基于全局与序列变分自编码的图像描述生成
2024-08-17刘明明刘浩王栋张海燕


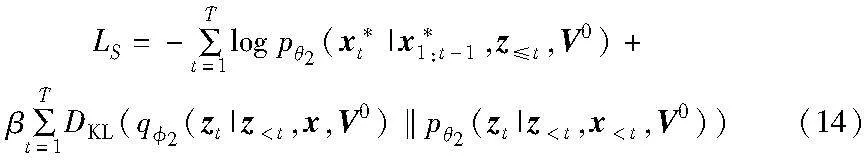




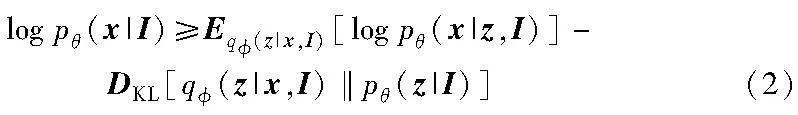





摘 要:基于Transformer架构的图像描述生成方法通常学习从图像空间到文本空间的确定性映射,以提高预测“平均”描述语句的性能,从而导致模型倾向于生成常见的单词和重复的短语,即所谓的模式坍塌问题。为此,将条件变分自编码与基于Transformer的图像描述生成相结合,利用条件似然的变分证据下界分别构建了句子级和单词级的多样化图像描述生成模型,通过引入全局与序列隐嵌入学习增强模型的隐表示能力。在MSCOCO基准数据集上的定量和定性实验结果表明,两种模型均具备图像到文本空间的一对多映射能力。相比于目前最新的方法COS-CVAE(diverse image captioning with context-object split latent spaces),在随机生成20个描述语句时,准确性指标CIDEr和多样性指标Div-2分别提升了1.3和33%,在随机生成100个描述语句的情况下,CIDEr和Div-2分别提升了11.4和14%,所提方法能够更好地拟合真实描述分布,在多样性和准确性之间取得了更好的平衡。
关键词:图像描述生成;多样化描述;变分Transformer;隐嵌入
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)07-042-2215-06
doi: 10.19734/j.issn.1001-3695.2023.09.0510
Diverse image description generation via global andsequential latent embedding
Abstract: The Transformer-based image captioning models have shown remarkable performance based on the powerful sequence modeling capability. However, most of them focus only on learning deterministic mappings from image space to caption space, i. e., learning how to improve the accuracy of predicting “average” captions, which generally tends to common words, repeated phrases and single sentence, leading to the severe mode collapse problem. To this end, this paper combined the conditional variational encoder with the Transformer-based image captioning model, and proposed the sentence-level and word-level diverse image captioning models, respectively. The proposed models introduced the global and sequential latent embedding learning based on the evidence lower bound(ELBO), which promoted the diversity of Transformer-based image captioning. Quantitative and qualitative experiments on MSCOCO dataset show that both models have the ability of learning one-to-many projections between the image space and the caption space. Compared with the state-of-the-art COS-CVAE, the proposed method with 20 samples improves the CIDEr and Div-2 scores by 1.3 and 33% respectively in the case of 20 samples, improves the CIDEr and Div-2 scores by 11.4 and 14%, respectively in the case of 100 samples. The proposed method can fit the distribution of ground-truth captions well, and achieve a better balance between diversity and accuracy.
