机器学习在金价时间序列预测中的应用
2024-11-21王星月王晓玲




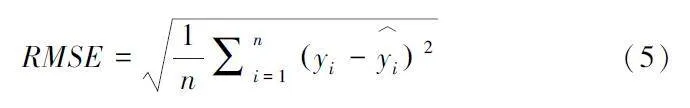
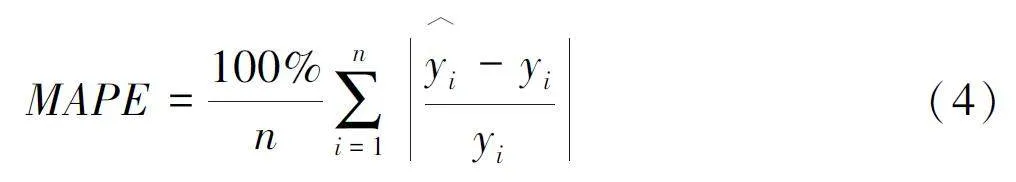





摘 要: 文章利用COMEX 黄金期货每日收盘价共2019 个数据点, 探讨机器学习技术在黄金价格时间序列预测中的应用与效能。数据集被分为80%的训练集和20%的测试集, 以评估预测模型的准确性和泛化能力。首先, 以ARIMA (3, 1, 3)作为基线模型, 其性能表现不佳。随后, 运用多种机器学习模型进行比较分析, 包括长短期记忆网络( LSTM)、BP 神经网络、随机森林模型以及小波神经网络, 以评估它们在金价预测中的性能。最后, 小波神经网络在测试集上的性能指标显示出良好的预测精度, 同时BP 神经网络也展现了卓越的预测能力, 共同印证了机器学习技术在黄金价格预测领域的有效性。文章的结果对于金融市场分析师和投资者来说, 提供了一个强有力的工具, 以更准确地理解和预测黄金市场的动态。
关键词: 金价预测; 时间序列分析; 机器学习; 小波神经网络; 预测评估
中图分类号: F22; F831; TP18 文献标识码: A
文章编号: 1674-537X (2024) 10. 0014-09
一、引言及文献综述
金价对全球经济的影响深远, 不仅是衡量经济状况的关键指标, 也是投资者在进行避险操作时的首选工具。金融市场的不断发展使得金价预测变得极其重要且复杂。从个人投资者到大型金融机构,市场参与者们都在寻求更为精准的预测方法, 以便优化投资策略并降低风险。另一方面, 金价的波动会影响到宏观经济的稳定, 因此政府和监管机构需要对金价有准确的预测以便做出相应的经济政策决策。在传统市场中, 虽然多种统计模型被广泛应用于金价预测, 但随着金融数据量的激增和市场行为的日益复杂化, 这些传统方法在处理海量数据和复杂市场动态方面的局限性逐渐凸显。
近年来, 众多研究者运用各种传统统计模型对金价进行预测, 旨在揭示影响金价变动的关键因素, 并提高预测精度。薛吟凇以中国黄金期货实际波动率为预测目标, 选取了2010 年到2022 年历时12 年的样本数据, 将来自中国、美国期货、期权市场的波动率信息作为解释变量, 使用AR 和HAR 模型对比两个国家、两类市场的信息在预测中的不同表现, 得出中美期权市场均含有独立于期货外的预测信息和在期货市场, 中美黄金期货波动率有正向的预测作用的结论[2] 。吴虹晓收集了2008 年1 月至2023 年9 月的上海期货交易所主力黄金期货合同价格和上海黄金交易所AU (T+D) 现货价格数据,通过运用Johansen 协整检验、Granger 因果检验以及脉冲响应函数, 探讨了黄金期货与现货价格的相互关系, 进而得出黄金期货价格与黄金现货价格之间存在显著相关性, 且二者存在长期均衡关系的结论[3] 。徐静怡等人选取了2020 年1 月2 日—2021年12 月31 日纽约COMEX 黄金期货价格作为研究样本, 通过构建ARIMA 模型进行实证分析, 并得出黄金价格在未来短期内将保持稳定增长, 最后针对黄金价格变化趋势分别对投资者和监管部门提出相关建议[4] 。
在金价预测的研究中, 机器学习技术的应用已经展现出其深厚的潜力。梁龙跃等人通过对原数据进行分解, 利用样本熵SE 方法将分解所得的子序列重构合并为高频、中频、低频序列, 再分别输入步长为1 天、7 天、30 天的LSTM 模型进行预测,并建立4 种对比模型进行比较分析, 进而得出CEEMDAN-SE-LSTM 三阶段组合模型能够更准确预测黄金期货价格走势的结论[5] ; 在张均东、刘澄和孙彬的研究中, LM-BP 人工神经网络模型通过结合宏观经济因素与时间序列数据, 进一步提高了预测模型的性能[6] ; 而秦博文针对预测模型中的噪声干扰问题, 采用小波变换对数据进行降噪处理, 并引入了改进的WLSTM (波小波长短期记忆) 网络,该网络通过使用小波函数作为非线性激活函数, 增强了模型对金价数据的拟合能力[1] ; 伍文娟的研究通过比较不同模型的表现, 发现单因素LSTM 神经网络在预测金价方面优于传统的ARIMA 模型, 并通过结合多项经济指标的多因素LSTM 模型来解决预测结果的滞后性问题, 提升了预测准确性[7] 。这些研究展示了机器学习在金价预测中的广泛应用及其显著优势。
