人工智能在工业自动化控制系统中的应用
2024-12-06张瑞强



摘 要:在具有高延迟、非线性特性和强耦合性的复杂工业环境中,实现稳定而准确的连续控制面具有一定挑战。为了应对该问题,本文提出一种基于二阶价值梯度的强化学习模型的创新控制策略。该策略首次将状态价值函数的二阶梯度信息纳入模型训练,旨在利用更准确的函数近似提高学习迭代效率,并增强模型的鲁棒性。本文还引入一种高效的状态采样策略,以优化策略学习过程。基于OpenAI Gym平台和2种工业场景的仿真测试表明,与基于最大似然估计的传统模型相比,本文方法显著降低了环境模型的预测误差,提高了学习效率和控制性能,有效减少了控制过程中的振荡现象。
关键词:强化学习;二阶价值梯度;工业自动化;控制策略
中图分类号:TP 273" " " " " " " 文献标志码:A
目前,强化学习在工业自动化控制领域得到广泛关注,特别是在处理非线性和强耦合系统方面表现出极大潜力。然而,无模型强化学习需要大量数据,因此在复杂场景中受限。相比之下,基于模型的强化学习通过构建环境模型来减少实际交互,提高了数据利用率和学习速度。此外,本文引入二阶梯度信息的状态价值函数,提出了基于二阶价值梯度的方法,采用状态采样策略,显著提升了学习效率和控制性能。该研究为复杂工业自动化控制提供了新的视角,并开辟了研究和实践的新途径。
1 工业自动化控制中的人工智能应用
1.1 模型驱动的决策学习在工业控制中的应用
工业自动化控制系统的核心是其决策过程,可将其理解为一种序贯决策问题,适合建立一种称作马尔可夫决策过程的框架。该框架由5个元组(S,A,P,r,γ)定义,其中,S为一系列可能的状态,A为可能采取的动作集合。转移概率P(s'|s,a)描述了在当前状态s和动作a下转移到新状态s'的概率,而r(s,a)为奖励函数,表征在特定状态和动作下智能体获得的即时回报[1]。同时,折扣因子γ用于调整未来奖励的当前价值。在该系统中,智能体通过与环境的互动产生交互轨迹τ=(s0,a0,s1,a1,...),并获得一系列奖励(r0,r1,r2,...),累积奖励的总和,如公式(1)所示。
(1)
式中:η为累计奖励的总和,是智能体在整个过程中的期望奖励;t为时间步长,是在序列中的每个时间点;γ为折扣因子,范围为0~1,用于调整未来奖励的当前价值,越接近1,表示未来奖励的权重越高,越接近0,表示未来奖励的权重越低;r(st,at)为奖励函数,是在特定状态st下采取动作at后获得的即时奖励,状态st为智能体在某一特定时间点所处的状态,动作at为智能体在某一特定时间点采取的动作。
公式(1)表示在时间步长从0到∞的过程中,所有折扣奖励的总和。
强化学习的目标是找到一个最优策略π*,能够最大化累积奖励的期望值,如公式(2)所示。
(2)
