基于Web3.0的高校图书馆图书采访智能化决策设想
2009-07-13马启花
马启花
〔摘 要〕文章针对目前高校图书馆图书采访决策存在采访人员主观判断,导致图书利用率低等现象,充分利用Web3.0先进技术,计算机通过对用户需求、馆藏数据、书目数据、图书价值、学科经费分配等方面进行全面综合权衡、判断、评价,最后做出图书采访智能化决策。这种方法比传统采访人员图书采购决策做法显得更客观更科学,排除了采访人员主观判断干扰,能较大程度地提高图书馆馆藏质量和提升图书馆服务水平。
〔关键词〕Web3.0;图书馆;图书采访
〔中图分类号〕G253 〔文献标识码〕A 〔文章编号〕1008-0821(2009)04-0117-03
A Tentative Plan of the Intelligentized Web3.0 Based
Decision Making of Book Purchase in University LibrariesMa Qihua
(Library,Yulin Normal University,Yulin 537000,China)
〔Abstract〕There exist phenomenon in university library book purchase like the subjective judgment of personnel which may lead to low book utilization ratio at present.The article puts forward that,by making full use of Web3.0 advanced technology,computers can balance,judge and appraise the user餾 need,the collection data,the catalogue data,the value of books and the distribution of money to different disciplines,and thus it can make an intelligentized decision on book purchase.This method appears more objective and more scientific than the traditional method made by the personnel making policy on book purchasing and it can remove the subjective judgments too.Obviously,this method improves the quality of the library餾 collection and promotes the library餾 service.
〔Key words〕Web3.0;library;book purchase
图书采访工作是高校图书馆文献资源建设的前提和基础,其质量的高低,直接影响着图书馆的馆藏质量、服务水平和用户的满意度。但是,由于技术条件、采访人员自身条件等因素的制约,长期以来,高校图书馆的图书采访决策停留在凭经验的定性分析水平上,对许多学科图书的把握和订购精确度不高,使得整个图书经费分配呈现出不合理的现象。其二,用户参与选书在多数高校已经不是什么新鲜事,但采访人员与用户缺乏真正地广泛地交流,用户真正参与选书的很少。尽管不少学校也建立了学科专家选书委员会,但这种方法存在着许多的不足。由于专家不是图书馆的在编人员,没有责任务必做好这项工作,为图书馆选书常常被看作是额外工作,可干可不干,非专职性决定了它的局限性。图书馆若聘请这些专家,成本又太高。因此,在实际工作中,大部分图书采访还是采访人员凭主观判断决策,造成图书馆馆藏结构不合理,图书利用率低,用户需求得不到最大限度地满足。如何科学地做出图书采访决策,已成为高校图书馆工作中的重中之重。