尽管单一模型的性能已经得到了广泛的研究和评估, 但模型间的比较研究却相对较少, 这对于理解不同模型如何处理特定数据类型以及评估它们在特定市场环境中的相对优势和劣势至关重要。此外, 大多数研究倾向于在特定的数据集上评估模型性能, 而忽视了跨模型比较的重要性, 这种比较在评估模型在类似条件下的相对效力方面具有重要价值。金融市场是动态变化的, 不同市场条件可能影响预测模型的性能, 但研究在不同市场波动、经济周期及极端市场条件下各种预测方法的表现的比较研究是有限的。因此, 未来的研究应当致力于填补这些空白, 特别是在不同市场环境下对比多种预测方法的性能, 以及探索统计与机器学习方法融合后的预测能力。文章通过全面比较和综合评价, 为机器学习在黄金价格预测中的应用提供了新的视角和实证证据。
二、理论模型介绍
总体而言, 目前对金价的预测主要分为两类:一是传统模型, 二是机器学习。通过对国内外相关研究的大量研究, 并考虑到数据的特性, 文章选取了传统模型中的ARIMA 模型和机器学习方法中的LSTM 模型、随机森林模型、BP 神经网络、小波神经网络来对金价进行分析预测。
(一) ARIMA 模型
ARIMA 模型(自回归移动平均模型) 是针对非平稳时间序列进行预测的一种统计方法, 该模型结合了自回归(AR)、差分整合(l) 和移动平均(MA) 三种成分。其中AR 部分反映了时间序列中当前值与其过去值之间的线性关系; 差分是将序列中的每个值减去其前一个值(一阶差分), 这一步骤可以消除趋势, 使序列变得平稳。如果序列需要经过d 次差分才能达到平稳, 模型中就包含d 阶差分; 而MA 部分涉及到误差项的过去值, 表示当前的误差项与过去的误差项有关。一个MA (q) 模型表示当前的误差项是过去q 个误差项的加权平均加上一个新的独立误差项。综合起来, 一个ARIMA(p, d, q) 模型可以表述为:
yt = c + φ1yt -1 + … + φμ yt -p + θ1εt -1 + … +θq εt -q + εt (1)
其中, d 表示差分的阶数, p 和q 分别是自回归和移动平均的阶数。通常使用极大似然估计法来确定模型中的参数, 经常通过使用自相关图、偏自相关图、AIC 最小化准则等来判断是否是ARIMA 模型。ARIMA 模型广泛应用于经济、金融、气象等多个领域的数据分析和预测中。
(二) LSTM 模型
长短期记忆网络模型(LSTM) 是一种特殊的循环神经网络, 它是针对传统神经网络在处理长期相关性问题中存在的梯度消失、梯度膨胀等问题,提出的一种新的神经网络模型。LSTM 的核心是其特有的内存单位结构, 可以有效地对数据进行存储与遗忘, 以更好地捕获时序数据中的长时相依关系。LSTM 单元包括四个组成部分: 一是遗忘门,利用sigmoid 函数求取0 至1 的向量, 并将其与上一步单元的状态相乘, 从而实现了对旧信息的选择性遗忘; 二是输入门, 一方面通过sigmoid 函数决定哪些新信息应该被更新, 同时通过tanh 函数生成一个候选向量, 表示可能添加到细胞状态的新信息;三是输出门, 它决定哪些信息应该被输出到网络的下一个状态; 四是记忆单元, 用于存储长期依赖信息。它的建模步骤如下: 第一步, 构建LSTM 模型,选取合适的损失函数; 第二步, 确定初始化参数,求解数据的估计值并计算估计值与真实值之间误差; 第三步, 运用误差函数对参数求导, 计算参数的梯度并更新模型参数, 进而构建新的LSTM 模型,将数据带入重新反复迭代计算; 第四步, 循环第二步、第三步, 直至确立最优的模型参数并带入数据进行预测分析[7] 。
(三) BP 神经网络模型
