灾害场景下基于MADRL的信息收集无人机部署与节点能效优化
2024-08-17李梦丽王霄米德昌孟磊
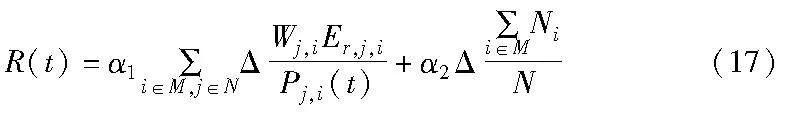

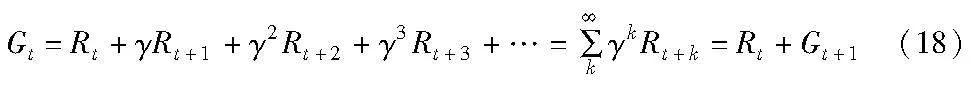
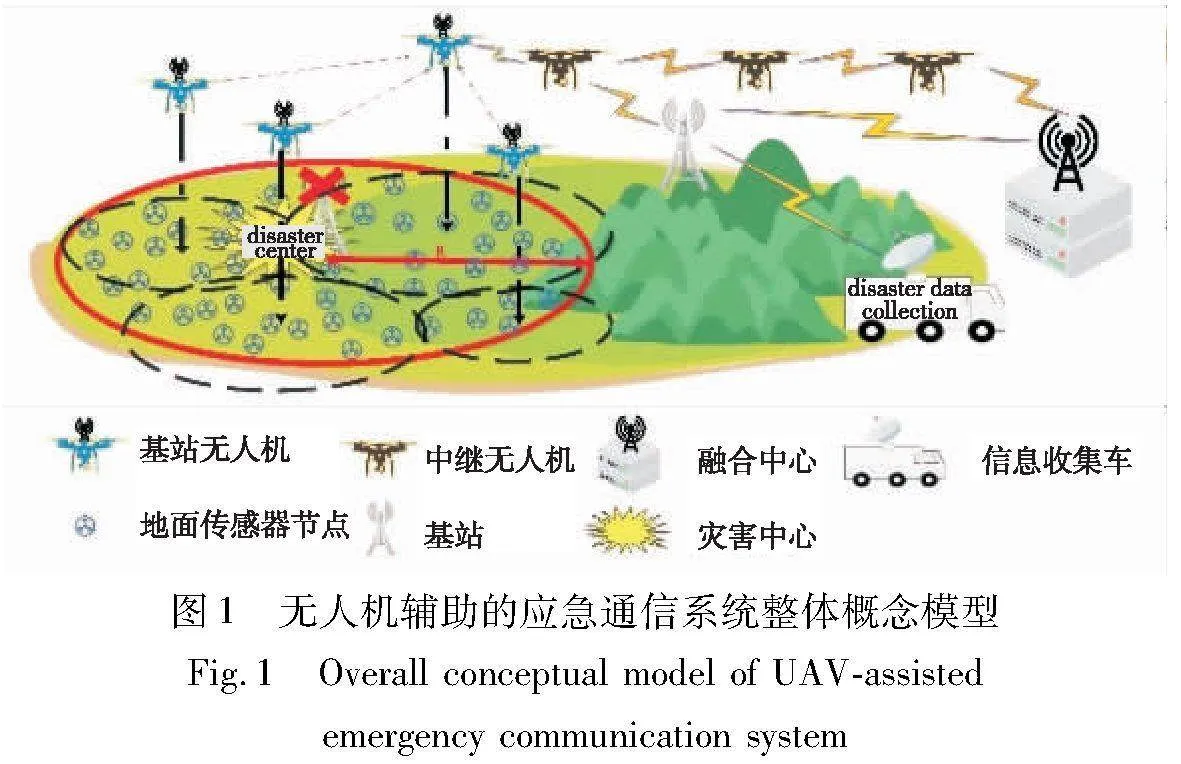


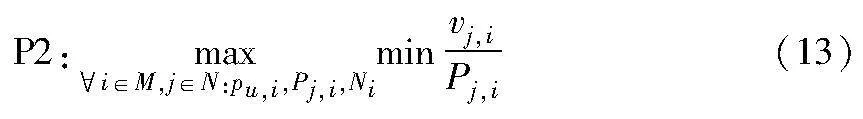
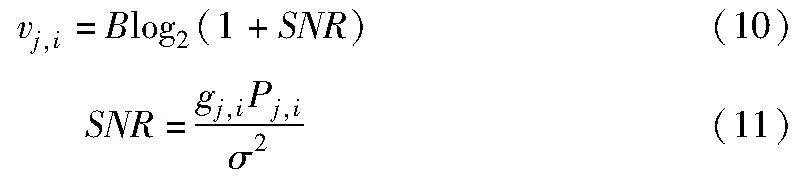
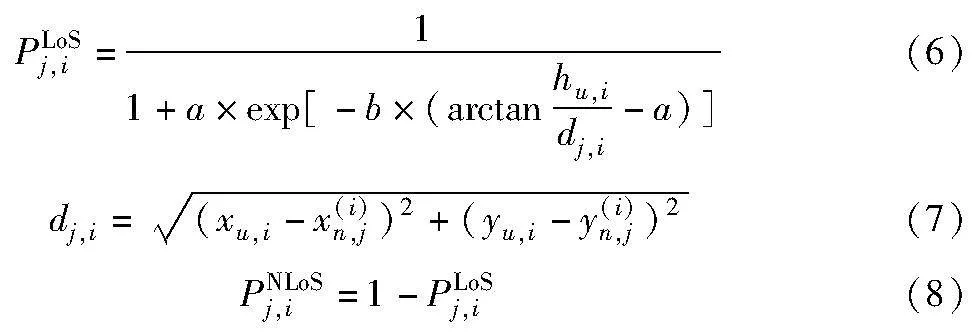





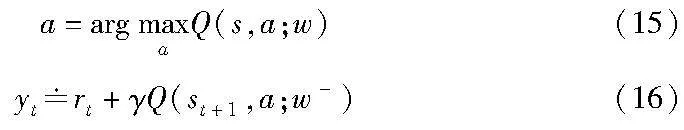


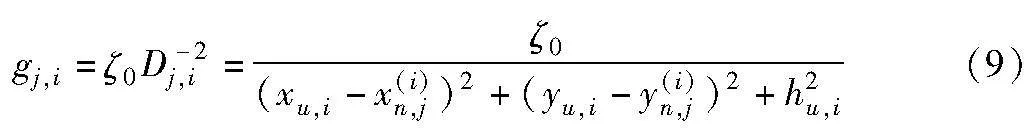


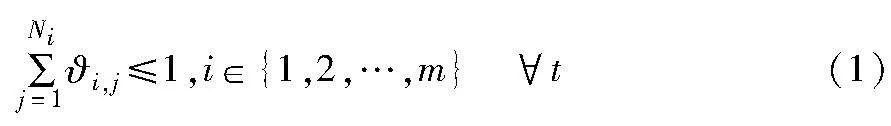

摘 要:灾害场景下,对灾区内第一手重要信息的及时、可靠收集是灾害预警研究、灾区救援工作开展的关键。无人机是与灾区内部建立应急通信网络的高效辅助工具。通过对现有研究中应急场景下无人机的部署方法进行调查,指出了无人机部署时对节点能效考虑不充分的问题。由于地面传感器节点位于灾区内部,环境恶劣且极为被动,所以结合灾害场景,首次以提高地面节点能效为优化目标,基于深度强化学习方法,在DDQN网络模型基础上,通过自定义经验回放优先级、合理设计奖励函数和采用完全去中心化训练方式,解决该特定场景下用于信息收集无人机的自适应部署问题。仿真结果表明,所提算法的节点能源效率比DDQN基准算法提高21%,训练速度相比DDPG、A3C算法分别提升42%和34%。
关键词:应急服务; 节点能效优化; 深度强化学习; 无人机部署
中图分类号:TP399 文献标志码:A 文章编号:1001-3695(2024)07-027-2118-08
doi:10.19734/j.issn.1001-3695.2023.11.0537
MADRL-based UAV deployment and node efficiency optimization forinformation collection in disaster scenarios
Abstract:In the disaster scene, the timely and reliable collection of first-hand and important information in the disaster area is the key to the early disaster warning research and rescue work. Unmanned aerial vehicle(UAV) is an efficient auxiliary tool for establishing emergency communication network within disaster zones. Through the investigation of the deployment methods of UAV in emergency scenarios in the existing research, this paper reported the problem that node energy efficiency was not considered in UAV deployment. Since the ground sensor nodes were located inside the disaster area in a hostile and extremely passive environment, the combination of disaster scenarios. Taking improving the energy efficiency of ground nodes as the optimization goal for the first time, based on the deep reinforcement learning method and on the basis of DDQN network model, the adaptive deployment problem of UAV for information collection in disaster scenarios was solved by defining experience playback priority, reasonably designing reward function and adopting complete decentralized training method. Simulation results show that the energy efficiency of the nodes under the proposed algorithm is 21% higher than that of the DDQN benchmark algorithm, and the training speed is 42% and 34% higher than that of the DDPG and A3C algorithms respectively.
