基于本体的机构信息智能检索系统的设计与实现
2009-07-15冯微峰
冯微峰
〔摘 要〕本文提出了一个基于本体的智能检索系统的设计框架并实现了主要的功能模块,该检索系统对中科院图情方向的机构信息进行提取和加工,利用本体语言对中科院图情方向的组织机构,主要研究人员,重大研究项目等之间的逻辑进行描述,构建一个以机构为主要对象的具有逻辑推理 性的功能本体,并通过自定义规则,加载泛化规则引擎来实现系统的智能检索功能。
〔关键词〕智能检索;机构信息;推理规则;本体建模
〔中图分类号〕G35 〔文献标识码〕B 〔文章编号〕1008-0821(2009)03-0170-06
本体对领域和任务进行了良好的描述,具有较好的概念层次结构和对逻辑推理的支持,从而在信息检索,特别是在智能检索中得到了很好的应用。在基于本体的智能检索系统中,通过对原始信息的加工提取和本体的语义推理机制,可以进一步提高检索结果和检索目标的相关性,从而使得检索结果更加符合人们的要求。
起初,国内外本体研究机构[1]主要着力于顶层本体和领域本体的研究和探索,而现在随着功能本体广泛的应用,对于功能本体的研究也越来越多了。比如说,对一个跨国机构进行本体建模,利用本体对该机构的组织、资源、技术等进行逻辑描述。与资源直接相关是人,通过本体的逻辑性就可以知道,需要资源的人是属于哪个部门的,他具有什么样的研究技能。通过对机构的本体描述就可以优化机构的运作流程,促进信息沟通和便于协同管理。
本文提出了基于功能本体的智能检索系统的构建模式和设计思想并且对系统的实现方案进行了解析和探索研究。
1 智能检索系统框架设计方案
本文采用以Java环境下的Eclipse平台加MySQL数据库作为系统实现的基础,并使用Jena和JPowerGraph等Java开源包。系统的体系结构如图1所示。
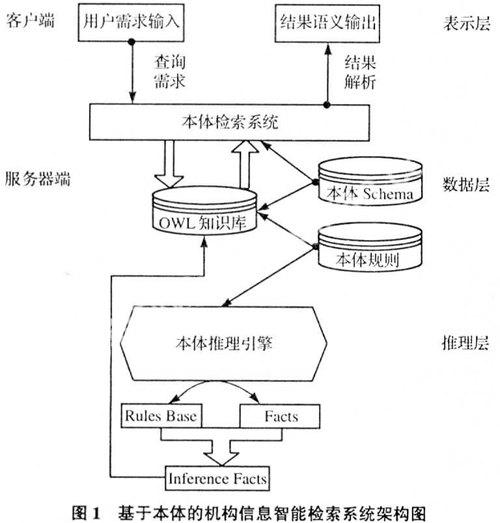
智能检索系统是一个三层体系架构:
1.1 表示层
这一层主要是通过JSP给用户提供UI接口。用户需求输入的表达方式主要有如下几种:一是以自然语言方式表示,最典型的例子是关键字的方式;二是以特定的查询语言表示,如SQL、RQL、SPARQL[2]等;三是以可视化的方式表示,例如通过菜单选择查询条件的方式。本文设计的用户需求输入的目标就是在准确表达用户需求的同时,尽可能使得用户的输入操作简单易行,因此一方面从服务器端取得本体的Schema,生成清晰的树形结构,用户可以通过点击树形结构上的节点获得所需信息,另一方面用户可以根据需要选择检索的类型,比如“根据地区检索”、“根据研究机构检索”、“根据研究人员检索”、“根据研究项目”等等。也可以通过限制查询条件和查询范围和特定关键词来实现复杂查询。
结果语义输出[3]是指把语义类、语义属性和语义关系的实例进行可视化的输出,对JPowerGraph开源包进行二次开发,把相关的语义数据转化为相关联的节点和边,动态的呈现给用户。
1.2 数据层
数据层包含本体Schema、推理规则和OWL知识库3部分。本文以网上公布的中科院图情机构相关信息作为原始材料进行语义提取,将最终结果转化为OWL格式文件本体数据,从本质上来讲,就是一组OWL文件和一系列推理规则(Rules)文件。本论文的智能检索系统中所构建的中科院组织结构信息本体是从地区、机构、人员、项目4个维度来定义的语义本体。
首先通过讨论确定语义类、语义属性、语义关系以及传递、对称、相反等规则。然后将讨论结果定义为数据字典,数据字典包括名称及其说明部分。最后在数据字典确定以后,通过Protégé手工创建OWL和推理规则文件。
1.2.1 本体Schema
本体的Schema是整个系统的概念基础,它提供了本体模型基本的类别层次结构,是定义推理规则的基础,是OWL知识库中信息的结构基础。
1.2.2 推理规则
推理规则以Jena规则语法描述,是进行基于推理的查询的基础。
1.2.3 OWL知识库[4]
用OWL描述的本体知识,是智能检索系统的数据源,它不仅包含了实例化的本体本身,还包含了本体经过描述逻辑推理(DL reasoning)[5]分类后的隐含信息以及本体推理引擎推理所获得的蕴含知识。
1.3 推理层
