基于预测模型的汽车零部件工业流程优化方法研究
2024-10-08张友友李亮林梅林莉

摘 要:文章针对汽车电力变压器生产过程中存在的供销不平衡的问题,利用预测模型,对汽车电力变压器的工业生产过程进行优化研究。文章使用Kaggle平台上470条电力变压器故障分析数据,对电力变压器的预期寿命进行回归预测。将GradientBoosting模型与RandomForest等8种模型进行对比,GradientBoosting模型准确率达86%,证明了其预测性能的优越性。此外,文章还对特征进行重要性分析,有助于理解模型的内部工作机制、更好地进行数据预处理和特征工程。
关键词:电力变压器 生产流程优化 预测模型 特征重要性排序 机器学习
0 引言
电力变压器是一种交流电压转换的设备,由一个或多个线圈组成,可以用于传输和分配电能。氢、氧化原、氮、甲烷、一氧化碳、二氧化碳等绝缘气体,乙烯、乙烷、亚甲基、二苄基二硫等绝缘材料,它们可以用于保护变压器线圈免受外界环境的影响。功率因数、介电刚度、含水量等参数是电力变压器中常用的技术参数,它们可以用于评估变压器的性能和可靠性。
经查阅相关资料,目前汽车电力变压器工业生产流程优化方法主要包括基于仿真技术的优化、基于数理模型的优化等。基于仿真技术的优化主要集中在CAD/CAM、三维虚拟仿真分析等方面;如苏得收(2018)[1]结合层次分析法用工业互联网的思维导入LED封装生产;田磊(2020)[2]通过将三维仿真软件和工业工程相结合合理进行人员调度及资源配置;陈硕(2022)[3]提出基于Petri网建模的产品生产线优化研究。基于数理模型的优化主要集中于统计模型与机器学习模型;孙洋(2019)[4]通过IE法和线性规划模型对B型断路器进行的生产线平衡改善;刘孝保[5]、杨小实[6]等分别建立机器学习模型对相关流程进行优化;此外,深度学习中的神经网络[7]、迁移学习[8]也得到广泛应用。
综上,制造业的工业流程优化研究中,各界学者已经做了大量工作,但少有研究对多种机器学习模型效果进行综合评比,且所选模型缺乏可解释性。基于此,考虑实验数据的多特征性,本文选择多种集成模型,对汽车电力变压器的预期寿命进行预测,并结合特征重要性,分析外界因素对其需求量影响,从而对汽车电力变压器工业生产流程进行优化。
1 优化方法简述
1.1 集成模型
集成学习模型是一种将多个模型结合在一起来提升整体性能的方法。集成学习模型的流程如下:首先,构建多个子学习器;然后,使用某种集成策略将这些模型集成在一起;最后,完成学习任务。子学习器的筛选原则是每个子学习器都要有一定的准确性,并且子学习器之间要保持相对独立性和多样性。
本文所用的Boosting算法的主要思想在于:每一个后续的学习器都会重点关注前一个学习器预测错误的样本,并对这些样本赋予更高的权重,以此来逐步改进模型的预测性能。
1.2 特征重要性排序
特征重要性排序是为了确定哪些特征对模型预测结果的影响最大。有多种方法可以用来计算特征重要性,包括嵌入法(如使用sklearn库中的SelectFromModel)、排列重要性(Permutation Importance)以及SHAP值等。