Key words:emergency service; node energy efficiency optimization; deep reinforcement learning; UAV deployment
0 引言
随着信息科技的飞速发展,信息对人类生产生活的影响越来越大,人们对信息传输的要求也随之增高,可靠性、有效性是对信息质量最基本的要求。然而,频繁发生的自然灾害,不仅严重威胁着人们的生命财产安全和生产生活秩序,还会使地面通信设备设施受损甚至瘫痪,严重影响了受灾区域内部与外界的信息交换,妨碍了灾后救援工作的开展,限制了灾害数据收集工作及其后续研究。
灾害发生后,对灾区内第一手重要信息的及时、可靠收集,有助于作出快速反应和决策[1],利于救援、重建和预警研究工作的开展。近年来,多种应急通信方案涌现,有学者提出将卫星用于构建灾后应急通信[2],或使用无须基站的D2D网络[3],但是这些网络都存在一定的弊端,如卫星通信资源不足且成本较高,普通用户很难获得资源[4];D2D网络的网络拓扑路由规划烦琐复杂,具有较大的时延[5],且很大程度上受其电量等众多因素约束。
稳定、可靠、具有灵活性的应急通信系统是解决上述问题的关键。无人机(unmanned aerial vehicle,UAV)所具备的体积小巧、机动灵活且成本较为低廉等特点[6]几乎可以完美应对应急通信系统的实际需求,这使它可以深入灾区内部与灾区内的设备或用户建立网络链接,可用于收集灾害数据,亦可用来为用户提供网络服务,为灾后救援、灾害预警研究等相关工作提供了极大便利。
目前,有大量学者对无人机辅助地面无线网络通信中无人机的部署进行了研究。Zhao等人[7]提出了一种统一的无人机辅助应急网络框架,分别研究了有残存基站场景的无人机基站的轨迹和资源调度优化问题、无残存基站场景的无人机收发器设计和多跳D2D网络的建立问题,以及远距离传输场景中无人机中继的数量和悬停位置优化问题,但仅研究了固定翼无人机作为临时基站的情形。Liu等人[8]将无人机用于辅助异构物联网的应急通信,采用无人机-用户链路与D2D链路频谱共享方案,提出的基于无串行干扰消除非正交多址接入的多目标资源配置方案,设计了一种迭代算法寻找无人机的最佳悬停位置,在用户传输耗时、用户接入率方面表现良好,该方法虽然提高了频谱利用率,但是引入了大量干扰,一定程度上忽视了剩余电量的能源效率对于灾后节点生存的重要性。Barick等人[9]采用了非正交多址接入(non-orthgonal multiple access,NOMA)方式,先后通过最小化扇区无人机与IoT设备总和距离,使用拉格朗日对偶方法,对扇区无人机的位置和IoT设备的功率控制进行了联合优化,提高了系统上行链路的容量,但只对灾区内临时地面基站覆盖区域外的节点进行了简单的均等扇形划分,这种形状并不利于无人机对其覆盖。Lin等人[10]通过收集地面节点的信息建立其虚拟遮挡,对无人机的位置和地面节点传输功率进行优化,针对灾后无人机辅助通信中,如何在保证数据高效传输和服务质量的前提下,对地面节点覆盖最大化的问题,提出了一种适用于应急网络的自适应无人机部署方案,但也只对地面节点进行了简单粗糙的划分,不利于无人机动态调整对节点覆盖。
随着人工智能技术的飞速发展,有学者尝试将深度强化学习(deep reinforcement learning,DRL)用于无人机的自适应部署领域[11~18]。文献[15]将无人机飞行动作离散化的方法存在一定的动作冗余,造成了动作空间维度不必要的增加。文献[16,17]基于DDPG方法提出了一种叫做DRL-EC3的无人机控制方法,同时考虑了无人机基站的通信覆盖范围、公平性、能源消耗和连接性。文献[18]以最大化无人机能效优化目标,以用户覆盖为约束,使用去中心化的多智能体DDQN方法训练无人机具备自适应部署能力。
但是上述方法存在一定不足:
a)对于灾害场景下无人机辅助通信这一特殊具体场景考虑不足:一方面体现在采用传统数学方法的无人机部署较为被动,对灾后环境缺乏自适应性,而基于传统机器学习算法的无人机部署方法需要大量的训练样本及人工标注;另一方面对部署区域的粗糙划分不利于无人机对用户充分覆盖,在各种各样复杂多变的灾害场景下,上述部署方法均欠智能化。
b)在优化目标设定方面,大部分文章考虑的优化无人机的能源效率,忽略了灾害场景下地面无线传感器网络的脆弱性和能耗敏感性。
结合灾害场景紧急、环境恶劣等特点,考虑到无人机受灾害影响相对较小,属于“施救方”,进出灾区较为灵活,具有补充电量的条件和优势。相比之下,灾区内节点处于环境恶劣之中,尤其是提前部署在灾区内的物联网监测系统,移动灵活性极低,几乎为零。但是由于上述监测系统集成了大量传感器并且深入灾区内部,相对于无人机挂载成像设备而言,其所能提供的多维度、多特征、深层次的灾害数据价值不可忽视,所以认为该场景下,相对于现有大量研究中探讨如何提升无人机的能源效率,研究如何提升灾区内节点的能源效率以提高灾区内监测网络的使用寿命,更具实际工程意义。
由于多旋翼无人机相对于固定翼无人机具有更高的灵活性且成本较低,更适合民用场景,所以选择对多旋翼无人机在灾区上空的部署问题进行研究。针对上述问题,本文提出一种基于多智能体深度强化学习以优化节点能效为主要目标的无人机自适应部署方案,主要贡献如下:
a)针对灾害场景特殊的工程需要,无人机部署过程中,首次提出以提高地面无线传感器网络的能源效率为主要目标,充分考虑地面无线传感器监测网络寿命,重点突出优化目标,以此指导无人机部署过程。
