基于知识表示学习的KBQA答案推理重排序算法
2024-08-17晋艳峰黄海来林沿铮王攸妙



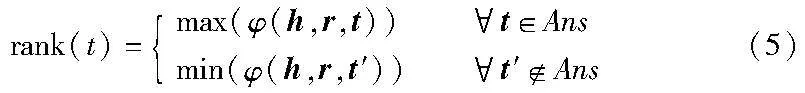








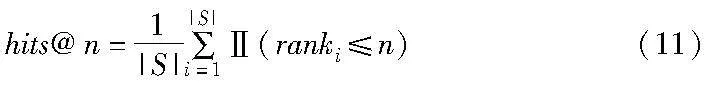

摘 要:现有的知识库问答(KBQA)研究通常依赖于完善的知识库,忽视了实际应用中知识图谱稀疏性这一关键问题。为了弥补该不足,引入了知识表示学习方法,将知识库转换为低维向量,有效摆脱了传统模型中对子图搜索空间的依赖,并实现了对隐式关系的推理,这是以往研究所未涉及到的。其次,针对传统KBQA在信息检索中常见的问句语义理解错误对下游问答推理的错误传播,引入了一种基于知识表示学习的答案推理重排序机制。该机制使用伪孪生网络分别对知识三元组和问句进行表征,并融合上游任务核心实体关注度评估阶段的特征,以实现对答案推理结果三元组的有效重排序。最后,为了验证所提算法的有效性,在中国移动RPA知识图谱问答系统与英文开源数据集下分别进行了对比实验。实验结果显示,相比现有的同类模型,该算法在hits@n、准确率、F1值等多个关键评估指标上均表现更佳,证明了基于知识表示学习的KBQA答案推理重排序算法在处理稀疏知识图谱的隐式关系推理和KBQA答案推理方面的优越性。
关键词:知识库问答; 知识图谱; 知识表示学习; 答案推理
中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2024)07-009-1983-09
doi:10.19734/j.issn.1001-3695.2023.11.0545
KBQA answer inference re-ranking algorithm based onknowledge representation learning
Abstract:Existing research on knowledge base question answering(KBQA) typically relies on comprehensive knowledge bases, but often overlooks the critical issue of knowledge graph sparsity in practical applications. To address this shortfall, this paper introduced a knowledge representation learning method that transforms knowledge bases into low-dimensional vectors. This transformation effectively eliminated the dependence on subgraph search spaces inherent in traditional models and achieved inference of implicit relationships, which previous research had not explored. Furthermore, to counter the propagation of errors in downstream question-answering inference caused by semantic understanding errors of questions in traditional KBQA information retrieval, this paper introduced an answer inference re-ranking mechanism based on knowledge representation learning. This mechanism utilized pseudo-twin networks to represent knowledge triplets and questions separately, and integrated features from the core entity attention evaluation stage of upstream tasks to effectively re-rank the answer inference result triplets. Finally, to validate the effectiveness of the proposed algorithm, this paper conducted comparative experiments on the China Mobile RPA knowledge graph question-answering system and an English open-source dataset. Experimental results demonstrate that, compared to existing models in the same field, the proposed method performs better in multiple key evaluation indicators such as hits@n, accuracy, and F1-scores, proving the superiority of the proposed KBQA answer inference re-ranking algorithm based on knowledge representation learning in handling implicit relationship inference in sparse knowledge graphs and KBQA answer inference.