BP 神经网络是一种广泛应用的神经网络, 它按照误差逆向传播算法进行训练[1] 。BP 神经网络的主要思想是利用信号前向传递, 而误差反向传递, 从而实现对模型各参数的训练[1] 。BP 神经网络通常包含输入层、一个或多个隐藏层和输出层。每一层都由若干个神经元组成, 神经元之间通过加权连接形成网络。输入层负责接收外部输入信息,输出层负责给出网络的最终输出, 而隐藏层则位于输入层和输出层之间, 负责复杂特征的提取和转换。BP 神经网络能够处理非线性问题, 适合复杂的模式识别和分类, 同时隐藏层可以自动提取输入数据的有用特征, 无需手动选择或构建特征。然而它也存在一些局限性, 比如训练过程可能较慢, 容易陷入局部最优解, 且对于大规模数据集和深层结构的训练需要更高效的算法和计算资源。
(四) 随机森林模型
随机森林模型是一种集成学习方法, 要用于分类、回归以及其他机器学习任务。随机森林通过自助采样、构建决策树、集成预测几个关键步骤构建而成, 即对原始数据集进行有放回的抽样, 生成多个子数据集, 对每个子数据集, 分别构建一棵决策树, 在树的每个节点上寻找最佳分割点, 再划分数据, 重复此过程直到满足停止条件。对于新的输入样本, 让森林中的每棵树都进行一次预测, 然后根据多数投票(分类任务) 或平均值(回归任务) 来决定最终的输出结果。它具有随机性、并行性的特点。
( 五) 小波神经网络模型
为应对BP 神经网络中存在的收敛速度慢和样本依赖严重的问题, Tsung -Jung Hsieh 等学者在2011 年提出了小波神经网络模型, 该模型结合了小波变换的强大时频局部化分析能力和神经网络的自学习、自适应特性。它通过使用小波函数作为激活函数, 替代了传统神经网络中常用的sigmoid 或其他非线性函数。小波基函数具有良好的时频局部化特性, 这意味着它们能够在时间和频率域上同时聚焦于信号的特定部分。通过选择合适的小波基, 网络能够有效地提取输入数据的局部特征和细节。小波基函数的平移和尺度参数可以调整, 以适应不同尺度和位置的信号特征。
三、黄金价格预测分析
(一) 数据来源
文章所使用的数据集包含从2016 年1 月4 日至2024 年4 月18 日的COMEX 黄金期货每日收盘价,共计2019 个数据点。此数据集由指标代码1330021181 所标识, 并且是从聚源数据平台获取的(聚源数据是知名的金融信息服务提供商, 为金融市场分析和研究提供了高质量的数据)。此数据的收集和整理为我们运用机器学习方法对黄金价格进行时间序列预测提供了坚实的基础, 数据的处理及预测过程在Matlab 编程语言中完成。
(二) 数据预处理
1. 样本划分
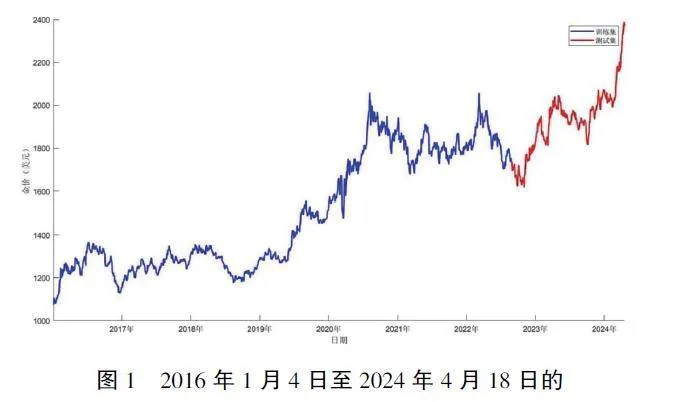
为了确保我们的机器学习模型能够有效地学习并准确预测黄金价格的未来走势, 我们将COMEX黄金期货每日收盘价数据集进行划分, 采用常见的数据集分割比例。具体而言, 我们将数据集的80%作为训练集, 即大约1615 个数据点, 用于模型的训练和参数调优。剩余的20%将被用作测试集, 约404 个数据点, 用于评估模型在未见过的数据上的表现, 从而检验模型的泛化能力。数据集的分割是在保证时间序列连续性的前提下进行的, 确保训练集和测试集在时间上的连续性不被打断。这种划分方法能够更好地模拟实际操作中对未来价格走势的预测情境, 并保证测试集能够提供公正的模型性能评估。黄金价格数据划分如图1 所示。
由图1 可知, 2016 年至2024 年的COMEX 黄金价格呈上升趋势, 文章将2022 年上半年及以前数据作为训练集, 将剩余数据作为测试集, 利用训练集来训练模型, 而测试集则用于检验模型的优劣性。将预测数据与真实数据进行对比来观察模型预测的准确性。
2. 数据标准化
在进行金价预测的统计建模和机器学习分析中, 数据预处理是一个关键步骤, 对于金价预测模型来说, 考虑到原始数据涉及到不同的数值范围,我们采用了最小-最大标准化方法对金价数据进行预处理。这种方法将所有数据点缩放到0 和1 之间的范围, 公式如(2):