b)紧密结合灾害应用场景的紧急性、突发性、多变性特点,将待解决问题建模为马尔可夫过程,选择基于深度强化学习中较为简单DRL方法进行改进,改进和加入多重计算技巧,提出使用完全去中心化的多智能体优先经验回放双重深度Q网络(fully decentralized multi-agent customized prioritized experience replay double deep Q network, MAFD-CPER-DDQN)方法用于无人机部署,所提算法使平均节点整体节点能源效率、学习过程收敛速度比DDQN算法分别提高了21%和17%,在长期收益仅低于DDPG算法9%的情况下,智能体学习过程的收敛速度比DDPG算法提升42%,比异步优势演员-评论家(asynchronous advantage actor-critic,A3C)方法提升34%,兼顾灾害应急场景下高时效、高质量的无人机自适应部署要求。
1 系统建模与问题描述
1.1 系统模型
本文基于以下假设:
a)假设用于灾区监测的无线传感网络节点部署满足所需的冗余性、错误容忍性、健壮性,在受灾严重区域总有捕获到重要环境信息的节点存留,网络的抽样速率、消息发送周期等重要参数设计合理,节点密度部署合理[19];
b)假设存活节点在无人机靠近时,总可以被低功率唤醒,即节点可被无人机检测到;
c)假设无人机和节点均存储有一个相同的特殊比特流,用于误码率测试;
d)假设该模型中无人机构成的子系统是可扩展、自适应的,根据灾区任务量添加或移除无人机时,不会影响其他无人机的性能;
e)假设基站无人机下降过程中,天线方向不改变,忽略地平面反射的信号对原信号的干扰或增强;
f)假设灾区基站受损前,其所覆盖范围内的传感器节点通过该基站接入骨干网络,灾后该区域内无其他基站可正常运行。
示第i个节点是否已经与无人机接通并正在上传数据,为简化模型,节点与无人机之间采用时分多址接入(time different multiple access,TDMA)方式,即任意时刻t一架无人机最多只能与其覆盖下的一个节点接通并进行数据收集,则有
进一步地,灾区上空的基站无人机将收集到的数据通过其他中继设备传输至最终目的地进行下一步处理研究工作。
1.2 信道模型
信道模型为一般化模型,认为无人机ui与其覆盖下第j个地面传感器节点之间的无线信道分别依概率PLoSj,i和PNLoSj,i存在视距(line-of-sight,LoS)链路传输和非视距(non line-of-sight,NLoS)链路传输, ηLoS和ηNLoS分别是地面节点与无人机之间LoS和NLoS链路的平均路径损耗,则地面节点与无人机传输链路的平均传输路径损耗公式如下:
βi,j=ηLoSPLoSj,i+ηNLoSPNLoSj,i(2)
其中:LoS链路传输的信号衰落主要是自由空间路径损耗Lj,i,由式(3)(4)给出。
其中:fc为载波频率,单位为Hz;c代表光速,取3.0×108 m/s;Dj,i表示第i簇簇心上方无人机与该簇内第j个节点间的欧几里德距离,路径损耗指数α≥2。本文取α=2,故式(3)写作:
建立视距链路和非视距链路的概率由式(6)~(8)给出。
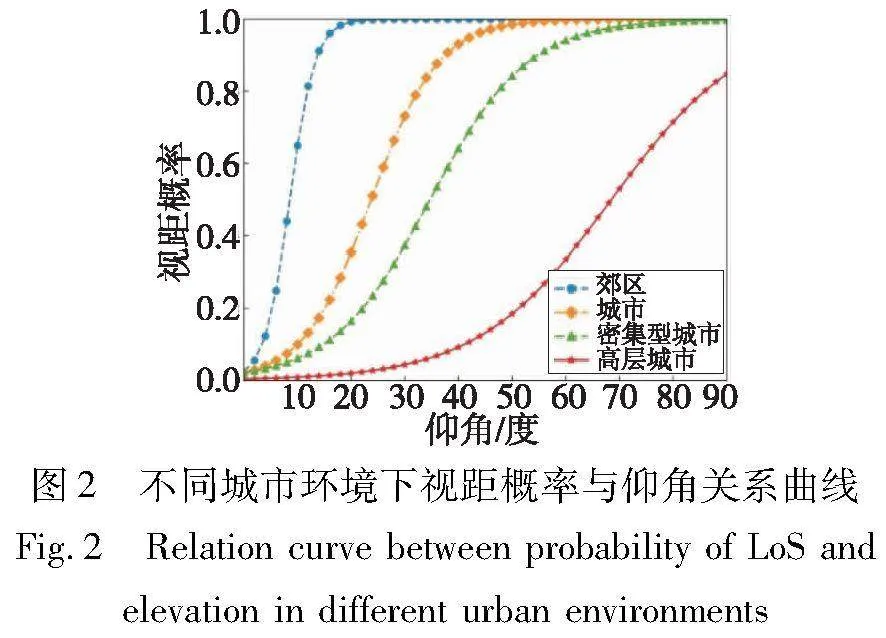
其中:dj,i表示第i簇节点对应的无人机与该簇内第j个节点间的水平距离;a、b是由环境决定的经验参数,Al-Hourani等人[20]通过数据拟合方法得到在不同城市环境下的参数a和b的具体数值。不同情景下,视距链路概率与地面节点到无人机仰角θj,i=hu,i/dj,i的对应关系如图2所示。观察可知,视距概率PLoSj,i是关于仰角θj,i的非凸非凹函数[21],仰角相同时,郊区因其建筑物密度、高度低,而具有更高的视距概率。因此,在不同的灾害场景下可以根据具体应用场景结合感知技术人为或机器自主地选择不同的参数值带入信道模型。
为简化计算,考虑无人机与节点之间LoS传输占主导地位,则无人机ui与其覆盖地节点之间的信道增益gj,i可以表示为
其中:ζ0表示单位参考距离下的信道增益,令P(i)j表示被无人机ui覆盖的第j个节点的发射功率,那么无人机与节点之间的上行链路数据速率vj,i可以表示为
其中:σ2是高斯噪声的方差;SNR表示节点到无人机上行链路的信噪比;Pj,i是第j个节点向为其服务的无人机ui发送数据的功率。
1.3 问题描述
无人机的电量远高于所有节点剩余电量的最大值,且可以自如飞行至灾区外充电站充电或更换电池,所以在考虑功耗优化时,认为无人机的电量足够使其完成任务,重点考虑在保证较高传输速率下如何尽可能降低节点发射功率,延长节点寿命,以保证每个节点所持有数据的完整发送,提升网络上行链路中节点的能源效率。
在QoS约束下,提出保证无人机对节点覆盖率的同时,通过调整无人机部署位置和节点发射功率来优化节点向无人机传输灾害信息时的能源效率,将其表示为最大化每架无人机覆盖下节点使用单位发射能量所能发射的最大数据量,用Ej,i表示无人机ui覆盖下第j个地面传感器节点向ui传输数据消耗的能量,Wj,i表示同一场景下节点向ui传输的数据总量,则优化问题可以表达为P1:
其中:式(12)可以看做节点消耗单位能量所发送的平均数据量,可以作为节点能源效率的一种度量方式;约束式(12a)(12b)分别为QoS中对传输速率、信噪比的要求;式(12c)是对无人机高度的约束;式(12d)是对节点发射功率的约束,保证其不高于最大额定功率Pmax;式(12e)是对任意时刻无人机接入节点数量的约束;式(12f)保证无人机不飞出需要收集灾害信息的受灾圆域。