在基于模型的强化学习中(MBRL),一种常用的方法是利用神经网络来学习一个环境模型P(s'|s,a;θ),其中θ为网络参数。可使智能体能够在没有与实际环境交互的情况下利用与环境模型交互进行学习和决策。
1.2 工业控制中的模型驱动策略优化与价值感知学习
在经典模型驱动强化学习中,模型学习和策略优化通常是分开的。例如,MBPO算法结合SAC策略进行学习,先在真实环境数据上训练环境模型,然后利用此模型和SAC算法迭代优化策略,以获取高累积奖励。但是,环境模型的精确度与策略优化的目标可能不一致,会导致出现低预测误差的模型,无法保证最优奖励。为解决该问题,本文引入了价值感知的模型学习方法VAML,该方法在模型学习阶段融合状态价值信息,旨在使模型与实际环境间的单步价值估计差异最小化,如公式(3)所示。
loss(p,p' )=∫μ(s,a)|∫p(s'|s,a)V(s' )ds'-∫p'(s'|s,a)V(s' )ds'|dsda" (3)
式中:loss(p,p' )为损失函数,用于衡量2个概率分布与p' 间的差异;V(s' )为状态s'下的价值函数,分别在真实环境和模型环境p'(s'|s,a)下进行评估;μ(s,a)为状态和动作对的概率分布。
VAML方法的核心是利用价值函数的精确估计来定义损失函数,在实践中需要利用神经网络进行估计,并可能引入偏差。
1.3 工业自动化中的增强模型训练(价值梯度方法)
在工业自动化控制系统中,VaGraM方法是VAML的改进版,它提供了一种更精确的模型训练方案。该方法重视价值函数的梯度信息。假设环境模型预测的下一状态与实际非常接近,通过泰勒展开求近似值函数,并结合状态间的差值。VaGraM的损失函数计算了模型预测与泰勒展开基于梯度差异的平方和,从而提升了预测精度和模型的学习效率,如公式(4)所示。
(4)
式中:lossθ为目标函数,衡量的是模型在状态s下采取动作a并转移到状态s'的预测准确性;∑为对所有可能的状态和动作组合进行求和;Pθ(s'|s,a)为转移概率,表示在状态s和动作a下转移到新状态s'的概率分布;ΔV(ss)为状态价值函数关于状态的梯度,即价值函数在状态空间中变化的方向和幅度;(s-s')为状态差,表示模型预测的下一状态′与实际状态间的误差;dsda为该损失函数在状态-动作空间上进行积分或求和,以考虑所有可能的状态和动作。
2 在高维控制系统中的二阶价值梯度强化学习
2.1 提升学习效率的二阶泰勒展开策略
在自动化控制系统优化中,强化学习算法的整合推动了控制策略的发展。在处理复杂工业任务过程中,为提升模型训练速度和学习效率,本文引入了一种二阶价值梯度模型和新的状态采样策略。该模型假设智能体预测的下一状态与实际环境的下一状态非常接近。与一阶泰勒展开方法相比,本文使用二阶泰勒展开进行向量化表达,以更精确地近似价值函数,如公式(5)所示,该公式是一个函数在某一点x0附近的二阶泰勒展开,用来近似函数f(x)在x点的值。
