文本提取分类技术在海关资讯中的应用研究
2024-12-16林嘉宜梁晓智张鹏谢俊敏






摘 要:随着人工智能技术快速发展,自然语言标注、识别和提取分类技术也取得较大进展,基于此类技术的智能模型应用广泛,但是模型应用时的通用性和泛化性仍是技术难点。为解决目前资讯分析中信息量大、处理过程繁杂、通用性和泛化性不高等问题,本文提出了一种通用的资讯文本信息提取和分类算法,并基于人工智能框架建立模型,将其应用于海关资讯信息分析。试验证明该模型具有较好的信息提取和分类效果。
关键词:文本提取;文本分类;深度学习
中图分类号:TP 311 " " " " " 文献标志码:A
资讯的来源多样,包括非结构化的公开新闻、报道、内部案情和情报等[1]。其文本也包括风险防控相关特定领域的有用信息。但是资讯文本存在逻辑复杂、实体嵌套和多层次分类难以识别的问题。传统算法仅能进行一般的结构化识别和提取,对国内海关资讯文本特征的适配度低,难以达到智能化、精准化分析目标。
人工智能深度学习技术的发展为资讯文本智能化分析带来了新思路[2]。国内、外在此方面进行了不断研究,利用自然语言处理模型高效、准确地解决了大规模的生物、化学和医疗等多个领域文本的实体或关系抽取;基于生成式路线的基础模型完成了通用文献资讯的写作优化和准确化文本分析任务[3];中国海关利用国际人工智能框架也进行了有效的通用抽取,例如国家、物品、数量和日期等。总的来说,人工智能技术用于文本结构化已成为国内、外资讯分析的重要手段。为解决国内资讯文本提取的智能化和精准化问题,本文在资讯文本分析中引入国内人工智能框架,设计文本提取和分类模型,将其应用于海关资讯分析,不仅能够满足数据安全和自主可控要求,还能进行快速分析和风险预警,提升风险研判效能。
1 融合文本提取与分类技术的资讯文本分析新方法
国内的人工智能框架在自然语言处理等领域展现出了优秀的性能和可控性。该框架与国内模型相结合,具有更好的数据隔离、保护机制以及更可控的算法、模型训练过程。此外,该框架在与国内数据平台和安全技术的集成方面更具优势。基于自然语言处理的文本提取技术旨在从大规模无结构文本中自动提取结构化信息(包括实体、关系和事件等,其中实体提取是指识别文本中具有特定意义的信息)。文本分类技术也是一种将文本自动分类到预定义类别的自然语言处理技术,常用于情感分析、主题识别等任务。
1.1 资讯文本分析新方法及其模型
根据资讯文本既要精准提取知识,又要智能分类文本的分析目标,本文提出的新方法是在使用知识增强的预训练模型的基础上进行调优,从而形成的文本提取和分类模型。
1.1.1 主体模型设计
本项目模型将基于国内人工智能框架的Ernie[4]知识增强预训练模型作为主体模型,该模型具备多任务范式间的协同处理能力。该模型架构由通用表示层和特定表示层组成。通用表示层能够获取不同任务范式中相同底层的抽象特征,例如词汇信息和句法信息等;特定表示层包括自然语言理解(NLU)特定表示模块和自然语言生成(NLG)特定表示模块。基于这种上、下2层架构,利用较少的训练语料和时间成本对特定表示层调优,就能快速、有效地提升特定任务的识别效率和适应性。
ERNIE 3.0的通用表示层和任务特定表示层均将Transformer-XL结构作为主干。本文在新算法模块的预训练任务中采用具有48个transformer层、4 096个隐藏单元和64个注意力头结构的通用表示层;采用具有12个transformer层、768个隐藏单元和12个注意力头结构的特定表示层。并使用GeLU激活函数和Adam优化算法。参数设置如下:上、下文的最大序列长度为512,语言生成的记忆长度为128,总批量大小为6 144,学习率为1×10-4。通过单词感知、结构感知和知识感知预训练任务,使模型具备理解、生成和推理能力。
1.1.2 模型特定能力泛化
进行资讯文本分析,需要利用预训练好的参数组合来初始化模型,再对预训练的主体模型的特定表示层进行调优,使调整后的模型获得宽泛的资讯文本提取和分类能力。
1.1.2.1 资讯文本提取能力泛化
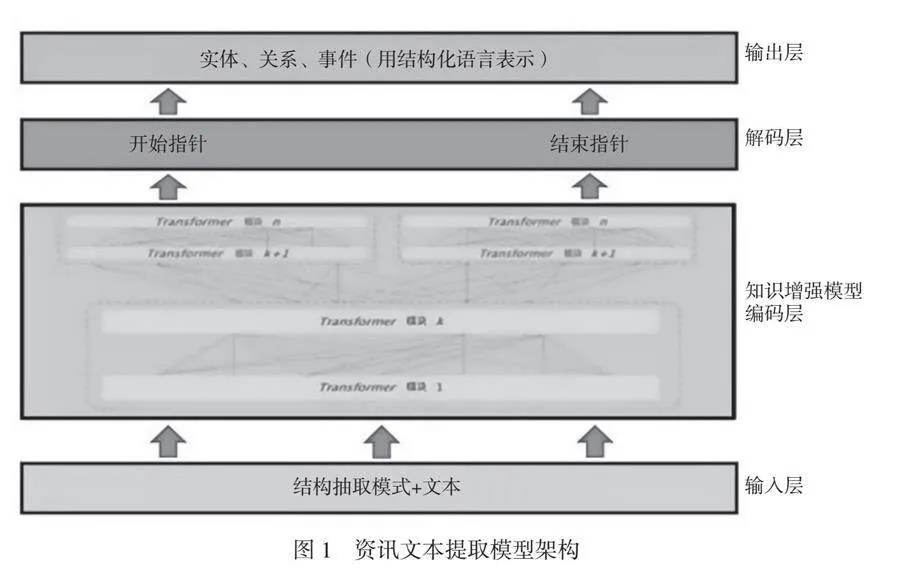