将无人机ui与其覆盖下第j个地面传感器节点的数据传输时间记作tj,i,式(12)分子分母同时除以tj,i,优化问题P1可以转换为P2:
本文目标是通过优化无人机的3D悬停位置来均衡无人机对节点的覆盖率、节点发送数据的能源效率,由于无人机群之间存在协作关系,故将无人机群与地面节点所组成的系统作为操作和优化对象,避免单独地优化个体可能出现极端自私行为。那么在任意时刻t,在保证对节点覆盖率的前提下,最大化地面无线传感器网络系统整体的能源效率以延长网络在恶劣环境下的寿命更加科学合理,于是将P2转换成P3。
问题式(14)是非凸的,具有多个局部最优解,使用传统的数学方法求解难度极高。而灾害场景下,环境复杂多变,任一时刻地面网络节点的分布、电量、能效受环境变化的影响极大,因此可以将上述重要变量的状态转换过程建模为马尔可夫随机过程(Markov random processes,MRPs),这种情况下,往往希望用于灾害信息收集的无人机有自主学习能力,能根据不同的环境状态主动调整部署策略,进行自适应部署及性能优化。深度强化学习具备强大的环境感知和决策能力,能够在与环境不断的交互过程中学习并不断优化智能体的动作策略,适用于所研究的复杂多变灾害场景下无人机部署问题。结合场景需求,本文在传统的DRL算法中改进和加入计算技巧,首次将深度强化学习算法用于灾害场景下无人机进行信息收集任务时的节点能效优化问题。
2 基于MAFD-CPER-DDQN的传感器网络节点能效优化
深度强化学习以MDPs为数学理论基础,将深度学习(deep learning,DL)的环境感知能力与强化学习(reinforcement learning,RL)的决策处理能力相结合,用于解决智能体的贯序决策问题[22]。在面对复杂的状态空间和时变问题时,具备从原始高维数据中学习的强大能力,表现出良好的性能,在自动驾驶、通感一体、边缘计算、自然语言处理等高复杂度无人系统中得到了广泛的应用。
2.1 DRL算法族选择与场景契合度分析
在无人机自适应部署领域,以各种不同性能指标为优化目标的灾害场景下无人机部署问题可以建模为一系列马尔可夫决策过程,借由无人机智能体与环境进行交互,以环境状态空间作为输入,智能体提取状态特征映射输出策略或动作,对此策略或动作进行奖励或惩罚来指导或修正其作出决策,重复上述步骤,以最大化累积奖励为目标,训练智能体使其能根据不同环境特点作出对应的合理行为组合逻辑,即从观察到动作的映射,形成一个完整的决策。一个回合(episode)训练中,智能体观测到的所有的状态、动作、奖励,称为轨迹(trajectoty),具体如图3所示。
无外界干预状态下,无人机部署时的飞行动作是连续的无限集合。DRL中的深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法[23,24]可用于处理连续动作空间,但是其训练时的复杂度以及对计算资源的要求较高,训练收敛速度缓慢,不能较好地满足灾害场景下无人机快速决策、部署的应用场景需要。所以,考虑将智能体的动作空间离散化,验证使用处理离散动作空间的DDQN算法能否更简单、高效地解决该问题。
在众多处理离散化动作空间的DRL算法中,深度 Q 网络(deep Q network,DQN)是一种网络结构较为简单且可扩展性较强的算法,其通过使用以贝尔曼方程为数学基础的时序差分(temporal difference,TD)方法来解决值函数估计问题,性能明显优于直接使用蒙特卡罗方法。但DQN的价值函数Q(s,a;w)是使用式(15)得出的动作估计下一时刻的动作价值,同时TD算法式(16)用到了自举方法,即用t+1时刻的估计值估计t时刻的值,而自举产生了正反馈,导致传统的DQN算法存在高估问题,产生机理如图4所示。同时由于DQN的高估是非均匀的,所以会导致智能体基于错误的价值估计作出错误的决策。
针对上述两大问题,本文使用已有的双重DQN(double DQN,DDQN)网络结构,以减轻自举产生的高估问题和提高算法的稳定性。
a)DDQN是在原有DQN网络Q(s,a;w)的基础上增加一个与之结构相同的网络Q(s,a;w-),后者称为目标网络,两者结构相同,网络参数不同,即w-≠w。一方面,在DDQN算法中,使用主网络选择动作控制智能体和收集经验,使用目标网络计算TD目标值,在DDQN中,目标网络的参数并不是与主网络同步更新,而是以一定频率进行更新,目标网络的参数w-更新频率往往低于主网络参数w,因此可以一定程度上减缓DQN算法的高估程度,在灾害场景下,减轻高估问题可以让无人机作出正确的决策。另一方面,使用两个网络来估计Q值,DDQN更易收敛,相对于传统的DQN算法更为稳定。在灾害场景下,无人机需要在复杂和危险的环境中操作,训练稳定性的提高能够确保智能体更好地适应各种情况,以更加平稳地传递经验,提高无人智能系统自主决策部署的自适应性。
b)由于灾区的环境趋于复杂,相较于DDPG方法, DDQN不需要面对DDPG中探索-利用(exploration-exploitation)的复杂连续空间,训练需要的数据数量相对较少,具有更高的样本效率,使用同等数量的学习样本DDQN方法更易于收敛,更容易在有限时间内给出合理、稳定的决策。因此,在对无人机的响应速度有较高要求的灾害场景下,使用DDQN算法更具有实际工程意义。