关于图书采访决策的研究,成果颇多,如:朱世平对图书采访辅助决策系统进行了系统框架结构构建,但对系统具体设计和实现并未给出,同时利用层次分析对经费进行了分配,但未对图书本身价值进行评价。游丽华运用模糊数学的理论给出高校图书馆藏书特征模糊集和图书隶属函数,并建立了中文图书采访模块,但未注意学科之间的经费分配比例。靖培栋等从书刊影响因素入手,对书刊采购决策进行了深入系统研究,以尽量保证学科经费分配公平为目的,采用席位分配模型构建了按学科分配经费的数学模型,但未给出书刊本身价值评价的数学模型。向桂林等详细讨论了图书价值构成因素并与图书价值的关系,建立了计算图书价值的数学模型,并通过已有馆藏某类书刊的流通,计算每个大类图书的评分比率来分配购书经费,但未考虑如何从待选书刊中进行采购决策。李武等在给出计算书刊本身价值定量模型的基础上,给出了按学科专业分配采购经费的概念性步骤。资芸等将优选图书按其重要程度分为3个等级,在全面考虑图书价值和读者需求的基础上,确定了6个图书评价决策要素,但未考虑学科专业经费的合理分配。
从以上分析可知:图书采访决策要么从图书本身价值,要么从学科分配资金,要么从图书价值和学科资金分配相结合角度来研究。不管是从哪个角度来研究,若对每本书刊做手工计算则太繁琐,在实际工作中采访人员在做图书决策前做这么复杂的工作,也不太可能。这些决策模型离不开计算机条件的辅助。但是,在这些决策模型中,计算机只是起到辅助作用,还需要人工操作输入,图书采访决策还是由图书采访人员决定,还掺杂采访人员主观意愿。为此,笔者在以上研究的基础上,利用Web3.0智能化技术,计算机通过对用户需求、馆藏数据、书目数据、图书价值、学科经费分配等进行全面综合权衡、比较、判断、评价,最后做出图书采访决策,采访人员只需根据计算机输出结果发订单就行了。这种方法显得更客观更科学,排除了采访人员主观判断干扰,能较大程度地提高图书馆馆藏质量和提升图书馆服务水平。
1 Web3.0的特点
对于Web3.0,目前还没有权威、确切的定义,Google CEO埃里克施密特将其定义为:Web3.0是一系列组合在一起的应用。杰森•加拉勘尼斯将Web3.0定义为:由天才们利用Web2.0的技术作为切实可行的平台,创造高质量的内容和服务。索尼斯从广义的范围来对Web3.0进行了界定,认为:Web3.0这一术语结合了不同思想来描述互联网的功能及其影响将沿着几个不同的方向进化;这些进化方向包括将网络转变成为一个数据库,各种非浏览器应用程序可以获取网络内容,使网络朝着人工智能技术、语义网、地理空间或3D空间等方向发展。斯彼瓦克从系统的角度来谈论Web3.0,认为Web3.0就是将统计学、语言学、开放数据、计算机智能、集体智慧和用户在网上生成的内容全部集合到一起,这并不是一个特定的技术,它是发生在特定时期的一个集合。指出了Web3.0应当是各种网络技术进步的结果。
从以上观点可看出:Web3.0是Web2.0进一步发展的结果,其的核心软件技术是人工智能,能够进行语义的智能学习和理解。因此,Web3.0技术的运用可实现互联网更加人性化、精准化和智能化。
1.1 智能化
所谓智能,就是说这些不是通过人工编辑的,而是基于搜索技术和统计技术的。它是全面展现信息真实面貌的一个载体。Web3.0利用RDF的3倍存储器(RDF triple store),可以迅速建立起网络内容之间的本体联系,整个因特网络可以看为一个复杂的本体库。通过动态内容搜索引擎(Dynamic content engine),就可以很快地实现对网络内容深入挖掘,从而满足用户的自然语言查找。人们查找信息,只需你打开电脑,输入你要查找的问题,计算机通过动态内容引擎在3倍存储器中进行本体化操作,在网络中自动搜集,对各种信息资料进行相关性迅速比较、权衡、评价,最后给出你需要的结果。而不是当前搜索引擎所做的给出一些相关或不相关的结果,由用户自己阅读和甄选。也就是说,在Web3.0环境下,用户得到就只是自己所需的信息,其它的如信息比较、甄选、评价等工作全部由计算机代替,由计算机去思考。
