先秦人名识别初探
2009-08-31汪青青
汪青青
摘要:先秦人名和现代人名的构成方式和上下史语境有很大不同。本文以先秦文献《春秋左传》为突破口,对书中的人名进行了统计分析,挖掘其内部特征及分布特征。并且利用CRF模型对先秦人名的识别进行了初步的尝试。在开放测试中,该方法取得了92.48%的准确率。
关键词:先秦人名特征识别crf型
命名实体识别是自然语言处理的重要内容。但目前这方面的研究主要集中在现代文献领域,古籍中命名实体的识别是古典文献信息化进程中的关键所在,是一个值得探索研究的问题。
人名在先秦文献中占据很大的比例。据我们对《春秋左传》27万多字的语料统计:其中人名一共出现12900多次,人名总字数为28400多个字,占全书总字数的10.41%。因此,是否能正确识别人名直接影响着自动分词的精度。此外,先秦人名识别还是解决先秦人名异名同指和同名异指的基础,也是构建先秦人名知识库的基础。
一、先秦人名的特点
先秦人名和现代人名的构成方式及其上下文语境和现在有很大的差别。因此,我们首先要充分挖掘先秦人名的内部特征和分布特征。
(一)内部特征
1、构成成分多样
现代人名一般只有“姓氏”和“名字”两种构成成分,而先秦汉语中,情况要复杂得多。其构成成分有:姓、氏、名、字、谥号、爵位、职官、尊,亲称和“氏”字等。
A、“姓”和“氏”
今天我们一说到姓和氏,大家都觉得是一回事。但在先秦时代,姓和氏是有严格区别的。先秦姓氏分而为二,男子称氏,女子称姓。姓是用来别婚姻的,氏是为了明贵贱的。姓者,统其祖考之所自出,比较稳定;氏者,别其子孙之所自分,会随着封邑、官职的改变而改变(如:卫鞅、公孙鞅、商鞅),因此有时一个人会有几个氏或者父子两代不同氏。
在先秦文献中,姓的数量很少,据统计先秦的古姓的数量大约三十多种。《左传》中一共出现了二十几种;而氏的数量比姓多得多,在《左传》中共有657个氏,主要是以国(如:晋重)、以邑(如:随会,范会)、以官(如:中行桓子)、以字(包括名,如:国参)为氏,这四种命氏发式产生的氏名473个,占70%以上。
B、“名”和“字”
先秦人既有名,又有字。名是幼时起的,供长辈呼唤。男子到了二十岁成人,要举行冠礼;女子十五岁许嫁时,举行笄礼,也要取字。供朋友呼唤。古人尊对卑称名。卑自称也称名:对平辈或尊辈则称字。当名和字连称时要先字后名。如:孟明(字)视(名)。
先秦时人名以单字为主。当时凡有文化教养的人,都以取双字名为耻,几乎形成全社会清一色的单字名。如孔丘(孔子)、庄周(庄子)等都是单字名。贵族男子的字一般由“行次(伯艋、仲、叔、季)+字+父庸(二字古通用,男子的美称)”三部分组成。例如:伯(排行)禽(字)父(男子的美称)其中,行次和“父/甫”是可以省略的。男子取字还常在前面加“子”(“子”是对男人的尊称)。例如:冉求,字“子有”。先秦贵族女子也有字,一般由“行次+姓+字+母,女”四部分构成。例如:孟(排行)妊(姓)车(字)母(女性)。其中,行次和“母,女”也可以省略。有时甚至可以单称“某母”或“某女”。
C、“爵位”和“谥号”
爵位,又称封爵、世爵,是古代皇族、贵族的封号,用以表示身份等级与权利的高低。先秦时”爵位”大致分为公、侯、伯、子、男五级。谥号是皇帝、王或有一定社会地位的人死了后,朝廷或后人按其生前有无功绩,评定褒贬给予的称号。谥号一般是固定的一些字,这些字被赋予特定的涵义。谥号大致可以分为三类:A,表扬的,例如:庄、文、武、景、烈、昭、明、睿、康、穆等;B,批评的,例如:厉、灵、炀等;c,同情的。哀、怀、愍、悼等。上古谥号多用一个字。也有用两三个字的。例如:赵孝成王。
2、内部结构复杂