c)考虑到灾害发生的偶然性,用于训练无人机的样本数量相对受限,但对无人机部署高效性要求较高,对训练样本的高效利用就显得尤为重要。传统的经验回放方法将经验样本以相等的概率从缓冲区中进行随机采样,无法区分哪些经验对于学习更为重要。然而,在实际环境中,有些经验可能对学习有更大的贡献,值得更频繁地被采样。将优先经验回放(prio-ritized experience replay,PER)技术加入传统的DDQN算法中,并根据工程进行科学的合理的自定义对其改进,称为自定义经验回放优先级(customized prioritized experience replay,CPER)。在经验回放缓冲区中,每个经验样本被赋予一个优先级,每次按照经验样本优先级由高到低进行非均匀采样。在选取经验样本时,根据其优先级进行重要性采样,优先选择优先级高的样本被采样的概率更大,这样可以增加那些对学习性能有较大贡献的样本出现在训练过程中的次数。通过加入CPER技术,智能体能够更集中地学习那些具有较高优先级的经验样本,自定义的思想能增加算法的场景适度,提升算法对重要经验的学习效果,以提高算法的样本利用效率,达到提高算法的学习速度和性能的目的。文中结合实际应用场景,综合考量自定义优先级评价指标给经验池中的样本标定优先级。
d)多智能体系统中通常存在竞争和合作的关系。每个智能体可能试图最大化自身的利益,而不考虑整个系统的利益,这种竞争与合作的平衡关系会导致自私行为的出现,如单架无人机为了提高个别节点的能效从而无限接近节点牺牲覆盖率的自私行为。虽然A3C方法是解决分布式问题常用的方法,但是异步策略的加入会消耗无人机大量的计算资源和通信资源,在不同的应用场景中,算法稳定性和收敛速度不能得到保证。为了平衡智能体之间的竞争与合作关系,文中使用完全去中心化的多智能体深度学习(fully decentralized multi-agent deep reinforcement learning,MAFD-DRL)方法避免引入过多计算和通信复杂度,将合作机制从集中式的训练方式中分离出来并转移至分布式训练的奖励函数中,通过设计合适的奖励函数引入奖励信号,考虑整体系统的性能,鼓励智能体之间的合作。这样,当智能体采取能够促进整个系统性能的行为时,可以获得更多的奖励。这种奖励机制可以促使智能体更多地考虑整体利益,而不仅仅是个体利益,同时避免引入更高的复杂度和计算代价。
2.2 DRL算法要素与设计
所选深度强化学习算法涉及的关键要素及其定义如下。
a)智能体(agent)。深度强化学习算法中的学习者,通过与环境互动进行学习的实体。智能体的目标是通过观察环境的状态,采取适当的动作来最大化其在环境中获得的奖励。智能体在强化学习中通过学习经验改进自身策略,使其能够在特定任务中获得更高的奖励。该场景下,无人机是MADRL中的智能体,作为动作的发出者,通过与环境交互作出自身部署决策。
b)环境(environment)。环境是智能体与之交互的外部系统。智能体通过对环境观察并进行特征分析,采取行动,环境根据智能体执行的动作提供奖励或惩罚。该场景下将无人机位置、节点位置、节点电量构成的直接影响无人机智能体部署策略的外部系统视为环境。
c)状态(state)s。智能体从环境接收的数据。在该场景下指某一时刻无人机获取的所观测对象的数据,包括当前节点位置、剩余电量、传输能效以及无人机自身位置等具体数据。
d)状态空间(state space)Euclid Math OneSAp。状态空间是指在任意时间点,环境可能处于的所有可能状态的集合。由于无人机的3D位置决定了其与地面节点之间的距离Dj,i,由式(9)~(11)可知,在给定信噪比阈值SNRTH的情况下,Dj,i影响着节点的发射功率,所以无人机基站的3D位置是状态空间的关键组成部分。在每个时隙开始时,无人机会根据地面无线传感器节点的位置pu,i、剩余电量Er、当前节点能效EEj,i调整自身位置,因此无线传感器节点的位置和剩余电量也是状态空间的一部分,该系统的状态空间可以表示为:Euclid Math OneSAp={pu,i,Er,EEj,i}。
e)动作(action)a。智能体根据其对环境状态的观察所作出的决策或行动。该场景下指无人机具体飞行动作。
f)动作空间(action space)Euclid Math OneAAp。动作空间是指代智能体可以执行的所有可能动作的集合。考虑到连续的动作空间会导致训练收敛慢的问题,不满足应急场景需要,故将动作空间离散化用于智能体的训练,将三维直角坐标系中无人机的动作延
g)奖励函数(reward function)。在一个强化学习任务中,智能体在时间步t执行动作后,会得到一个即时奖励Rt。对应2.1节中第四点,合理设计奖励函数可以提高智能体处理合作-竞争关系的能力,此处结合具体应用场景,设计如下:
式(17)多项式中的第一项是针对单架无人机自身信息收集效率节点能源效率方面的奖励,与问题描述中的优化目标息息相关;第二项是针对全部无人机合作覆盖节点方面数量的奖励,可以加强无人机之间的合作,避免单架无人机为了提高第一项分数无限接近节点牺牲覆盖率等这类自私行为。
h)折扣回报(disconnected return)。是指在强化学习任务中,智能体在未来时间获得的奖励的总和,记作Gt,计算方式如下:
其中:γ是折扣因子,表示未来奖励对当前时刻回报的影响。