推理层采用Jena[6]自带的GenericRuleReasoner。该泛化规则引擎是基于规则的,并且支持用户的自定义。该推理引擎支持前向链、后向链以及二者混合的推理执行模型,更准确地说,Jena有2个内部规则引擎:前向链推理RETE[7]引擎和一个tabled da talog engine[7]。它们可以独立运行,或者前向链作为后向链引擎的先导,来完 成“查询——问答”。泛化规则引擎可以自定义规则,因此具有强大的推理功能和灵活性, 并且易于扩展,因此本智能检索系统的推理以基于静态规则推理为主,采用GenericRuleRea soner,根据事实库中的已有事实,加载规则库中的规则,并将新的事实加入到OWL知识库中 ,实现了OWL知识库内容的更新与扩充。
2 智能检索系统实现方案
2.1 浏览器端
对于浏览器端而言,采用Ajax框架实现浏览器端的主要功能。Ajax采取了JavaScript+DOM的方式来实现与浏览器的交互功能。另外,Ajax利用基于JavaScript的XmlHttpRequest组件提供Xml数据异步传输,它能够实现页面无刷新的数据传输。浏览器端主要包括了以下3个方面的功能:
2.1.1 本体知识的检索
本体检索的界面如图2所示。用户可以采用简单查询和复杂查询2种方式来进行本体知识检 索。简单查询就是输入关键词进行查询。复杂查询一方面可以通过导入本体的Schema文件,采用Jtree这个插件生成清晰的本体检索导航树,用户可以点击相关节点进行查询。另一方面用户可以指定检索条件和检索关系来构造复杂查询。检索条件包括地区名称、机构名称等等。检索关系包括所属关系、拥有关系、合作关系等等。

2.1.2 本体知识的添加
本体知识的添加的界面如图3所示。用户通过添加各个类别的实例来实现OWL事实库的初始化。本体的Schema和本体的初始事实库是以后进行语义推理的知识基础。用户也可以直接添加本体事实描述,用户首先选择相关的本体类别,比如说用户选择了“Branch”类,则后面级联的选择框会自动弹出事实库中已有的该类的实例,比如说用户选择了“国家科学图书馆北京分馆”的实例,然后选择“HasDepartment”关系,在最后的本体实例框中填写了“信息技术部”,这样用户就添加了这样一条本体事实:
国家科学图书馆→HasDepartment→信息技术部

2.1.3 结果语义可视化输出
结果语义可视化输出如图4所示,这个功能主要是通过JPowerGraph开源包来实现的。用户在客户端提交了检索内容后,服务器端通过语义推理将与检索内容相关联的语义类、语义属性和语义关系传回给客户端,客户端再通过JPowerGraph可视化功能把获得的相关联的语义类、语义属性和语义关系的实例转化成节点和边,动态的呈现给用户。
2.2 服务器端
对于服务器端而言,包括数据层和推理层两层结构,所以服务器端主要实现以下两大功能模块:
2.2.1 本体知识库的建立和持久化
本文以中科院图情机构为例说明构建机构信息这个功能本体的基本流程。
(1)机构信息本体的建立
因为机构具有良好的层次性,所以采用自上而下的本体构建法。首先标识本体中最通用的概念,然后在通用层次上创建相应的种类并逐步的细化本体。总体而言只要包括以下3个步骤:
①分析机构本体和定义数据字典
该机构本体是中科院图情方向的机构信息为基础,利用本体语言对该方向的组织机构、主要研究人员、重大研究项目等进行逻辑描述。所以相关的实体主要包括:

相关本体描述:
1.房俊民老师是情报研究部的成员。
2.房俊民老师的研究方向是竞争情报。
3.……
4.……
图4 语义结果可视化输出
机构:名称,地址,简介
分支机构:名称,地址,简介
部门:名称,人员数目,简介
导师:姓名,职称,性别
学生:姓名,性别
研究方向:名称,简介
研究项目:名称,时间段,经费
本文将机构信息所用到的词典整理出来,这些词汇有可能是类或是属性,将在后面几个步骤中加以区分。表1是本文所制定的词典。
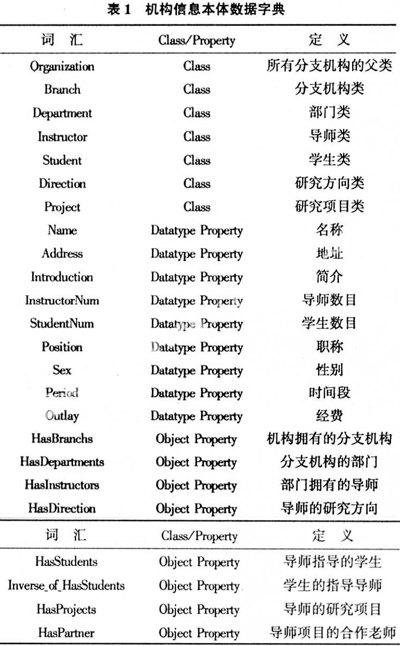