Key words:image description generation; diverse image captioning; variational Transformer; latent embedding
0 引言
图像描述生成是一项具有挑战性的条件生成任务,旨在生成语法正确且与图像相对应的描述语句,在图像理解领域引起了极大的关注。近几年,随着深度学习技术的兴起,受神经机器翻译启发的编解码(encoder-decoder)框架在图像描述领域中被广泛采用,其中卷积神经网络(convolutional neural networks,CNN)作为编码器提取图像特征,解码器则采用循环神经网络(recurrent neural network models, RNN),将图像特征解码成对应的描述[1~4],或者直接采用Transformer模型实现整个编码器解码器架构。这些方法在一些准确性评价指标上(例如BLEU[5]、ROUGE-L[6]、CIDEr[7]),性能取得了显著提升。然而,现有模型大多关注从图像空间到文本空间的确定性映射,导致严重的模式坍塌问题。流行的Updown[8]和Transformer[9]图像描述模型均倾向于生成重复的短语和句子,无法保证描述的多样性。为了解决模式坍塌问题,最近一些研究者开始探索多样化的图像描述生成方法。这些工作通常将生成对抗网络(generative adversarial network, GAN)[10]或者变分自编码器(variational auto encoders,VAE)[11]引入图像描述生成模型[12,13],从而赋予模型一对多映射的能力。尽管基于GAN的图像描述模型可以有效提高句子多样性,但是这种模型很难兼顾句子的准确性指标。现有的基于条件变分自编码器的图像描述模型在多样性和准确性之间取得了一个较好的平衡。然而,这些模型大多基于传统的长短时期记忆网络(long short term memory, LSTM)构建,导致不能充分利用图像和文本的全局信息,以及无法提供并行训练支撑。
针对上述存在的问题,本文将条件变分自编码引入基于Transformer的图像描述框架,提出一种新的图像多样化描述生成模型。利用条件似然的变分证据下界,通过引入全局与序列隐嵌入学习,分别提出了句子级和单词级的多样化图像描述生成方法。首先,本文结合条件变分自编码和Transformer模型,提出一种句子级的变分Transformer图像描述模型,通过全局隐空间捕获句子级多样性。然后,将全局隐空间拓展为序列隐空间,提出一种单词级的条件变分Transformer图像描述模型,通过序列隐空间捕获单词级多样性。如图1所示,本文方法具备从图像空间到文本空间的一对多映射能力。在MSCOCO标准数据集上,针对所提出的两种模型和对比方法进行了充分的定量和定性实验对比分析,验证了本文方法的有效性。
本文的主要贡献包括以下三个方面:
a)设计了一种新颖的基于条件变分Transformer架构的句子级图像多样化描述框架,支持从图像空间到文本空间的一对多映射;
b)将句子级条件变分Transformer框架拓展为单词级图像多样化描述生成模型,通过单词级多样性的隐空间嵌入同时提升描述的准确性和多样性;
c)实现了端到端的图像多样化描述模型训练,并在MSCOCO公开数据集上进行了大量的实验验证,实验结果表明,本文方法在多样性和准确性指标上均显著优于现有的多样化图像描述方法。
1 相关工作
传统的图像描述生成模型通常生成输入图像的单一描述,聚焦描述语句的准确性指标。例如,李志欣等人[14]提出结合视觉特征和场景语义的图像描述生成方法,利用潜在狄利克雷分布模型与多层感知机提取图像场景语义相关的主题词,通过主题词指导单词的准确生成。周东明等人[15]提出基于强化学习的多层级视觉融合网络模型,通过将视觉特征转换为视觉知识的特征集,从而生成更加流畅的描述语句。刘茂福等人[16]利用视觉关联与上下文双注意力机制,指导生成准确的图像描述文本。宋井宽等人[17]通过视觉区域聚合与双向协作学习,以促进模型生成更加细粒度的图像描述文本。尽管这些模型有效提升了图像描述的准确性,但模型仍未从根本上解决确定性映射导致的模式坍塌问题,无法生成多样化的描述语句。