本文所用的排列重要性是一种基于模型的特征选择方法。其原理是打乱某个特征的值,然后观察模型性能的变化。如果打乱某个特征后,模型预测的正确率显著下降,那么这个特征就被认为是重要的。为了消除随机性的影响,这个过程会多次重复,然后求取平均值和方差。
2 实验准备
2.1 数据勘查
本文数据来源于Kaggle平台所提供的电力变压器数据故障分析。该数据集提供了电力变压器的材料、外界因素等相关信息,通过对全部数据分析发现,该电力变压器共14个属性,2个标签。使用info()函数可得该数据集共有16列,每列有470条数据,均无缺失值、重复值,故可不做相关预处理。
2.2 数据相关性
通过corr函数查看各特征与'Life expectation'(预期寿命)列之间的相关性,并按相关性从高到低排序,且各个影响因素与预期寿命均有显著的统计关系,因此保留每一项影响因素。
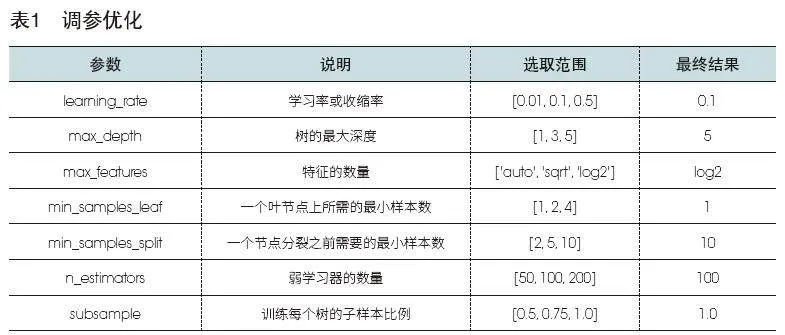
为进一步了解数据的分布、异常值等特点,对每个影响因素进行可视化,展示其分布情况,包括直方图、箱形图和群点图。其中,CO对预期寿命的影响如图1所示。
初步探索数据后,调用scikit-learn库中的train_test_split函数,将数据集按7﹕3的比例划分为训练集和测试集,并使用scikit-learn库中的StandardScaler来对所有数据进行标准化处理,使其更适合机器学习算法。
3 预测模型构建与评分
3.1 模型建立
对数据进行清洗后,采用九种集成模型对训练集进行训练,并计算每个模型在测试集上的准确率,GradientBoosting模型的准确度达到了0.86,因此,选用GradientBoosting作为基础模型。
为了更好全面评估机器学习模型的预测性能,利用matplotlib库绘制散点图(如图2所示),采用可视化技术来展示数据实际值与预测值之间的关系。
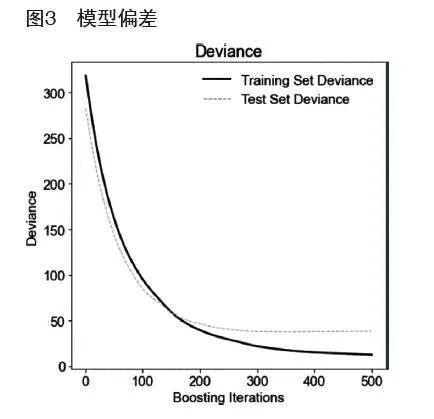
为深入探究机器学习模型在训练过程中的性能演变,对模型的偏差进行可视化分析。偏差是衡量模型预测值与实际值之间差异的重要指标,它随着迭代次数的增加而逐渐减小,图3能够直观了解模型在训练过程中的性能变化,从而识别出可能存在的过拟合或欠拟合问题。
3.2 模型调参
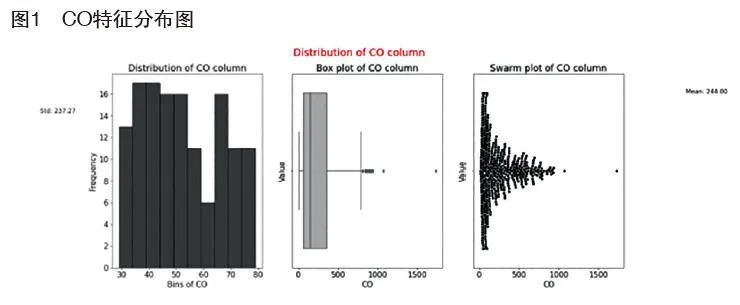
通过前文实验筛选出预测精度最好的GradientBoostingRegressor模型,输入训练集与测试集进行性能测试。并使用GridSearchCV来搜索最佳的超参数,此方法是对模型的指定参数进行范围内穷举,以获得最佳的性能。调参优化步骤如表1所示。
3.3 实验效果评估
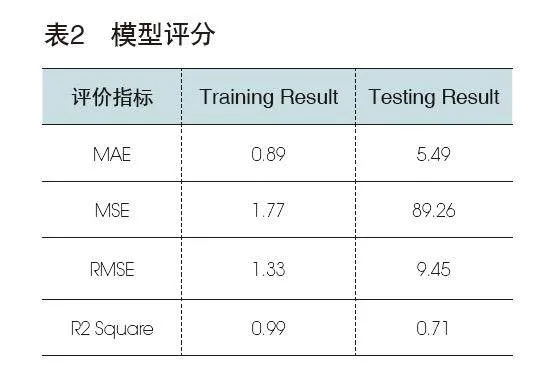