传统的资讯文本提取结构化的信息,不同任务间的数据表示和网络均存在差异。本文以多任务统一建模的方式进行调优,借鉴通用信息提取框架范式[5],在输入层使用基于提示机制的结构模式,指导模型在训练过程中自适应地判别提取目标。知识增强模型编码层就是主体模型。在输出层,解码后的主体模型结果采用结构化提取语言,将不同任务的提取结果表示为统一的形式。利用调优,使模型具备不限定行业领域和抽取目标的关键信息抽取能力。主要过程如图1所示。
输入的表达式如公式(1)所示。
y=UIE(s⊕x) " " " " " " " " (1)
式中:y为抽取并生成的结构化结果;s为定义的结构抽取模式;x为输入文本。
文本提取的整体输入形式如公式(2)所示。
s⊕x=[s1,s2,...,si,x1,x2,...,xi] " " "(2)
式中:si为第i个结构抽取模式的组件;xi为第i个原始文本序列内容。
将公式(2)展开,得到最终模型输入结果,如公式(3)所示。
s⊕x=[[spot],sp1,...,[spot],spi,...,[asso],a1,...,[asso],ai,...,[text],x1,...xi] (3)
式中:[spot]为后面接实体;spi为第i个不同类别实体;[asso]为后面接关系或事件;ai为第i个不同类别的关系或事件;[text]为后面接文本内容。
1.1.2.2 资讯文本分类能力泛化
传统的资讯文本分类存在不同任务间的标签迁移难度大和学习知识不共享的问题。本文采用多任务统一语义匹配方式进行调优,将分类任务统一建模为标签与文本间的匹配任务。知识增强模型编码层是主体模型,在解码层采用定向标记链接,将输入内容解码成标签与文本间的词对链接并计算分数,在输出层输出标签名词和文本内容的关联对。调优后的模型支持不同领域间标签知识的迁移和众多“泛分类”任务。主要过程如图2所示。
输入的表达式如公式(4)所示。
H=Encoder[l1,l2,...,li,t1,t2,...,ti,M]
(4)
式中:li为第i个标签序列;ti为第i个文本序列;M为掩码矩阵,用于确定哪些序列对可以相互关注。
配对的连接分数表达式如公式(5)所示。
S(li,tj)=FFNNlabel(hli)TRj-iFFNNtexthtj
(5)
式中:(li,tj)为标签和文本标记配对的连接;FFNNlabel、FFNNtext分别为前馈神经网络,数据会单向传播且过程中没有反馈连接;Rj-i为旋转位置嵌入,可注入相对位置信息;hli、htj分别为标签和文本标记的嵌入表示。
以上2种模型泛化训练需要调节的超参数主要包括训练周期、最大学习率、批量处理大小以及文本最大切分长度等,以使相应参数达到最优区间,提高资讯文本提取和分类的精度。
1.2 模型评价
1.2.1 资讯文本提取模型
通常,文本提取将准确率p、召回率R和F1分数作为评估指标。在模型优化过程中,提高准确率可以减少将实体错误识别和将类别错误归类的概率,提高召回率则可以捕捉更多正确的实体并减少遗漏。这2个指标间通常需要进行平衡,应在平衡的前提下,将两者维持在相对较高的水平,以获得最佳性能。3个指标的表达式分别如公式(6)~公式(8)所示。
(6)
(7)
(8)
式中:Tp为预测正确实体数;Fp为不是该类实体而被错误地预测到该类的实体数;Fn为该类文本被误预测到其他类别的实体数。
1.2.2 资讯文本分类模型
文本分类评估一般采用Macro F1和Micro F1作为评估指标。Macro F1是F1分数的宏观平均,对每个类别的F1分数取平均值,避免模型性能主要由数量大的类别主导。Micro F1全面评估模型在所有类别上的总体性能。不断参数调优,使各种评估指标达到最优。指标相关的表达式分别如公式(9)、公式(10)所示。
(9)
(10)
式中:n为所有类别总数;F1i为第i个类别的F1分数;Psum为所有类别总的准确率;Rsum为所有类别总的召回率。
2 新方法在海关资讯文本分析的应用研究
2.1 海关资讯文本分析模型构建