Xnorm =X - Xmin/Xmax - Xmin (2)
这里, Xnorm 代表标准化后的数据, Xmax 和Xmin 分别代表数据集中的最大值和最小值。通过这种转换, 模型的输入特征处于同一尺度上, 避免了因尺度不同而导致的偏差。此外, 标准化还有助于加速梯度下降算法的收敛速度, 因为它使得损失函数的等高线更加接近于圆形, 减少了算法在搜索最优解时的震荡。
然而, 在预测阶段之后, 为了解释模型的输出并将其转换回原始的金价尺度, 需要进行反归一化处理。这可以通过最小-最大标准化的逆运算来实现, 公式如(3):
X = Xnorm(Xmax - Xmin ) + Xmin (3)
其中, Xnorm 表示归一化后的数据点, Xmax 和Xmin分别表示原始数据集中的最小值和最大值, X 表示反归一化后的原始数据点。通过这个公式, 我们可以将数据从[0, 1] 的范围恢复到其原始的范围。实施该转换后, 模型输出的标准化预测值将被转换回原始数据的实际金价范围。这允许我们直观地解释预测结果, 并在实际应用中使用。
3. 指标评价
在构建黄金价格预测模型时, 评估模型性能和选择最优参数通常涉及以下几个关键参数或指标:
(1) 平均绝对百分比误差
平均绝对百分比误差(MAPE) 是一种度量模型预测准确性的指标, 常用于评估时间序列预测模型的性能。它反映了预测值与真实值之间的差异,以百分比的形式表示。其计算公式为:
MAPE 的取值范围为 [0, + ¥] , MAPE 值越小, 说明模型预测精度越高。当MAPE 为0%时表示完美模型, MAPE 大于100% 则表示劣质模型。MAPE 在金融领域常用于评估投资组合风险模型的表现。然而缺点在于, 当真实值接近0 时, 计算可能会出现分母为0 的情况, 导致评价结果不可用。
( 2) 均方根误差
均方根误差(RMSE) 是评估预测模型精度的常用指标之一。衡量预测值与真实值之间的偏差程度。它的计算公式为:
其中, n 为样本个数, yi 为真实值,y ︿i 为预测值。取值范围为 [0, + ¥] , 数值越小表示模型的预测误差越小, 模型的预测能力越强。当预测值与真实值完全吻合时等于0, 即完美模型。RMSE 易于理解, 计算方便, 对异常值较为敏感。然而RMSE 的缺点在于对目标变量本身的变异性缺乏考虑。
(3) 决定系数
决定系数(R2) 反映因变量的全部变异能通过回归关系被自变量解释的比例。其计算公式为:
我们以数据集的均值作为误差的基线, 然后衡量预测误差是大于还是小于这个基线。若R2 = 1,它表示模型中自变量能完全解释因变量的变动; 若R2 = 0, 那意味着模型的预测结果与简单的平均值预测差距不大, 即模型对于因变量的解释力度相当低。
在文章中为从多种角度比较黄金价格预测模型的优劣, 我们将选取上述三种指标来进行模型的评估。
( 三) 黄金价格预测
1. 传统统计模型
ARIMA 模型是时间序列预测中广泛使用的一种方法, 它结合了自回归(AR)、差分(I) 和移动平均(MA) 三种技术。自回归部分捕捉时间序列中的趋势动态, 差分部分处理非平稳性, 而移动平均部分则用于消除噪声影响。模型的核心在于通过调整参数p (自回归项数)、d (差分次数) 和q(移动平均项数), 来捕捉时间序列数据中的特定模式。
在本研究的模型选择过程中, 我们采用Akaike信息准则(AIC) 作为评估标准, 以寻找最适合我们数据的模型配置。AIC 是衡量统计模型拟合好坏的一种标准, 它旨在解决模型复杂性和拟合优度之间的平衡。较低的AIC 值通常表示模型具有较好的预测性能, 并且在复杂性与拟合度之间保持了较好的平衡。
通过系统性地评估和比较不同的ARIMA 模型配置, 我们确定了具有最低赤池信息准则(AIC)值的最佳金价预测模型。结果如下:
通过对不同的ARIMA 模型配置进行比较和分析, 我们发现ARIMA (3, 1, 3) 模型在我们的数据集上表现最佳, 其AIC 值为13313. 4715。这意味着模型在一次差分后, 通过三个自回归项和三个移动平均项最有效地捕捉了时间序列的特性。自回归项反映了金价在前三期的影响, 而移动平均项则平滑了随机波动的影响。