为进一步比较电力变压器剩余寿命预测模型的准确性,利用均方误差(MSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、决定系数(R2)等指标对模型进行评价,结果如表2所示。
由表2可知,该模型在训练集上表现优异,但在测试集上性能较差,可能存在过拟合问题。为了改进模型性能,可以考虑采用正则化技术、增加数据多样性、调整模型复杂度或使用交叉验证等方法来减少过拟合。
4 基于特征重要性的电力变压器影响特征分析
为深入理解各个特征对电力变压器预期寿命的影响程度,本文采用两种不同的方法来评估特征的重要性,并通过可视化展示结果。
除使用模型自带的feature_importances_属性获取每个特征的重要性分数以外,本文还采用了更为稳健的置换重要性(Permutation Importance)来进一步评估特征的重要性。置换重要性是通过随机打乱测试集中某个特征的值,然后观察模型性能的变化来计算的。如果打乱某个特征后模型性能大幅下降,则说明该特征对于模型的预测能力至关重要。
由图4可以看出,Interfacial、Water content、Health index特征性排名前三,说明其对电力变压器的预期寿命影响较大;在实际工程中,可重点关注其值的变化,以便准确的掌握电力变压器的使用状况等。
5 结论
本文介绍并详细阐述了实施方法、流程和具体效果,且对比了GradientBoosting等9种集成学习模型的预测效果,结果表明GradientBoosting模型预测精度达到0.86,明显优于其他模型,验证了其有效性。
使用综合性能最优的集成模型对电力变压器数据故障分析的变量进行特征重要性排序,结果显示Interfacial、Water content、Health index对模型预测结果影响较大,并针对变量的重要性对电力变压器的生产监控提供建议,帮助公司优化其工业流程,提升经济效益。
基金项目:2022年四川省大学生创新创业训练项目:基于预测模型的汽车零部件工业流程优化方法研究(107261858)。
参考文献:
[1]苏得收.基于工业互联网的LED封装生产流程优化[D].天津:天津大学,2017.
[2]田磊,王婕.VR眼镜后组装生产线流程优化研究[J].制造技术与机床,2020(03):139-144.
[3]陈硕.基于Petri网建模的G公司缸盖生产线优化[D].石家庄:河北科技大学,2022.
[4]孙洋.基于Witness的电力设备生产线平衡优化研究[D].北京:华北电力大学(北京),2020.
[5]刘孝保,严清秀,易斌,等.基于集成学习和改进粒子群优化算法的流程制造工艺参数优化[J].中国机械工程,2023,34(23):2842-2853.
[6]杨小实,王湘龙.基于机器学习支持向量回归SVR算法对外卖配送流程优化的研究[J].计算机产品与流通,2019(11):108+146.
[7]王旭.面向神经计算的连铸坯质量预测方法研究[D].唐山;华北理工大学,2022.
[8]陈航.基于BERT和迁移学习的业务流程预测与可解释性研究[D].淮南:安徽理工大学,2023.
