基于概念漂移检测的数字孪生流程预测模型
2024-08-17熊正云方贤文
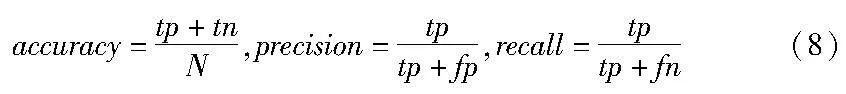

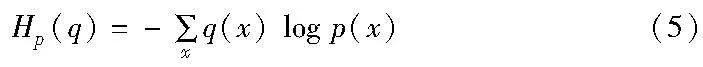
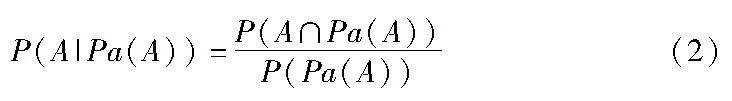
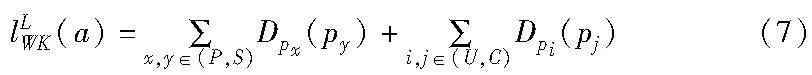



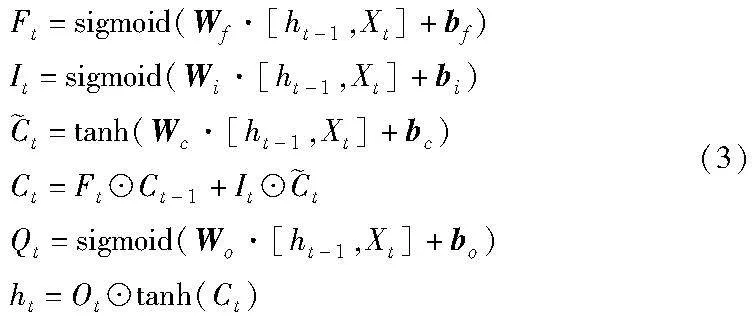



摘 要:预测性流程监控可以在业务流程运行过程中提供及时的信息,以便采取措施来应对潜在风险,如何提高流程预测的准确度一直受到高度关注。现有的研究方法大部分都在静态环境下引入,很少有结合数字孪生技术用于动态环境的流程预测。为此,提出了一个基于概念漂移检测的方法,并构建数字孪生流程预测模型(digital twin based on concept drift,DTBCD)预测下一个活动。首先利用事件流行为关系和权重散度将流程中的活动进行特征提取,得到数据流的特征集,其次进行漂移检测,动态选择特征集输入人工智能模型中训练并预测下一个活动,然后运用物联网和云计算等先进技术创建数字孪生虚拟环境,最后得到基于概念漂移的数字孪生模型。通过公开可用的数据集进行评估分析,实验结果表明,提出的方法能够有效提高预测的准确性。
关键词:预测性流程监控; 活动预测; 漂移检测; 数字孪生
中图分类号:TP391.9 文献标志码:A 文章编号:1001-3695(2024)07-017-2039-07
doi:10.19734/j.issn.1001-3695.2023.11.0541
Digital twin process prediction model based on concept drift detection
Abstract:Predictive process monitoring can provide timely information during the operation of business processes, in order to take measures to address potential risks. How to improve the accuracy of process prediction has always been highly concerned. Most of the existing research methods focus on process prediction in static environments, with few combining digital twin technology for process prediction in dynamic environments. To this end, this paper proposed a method based on concept drift detection and constructed a digital twin process prediction model to predict the next activity. Firstly, this method used behavioral relationship between event streams and weight divergence to extract features from activities in the process and obtained the feature sets of data flows. Secondly, this method performed drift detection. It dynamically selected feature sets and input them into the artificial intelligence model for training and predicting the next activity. Then, it used advanced technologies such as the Internet of Things and cloud computing to create a digital twin virtual environment. Finally, this paper obtained a digital twin model based on concept drift. It carried out evaluation and analysis on publicly available datasets, and the experimental results show that the proposed method can improve the effectiveness of prediction.