现代中国姓名结构简单,即:姓氏+名。但在先秦,姓名的结构复杂多样,而且女子的人名结构和男子的人名结构也不相同。
A、女子人名结构
妇女姓名主要涉及到以下几种成分:姓、氏、字、名、谥号、尊,亲称和“氏/妇”字,这几种成分除了姓以外,其它几种姓名构成成分视具体情况决定取舍。先秦女子称姓方式主要有以下几种:
A、氏+姓,如:“许(夫氏)姬(姓)”。
B、字+姓,如:“孟姜”。
c、谥+姓,如:怀(夫谥)赢(姓)。
D、姓+“氏”字,如:“姜氏”。
这几种形式在先秦文献中出现频率较高,除此之外,先秦女子还有单称姓、名+姓、“妇”字+姓、特殊称谓+姓、尊/亲称+姓、氏+字+姓、氏+谥+姓、氏+姓+名、姓十字+姓+名等多种形式,但这些形式出现的频率很低。
B、男子人名结构
男子的姓氏制度与女子的姓氏制度是大相径庭的。男子是绝对不称姓的,这一点与女子必须称姓的原则刚好相反。男子姓名主要有以下几种构成成分:氏、字、名、排行、谥号、尊,亲称、爵位和职官等。男子称氏的方式主要有以下几种:
A、氏+字,名,例如:南(氏)季(字)。
B、氏+爵位,例如:齐(氏)侯(爵位)。
c、氏+谥号+爵位,例如:郑(氏)庄(谥号)公(爵位)。
D、氏+字+名,当氏和名同时相称时,一般字放在名的前面。祭(氏)仲(字)足(名)。
以上几种称氏方式是男子称氏最常用的形式。除了这些,还有一些其它称氏方式。如:“单称氏”、“氏+职官”、“氏+亲称”、“氏+谥号+-Sz”、“职官+氏+字”、“氏+爵位+名”。
3、人名用字
A、在前315的左传训练语料中,一共出现汉字2929个,其中可以作为人名用字的有1021个。由此可见人名用字范围广、分布松散。
B、有些人名用字兼类的比例虽然大。但有的是很有规律的。例如:“公”在语料中出现了1630次。作为非人名用字的749次,其中以单字名词出现的就有546次,还有42次是在名词“公子”中出现。
C、人名用字虽多。其中有几类人名构成成分作为人名用字的频率较高:如:部分爵位、姓和字中的“排行”等,具体情况如下表

4、人名长度
我们对《春秋左传》前面315的语料中出现的七万多次人名的长度进行了统计,具体情况如下表:
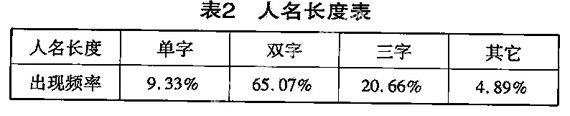
这里的出现频率是指在真实文本中某种长度人名的出现次数和所有人名出现次数之比。由上表可知,在先秦时期,双字人名和三字人名占绝对的优势。
(二)分布特征
1、上下文限制性成分
在语料中出现的人名限制性成分,主要有:
A、指界动词:日、言、谓、说、葬、闻、生、卒、帅、出奔等。
B、成串人名之间用顿号、“及”和“与”等连词连接。
2、句法成分
先秦人名在文中充当主语和宾语占绝对的优势。如:“郑伯克段于鄢”,其中,“郑伯”充当句子的主语,“段”充当句子的宾语。
二、基于CRF的人名识别方法
(一)先秦人名标注规范
A、先秦人名整体作为一个分词单位,标注为“nr”。
B、国名和人名连用时,有的是以国为氏(如:鲁庄公中的“鲁”),有的还存在争议(如:“宋向荣”中的“宋”),这种情况我们一律视为人名的氏来处理,但如果国名单独出现,则标为“ns”。
C、官名和人名连用时,同样有的是以官为氏(如:右宰丑),还有的也存在分歧,我们也一律视其为以官为氏。但如果官职名单独出现,则是普通名词。
D、“年号”和“××年”中的年号是一种纪年法,其中的年号虽形同人名,但不是人名(如:“昭公四年春”中的“昭公”),而是时间词的一部分。
E、某些称谓带有普通名词性质,如果单独出现,如:“公”、“王”、“太子”、“公子”、“公繇”等,有些虽然在一定上下文专指某个人,但我们把其标注为名词。
