基于CUDA平台的DR图像增强处理加速算法
2010-01-26何祥彬周荷琴李方勇
【作 者】何祥彬,周荷琴,李方勇
中国科学技术大学自动化系,安徽,合肥,230027
直接数字化X线摄影(Digital Radiography, DR)是现代医疗诊断中的一种先进医学成像技术,具有曝光剂量小、成像速度快和动态范围大等优点。但DR成像过程易受噪声等的影响,使原始的DR图像对比度达不到医学诊断要求,需要对其进行一定的增强处理。多尺度增强算法较适用于DR图像的增强处理,其方法主要包括小波变换和在小波分析基础上提出的塔型多尺度增强算法[1]。后者虽然简化了图像分解和重构的计算过程,但由于DR图像的分辨率极高,其算法运行仍需要较长的时间,因此如何提高其运行速度是能否将它应用到实际DR系统上的关键问题。有作者在不影响图像整体质量前提下,通过去掉一些冗余的计算来提高塔型算法的速度[2],但加速效果仍不甚明显。随着计算机技术的快速发展,不断有更高性能的部件问世,如何深入挖掘它们的潜力,将它们用到新型医学成像设备中去,也是生物医学工程的课题。例如,CPU的多线程和并行计算功能已被成功应用于图形绘制和图像处理,但由于操作系统的流水线作业调度方式和CPU本身在浮点运算上的限制[3],使基于CPU的多线程操作对加速效果仍不够明显。Intel奔腾处理器的单指令多数据(Single-Instruction Multiple Data, SIMD)技术,能让一条指令同时对4个数据进行相同的操作,我们小组曾将其用于基于CT图像的体绘制中,明显提高了绘制的速度[4]。然而,对于分辨率很高的DR图像,这两种技术均难以满足速度的要求。为此,我们尝试用GPU(Graphic Processing Unit,图形处理器)来提高多尺度塔型算法的运行速度,采用CUDA(Compute Unified Device Architecture, 计算统一设备体系结构)架构,将算法中包含的大量卷积运算交给具有超强并行运算能力的GPU来执行,显著提高了算法的运行速度。
1 加速方法设计
1.1 CUDA架构
GPU是专为计算密集型、高度并行化的算法而设计的处理器。它将更多的晶体管用于数据处理,而非数据缓存和流控制,具有极高的计算密度,对浮点数的计算能力远胜于CPU和其它处理器,已进入计算主流[5]。CUDA是显卡厂商NVIDIA公司推出的一种基于GPU的软硬结合的通用计算构架,并提供硬件的直接访问接口,不必靠图像API接口来实现对GPU的访问。它用CPU做总控制器,与GPU结合,以C为编程语言,并进行了适度扩展,能大量开发高性能计算指令。因此,能在GPU强大计算能力的基础上,实现高效的密集数据计算,且非常适合并行计算[6]。
CUDA的运行模型如图1所示,在Host(CPU)上分配了不同的任务,一个个线程Kernel按照线程网格(Grid)的概念在Device(GPU)上执行。这样,每个Grid都得到资源,但不同Grid间相互独立。每个Grid又可包含很多个线程块(Block),各Block之间不相互通信,也不并行工作,但共享同一个任务分配的资源。每个Block又把任务分配给多个线程(Thread),每个Thread都有自己的编号,我们可以很方便地给它分配具体的任务,Thread之间共享资源,可相互通信,并行工作,并按既定的规则同步。每个Block下的线程均可读写自己的寄存器和本地内存(local memory)和Block的共享(share)内存,也可以读写Grid的全局(global )内存、常量(constant)内存和纹理(texture)内存。
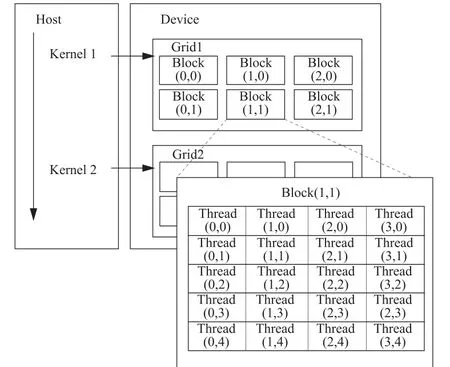
图1 CUDA运行模型Fig.1 The running model of CUDA
