基于XML的Web数据挖掘系统模型的设计
2010-01-25黄淑芹
黄淑芹
(安徽财经大学 管理科学与工程学院, 安徽 蚌埠 233030)
Internet的飞速发展,使其成为全球信息传递与共享的日益重要和最具潜力的资源,同时Web上信息也在爆炸性的增长,出现了“信息丰富知识匮乏”的现象,使人们迫切需要一种能够快速、有效地从丰富的Web资源中发现大量潜在价值知识或者模式的工具.如何从海量的数据中发现潜在规律,获得有用的知识,数据库领域的数据挖掘[1]技术扮演着重要的角色.但由于Web的内容呈现多元化,包含了文本、音频、视频、图形、图像等多种元素,显示形式也不拘一格,所以Web数据具有动态、异构、半结构化的特点[2].传统数据挖掘的对象多是数据库中规则化的数据[3],对这样的数据已显得力不从心.而W3C开发的XML[4]是一种半结构化的数据模型,具有“自描述”、“树形结构”、“结构嵌套”等特点,能够使来源于不同结构化的数据很容易结合在一起.它不仅可以很好地兼容原有的Web应用,而且可以更好地实现Web中的信息共享与交换,它自然地成为Web数据挖掘良好的中间载体,使Web挖掘工作变得更容易.
1 XML和Web数据挖掘技术
1.1 Web数据挖掘概念
Web数据挖掘是利用数据挖掘技术从Web文档及Web 服务中自动发现并提取人们感兴趣的信息[2].通常Web数据挖掘过程分为以下几个阶段:资源发现,数据抽取及数据预处理阶段,数据汇总及模式识别阶段,分析验证阶段.由于Web的开放性、动态性、异构化与半结构化等特点,要从这些分散的、异构的、没有统一管理的海量数据中快速准确的获取信息成为Web 数据挖掘的难点.显然,面向Web的数据挖掘比面向单个数据仓库的数据挖掘要复杂得多.Web数据挖掘要充分考虑数据来源分析,异构数据环境,半结构化的数据结构,解决半结构化的数据源问题等几个方面.
1.2 XML在Web数据挖掘中的应用优势
XML是一种半结构化的数据模型,它可以很容易地将XML的文档描述与关系数据库中的属性一一对应起来,实施精确地查询与模型抽取,XML的出现为解决Web数据挖掘难点提供了很好的解决方法.XML能增加结构和语义信息,使计算机和服务器即时处理多种形式的信息.XML没有固定的标记,能描述数据的形式和结构,并且数据和显示形式分开,从而能方便地实现网络应用和信息共享.XML的自定义性及可扩展性,使它足以表达各种类型的数据,客户收到数据后可以进行处理,也可以在不同数据库间进行传递,XML在这类应用中解决了数据的统一接口问题.XML是自我描述的,数据不需要有内部描述就能被交换和处理.XML解决了Internet发展速度快而接入速度慢的问题,以及可利用的信息多,但难以找到自己需要的那部分信息的问题.XML为组织、软件开发者、Web站点和终端使用者提供了许多有利条件.
2 基于XML的Web数据挖掘系统的模型
2.1 系统模型图
由于XML具有简单、开放、高效且可扩充、支持复用,能处理不同结构的数据,实现异构数据交换和共享,且内容和显示形式分离,表现数据能力较强,所以本文基于XML建立了Web数据挖掘系统的模型,模型分三个层次:数据获取层,数据存储层,数据挖掘层.结构如图1所示:

图1 系统模型图
2.2 系统模型各部分功能
系统模型各部分互相协调,统一合作,各部分功能如下:
数据获取层:从Web页获取各种异构、半结构化数据,包括HTML数据或XML数据,及Web服务器日志数据,对这些数据进行清洗、抽取、转换,将HTML文档进行规范化处理;把规范化后的HTML文档转化为XML文档,得到结构良好的数据.
数据存储层:将上一层获取的数据存储起来,以结构化数据库形式进行存储.由于XML是一种半结构化数据,强调数据语义与元素之间的关系,可以很容易将XML的文档描述与关系数据库中的属性对应起来.在数据存储层建立多层次Web数据库,提供Web的多维分析与层次化视图.