Key words:predictive process monitoring; activity prediction; drift detection; digital twin
0 引言
伴随着当代信息技术高速稳步发展,制造工业的智能化也应运而生。由于制造工业流程的复杂化和智能化,其可靠性和安全性也逐步引起了相关利益者的广泛关注。数字孪生(digital twin,DT)技术被认为是工业4.0核心力量之一[1],为了减少制造工业系统的损失以及及时对制造系统流程作出决策,数字孪生发挥了不容忽视的作用。DT可以被认为是一个虚拟模型,能够在网络虚拟世界反映物理世界的过程,并且通过实时的高保真建模,它能够在整个生命周期对物理实体进行有效监控和预测。对于真实实体中发生的变化,DT可以及时更新仿真模型,这使得数字提取的仿真模型能够成为真实实体在实时建模时的高保真副本[2],并且能够通过模拟和映射物理实体得到的虚拟模型,完成动态优化[3]。数字孪生主要由以下四个部分组成[2]:a)真实世界实体,如制造工业的某个工厂,或是工厂内某个机器(组件);b)数据驱动仿真模型,包括描述仿真模型的算法、机器学习、深度学习和数据挖掘,对数据深度挖掘的分析、提炼模型及其软件实现等;c)连接组件,物联网系统和云计算等;d)物理世界的动态变化:真实世界实体已经或正在生成的动态数据。第四个部分是数字孪生的关键部分,它影响数字孪生虚拟建模目标的完整复现程度。
现有的数字孪生方法是基于公司或咨询专家制造的模型结构,最近的研究侧重于事件日志数据等数据驱动技术,以实现数据流创建仿真模型的目标[4]。流程挖掘可用于预测制造场景中流程变化的结果或原因[5],因此使用流程挖掘方法来跟踪和确定各种特征的研究越来越受欢迎。制造工业中产生的数据纷繁复杂,但是对人工智能技术的研究表明,它能够有效学习这些数据,并驱动着数字孪生的实现,从而使现实世界中复杂的数据可以更容易地转换为虚拟世界的数据。通过使用人工智能模型,提前预测可能具备严重影响性的问题并采取应对措施,从而减少不必要的资源浪费,此外与数字孪生的结合,扩大了它们的适用范围。预测性流程监控作为流程挖掘中不可分割的一个部分,大多数采用的方法就是人工智能技术中的深度学习技术[6~8],通过训练模型来提高预测的准确度,但很少结合数字孪生技术在动态环境中预测。实际上的业务流程中总是不断变化的[9],因此动态环境中的预测性流程监控能够更有效地捕捉业务流程中的变化,从而避免出现突发情况,造成难以估计的时间和物质上的损失。文献[9~11]是在动态环境下的流程预测,但是没有结合DT技术,文献[5]为了预测剩余循环时间,提出了一种使用过程变迁技术的数字孪生发现框架。在本文中,利用DT技术建立数字孪生模型是以准确度为指标,预测流程中下一个活动,并且考虑了流程的动态变化,这关系到什么时候流程可能会出现异常情况(如制造工业中机器的故障),数据的概念漂移检测则可以很好地处理这种情况。此外,DT在虚拟空间中实时的监控和预测也可以及时应对突发情况,并且在短期和中期场景中都有助于对过程的当前状态作出适当的决策[4]。
本文的主要贡献如下:a)考虑流程中的动态变化,利用事件流的行为关系,并结合信息理论中的熵概念将事件日志转换为数据流,从而进行概念漂移检测;b)基于数字孪生技术构建一个虚拟模型来预测制造工业流程中的下一个活动,此外还能将物理世界接收到的动态事件日志应用于改进模型,从而构建更精确的数字孪生模型;c)使用公开可用数据集进行实验,并对实验结果进行分析,结果表明本文方法可以有效提高预测的准确性。
1 相关工作
1.1 数字孪生