i)自定义经验回放优先级函数。对应2.1节中第三点,将经验回放优先级合理设计,提高经验利用效率。时间差分误差(temporal difference error,TDE)δt可以表示网络对动作价值评估的准确水平,δt越大,说明网络对该环境状态的学习越不充分,需要加强该部分学习,所以TDE可以用来衡量其优先级,TDE越大,优先级越高。其次,某一状态下作出的动作获得的奖励rt越低说明网络的决策越差,需要加强网络在该环境下作出优异动作的能力,所以,即时奖励越低,优先级越高。综上,经验回放优先级函数设计如下:
其中:φ与1-φ表示δt与rt在经验优先级中所占的权重;是rt负相关性调节指数。
2.3 基于MAFD-CPER-DDQN的节点能效优化方法算法
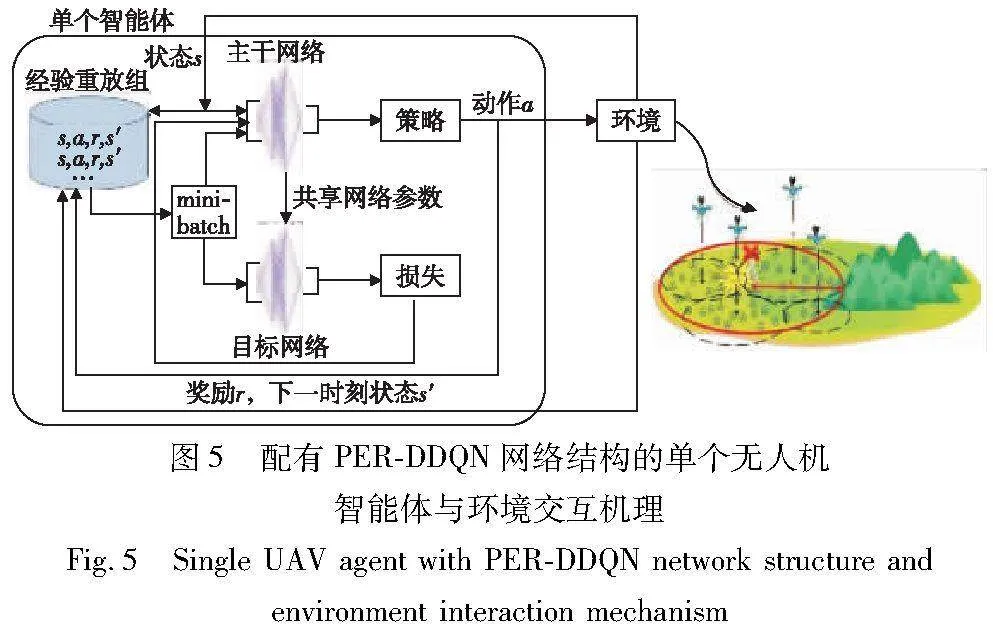
将DRL算法用于解决本文应用场景下的优化问题,通过合理拆分动作空间、设计奖励函数、自定义经验回放优先级函数,同时采用完全去中心化的多智能体强化学习方法,提出MAFD-CPER-DDQN无人机部署算法,详见算法1,网络结构见图5。
算法1 无人机自主部署算法
上述算法中,1行之前的内容是对算法中输入、输出、超参数的声明;1行表示初始化算法参数;2~21行表示智能体重复学习I个回合;3行表示在每个回合开始都要对外部环境状态进行初始化;4~20行表示智能体每个回合执行T步;在每一步中,5行是当前步执行迭代的条件,6~19行是每一步迭代要执行的内容;6行表示对当前环境状态的观察值;7行表示智能体使用ε-greedy策略根据6行中的状态和以往经验执行决策出的动作;8行表示此轮迭代是否达到最终状态的标志位;9~18行是根据8行中标志位判断是否已达到最终状态;9~16行代表如果未达到最终状态;10、11行表示进行观察值、奖励值的更新;12行表示使用TD target方法计算TD目标值;13行表示计算loss值;14行表示使用梯度下降法算法更新主网络参数;15行表示将六元组数据(st,at,rt,st+1,signal,priority)存入经验回放缓冲区;16行表示按照设定的频率和规则更新目标网络参数;17、18行表示如果当前达到的状态是最终状态,此轮迭代获得的奖励就是TD目标值。
3 仿真结果与分析
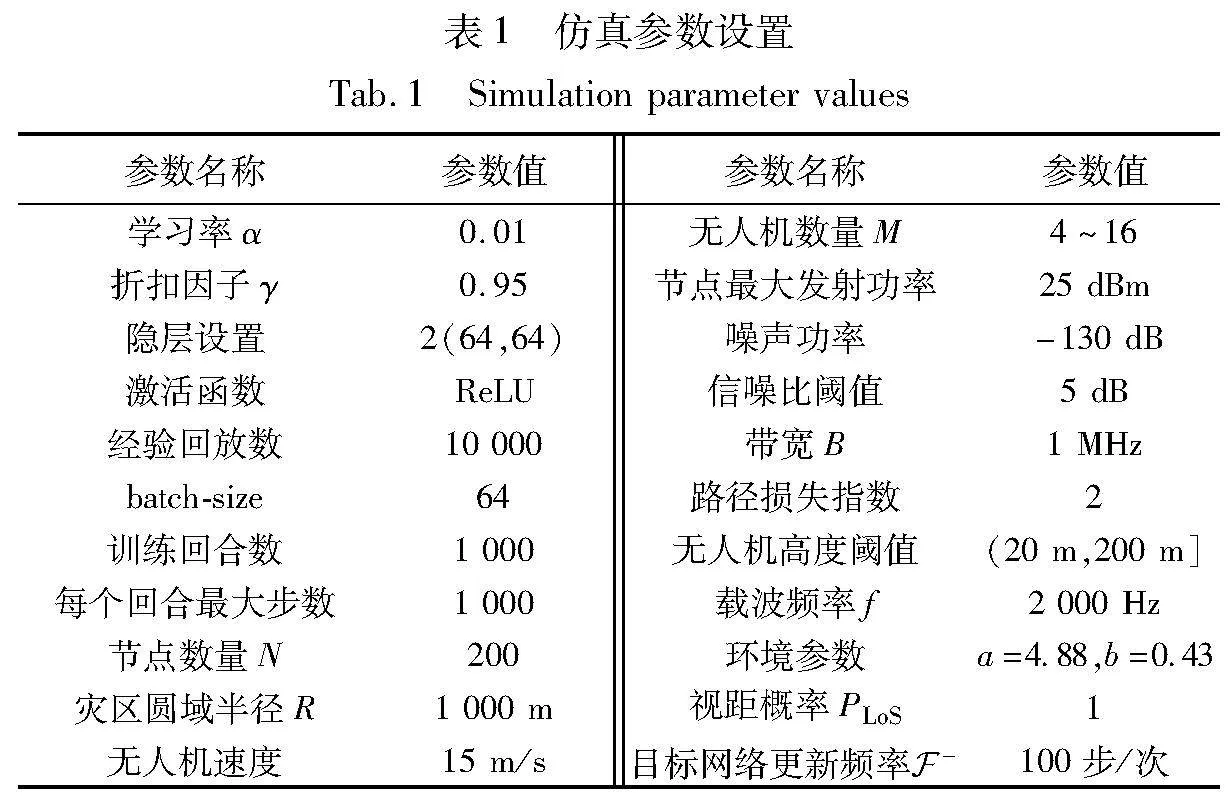
本章使用Python 3.10.6软件平台的TensorFlow 2.11.0框架,验证将所提MAFD-CPER-DDQN方法用于灾害场景下信息收集无人机部署及节点能效优化工作中的可行有效性、相比传统DDQN和DDPG两种基线算法的性能指标提升值、差异化应用场景下算法表现,仿真过程忽略了来自附近UAV小区的干扰。模拟参数如表1所示。
3.1 收敛性分析
对于灾害应急场景下所使用的MAFD-CPER-DDQN算法进行基本的可行性验证,运用此算法将智能训练1 000回合,从图6可以看出平均损失值在第600回合附近开始收敛,这说明奖励函数定义合理,将MAFD-CPER-DDQN算法应用于以优化节点能效为目标的灾害场景无人机自适应部署工作中是可行的。
3.2 性能指标对比分析
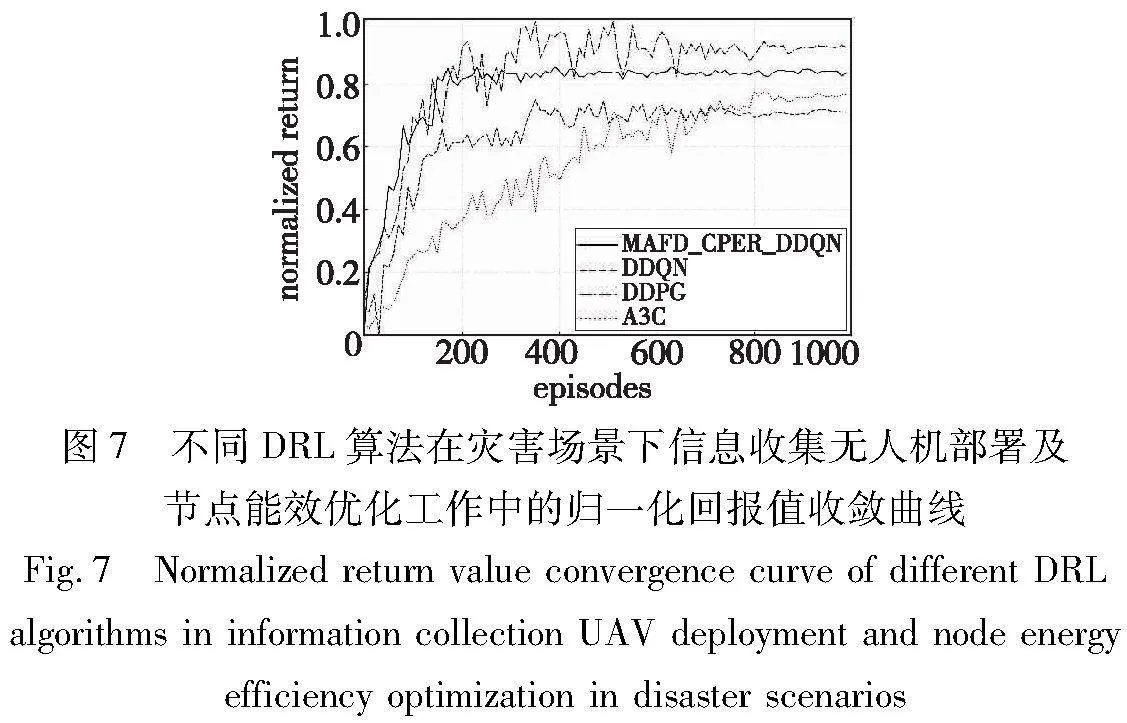
将MAFD-CPER-DDQN算法与以下DDQN、DDPG、A3C算法三种方法进行了对比实验。在控制输入相同的情况下,让智能体进行1 000回合训练,实验结果如图7所示。
从图7可以看出,所提MAFD-CPER-DDQN相比于DDQN、DDPG、A3C算法具有更快的收敛速度。a)DDPG方法处理的是连续动作空间,这使无人机对下一时刻采取动作的决策高维化、复杂化,选择的增加意味着需要更加优异的策略才能作出有利的动作,也意味着需要更加广泛的探索、更缓慢的收敛速度和更长的训练时间,而所提方法将无人机的动作空间离散化,有利于加快算法收敛速度;b)相比于传统的DDQN算法,所提算法加入了优先级经验回放技术,增加优先级较高经验的选择概率,在避免经验相关性的同时,能更加高效地利用训练经验数据;c)由于A3C算法中智能体的训练是异步的,训练过程具有更多的随机性,不同的智能体可能经历不同的轨迹并在不同的时间更新网络,增加了训练过程的不稳定性和随机性,所以需要更多的训练步骤才能获得稳定可靠的策略,而相对于A3C网络,所提算法使用完全去中心化的分布式训练-分布式执行的策略,使其不仅可以用于分布式计算,而且将智能体之间的竞争-合作关系完全量化并定义到奖励函数中,避免了引入额外的同步复杂性、智能体间通信带来的时间和计算开销,因此智能体的训练过程能更加快速地收敛。
所提MAFD-CPER-DDQN相比于DDQN和DDPG算法具有更强的稳定性,整个训练过相对平稳,这是因为优先经验回放技术的加入让智能体有更高的概率去选择损失函数值较大的经验进行学习,增加在决策质量不高场景下的训练次数,因此智能体获得的累积奖励随决策质量的提升而稳步提升。相比之下,传统的DDPG和DDQN算法没有加入经验回放技术,每次的训练数据都会在更新参数之后丢弃,且DDPG算法对庞大连续动作空间的探索更加剧了其非平稳特性。
所提MAFD-CPER-DDQN算法相比于DDQN能获得更高的回报,这是由于经验回放技术放大了双DQN网络的优势,使DDQN算法主网络的学习范围从当前一条训练数据变成了一批次训练经验数据,对训练历史数据进行了更为高效的利用,更有利于跳出局部最优去作出更好的决策控制无人机的部署。与DDPG算法相比,能获得的最终回报偏低,这是由于动作空间的离散化降低了无人机位移的精度,使无人机很难精确探索到使长期累积奖励最大的3D位置。
