基于深度学习的机场物流暴力分拣行为识别系统
2024-09-15赵国轩魏书伟

摘要:机场行李箱分拣是机场安检的重要环节之一。目前,在行李箱分拣过程中,普遍存在机场人员的暴力分拣行为。为杜绝此类违规现象的发生,本文提出了一种基于SlowFast动作行为识别算法的系统,可以实时监测机场分拣人员的暴力分拣行为。SlowFast神经网络算法通过慢速路径(slow-pathway)捕获静态信息和全局动态信息,快速路径(fast-pathway)捕获局部动态信息。两个路径提取的特征经过融合后,在存在暴力分拣行为的AVA格式训练集上进行迭代训练,获得最佳检测模型。实际应用表明,本系统在室内场景中识别暴力分拣行为的准确率达到了99.1%,能够有效减少此类违规行为的发生。
关键词:SlowFast算法;神经网络;机场;行李分拣;行为识别
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2024)24-0043-03
开放科学(资源服务)标识码(OSID)
0引言
近年来,随着世界民航事业的迅猛发展,机场客流量激增,行李箱总量给机场分拣系统造成了巨大压力。截至2023年,国内机场客流量激增至32.4亿人次,远超行业专家的预测。预计在未来几年,国内机场客流量将继续保持高增长势头。然而,伴随着客流量的激增,许多违规操作的暴力分拣行为出现,持续引发广泛关注。在机场分拣系统中,由于工作压力和分拣人员的工作态度等原因,行李箱遭遇踢、抛、扔、摔等违规操作,导致行李箱受到严重的人为损坏,不仅造成一定的经济损失,同时也损害了机场的声誉,性质极为恶劣。因此,识别机场中的暴力分拣行为已然成为机场行李箱分拣系统的重要组成部分。
传统的暴力分拣行为识别方式包括人工检查和视频监控。人工检查通过人员观察分拣过程,若发现分拣员在处理行李箱时存在踢、抛、扔、摔等明显粗暴的违规动作,则可判断为暴力分拣。此方法需要投入大量人力资源,且存在主观性和监控盲区的问题。视频监控通过在分拣区域安装摄像头,可实时监控行李箱的分拣过程。工作人员通过查看监控视频,判断是否存在暴力分拣行为。这种方式较为客观但仍需人工参与,对大量视频数据的处理和分析效率较低。
Yang等[1]提出了一种在时间和空间两个维度进行图卷积的时空卷积网络(ST-GCN),但该方法对多个识别目标的识别不够准确,且检测时间较长。杨君等[2]基于OpenPose模型,通过人体关键点检测的方法进行人体动作识别,但该算法相对复杂,需消耗大量计算资源。同时,当人体出现遮挡时,可能无法准确检测到关键点,而且对光照和背景也十分敏感。
1相关技术与理论
卷积神经网络[3]是深度学习领域的重要技术之一,在目标检测和行为识别任务中具有显著优势,远超其他技术。卷积神经网络具备局部特殊感知的特点,可以共享权重参数,大大降低网络运算的复杂度。本文采用的SlowFast算法[4]是一种典型的有监督卷积神经网络算法。它采用双分支结构,结合两个不同速度的卷积神经网络(CNN)来处理视频中的动态和静态信息。其中,慢速路径(slow-pathway)捕获静态信息和全局动态信息,快速路径(fast-pathway)捕获局部动态信息。为了提取图像特征,使用了3DResNet模型[5],捕获若干帧后进行3D卷积[6]操作。在Slow路径中,ResNet层被用来处理低帧率、低时间分辨率的视频帧。在Fast路径中,ResNet层被用来处理高帧率、高时间分辨率的视频帧,从而捕获详细的运动信息。最后,通过侧向连接(lateral connect)进行融合,使得两个路径可以相互借鉴信息,从而以不同的速率处理原始视频。
本文使用的卷积核为3D卷积,它是一种在三维空间中进行滤波操作的技术,可以在深度、高度和宽度三个维度上同时提取特征。尺寸记作{T×S², C},其中T、S和C分别表示时序Temporal(时间)、空间Spatial(宽度×高度)和频道Channel(通道)的尺寸。3D卷积核是一个小型的三维矩阵,会在输入的三维数据(如视频帧序列)上滑动。在滑动的每个位置,卷积核都会与对应位置的输入数据进行元素乘法并求和,从而生成一个输出值。这个过程会在整个输入数据上重复进行,最终生成一个新的三维输出数据块。与二维卷积相比,3D卷积能够更好地捕捉视频数据中的时间维度信息,即帧与帧之间的动态变化。这使得3D卷积在动作识别、视频分类等任务中具有独特的优势。
2技术路线