Key words:knowledge graph question answering; knowledge graph; knowledge representation learning; answer reasoning
0 引言
知识库问答(KBQA)基于实体和实体间关系构建,可以更好地理解用户的语义意图。相比于输入查询返回文档或页面形式的基于搜索引擎的传统问答系统,KBQA可提供更精确的个性化回复。另外基于知识库存储的关系和规则,KBQA可以进行某种程度的逻辑推理,从而为用户提供更深层次的信息和答案。
现有KBQA的理论研究往往基于完善的知识库,在标注了核心实体的复杂问句上进行问答,忽略了实际应用场景中知识图谱的稀疏性,以及实际场景中用户提问形式的复杂多样性。于是,本文针对企业合作项目中国移动RPA业务场景下的KBQA问题进行研究,引入知识表示学习,在复数空间中对知识图谱中的实体和关系进行嵌入,依据ComplEx算法的评分函数评估三元组存在的合理性,从而实现对隐性关系的推理。另外KBQA的传统pipeline,实体识别、实体链接、答案推理通常会被视为一个完整的pipeline,实体识别、实体链接的结果仅保留得分最高项,一旦获取到了错误的实体项,则必然导致下游问答推理任务的错误。基于此,本文引入答案推理重排序机制,将上游任务核心实体关注度与实体链接得分结果作为重要特征融入到答案重排序模型中,基于伪孪生网络对知识三元组和问句分别进行表征,对答案实体集进行重排序,剔除实体所在的错误三元组,纠正上游问句语义理解阶段任务中可能存在的错误。
回溯KBQA解决方案,已经提出了基于语义解析(SP)的方法和基于信息检索(IR)的方法两种主流方法。基于SP的方法首先利用自然语言理解模型识别出问题中的核心实体,并利用实体链技术映射到知识库中真正实体(topic entity),然后将查询转换为一个或多个逻辑形式或中间表示,在知识库上执行转换得到的查询,检索相关信息[1]。基于IR的方法首先识别问句中的主题实体,再在知识图谱库中构建与一个特定于问题和主题实体的子图,该子图包含了与主题实体或问题相关的全部信息,最后通过子图与问题的相关性进行排序,获取得分最优的子图,从而检索到答案[2,3]。
基于SP的方法,将自然语言查询或问题转换为某种形式的逻辑表示,可进一步用于数据库查询、知识图谱检索等。然而,面对复杂的KBQA问题,这些方法在复杂语义的理解、知识库的实例化搜索以及弱监督信号下的训练等方面遇到了很大挑战。
为了应对这些挑战,许多现有基于SP的方法依赖于句法分析技术,例如通过抽象意义表示(abstract meaning representation,AMR),以图形结构捕捉句子核心意义的表示方式,旨在简洁且清晰地呈现自然语言句子的语义内容,从而避免涉及到与该内容不直接相关的句法细节[4,5]。另外利用依存关系,表示单词之间的句法和语义关系,以在问题成分和逻辑元素(例:实体、属性、关系和实体类型)之间提供更高精度的对齐[6,7]。然而对于复杂问题,生成式句法分析的准确率表现一般。为了减弱从句法分析阶段到下游语义分析阶段的错误传播,Sun等人[8]提出了一种基于骨架的句法分析方法,首先通过识别句子的核心结构,对复杂问题的主干进行解析,然后再补充其他详细的句法信息。另外在实际应用中发现,大量精确标注的行业数据往往是有限的、不完美的,常包含噪声和错误。进而研究者提出了弱监督训练,弱监督训练提供了一种更灵活、成本效益更高的方式来训练模型,尤其适用于数据标注成本高、数据不完美的实际应用问题。弱监督通常依赖于噪声较大或不完整的标注,与全监督学习相比,弱监督提供的反馈信号更加稀疏,这可能会导致学习算法很难找到稳健的模型参数。KBQA也常常遇到训练数据有限或未标注的问题,语义解析的输出空间通常很大,导致在弱监督的情况下找到正确的解析结果特别困难。为了应对这些挑战,研究者尝试了多种方法,如数据增强、多任务学习、半监督学习和迁移学习等。文献[4,9]通过采用基于强化学习的方法来获得最大的预期回报。针对弱监督训练可能无法为模型提供明确的反馈以及稀疏正反馈问题,Saha等人[10]提出,当基本事实类型与预测的答案类型相同时,将会附加反馈奖励模型,通过智能体与环境的交互学习,以使累积奖励最大化。Li等人[11]采用类似的思路,通过将语义解析生成的逻辑形式与前阶段缓存的高反馈逻辑形式进行对比,从而实现对生成的逻辑形式的评估。在语义解析的上下文中,除了对整个过程的反馈最终评价之外,弱监督信号下,中间反馈可以为模型提供更详细的指导。Qiu等人[9]提出了一种基于层次化强化学习的框架,利用中间反馈机制为模型训练提供了更细粒度的阶段性指导,从而起到了增强监督信号的目的,也有助于模型更快地收敛。