数字孪生正在对工业进行改革,未来的物理世界将通过数字孪生技术被克隆到数字空间中,文献[12]以五维数字孪生模型为出发点,研究数字孪生相关常用技术和工具,并对其进行总结,为今后数字孪生的应用提供一定的参考价值。文献[13]基于数字孪生技术提出了一种四层设计架构:CMCO(configuration design-motion planning-control development-optimization decoupling),基于此模型,提出了一个数字孪生系统,即制造系统设计平台,并验证了此设计平台的可行性和有效性。文献[14]提出了一种自动发现制造系统并生成适当数字孪生的方法,根据事件日志中的相关特征,产生仿真模型并进行调优,保证了在短时间内的任何时间都可以获得物理系统的更新和合理详细的数字孪生模型。针对目前智能制造企业迎来的严峻的现实问题,文献[15]旨在对基于数字孪生的工业信息集成系统驱动的智能制造进行定量绿色绩效评估(green performance evaluation of smart manufacturing,GPEoSM),构建的GPEoSM框架通过案例证明是有效的。文献[2]提出了一个数据驱动的方法,利用了机器学习和过程挖掘技术,并对模型进行不断改进和持续验证,在建立仿真模型需要一定的先验知识和专家知识的情况下,此框架的目标是最小化并充分定义,甚至消除这些知识的需求。
1.2 预测性流程监控
预测性流程监控领域已有许多研究方法,在过去的几年中,深度学习被广泛应用于此,如长短期记忆(long short-term memory,LSTM)网络,已被提出用于下一个活动[16]、后缀生成[17]、流程的剩余时间预测[18]和结果预测[7]。Hinkka 等人[19]应用循环神经网络,通过从事件日志的迹中提取有标签的流程实例,以有监督的方式来训练模型。Pasquadibisceglie等人[20]运用卷积神经网络预测运行迹中的下一个活动,其特色是将时间数据转换为空间数据来训练深度学习的模型。Taymouri等人[16]针对训练数据不足或网络配置和架构次优的问题,提出了一个对抗训练框架来预测下一个事件标签和时间戳[14]。注意力机制可以解决序列建模的长距离依赖问题,并且无须考虑它们在输入和输出序列中的距离,因此,Vaswani等人[21]引入了一个深度序列模型,即Transformer神经网络,它采用自我注意从而保持长距离序列的一致性,实验证明了模型的质量更优越,更具并行性,并且训练时间更少。由于Transformer的流行,基于它的编码器-解码器模型已经迅速成为神经网络机器翻译和自然语言理解的主导架构[22~24]。
1.3 概念漂移
大多数业务流程具有动态的特性,会随着时间的推移而发生变化,过程中的变化可能是突然性的或逐步性的[25],因此对于流程管理来说,发现流程中的这种概念漂移并进行深度理解和采取恰当的处理方式是至关重要的。文献[26]提出了一种新方法——ElStream(ensemble and conventional machine lear-ning techniques detect distribution of streaming data),该方法使用集成和传统的机器学习技术来检测概念漂移,ElStream是基于多数投票技术,只制作最佳分类器来投票决定是否产生漂移。概念漂移的检测也是流程预测工作中一个重要部分,文献[9]在增量流程预测中对于漂移的检测采取了文献[25]的方法,即提取事件日志中不同的特征表示活动之间的关系,并转换为数据流,接着利用滑动窗口技术和统计方法检测这些特征数据流,用于发现连续窗口之间的差异,从而判断出漂移发生点。文献[27]提出了一个在线预测监控(in-line predictive monitoring,ILPM)框架,在第一阶段使用过程参数监控,在第二阶段使用设备参数监控。为了保持鲁棒性和准确性,使用概念漂移来实时更新ILPM模型。
2 准备工作
2.1 事件日志
本文定义了事件日志,它用于表示流程执行记录。
定义1 事件日志。令ε为所有事件的集合,事件日志L是一组K大小的事件序列(或案例),记作L={σi:i=1,…,K},且σi=(e1i,…,enii)。此外,序列中的每个事件都与属性和属性值相关联[28]。
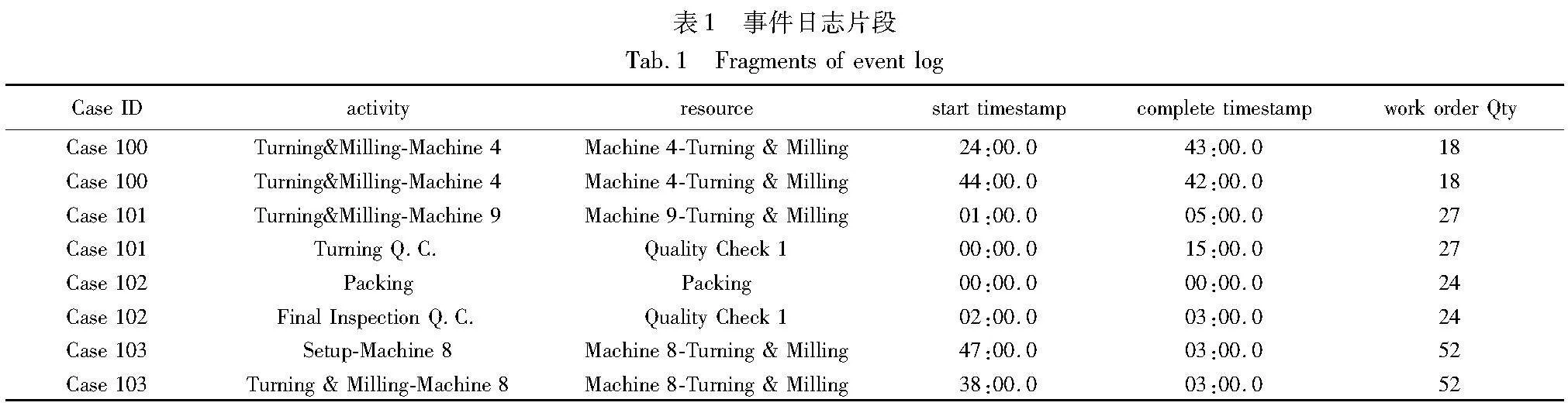
表1是某制造工业的部分事件日志,它包含案例号、活动(机器的操作)、资源(工作的单元)、机器开始和结束时间以及工作订单数量。
2.2 动态贝叶斯网络
贝叶斯网络(Bayesian network,BN)是一个有向无环图,其中每一个节点表示一个属性,当属性Ai依赖于Aj时,就存在一条有向边(Ai,Aj)。此时称变量Ai为Aj的父级。Pa(A)是A所有父节点的集合,即A所依赖的属性。对于所有节点(X0,X1,…,Xn)的联合概率分布为[29]