针对海关资讯文本行业背景和专业术语特殊的特点,利用上文提出的提取与分类技术融合的新模型进行资讯文本提取和文本分类模型的优化和适配,构建查获资讯智能提取和分类模型,提高海关资讯分析的准确性和适用性。在海关缉私和旅检等场景中,海关的资讯文本多为进、出口货物查获情况信息。应用场景为查验事后分析预警环节,模型构建的数据来源为海关公告、媒体报道、综合报告和周报等资讯数据。选取近一年进、出口货物查获资讯作为训练数据,数据的选取原则为保证样本集有足够的多样性,以覆盖海关领域的主要知识点和标签范围。将资讯中有效实体定义为29类(可动态调整),包括查发国家/地区、来源地、目的地和价值等;将资讯分类定义为104类(可动态调整),包括现场查验、货物夹藏、水运和侵权风险等,然后根据自定义的实体标签和分类标签进行人工标注,将标注后的货物查获记录转化为词向量,将其作为模型输入数据,有效样本数据约1 100条。
本文建模基于通用的提取与分类技术融合的新模型。该模型能够通过少量的梯度更新适应新任务。模型采用具有12个transformer层、768个隐藏单元和12个注意力头的结构,采用少样本学习方法,以少量货物查获资讯标记数据集作为输入并计算输出,再以少次训练迭代,反向传播优化模型中编码层和解码层的全量参数。在不断的参数调整过程中得到货物查获实体识别模型和分类识别模型,对海关资讯中专业的海关术语进行编码表示;在解码层针对实体执行提取任务,预测海关资讯实体的起始位置和结束位置;针对分类任务,预测海关资讯标签和文本的连接关系;最终在输出层输出以结构化表示的货物查获资讯实体和分类。
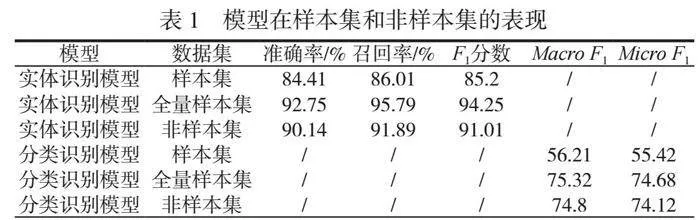
2.2 模型效果
模型在样本集和非样本集的表现见表1。由220个测试样例验证模型效果可知,实体识别的结果是准确率为92.75%,召回率为95.79%,F1分数为94.25。分类识别的结果是Macro F1为75.32,Micro F1为74.68。使用全量样本集进行调优后,2个模型预测准确率分别提高了8.34%和19%,识别效果显著提升。同时,使用非样本集共200条新增文本进行预测,实体识别准确率为90.14%,分类识别准确率Macro F1为74.8。与样本测试集的识别效果相比,准确率下降幅度较小,可见在海关资讯文本领域,本文模型具有较好的实体提取和分类泛化能力。
资讯文本提取和分类模型已用于3 374条各种无结构资讯文本的关键信息自动识别,每天预警分析的资讯量由过去人工操作的数十条提高至1 000多条,夯实了海关资讯分析工作,能够对大量未标记海关资讯文本进行自动解析/识别、快速检索分析和风险预警,海关资讯文本分析实例如图3所示。模型还不断进行适配性迭代训练升级,其智能化和准确度也在逐步提升。
3 结论
本文提出的融合文本提取和分类新算法的模型能够快速进行资讯文本自动处理和分析,具有通用性和泛化性。该模型在海关领域的资讯文本分析应用中取得了良好效果。实践表明,经过特定领域数据集增强训练后,该模型将具有更好的行业适配性和更高的识别准确度。
参考文献
[1]郑彦宁,化柏林.数据、信息、知识与情报转化关系的探讨[J].情报理论与实践,2011,34(7):1-4.
[2]白如江,陈鑫,任前前.基于供需理论的生成式人工智能赋能情报工作范式模型构建与应用研究[J].情报理论与实践,2024,47(1):75-83.
[3]李广建,潘佳立.人工智能技术赋能情报工作的历程与当前思考[J].信息资源管理学报,2024,14(2):4-20.
[4]SUN Y,WANG S H,FENG S K,et al.ERNIE 3.0:large-scale
knowledge enhanced pre-training for language understanding and generation
[EB/OL].[2021-07-05].https://arxiv.org/abs/2107.02137.pdf.
[5]LU Y J,LIU Q,DAI D,et al.Unified structure generation for universal information extraction[EB/OL].[2022-03-23].https://arxiv.
org/abs/2203.12277.pdf.