f(x)≈f(x0)+∆f(x0)T(x-x0)+(x-x0)T+H(x0)(x-x0) (5)
式中:f(x0)为函数在点x0的值;f(x0)T(x-x0)为利用函数在x0处的梯度来捕捉f关于x的一阶变化;(x-x0)TH(x0)(x-x0)为函数在x0处的海森矩阵H(x0)考虑二阶效应,即f的局部曲率。
2.2 增强型状态采样策略在自动化控制中的应用
在工业自动化控制系统的AI应用中,有效利用环境模型非常重要[2-3]。本文优先从预期高回报状态开始推演,增加智能体学习高价值状态路径的机会。该方法不仅能帮助智能体掌握达到高价值状态的策略,还能覆盖低价值状态,实现了全面学习。还引入了以Boltzmann概率分布为基础的状态采样策略,由价值网络估计的状态价值和超参数β控制,如公式(6)所示,该公式表达了一个依赖于状态价值函数V(s)的概率分布p(s)。
p(s)∞eβV(s) " " " (6)
式中:p(s)为状态s的概率分布,该概率分布描述了智能体选择状态时的偏好,概率越高表示智能体越有可能选择该状态;e为自然常数,约为2.71828,它是指数函数的底数,在该公式中用于将价值函数转换为概率分布的一部分;β为超参数,控制价值函数对概率分布的影响程度。
通过这样的设置,智能体能够根据状态的估计价值进行状态采样,平衡探索高价值和低价值状态的策略。
3 在工业自动化中的强化学习应用示例
本文在OpenAI Gym平台使用二阶价值梯度模型,评估了包括MuJoCo的CarPole、InvertedPendulum和Hopper环境在内的多种测试场景。同时,仿真试验还包括青霉素生产和食品加工工业场景,利用MATLAB/Simulink和Python模拟关键控制过程。试验通过设计奖励函数,有效评估并提升了控制策略的性能,如公式(7)所示。
(7)
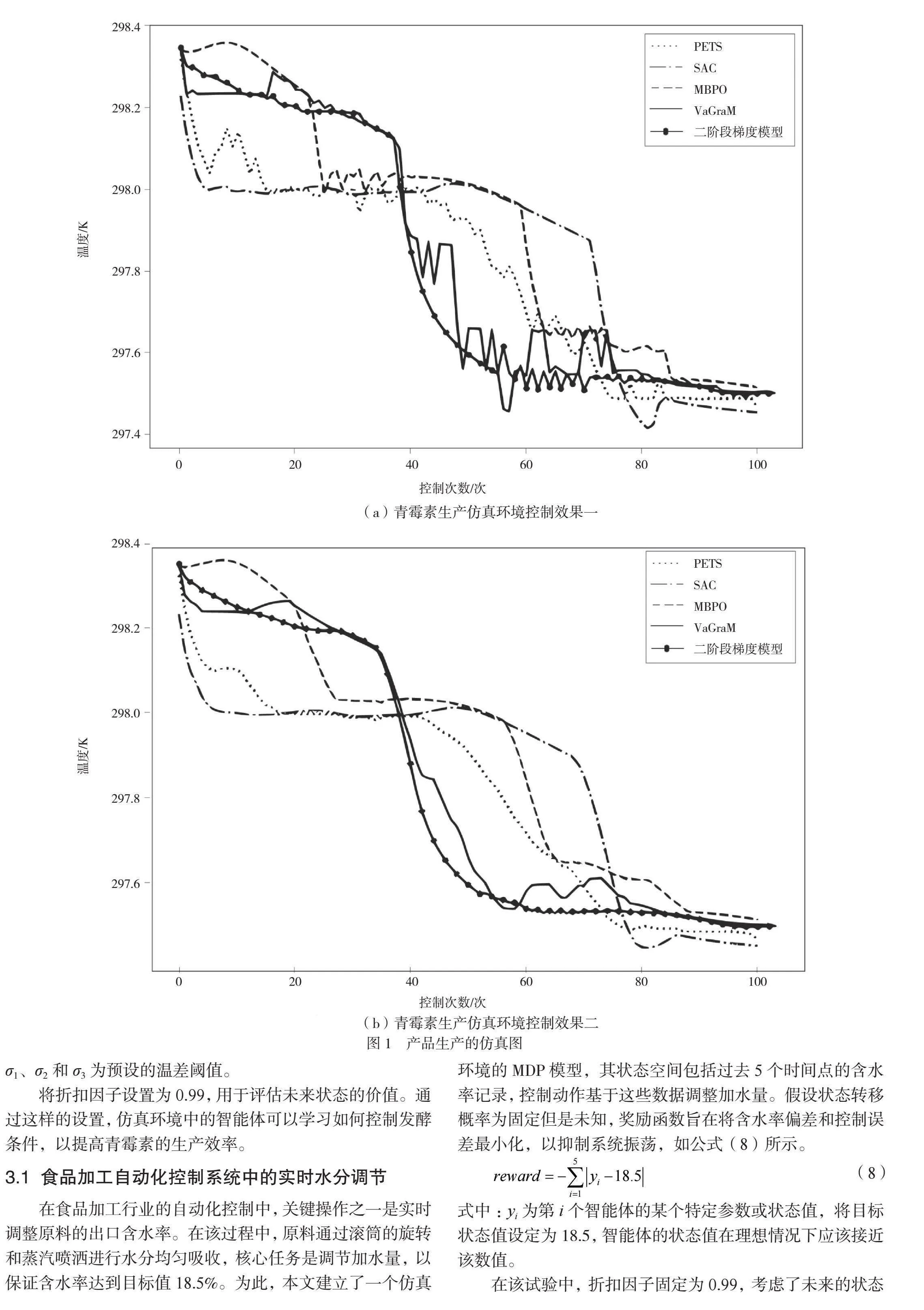
式中:reward为奖励值,用于评估系统在当前状态下的表现,奖励值可以是正数,也可以是负数,分别表示正向激励和负向惩罚;err为当前温度与目标温度297.5 K间的差值;σ1、σ2和σ3为预设的温差阈值。
将折扣因子设置为0.99,用于评估未来状态的价值。通过这样的设置,仿真环境中的智能体可以学习如何控制发酵条件,以提高青霉素的生产效率。
3.1 食品加工自动化控制系统中的实时水分调节
在食品加工行业的自动化控制中,关键操作之一是实时调整原料的出口含水率。在该过程中,原料通过滚筒的旋转和蒸汽喷洒进行水分均匀吸收,核心任务是调节加水量,以保证含水率达到目标值18.5%。为此,本文建立了一个仿真环境的MDP模型,其状态空间包括过去5个时间点的含水率记录,控制动作基于这些数据调整加水量。假设状态转移概率为固定但是未知,奖励函数旨在将含水率偏差和控制误差最小化,以抑制系统振荡,如公式(8)所示。