条件概率表(conditional probability table,CPT)捕获属性Xi的P(Xi|Pa(Xi)),这些表在父值出现的前提下包含所有可能值的概率。通过学习CPT和模型结构(属性之间的依赖关系)来学习BN。动态贝叶斯网络(dynamic Bayesian network,DBN)[30]结合了序列层面,是通过向网络添加额外的变量来实现的。动态贝叶斯网络由模型结构和模型参数两者组成,结构和参数都可以从数据中学习获得,因此都可以单独更新。DBN的结构描述了数据中属性之间的条件依赖关系。DBN的参数描述了所有属性的条件概率,可按如下公式计算[9]:
2.3 LSTM网络
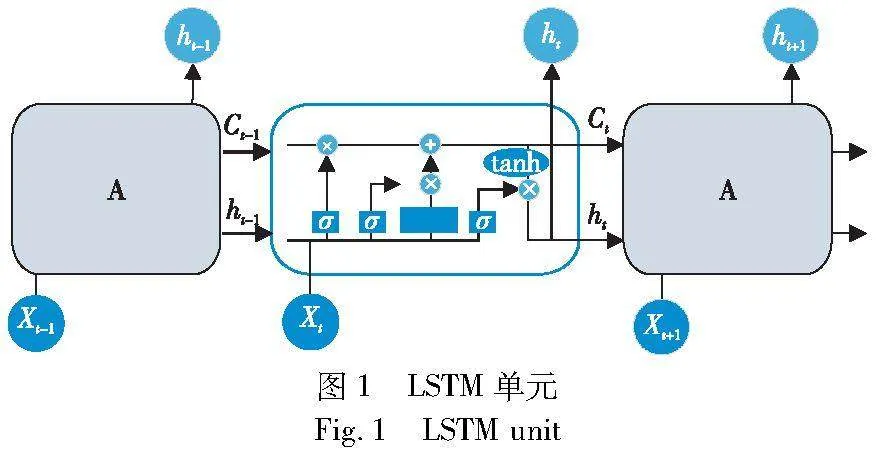
LSTM是一种神经网络,专门用于处理长序列数据[31],它有 “门”结构来去除或者增加信息到LSTM单元状态的能力,这些门是使用逻辑函数实现的,用于计算0到1之间的值。乘法应用于此值以部分允许或拒绝信息流入或流出内存[32]。图1描述了单个LSTM单元的架构,每个蓝线框都代表一个LSTM单元(用A表示),该单元通过输入前一个隐藏状态ht-1和单元状态Ct-1以及当前输入Xt来输出下一个状态ht和Ct。单个LSTM单元完成的操作由式(3)描述,其中Wi、Wf、Wc和Wo是可训练的权重矩阵,bi、bf、bc和bo是偏置矩阵。
3 基于概念漂移的数字孪生
为了避免业务流程中出现突发情况,造成难以估计的时间和物质上的损失,在不断变化的流程中进行动态预测是至关重要的。此外,利用DT技术在虚拟空间中进行实时监控和预测,可以及时应对突发情况,有助于针对流程的当前状态采取适当的对策措施以及决策优化。本文提出了基于概念漂移的数字孪生虚拟模型架构DTBCD(digital twin based on concept drift),在动态环境下进行预测性流程监控。
3.1 概念漂移检测
业务流程中不确定性通常表现为执行过程中的重大变化[33],这种现象被称为概念漂移。它包含突发式漂移、逐渐式漂移、反复式漂移和增量式漂移四种类型[25],它的特点是数据分布的变化,而正是通过这种数据的变化可以研究动态环境中的流程,并且能够快速充分地对流程中的变化作出反应。本文基于事件流严格序、排他序和交叉序[10]考虑事件日志中活动之间的关系。
在事件日志中,如果在活动a出现的迹中,活动b都直接跟随a,那么说b严格遵循a,即事件流中的严格序;如果b没有直接或没有间接跟随a,反之亦然,那么说b排他遵循a,对应于事件流中的排他序。事件日志中a出现的情况下,若活动b仅在部分迹中直接跟随活动a,为此本文设定了一个阈值λ,这部分迹出现的次数与所有迹总数的比值小于或等于某个阈值(λ),则说b微遵循a;若大于,则说b常遵循a。例如,假设迹的总数为l,活动b仅在几条迹中(这样的迹的数量较少)直接跟随活动a、活动b在大部分迹中(这样的迹的数量较多)直接跟随活动a的这两种情况。λ可以体现这种变化差异,即能够对漂移的检测更加敏感(能够更好地感知到数据流的变化)。
那么在事件日志L中活动之间定义四个关系:对于活动对(a,b),b严格遵循a(用S表示),b排他遵循a(用P表示),b常遵循a(用C表示),b微遵循a(用U表示),如表2所示。
定义5 跟随关系。对于事件日志L中某个活动a∈A,RLfow(a)=〈cS,cC,cU,cP〉,cS、cC、cU和cP表示事件日志中严格遵循、常遵循、微遵循和排他遵循a的活动数量。
定义6 熵。如果随机变量x出现的概率为p(x),则随机变量x的熵定义(信息论中为信息量的多少)为
定义7 交叉熵。把来自一个分布为q(x)的变量信息使用另一个分布p(x)的最佳方式传达的平均信息长度称为交叉熵:
定义8 KL散度。KL(Kullback-Leibler)散度是交叉熵和熵之间的差,能够衡量两个分布之间的差异,且它是非对称的。p相对q的KL散度可定义为
Dq(p)=Hq(p)-H(p)(6)
在以上定义的基础上提出本文的权重散度。
定义9 权重散度。对于事件日志中某个活动a∈A,权重散度lLWK(a)如下:
其中:pS=αcS/|A|,pC=βcC/|A|,pU=(1-β)×cU/|A|,pP=(1-α)×cP/|A|,α和β是权重参数(0<α<1,0<β<1)。
通过定义5和9得到的特征集,可以将n个事件日志转换为数据流/序列D,特征值的数据集D可以被视为m个值的时间序列,此过程被称作特征提取。为了检测概念漂移,考虑m个值中大小为w的连续数值群体(w<m),并检查两个群体之间是否存在显著差异(即检测大小为w的滑动窗口之间的差异),接着使用统计假设检验[9](例如:Kolmogorov-Smirnov检验、Mann-Whitney U检验或Hotelling T2检验)来检测差异,从而发现这些变化点。
3.2 DTBCD系统结构
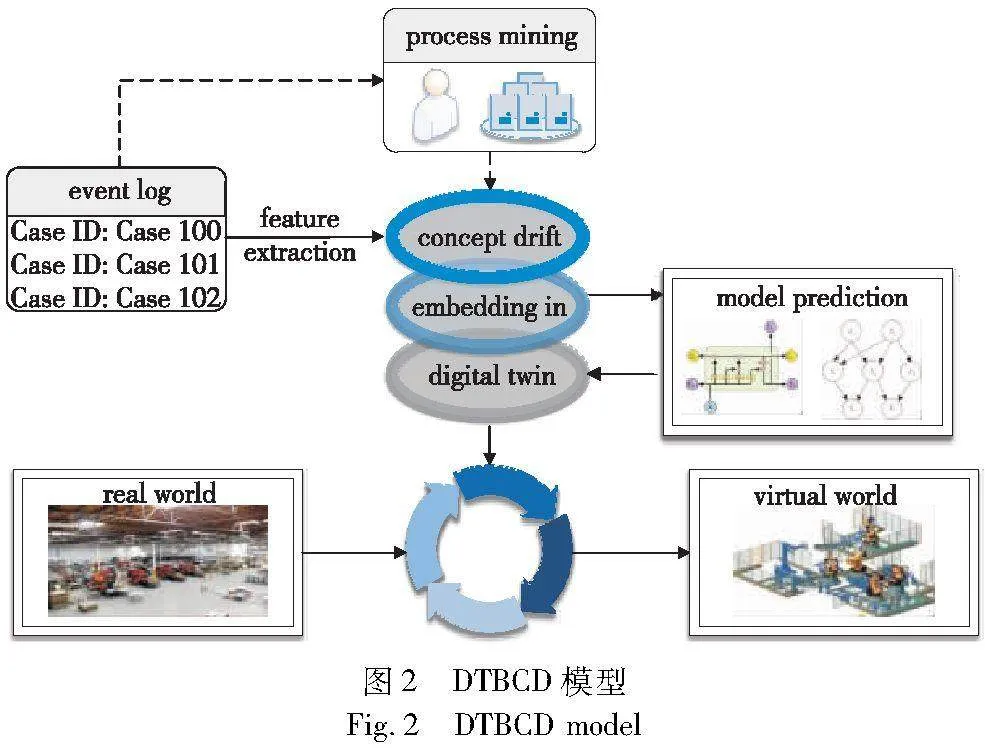