最近,多样化图像描述生成逐渐成为本领域的研究热点。Dai等人[18]首次提出了一种基于条件生成对抗网络(CGAN)的图像多样化描述生成框架,其中生成器采用编解码架构,解码器所生成的描述再传入至判别器中进行判别。随后在联合交替训练生成器和判别器的同时,通过在生成器端输入随机噪声来实现生成描述语句的多样化。Shetty等人[19]也基于生成对抗网络提出了更进一步提高语义多样化的模型。该方法将对抗样本与近似耿贝尔采样[20]相结合,用于图像描述的训练中,使得生成的描述语句更贴近于人类标注的真实标签。尽管基于生成对抗网络的图像多样化描述方法可以有效提升生成描述的多样化,但该类方法生成的描述与真实描述之间差异较大,精确性指标较低,且存在难以平衡生成器和判别器联合训练的问题。
为了兼顾图像描述的准确性和多样性,基于条件变分自编码的图像多样化描述方法逐渐成为主流。Wang等人[21]首次将条件变分自编码引入到图像多样化描述生成任务中,不同于以往常见的采用固定高斯先验的方式,该方法使用加性高斯先验增加模型对于不同图像生成描述的可变性,由此提升模型生成多样化描述的性能。Aneja等人[22]为了提升模型的细粒度描述能力,提出了基于序列化隐空间的条件变分自编码(sequential conditional CVAE, Seq-CVAE)方法,该方法通过对逐个单词的隐空间建模,实现对单词级的多样化控制,并通过双向循环神经网络和意图模型分别实现训练和测试阶段的多样化保证。Mahajan等人[23]在Seq-CVAE的基础上采用伪监督方式对数据集扩充,然后分别对数据集中描述文本的上下文和目标进行建模,以提升多样性。 Xu等人[24]进一步结合双层对比学习缓解了交叉熵损失导致的模型坍塌问题。Deshpande等人[25]通过引入词性标注信息提升多样化图像描述生成性能。与此同时,针对多样化描述的相关评价指标也被相继提出。Wang等人[26]提出了依赖于潜在语义分析(latent semantic analysis,LSA)方法的多样性评价指标Self-CIDEr。 2021年,Shi等人[27]通过与强化学习相结合提出了多样性评价指标max-CIDEr,由此提升了模型生成多样化描述的能力。2022年,基于自评价序列训练(self-critical sequence training,SCST)[28],Wang等人[29]提出了与检索奖励相结合的多样性评价指标CIDErBtw,该方法能够促使模型生成的描述语句更具备多样化的特点。
然而,上述基于变分自编码的图像描述生成方法大多基于LSTM构建,受限于LSTM的序列化建模局限性,这些方法未能引入自注意力机制充分建模图像和文本全局特征,也无法通过交叉注意力实现图像与文本两种模态的交互对齐。此外,这类模型不支持并行训练,这些问题严重制约了多样化图像描述生成性能的进一步提升。为此,本文探索如何在Transformer框架下构建多样化图像描述生成模型,以获得更优的描述准确性和多样性。
2 方法
本章首先介绍条件变分自编码及变分证据下界,然后基于变分证据下界构建句子级的全局变分Transformer多样化图像描述生成模型。最后进一步拓展全局变分Transformer框架,提出了一种基于序列变分Transformer的多样化图像描述生成模型。
2.1 基于全局变分Transformer的多样化图像描述生成模型
对于图像描述这种条件生成任务,大多数基于Transformer的模型无法针对一张图像生成多个描述xk,k∈{1,…,K},即无法建模图像与描述之间的一对多映射。受到条件变分自编码的启发,拟将条件变分自编码引入Transformer模型,以拓展其多样化描述生成能力。具体地,假设I表示图像视觉特征,x表示生成的描述,θ为模型参数。通过引入全局隐变量z,则条件概率分布pθ(x|I)表示如下:
pθ(x|I)=∑p(x,z|I)=∑p(x|z,I)p(z|I)(1)