数据挖掘层:提供各种数据挖掘算法和有效的解决方案以及结合用户的兴趣模型,得出挖掘结果,对结果进行评价,若不满足用户需求,再提出新的挖掘要求,重新挖掘,最终为用户挖掘到所需要的信息,有效完成各种数据挖掘任务.数据挖掘的结果可用来完善用户模型,改善服务效率,改进站点结构设计.
3 系统实现中的关键技术
3.1 数据预处理
预处理是整个挖掘系统中的一个重要环节.Web页面内容预处理的目的是把文本、图片、脚本和其他一些多媒体文件所包含的信息转换成可以实施Web挖掘算法的规格化形式.预处理包括清洗、抽取、转换等步骤.
数据清洗的原理是利用数据清洗的规则和策略、数理统计方法和数据挖掘技术对“脏数据”进行清洗,使其变为满足应用要求的数据,提高数据的质量[5].数据清洗主要是解决多个数据源中数据的不规范性、二义性、重复和不完整等问题.包括空值处理、异常数据处理和不一致性数据处理等.具体为删除无关紧要的数据,避免无关数据对后续步骤的影响,合并某些记录,对用户请求页面时发生错误的记录进行适当的处理,检测数据中存在的错误和不一致,剔除或者改正它们,提高数据的质量.
数据抽取是对前面获得的数据抽取出代表其特征的元数据,以方便进一步处理.数据抽取在技术上主要涉及互连、复制、增量、转换、调度和监控等方面.基于XML的信息抽取[6]是基于网页特征结构的抽取策略,该方法先将HTML转化成XHTML,然后根据抽取规则对XHTML进行处理.
数据转换是把非XML的网页转换为相应的XML文档.使用Web包装器,结合TIDY软件将HTML数据源页面转换成XML代码的网页,以便进行挖掘.
3.2 权威页面的确定[7]
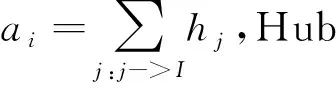
HITS算法如下:
输入:把WWW看作一个引导图W,查询请求q,n×n的邻接矩阵M,其元素

输出:权威页面的集合A,中心页面的集合H.
(1)R=SE(W,q);A,H初始化:A=(1,1,…,1),H=(1,1,…,1).
(2)B=R∪{指向R的链接}∪{来自R的链接}.
(3)G(B,E)=由B导出的W的子图.
(4)重复迭代A=MTH,H=MA,迭代后泛化A、H,A、H收敛于MTM,MMT的主特征向量.
(5)按Authority和Hub的权重逆序排列Authority页和Hub页,输出具有较大权重的Authorities页和Hubs页.
(6)结束
3.3 用户模型的建立
首先根据用户登录信息建立初始兴趣模型,然后根据用户访问信息对初始兴趣模型进行动态更新,建立相对稳定的用户模型.动态变化部分主要通过cookies分析模块、收藏夹分析模块和浏览动作捕捉模块[8]来分析用户对一个Web页的访问时间、频率、页内被访问的链接与未被访问的链接比、访问时长以及是否被作为收藏夹等计算用户对一个Web页的访问兴趣.根据分析这些数据,改进站点内容和结构,更好的服务于用户.也可以利用分类技术,通过训练得到用户分类模型,在训练好分类器以后用来推断未知统计特性的访问者的统计特性.
本文设计的模型充分应用XML的优势,以它为中介,实现非结构化数据向结构化数据的转化,同时充分将XML和个性化技术结合起来,挖掘出潜在的有价值的信息.
参考文献:
[1]曼丽春,朱宏.Web数据挖掘研究与探讨[J].西南民族大学学报,2005(2).
[2]夏火松.数据仓库与数据挖掘技术[M].北京:科学出版社,2009.
[3]陈景霞,张鹏伟.基于XML的Web数据挖据模型的研究[J].情报杂志,2006(11).
[4]范立峰.XML实用教程[M].北京:人民邮电出版社,2009.
[5]邱英.基于XML的Web数据存储与数据清洗技术研究与实现[D].武汉:武汉理工大学,2008.
[6]陈俊彬.Web信息抽取策略及其实现方法研究[J].科技情报开发与经济,2008(23).
[7]毛国君,等.数据挖掘原理与算法[M].北京:清华大学出版社,2007.
[8]周晓兰.基于XML的WEB的数据挖掘系统的框架探析[J].湘潭师范学院学报:自然科学版,2008(9)