本文使用一个基于数字孪生的虚拟模型架构DTBCD来预测流程中的下一个活动。第一步基于事件日志数据先对数据流进行概念漂移检测(如3.1节所述),提取的数据用于构建DT模型。第二步通过机器学习来解决预测的问题。此外,由于技术不足的专业性问题的存在,所提出的虚拟模型架构可以通过与其他相关公司企业的合作来处理。图2展示了DTBCD模型。
首先在事件日志中跟踪制造过程的活动,利用事件流行为关系和权重散度(如3.1节所介绍)对流程中的活动进行特征提取。其次,根据特征提取得到的数据流进行概念漂移检测,从而得到数据变化点并将其作为数据选择的依据,然后将所选数据嵌入人工智能模型进行训练,并学习输出值。通过与公司的合作,运用物联网和云计算等先进技术就可以创建一个数字孪生模型来预测流程中下一个活动,最后得到基于概念漂移的数字孪生DTBCD,如图2所示。
DTBCD虚拟模型的构建算法如下所示:最初输入一个事件日志,最后输出一个数字孪生模型。首先进行变量初始化,再进行数据的转换操作(步骤a)),以便调用概念漂移检测的方法,然后将数据按“天”或是“周”分批(步骤b))。接着根据事件流行为关系和权重散度对每一个活动进行特征提取,转换为数据流(步骤c))。其次是模型训练部分,先利用DBN或是LSTM进行模型的初始训练(步骤d)),然后进行概念漂移检测,即对每一个批次内的数据,都会检验滑动窗口内是否存在差异。若存在,则将该批次的数据添加到更新数据中,并利用更新的数据训练模型,从而得到更新后的模型来预测下一个活动;若没有差异,则利用当前数据训练模型来预测(步骤e))。最后将机器学习模型和人工智能技术结合,构建出数字孪生模型(步骤f))。由于算法只有两个顺序执行的循环语句,所以算法复杂度为O(n)。
算法1 构建DTBCD模型
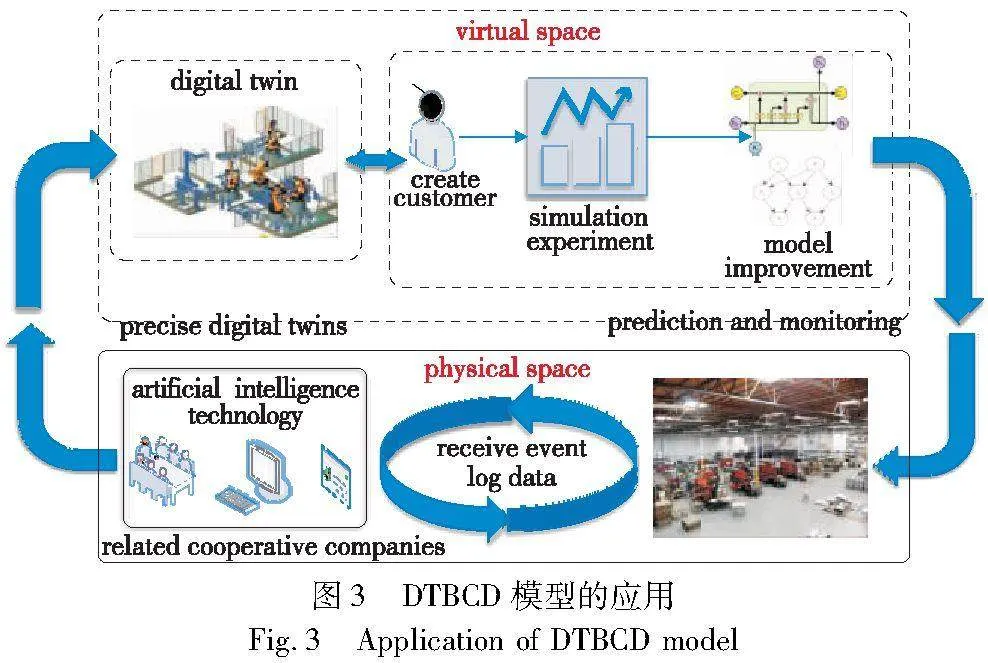
随着物联网技术的发展,实时收集通过概念漂移检测方法预测得到的动态数据信息,在云计算环境中与相关企业公司共享,从而用于创建的数字孪生虚拟模型。此外,在与他们合作的过程中,根据其提供的人工智能技术,可将物理世界接受到的动态真实事件日志数据应用于改进模型,从而构建更精确的DT。数字孪生模型的应用前景广阔,在虚拟环境中可以创建客户和流程进行实验,结果将交付给制造工业的工厂,以便客户能够对制造过程进行长期监控与预测,如图3所示。
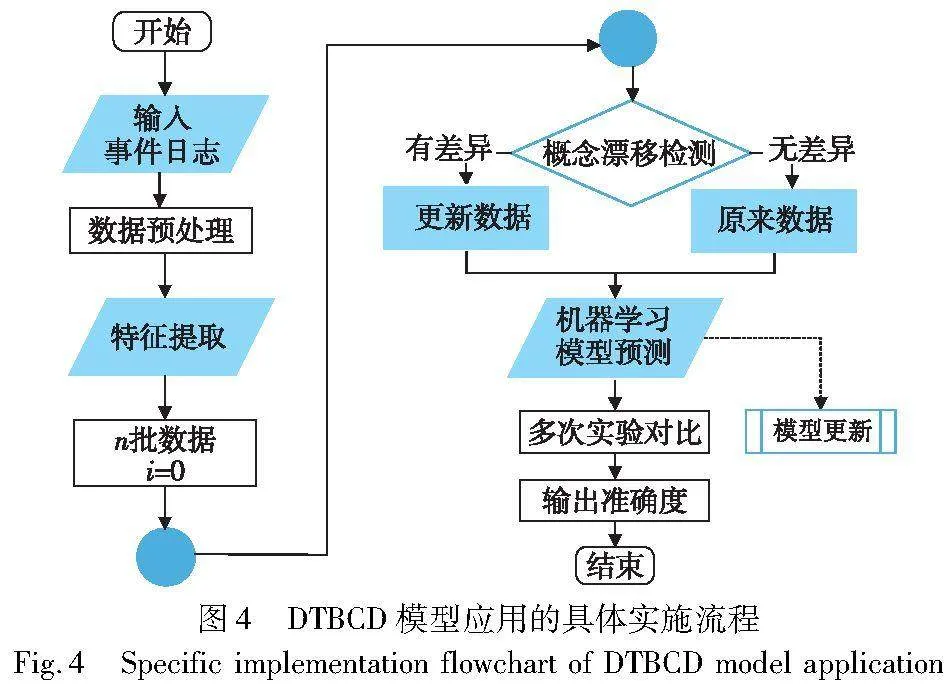
3.3 具体实施流程
本文提出的漂移检测方法,用于业务流程中下一个活动的预测,并借助了机器学习模型和事件流行为轮廓的知识。具体的实施流程如图4所示。
首先输入事件日志,进行数据预处理并将其分为n批数据,然后对流程中的活动进行特征提取,即根据活动之间的跟随关系计算权重散度,即将事件日志转换为数据流,从而得到特征集(特征值的数据集)。
其次,为了检测概念漂移,应用自适应滑动窗口,即随着窗口的移动,通过假设检验来检测特征集中两个窗口之间的差异,从而判断是否有概念漂移现象产生。若发生,则将此训练数据加入到更新数据之中,反之则保留原来数据。窗口大小的设置由数据量决定。
然后,为了使用数据进行机器学习,将更新后选择的数据输入人工智能模型进行训练,从而学习输出值。模型可以根据不同的数据选择产生不同的模型(即模型更新)。
最后通过训练的模型来预测流程中下一个活动,并输出预测的准确度。
4 实验评估
本文的实验是在Windows 10操作系统上进行测试,使用的硬件包括3.20 GHz AMD R7 5800H CPU和16 GB主内存以及4 GB内存的NVIDIA GeForce MX450 GPU。测试框架是在使用Python编程语言的测试系统上构建的。
4.1 实验数据集
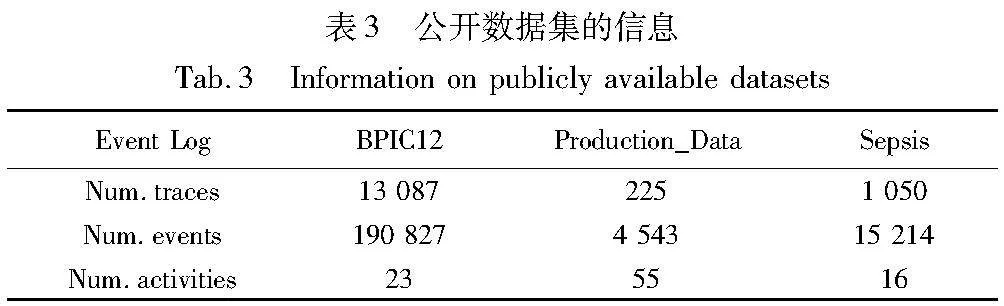
为了测试在模型中的概念漂移检测的效果,本文需要在活动视角中发生一些漂移的数据集。本文使用人工创建的仿真事件日志、公开数据集(表3)以及实际案例数据集的事件日志进行评估,数据集介绍如下:
a)Artificial Log:仿真事件日志,包括175个案例、17个活动、2 372个事件。
b)BPI12W_Complete:2012年BPI挑战(BPI12 W完成)事件日志,是全球融资组织内个人贷款或透支的申请流程。本文保留了类型为“完成”的6项活动的72 413个事件,共有9 658条迹。预处理迹的长度在1~74。
