借助XEduHub,让学生的AI模型作品“流通”起来
2024-10-12谢作如邱奕盛
摘要:中小学人工智能教育的核心要素是模型,但目前缺少相应的技术规范和社区平台,导致中小学生的人工智能学习成果难以有效“流通”。本文介绍了XEduHub的“repo”功能,提出借助XEduHub和魔搭社区分享AI模型作品的方法,并以MMEdu的“车牌识别”模型为例,展示了分享AI模型作品的具体过程。
关键词:XEduHub;人工智能教育
中图分类号:G434 文献标识码:A 论文编号:1674-2117(2024)19-0090-03
新一代人工智能教育的核心要素是模型。中小学的人工智能教育一般要围绕模型展开,经历从搭建、训练、部署到应用的过程,最终解决一个真实问题。然而,在信息科技类课程中学生的作品类型有Word文档、演示文稿、Flash动画等,也有网页、程序代码等,但几乎很少看到中小学生发布或者分享模型方面的学习成果。
人工智能教育的学习成果有哪些?笔者在编写清华大学出版社出版的《信息科技》教材时曾经讨论过这个问题,并对学生的学习成果进行了梳理,认为大致有如下几类:数据集、模型、训练代码、推理代码、在模型基础上开发的应用程序等。相对来说,要求“分享”模型作品很简单,但是如何让分享的模型有效“流通”起来却并不容易。
人工智能模型的有效“流通”是一道难题
人工智能模型的有效“流通”是一道难题,首先难在技术规范上。人工智能的开发工具很多,仅Python代码中就有Scikit-Learn、SciPy和BaseML等传统机器学习工具,还有TensorFlow、PyTorch和PaddlePaddle等深度学习开发框架。几乎每一种开发框架都会有自己特定类型的模型,如PyTorch的模型格式为“.pth”,TensorFlow的模型格式为“.h5”等。那么,中小学生选择哪一种类型的模型进行分享呢?还有,模型推理往往需要对数据进行前处理和后处理,仅仅提供模型显然没办法让其他人方便地拿来就用,达不到“流通”的目的。
其次,还缺少方便青少年分享模型的社区。模型分享是一个相对比较专业的工作,直接将模型作品放在云盘上,显然不是一个可行的分享方式,也很难达到分享交流的目的。例如,人工智能企业或者研究者往往会选择Hugging Face、魔搭(ModelScope)等开源模型社区或者平台。这些平台会提供特定的运行环境和下载协议,吸引了越来越多的爱好者前来“寻宝”。
借助XEduHub分享学生人工智能模型
为了方便人工智能模型的交流,XEduHub在设计之初就选择了ONNX Runtime推理框架。支持ONNX Runtime的企业很多,其模型格式为ONNX,全称为Open Neural Network Exchange,即开放神经网络交换格式,旨在实现不同深度学习框架之间的模型互操作性,便于模型的共享和部署。考虑到更多的模型需要快速支持,XEduHub设计了“repo”功能,无意中为学生模型的有效流通问题提供了一个不错的解决方案。
1.XEduHub的“repo”功能
“repo”一词是“Repository(仓库)”的缩写,是指用来存储代码、模型以及其他项目文件的地方。想要分享任何一个模型或者其他作品,都需要将相关的文件放在一个公共的区域,如GitHub、GitLab、魔搭等。XEduHub的“repo”功能也一样,要求分享者将代码、模型等文件放在公共的网络空间中,公开其空间信息。使用者通过空间信息,将网络空间的项目自动下载(同步)到本地(如图1),达到了分享的目的。
经过多方面的比较XEduHub最终选择魔搭社区为统一分享的空间。分享者需要在开源模型社区上创建一个新的仓库(repo),并上传所需的代码、模型等项目文件。这个仓库的名称就是workflow对象的“repo”参数名称。