为了识别暴力分拣行为,基于SlowFast神经网络算法,本文对原始视频序列进行了分割,并标注了人物回归框的位置(x1,y1,x2,y2)和人物的行为标签,使其与动作行为文件的标号一一对应。然后将原始视频数据切分为一系列的帧序列,并对帧序列进行尺寸调整、归一化等与处理操作,从而适应模型的要求。然后采用双分支结构的SlowFast算法进行特征提取,在慢速路径中,使用较深的网络结构作为主干,使用较低的频率输入帧序列,以获取丰富的空间信息;在快速路径中,使用较浅的网络结构,以较高的频率输入帧序列,来捕获更精细的时间动态,以补充慢速路径中缺失的时间信息。特征提取完成后,在不同层级上,使用time-to-channel的方法,重塑并交换维度,将快速路径提取的特征融入慢速路径中,从而增强模型的时空表征能力。最后设定好超参数和优化方法,反向传播求解梯度,更新权重参数,从而训练一个较好的模型,利用模型对视频序列进行预测,识别其中存在的暴力分拣行为。
3网络结构介绍
本实验采用了动作识别算法SlowFast作为实验算法,该算法能够同时捕捉视频中的空间语义信息和时间动态信息。得益于快速路径的轻量化设计,通过减少通道容量和避免在时间维度上的降采样,使快速路径的计算量相对较小。同时,快速路径和慢速路径的特征融合采用了更为高效的方式,进一步提高了计算效率。在实际应用中,该算法在多个验证数据集上均取得了卓越的性能,在准确率和召回率上表现优异。
SlowFast网络由卷积层和池化层组成,并将ResNet残差连接模块作为特征提取模块,从而保证新特征能够不断被学习。在特征提取前,还设置了不同大小的步长以进行间隔采样。其中在慢速路径中,步长较大,而在快速路径中,步长较小。此外,快速路径使用的3D卷积核的时间维度较大,表示关注的不再是静止信息,而是通过卷积核提取每次多帧信息,从而不间断地确定视频帧序列中的动作语义信息。慢速路径中使用的3D卷积核的时间维度较小,这表示无须考虑视频帧序列之间的连续关系,只需获取静态特征,即背景语义信息。
4实验方案
4.1数据集获取与预处理
本次实验使用了符合AVA格式的视频帧数据,数据总量为430个视频,其中235个用于训练,64个用于验证,131个用于测试。每个视频的时长为15分钟,以1秒为间隔进行标注,标注文件保存为CSV格式。此外,通过随机裁剪和翻转等数据增强操作提升模型的鲁棒性。本次实验的标注类型包括四类动作:踢、抛、扔和摔。使用VIA工具标注视频帧序列中不同帧数下的动作行为,并框选人物,勾选行为类型,以构建符合AVA格式的数据集。
为了提高模型的迁移和泛化能力,实验中Slow pathway和Fast pathway的输入分别为T帧和αT帧。在空间域上,随机从视频或其水平翻转中裁剪224×224的图像,或在[256,320]像素范围内随机采样较短的边。
4.2 SlowFast算法模型训练
在SlowFast算法模型训练方面,步骤如下:1)准备用于训练的视频帧序列和标注文件,包含目标动作或行为以及人物位置。2)进行视频抽帧,将视频转为图像序列,慢速路径和快速路径以不同帧率采集,以适应不同时间尺度的动作识别。3)设定学习率、训练批次等超参数。4)选择合适的优化方法。5)执行梯度归零,进行反向传播以求解梯度,更新权重参数,寻找函数的极小值点。6)最终获取训练好的模型。
在训练过程中通过SlowFast算法,网络通过学习从输入的视频帧中提取特征,并基于标注信息进行预测。通过反向传播算法和优化器调整网络的权重和参数(即权重和偏差),以最小化预测误差,最终得到最佳的动作识别模型。
5实验配置和结果分析
本实验的运行环境如下:GPU为NVIDIA GeForce 1650(notebook);CPU为9th Intel i5-9300H@2.40Hz;内存16GB。Cuda版本为12.1;cuDNN版本为8.5;操作系统为Window11;开发语言为Python;开发框架为PyTorch;优化器采用自适应的梯度下降Adam。超参数设置如下:动量因子为0.94;最大迭代次数为300;初始学习率为0.001;权重衰退系数为0.0002。
5.1 评价指标
本文采用F1-score[7]来衡量暴力分拣行为的识别效果。F1-score是精确率和召回率的调和平均数,用于综合评估模型的性能。在SlowFast算法中,F1-score可以提供一个平衡精确率和召回率的指标。精确率表示模型预测为正例的样本中真正为正例的比例,而召回率则表示在所有真正为正例的样本中,模型正确识别出的比例。在某些情况下,精确率和召回率可能会出现矛盾,例如,当模型预测的正例过多时,精确率可能会下降而召回率上升;反之,当模型预测的正例过少时,精确率可能会上升而召回率下降。因此,单独使用精确率或召回率作为评价指标可能不够全面。使用F1-score则能够更全面地反映模型在分类任务上的表现。其计算公式如下:
[F1-score=2Precision×RecallPrecision+Recall]
式中:Precision表示精确率,Recall表示召回率。
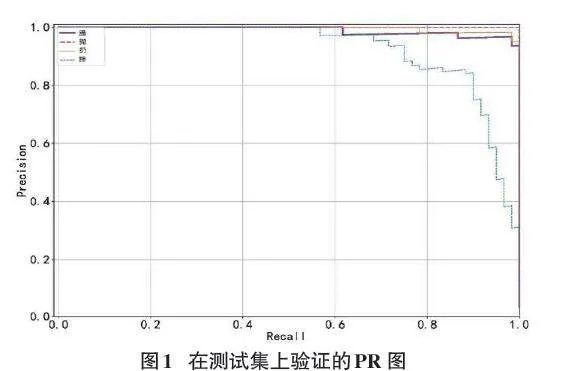
经过对430个视频帧序列进行200次迭代训练后,获得了最佳的权重模型。在测试集上验证的PR图如图1所示。
由图1可知,动作行为“踢”在较低召回率下的精确度相对较高,但随着召回率的提高,精确度逐渐下降。这表明在检测“踢”这一动作时,系统在严格条件下更容易准确识别,然而在宽松条件下可能会引入更多误检。动作行为“抛”的精确度曲线在整个召回率范围内波动较大,且没有明显趋势,这可能说明识别“抛”时受到多种因素影响,或数据集中“抛”样本具有较高的多样性。动作行为“扔”的精确度曲线相对平稳,在大部分召回率下保持在中等水平,表明“扔”的分类性能稳定但非最佳。动作行为“摔”在较高召回率下的精确度明显较高,显示出在宽松检测条件下,系统能够有效识别“摔”,同时保持较高精确度。实验结果显示,本系统对暴力分拣中的违规行为识别准确率较高,并且在测试集上依然可以准确识别特定动作行为,表现出强的鲁棒性。
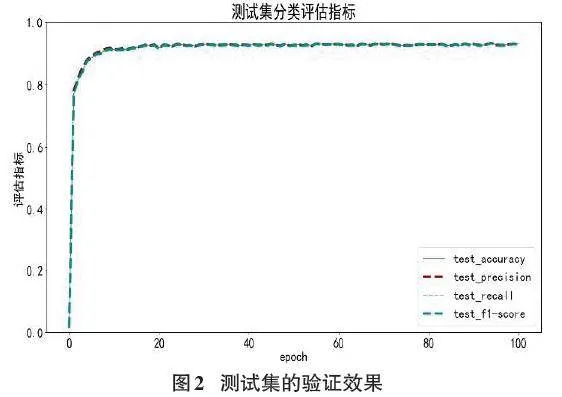
测试集的验证效果如图2所示。实验检测效果如图3所示。网络模型中的训练损失如图4所示。
由图4可知,随着迭代次数的增加,损失函数逐渐呈现出减少的趋势。特别是在引入动量因子后,下降过程变得更加平滑,有效地避免了震荡下降的现象,显示出一条稳定的下降曲线。当迭代进行到第30次时,梯度下降的速度开始逐渐放缓,这表明损失已经接近其最小值。与此同时,mAP值也在逐步接近其最大值,这反映了模型的预测能力在不断提升,模型的拟合程度日益增强。
6 实验总结
本文设计了一种基于SlowFast算法的暴力分拣行为识别系统,该算法在视频行为识别任务中表现出色,特别是在处理长视频和复杂动作时。同时,在某些动作类别上,该模型的性能不如其他动作类别,可能与动作类别间的样本数量不平衡有关。但总体来看,模型在保持高准确率的同时提供了较快的处理速度,可用于实时检测任务,并应用于机场行李箱的分拣业务中。
参考文献:
[1] ZHU S Q,DING X L,YANG K,et al.A spatial attention-enhanced multi-timescale graph convolutional network for skeleton-based action recognition[C]//Proceedings of the 2020 3rd International Conference on Artificial Intelligence and Pattern Recognition.Xiamen China.ACM,2020.
[2] 杨君,张素君,张创豪,等.基于OpenPose的人体动作识别对比研究[J].传感器与微系统,2021,40(1):5-8.
[3] 吴婷,刘瑞欣,刘明甫,等.基于深度学习的人体行为识别综述[J].现代信息科技,2024,8(4):50-55.
[4] FEICHTENHOFER C,FAN H Q,MALIK J,et al.SlowFast networks for video recognition[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).October 27 - November 2,2019,Seoul,Korea (South).IEEE,2019:6201-6210.
[5] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:770-778.
[6] 蒋可欣,谢雨含,李勉文,等.基于半月板MRI的3D卷积神经网络模型预测膝骨关节炎发生的研究[J].磁共振成像,2024,15(2):103-107,121.
[7] 王照国,张红云,苗夺谦.基于F1值的非极大值抑制阈值自动选取方法[J].智能系统学报,2020,15(5):1006-1012.
【通联编辑:唐一东】