为优化式(1),引入后验概率分布q(z|x,I),则条件概率分布pθ(x|I)的log似然变分证据下界公式可表示为
为了优化式(2)中的变分证据下界,需要分别将后验q(z|x,I)、先验pθ(z|I)以及条件分布pθ(x|z,I)参数转换为神经子网络。如图1所示,面向多样化图像描述生成,构建一种基于全局隐嵌入的条件变分Transformer模型(global conditional variational Transformer for image captioning, GCV-T-IC)。GCV-T-IC模型由后验推断分支网络q(z|x,I)、先验分支网络pθ(z|I)以及解码网络pθ(x|z,I)构成,其中后验推断分支网络和先验分支网络组成了双分支的编码网络,具体描述如下:
其中:MSA表示多头自注意力(multi-head self-attention)模块;AN表示残差归一化(add&layer norm)模块;FFN表示前馈网络层(feed forward network)。
为了抽取图像和描述的全局特征表示,引入一个可学习向量作为查询向量,并通过交叉注意力(cross-attention, CA)模块自适应地将非固定长度的向量融合为单一向量,具体如下:
b)解码网络。
GCV-T-IC的解码网络pθ(x|I,z)与Transformer解码器结构类似,但隐嵌入变量z需要与描述语句每个单词的词嵌入向量进行逐个拼接作为解码网络输入。输入特征首先经过线性层降维,然后利用MSA和AN模块提取文本语义特征,并与图像视觉特征VN一同输入一个CA模块,利用交叉注意力获得加权视觉特征。依次经过AN与FFN层与文本语义特征进行融合。最后通过线性层和softmax操作预测词汇表中单词出现的概率。
2.2 基于序列变分Transformer的多样化图像描述生成模型
在句子级的全局变分Transformer模型基础上,进一步将其拓展为单词级的序列变分Transformer,以提升模型的多样化
基于式(7),通过最大化条件分布pθ(x|I)的对数似然,可以得到以下基于时间步的变分证据下界:
1)后验推断子网络
在后验推断子网络中,首先将单词嵌入后的向量进行位置编码得到输入向量W0。随后,将其输入多头自注意模块MSA并经过AN层可得
Wq=AN(MSA(W0,W0,W0)+W0)(9)
紧接着,通过多头交叉注意模块和残差归一化层将文本特征Wq与视觉特征VN进行融合,混合特征Fq表示为
Fq=AN(CA(Wq,VN,VN)+Wq)(10)
2.3 训练与推断方法
如前所述,全局和序列变分Transformer模型均使用相应的ELBO变分证据下界作为优化目标函数,具体地,已知图像视觉特征V0和对应的成对描述句子x*={x*0,x*1,…,x*T}。基于全局变分Transformer的多样化图像描述生成模型的优化目标如下:
其中:α表示平衡因子; 第一项表示交叉熵损失函数;第二项为先验和后验概率之间的KL散度。
相应地,基于序列变分Transformer的多样化图像描述生成模型的优化目标如下:
其中:β表示平衡因子。
全局和序列变分Transformer模型的优化与推断过程如下:
a)通过N层Transformer编码器提取图像视觉特征VN。利用词嵌入、位置编码和N个注意力块将输入语句转换为文本特征WN。
b)将图像视觉特征VN与文本特征WN融合后分别映射为全局和序列后验隐变量。
c)从两种模型的后验分支中采样全局与序列隐嵌入,用于输入解码网络生成句子。利用优化目标函数,将后验分支网络作为教师网络指导先验网络,从而实现先验隐变量与后验隐变量的对齐。
d)在测试阶段,由于图像的真实描述不可观测,此时,使用先验分支网络替换后验分支网络,从两种模型的先验分支中采样对齐后的全局与序列隐嵌入,将隐嵌入与图像特征一起输入解码器进行单词推断。解码过程中,使用束搜索策略提升生成句子的准确性。
值得注意的是,所提出的两种模型均可以实现端到端的训练和测试,更便于实际应用。
3 实验
3.1 数据集和评价标准
3.1.1 数据集