1.2 多尺度塔型增强算法的加速
多尺度塔型增强算法包括图像分解、子带增强和图像重建等三个主要步骤,其流程如图2所示。图像分解是多尺度塔型增强算法不可缺少的部分,算法由上而下的分解过程,即为拉普拉斯金字塔的建立过程[7]。图中LP代表低通滤波器,一般采用5×5的高斯低通滤波器。Fi-1是i级输入图像(i=1,2,……L+1),经过滤波并以2步长进行抽样,得到第i级图像的近似Fi。接着再对Fi进行内插和滤波,把得到的图像与Fi-1相减,便可得到第i级的拉普拉斯金字塔Gi。在图像分解过程中得到的每一级图像Gi,代表着图像中不同尺度的高频信息,即图像的细节信息。图2中虚线框部分是子带增强,它是塔型算法的关键步骤。采用非线性变换对分解得到的每一级图像即不同尺度的细节信息进行子带增强。所选用的非线性变换函数直接影响着图像的增强效果。子带增强后,紧接着进行图像重建,它是图像分解的逆过程,由下而上,将经过增强后的图像高频信息相加,便可得到处理后的图像。
DR图像的分辨率很高,每幅图片包含的像素一般在2000×3000左右,因此在多尺度塔型增强的分解和重构的每一层上进行高斯低通滤波时,都需要进行大量的卷积运算,这也是塔型算法耗时多的主要原因。若能提高这部分卷积运算的速度,就会显著缩短整个算法的运行时间。
很多文献都对多尺度塔形算法进行了介绍,这里不再赘述,仅考察算法中涉及的包含大量运算的空间域内的二维卷积公式:

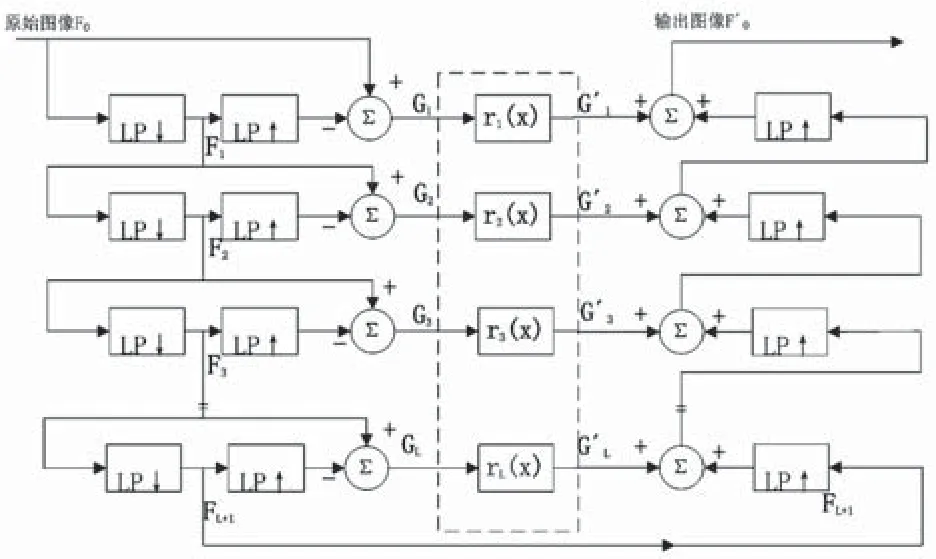
图2 塔型多尺度增强算法流程Fig.2 Flow diagram of Laplacian pyramid multi-scale contrast enhancement
式中s(i,j)为像素点的值,k(i,j)为滤波器的值。由式(1)可知,对于n*n的二维滤波器,每个输出点的计算需要作n*n次乘法及n*(n-1)次加法运算。在塔型增强算法中常用的5×5的高斯低通滤波器为:
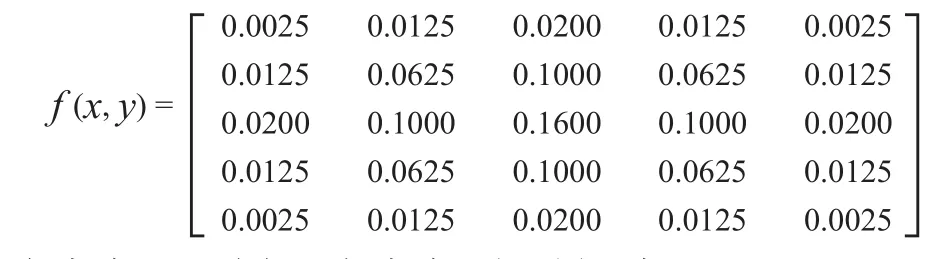
该滤波器可以由两个滤波器相乘得到,即

式中h=[0.05 0.25 0.40 0.25 0.05]。因此,我们可以对该二维滤波进行分解,先使用h滤波器进行一次行滤波,再使用hT进行一次列滤波。容易证明,采取这样的滤波形式可将算法复杂度从原来的O(n2)降为O(n),从而显著减少计算量,缩短算法的运行时间,而滤波效果又没有改变。此外,先做行卷积,再作列卷积,每次读取显存都可以利用其寻址模式顺序读取,进一步提高了GPU的运算速度。
1.3 基于CUDA的加速
根据CUDA的运行模型,将要处理的卷积任务划分为多个 Block,Block中的每个线程执行一个输出点的卷积运算。为了不执行过多的内存拷贝和边界控制,我们在实现加速方法时选用纹理内存来进行线程的数据存取。下面介绍主要的实现步骤:
(1) 首先声明纹理变量及纹理模式texture<usigned short, 2, cudaReadModeElementType> texData;
(2) 开辟CUDA数组空间cudaArray*a_Data,并将图像数据从显存拷入CUDA数组空间 cudaMemcpy
ToArray (filData[i],0, 0, pCrt, crtS*sizeof(unsigned sh ort),cudaMemcpyDeviceToDevice);
(3) 将CUDA数组绑定到纹理内存cudaBind ToArray(texData, filData[i])。这样就可以利用纹理内存,使GPU快速的完成所有计算,最后将计算结果输出到CPU。
2 实验结果及分析
