煤矿工业数据AI 模型自动推理技术
2024-10-31张智星付翔张小强李浩杰秦一凡刘萌孙岩贾一帆杨宇琪


摘要:煤矿生产过程的智能化主要依托于人工智能(AI)技术分析煤矿工业数据,但单一应用场景AI 模型无法适用于煤矿复杂的应用场景,且仅使用分布式计算来处理AI 模型输入特征值会导致模型应用效率降低。针对上述问题,提出了一种煤矿工业数据AI 模型自动推理技术。该技术架构包括数据层、计算驱动层和模型推理层:数据层采集各类监测数据并统一存储,为计算驱动层提供原始数据;计算驱动层将数据层采集的海量原始数据转换成煤矿应用场景AI 模型输入特征值,通过煤矿应用场景AI 模型输入特征值双计算引擎自动切换机制,根据数据量自动合理地选择使用基于Spark 的分布式计算方式或基于Python 的单机计算方式,解决了海量数据计算速度慢、数据应用延迟大的问题;模型推理层将特征值输入应用场景AI 模型进行推理,引入煤矿应用场景AI 模型多触发方式协同推理机制,通过定时触发、人为交互触发、信号反馈触发3 种触发方式,解决了在煤矿复杂的应用条件下单一应用场景AI 模型利用效果差的问题。测试和应用结果表明,该技术可实现多应用场景AI 模型输入特征值的快速计算,以及不同应用场景AI 模型的快速、自动、协同推理。
关键词:煤矿人工智能;煤矿工业数据;AI 模型推理;海量数据计算;AI 模型应用
中图分类号:TD67 文献标志码:A
0 引言
智能煤矿产生的海量工业数据蕴藏着宝贵的信息和潜在的价值。利用人工智能(ArtificialIntelligence,AI)技术分析煤矿工业数据,可帮助发现隐藏在数据背后的规律和趋势,预测设备故障和异常情况,优化生产过程和资源配置,从而提高生产效率和安全性,实现对煤矿生产过程的智能监测、优化和控制[1-3]。
