基于大数据技术的电商用户行为分析与可视化
2024-09-15刘莹




摘要:随着互联网技术的进步,消费者逐渐形成在电商平台购物的习惯,由此产生了海量的用户行为数据。有效分析和挖掘这些数据并发挥其价值,是当前电商平台的迫切需求。文章详细阐述了从数据采集与预处理、数据存储、数据分析与可视化等多个方面。数据分析结果可为电商平台制定产品策略、优化用户体验和增强市场竞争力提供参考。
关键词:电商平台;用户行为分析;大数据技术;多层次架构
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)24-0070-03
开放科学(资源服务)标识码(OSID)
0 引言
对海量用户行为数据进行分析和挖掘,对优化商家的营销策略和改善客户服务至关重要。用户行为的特征数据包括用户浏览商品次数、购买记录、购物车记录、收藏记录及发生购买行为的时间戳等。动态分析用户行为特征数据并结合商品特征数据,可以获取用户购物偏好、行为规律,并准确定位优质用户和高黏性用户[1]。因此,本文基于大数据技术,设计并实现了一种电商用户行为数据分析与可视化系统。
1 技术分析
电商平台用户行为数据具有以下特点:大规模、数据源结构多样、时效性强。本系统采用Spark作为计算引擎,Hadoop分布式文件系统(HDFS)作为存储,并利用Python爬虫、Kafka、Storm等技术进行数据采集和预处理,最终使用Echarts进行可视化呈现。
1)爬虫技术。网络爬虫是一种按照特定规则自动地抓取互联网信息的程序。常用的爬虫库包括requests、re、lxml、scrapy等。
2)HDFS是Hadoop生态圈中的分布式存储组件,采用主从结构,将数据分块存储在集群节点上,实现容错容灾[2]。
3)Kafka是一个事件流处理平台,作为消息中间件,它将数据作为事件流导入和导出,实现与现有系统的集成。
4)Storm是一个开源的分布式实时计算系统,具有低延迟、高可用、分布式、可扩展等特性,并保证数据不丢失。
5)Spark是一种基于内存计算的大数据计算框架,利用SparkCore、SparkStreaming、SparkSQL等组件处理数据,通常从HDFS中获取数据源[3]。
6)Echarts是一款开源JavaScript库,专注于创建高级数据图表,提供多种可视化图表类型,包括折线图、柱状图、散点图、饼图等[4]。
2 系统架构设计
本系统采用四层架构,如图1所示。
第一层外部数据源层,目标网站为京东商城,爬取的信息包括手机列表、手机属性和手机评论信息。
第二层数据采集层,利用Python编写爬虫程序,自动抓取目标网站信息。爬虫从初始URL开始,获得链接并不断提取新的URL,直到满足特定条件时停止。
第三层实时流处理层,采用Kafka+Storm架构实现实时数据处理,并将数据存储到HDFS。分布式存储爬取数据,兼顾存储系统的I/O性能和文件系统的可靠性与可用性。
第四层为数据分析与展现层,使用Spark及Echarts进行数据分析与可视化结果展示。
3系统实现
3.1数据采集模块的实现
本系统使用Python爬虫程序爬取京东平台手机商城数据,爬取数据包括手机列表信息、详情信息和评论信息。爬虫主要流程如下:
步骤1:打开京东网站,搜索框中输入“手机”进行搜索,访问手机列表页。分析目标网页URL,获取代表页数的可变参数page。拼接字符串生成目标URL。
url='https://search.jd.com/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page='+str(2*n)+'&s='+str(48*n-20)+&scrolling=y&log_id='+str(b)
步骤2:使用requests库获取网页源码,并利用XPath定位每个商品的li标签。
r = requests.get(url,headers=head)
r.encoding = 'utf-8'
html = etree.HTML(r.text)
datas = html.xpath('//li[contains(@class,"gl-item")]')
步骤3:使用XPath提取目标数据,包括商品名称、商品ID、价格、评论、店铺名称、详情链接、是否自营,并存储到csv文件中。
with open('JD_Phone_list.csv','a',encoding='utf-8') as f:
write = csv.writer(f,lineterminator='\n')
for data in datas:
p_id = data.xpath('@data-sku')[0]
p_price = data.xpath('div/div[@class="p-price"]/strong/i/text()')[0]
p_comment = data.xpath('div/div[5]/strong/a/text()')[0]
p_name = data.xpath('div/div[@class="p-name p-name-type-2"]/a/em')[0]
p_shop = data.xpath('div/div[7]/span/a/@title')[0]
p_detail = data.xpath('div/div[1]/a/@href')[0]
p_model = data.xpath('div/div[8]/i')[0]
write.writerow([p_name,p_id, p_price,p_comment,p_shop,p_detail,p_model])
步骤4:重复上述步骤获取手机详细信息页、评论页数据,并提取相应字段信息,分别存储在对应的CSV文件中。手机详细信息页字段包括品牌、商品名称、品ID、商品毛重、商品产地、系统、机身厚度、拍照特点、电池容量、屏幕、机身颜色、热点、运行内存、前置摄像头像素、后置摄像头像素、机身内存、屏幕配置;手机评价页字段包括序号、商品ID、GUID、评论内容、评论时间、参考ID、参考时间、评分、用户昵称、顾客会员等级、是否手机、购物使用的平台。
3.2数据实时处理模块的实现
数据处理是数据分析与可视化的关键环节,包括数据清洗、数据去重及转换等操作,为后续的各种数据分析奠定基础[5]。本系统采用实时流处理过滤掉不符合标准的数据并存储到HDFS中供后续Spark进行离线分析。处理的主要流程如下:
步骤1:Python读取CSV数据文件并发送到kafak的topic中。