基于IR的方法,在处理查询或问题时,不需要大量标注数据,可扩展性高,其流程主要包括问题转换、子图生成、子图评估、答案提取等核心环节。问题先被转换为一个或多个实体和与其相关的关系。接着在知识库中探索与其直接或间接相关的实体和关系,生成一个或多个候选子图,最后采用图匹配、语义相似性进行子图评估。选择得分最高的子图,从中提取出实体、关系或一个更复杂的子图答案。对于复杂的KBQA问题,基于IR的方法主要面临不完整的知识库推理、弱监督信号下的训练策略等方面的挑战。
简单的KBQA问题,往往只需要在中心实体的单跳子图上进行推理,采用基于IR的方法对知识库的完全性要求不是很严格[12]。而对于复杂问题,答案可能涉及多个实体及实体间关系,知识库的不完整,可能造成整个推理链的断裂,另外这种不完整性减少了核心实体的邻域信息,给推理过程造成困难。所以针对复杂问题,为了确保子图搜索能够提供准确和有洞察力答案,对知识库的完整度具有较高的要求。
实际应用中,知识库往往是不完整的。或者现有知识库的收集和构建过程可能存在遗漏。因此,对不完整知识库的推理是目前的一个重要研究领域。研究人员利用辅助文本,为知识库提供有价值的背景信息和上下文,填补知识的空白和推理过程。Sun等人[13]提出使用问题相关的文本语料,通过提取新的实体、关系和属性,对不完备知识库进行补充,并将其与知识图谱结合为一个异构图,并基于该图进行推理。文献[14,15]在实体表示中融合额外的非结构化文本,来取代直接将非结构化文本作为知识节点补充到图中的做法。除了引入额外的文本语料外,还可以采用知识图谱嵌入的方法,通过链接预测(linking prediction)对缺失和隐含的关系进行表示。Saxena等人[16]通过先获取预先训练的相似领域知识图谱嵌入,再融合嵌入到目标知识图谱中,来弥补当前特定业务知识图谱的不完整性。
基于IR的方法,在弱监督信号下的训练策略方面,与基于IR的方法类似,也是一个端到端模型,整个问答过程中,模型直到推理结束才能收到反馈。研究者们发现,这种情况可能导致虚假推理[17]。为了缓解上述问题,Qiu等人[9]采用奖励形成策略提供中间奖励,通过计算推理路径和问题表征之间的语义相似性,有效地引导模型在复杂推理任务中作出正确的决策。另外,除了在中间步骤对推理过程进行评估外,还能通过推断伪中间状态,来增强模型训练中的信号。受双向搜索算法的启发,He等人[18]提出了基于图的双向搜索算法,同时从源点和目标点进行搜索,通过同步双向推理过程来学习中间推理实体分布,提供了一种有效的方式来优化和加速复杂图结构上的推理任务。实体链接过程中,使用离线工具进行定位,可能导致上游任务的错误传播到下游的推理任务中。在未标注主题实体的问句中,为了对核心实体准确定位,Zhang等人[19]提出了利用基于知识库的核心实体识别和推理阶段的联合学习算法来训练实体链接,以优化整个问答方法流程。
通过技术的不断改进,基于SP和基于IR的技术,已经在一定程度上满足了用户个性化问答需求。但是基于SP的方法在关系分类的标注上需要投入大量的人力资源,对训练集中未出现过的关系预测能力有限。另外基于SP的方法,在问答知识库关系不完善时会对问答系统准确率和hits@1指标造成较大影响。基于IR的方法相比于基于SP的方法,在生成路径方面具有更强的泛化能力,能够更有效地处理多跳查询问题。在现实业务场景中,知识图谱通常处于不断完善的过程中,经常表现为每个实体节点平均仅与三条边相连。在本次企业合作项目中国移动RPA知识图谱中,关系与实体节点的比例接近1∶1,而较为丰富的知识图谱其实体节点与关系的比例往往在3∶1以上,这显著低于其他较为丰富的知识图谱。这种稀疏性会导致问题理解和答案生成的精确度降低,知识库中的信息不足以支撑复杂的查询和推理。然而,现有研究通常基于完善的知识库,这导致对语义关系信息利用不足,同时忽视了知识图谱稀疏性和实体节点间可能存在的隐含关系。对三元组信息检索和问答推理构成了挑战。
针对以上问题,本文的研究建立在中国移动知识图谱项目上,该项目针对机器流程自动化(robotic process automation,RPA)领域构建知识图谱,并依据该图谱进行知识检索与知识推理。本文主要目标是提出一套知识库问答方法,完成基于RPA领域知识图谱的知识推理问答。首先,在知识表示学习与答案初筛阶段,引入了知识表示学习方法,学习知识图谱在嵌入空间中的表示(SubGraph embedding),建立两个知识节点之间的联系,使得KBQA流程能完成隐式关系的推理,弥补实际业务中知识图谱不完善问题。此外,还训练了一个排序函数,用于实现答案三元组范围的初步筛选。特别地,为了解决KBQA传统流程中问句语义理解阶段的潜在错误传播问题,基于伪孪生网络设计了一个答案推理重排序模型。该模型不仅保留了上游任务的输出结果,并将其作为重要特征输入到答案推理重排序模型中,进一步利用核心实体关注度与实体链接得分标注后续的推理过程。最后,分别在中国移动RPA知识图谱问答系统与英文开源数据集下进行了对比实验,通过与其他模型的横向比较和消融实验,证明了本文算法的有效性。本文的创新之处在于有效解决了知识图谱稀疏性问题,并提高了KBQA系统在处理复杂查询时的准确性和效率。这为实际业务场景下知识图谱问答系统的构建提供了新的视角和解决方案。