c)Production_Data:来自某制造工业工厂的数据集,包括一些机器名称以及其对应的操作,如:Packing、Final Inspection Q.C.等。数据还包括机器开始和结束完成时间等内容,以及不同级别的属性(例如,涉及的机器操作者Worker ID)。
d)Sepsis:是包含处理医院中脓毒症患者流程的事件日志。包括1 050个案例,总共有15 214起事件,记录在16种不同的活动中。此外,还记录了39个数据属性,例如,负责活动的小组、测试结果和检查表中的信息。
在本文的实验中,感兴趣的是概念漂移检测之后数据是否更新的差异,因此,将更新纳入下一个活动预测。在数据预处理之后,会对流程中的活动进行特征提取,据此进行概念漂移检测。考虑使漂移检测更加敏感(即能够更好地感知到数据流的变化)从而提高检测的有效性,本文利用参数λ(表2),在[0,1]区间每隔0.1不断调试,得到0.8的效果最佳。同理α和β(如定义9所述)分别为0.7和0.9。检测之后便可对数据进行选择,数据选择有两种方式,即原始无更新的数据、概念漂移检测之后滑动窗口内的数据(即更新后的数据)。
4.2 模型训练设置
为了测试不同的概念漂移检测方法,选择了机器学习模型动态贝叶斯网络DBN,由于DBN针对多属性的预测效率较高,所以选择了DBN来提高预测的有效性。此外还选择了深度学习模型LSTM,用于在深度学习技术领域中进行本文概念漂移方法的检测研究。将数据输入到两种模型中——动态贝叶斯网络DBN和LSTM,即可得到原始的模型和更新的模型。本文的实验是根据不同的数据选择,将进行漂移检测以及无漂移检测这两种情况,分别在DBN与LSTM两个模型上进行比较来得出结论。
在本文的实验中,提出两种将数据分批的方法:按天和按周来进行实验。当评估预测性能时,使用交叉测试然后训练的方法。首先根据时间戳对数据集中的事件进行排序,然后按时间顺序将训练和测试集按1∶1的比例划分。初始模型从训练集中训练得到,测试集用于测试方法并逐步更新模型。
本文使用DBN是根据属性之间依赖关系进行训练,对于LSTM模型,用一个共享层训练两层LSTM,并使用Nadam梯度下降优化器进行训练,该优化器在各种类型的神经网络中准确率较高[34],dropout设置为0.2,最后使用一个全连接层进行输出。
4.3 实验结果
本文侧重于不同方法的准确性如何随时间变化,因而为了衡量下一个事件预测的准确性,本文使用正确预测占预测总数的比例[34]。本文的指标准确度、精确度和召回率定义如下:
其中:tp表示真正例;tn表示真负例;fn表示假负例;fp表示假正例,N=tp+tn+fp+fn。此外,本文使用一个图形表示,如图5、6所示,x轴上为按时间顺序的事件索引,y轴表示预测的准确度、精确度和召回率,利用该图(使用滑动窗口来计算准确度、精确度和召回率),即可查找预测这三者随时间的变化。最后将本文方法(Weight Divergence)与在动态环境中预测的Jmeasure[11]方法(Jmeasure)以及无漂移检测模型预测的方法(No Drift)进行比较,接下来展示实验结果。
4.3.1 仿真数据集
由于仿真数据集结构较为简单,所以实验只将它按天分批,预测的准确度如图5所示。由图5可以看出,相较于无漂移检测的方法和Jmeasure方法,在仿真数据集中本文权重散度方法的预测准确度有一定程度的提升,且在DBN和LSTM网络中都得到了较为不错的效果。
表4展示了仿真数据集预测准确度,加粗表示预测最好的结果。由表4结果可知,在仿真数据集上利用LSTM预测,本文方法的预测准确度相比于无漂移检测的方法和Jmeasure方法,分别提高了0.754%和0.881%。而利用DBN进行预测时,本文方法相较于后两者分别提高了0.998%和0.872%。
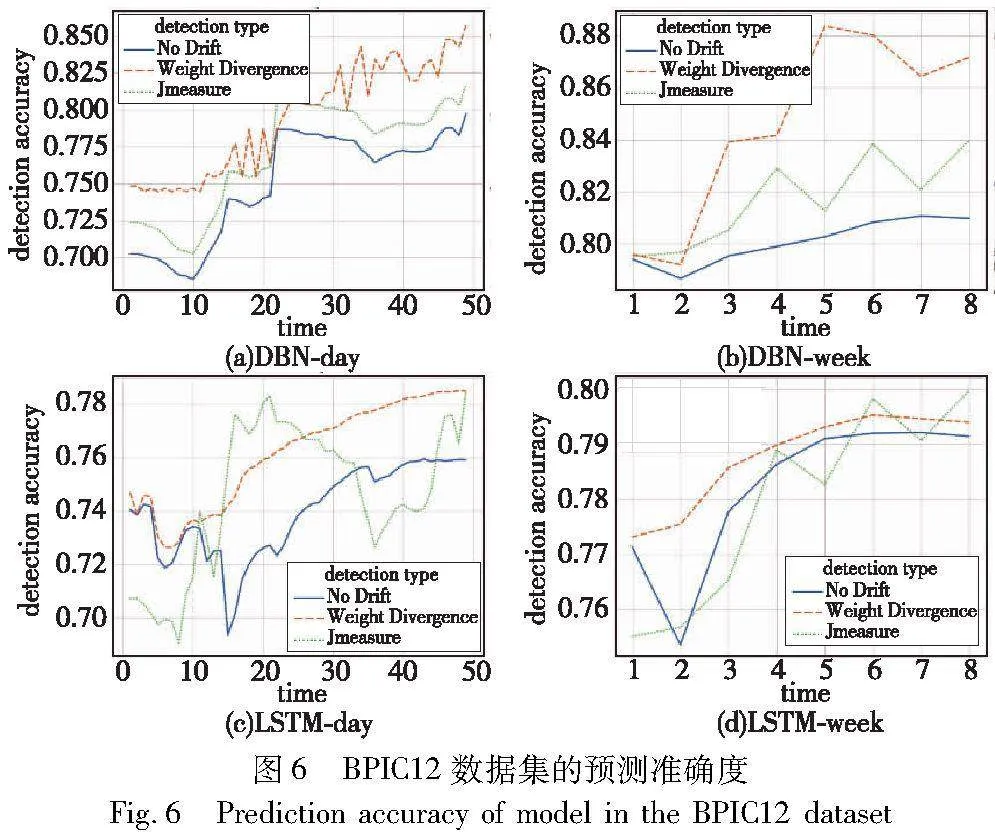
4.3.2 BPIC12数据集
由图6可以得到对于DBN模型不论是按天或按周进行预测,总体来看采用本文漂移检测的方法(Weight Divergence)比无漂移检测和Jmeasure预测的准确度要高。除此之外,按周进行预测的准确度要高于按天预测的准确度,即相对于无漂移检测,本文权重散度的方法按周预测的准确度提升幅度更大。
此外对于LSTM模型,不论是按天或是按周进行预测,采用本文漂移检测的方法(Weight Divergence)都比无漂移检测的预测准确度要高。除此之外,按周进行预测的准确度要高于按天预测的准确度,相对于Jmeasure的预测漂移,本文权重散度的方法在按周预测的准确度较大,而按天的准确度较小。
4.3.3 实际案例的数据集
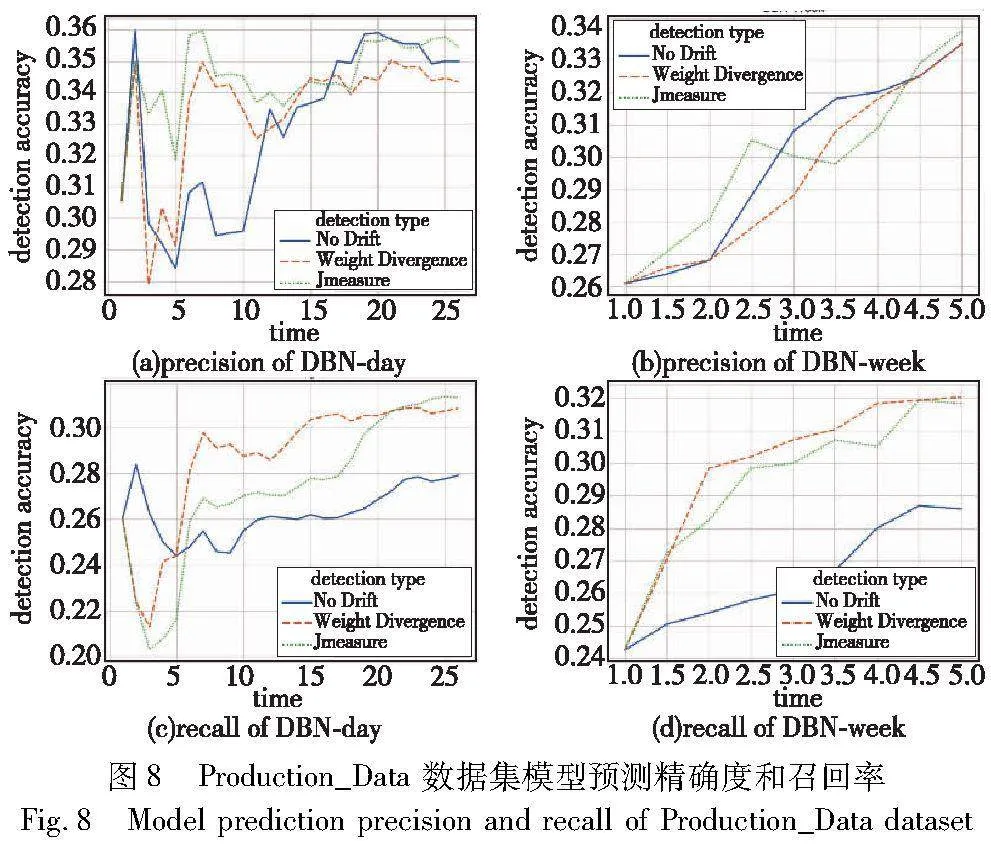
