基于YOLOv8-OCR的井下人员检测算法
2024-09-16倪云峰霍洁侯颖王静郭苹



关键词:目标检测;YOLOv8:光学字符识别;反光号码牌;注意力机制
0引言
煤炭工业对我国国民经济快速发展具有基础性作用。2022年中国拥有的煤炭储量约占世界总量的15.1%,居世界第三位,仅次于美国和俄罗斯。煤炭产量比上年增长7.9%,超过全球煤炭总产量的50.8%,消费量比上年增长0.6%,达到了161.10 EJ(占比为27%),位居世界第一。
在我国,煤矿环境错综复杂,一旦发生事故就会造成重大的经济损失以及人员的伤亡。因此,对井下工作人员的严格保护变得至关重要。通常,井下许多重点安全区域都是以人员监控管理为主。由于我国很多煤矿工人在井下穿着统一的安全帽和工作服,一旦发生事故,难以确定受害者的身份以及位置,对后续的救援增加了困难,因此,改善井下人员的着装对防范安全事故有着至关重要的作用。本文创新性地将行人属性应用到井下,将反光号码牌贴在安全帽和工作服上作为属性进行识别。安全帽和工作服上的反光号码牌在井下昏暗环境中容易被摄像头捕捉,从而提高井下人员的人身安全。近年来,随着视频监控系统的普及,基于图像处理的着装识别技术得到快速发展。但是,复杂的背景干扰和非刚性的人体结构特点使得直接从原图提取着装特征的方法效果不佳。因此,大多数现有的识别算法依赖基于深度学习的目标检测方法。
图像的目标检测是对目标进行识别然后框出目标所在位置。目前的煤矿井下人员检测方法主要以深度学习的目标检测为框架,包括R-CNN和Y0L0系列两大类。R-CNN主要针对候选区域进行分类回归,检测精度高;Y0L0系列则通过处理整个图像而不需要复杂的设计来优先考虑更快的检测。
因此,为提高人员在井下昏暗环境的检测性能,本文采用改进的Y0L0v8算法对井下人员进行检测,首先,本文创新性地将行人属性应用到工地场景,将反光号码牌贴在安全帽和工作服上作为属性进行识别,之后收集井下环境的图片,通过图片的预处理构建对应的井下数据集,在Y0L0v8基础上替换了FReLU激活函数,解决了激活函数中的空间不敏感问题,使普通的卷积也具备捕获复杂的视觉布局能力,使模型具备像素级建模的能力。除此之外,还引入注意力机制,使得精确度提高。然后对识别的号码牌区域用光学字符识别(Optical Character Recogni-tion,OCR)技术对区域的数字进行识别。根据训练及验证数据集的划分,评估不同算法下的检测性能,与传统算法YOLOv8进行性能对比,提高了精度与速度,以及模型鲁棒性,应用性能更优。
1Y0L0v8算法原理