1 问题定义
本章将对文中提及的几个核心概念进行形式化定义。这些定义结合了现有研究中的理论基础和本文提出的基于知识表示学习的KBQA答案推理重排序算法在该领域的创新点。
定义1 核心实体。一个问句中可能存在多个实体,核心实体是指问题真正意图,也就是用户询问的真实焦点。该定义融合了现有文献中的概念和本研究对问句意图理解的深化。
定义2 核心实体关注度。对多实体问句,通过核心实体关注度模型计算每个实体的关注度得分,评估自然语言问题中各实体的重要性,旨在解决多实体和多意图问句理解问题。该定义基于现有理论,并结合了本文在处理复杂问句方面的创新方法。
定义3 知识表示学习与答案初筛。通过学习知识图谱在低维的嵌入空间表示(SubGraph embedding),捕获实体和关系之间的语义信息供下游推理任务使用。并利用知识表示学习的结果,基于信息检索方式,使用答案初筛模型完成对答案实体节点所在的top-k三元组集合的初步筛选和保存。该定义是基于现有知识表示学习方法的扩展,以及对本文答案检索过程中创新模型的定义。
定义4 答案推理重排序。旨在弱监督情况下,通过考虑问题中核心实体周围的语义分布和核心实体到答案实体的关系路径来提高推理的精度。对候选答案集合中的三元组链路进行关系表征,并融合核心实体关注度评估阶段的特征,进行答案推理结果三元组的重排序。该定义基于现有弱监督学习、知识表示学习、答案排序等机器学习知识,对本研究在提高推理精度方面的创新方法定义。
2 模型设计与实现
KBQA解决方案中,基于IR的推理方法通常在完善的知识图谱(如FreeBase和Wikipedia)中表现出色。然而,在实际业务应用中,知识图谱常处于不断完善的状态,实体之间的关系通常稀疏且不完整。图谱中的关系的丰富程度不如Freebase等知识库。知识图谱的隐式关系指的是那些在知识图谱中没有直接表示或显式列出的关系,但可以通过推理、分析或推断从已有的知识和关系中间接地推断出来的关联。隐式关系的发现和推理对于知识图谱的应用非常重要,可以通过隐式推理来填补知识图谱中的空白和缺失。
知识图谱隐式推理时,需要考虑知识的可信度、不确定性和可能的错误。受之前EmbedKGQA的启发,通过知识表示学习方法,实现复数空间中对图谱实体和关系的嵌入表示,进而发现图谱中隐含的关联和模式,可以有效地解决稀疏知识图谱推理问题[16]。据此,本文引入知识表示学习来实现隐式关系推理。使用complex embedding将知识图谱中的实体和关系映射到低维向量空间,然后利用ComplEx的复数域得分函数评估构成三元组的合理性;同时基于答案初筛模型训练了一个排序函数,基于该函数给出的得分进行答案三元组范围的大致筛选。
2.1 核心实体关注度计算
核心实体关注度计算,主要包括命名实体识别和实体关注度计算两个阶段。命名实体识别采用了基于规则和基于BERT预训练模型的组合方法。前者根据领域和特定任务定义实体类型、上下文关键词、实体位置等语义规则,再使用模式匹配技术来识别和提取符合规则的实体,得到的候选实体Mention存储至集合Ce1中。该方法可解释性强,在特定任务和领域内提取实体具有较高的准确性。
基于BERT预训练语言模型提取Mention实体,首先,将每个字(词)通过BERT预训练模型向量化表示,将问句文本转换为token序列,再经过模型嵌入层,token序列被转换为多维向量。最后通过全连接层对每个token进行二分类表示,判断每个token是否可能是一个实体mention。若是,token被标注为1;若不是,则标注为0。该实体抽取方法能够提供深入的语义理解和捕获丰富的上下文信息,有助于更准确地识别语境中的实体。得到的候选实体mention存储至集合Ce2中。对候选实体集合Ce1,Ce2取并集,即得到最终的实体mention集合Ce。
获取到实体mention之后,将进行实体关注度计算。首先对问句文本Q进行tokenize,使用RoBERTa模型完成词嵌入,获取问句token的embedding,记作Q′。接着对句子中的每个实体,使用注意力打分函数来计算其与整个句子的相关性,打分函数采用神经网络加性实现。注意力分数ei计算公式为
ei=vTtanh(WqQ′+WkCei+b)(1)
其中:Wq、Wk、v和b为可学习参数;Q′表示问题向量;Cei表示实体mention向量。
使用softmax函数对注意力分数进行归一化,使得所有实体的注意力分数之和为1。得到归一化的注意力权重值αi,再通过maxpooling和avgpooling的拼接池化层,以尽可能保留注意力信息,获取每个mention的注意力分布。最终映射至句子长度同维度的向量,根据每个实体的注意力分数,对所有实体的特征向量加权组合,进而得到最终的加权特征表示,在加权组合的特征表示中,权重最大的实体被视为句子的核心实体。