下表展示了ARIMA (3, 1, 3) 模型参数的估计结果及其统计显著性:
从表2 可以看出, 模型中所有参数的P 值均显著小于0. 05, 表明这些参数在统计上是显著的, 意味着它们对金价的预测具有实质性影响。自回归项(AR {1}、AR {2}、AR {3} ) 和移动平均项(MA {1}、MA {2}、MA {3} ) 在统计上均表现出显著性, 这表明它们对金价的预测具有一定的影响力。此外, 模型的常数项尽管不是统计上显著的(P 值=0. 2742), 但仍为模型提供了一个基准价值。
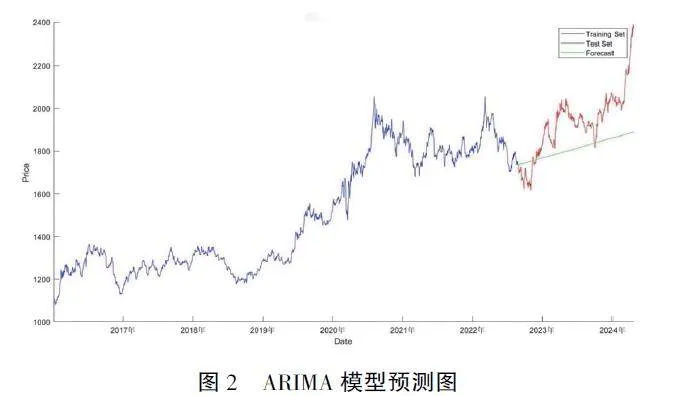
由图2 可知, 通过初步观测, 我们可以得到一个初步的结论: 在将2016—2024 年黄金价格按8: 2的比例划分成一个训练集合和一个测试集合,ARIMA 模型预测图整体上呈上升趋势, 而从黄金价格的初始数据曲线可以看出, 黄金价格自2016 年以来也呈现出整体上涨的态势。在此基础上,ARIMA 模型在训练集上的拟合结果似乎与金价整体的上升趋势相吻合, 这表明模型在一定程度上能够捕捉到时间序列的长期趋势。但是, 大多数的测试集都在预测值之上, 只有小部分的数据在预测值以下, 而且, 不管训练集是在预测值之上, 还是在下面, 两者之间的差异都很大, 因此, ARIMA 模型的拟合效果并不理想。这两种观点看似相互矛盾, 但因为两者都是描述性的统计结果, 所以要想进一步判断ARIMA 模型的拟合效果, 还需要更加严格的统计学方法, 最简便的一种方式是通过对模型的统计指标进行计算, 其结果如表3 所示。
由表3 可知, ARIMA (3, 1, 3) 模型的平均绝对百分比误差(MAPE) 为6. 712%, 表明模型预测值与实际值之间的平均偏差较小, 证明了模型的准确性。均方根误差(RMSE) 为162. 025, 该指标反映了预测值偏离真实数据点的平均程度。然而,决定系数(R2) 值为-0. 201, 这通常表明模型未能在统计上捕捉到数据的变异性, 或者模型可能并不比简单的均值预测更优。综合考虑ARIMA (3, 1, 3)模型的性能指标, 我们可以得出结论: 尽管模型的平均绝对百分比误差(MAPE) 相对较低, 显示了一定的预测准确性, 但均方根误差(RMSE) 的高值和决定系数(R2) 的负值共同揭示了模型在捕捉金价变异性和提供精确预测方面的局限性。因此,从预测评价指标来看, 传统ARIMA 模型在金价预测上的整体评价效果并不理想, 需要进一步探索更为有效的预测方法, 如引入机器学习模型, 以提高预测的准确性和可靠性。
2. 机器学习模型
(1) 长短期记忆网络(LSTM 模型)
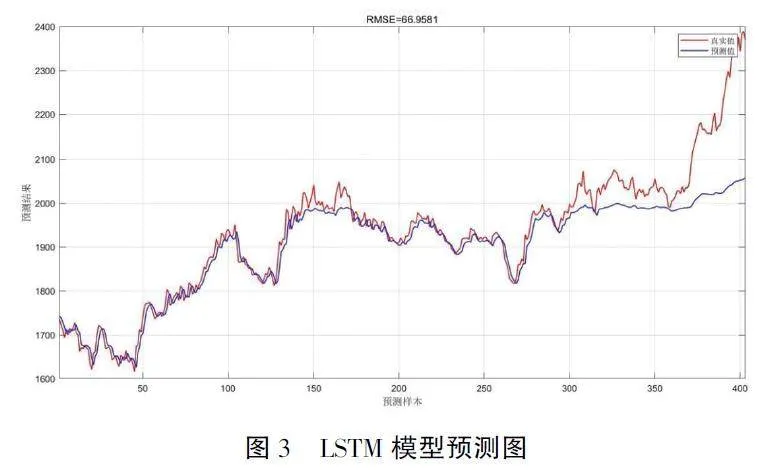
我们采用了滑动窗口的方法, 选取连续六天的金价数据作为模型的输入特征, 以此来预测未来第七天的金价走势。这种策略使得模型能够对未包含在训练集中的未来数据进行预测, 从而验证了模型在样本外数据上的泛化能力。模型的架构包括一个序列输入层、一个具有10 个单元的LSTM 层、一个ReLU 激活层和一个全连接层, 输出预测的金价。我们使用的激活函数是ReLU, 因为它可以加快模型在训练过程中的收敛速度, 并减少梯度消失的问题。该模型通过Adam 优化器进行训练, 训练周期设置为500 次。训练完成后, 我们得到的预测结果如图3 和表4 所示。
上图显示了训练集的预测结果, 其中均方根误差(RMSE) 为15. 9905, 这表明模型在训练集上的预测与实际金价之间的差异较小。此外, 训练集的R2 值为0. 9964, 这表明模型能够解释训练数据中几乎所有的方差。训练集的平均绝对百分比误差(MAPE) 为0. 0073, 这表示预测值与实际值在百分比上平均误差非常小, 说明模型在训练集上具有很高的精度。