Y0L0v8算法是由Ultralytics于2023年发布的Y0L0系列最新模型,Y0L0v8的一个关键特性是可扩展性。它被设计为一个框架,支持所有以前版本的Y0L0,可以轻松地在不同版本之间切换并比较它们的性能。除了可扩展性之外,Y0L0v8还包括许多其他创新,使其广泛应用在对象检测和图像分割任务上,包括新的骨干网络、新的无锚网络检测头和新的损失函数功能。Y0L0v8非常高效,可以实现从CPU到GPU的运行。Y0L0v8的骨干部分与Y0L0v5基本相同,基于CSP思想,将C3模块替换为C2f模块。C2f模块借鉴了YOLOv7中的ELAN思路,将C3和ELAN结合在一起组成了C2f模块,使Y0L0v8在保证自身质量轻的同时可以获得更丰富的梯度流信息。在骨干末端,仍然使用最流行的快速空间金字塔池化(Spatial Pyramid Poo-ling-Fast,SPPF)模块,依次传递3个大小为5×5的Maxpools,然后将每一层进行串联,这样既保证了不同尺度下物体的精度,同时又保证了物体的轻量化。在颈部,YOLOv8使用的特征融合方法仍然是PAN-FPN,加强了不同尺度下特征层信息的融合和利用。Y0L0v8的作者使用了2个上采样和多个C2f模块以及最终解耦的头部结构来组成颈部模块。在Y0L0x中,头部解耦的想法被Y0L0v8用于颈部的最后一部分。它将置信度和回归盒结合起来,达到了一个新的精度水平。对于正样本和负样本分配,Y0L0v8算法使用任务对齐单阶段目标检测(Task-aligned One-stage Object Detection,TOOD)的分酉己器,根据分类和回归的加权得分选择正样本。
Y0L0v8支持所有版本的Y0L0,可以在不同版本之间随意切换,还可以在各种硬件平台(CPU-GPU)上运行,具有很强的灵活性。Y0L0v8网络架构如图1所示。
2改进模型
2.1引入卷积注意力模块注意力机制
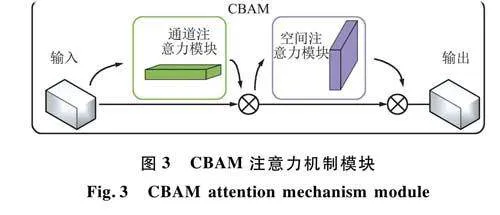
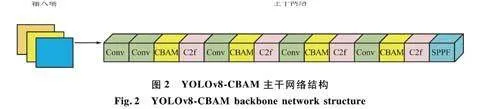
注意力机制最初应用于计算机视觉以模拟人类视觉注意力处理。起源于2014年Google Deep-Mind团队,此后在各种深度学习领域得到了广泛应用,例如自然语言处理、对象检测和语义分割。通过将注意力机制纳入目标检测中,模型可以专注于图像中的关键信息,过滤掉不相关的数据,从而优化计算资源并提高小目标的检测性能。本文将卷积块注意力模块(Convolutional Block AttentionModule.CBAM)引入图2所示的黄色位置。
CBAM结构由通道注意力模块和空间注意力模块组成,如图3所示。通道注意力侧重于识别具有特定目标特征的相关通道,而空间注意力则强调空间域内的关键信息。通过将网络的注意力引导到感兴趣的区域,这些机制增强了特征提取,特别是对于表面字符等小目标,从而显著提高了检测精度和整体模型性能。通道和空间注意力模块与卷积层的集成通过自适应调整进一步优化特征图,过程如下:
通道注意力模块通过输入,分别通过多层感知机(Multi-Layer Perception,MLP)对MLP输出的特征进行逐元素求和运算,生成最终的通道关注特征图。对其与输入特征图进行乘法运算,生成空间注意力模块所需的输入特征。该过程表示如下:
空间注意力模块使用上述注意输出的特征图作为该模块的输入特征图。将特征与模块输入相乘,生成最终生成的特征图。该过程表示如下:
2.2替换激活函数
通过保留基本特征并消除冗余,激活函数有效地映射激活的神经元特征,从而增强卷积神经网络(Convolutional Neural Network,CNN)的表达能力,在整个网络结构中也起到了重要作用。目标检测常用的激活函数包括Sigmoid、tanh、ReLU、PReLU和Mish,都有助于网络的非线性能力。然而,这些函数有一个共同的局限性:只激活单个特征点,而不考虑上下文信息,导致激活域大小固定为1X1,并且对整体图像信息的关注有限。
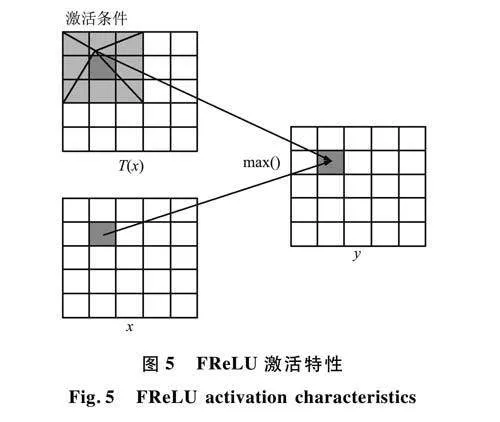
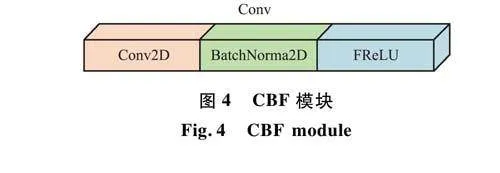
针对此问题,香港理工大学于2020年提出一种专门用于图像识别Funnel激活函数(FReLU)。本文将激活函数中的Sigmoid-Weighted Linear Unit(SiLU)替换为FReLU的模块称为CBF模块,如图4所示。FReLU是一种专用于视觉任务的激活函数,增加了空间条件来扩展ReLU和PReLU。FReLU提出的二维漏斗样激活函数,通过在ReLU激活函数中加入漏斗条件T(x),将二维漏斗样激活函数扩展到2D。只引入少量的计算和过拟合风险来激活网络中空间不敏感的信息,以改善视觉任务。该过程表示如下:
激活特性分析:FReLU激活函数中(激活特性如图5所示),在进行非线性激活时,max()函数给了网络模型是否关注空间信息的2种选择,当卷积的结果T(x)更大时,模型将关注到更多的空间信息而不再是单个特征点。
通过分析可以看出,采用FReLU激活函数进行模型搭建将使模型有更广的激活域,同时增强对空间信息捕获能力。
2.30CR
OCR技术的发展得益于计算机视觉、深度学习和自然语言处理等领域的进步。现代0CR系统通常基于深度学习模型,如CNN和循环神经网络(Recurrent Neural Network,RNN),这些模型能够更好地捕捉字符的特征和上下文信息,提高识别准确性和鲁棒性。字符识别就是对分割的字符一个个进行识别,一般分为模板匹配法与神经网络2种算法。模板匹配计算目标图像与每个模板图像之间的距离,并根据相似度对它们进行排序,最相似的模板代表识别出的字符。然而,该算法需要结构良好的字符,并且容易受到角度变化和拉伸引起的扭曲的影响。相比之下,神经网络利用字符间特征来实现鲁棒识别,能够从不同类型的噪声干扰中提取不变特征,即使在处理变换后的目标字符图像时也表现出很强的适应性。因此,本文在识别过程中采用Easy0CR,从预处理阶段得到的增强图像中读出数字。
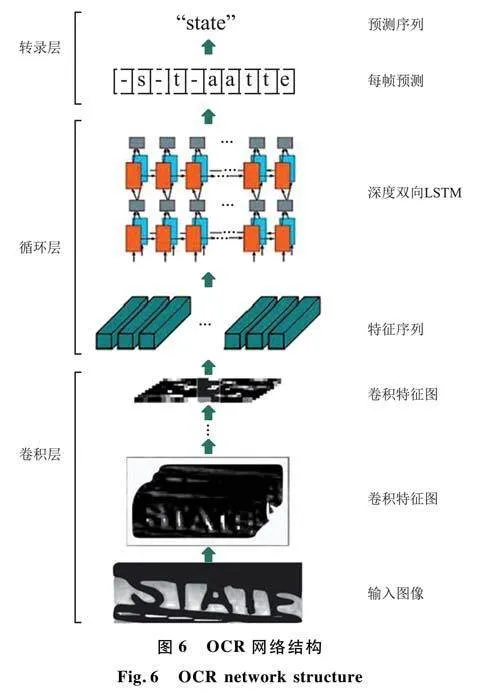