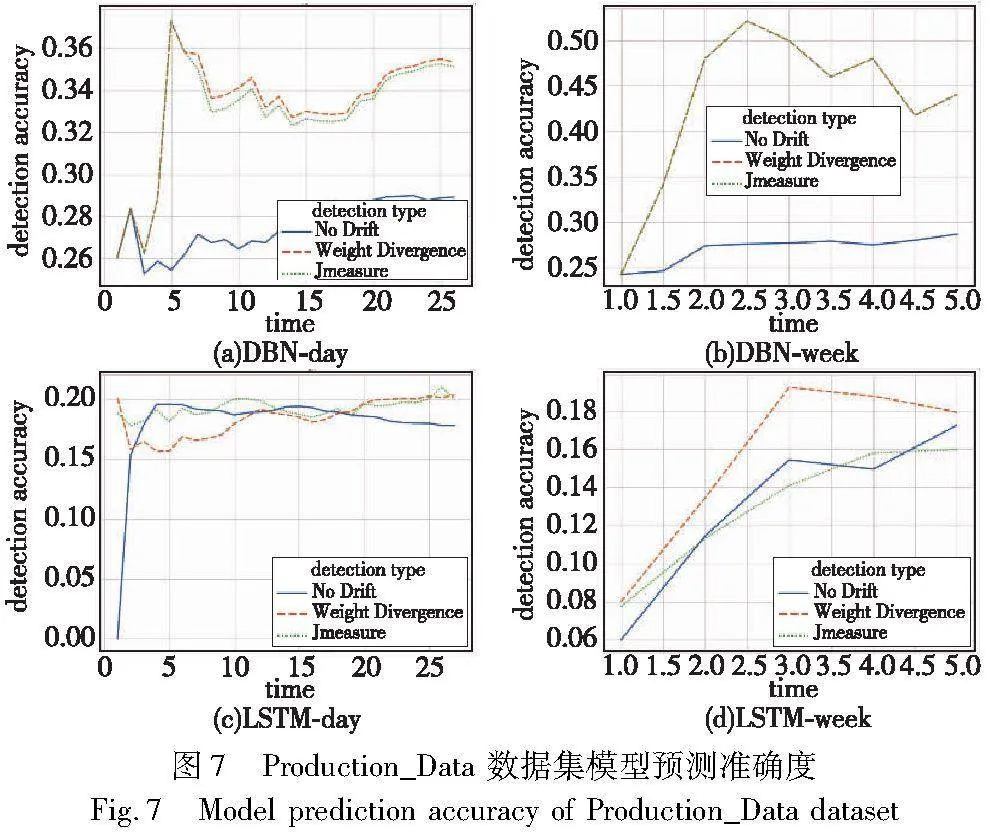
1)Production_Data 数据集模型预测结果
图7展示了Production_Data数据集DBN和LSTM模型预测的结果。由图7可以得到,对于DBN模型,不论是按天或是按周进行预测,采用本文漂移检测的方法都比无漂移检测和Jmeasure预测的准确度要高。除此之外,按周进行预测的准确度要高于按天预测的准确度,即相对于无漂移检测,本文权重散度的方法在按周预测的准确度上提升幅度更大。更进一步,按天预测中,本文将权重散度和Jmeasure两种概念漂移检测的方法进行比对,在时间序列的开始部分两者几乎没有明显差异,后来可以观察到权重散度预测的准确度要略微高于Jmeasure,即在DBN模型预测中,权重散度预测的准确度要更高一点。按周预测中,两者预测准确度没有区别。
对于LSTM模型来说,在三种方法中按天预测的准确度相差较小,且没有DBN模型预测的效果好。也就是说,相对于无漂移检测的方法来说,LSTM模型嵌入漂移检测方法之后预测的准确度提升幅度不大,甚至可以说没有提升。除此之外,在LSTM模型按周预测中,使用权重散度的漂移检测方法来预测制造过程的下一个活动的准确度要明显高于无漂移检测和Jmeasure方法。
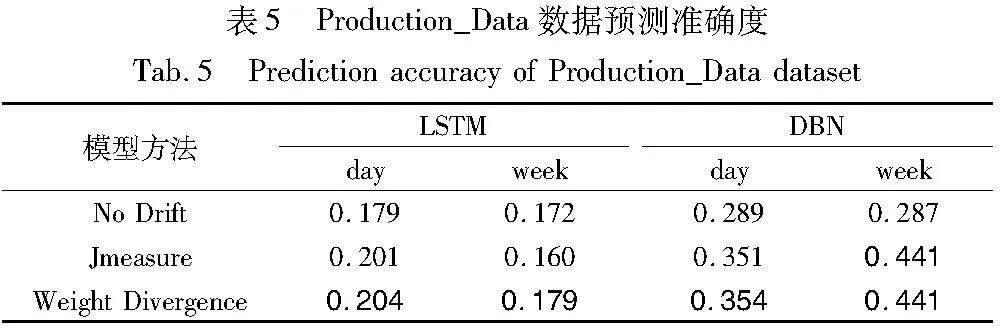
图8(a)(b)是DBN模型预测精确度,图8(c)(d)是召回率。精确度是模型描述的行为在日志中出现多少的程度,而召回率对应的是一致性检查的适合度,即事件日志中有多少迹能够被模型正确描述。本文权重散度的方法在精确度上效果不是很好,然而对于召回率来说,在按天预测中,权重散度最后的结果要优于无漂移检测的方法,并且除了最后的时间段,大部分时间都优于Jmeasure方法;在按周预测中,可以说权重散度的结果优于其他两种方法。表5展示了Production_Data数据集准确度,加粗表示预测最好的结果。由表5结果可知,在Production_Data数据集上利用DBN预测,Weight Divergence预测准确度相比于无漂移检测的方法和已有文献中的漂移检测Jmeasure方法,在按天和按周预测方面分别提高了13.97%、1.493%和4.70%、10.61%。而利用DBN进行预测时,本文方法相较于后两者,在按天中分别提高了22.49%、0.855%和22.49%、0.855%,在按周预测中,本文方法相较于无漂移检测的方法提高了53.66%。
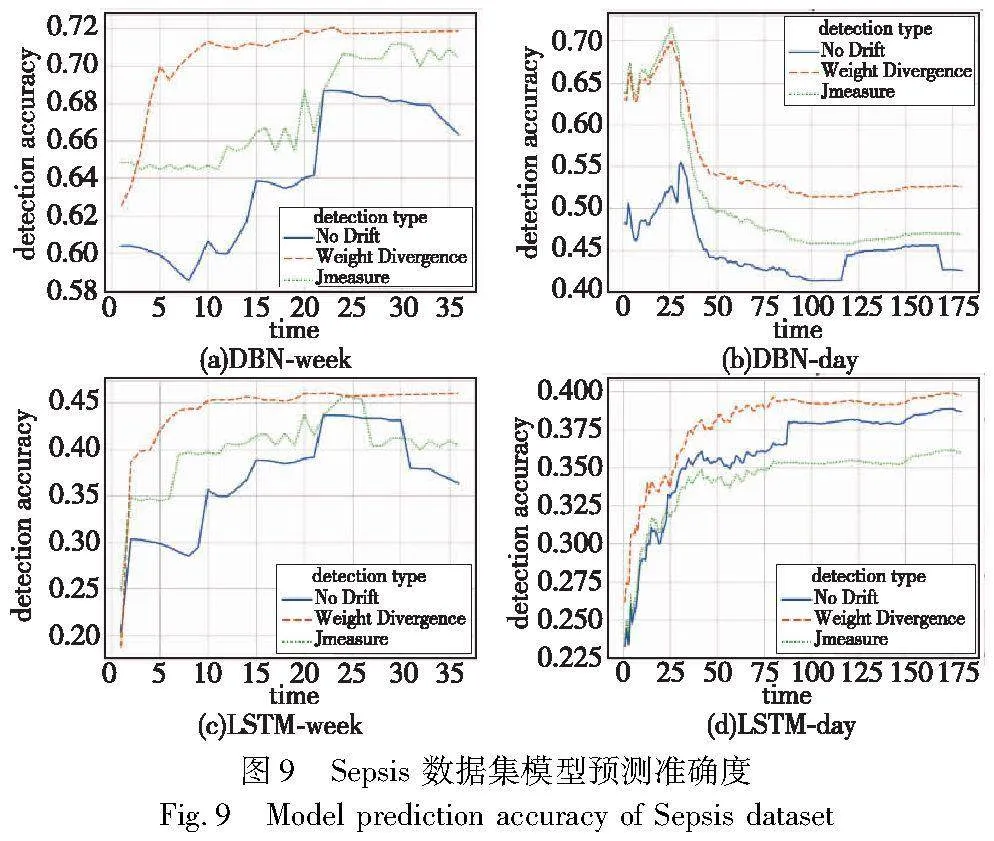
2)Sepsis数据集模型预测结果
图9展示了Sepsis数据集DBN和LSTM模型预测的结果。由图9可以得到对于DBN模型进行预测,采用本文漂移检测的方法刚开始预测效果不是非常好,但最终比无漂移检测和Jmeasure的预测准确度要高,除此之外,按周进行预测的准确度要高于按天预测的准确度。对于LSTM模型来说,本文方法也得到了较好的效果。由于在数字孪生虚拟环境中可以选择所需的机器学习模型或深度学习模型,所以本文只选择了两种在预测准确度上较有优势的模型,从而能够保证本文方法在准确度方面的有效性,并由实验结果可以得到,总体来看DBN模型的预测效果要好于LSTM模型。综上表明,基于概念漂移检测的权重散度方法具有较高的预测准确度。
5 结束语
在本文中,为了创建一个数字孪生模型来预测制造过程中的下一个活动,使用基于概念漂移检测的方法对人工智能的模型(DBN和LSTM)进行了验证,本文提出的基于概念漂移的数字孪生虚拟模型DTBCD不仅有利于制造工业的智能化,还能在制造流程预测中提高效率。此外,基于概念漂移检测的方法有助于应对紧急突发情况的发生。通过实验表明,本文方法在预测性流程监控中显示了良好的结果。数字孪生是当前的一个热点,相关利益者对它的兴趣也在不断增加。随着制造业发生日新月异的变化,预测工业过程的需求也随之增加。使用本文提出的基于概念漂移的数字孪生模型可以帮助更多的企业通过数字孪生技术进行合作。未来的研究可以着眼于提出更好的算法或预测制造流程中的其他内容(如时间、资源等),从而升级该模型,提高其可靠性,并将该模型应用于其他领域。
参考文献:
[1]Liu Mengnan, Fang Shuiliang, Dong Huiyue, et al. Review of digital twin about concepts, technologies, and industrial applications[J]. Journal of Manufacturing Systems, 2021,58: 346-361.