同时也显示了测试集的预测结果, 其中均方根误差(RMSE) 为66. 9581, 相比于训练集, 这显示出在测试集上模型的预测精度下降。测试集的R2 值为0. 7906, 意味着模型能够在一定程度上解释测试数据集中的方差, 但是相比于训练集的R2 值, 它的解释能力有所下降。测试集的MAPE 值为0. 0171,这意味着模型在测试集上的平均百分比误差较训练集有所增加, 但总体上仍然在可接受范围内。
这些结果表明, 虽然我们的模型在训练集上表现出色, 但在测试集上存在一定程度的过拟合。过拟合发生在模型在训练数据上学到了许多特殊的、噪声的模式, 而这些模式并不适用于未见过的数据。尽管如此, 模型的整体预测性能仍然证明了LSTM 在金价时间序列预测方面的潜力。
(2) BP 神经网络模型
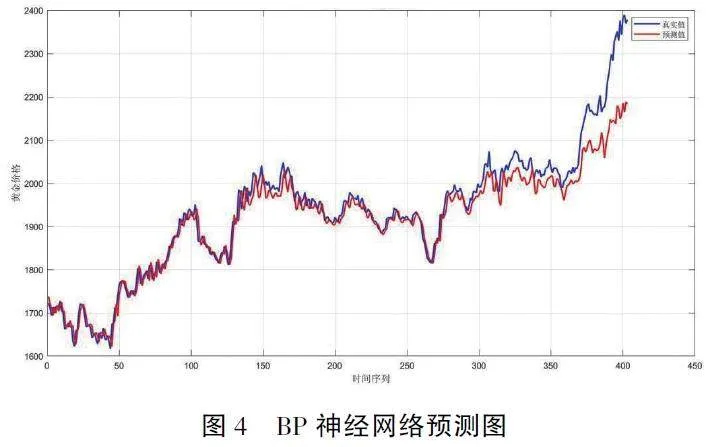
我们采用了前五天的黄金价格作为输入(X),而第六天的价格作为输出(Y), 通过这种方式创建了滑动窗口数据。接下来构建了一个包含两个隐藏层, 每层20 个神经元的前馈神经网络。模型的训练过程中, 我们设置了100 次的迭代次数和0. 01 的学习率, 以优化模型的性能。为了提高模型的泛化能力, 我们对训练数据进行了归一化处理。在模型训练完成后, 我们对测试集进行了预测, 并将预测结果与实际黄金价格进行了对比。结果如图4 所示。通过这种方式, 我们能够直观地评估模型的预测能力。
为了更精确地量化模型的性能, 我们计算了三个关键指标: 平均绝对百分比误差(MAPE)、均方根误差(RMSE)、以及决定系数(R2 )。其结果如表5 所示。测试集的MAPE 值为1. 314%, 表明模型的预测结果与实际值之间的平均绝对百分比误差较低, 说明模型具有较高的准确度。RMSE 值为44. 689, 提供了预测误差的量化指标。最后, R2 值为0. 908, 表明模型能够很好地拟合数据, 几乎可以解释数据变化的90. 8%。
综上所述, 我们的研究表明, BP 神经网络模型能够有效地应用于黄金价格的时间序列预测中。这一结果不仅证实了深度学习在金融时间序列分析领域的有效性, 也为未来在类似问题上的研究提供了重要的参考和启示。
(3) 随机森林模型
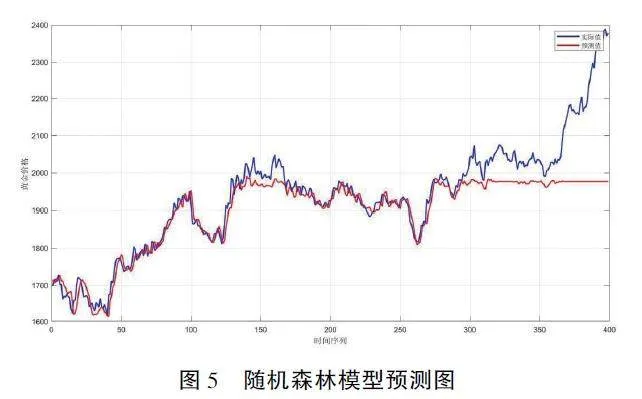
我们探讨了使用随机森林模型对黄金价格时间序列数据的预测能力, 在模型建立过程中, 我们采用了滑动窗口的方法来提取特征, 其中每个窗口包含连续五天的价格作为特征, 窗口的第六天价格作为标签。随后, 我们利用这些特征训练了一个包含100 棵决策树的随机森林回归模型。其结果如图5和表6 所示。
结果显示, 模型的MAPE 为2. 1656%, 表明模型预测的平均误差约为实际黄金价格的2. 17%。RMSE 为86. 2600 美元, 反映了预测值与实际值整体上的偏差大小。最后, R2 值为0. 6546, 表示模型解释了65. 4620%的方差, 暗示了模型具有一定的有效性, 但仍有改进的空间。上述结果通过图形的形式得到了直观展示, 其中实际价格和预测价格分别以蓝色和红色线条表示, 以便于比较和分析。图表显示了模型在捕捉数据整体趋势方面的能力,尽管也存在一些预测误差。
(4) 小波神经网络
我们使用窗口大小为5 的滑动窗口来构建训练和测试特征集, 为了提取更具代表性的特征, 我们对每个窗口内的数据进行了一级小波变换, 选取了“Daubechies” (db1) 作为母小波函数。小波变换的结果是, 每个窗口的数据被转换为一组近似系数,其数量大约是窗口大小的一半。
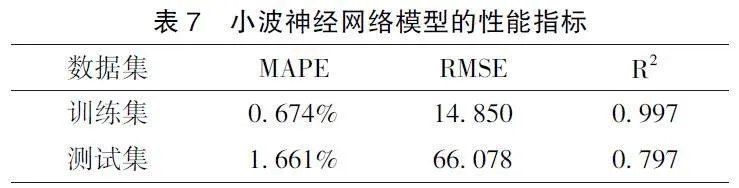
利用近似系数作为特征, 我们训练了一个具有10 个隐藏神经元的前馈神经网络。网络训练完成后, 我们将训练过程中的数据处理步骤应用于测试集。神经网络在测试集上的预测结果与实际金价进行了对比, 以评估模型性能。模型表现通过以下三个关键指标进行评估: 平均绝对百分比误差(MAPE)、均方根误差( RMSE) 以及决定系数(R2)。其结果如图6 和表7 所示。