2.XEduHub的“repo”功能的基础代码
在Python程序中使用以“repoUS9m5IA4VYw0dDcT6XaUlKaXeJRuNZytvppfZ0MfNqA=”形式分享的模型仅需要三行代码,如图2所示,其中第二行代码将云端的项目同步到本地,并实例化为模型以供调用,第三行代码则调用了模型的推理函数,对数据进行处理并返回推理计算的结果。如果云端项目已经同步,则不会重复下载,其规则和XEduHub的其他模型保持一致。
人工智能模型的分享实例
这里以MMEdu训练的车牌检测模型为例,展示一个人工智能模型的分享流程。首先,利用MMEdu的模型转换功能,将PyTorch模型格式转换为ONNX模型格式,并命名为“model.onnx”。其次,编写一个名为“data_process.py”的模型推理代码,可以实现“端到端”推理。在这里,“端到端”指的是输入一张图片,即可输出模型的推理结果——图片中车牌的坐标信息。“data_process.py”的核心代码如图3所示。
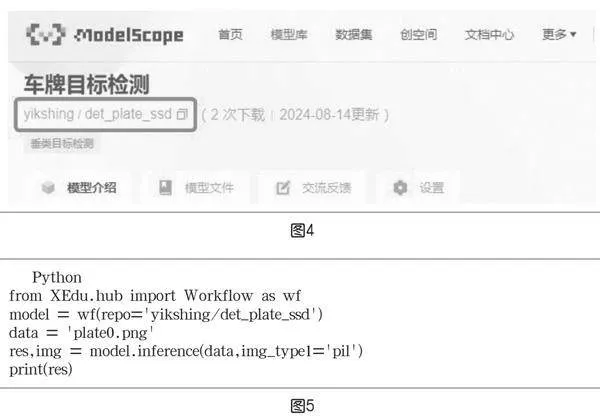
在图3所示的代码中,定义了一个函数get_model_path来辅助模型实例化。另一个函数inference则定义了核心的模型推理参数、流程和返回值。函数名“inference”不能修改,内容可以根据模型的具体情况来实现。接着,将这两个文件上传到魔搭社区。如用户名为“yikshing”,创建的仓库名为“det_plate_ssd”,那么“repo”的参数名称就是“yikshing/det_plate_ssd”(如图4)。图5中的代码实现了调用AI模型,推理一张名为“plate0.png”的图片。这段代码可以在任意支持Python并安装好XEduHub的电脑上运行。
借助“repo”功能实现更复杂的“流通”
在使用过程中笔者发现,结合一些创意,“repo”功能还能实现更复杂的“流通”。
①在一个人工智能项目中多次“repo”其他模型。例如,在一个语音交互的智能作品中,可以将其划分为“语音识别+智能问答+语音合成”的模型组合,借助XEduLLM(大语言模型库)和两个repo的配合,实现语音交互的完整应用。事实上,很多生活中的真实问题需要多个模型联合工作。用“repo”来组合这些模型,流程清晰且代码简洁。
②使用“repo”分享机器学习的模型。“repo”功能一开始仅仅为深度学习的模型分享而设计,所以规定了必须有model.onnx和data_process.py两个文件。但用户只要将模型的扩展名改为“.onnx”,就可以用“repo”方式分享机器学习的模型了。
③在项目中同时分享其他代码资源。“repo”功能会将一个项目中的全部文件都同步在本地,因此可以在项目中提供一些与模型相关的资源,如数据采集工具、模型训练代码、功能介绍视频等,甚至可以同步教学案例,方便教师们的交流分享。
④使用“repo”传递各种非AI的代码。“repo”功能的核心在于data_process.py文件。使用者可以在inference函数中加入各种复杂的功能,如可以设计一个图形化的交互界面,用gradio来实现一个网页端的编程助手等。
结语
XEduHub的“repo”功能为模型的分享而开发,因此项目组还在XEdu文档中提供了“repo”仓库收集页面,汇集了各种自定义的模型,方便大家查询,如人脸情绪判断、人脸特征提取、语音识别、语音合成等。只要看到有趣、有用的开源模型,或者自己训练了特定的模型,使用者都可以用这样的方式分享出来。因而,中小学生训练的人工智能模型也会因此相互“流通”起来。
