇款单附言请写明您的详细地址和电话,以便给您寄书。)
(2) 如果此时接收数据的进程正因为等待期望的数据而睡眠,数据包会被放到进程的预收队列中。预收队列主要为实现计算校验和并复制到用户空间的操作[14],以节省CPU周期。预收队列无溢出时,其中的数据包在进程上下文中处理。若送到预收队列中的sk_buff对象的总缓存长度超过TCP协议栈预先设定的接收缓存大小,系统判定预收队列溢出。此时,预收队列中的数据包将在中断上下文中处理。
如满足快速路径条件:TCP包没有失序、当前进程正是读取当前套接字的进程、应用程序提供足够大用户空间接收缓存能容纳当前 TCP数据包所有数据,则数据包将通过快速路径,以计算校验和并复制的方式直接到达用户缓存。否则TCP数据包将通过慢速路径。
慢速路径中,未失序TCP包经处理后被发送到接收队列,失序者则送到失序队列。若能大量连续地接收数据,则认为网络条件很好,可忽略TCP数据包失序,故图1未给出失序时的数据传输路径。
(3) 如在软中断时,进程既不在操作队列,也不在等待网络数据,说明进程此时正运行或休眠在与网络接收无关的地方。此时,收到的数据包会依据快速路径条件通过快速或慢速路径。
1.2.3 用户进程通过系统调用在进程上下文中处理接收到的数据
进程上下文中,将按先预收队列、再接收队列、最后候补队列的优先次序处理数据。接收队列中数据被直接复制到用户空间接收缓存。与软中断中预收队列溢出时数据的流向类似,预收和候补队列中的数据将通过快速或慢速路径到达用户空间或接收队列。与软中断中情况不同的是,慢速路径中如满足当前进程是接收当前数据包的进程,当前数据包序号是期望的序号,且有足够的用户空间接收缓存,则数据被复制到用户空间,而非接收队列中。
2 测试和分析
为测量系统用 TCP/IP协议从以太网接收数据时各部分消耗的处理器时间,用AT91RM9200三个定时计数器级联成一个运行在30 MHz频率下的48位计数器,统计内核相关部分的运行时间。
根据Linux 2.4内核TCP/IP协议栈结构特点,将计时区段划分为:(1) 不在中断响应中运行的驱动程序时间,(2) 中断响应中运行的驱动程序时间,(3) 软中断中运行的协议栈发送数据代码的运行时间,(4) 软中断中运行的协议栈接收数据代码的运行时间,(5) 不在软中断中运行的协议栈接收数据代码的运行时间,(6) 不在软中断中运行的发送数据代码的运行时间,(7) TCP重传定时器运行时间,(8) TCP延迟确认定时器运行时间,(9) TCP保活定时器运行时间,(10) 总运行时间。
根据测得各个时间的值,得到网络驱动程序及TCP/IP协议栈的运行时间和系统其它部分运行所需时间:

除测量协议栈消耗时间外,还记录了TCP接收相关的其它信息。
测试时,数据从PC送出,直接到达目标板。测试条件为:网络用TCP连接,发送方发送256 MB数据,接收方用64 KB协议栈接收缓存,用recv系统调用配合 MSG_WAITALL选项使用不同用户缓存接收数据。
图2是有无使用性能测试代码时不同用户空间接收缓存下系统接收数据的速率。
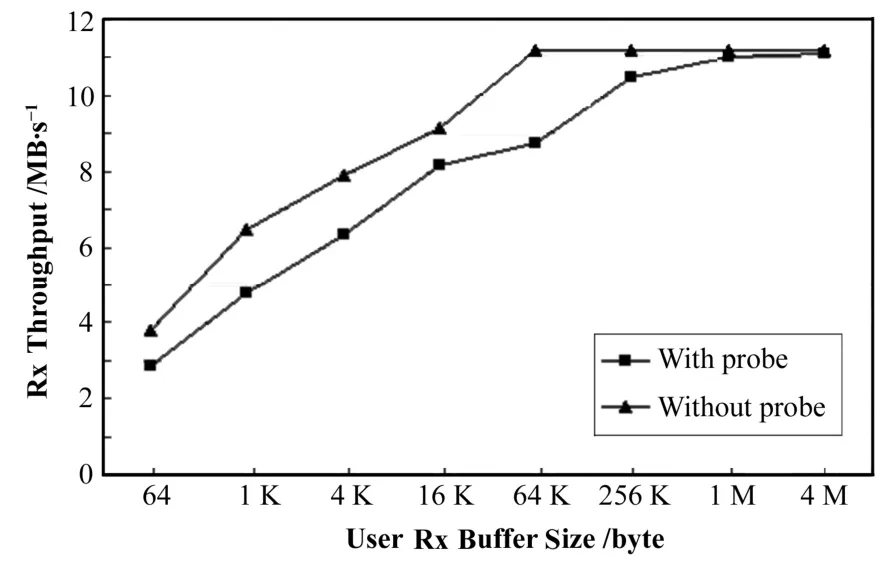
图2 不同用户空间接收缓存下的接收速率Fig.2 Rx throughput with various Rx buffer in user space.