[2]Friederich J, Francis D P, Lazarova-Molnar S, et al. A framework for data-driven digital twins of smart manufacturing systems[J]. Computers in Industry, 2022, 136: 103586.
[3]Xu Yan, Sun Yanming, Liu Xiaolong, et al. A digital-twin-assisted fault diagnosis using deep transfer learning[J]. IEEE Access, 2019, 7: 19990-19999.
[4]Lugaresi G, Matta A. Real-time simulation in manufacturing systems: Challenges and research directions[C]//Proc of Winter Simulation Conference. Piscataway,NJ:IEEE Press, 2018: 3319-3330.
[5]Yang M, Moon J, Jeong J, et al. A novel embedding model based on a transition system for building industry-collaborative digital twin[J]. Applied Sciences, 2022, 12(2): 553.
[6]Chiorrini A, Diamantini C, Mircoli A, et al. Exploiting instance graphs and graph neural networks for next activity prediction[C]//Proc of International Conference on Process Mining. Cham: Springer International Publishing, 2021: 115-126.
[7]Wang Jiaojiao, Yu Dongjin, Liu Chengfei, et al. Outcome-oriented predictive process monitoring with attention-based bidirectional LSTM neural networks[C]//Proc of IEEE International Conference on Web Services. Piscataway,NJ:IEEE Press, 2019: 360-367.
[8]Van Der Aalst W M P, Schonenberg M H, Song M. Time prediction based on process mining[J]. Information Systems, 2011, 36(2): 450-475.
[9]Pauwels S, Calders T. Incremental predictive process monitoring: the next activity case[C]//Proc of International Conference on Business Process Management. Cham: Springer International Publishing, 2021: 123-140.
[10]卢可, 方贤文, 方娜. 基于行为向量的在线事件流预测[J]. 计算机集成制造系统, 2022, 28(10): 3052-3063. (Lu Ke, Fang Xianwen, Fang Nan. Online event stream prediction based on beha-vior vectors[J]. Computer Integrated Manufacturing Systems, 2022, 28(10): 3052-3063.)
[11]Rizzi W, Di Francescomarino C, Ghidini C, et al. How do I update my model?On the resilience of predictive process monitoring models to change[J]. Knowledge and Information Systems, 2022,64(5): 1385-1416.
[12]Qi Qinglin, Tao Fei, Hu Tianliang, et al. Enabling technologies and tools for digital twin[J]. Journal of Manufacturing Systems, 2021,58: 3-21.
[13]Liu Qiang, Leng Jiewu, Yan Douxi, et al. Digital twin-based designing of the configuration, motion, control, and optimization model of a flow-type smart manufacturing system[J]. Journal of Manufactu-ring Systems, 2021, 58: 52-64.
[14]Lugaresi G, Matta A. Automated manufacturing system discovery and digital twin generation[J]. Journal of Manufacturing Systems, 2021,59: 51-66.
[15]Li Lianhui, Lei Bingbing, Mao Chuilei. Digital twin in smart manufacturing[J]. Journal of Industrial Information Integration, 2022, 26: 100289.
[16]Taymouri F, Rosa M L, Erfani S, et al. Predictive business process monitoring via generative adversarial nets: the case of next event prediction[C]//Proc of the 18th International Conference on Business Process Management. Cham:Springer International Publishing, 2020: 237-256.
[17]Lin Li, Wen Lijie, Wang Jianmin. MM-pred: a deep predictive mo-del for multi-attribute event sequence[C]//Proc of SIAM Internatio-nal Conference on Data Mining. Philadelphia,PA: Society for Industrial and Applied Mathematics, 2019: 118-126.
[18]Teinemaa I, Dumas M, Rosa M L, et al. Outcome-oriented predictive process monitoring: review and benchmark[J]. ACM Trans on Knowledge Discovery from Data, 2019,13(2): 1-57.
[19]Hinkka M, Lehto T, Heljanko K, et al. Classifying process instances using recurrent neural networks[C]//Proc of Business Process Management Workshops. Cham:Springer International Publishing, 2019: 313-324.
[20]Pasquadibisceglie V, Appice A, Castellano G, et al. Using convolutional neural networks for predictive process analytics[C]//Proc of International Conference on Process Mining. Piscataway,NJ:IEEE Press, 2019: 129-136.
[21]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc., 2017: 6000-6010.
[22]Wolf T, Debut L, Sanh V, et al. Transformers: state-of-the-art natural language processing[C]//Proc of Conference on Empirical Me-thods in Natural Language Processing: System Demonstrations. Stroudsburg,PA:ACL Press, 2020: 38-45.
[23]Ni Weijian, Zhao Gang, Liu Tong, et al. Predictive business process monitoring approach based on hierarchical transformer[J]. Electro-nics, 2023, 12(6): 1273.
[24]Hennig M C. Transformer for predictive and prescriptive process monitoring in IT service management[C]//Proc of ICPM Doctoral Consortium and Demo Track. 2022: 22-26.
[25]Bose R P J C, Van Der Aalst W M P, liobaitè I, et al. Dealing with concept drifts in process mining[J]. IEEE Trans on Neural Networks and Learning Systems, 2014,25: 154-171.
[26]Abbasi A, Javed A R, Chakraborty C, et al. ElStream: an ensemble learning approach for concept drift detection in dynamic social big data stream learning[J]. IEEE Access, 2021, 9: 66408-66419.
[27]Lee C Y, Wu C S, Hung Y H. In-line predictive monitoring framework[J]. IEEE Trans on Automation Science and Engineering, 2020, 18(4): 1668-1678.
[28]Senderovich A, Di Francescomarino C, Maggi F M. From knowledge-driven to data-driven inter-case feature encoding in predictive process monitoring[J]. Information Systems, 2019, 84: 255-264.
[29]Pauwels S, Calders T. Bayesian network based predictions of business processes[C]//Proc of Business Process Management Forum: BPM Forum. Cham:Springer International Publishing, 2020: 159-175.
[30]Russell S J, Norvig P. Artificial intelligence a modern approach[M]. 2010.
[31]Staudemeyer R, Morris E. Understanding LSTM-a tutorial into long short-term memory recurrent neural networks[EB/OL]. (2019-09-12). https://arxiv.org/abs/1909.09586.
[32]Guzzo A, Joaristi M, Rullo A, et al. A multi-perspective approach for the analysis of complex business processes behavior[J]. Expert Systems with Applications, 2021, 177: 114934.
[33]Adams J N, Van Zelst S, Rose T, et al. Explainable concept drift in process mining[J]. Information Systems, 2023, 114: 102177.
[34]Uddin M J, Li Yubin, Sattar M A, et al. Effects of learning rates and optimization algorithms on forecasting accuracy of hourly typhoon rainfall: experiments with convolutional neural network[J]. Earth and Space Science, 2022, 9 (3): 2021EA002168.