根据图6 和表7 可知, 小波神经网络模型的性能指标这些指标表明, 所开发的前馈神经网络模型在训练阶段呈现出了卓越的性能。具体来说, 训练集上的平均绝对百分比误差( MAPE) 仅为0. 674%, 说明模型在训练数据上的预测与真实值之间的平均偏差很小。同时, 训练集的均方根误差(RMSE) 为14. 850, 这个值表明模型在训练过程中学习得相当好, 预测值的波动与实际金价非常接近。此外, 一个接近完美的训练集决定系数(R2 )值0. 997, 进一步证实了模型拟合训练数据的能力极强, 几乎可以解释所有的方差。
然而, 当模型应用于未见过的测试数据时, 其表现略有下降, 但仍然表现良好。测试集的MAPE为1. 661%, 虽然高于训练集, 但仍然指示出模型具有良好的预测准确性。测试集的RMSE 值增加到66. 078, 这表明预测值与实际金价之间的差距在测试集上有所增加, 但差异仍在可接受的范围内。测试集的R2 值为0. 797, 这说明了模型在测试集上的预测能力较好, 尽管没有训练集高, 但是仍然能够解释了大部分的方差。
这种训练集与测试集上的表现差异通常是由于模型在训练时过度拟合到训练数据所致, 这可能导致模型在处理未知数据时表现出的泛化能力不足。尽管存在过拟合的迹象, 但本研究开发的模型整体上对金价具有较强的预测能力, 对未来的金价变动给出了相对准确的预测。这些发现在论文中将以详细的数据分析、图表展示以及深入的讨论形式呈现, 以便为读者提供全面的理解和判断模型有效性的依据。
四、结论与建议
(一) 研究结论
根据ARIMA 模型、LSTM 模型、BP 神经网络、随机森林模型、小波神经网络模型对黄金价格数据的应用研究结果, 文章梳理了模型预测的性能指标汇总图。
经验证, 传统的ARIMA (3, 1, 3) 模型在样本测试中表现较差, 具体表现为MAPE 为6. 712%,RMSE 为162. 025, 且R2 为-0. 201, 这表明模型无法很好地捕捉数据的变动趋势。相比之下, 机器学习模型, 尤其是BP 神经网络, 在黄金价格预测上展现出了卓越的性能, 得到了MAPE 为1. 314%,RMSE 为44. 689 以及R2 为0. 908 的优异结果, 表明了其在黄金价格时间序列预测上的高度适用性和准确度。此外, 小波神经网络在测试集上的MAPE为1. 661%, RMSE 为66. 078, R2 为0. 797, 也展示了较好的预测效果; 而长短期记忆网络(LSTM)和随机森林模型的表现虽好于ARIMA 模型, 却略逊于BP 神经网络和小波神经网络。
与现有研究相比, 本研究的结果与近期文献中关于机器学习在金融市场预测中的应用趋势相一致。例如, Nazish Ashfaq, Zubair Nawaz, 和M. Ilyas(2021) 的研究对纳斯达克股票市场进行了深入分析, 他们选取了十个不同行业的公司作为投资组合, 并应用了九种不同的机器学习回归模型来预测第二天的股票开盘价。他们的研究结果证明了机器学习模型在股市预测中的有效性, 尤其是在处理复杂和动态的股票市场数据时[12] 。同样, 张延利(2013) 在其研究中也使用了BP 神经网络来预测黄金价格, 并发现该模型因其对非线性模式的高度敏感而显示出良好的预测能力[11] 。张坤等人的研究提出了一种基于小波神经网络的黄金价格预测模型,并通过对比测试验证了该模型相比于BP 神经网络模型具有更快的收敛速度和更高的预测精度[10] 。此外, 本研究的结果与A Adebiyi, A. Adewumi,C. Ayo在2014 年发表在《Journal of Applied Mathe⁃matics》上的研究相呼应。他们利用纽约证券交易所公布的股票数据, 检验了ARIMA 和人工神经网络模型的预测性能, 并发现神经网络模型优于ARIMA 模型[13] 。近期秦博文[1] 和伍文娟[7] 对金价预测的研究也有类似结果, 都是机器学习方法优于传统时间序列模型, 不同之处在于最优的机器学习方法不同, 大致原因是各机器学习模型参数选取不同。本研究的BP 神经网络和小波神经网络的优异表现进一步证实了这些发现, 并扩展了它们在黄金市场预测中的应用。