定量与定性实验中所对比的图像描述方法均在MSCOCO数据集上进行训练与测试。为了公平对比,与现有方法均采用常用的m-RNN数据集划分方法[2],其中训练集118 287张图像,验证集4 000张图像,测试集1 000张图像,且每张图像均有5条由人工标注的描述语句与之对应。
3.1.2 准确性指标
实验采用了四种在图像描述任务中广泛使用的评价指标来评价模型所生成描述的准确性,包括BLEU@N[5]、METEOR[31]、ROUGE-L[6]、CIDEr[7]。其中:BLEU通过计算生成文本和参考文本之间n-gram的精准率(precision)来评价生成文本的精确性;METEOR在BLEU的基础上进一步考虑了召回率(recall),使得所生成描述在保证精确性的前提下更加人性化和贴合自然的描述内容;ROUGE通过比较生成文本和人工标注文本相同的部分,实现对句子中单词的重复率以及排列顺序的相似度的计算;CIDEr通过比较生成文本和人工标注文本相同的部分,实现对句子中单词的重复率以及排列顺序的相似度计算。
传统的图像描述模型对于单张测试图像利用生成的单个描述进行评价指标的计算, 而图像多样化描述生成模型需要针对生成的一组描述进行评价。目前大多采用Oracle重排序(Oracle re-ranking)计算best-1 accuracy指标。具体地,Oracle重排序使用测试图像的真实描述作为指标计算参考描述,其中在生成的一组描述中,每个指标得分最高的描述被选为best-1,然后计算所有测试图像的best-1准确性评价指标的平均值。
3.1.3 多样性指标
目前图像多样化描述方法大多采用Consensus重排序(consensus re-ranking)的方式统计和对比多样性指标。在Consensus重排序中,对于一张生成了n个描述的测试图像,首先计算其与训练集中相似度最高的K个图像,然后将n个描述分别与这K个相似图像的M个真实描述计算CIDEr分数。其中得分最高的描述被选为best-1描述。
多样性指标使用best-1 accuracy consensus re-ranking的排序方式,最终选取单张图片得分最高的best-5个描述。
a)Uniqueness:测试集所有图像生成的best-5个描述中,不重复的描述所占比例。
b)Novel:测试集生成的描述与训练集中真实描述不重复的描述个数。
c)mBLEU:对于每一张测试图像的best-5,分别计算其中一个描述与其余四个描述的BLEU-4分数,取单张图像五个描述分数的平均后,再取测试集平均。
d)Div-1:计算每一张测试图像的best-5中不重复的1-gram在五个描述总1-gram长度中所占比例,并取测试集平均。
e)Div-2:使用2-gram 替换1-gram,计算方法同Div-1。
3.2 实验设置
所提出的模型在训练中的图像特征、单词嵌入和隐变量的维度均设置为512。在视觉编码器中,本文方法使用预训练的Swin-Transformer来提取每幅图像的网格特征,且维度为1 536,并将其线性映射到512维向量中。在生成器中,使用单词嵌入并加上位置编码作为后验推断网络和先验近似网络的输入。此外,视觉编码器和生成器均是由3层的注意力块组成的,其中多头注意力的头数为8。在训练阶段,设置批大小为10,利用Adam优化算法和warmup学习率预热技巧来优化提出的模型。在学习率为5×10-6和交叉熵与KL散度损失函数下训练30个回合。平衡因子α和β分别设置为0.1。
在测试阶段,为了对比的公平性,与对比方法使用相同的束搜索参数。在进行准确性评价度量时束搜索宽度设置为2,而在多样性评价度量时的束搜索宽度设置为1。此外,本文的实验环境为PyTorch=3.8.2、CUDA=10.2和1个NVIDIA GTX 3080 GPU。
3.3 实验结果定量分析