词 汇Class/Property定 义OrganizationClass所有分支机构的父类BranchClass分支机构类DepartmentClass部门类InstructorClass导师类StudentClass学生类DirectionClass研究方向类ProjectClass研究项目类NameDatatype Property名称AddressDatatype Property地址IntroductionDatatype Property简介InstructorNumDatatype Property导师数目StudentNumDatatype Property学生数目PositionDatatype Property职称SexDatatype Property性别PeriodDatatype Property时间段OutlayDatatype Property经费HasBranchsObject Property机构拥有的分支机构HasDepartmentsObject Property分支机构的部门HasInstructorsObject Property部门拥有的导师HasDirectionObject Property导师的研究方向 续表1
词 汇Class/Property定 义HasStudentsObject Property导师指导的学生InversezofzHasStudentsObject Property学生的指导导师HasProjectsObject Property导师的研究项目HasPartnerObject Property导师项目的合作老师
②建立类别、属性和实例
类别:
该本体包括Organization、Branch、Department、Instructor、Student、Direction、Project等类别及其它们的子类别和父类别,本体的根节点是owl:Thing。
属性:
在属性方面可分为数据属性(Datatype Property)和对象属性(Object Property)。
数据属性:使用RDF(S)的数据类型,包括定义域(domain)、值域(range)和公理(axiom)。
定义域:定义域限制该属性在哪一个类别使用。
值域:数据属性的限制包含any、string、integer、boolean、float、symbol,可以使用xml schema datatype,在填入实例时只要符合其数据类型限制即可。
公理:可以使用functional,如果一个属性P被声明为functional,那么对于每个个体,属性最多只有1个值。
该机构信息本体的数据属性如表2所示。Name使用的定义域包括Organization、Branch、Department、Instructor、Student、Direction、Project等类别,因为这些类别都会有一个特定的名字,所以Axiom是Functional的。其它几项数据属性也同样具有Functional的特性。
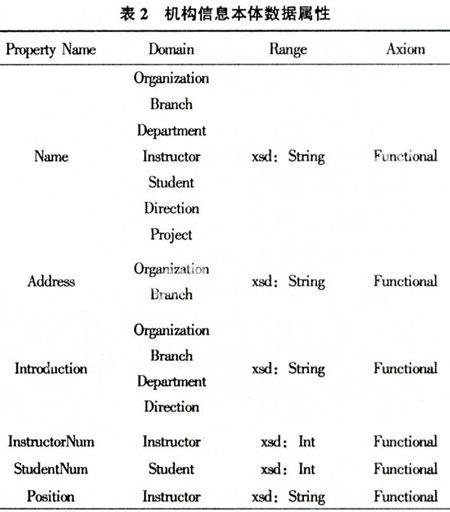
对象属性:仍然包括定义域(domain)、值域(range)和公理(axiom)3个方面。
定义域:限制该属性在哪一个类别中使用。
值域:对象属性的值域是类的实例而不是具体的数值。
公理:包含Functional、InverseFunctional、Symmetric、transitive、Inverse等Axiom。
该机构信息本体的对象属性如表3所示。
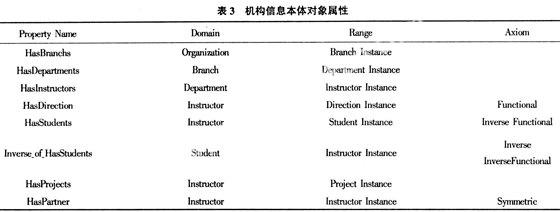
HasBranch的Domain是Organization,Range是Branch类的实例,定义了Organization拥有的Branch。
HasDepartment的Domain是Branch,Range是Department类的实例,定义了Branch拥有的Department。
HasInstructors的Domain是Department,Range是Instructor类的实例,定义了Department拥有的Instructor。
HasDirection的Domain是 Instructor,Range是Direction类的实例,定义了Instructor的Direction,因为中科院图情方向的老师一般都只有1个研究方向,所以Axiom是Functional。
HasStudents的Domain是Instructor,Range是Student类的实例,定义了Instructor拥有的Student。因为中科院图情方向的老师一般都只有1个学生,所以Axiom是Functional。并且设定它与InversezofzHasStudents具有Inverse的关系。