所提MAFD-CPER-DDQN相比于DDPG、A3C算法能够节省更多的计算时间,相比于DDQN能使智能体获得更高的奖励。上述两种指标之间存在冲突,由于应用场景的特殊性,既不能一味追求奖励最大化忽略灾害场景下时间的重要性,也不能过度追求快速性忽略了无人机部署质量对地面节点能效的影响。选择、改进和使用传统的DDQN算法是对动作空间离散化和连续化下深度强化学习性能的折中,达到统筹兼顾训练效率和训练质量的目的。从图7可以看出,使用所提MAFD-CPER-DDQN算法应用于以提高节点能效为优化目标的灾害场景下无人机部署工作,整体节点能源效率、学习过程收敛速度比DDQN算法分别提高了21%和17%;所提算法在回报仅低于DDPG算法9%的情况下,智能体训练收敛速度比DDPG算法提升42%;所提算法的收敛速度比A3C方法提升34%:兼顾了灾害应急场景下高时效、高质量的无人机部署要求。
3.3 差异化应用场景对比分析
分别对比以评估不同数量的无人机部署对地面节点能源效率总和的影响。仿真模拟了不同数量(4、10、16架)的无人机为半径1 000 m的圆形区域内的静态无线传感器网络节点提供服务时的部署算法收敛曲线,仿真结果如图8所示。
从图8可以看出,当无人机数量较少时,智能体的学习回报曲线收敛速度较慢,地面系统所能达到的最大能效也较低;反之,无人机数量越多,学习回报曲线收敛速度越快,所能达到的最大回报也较高。这是因为智能体数量较少时,单架无人机到最佳部署点需要的平均位移较大,贯序决策中包含的的单步决策数量较多,因此收敛速度较慢,当无人机数量增加时,每架无人机接入的节点数量变少,单架无人机到最佳部署点需要的平均位移变小,在平均速度不变的情况下,无人机需要作出的决策数量变少,收敛速度加快。此外,无人机较少时,所能达到的最大回报较低,这是因为无人机的数量和覆盖面积限制了其对节点覆盖率与节点能效的兼顾能力,由于在奖励函数中赋予节点能效项的权重较大,较少的无人机在提高节点能效的情况下就牺牲了对一部分节点的覆盖率。但是随着无人机数量的增加,其对节点覆盖率与节点能效的兼顾能力得到提高,因此,所能达到的最大回报有所升高。但是当无人机数量继续增加时,回报不再增值明显放慢,这意味着当前灾区范围内,无人机数量已达到饱和,增加无人机数量对回报的提升已经几乎不起作用,反而会造成无人机资源的浪费。
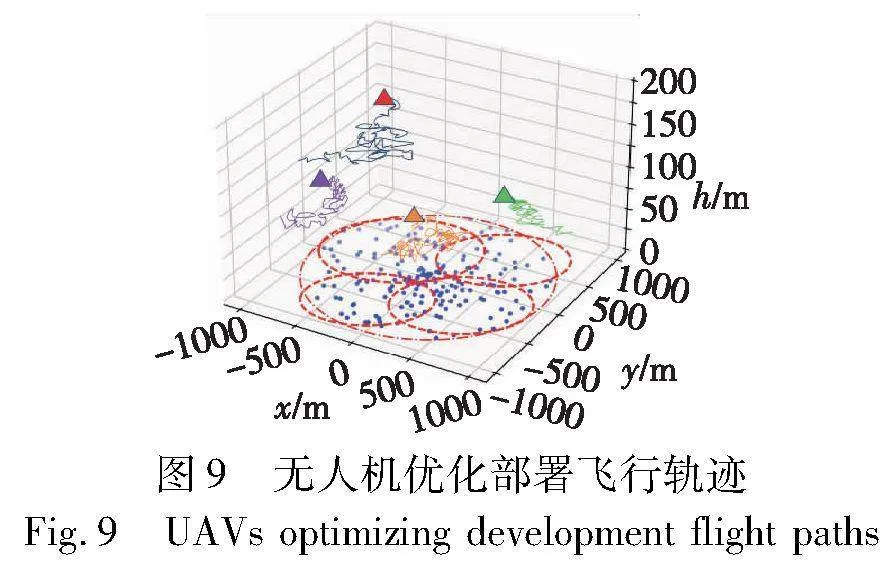
以4架无人机的部署为例,其部署过程中的飞行轨迹如图9所示。图9可以看出,根据地面节点的地理分布及其具体情况,无人机的高度以及覆盖范围各不相同,符合自适应部署的要求。无人机之间的覆盖区域存在重叠,部署高度更低的无人机认为应为该区域内的节点提供更加高能效、高可靠性的服务,但是这难免增加了UAV小区间的干扰。同时,可以看出对于少部分边缘节点的覆盖并不完善,此时无人机的数量尚未达到饱和,仍可通过增加无人机数量提高回报。
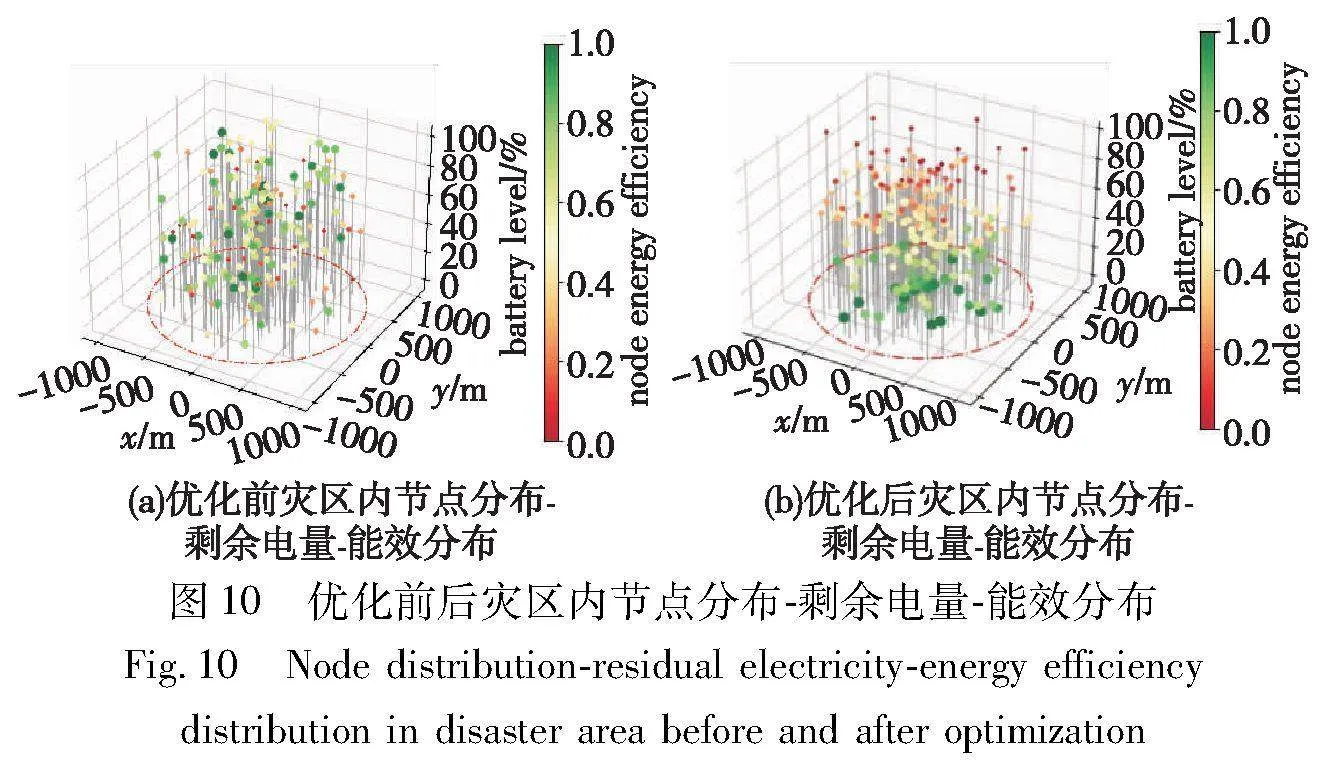
3.4 优化效果对比
将所提MAFD-CPER-DDQN算法用于以提高节点能效为优化目标的无人机自适应部署工作中,算法使用前后,分别生成地面节点剩余电量-能效图,以更为直观的方式展示该场景下使用所提算法的效果及意义,具体如图10所示。图10中:节点全部处于同一水平面,xOy面描述其水平面上的二维坐标,z轴正方向表示节点当前剩余电量,3D坐标位置处的圆点的颜色表示节点当前时刻的能源效率,颜色由红至绿表示节点能效由低到高,为方便观察,将节点能效也与圆点大小对应起来,由小到大亦可表示节点能效由低到高。
从图10可以看出,起初节点的能源效率是依据无人机的随机初始化杂乱分布的,使用所提算法让无人机进行学习后,较高的能效被分配在剩余电量较低的节点处,而剩余电量较高的节点处能效大都较低。这也意味着,无人机在更靠近剩余电量低的区域部署密度越大、飞行高度越低。
4 结束语
所提算法用于以提升地面节点能源效率为优化目标的灾害场景无人机辅助信息收集工作中,填补了灾害场景下无人机部署领域以优化节点能效优化为导向的空白。在所提特定场景下,整体节点能源效率、学习过程收敛速度比DDQN算法分别提高了21%和17%,在长期收益仅低于DDPG算法9%的情况下,智能体学习过程的收敛速度比DDPG算法提升42%,比A3C方法提升34%,兼顾了灾害应急场景下高时效、高质量的无人机自适应部署要求。
在未来的研究工作中:a)将会综合考虑异构物联网节点的移动性和无人机在收集灾害信息过程中的小范围可移动性;b)将考虑不同灾害场景对智能体响应时长、智能体部署精度等不同方面的需求,在训练之前加入算法可选模块,使应急系统更加智能地按需部署;c)考虑将无人机载具与基于深度强化学习算法的边缘计算[25,26]、可重构智能超表面[27~29]结合起来,为灾害场景下的计算、通信等应急服务提供更多解决方案。
参考文献:
[1]Kargel J, Leonard G, Dan S, et al. Geomorphic and geologic controls of geohazards induced by Nepal’s 2015 Gorkha earthquake[J]. Science, 2016, 351(6269):8353.