(8)
式中:yi为第i个智能体的某个特定参数或状态值,将目标状态值设定为18.5,智能体的状态值在理想情况下应该接近该数值。
在该试验中,折扣因子固定为0.99,考虑了未来的状态价值。
3.2 强化学习方法在自动化控制系统中的应用比较
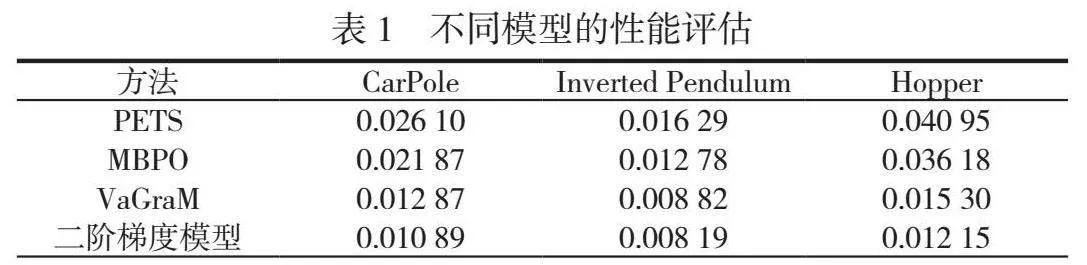
在自动化控制系统的最新研究中,本文与多种主流控制算法进行了比较,包括PETS、SAC、MBPO和VaGraM方法,展现了基于二阶价值梯度强化学习方法的优越性。本文利用累积奖励、均方误差和平均绝对误差等评价指标,从多个维度验证了新方法的有效性,并进行了性能分析,优化了超参数设置。同时,在公共强化学习环境中对CarPole、Inverted Pendulum和Hopper这3种场景进行了比较,见表1。
结果显示,本文方法在学习效率、快速收敛性和奖励稳定性方面具有优越性,尤其在处理复杂的Hopper任务中表现良好。与VaGraM方法相比,本文方法在预测精确性和模型误差上有所改进,显示了良好的鲁棒性和较高的更新效率,训练效率更优。综上所述,本文方法在自动化控制领域的人工智能应用中具有显著的实用价值。
3.3 自动化控制中基于二阶价值梯度的强化学习方法的应用实证研究
为展示基于二阶价值梯度模型强化学习方法的效用,本文在青霉素生产和食品加工的工业仿真场景中进行了试验。结果表明,在青霉素生产仿真中,本文方法与其他方法(例如PETS和MBPO)相比,误差减少了约3%,在训练速度上具有优势,如图1所示。在食品加工仿真中,本文方法性能更优,显示了其在复杂环境中的调控能力,如图2所示。无论是青霉素发酵过程的温度控制,还是食品加工中的含水率控制,本文方法均能快速响应且系统稳定性高,超越了传统和无模型控制方法,显示了其在实际工业应用中的潜在价值。
4 结语
在自动化工业控制领域的研究中,基于二阶价值梯度的强化学习方法证明了其在处理复杂动态系统过程中的显著优势。无论是在标准测试环境,还是特定的工业仿真场景中,该方法不仅加速了模型的收敛过程,还提高了策略的稳定性和效率,特别是在青霉素生产和食品加工的控制任务中更具优越性。试验结果显示该方法在准确模拟和预测复杂工业过程中具有强大能力,在实际应用中也具有高效控制潜力。本文研究不仅推动了工业自动化控制系统的技术进步,也为未来深度强化学习在工业应用领域的发展奠定了坚实基础。
参考文献
[1]李辰.人工智能在工业自动化控制系统的应用探讨[J].数码设计,2021,10(11):60-61.
[2]丁建军.智能制造技术在工业自动化生产中的应用研究[J].机械与电子控制工程,2024,6(1):180-182.
[3]李占辉.人工智能技术在电气自动化控制中的应用问题探讨[J].水电科技,2024,7(1):90-92.