首先将本文方法与主流多样化图像描述方法进行对比。表1列出了各方法在MSCOCO数据集上使用M-RNN划分和Oracle重排序后统计的准确性结果,其中“sample”表示每个方法采样生成的描述语句数量,最佳结果进行了加粗显示。具体地,与对比方法保持一致,实验中利用先验分支网络采样20和100个隐变量,然后输入解码网络生成多样化的描述语句。如表1所示,GCV-T-IC在两种采样下获得的各个准确性评价指标得分均优于其他对比方法。特别地,在与人工评价相关性较好的CIDEr指标上,GCV-T-IC显著优于其他方法。此外,GCV-T-IC模型在生成过程中没有引入其他的额外信息,而AG-CVAE、POS、COS-CVAE和DCL-CVAE分别在训练过程中利用了目标对象信息、PoS标签、增强的上下文信息和预训练模型。SCV-T-IC模型在采样100的条件下,其准确性指标优于当前最优的DCL-CVAE模型,而仅次于GCV-T-IC。
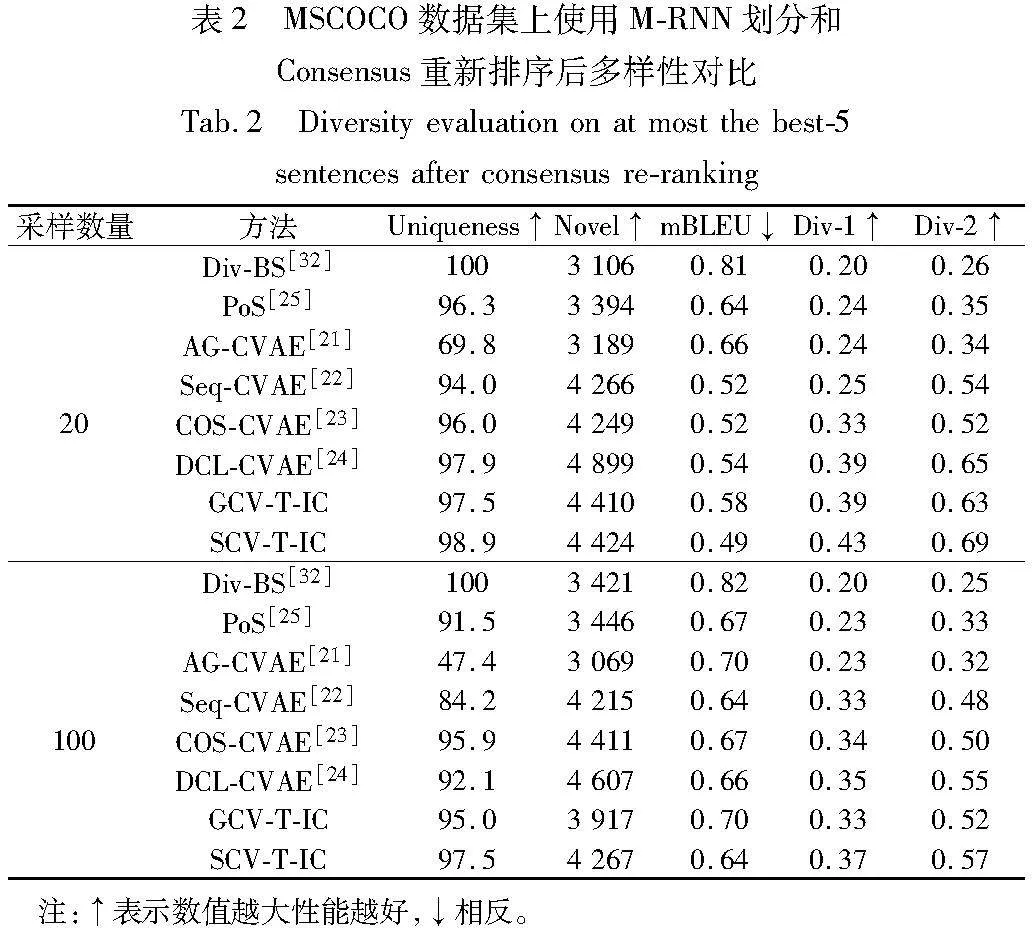
表2列出了各方法在MSCOCO数据集上使用M-RNN划分和Consensus重排序后统计的多样性结果。SCV-T-IC在两种采样下获得的多样性评价指标综合性能均优于其他对比方法,这是因为SCV-T-IC结合自注意力机制和序列变分推断,更加关注单词级的多样性,倾向于生成更加多样的句子。
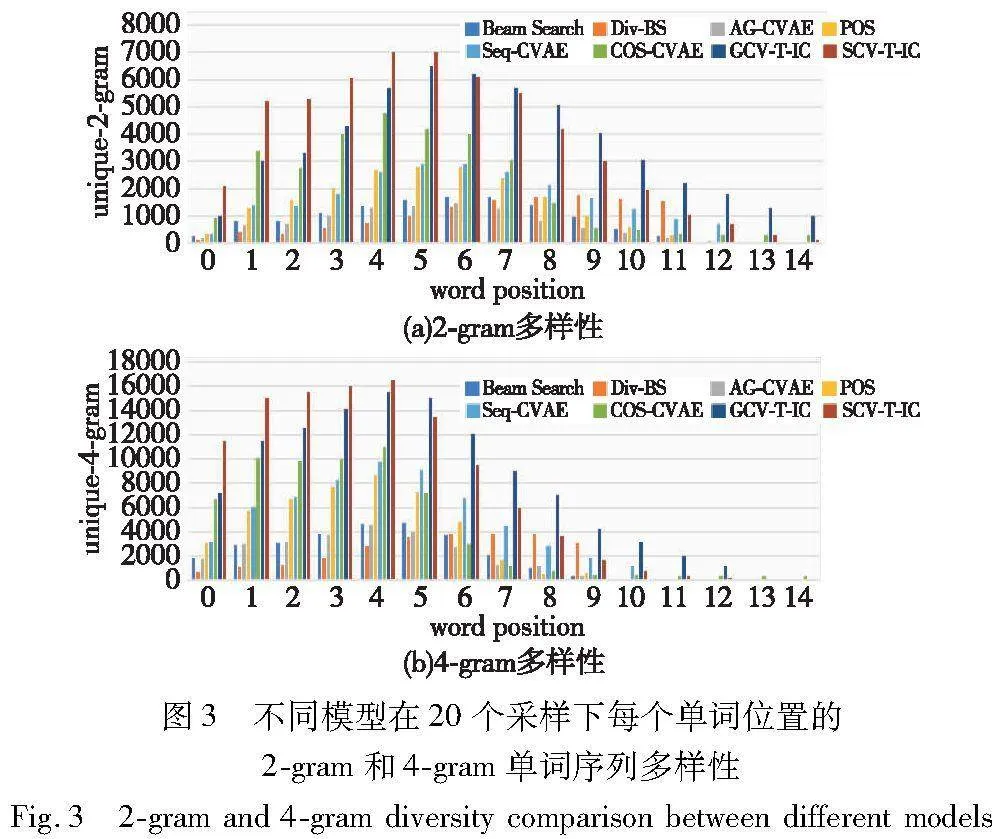
图3展示了不同模型在采样20个句子时每个单词位置上各不相同的2-gram和4-gram单词序列的数量。可以发现,本文方法在大多数单词位置上的2-gram和4-gram单词序列的数量都有显著提高。 这是因为本文方法不仅能够对每个单词位置进行细粒度的隐式表征,而且能利用Transformer全局注意力机制更好地近似条件先验,以提供更好的泛化能力。实验结果进一步证实,与现有方法相比,本文方法具有更好的多样化图像描述性能。
3.4 实验结果定性分析
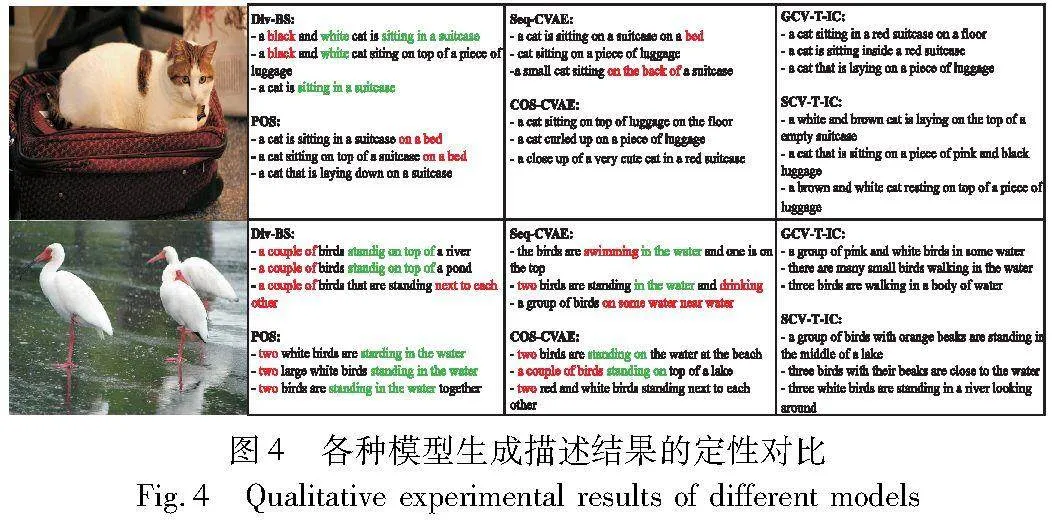
图4进一步定性对比了各方法从相同的两个测试图像采样得到的描述语句(参见电子版)。其中错误的单词用红色标记,重复的短语用绿色标记。直观地说,与其他方法相比,本文方法生成的描述更加准确和多样。如图4第二幅图像及其对应描述所示,SCV-T-IC可以准确识别出图像中鸟的数量,而其他方法则生成了不准确的量词和错误的单词。此外,对比方法倾向于生成高频n-gram的短语,而本文提出的GCV-T-IC和SCV-T-IC方法均可以生成更连贯和精细的描述,例如,生成的描述中包含了不常见的单词“orange beaks”“looking around”等。
为了更好地定性评估所提出方法的有效性,分别对本文两种模型生成描述过程中的交叉注意力权重进行可视化。图5展示了在每个时间步生成的单词及其对应的Transformer解码网络最后一层的交叉注意力权重热图。从图中可以看出,本文方法可以针对生成的语句关注到与语义最相关的图像区域,而一些与图像无关的词的注意力权重分布则较为稀疏,说明本文提出的两种方法均能针对单词推断学习比较准确的注意力权重。
4 结束语
本文提出了一种新颖的变分Transformer多样化图像描述生成框架,该框架将条件变分自编码器与端到端的Transformer的图像描述生成模型无缝融合。基于证据下界,设计了两种类型的条件变分Transformer模型,即GVC-T-IC和SCV-T-IC。 其中:GVC-T-IC利用全局隐嵌入捕获句子级多样性;SCV-T-IC将序列隐变量引入编解码过程,以提升每个时间步生成单词的多样性。定量和定性实验表明,所提出的方法在准确性和多样性指标方面显著优于现有的多样化图像描述方法。下一步工作将引入扩散模型进行语言建模,以进一步提高多样化图像描述的性能。
参考文献:
[1]Karpathy A,Li Feifei. Deep visual-semantic alignments for generating image descriptions [C]// Proc of IEEE/CVF Conference on Compu-ter Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2015: 3128-3137.