我们用2560×3072的DR胸部图片为实验数据。实验环境为CPU AMD 4200+,主频4.4GHz,2GB内存,Windows XP操作系统,编译工具为Visual C++2005。GPU选用NVIDIA公司的GeForce 9500GT,驱动的版本为NVIDAI Driver 2.2。
实验中采用文献[8]提出的非线性变换公式作为子带增强函数,分别在GPU和CPU下实现塔型算法。图3是结果图像,其中(a)为原始图像,(b)、(c)分别为利用GPU和CPU分解得到的图像细节信息,(d)、(e)分别为GPU和CPU下增强后的图像。从图3可以直观地看出,无论是增强过程中的分解结果还是增强后的最终结果,在GPU和CPU下均是一致的,且处理后的图像清晰度相对原图均有较大的提高。
为了进一步验证在GPU下做塔型增强算法的正确性,对GPU和CPU下的运算结果的每一像素点计算差,然后求平方和,结果为0,表明算法在GPU和CPU下执行后得到的结果是一致的。
实验统计了20次塔型增强算法的运行时间,然后取平均值,得到表1所示的结果。可见,在CPU下执行单线程对DR图像实施增强,计算非常耗时;采用多线程方案可以稍微提高计算速度,但其加速效果不是非常明显;而在基于GPU的CUDA平台下,DR图像的增强处理耗时仅为CPU单线程方式的1/30,加速效果非常明显。
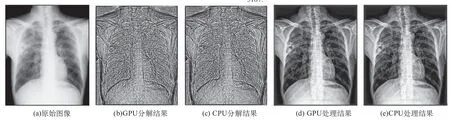
图3 GPU和CPU下DR胸部图像增强结果比较Fig.3 The comparison of processing results based on GPU and CPU

表1 CPU和GPU下塔型算法的运行耗时Tab.1 The time-consuming of CPU and GPU
3 结论
图像增强是DR系统图像处理过程中的重要环节,由于DR图像包含的数据量很大,因此提高增强算法的运行速度直接关系到DR系统的性能。本文基于CUDA平台,利用GPU来完成多尺度塔型增强算法中图像的分解和合成过程中的大量卷积运算,能够在保持原有增强效果的基础上,将算法运行速度提高近30倍,为在微型机系统上快速处理DR图像提供了一条新途径,具有较大的实用价值。而且,所介绍的方法也可用于其他大容量数据处理的场合。
[1] P. Vuylsteke, E. Schoeters. Multiscale Image Contrast Amplification (MUSICATM)[J]. Proc SPIE Image Processing,1994, 2167:551 - 560.
[2] 李名庆, 高新波, 许晶. 多尺度塔型医学图像增强算法[J]. 中国生物医学工程学报, 2006, 25(2):178 – 181.
[3] 宋晓丽, 王庆. 基于GPGPU的数字图像并行化预处理[J]. 计算机测量与控制, 2009, 17(6):1169 – 1171.
[4] 袁非牛,诸葛斌,周荷琴,等. 基于奔腾SIMD和分割技术的快速体绘制[J]. 中国图形图像学报,2003,8(12):1438 – 1443.
[5] 吴恩华, 柳有权. 基于图形处理器(GPU)的通用计算[J]. 计算机辅助设计与图像学学报. 2004, 16(5): 601 – 611.
[6] CUDA-走向GPGPU新时代. 程序员, 2008, 10(3):36 – 39.
[7] (美)冈萨雷斯等. 数学图像处理[M]. 北京:电子科学出版社,2004.
[8] Xuanqin Mou, Min Zhang. Nonlinear Multi-scale Contrast Enhancement for Chest Radiograph[J]. ICIP, 2008, 3184 –3187.