许多学者利用AI 技术对矿井下复杂场景进行建模,并通过井下实时数据进行模型推理[4]。文献[5-7]通过挖掘分析采煤工作面液压支架的压力数据与行程动作数据对中部支架进行推理,得到支架的操作策略参数与操作建议。文献[8]通过分析液压数据,对井下液压系统进行分析建模,从而动态调整液压供应实现稳压供液。文献[9]根据支架跟机推进数据进行分析建模,最终实现支架动作智能决策。文献[10]通过计算巷道当量距离, 基于改进DK(Dijkstra-Kruskal)算法建模,得出逃生路径规划结果。文献[11]利用前期积累的煤层地质模型数据和采煤机历史截割数据, 基于长短期记忆(Long-Short Term Memory,LSTM)神经网络对煤层厚度分布进行预测。文献[12]以采煤机截割过程中的状态参数为输入信号,采用BP 神经网络实时调整采煤机工作参数来实现自适应调速。文献[13]利用煤岩图像数据,基于生成式对抗网络构建模型,实现了煤岩识别。上述研究利用AI 技术实现了煤矿工业数据的初步挖掘和煤矿单一应用场景的AI 建模。然而鉴于煤矿生产系统的复杂性(多场景、多融合和多数据特性),单一应用场景AI 模型无法适用于煤矿复杂的应用场景。另外,在煤矿工业数据挖掘过程中,由于智能煤矿数据具有实时性强和数据体量大的特征,许多学者利用分布式计算处理海量数据。文献[14-17]构建了基于大数据计算技术的计算平台,通过对煤矿生产子系统产生的工控数据的计算分析,基本实现了设备工况数据采集、故障预判、设备全生命周期管理。文献[18]为满足海量大数据的可靠存储,设计了面向大数据分析、专为大规模集群应用的分布式文件系统Clover。文献[19]利用Spark 并行计算框架接收大量的煤矿实时数据,对井下环境数据进行并行计算。