考虑到缺乏专业知识的用户在输入问句时,可能会出现简写、误写、漏写,导致模型得到的实体是不规范的或者一个实体mention对应多个实体项。为了解决这个问题,在识别到问句的核心实体后,会基于同义实体库进行实体链接。通过计算问句中实体与同义实体库的相似性得到实体链接得分,作为特征值传输到下游任务中。实体链接语义相似度得分计算公式为
score(Cei)=similarity(Q′,vec(E))(2)
其中:相似度计算采用BERT+FC模型;Cei表示得到的每个实体mention;vec(E)表示知识库中的实体向量。为减弱下游任务对上游实体识别、实体链接任务输出的依赖,取模型score得分最高的五个实体mention作为候选实体,当实体链接模型出错时,依然可以通过答案推理重排序模型予以纠正,返回正确的推理结果。
2.2 知识表示学习与答案初筛
答案初筛模型基于知识表示学习的结果对相关的子图依据问题的表征进行答案三元组的初步筛选。基于文献[20]直接筛选top1候选三元组作为答案返回的做法,考虑到上游问句理解任务的错误可能会对答案实体造成影响,本文引入了答案推理重排序机制,不完全信任于pipeline上游问句语义理解任务的输出,而是将上游任务的输出作为特征融入到下游问答推理阶段的模型中,基于伪孪生网络对知识三元组和问句分别进行表征,实现答案推理结果三元组的重排序,对实体所在的错误三元组进行筛选和剔除。从而使得正确的三元组作为答案项返回。该部分框架如图1所示。
2.2.1 知识表示学习
知识表示学习的目的是将知识图谱中的实体和关系嵌入到连续的低维空间中。常用的模型有complex embeddings(ComplEx)[21]、TransE、全息嵌入(HolE)和RESCAL等。TransE模型简单,计算高效,但是对一对多、多对一、多对多的关系建模存在困难[22]。HolE模型,参数量上更加高效,但是往往不如其他复杂模型的表现力[23]。RESCAL在捕获复杂关系上更具表现力,但是需要的参数量大,易容易导致过拟合和计算上的开销[24]。ComplEx是一个复数嵌入模型,可以很好地处理对称、反对称、传递等多种关系,模型在语义匹配方面通常能获得更好的结果。另外与其他模型相比,它有更少的参数,更方便工程实践。因此本文采用ComplEx算法,将实体和关系表示为复数向量,在连续的低维向量空间进行嵌入。对每个候选三元组,记作(h,r,t),h,t∈E,r∈R(E为知识图谱中的实体节点集,R为边的集合),并定义一个得分函数(score funcJssN+hUNlrh4ICs5UkcyGSTFv4qh/m0JYvtHS1SGDq8=tion),如式(3)所示。
其中:νh,νr,νt∈Cd,分别表示头实体、关系和尾实体的复数向量嵌入;d表示嵌入的维度;Re表示取复数的实部。若是一个真实的三元组,则socre(h,r,t)其得分应该相对高;否则得分相对低。
2.2.2 答案初筛
在答案初筛模型中,首先根据问句理解核心实体关注度模型得到的实体,通过知识表示学习模型,获得实体子图,从而输出实体节点以及所有可能答案实体节点在连续的低维向量空间的嵌入集合,分别记作核心实体向量h和候选答案实体向量t。核心实体向量h代表问句中核心实体的嵌入向量,用于捕获问题的主要焦点。候选答案实体向量t(其中t∈T),代表知识库中可能的答案实体的嵌入向量。另外通过组合网络对question进行问题表示,以获取关系表示向量r。
问题表示网络由一个RoBERTa语义表示层、一个BiLSTM层和一个注意力计算层构成,共同实现对问题的深度理解和有效的关系表征。RoBERTa作为预训练模型,融合了先验的自然语言特征,借助Transformer强大特征抽取能力,通过上下文语境实现相应字符的动态嵌入向量表示。为BiLSTM层提供一个可靠高质量,具有丰富语义信息的输入向量。BiLSTM作为一种特殊的RNN,凭借其特殊的门控机制以及细胞结构,能够有效捕获长距离依赖关系,这对理解长问句中的复杂语义非常重要。尤其在处理包含多个实体的问句时,BiLSTM的双向结构能够同时考虑前后文信息,从而在理解问句的整体含义方面表现更佳。在BiLSTM层之后,引入了一个注意力机制层来捕获更有价值的特征。通过注意力机制能够赋予不同语言单元不同的权重,聚焦于问句中最关键的部分,能够更有效地捕获与问句关系表征相关的特征,进而提升复杂自然语言问句中关系抽取的精确度和效率。通过结合RoBERTa、BiLSTM和注意力机制,问题表示网络不仅能够提供丰富的语义理解,还能够精确地抽取与问题相关的关键信息。模型的组合有效提升了自然语言处理任务中的性能,尤其是在理解复杂问句和抽取关系方面。该网络获取到关系向量r的过程如式(4)所示。
r=SelfAttention(BiLSTM(RoBERTa(Q)))(4)
将得到的问句关系表示向量r,综合上游问题理解任务得到的核心实体向量h以及候选答案实体向量t,通过式(3)的score评分函数,来评估三元组的合适程度。得分越高意味着核心实体、问题中隐含的关系和候选答案节点更可能组成一个三元组。即向量t对应的实体是正确答案的概率就较大。相对地,得分较低则意味着候选答案节点与实体和问题关系的关联较弱,不太可能形成三元组。通过学习一个得分函数rank(t)来计算候选答案的得分,损失函数采用二元交叉熵(binary crossentropy),最大化正确答案实体得分,最小化错误答案实体以及无关实体得分,如式(5)所示。