(二)语料的预处理
A、对原始语料《春秋左传》的文本进行校对,然后人工分词并标注词性。
B、将语料的前315作为训练语料,后2/5作为测试语料。
C、将标注文本转化为cRF格式文本。
(三)CRF模型简介
条件随机场模型(Conditional Random Fields。CRF)是由Lafferty在2001年提出的一种典型的判别式模型。它在观测序列的基础上对目标序列进行建模,重点解决序列化标注的问题。条件随机场模型既具有判别式模型的优点,又具有产生式模型考虑到上下文标记间的转移概率,以序列化形式进行全局参数优化和解码的特点,解决了其他判别式模型难以避免的标记偏置问题。
本文的实验使用了条件随机场模型,采用了TakuKu,do编写的工具包“CRF++-0.51”进行训练和测试。本文是以单字作为基本模型符号,设计了两种特征集进行了实验。

(四)特征模板和标记集的选择
1、特征模板
我们选用了6个一元特征模板,即:C-1,C0,C1,C*1 CO,COC1,C-1 C1。
2、标记集
实验1:我们选用了五词位标记集,即单字人名(Ⅲ_s),人名首字(nr_B),人名中间字(nr_I),人名尾字(nr_E)以及非人名用字(O)。具体标注例子如下:实验2:利于了词性和词位信息。具体标注例子如下:

(五)规则后处理
我们还利用了一些规则对识别的结果进行后处理,如果识别出来的人名是以下几种情况中的一种。则排除该人名:A,识别出的人名是“公”、“王”、“子”、“太子”“公子”和“公孙”等名词。B,识别出的人名是“军尉”、“司马”、“司空”、“舆尉”、“候奄”和“亚旅”等官职名。C,识别出的人名“×公”在“x公xx年”的结构中。D,识别出的人名长度大于六。
(六)实验结果及分析
根据测试集和训练集的不同关系,可以将评测分为封闭测试和开放测试。测试的结果采取了常用的3个评测指标,即准确率(P)、召回率(R)和综合指标(F)来评测人名识别的结果。
具体的实验结果如下表:

(表4实验结果)
从上面的两个实验对比可以看出:在这两个实验的封闭测试中都取得了很好的效果。但在开放测试中效果有明显的差别:在实验1中,只利用简单特征就达到了较高的正确率,但召回率较低;在实验2中,利用了词性特征,有效地提高了召回率,但随着特征数量的增加,也产生了一些“噪声”特征数据,影响模型的训练和识别速度与正确率。
三、结论和将来的工作
本文的研究对先秦人名自动识别进行了尝试。取得了一定的效果。我们未来的主要研究工作是进一步扩大语料的规模,我们准备对25种先秦传世文献进行处理@。从中充分挖掘先秦人名的特征,提高人名识别的正确率和召回率。同时,我们进行人名的识别不仅仅是为了给人名加上标记而已,而是为了研究异名同指和同名异指服务,从而为自动构建人名知识库奠定基础。
注释:
①http://crfpp.sourceforge.net/.
②陈小荷,先秦文献的信息处理刍议,中文信息学会会议上的发言,2008,11,23
参考文献:
[1][晋]杜预,春秋左传集解,上海古籍出版社,1977
[2]陈絮,商周姓氏制度研究,商务印书馆,2007
[3]刘开瑛,中文文本自动分词和标注,商务印书馆,2000
[4]杨伯峻,春秋左传注,中华书局,1981
[5]张淑一,先秦姓氏制度考索,福建人民出版社,2008
[6]孙茂松,黄昌宁,高海燕,方捷,中文人名的自动辨识,中文信息学报,1995,(02)
[7]严军,《左传》姓氏相关问题的探索,浙江学刊,1994,(04)
基金项目:南京师范大学211工程三期重点学科建设项目“语言科技创新及工作平台建设”子课题。