文献[20]利用SparkStreaming 的流处理技术,减少计算开销,使预测模型更新周期达到秒级。然而在多应用场景AI 模型应用过程中,仅使用分布式计算来处理AI 模型输入特征值会降低小批量特征值的计算速度,导致部分需要小批量特征值的AI 模型应用效率降低。
针对多应用场景AI 模型协同运行机制和数据计算方式,本文提出了一种煤矿工业数据AI 模型自动推理技术。基于双计算引擎自动切换机制实现多应用场景AI 模型输入特征值的快速计算,通过多触发方式协同推理机制实现多应用场景AI 模型的快速、自动、协同推理。
1 技术架构
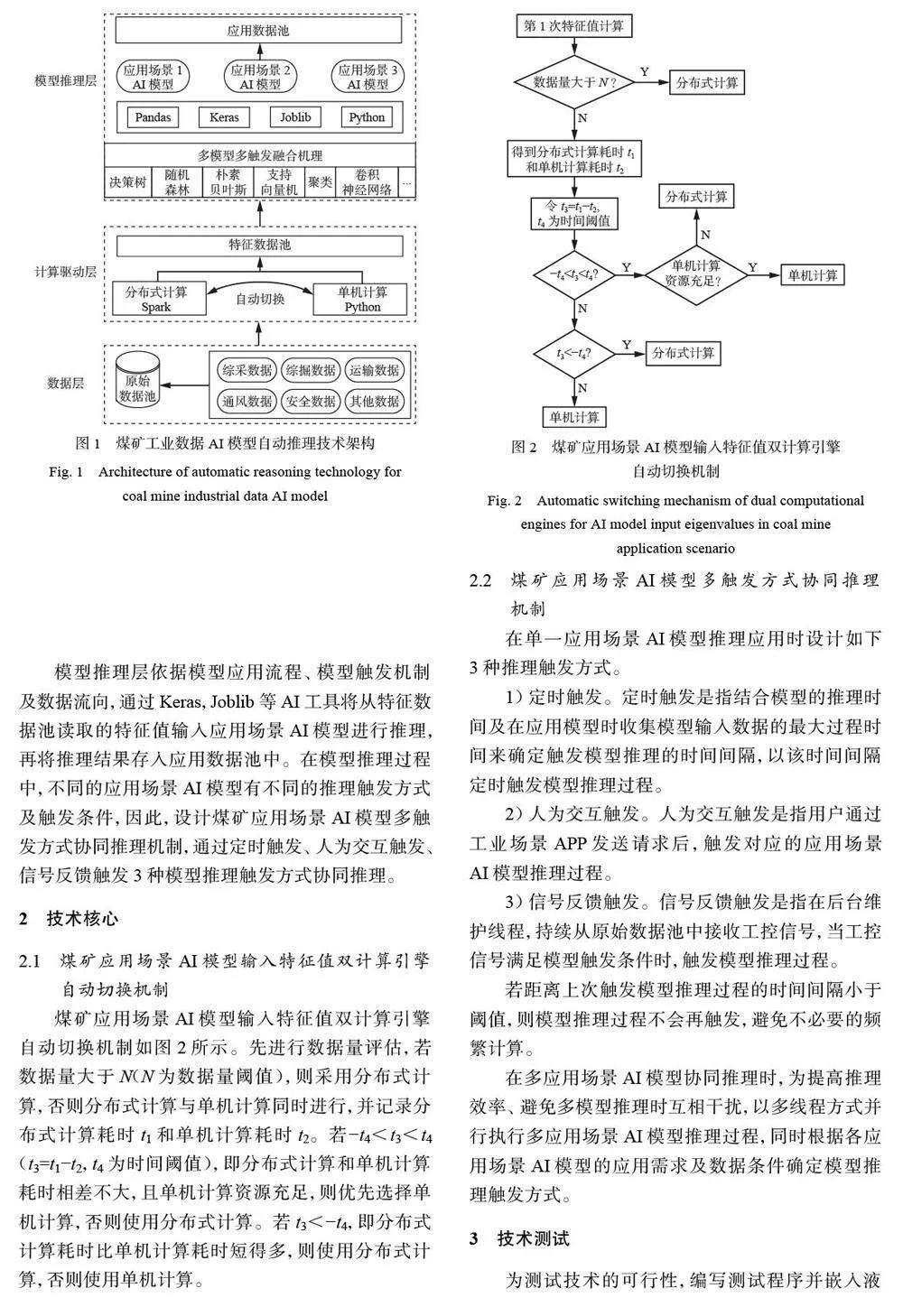
煤矿工业数据AI 模型自动推理技术架构包括数据层、计算驱动层和模型推理层,如图1 所示。
数据层通过RS485/TCP 等通信协议将井下各类机械(采煤机、液压支架、刮板输送机、泵站等)传感器产生的各类监测数据传输至OPC 网关[21],统一存储至原始数据池中,为计算驱动层提供原始数据。
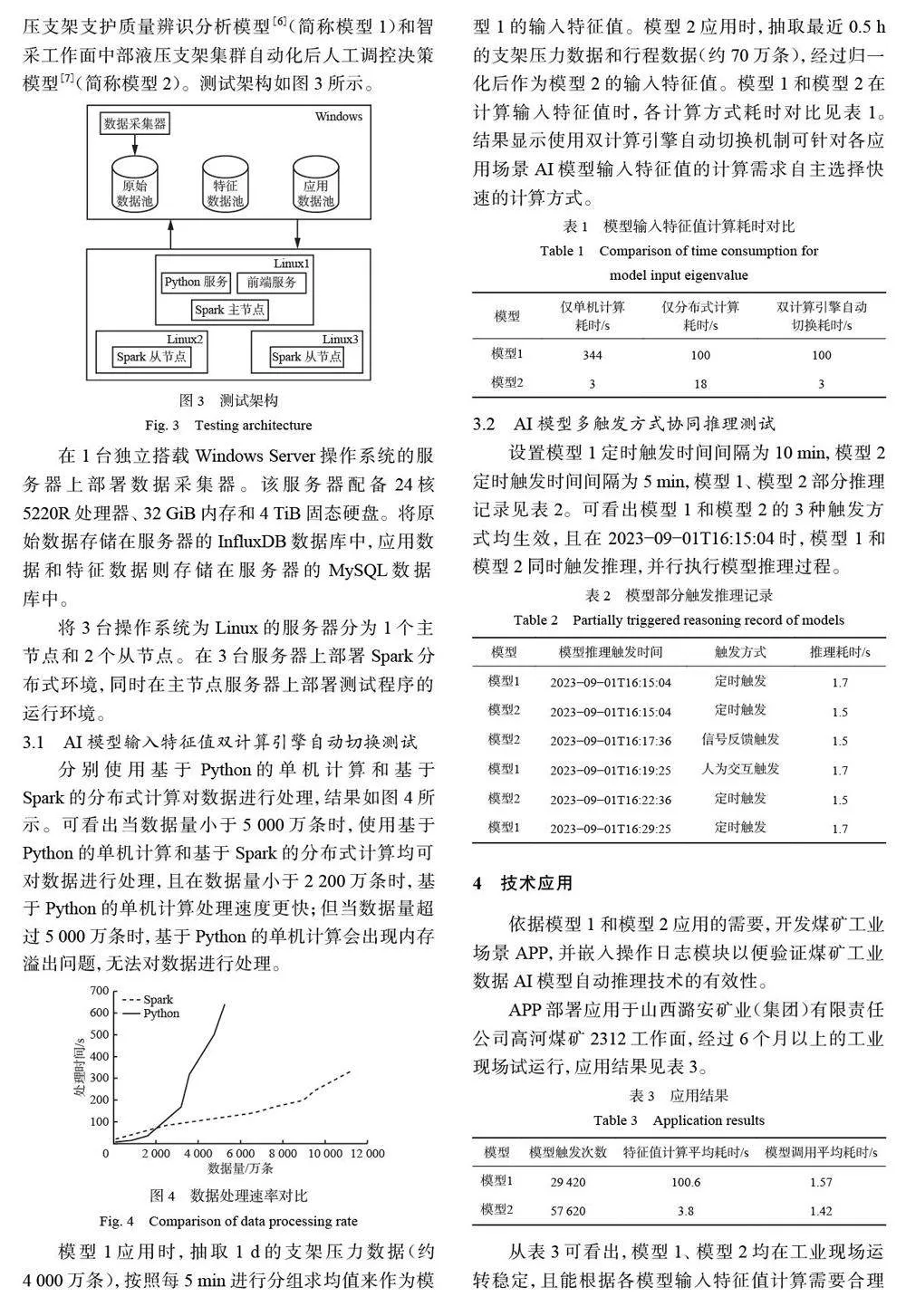
计算驱动层对数据层采集的海量原始数据进行处理,转换成煤矿应用场景AI 模型输入特征值。煤矿不同应用场景AI 模型需要不同的特征值,计算时数据类型多样,数据量大小不一,数据计算流程与方法不尽相同,计算驱动层需要协调多组特征值计算(如算力分配、串行并行) ,因此设计煤矿应用场景AI 模型输入特征值双计算引擎自动切换机制,根据数据处理时延和数据量自动选择基于Spark 的分布式计算或基于Python 的单机计算方式。将计算得到的特征值分库分表存入特征数据池中,为模型推理层提供特征值。