1.2 兼容性
在Web3.0环境下,网络更加开放包容,整个互联网就是一个数据库,每个网站服务器都将是Web3.0整体数据库存储单元的一部分,都拥有平等的查询入口。任何一个网络节点的终端计算机,用户只需输入查询命令就可以了,不必考虑本系统是否与其它服务器系统存在兼容性等问题,系统自动在后台为你操作。在Web3.0条件下,语义网已经发展成熟完善,信息可以直接从底层数据库之间进行通讯,底层数据库具备完整的信息交换机制,信息可以直接和其他网站相关信息进行交互,实现windows、liunxs(unixs)和mac系统的融合兼容,并能将设计和编程、三维虚拟现实技术和交互网络编程技术等高度融合,通过第三方信息平台同时对多家网站的信息进行整合使用。
1.3 人性化
Web3.0时代的最大价值不是提供信息,而是提供基于不同需求的智能过滤器和综合需求满足的平台,而每一种过滤器都是基于一个用户需求,综合的平台则是基于用户的综合需要,从而给互联网带来新机会和新革命。Web3.0时代,每个人都能看到同样一个模式的综合化门户将不复存在,因为Web3.0的平台是以微单元构成,用户可以根据自己的兴趣、爱好、需求、性格、知识等组合单元,构建出个性化的信息平台。平台将根据用户需求,智能化处理互联网海量信息的整合,最终聚合用户个性化的需求。
1.4 精准化
Web3.0网站是基于用户需求的智能过滤器和多元化需求满足平台,应用Mashup技术将精确地阐明信息内容特征的标签进行整合,提高信息描述的精确度;应用UGC技术筛选过滤信息,提高信息获得的可信度;应用聚合技术和挖掘技术,使搜索信息反应迅速、准确。因此,获取信息将变得比以往任何时候都要便捷而精确。
目前美国的Facebook网站(www.facebook.com)、中国的大脉网(www.my160.com)、热度网
(www.redoo.com)、雅蛙(www.yaawa.com)、阔地(www.codyy.com)等,都具有Web3.0网站的特征,可实现信息的个性化、主动自由聚合,跨平台操作,信息一站式服务等。
2 图书采访智能化决策构想
在Web3.0环境下,图书采访模式“民主选书,集中决策”得到最大限度的诠释,真正地实现了由全校用户参与选书工作,不过“集中决策”不是由采访人员或选书专家决策,而是由计算机智能决策。计算机智能化决策图书采购,改变了在自动化系统管理模式下,读者只是形式上参与选书,大部分的选书工作还是由采访人员独立完成局面;也改变了采访人员与用户之间缺乏交流的局面。利用Web3.0先进技术条件,用户可以广泛参与选书,计算机根据用户需求智能化决策所购得的图书,没有掺杂采访人员或选书专家个人主观意愿,真正体现“用户第一”理念,从而最大限度地提高用户满意度和提升图书馆服务水平。基于Web3.0图书采访智能化决策工作流程图如下:
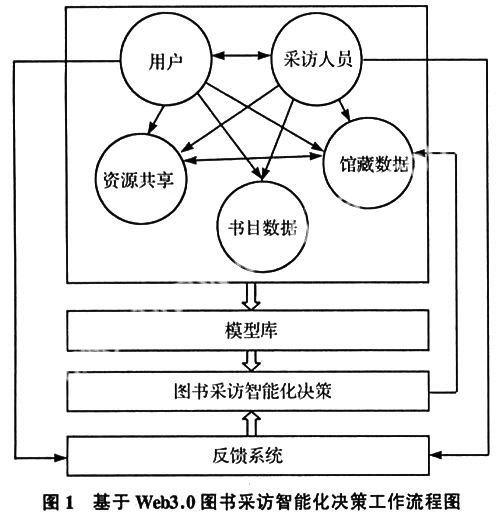
2.1 信息采集
在Web3.0条件下,用户查找资料不再是先登录图书馆自动化管理系统,查看本馆是否馆藏。如果本馆没有馆藏,则看本馆与其他馆资源共享是否有这类资料。如果还没有,则通过图书荐购系统荐购这类资料,或浏览采访人员书目数据,查看是否有这类资料。而是只需用户输入查找信息,计算机会自动从馆藏数据库、资源共享库、书目数据库或其他网站进行全面收集、比较、整合、评价,给出用户需要的信息,用户看到的就是他想得到的结果。此外,在Web3.0条件下,用户根据自己拥有的信息资源,可以向图书馆、信息资源共享库或书目数据库提供信息。
采访人员充分利用Web3.0先进技术,广泛与用户进行交流互动。通过交流互动,采访人员能深入有效了解不同层次用户的个性化需求,有针对性地广泛收集新书书目、教学参考书目、科研项目参考书目、用户推荐书目、馆藏补充书目等信息,构建书目信息源数据库。征订书目数据查重等工序,采访人员交给计算机去做就行了,采访人员只需输入一些条件限制如:本校专业设置,重点学科和一般学科,课程设置等等信息,计算机就会进行自动筛选,剔除馆内已有收藏无须加复的数据,形成待选书目信息源。同理,采访人员根据自己拥有的信息资源,可以向图书馆、信息资源共享数据库或书目数据库提供信息。