上游问句理解阶段,可能会出现实体识别的错误。因此在这一环节中并不直接返回得分最高的答案实体节点,而是选择得分位于top-k的答案实体节点,将这k个得分最高的实体节点作为潜在的答案节点,实现三元组的粗过滤。接下来,在答案推理重排序模型中进行再次筛选。
2.3 答案推理重排序
KBQA的传统pipeline中,实体识别、实体链接、答案推理通常会被视为一个完整的pipeline。一般研究中,实体识别、实体链接阶段的结果仅保留得分最高项,但如果该阶段得到了错误的实体项,则必然导致下游问答推理任务的错误。根据中国移动业务场景下的实际用户查询,发现用户的问题往往是复杂多样的,经常会出现一个问题中有多个实体项。若参照文献[20]直接筛选top1候选三元组作为答案返回,该三元组的头实体可能并非用户所提问的核心意图。另外虽然中文pipeline中实体识别和实体链接都采用了深度学习模型,模型准确率较高,但仍可能得到错误的实体项,将会导致下游推理任务的错误[25,26]。故而引入答案推理重排序阶段,以融合上游任务中的输出信息,进一步对答案初筛模型输出的答案实体集合进行筛选。
基于此,本文将上游任务的输出结果进行保留,并作为特征输入到答案推理重排序模型中,使用核心实体关注度与实体链接得分对后续的推理过程进行标注,对答案初筛模型得到的候选答案实体集合进行精排。即便上游任务中得到了错误的实体项,通过答案推理重排序模型,依然可以对这些实体所在的错误三元组实现筛选和剔除。答案推理重排序模型使用伪孪生网络,通过两个网络分别对知识图谱结果和问句进行处理,解决问答领域相似度计算问题。答案推理重排序模型的框架如图2所示。
对问句的表征向量表示,首先通过对RoBERTa微调,实现问句编码的语义嵌入,BERT系列模型中,Token[CLS]蕴涵了整句话的语义信息,因此取Token[CLS],代表整个句子信息,用于下游任务的输入。接着引用BiLSTM,对向量Token[CLS]进行特征增强。最后通过全连接层,将处理过的[CLS]向量压缩到与KG处理部分输出的向量具有相同的维度。问句经过该模型得到问句向量的过程vq,如式(6)所示。
vq=FC(BiLSTM(RoBERTa(Q)))(6)
对知识图谱的表征向量表示,首先使用知识表示学习模型中得到的实体和关系嵌入,对知识图谱中三元组关系进行embedding,接着送入BiLSTM表征层得到一个关系内容向量,记作vrc,该过程如式(7)所示。Tri表示经过答案初筛模型中获取到的top-k三元组中的第i个三元组。
vrc=BiLSTM(KGEmbedding(Tri))(7)
接着,将该关系内容向量vrc与核心实体关注度模型得到的前期特征共同进行注意力计算。前期特征,主要包括核心实体关注度计算得分α以及实体链接得到的问句中实体与知识库中的实体语义相似度计算得分score。计算获取到知识图谱处理模型的输出vt,该过程如式(8)所示。
vt=attention(vrc,(α,score))(8)
通过式(6)(8)两个网络编码分别得到了三元组在问句中的表征向量vq和在知识图谱中的表征向量vt。通过欧氏距离对两向量计算相似性,vt和vq的相似性越高,则最终输出越接近于1,反之则越接近于0。为了将最终的输出约束在(0,1],使用了以e为底数的函数,如式(9)所示 。
反向传播中使用constrastive loss作为损失函数。constrastive loss损失函数目标是学习一个距离函数,使得相似样本之间的距离小,而不同样本之间的距离大。constrastive loss损失函数的表达式如下:
通过距离计算方法,可以处理伪孪生神经网络中的paired data从而衡量成对样本的匹配程度。其中y∈[0,1]为两个样本是否相似的标签,d代表两个向量的欧氏距离,η为预先设定的阈值。y值越大,表示问句表征的关系与知识图谱三元组表征的关系匹配度越高。当y=1,表示完全匹配,可以看出此时的损失仅跟距离d有关,为了最小化损失函数,d越小则表明当前模型效果较好。当y=0,则表示样本不相似,损失函数只剩下L=max(η-d,0)2,此时为了最小化损失函数,距离d反而应该越大。符合伪孪生网络需求。
最后,对伪孪生网络中得到的各个三元组与原问句Q的相似度得分进行排序,选择相似度得分最高的top1三元组中的答案节点实体作为最终答案输出。完成基于伪孪生网络对知识三元组和问句分别表征的答案推理重排序。
2.4 迁移学习策略
实际业务全新领域下,数据规模往往较小,知识图谱不够完善。而本节涉及的模型都较为复杂,且每个模型的参数量都来到了亿级别。可见基于有限的非结构化语料实现精度较高的KBQA系统,这是业界在KBQA方面落地的难点。中国移动的业务场景下,仅仅提供了一个万级别字符长度的用户手册,以及百级别的QA对,如果直接使用如此大参数量的模型进行训练和预测,加上KBQA模型中间的监督信号比较弱,很大可能导致严重的过拟合或预测错误。因此引入迁移学习来解决KBQA冷启动问题。先基于外部语料库CCKS2021生活服务领域知识图谱万级别问答数据集上进行了预训练。冻结部分网络层后在中国移动问答语料上进行模型微调。