Easy 0CR是一种支持70多种语言的0CR方法,如汉语、英语和印地语等。0CR是基于ResNet、长短期记忆(Long Short Term Memory,LSTM)和连接时间分类(Connectionist Temporal Classification,CTC)模型的字符识别。Easy 0CR有3个主要组件,网络结构如图6所示。①特征提取,对ResNet模型进行特征提取训练。②序列标记,采用LSTM算法。③基于CTC进行解码。在识别过程中利用了EasyOCR的Readtext功能。简单0CR的主要特点是从图像中读取字母和数字,并返回其所在位置的坐标。
3实验过程
3.1实验环境
本实验所用计算机操作系统为Windows 11 64位,处理器型号为i7-12700H,显卡型号为NVIDIAGeForce RTX 3060 Ti,内存8GB。以PyTorch框架:为基础,编程环境为Python 3.8。
3.2数据集和预处理
为验证本文井下人员着装号码牌检测方法的有效性,利用自建井下数据集进行实验,共采集1 830张图片,标签包括号码牌0~9,分别代表张某(0)、王某(1)、李某(2)、刘某(3)、陈某(4)、杨某(5)、赵某(6)、周某(7)、吴某(8)、许某(9)。为满足数据集的多样化要求并提高模型的稳健性,选择3种图像处理技术扩大数据集的广度和深度,从而增强模型的弹性,包括水平翻转以引入方向不变性、添加随机高斯噪声以提高针对相机失真的鲁棒性,以及随机亮度调整以模拟同一位置的照明条件的变化。
扩充后的数据集共有8581张图片,并将数据集图片按照7:2:1的比例划分为训练集、测试集和验证集。
3.3训练模型
本文数据集来源于自建井下数据集,其中图像为某煤矿井下图片,分辨率均为2048pixel×2048pixel。数据集中有近8580张图片,对图片中的人员号码牌进行标注,共包含10个类别。共计训练集6000张,测试集1700张。数据中使用0~9的标签代替人员信息。采用PyTorch框架对本文改进后的网络结构进行训练学习。训练过程中每批次图像为32张,模型在数据集中循环训练300次,学习率为0.0001。如果3个连续循环训练损失不下降,将学习率降低10倍。如果10个连续循环训练参数不下降,结束训练过程。
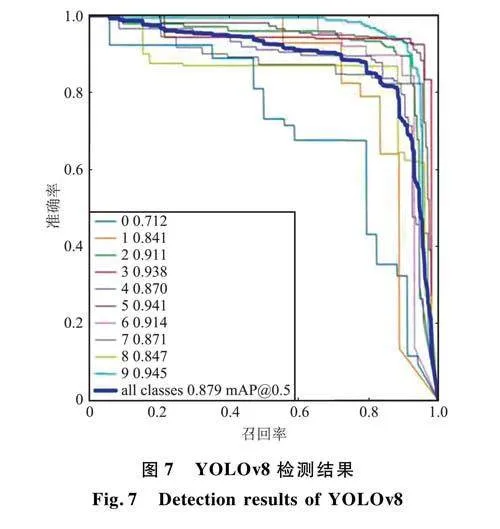
图7是使用Y0L0v8进行检测的结果,其中对带有2、3、5、6、9号码牌的井下人员检测率达到了90%以上(9号码牌的检测准确率最高为94.5%,0号码牌的测试准确率仅为71.2%)。
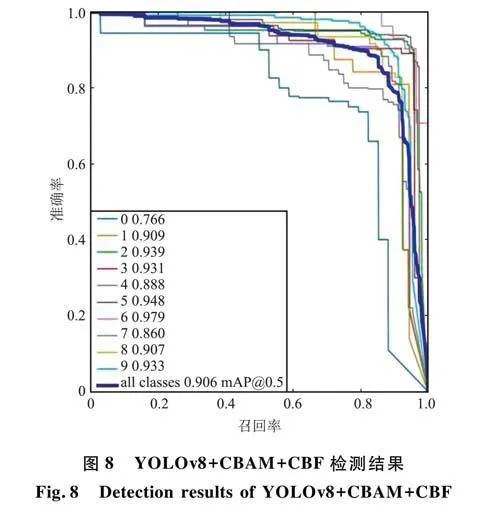
图8是使用YOLOv8+CBAM+CBF进行检测的结果,其中对带有1、2、3、5、6、8、9号码牌的井下人员检测率达到了90%以上(6号码牌的检测准确率最高为97.9%,0号码牌的测试准确率仅为76.6%)。
4实验结果分析
4.1评价指标