InversezofzHasStudents的Domain是Student,Range是Instructor类的实例,定义了Student的Instructor。它与HasStudents属性具有Inverse的关系,并且HasStudents是Functional的,所以InversezofzHasStudents具有InverseFunctional属性。
HasProjects的Domain是Instructor,Range是Project类的实例,定义了Instructor拥有的Project。
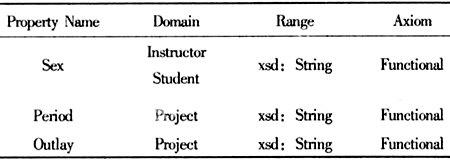
HasPartner的Domain是Instructor ,Range是Instructor类的实例,定义了Instructor拥有的Partner。因为对于同一个项目的导师而言他们是互为partner,因此Axiom是Symmetric。
实例:
在本体的Schema构建完成后,Organization类、Branch类、Department类、Instructor类、Student类、Direction类、Project类的实例作为初始化的查询条件,在本体规则基础上经过首次推理以后形成原始的OWL知识库。
(2)本体知识库的持久化
本体数据持久化有文件存储和数据库存储2种方式,文件存储是将本体库以文件形式存储在本地文件系统中,将数据从文件中读入内存,在内存中对本体库进行一系列的操作,操作完成后再将本体库以文件形式写回到文件中。
以文件方式存储本体库轻便快捷,适合于小型的本体库。因为它不需要过多的配置,而且便于备份、复制,还可以随时编辑修改,而且查询速度快。缺点在于不适合较大的本体库,因为它每次都需要读入内存在做操作,因此耗用太多的内存,如果再加入推理机将会占用大量 的内存,而且对于模型的修改需要一次性保存全部模型,效率不高。
而关系数据库来持久化本体数据可以处理更大更复杂的本体模型,而且利用数据库存储本体模型,可以使得本体模型具有更大的灵活性和可扩展性,对于大多数本体应用来说,数据库方式是较好的选择。
因此本智能检索系统采用关系数据库来持久化本体数据,Jena通过一个数据库引擎接口实现了对本体模型的透明持久化,目前支持的数据库主要包括3种:MySQL,Oracle,PostgreSQL and Microsoft SQL server。本系统采用MySQL作为本体数据库。其核心代码包括4个方面:
①创建数据库的连接
IDBConnection conn=new IDBConnection(MzDBzURL,MzDBzUSER,MzDBzPASSWD,MzDB);
OntModelSpec spec=OntModelSpec.OWLzMEM;
spec.setModelMaker(ModelFactory.createModelRDBMaker(conn));
②在已有数据库连接的基础上创建本体模型
Model base=maker.createModel(″MyNameModel″);
OntModel model=ModelFactory.createOntologyModel(spec,base);
③把本体本件转化成三元组存储到MySQL数据库中
URL url=ClassLoader.getSystemResource(″file:src-examples/data/test1.owl″);
model.read(url.toString(),″RDF/XML-ABBREV″);
④从MySQL数据库中获取已存储的本体数据
Model m=
ModelFactory.createModelRDBMaker(conn.openModel(″MyNameModel″));
2.2.2 本体推理规则库的建立和推理引擎的加载
(1)建立推理规则库[8]
在基于规则的推理机中,规则被定义为一个Java的Rule对象,该对象由body terms(前提)的list,head terms(结论)list以及可选的名字和可选的方向来定义。每一个term或者ClauseEntry是一个三元模式(triple pattern),一个扩展的三元模式(extended triple pattern)或者一个内嵌过程原语的调用。