系统接收数据时,无论何种情况,处理器使用率都一直处于100%。由图2,接收速率随用户空间缓存增大而增大。没用测试代码、用户空间缓存达64 K字节时,系统的接收速率饱和。即对200 MHz的 ARM9处理器能力,如其配置和 AT91RM9200相当,想要充分发挥百兆以太网数据传输速度,至少需开辟64 K字节用户空间缓存。使用性能测试代码、用户空间缓存4 M字节时,接收速率饱和。
图3是不同用户空间接收缓存下各计时区段占用的时间。对当前测试,目标板不发送数据,则重传定时器不运行。由于目标板连续接收数据,延时确认定时器超时前就被重置。而且并没使能保活定时器(Keep-alive timer),故图3未给出这三个运行时间为零的定时器的运行时间数据。
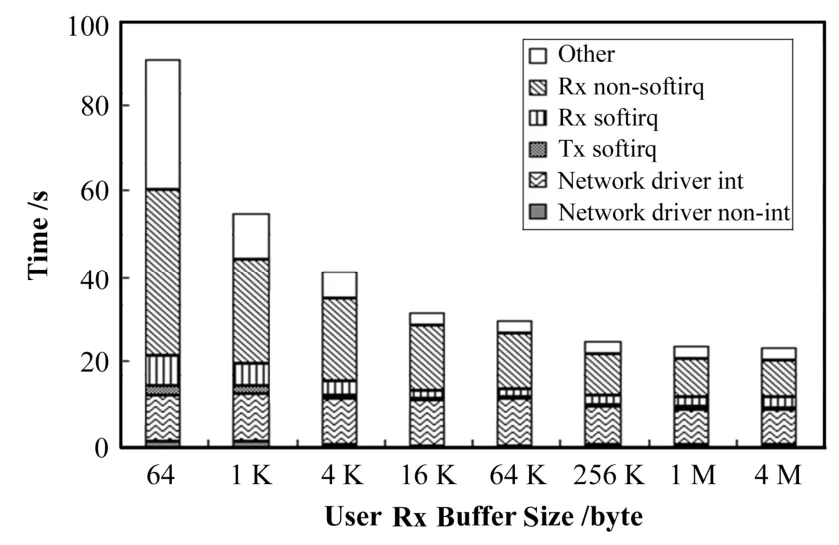
图3 不同用户空间接收缓存下TCP处理的时间分布Fig.3 TCP processing time distribution with various Rx buffer in user space.