为了验证模型有效性和检测效果,选取平均精度均值(mean Average Precision,mAP)、召回率(Re-call,R)、准确率(Precision,P)和每帧推理时间作为评价指标。
4.2反光号码牌区域检测效果验证
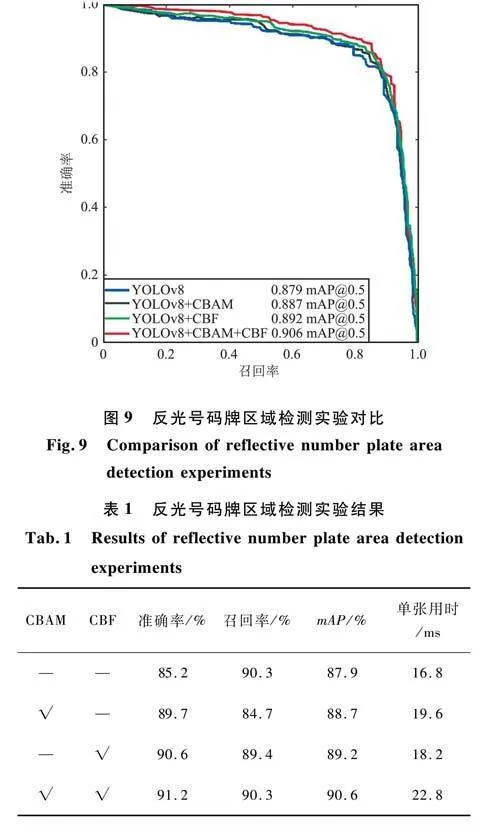
本文首先验证提出的模型在进行号码牌牌检测时的有效性。为了进一步验证上述改进方法的效果,进行了消融实验,结果如图9和表1所示。由于本文主要针对YOLOv8网络进行改进,实验选取YOLOv8网络作为对比基准。可以看出,为提高YOLOv8网络的精度,引入了CBAM注意力机制模块,模型准确率从85.2%提高到89.7%,提高了4%。然而,这一改进使得召回率下降了6%。召回率的下降可归因于通道注意力和空间注意力机制的引入,增加了网络的深度。因此,当在神经网络的较低层学习相似的物体时,判别性特征变得不那么突出,导致检测到物体但分类不正确,从而降低召回率。尽管如此,平均精度还是提高了近1%,证明了改进模型的有效性。引入CBF模块后,进一步提升了网络性能,准确率由89.7%提高至90.6%,使得最终检测结果更准确。相较于原YOLOv8网络,YOLOV8+CBAM+CBF模型模型的准确率由85.2%提高至91.2%,召回率较原网络没有变化,平均精度提升了2.7%。进一步提高了模型的准确性并证明了其有效性。
4.3反光号码牌识别效果验证
结合YOLOv8+CBAM+CBF和Easy OCR的识另IJ网络,在自建数据集上与传统字符识别算法EasyPR进行对比测试,结果如图10和表2所示。
实验结果表明,在自建数据集上,本文提出的基于YOLOV8的OCR井下人员识别算法准确率达到了93.2%,较Easy PR算法词准确率提高了16%。而检测一张2048pixelx2 048 pixel图片仅用时24.4ms,符合实时检测的时间要求。
从图10和表2结果可以看出,本文采用先检测人员着装号码牌的区域,然后在该区域上对数字进行识别,其虚报率(伪号码牌占有效总号码牌的比例)和漏检率有很大改善,去除了不少干扰,为后续的字符识别节约了时间(即阻止了伪号码牌进入字符识别模型)。
井下人员反光号码牌检测结果如图11所示,检测结果用矩形框表示,框上是识别的类别标签和相应的概率。通过对比看出,图11(a)中YOLOv8模型对煤矿昏暗背景下的小目标检测能力较差;图11(b)中的改进模型对以上问题都有明显改善,进一步证明了改进模型的有效性和实用性。
5结束语
针对煤矿人员在井下恶劣环境的检测效果,本文创新性地将行人属性应用到煤矿场景下,以提高检测性能。针对井下小目标检测率低的缺点,采用注意力模型,提高了网络对不同尺度的特征提取能力;然后通过引入视觉激活模块提高了模型检测准确率;最后对检测到的号码牌区域用字符识别技术对区域的数字进行识别,进一步提高了模型的检测精度。实验结果表明,本文算法与原算法相比能够更有效地应对井下环境中的光照变化和干扰因素并且满足实时检测的要求。