规则文件支持一些额外的宏命令:
@prefix pre:http:∥domain/url#。
定义一个前缀pre,前缀对规则文件来说是局部的。
@include
包含在一个给定文件中定义的规则。不管@include出现在哪里,包含的规则都将出现在用户定义的规则前面。规则文件可以包含预定义的规则,例如RDFS和OWL等,这时urlToRuleFile被关键字RDFS,OWL,OWLMicro,OWLMini取代。
下面是包含RDFS预定义规则的一个规则文件的完整例子:
# Example rule file
@prefix ins:
@prefix rel:
@include
[rule1:(?f ins:hasproject?a)(?u ins:hasproject?a)->(?f rel:haspartner?u)]
这条规则是指如果导师f有项目a,导师u也有项目a,推出导师f和导师u是合作者。
(2)加载规则推理引擎[9]
规则文件的加载和分析是这样进行的:
List rules=Rule.rulesFromURL(″file:myfile.rules″);
或者
BufferedReader br=/*open reader*/;
List rules=Rule.parseRules(Rule.rulesParserFromReader(br));
或者
String ruleSrc=/*lists of rules in lines*/
List rules=Rule.parseRules(rulesSrc);
3 小 结
本文以机构信息为例着重阐述了基于本体的智能检索系统框架设计和基本功能模块的实现。本体推理模块在本体的描述逻辑上加载了可以自定义规则的泛化规则引擎,提高了推理能力,从而可以获得更加有意义的蕴含知识。本体数据持久化的模块采用数据存储与本体模型存储相分离的方案,即:本体数据库只存储基本的数据信息,本体Schema采用单独的文件保存。OWL知识库的已有事实在加载本体Schema后,经过推理获得新的蕴含知识添加到OWL知识库中,从而实现了OWL知识库的更新与扩充。这种方式的本体数据存储的数据结构设计更加简单,本体模型也具有更好的迁移性。而对于如何做好本体的可重用性和面向特定领域之间的平衡,以及推理规则的优化和大规模本体存储的数据结构设计是今后研究工作的重点和难点所在。
参考文献
[1]邓志鸿,唐世渭,张铭,等.Oniology研究综述[J].北京大学学报:自然科学版,2002,38(5):730-738.
[2]SPARQL Query Language for RDF[EB/OL].http:∥www.w3.org/TR/rdf-sparql-query,2008-05-10.
[3]董慧,余传明,杨宁,等.基于本体的数字图书馆检索模型研究——体系结构解析[J].情报学报,2006,25(3):269-275.
[4]Zhijun Zhang.Ontology Query Languages for the Semantic Web:A Performance Evaluation.Masters Thesis,2005:5-34.
[5]F.Baader,D.Calvanese,D.MeGuinnes,The Description Logic Handbook:Theory,Implementation and Applications,Cambridge University Press,2003.
[6]Jena-A Semantic Web Framework for Java[EB/OL].http:∥jena.sourceforge.net,2008-03-15,2008-09-10.
[7]袁方,王涛.基于本体的推理机研究[J].计算机工程与应用,2006,(9):158-165.
[8]侯冕,廖乐健.基于语义Web本体语言的推理机引擎的实现[J].军民两用技术与产品,2005.7:41-43.
[9]韩亚洪,刘永革.本体的查询与推理机制研究[J].计算机工程与应用,2005.9:82-85.