def main(filename,KAFAKA_TOPIC):
#生产模块,区分消息
producer = Kafka_producer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, key)
#采集模块
with open(filename,encoding='utf-8') as csvfile:
csv_reader = csv.reader(csvfile) #读取csvfile文件
for row in csv_reader: #保存数据到birth_data中
roducer.sendjsondata("|".join(row))
步骤2:Storm 实时读取kafka中topic数据,进行数据处理,并将处理后的数据存储到HDFS。
//StormToHDFSTopology.java 负责设置集群运行模式、输出hdfs文件名称,配置kafka,配置strom的spout源等工作。
String kafka_zk_rootpath = "/brokers"; //kafka topic根路径
String topic="phone_data"; //kafka topic
String spout_id = "spout"; //storm spout数据源名称自定义
ZkHosts brokerHosts = new ZkHosts("node1.host:2181", kafka_zk_rootpath); //brokerhost 配置
String kafka_zk_port = "2181"; //zookeeper 端口号
//KafkaToFilter.java 负责空行数据过滤掉
String line = input.getString(0).trim();
if(!line.isEmpty()) {
collector.emit(new Values(line)); //发送消息,过滤空行数据
}
collector.ack(input);
//MessageScheme.java 负责重写消息发送时的类型
String msg = new String(Utils.toByteArray(byteBuffer), "UTF-8");
return new Values(msg);
步骤3:将程序打成JAR包并运行。可在浏览器中访问Hadoop地址(http://本地IP地址:50070)验证生成的HDFS文件。
3.3数据分析模块的实现
系统使用Spark进行业务分析,主要模块包括Spark Core和Spark SQL。Spark对数据文件进行处理和统计分析,并将结果存储到MYSQL数据库中。具体的分析流程如下:
步骤1:手机评论数据分析包括以下内容:对不同等级会员的销售倾向分析,买家评分情况分析,以及情感倾向词频分析。。
//手机对不同等级会员的销售倾向分析。
Dataset<Row> phoneLevelSaleDf = spark.sql("select product_id,user_level,count(*) ct FROM phoneCommentList group by product_id,user_level ");
//买家对商家销售的手机商品的印象分析。
Dataset<Row> impressDf = spark.sql("seletc product_id,score,count(*) ct FROM phoneCommentList group by product_id,score ");
//评论数据情感倾向词频分析。
Dataset<Row> fenciData=spark.sql("select * from fenciView");
步骤2:手机列表数据分析包括以下内容:对不同品牌手机销售数量分析,提取排名前十的数据。
//提取评论数前10的数据
Dataset<Row> namesDF = spark.sql(seletc productName,productId,comment FROM phoneComment order by comment desc limit 10");
步骤3:经上述步骤,得到多个数据表,包括:phoneCommentList(手机评论表)、phoneLevelSale(手机对不同等级的会员销售量表)、impression(买家对购买手机的印象表)、fenci(高频词汇统计表)、phoneDetai(手机属性表)、phoneList(手机销售前十排名表),存储到MySQL数据库中,如图2所示。
3.4数据可视化模块的实现
系统最后使用Echarts实现了电商用户行为数据的可视化呈现。通过图表的展示,更方便直观的了解用户行为数据的相关信息,为电商平台提供更好的决策支持。
1)不同等级会员的手机销售量如图3所示。
2)买家对手机商品的评分情况如图4所示。其中横坐标表示为:买家对手机的评分, 纵坐标表示为:评分的用户数量(单位:千)。
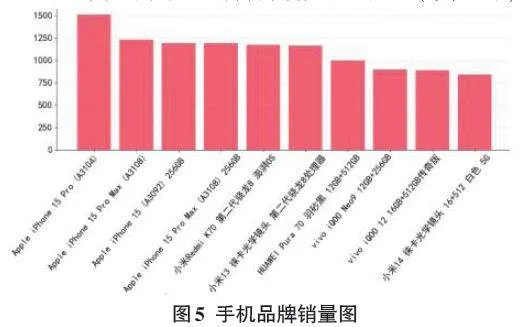
3)不同品牌手机销售排名如图5所示(单位:千)。
4)根据用户对手机的评价信息,使用分词功能提取关键词,用词云图展示如图6所示:
4 结论
本文研究了基于大数据技术的电商用户行为分析与可视化系统,详细阐述了从数据获取到数据分析和可视化展示整个流程。根据分析结果,手机销量占比排名前三的会员类型为:企业会员、金牌会员和钻石会员,占到整个销售量75%之多;消费者对手机产品的偏好主要集中在系统、速度、价格和屏幕及物流服务等方面。电商平台应据此提升产品竞争力并优化服务环节,从而改善客户体验、增强用户忠诚度,进而达到提高销售量的目的。
参考文献:
[1] 郝浩宇,任杰成.电商平台用户行为分析系统研究[J].信息与电脑,2021,33(21):80-82.
[2] 徐怡薇.电商App用户行为分析系统的设计与实现[D].北京:北京交通大学,2023.
[3] 顾炜伦,郝东来,陈立.基于Spark离线和实时的电商用户行为分析系统[J].电脑编程技巧与维护,2023(4):132-134.
[4] 付腾达,李卫勇,王士信,等.基于Python爬虫技术的招聘信息数据可视化分析[J].电脑知识与技术,2024,20(7):77-82.
[5] 高寒.基于电商平台的大数据挖掘系统的设计研究[J].信息记录材料,2023,24(11):204-206,209.
【通联编辑:光文玲】