采用迁移学习策略,对于那些难以获取大量标注数据的领域,迁移学习允许使用较少的标注数据仍然获得很好的性能。另外由于大部分权重都是从预训练模型中继承的,所以只需要微调模型,从而节省了大量的计算资源和时间。预训练模型首先在多个任务和数据集上进行训练,因此能够捕获更多的通用KBQA特征,再迁移至特定情景下的语料,有助于新任务的泛化,模型不仅能满足通用的KBQA需求,也能预测RPA领域专有的语料。在商业应用和实际场景下,往往有不断扩大语料甚至将系统迁移至其他领域的需求,快速得到一个可使用模型很关键。在预训练的策略下,将模型迁移至其他领域不需要付出过多的额外训练成本,可以迅速部署模型并对其进行微调以满足特定的业务需求。
英文问答模型的部分,由于MetaQA语料本身训练集的数据条数已经达到20万以上,故本文的英文问答模型直接在MetaQA数据集上进行训练。
3 实验
3.1 数据集
中文数据集采用企业合作伙伴中国移动提供的RPA用户指南数据,指南以非结构化文本的形式描述了用户可能遇到的问题、详细描述、原因剖析和应对措施。从RPA用户指南抽取实体、属性、属性值174个,考虑到RPA用户指南数据量较少,通过内部资源、外部资源等渠道对RPA用户指南问答数据进行了整合和扩充。内部资源整合包括中国移动内部已有的RPA文档、用户案例研究文档、最佳用户实践指南。外部资源汇集了来自RPA技术提供商、行业论坛、专业社区和用户反馈的相关资料。整合后问答数据扩充至5 968条。
由于移动方提供的数据资料有限,为防止出现严重的过拟合或预测错误,所以结合了迁移学习的方法,采用CCKS2021移动运营商知识图谱问答数据集作为补充。该数据集共计8 500条问答数据,包含问题、对应的实体节点、答案节点、供参考的SPARQL查询(含实体、属性等信息)。CCKS2021的移动运营商知识图谱问答数据集为中间步骤提供了部分答案,有效地解决了KBQA端到端模型中中间监督的不足,可以实现对pipeline中每个模块的独立训练。将CCKS2021移动运营商知识图谱问答数据集按照80%、10%、10%进行了训练集、验证集、测试集的划分,以该语料下训练得到的模型作为初步的问答模型,并迁移至RPA知识图谱领域的问答中。在5 968条中国移动PRA用户指南问答数据上选取2 984条数据用于模型微调,并选用2 984条数据进行测试。
英文数据集采用开源的MetaQA(movie text audio QA)数据集,MetaQA的数据主要来源于Facebook的MovieQA。该数据集中的问题包含三种类型,按问题所涉及的知识图谱跳数,分为1-hop、2-hop和3-hop。回答1-hop的问题,只需考虑一个实体和它的直接关系,而2-hop或3-hop问题则涉及更复杂的关系链。
鉴于MetaQA数据集中的主题实体已有标注,为了检验本研究上游问句理解任务中核心实体关注度评估模型的表现,本文所用数据移除了MetaQA数据集中问句实体的标注,并基于字符串匹配规则将问句转换为陈述句,使用and、but、while连接前后句,共构造了800 000条多实体问句,按照80%、10%、10%划分为训练集、验证集、测试集。
3.2 对比实验
本节将利用上文描述的处理后的中英文数据集,与目前表现较好的PullNet、EmbedKGQA、TransferNet等模型进行对比实验。评估指标采用hits@1指标进行计算。hits@n指标常用于知识图谱补全和推荐系统等领域。该指标衡量模型预测结果的前n个条目中是否包含正确的答案或项。若hits@3为0.9,表示在90%的测试样本中,正确答案都位于模型预测的前三位。hits@n指标的计算如式(11)所示。
其中:S为三元组集合;|S|表示三元组集合大小;Ⅱ(ranki≤n)为指示函数,检查第i个样本的正确答案是否在前n个预测中。如果是,则该函数值为1;否则为0。
3.2.1 中文数据集
中文数据集部分,采用RPA知识图谱问答下的2 984条数据作为测试集语料,将本文提出的基于知识表示学习的KBQA答案推理重排序算法模型与传统的pipeline、pipeline加特征融合方案,以准确率作为评估指标,分别进行测试,具体结果如表1,加粗数值为列表中的最优值(下同)。
从表1明显看出,本文算法在RPA问答数据集的预测性能更为优秀,准确率相较于传统pipeline提高了12.8%。相较于特征融合方案提高了4.5%。考虑到RPA问答数据集语料较少,可能存在实验结果的偶然性,又基于CCKS2021运营商知识图谱问答数据集,将本文提出的基于知识表示学习的KBQA答案推理重排序模型与传统的pipeline及CCKS知识图谱问答竞赛的top3方案[25],以F1为评估指标,分别进行了对比实验。结果如表2所示。
由表2中的预测结果可以看出,本文模型显著超越传统pipeline,F1值提高了21.9%,但相较于竞赛的top3方案有一定差距,与最优的基于特征融合的中文知识库问答方法,F1值相差1.48%。分析原因如下:
a)在实体链接的过程中,部分数据出现了异常。尽管链接到了正确的实体项,但通过SPARQL查询时无法找到这个实体的子图。
b)数据集里有相当一部分的问句包含了特定的条件,比如“蚂蚁金服最新的融资额是多少?”,含有限制条件的问句占比为3%,在测试集中存在23个句子有限制条件。