[2]Mao Junhua,Xu Wei,Yang Yi,et al. Deep captioning with multimodal recurrent neural networks(M-RNN) [C]// Proc of the 3rd International Conference on Learning Representations. 2015: 1-17.
[3]Vinyal O,Toshev A,Bengio S,et al. Show and tell: a neural image caption generator [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2015: 3156-3164.
[4]石义乐,杨文忠,杜慧祥,等. 基于深度学习的图像描述综述 [J]. 电子学报,2021,49(10): 2048-2060.(Shi Yile,Yang Wenzhong,Du Huixiang,et al. Overview of image captions based on deep learning [J]. Acta Electronica Sinica,2021,49(10): 2048-2060.)
[5]Papineni K,Roukos S,Ward T,et al. BLEU: a method for automatic evaluation of machine translation [C]// Proc of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2002: 311-318.
[6]Lin C Y. ROUGE: a package for automatic evaluation of summaries [M]// Text Summarization Branches Out. Stroudsburg,PA: Association for Computational Linguistics,2004: 74-81.
[7]Vedantam R,Zitnic C L,Parikh D. CIDEr: consensus-based image description evaluation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2015: 4566-4575.
[8]Anderson P,He Xiaodong,Buehker C,et al. Bottom-up and top-down attention for image captioning and visual question answering [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway,NJ: IEEE Press,2018: 6077-6086.
[9]Vaswani A,Shazeer N,Parmar N,et al. Attention is all you need [C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc., 2017: 6000-6010.
[10]GoodFellow I J,Pouget-Abadie J,Mirza M,et al. Generative adversarial networks [J]. Communications of the ACM,2020,63(11): 139-144.
[11]Kingma D P,Wellling M. Auto-encoding variational Bayes [C]// Proc of the 2nd International Conference on Learning Representations. 2014: 1-14.