[2]Jia Min, Gu Xuemai, Guo Qing, et al. Broadband hybrid satellite-terrestrial communication systems based on cognitive radio toward 5G[J]. IEEE Wireless Communications, 2016,23(6): 96-106.
[3]Nishiyama H, Ito M, Kato N. Relay-by-smartphone: realizing multihop device-to-device communications[J]. IEEE Communications Magazine, 2014, 52(4): 56-65.
[4]Taleb T, Hadjadj-Aoul Y, Ahmed T. Challenges, opportunities, and solutions for converged satellite and terrestrial networks[J]. IEEE Wireless Communications, 2011,18(1): 46-52.
[5]Tan D D, Long D N, Duong T Q, et al. Joint optimisation of real-time deployment and resource allocation for UAV-aided disaster emergency communications[J]. IEEE Journal on Selected Areas in Communications, 2021,36(11): 3411-3424.
[6]Zeng Yong, Zhang Rui, Lim T J, et al. Wireless communications with unmanned aerial vehicles: opportunities and challenges[J]. IEEE Communications Magazine, 2016,54(5): 36-42.
[7]Zhao Nan, Lu Weidang, Sheng Min, et al. UAV-assisted emergency networks in disasters[J]. IEEE Wireless Communications, 2019,26(1): 45-51.
[8]Liu Miao, Yang Jie, Gui Guan. DSF-NOMA: UAV-assisted emergency communication technology in a heterogeneous Internet of Things[J]. IEEE Internet of Things Journal, 2019,6(3): 5508-5519.
[9]Barick S, Singhal C. Multi-UAV assisted IoT NOMA uplink communication system for disaster scenario[J]. IEEE Access, 2022,10: 34058-34068.
[10]Lin Na, Liu Yuheng, Zhao Liang, et al. An adaptive UAV deployment scheme for emergency networking[J]. IEEE Trans on Wireless Communications, 2022, 21(4): 2383-2398.
[11]李斌, 彭思聪, 费泽松. 基于边缘计算的无人机通感融合网络波束成形与资源优化[J]. 通信学报, 2023,44(9): 228-237. (Li Bin, Peng Sicong, Fei Zesong. Multi-agent reinforcement learning-based task offloading for multi-UAV edge computing[J]. Journal on Communications, 2023, 44(9): 228-237.)
[12]李斌. 基于多智能体强化学习的多无人机边缘计算任务卸载[J]. 无线电工程, 2023,53(12): 2731-2740. (Li Bin. Multi-agent reinforcement learning-based task offloading for multi-UAV edge computing[J]. Radio Engineering, 2023, 53(12): 2731-2740.)
[13]Wu Guanhan, Jia Weimin, Zhao Jianwei. Dynamic deployment of multi-UAV base stations with deep reinforcement learning[J]. Electronics Letters, 2021, 57(15): 600-602.
[14]Ma Xiaoyong, Hu Shuting, Zhou Danyang, et al. Adaptive deployment of UAV-aided networks based on hybrid deep reinforcement learning[C]//Proc of the 92nd Vehicular Technology Conference. Piscataway, NJ: IEEE Press, 2020: 1-6.
[15]周毅, 马晓勇, 郜富晓, 等. 基于深度强化学习的无人机自主部署及能效优化策略[J]. 物联网学报, 2019,3(2): 47-55. (Zhou Yi, Ma Xiaoyong, Gao Fuxiao, et al. Autonomous deployment and energy efficiency optimization strategy of UAV based on deep reinforcement learning[J]. Chinese Journal on Internet of Things, 2019,3(2): 47-55.)
[16]Liu C H, Chen Zheyu, Tang Jian, et al. Energy-efficient UAV control for effective and fair communication coverage: a deep reinforcement learning approach[J]. IEEE Journal on Selected Areas in Communications, 2018, 36(9): 2059-2070.
[17]Liu C H,Ma Xiaoxin,Gao Xudong,et al. Distributed energy-efficient multi-UAV navigation for long-term communication coverage by deep reinforcement learning[J]. IEEE Trans on Mobile Computing, 2020,19(6): 1274-1285.
[18]Omoniwa B, Galkin B, Dusparic I. Optimizing energy efficiency in UAV-assisted networks using deep reinforcement learning[J]. IEEE Wireless Communications Letters, 2022,11(8): 1590-1594.
[19]王海涛. 基于无线自组网的应急通信技术[M]. 北京: 电子工业出版社, 2015: 76. (Wang Haitao. Emergency communication technology based on wireless Ad hoc network[M]. Beijing: Publishing House of Electronics Industry, 2015: 76.)
[20]Al-Hourani A, Kandeepan S, Lardner S. Optimal LAP altitude for maximum coverage[J]. IEEE Wireless Communications Letters, 2014,3(6): 569-572.
[21]王雷. 无人机中继通信链路性能分析与资源分配技术研究[D]. 北京: 北京邮电大学, 2022. (Wang Lei. Research on link perfor-mance analysis and resource allocation technology of UAV relaying communications[D]. Beijing: Beijing University of Posts and Telecommunications, 2022.)
[22]高扬, 叶振斌. 白话强化学习与PyTorch[M]. 北京: 电子工业出版社, 2019: 7. (Gao Yang, Ye Zhenbin. Reinforcement learning PyTorch[M]. Beijing: Publishing House of Electronics Industry, 2019: 7.)
[23]Silver D, Lever G, Heess N, et al. Deterministic policy gradient algorithms[C]//Proc of the 31st International Conference on Machine Learning. [S.l.]: JMLR.org, 2014: 387-395.
[24]Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[EB/OL]. (2015-09-09) [2023-09-05]. https://arxiv.org/abs1509.02971.
[25]米德昌, 王霄, 李梦丽, 等. 灾害应急场景下基于多智能体深度强化学习的任务卸载策略[J]. 计算机应用研究, 2023,40(12): 3766-3771,3777. (Mi Dechang, Wang Xiao, Li Mengli, et al. Multi-intelligence deep reinforcement learning-based task offloading strategy for disaster emergency scenarios[J]. Application Research of Computers, 2023,40(12): 3766-3771,3777.)
[26]李斌, 刘文帅, 谢万城, 等. 智能反射面赋能无人机边缘网络计算卸载方案[J]. 通信学报, 2022,43(10): 223-233. (Li Bin, Liu Wenshuai, Xie Wancheng, et al. Partial computation offloading for double-RIS assisted multi-user mobile edge computing networks[J]. Journal on Communications, 2022,43(10): 223-233.)
[27]Liu Xiao, Liu Yuanwei, Chen Yue. Machine learning empowered trajectory and passive beamforming design in UAV-RIS wireless networks[J]. IEEE Journal on Selected Areas in Communications, 2020,39(7): 2042-2055.
[28]Zhong Ruikang, Mu Xidong, Liu Yuanwei, et al. STAR-RISs assisted NOMA networks: a distributed learning approach[J]. IEEE Journal of Selected Topics in Signal Processing, 2023,17(1): 264-278.
[29]Nguyen T H, Park H, Park L. Recent studies on deep reinforcement learning in RIS-UAV communication networks [C]//Proc of International Conference on Artificial Intelligence in Information and Communication. Piscataway, NJ: IEEE Press, 2023: 378-381.