表1给出与TCP接收相关的其它一些测量值。在进程上下文即将处理接收队列前,接收队列中sk_buff对象的数目被累加。将累加的结果与接收队列的处理次数相比就得到了接收队列中 sk_buff的平均个数。TCP直接复制比率是指从预收或候补队列中以计算校验和并复制操作直接复制到用户空间缓存的数据占总接收数据的百分比。归一化回应包个数是目标板发送给PC回应包个数与TCP层接收到sk_buff对象数目的比值。测试结果显示TCP层收到sk_buff对象的数目不变。
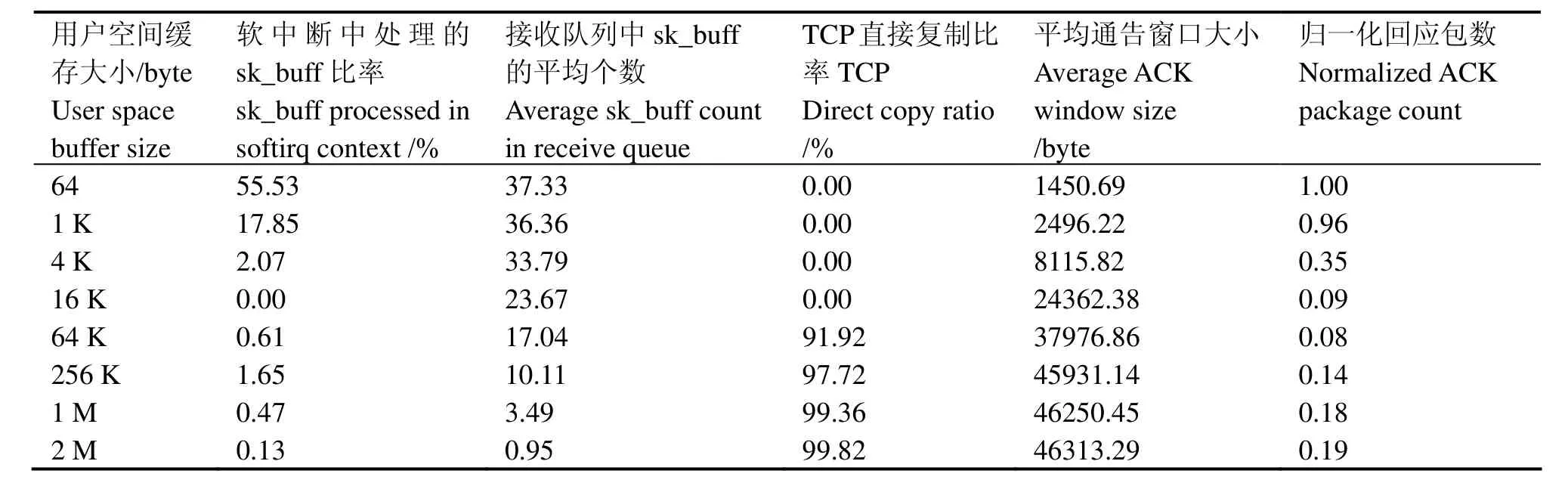
表1 不同用户空间缓存下TCP接收相关测量值Table 1 Measured items related to TCP receiving process with various user space Rx buffer.
由测试条件可知,系统调用只有复制了足够数据到用户空间后才会返回,所以小用户空间接收缓存会造成更多的系统调用次数,这不仅增加不在软中断中运行的协议栈接收代码的时间,还大幅增加系统的额外开销。当应用程序用套接字读取数据时,首先会通过 C库执行 Linux系统调用进入内核空间;然后在内核空间通过文件系统抽象层得到该操作对应的对象,即套接字层;最后,在套接字层数据被复制到用户空间。因每一次操作都产生一个层层递进的额外开销,所以图3显示小接收缓存下系统额外开销占很大比例。
目标板收到数据后需发送回应包给PC。由表1平均通告窗口大小和归一化回应包个数知,相对大用户空间缓存情况,小用户空间缓存下目标板将发送更多有更小通告窗口大小的回应包。更多的回应包,增加了软中断中运行协议栈发送数据代码和网络驱动非中断响应部分的运行时间。由于EMAC发完数据后会产生中断,所以这也意味着更多中断,即更多的网络驱动中断响应代码的运行时间。
由图1,若在软中断上下文中处理了sk_buff对象,只有两种情况:预收队列溢出,或使用当前套接字的应用程序运行或休眠在 TCP接收无关的地方。TCP有流量控制机制,所以当前测试条件下接收数据时不应出现预收队列溢出的情况。测试表明预收队列溢出的次数为0,证实预收队列不会溢出。结合表1和图3,在系统其它开销很大,即小用户空间缓存情况下,软中断发生时应用程序运行于TCP接收相关代码处的概率降低,导致软中断处理sk_buff对象比例增大,增加了系统在软中断上下文中接收数据的时间。
表1的TCP直接复制比率表明,小用户空间接收缓存下收到的数据没有直接达用户空间,而是通过接收队列进行了一次中转。测试表明,每个sk_buff对象均包含1448字节用户数据(包含时间戳选项的TCP包),结合表1接收队列中sk_buff的平均个数算出,用户缓存小于64 K时,接收队列中平均数据量大于用户缓存大小。这导致接收队列不能为空,由图 1,此时进程不会休眠等待网络数据,则收到的数据要么到候补队列延迟到进程上下文中处理,要么直接在软中断中处理。在进程上下文中处理数据时,接收队列先于候补队列处理,则处理候补队列时,用户缓存已被接收队列填满,不满足快速路径条件,数据只能送到接收队列。同样,软中断中满足快速路径条件的概率降低,基本上所有数据被送到接收队列。用户缓存不小于64 K时,接收队列中平均数据量小于用户缓存,快速路径条件易满足,基本上所有数据被直接复制到用户空间。