[12]Chen Chen,Mu Shuai,Xiao Wanpeng,et al. Improving image captioning with conditional generative adversarial nets [C]// Proc of the 28th International Joint Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2019: 8142-8150.
[13]Chen Fuhai,Ji Rongrong,Sun Xiaoshuai,et al. Variational structured semantic inference for diverse image captioning [C]// Proc of the 33rd International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc., 2019: 1929-1939.
[14]李志欣,魏海洋,黄飞成,等. 结合视觉特征和场景语义的图像描述生成 [J]. 计算机学报,2020,43(9): 1624-1640.(Li Zhixin,Wei Haiyang,Huang Feicheng,et al. Combine visual features and scene semantics for image captioning [J]. Chinese Journal of Computers,2020,43(9): 1624-1640.)
[15]周东明,张灿龙,李志欣,等. 基于多层级视觉融合的图像描述模型 [J]. 电子学报,2021,49(7): 1286-1290.(Zhou Dongming,Zhang Canlong,Li Zhixin,et al. Image captioning model based on multi-level visual fusion [J]. Acta Electronica Sinica,2021,49(7): 1286-1290.)
[16]刘茂福,施琦,聂礼强. 基于视觉关联与上下文双注意力的图像描述生成方法 [J]. 软件学报,2022,33(9): 3210-3222.(Liu Maofu,Shi Qi,Nie Liqiang. Image captioning based on visual relevance and context dual attention [J]. Journal of Software,2022,33(9): 3210-3222.)
[17]宋井宽,曾鹏鹏,顾嘉扬,等. 基于视觉区域聚合与双向协作的端到端图像描述生成 [J]. 软件学报,2023,34(5): 2152-2169.(Song Jingkuan,Zeng Pengpeng,Gu Jiayang,et al. End-to-end image captioning via visual region aggregation and dual-level collaboration [J]. Journal of Software,2023,34(5): 2152-2169.)
[18]Dai Bo,Fidler S,Urtasun R,et al. Towards diverse and natural image descriptions via a conditional GAN [C]// Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 2970-2979.
[19]Shetty R,Rohrbach M,Hendricks L A,et al. Speaking the same language: matching machine to human captions by adversarial training [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 4135-4144.
[20]Huijben I A M,Kool W,Paulus M B,et al. A review of the Gumbel-max trick and its extensions for discrete stochasticity in machine lear-ning [J]. IEEE Trans on Pattern Analysis and Machine Intel-ligence,2022,45(2): 1353-1371.
[21]Wang Liwei,Schwing A G,Lazebnik S. Diverse and accurate image description using a variational auto-encoder with an additive Gaussian encoding space [C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc., 2017: 5756-5766.
[22]Aneja J,Agrawal H,Batra D,et al. Sequential latent spaces for mo-deling the intention during diverse image captioning [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 4261-4270.
[23]Mahajan S,Roth S. Diverse image captioning with context-object split latent spaces [C]// Proc of the 34th International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc., 2020: 3613-3624.
[24]Xu Jing,Liu Bing,Zhou Yong,et al. Diverse image captioning via conditional variational autoencoder and dual contrastive learning [J]. ACM Trans on Multimedia Computing,Communications and Applications,2023,20(1): 1-16.
[25]Deshpande A,Aneja J,Wang Liwei,et al. Fast,diverse and accurate image captioning guided by part-of-speech [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2019: 10695-10704.
[26]Wang Qingzhong,Chan A B. Describing like humans:on diversity in ima-ge captioning [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2019: 4195-4203.
[27]Shi Jiahe,Li Yali,Wang Shenjin. Partial off-policy learning: balance accuracy and diversity for human-oriented image captioning [C]//Proc of IEEE International Conference on Computer Vision. Piscata-way,NJ: IEEE Press,2021: 2187-2196.
[28]Rennie S J,Marcheret E,Mroueh Y,et al. Self-critical sequence training for image captioning [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 7008-7024.
[29]Wang Jiuniu,Xu Wenjia,Chan A B,et al. On distinctive image captioning via comparing and reweighting [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2022,45(2): 2088-2103.
[30]Liu Ze,Lin Yutong,Cao Yue,et al. Swin Transformer: hierarchical vision Transformer using shifted windows [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 10012-10022.
[31]Banerjee S,Lavie A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments [C]// Proc of ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Stroudsburg,PA: Association for Computational Linguistics,2005: 65-72.
[32]Vijayakumar A K,Cogswell M,Selvarju R R,et al. Diverse beam search for improved description of complex scenes [C]// Proc of the 27th International Joint Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: 7371-7379.