2.2 模型库
在模型库里,主要储存有图书评价模型、经费分配模型等几个核心数学模型。计算机在做图书采购决策前,将用户所采选的图书,置之于模型库。根据图书价值影响因素(学术水平、针对性、价格),不同层次用户对影响图书价值的因素的不同评价;根据学校教学(包括国家重点学科、省重点学科,一般重点学科、博士点和硕士点)、科研(国家级、省部级和一般)和用户层次(本科生、硕士生、助教、博士生、讲师、副教授以上)及数量等情况。自动综合考虑、运用层次分析法计算各因素在图书采访质量中的权重,给出图书评价结果和各学科经费分配比率,并根据具体实际情况,不断调整数学模型,得出恰当数学模型。
比如,假设影响图书价值因素为:学术水平、针对性、价格,计算机通过计算给出它们权重为:0.5、0.4、0.3,评价采用5分制,对一种书的评价如果是“5、5、5”,那么这种书的评价是“学术性最高、针对性最强、价格最便宜”。如果某一用户对一种书影响因素的评价是:4.5、4.0、4.0,那么该用户对这种书的评价值则为:0.5×4.5+0.4×4.0+0.3×4.0=5.05。假如有5个副教授对一种书的评价为:4.8、4.5、4.3、4.2、4.0,那么该书的最终评价值为:(4.8+4.5+4.3+4.2+4.0)/5=4.36。对于不同层次的用户,如副教授以上(博士)、讲师(硕士)、助教、本科生,假设给出权重依次为:0.4、0.3、0.2、0.1,对一种书的评价为:4.8、4.6、4.4、4.2,那么该书的最终评价值为:0.4×4.8+0.3×4.6+0.2×4.4+0.1×4.2=4.6。
2.3 图书采购智能化决策
根据图书评价结果和各学科经费分配比率,计算机自动比较、推断、归纳、确定购买图书种类、某类别图书数量及某类别图书经费控制,根据用户需求强度确定图书复本量,最后输出图书需采购种类和复本结果。采访人员根据计算机输出结果进行发订单。
2.4 反馈系统
反馈系统起控制作用,即利用结果对原因的反作用来调整书刊的采选活动。它包括读者反馈、图书馆各环节系统数据反馈、文献利用效果反馈等。新书到馆后,经验收、编目、著录、典藏,最后进入流通。计算机会自动根据用户利用图书的反馈情况,图书借阅情况,拒借情况,文献利用效果情况等,做出各种分析和判断,并作为图书采购的决策依据和参数,经常修正文献采购误差,提高选书质量的参数指标。
计算机技术是向前发展的,而且发展速度是惊人的。从web1.0到Web2.0,人们还在谈论Web2.0时,Web3.0已经悄然逼近。在Web3.0时代,先进的技术,计算机进行图书采访智能化决策不是不可能的,而是完全有可能实现的。
参考文献
[1]朱世平.图书采访辅助决策系统的基本途径[J].大学图书馆学报,1993,(3):10-13.
[2]游丽华.高校图书馆中文图书采访模型的初步研究[J].图书情报工作,1995,(4):33-36.
[3]靖培栋.图书馆书刊采购模型研究[J].图书情报工作,2004,48(1):30-32.
[4]向桂林,吴金艳,辛希孟.采访质量控制数学模型研究[J].中国图书馆学报,2003,(1):36-39.
[5]李武,赵海兰,傅英姿,等.高校图书馆书刊采购决策及决策支持系统研究[J].情报理论与实践,2006,29(6):709-711,705.
[6]资芸,钟叔玉,董毅明.高校图书馆图书采访决策模型研究[J].情报杂志,2007,(6):145-147.
[7]傅英姿,李霞.高校图书馆采购决策建模及信息支持系统[J].图书情报工作,2007,51(9):84-86,99.
[8]吴汉华,王子舟.从“Web3.0”到“图书馆3.0”[J].图书馆建设,2008,(4):66-70.
[9]张振接,梁祥丰.Web3.0向我们走来[J].科技与出版,2007,(2):58-59.
[10]郭涛.Web3.0时代悄然逼近[J].博客,58-59.