由图 3,不同用户缓存条件下,在非软中断中运行的接收代码和网络驱动中断响应部分占用了系统大部分处理器时间。非软中断中接收代码的大部分时间都消耗在sk_buff对象的处理上。由图1,如进程长时间运行在网络接收无关的地方,则这部分时间会被转移到软中断中运行的接收代码处。所以作为非内核开发者,对Linux 2.4内核接收性能优化在内核层面主要是对网络驱动中断响应部分的优化。
结合上面分析,在应用程序层面对系统性能优化主要是尽量减少系统调用次数,尽量增加直接复制到用户空间数据的比例,即综合考虑系统资源和性能前提下,选用合适大小的用户空间接收缓存。
3 结论
本文从数据流角度分析了 Linux 2.4内核TCP/IP协议栈接收数据的过程,并结合具体测试结果分析了不同用户空间缓存条件下系统网络接收性能的变化及具体原因,并给出优化系统性能的方向。
1 Denis Calvet.IEEE Trans Nucl Sci, 2006, 53(3): 789–794
2 Youichi Igarashi, Hirofumi Fujii, Takeo Higuchi, et al.IEEE Nucl Sci Symp Conf Rec, 2004, 2: 1122–1126
3 Tao N, Chu Y P, Jin G, et al.Plasma Sci Technol, 2005,7(5): 3065–3068
4 Giuseppe Avolio.IEEE Trans Nucl Sci, 2004, 51(5):2081–2085
5 Artur Barczyk, Jean-Pierre Dufey, Clara Gaspar, et al.IEEE Trans Nucl Sci, 2004, 51(3):456–460
6 Ji X L, Li F, Ye M, et al.IEEE Nucl Sci Symp Conf Rec,2008, 2119–2121
7 Won Chulho, Lee Ben, Yu C S, et al.J High Speed Networks, 2004, 13(3): 169–182
8 Bovet D P, Cesati M.Understanding the Linux Kernel.2nd ed, O'Reilly Media, 2002.ISBN: 0-596-00213-0
9 Christian Benvenuti.Understanding Linux Network Internals.O'Reilly Media, 2005.ISBN: 0-596-00255-6
10 Wu W J, Crawford M, Bowden M.Comput Commun,2007, 30(5): 1044–1057
11 Wu W J, Crawford M.International J Commun Syst, 2007,20: 1263–1283
12 Jonathan Corbet, Alessandro Rubini.Linux Device Drivers.2nd ed, O'Reilly Media, 2001.ISBN:0-596-0008-1
13 Stevens W R.TCP/IP Illustrated.Vol 1, The Protocols,Addison-Wesley Professional, 1994.ISBN: 0201633469
14 Clark D D, Van Jacobson, Romkey J, et al.IEEE Commun Mag, 1989, 27(6): 23–29