综上所述, 本研究验证了机器学习模型在黄金价格时间序列预测中的有效性, 而且通过与现有研究的横向对比, 共同支持了使用小波神经网络和BP 神经网络在金融市场, 尤其是在黄金价格预测中的应用, 进一步证明了这些模型在金融市场预测领域的先进性和实用性。这些发现为市场分析师和决策者提供了一种强大的工具, 以更准确地预测市场动态并制定相应的策略。未来的研究可以探索更多先进的机器学习算法, 并考虑市场中的其他影响因素, 以进一步提高预测模型的准确性和可靠性。
(二) 对策与建议
鉴于小波神经网络和BP 神经网络在实验中的出色表现, 推荐金融分析师和投资者在黄金价格预测中优先考虑这两种模型。为进一步提高模型预测能力, 建议在未来的研究中考虑集成学习方法, 通过结合多个模型的预测结果来减少预测的不确定性, 进而可能得到更稳健的预测表现。此外, 可以考虑引入更多的外部变量, 如宏观经济指标、市场情绪指数等, 这些可能会对黄金价格产生影响的因素, 以增强模型的预测能力。
(三) 未来展望
未来研究可以探索将深度学习技术与传统时间序列预测方法相结合的可能性, 例如融合LSTM 与ARIMA 模型, 从而充分利用两者的优势。同时, 随着金融市场数据量的不断增长, 模型将需要适应更复杂多变的数据特征, 因此模型的可扩展性和实时更新将成为研究的重点。此外, 跨市场分析也可能为黄金价格预测提供新的洞见, 比如将黄金市场与其他贵金属市场或货币市场的动态相关联。最终目标是开发出能够适应市场变化并提供实时预测的智能系统, 为投资决策提供更高效、更精确的支持。
参考文献:
[1]秦博文. 基于小波理论与机器学习的金价预测[D]. 济南:山东大学,2022.
[2]薛吟凇. 中美黄金期货与期权信息对上海黄金期货波动率的预测能力研究[D]. 杭州:浙江大学,2023.
[3]吴虹晓. 中国黄金期货和现货价格关系的实证研究[J]. 中国货币市场,2024(2):71-75.
[4]徐静怡,孔梦奇. 基于ARIMA 模型对纽约COMEX 黄金期货价格的研究[J]. 中国商论,2022(18):123-125.
[5]梁龙跃,黄盈. 黄金期货价格短期预测方法研究:基于CEEMDAN 与LSTM 模型的COMEX 黄金期货价格数据分析[ J]. 价格理论与实践,2023(09):164-168.
[6]张均东,刘澄,孙彬. 基于人工神经网络算法的黄金价格预测问题研究[J]. 经济问题,2010(1):110-114.
[7]伍文娟. 国际黄金价格预测方法及应用研究[D]. 重庆:重庆大学,2021.
[8]王菲. 国际黄金价格影响因素及预测研究[D]. 北京:北方工业大学,2020.
[9]闫海啸. 黄金价格影响因素实证分析及建议[D]. 上海:上海财经大学,2022.
[10]张坤,郁湧,李彤. 小波神经网络在黄金价格预测中的应用[J]. 计算机工程与应用,2010,46(27):224-226.
[11]张延利. 基于BP 神经网络的黄金价格非线性预测[J]. 黄金,2013,34(07): 8-10.
[12]Ashfaq N, Nawaz Z, Ilyas M. A comparative study of different machine learning regressors for stock market prediction[ J] . arxiv preprint arxiv:2104. 07469, 2021.
[13]Adebiyi A A, Adewumi A O, Ayo C K. Comparison of ARIMA and Artificial Neural Networks Models for Stock Price Prediction[J]. Journal of Ap⁃plied Mathematics, 2014:614342, 1-7.