c)数据集中与答案无关的干扰实体项较少,所链接的实体大多与答案实体存在三元组的联系。
3.2.2 英文数据集
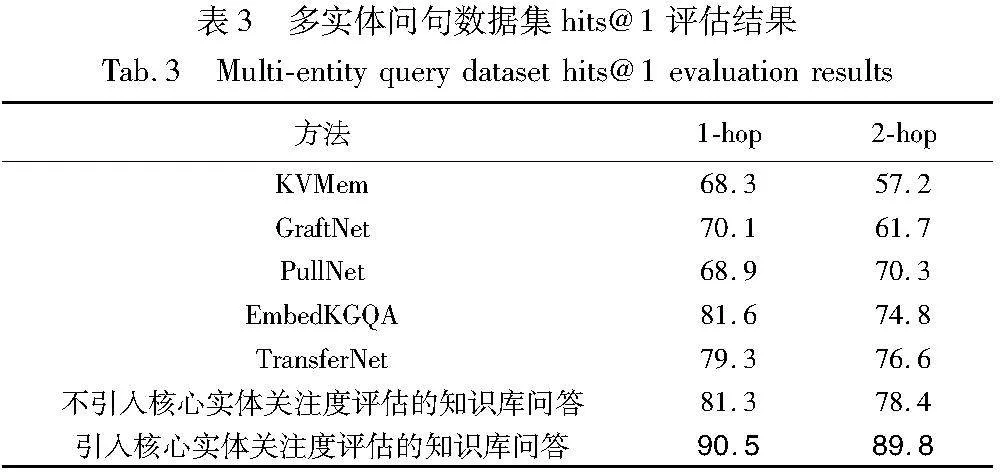
英文数据集部分,基于MetaQA原数据集和原知识库构造的多实体问句,以hits@1作为评估指标,对多实体问句数据集MetaQA测试集的1-hop、2-hop问句分别进行评估,评估结果如表3所示。
由表3可发现其他模型在处理含有多个实体和关系的复杂句子时性能明显下降,尤其在2跳问句的预测上更为明显。这表明通过引入核心实体关注度评估,可以显著提高问答准确率。1跳问句中,核心实体关注度评估的引入使得hits@1值从81.3%提升到了90.5%。2跳问句中,核心实体关注度评估的引入使得hits@1值从78.4%提升到了89.8%。原因在于,多实体关系会引入过多的实体关系信息,造成干扰并增加句子的语义复杂度。一般模型在区分多实体问句中各实体的重要性和关联度上存在局限,导致无法有效聚焦于关键实体。本文通过引入核心实体关注度计算模型,能够更精确地理解句子的主要焦点,提高实体识别的准确率。尤其在复杂句子中,关注度评估有助于过滤掉不相关的信息,减少噪声对实体识别的干扰,模型可以将更多资源集中于重要实体的识别上,从而提高整体处理效率。另外关注度评估的引入能够增强模型对句子的上下文理解,以及复杂句子结构的隐含语义理解。
为了验证本文模型在不完整知识图谱上问答推理的有效性,参照文献[20],对MetaQA数据集进行了50%的随机移除,来模拟一个稀疏的知识图谱(称为50%KG)。分别在50%KG的MetaQA数据集下,与表现较好的KVMem[26]、GraftNet[27]、PullNet[13]、EmbedKGQA[16]、TransferNet[28]等模型进行对比实验。表4中,括号内的数值为50%KG图谱下使用额外MetaQA文本对图谱补充的预测结果(实验结果数据源于文献[13,14,29,30]),括号外的数值为50%KG图谱上预测的结果(实验结果数据源于文献[20])。具体对比结果如表4所示。
由表4可见,在非完整的50%KG下MetaQA数据集上,其他模型的准确性均显著降低,EmbedKGQA模型在hits@1的评估结果上,远高于除TransfetNet方案外的其他模型,同时本文模型相较于EmbedKGQA模型,在1-hop、2-hop、3-hop上均取得了更优的效果。原因在于MetaQA的知识图谱本身的KG较为稀疏,拥有43 000个实体,而三元组数量为135 000个。当删除了50%的三元组后,每个实体平均只与1.66条边相连,图谱变得更加稀疏。这导致很多问题寻找答案实体的路径更长。KVMem模型虽然擅长存储和检索信息,但在多跳推理和稀疏环境中面临信息覆盖不足的问题。尽管GraftNet和PullNet模型擅长整合文本和知识图谱信息,但在稀疏知识图谱上往往难以找到足够的关联信息,导致推理链路不完整,表现较差。相较于GraftNet和PullNet,EmbedKGQA模型在研究多路径知识图谱嵌入方面,不只关注了深度搜索路径问题,还兼顾了邻居节点信息聚合的广度路径搜索。因此EmbedKGQA模型在执行稀疏KG的多跳问答任务上表现较优。但是EmbedKGQA主要依赖知识图谱的嵌入表示,稀疏图谱存在嵌入质量不佳问题,进而影响答案的准确性。TransferNet模型专注于实体链接和关系预测,它在处理具有明确实体和关系的问题时表现良好,但在处理多跳问题时,由于每一跳都需要精确的实体和关系匹配,而稀疏图谱导致关键信息的缺失。所以TransferNet在稀疏知识图谱上的表现大幅度下降。
可见使用传统的基于信息检索的多跳推理方法,很多问题的中心实体需要经过更长的路径才能达到其答案节点,问答推理性能不佳。因此本文模型通过引入额外的文本语料对关系进行补充,来提高模型性能。利用知识图谱嵌入将实体和关系的丰富语义信息编码为低维向量,能有效捕获知识图谱中的隐含信息。在稀疏知识图谱环境下,脱离了子图搜索空间的约束,即使直接的信息链路不完整,本文模型仍能利用这些嵌入来推理出问题的答案。此外,嵌入方法还有助于减少对直接、显式链接的依赖,从而在处理多跳问答时更为灵活。
综上,本文模型在多实体问句上的表现显著优于其他先进模型,说明本文模型通过引入注意力机制的动态聚焦能力,根据上下文变化动态调整对不同实体的关注程度,进而在处理多实体复杂句子时,能够更有效地识别出最关键的信息。另外,本文模型在50%KG的MetaQA知识库上的预测结果也优于先进模型EmbedKGQA,说明在不完整知识图谱上本文模型具有更强的链接预测能力,能够完成对缺失边的隐式关系推理,进而寻找到正确的三元组并提取答案。
3.3 模型选型实验
3.3.1 知识表示学习与答案初筛模型
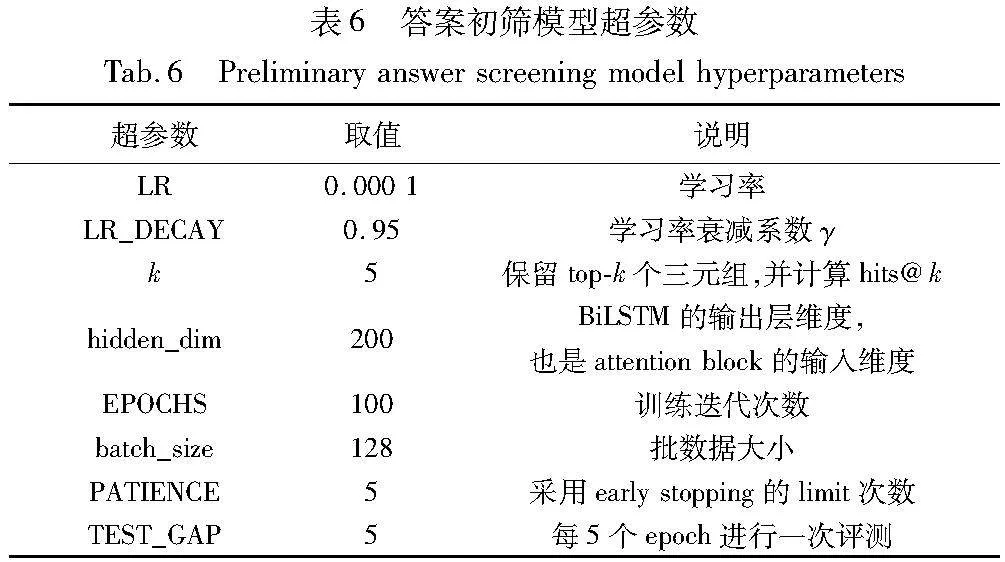
本节对知识表示学习和答案初筛部分进行实验,实验中经过精细化调参,确定了知识表示学习模型和答案初筛模型的超参数。具体如表5、6所示。
答案初筛阶段,使用hits@k和hits@1两种评估指标。hits@1主要目的是在消融实验中检验答案推理重排序模型的性能。hits@k为模型筛选到top-k候选实体中包含答案实体的概率,为该模型的核心评估指标。
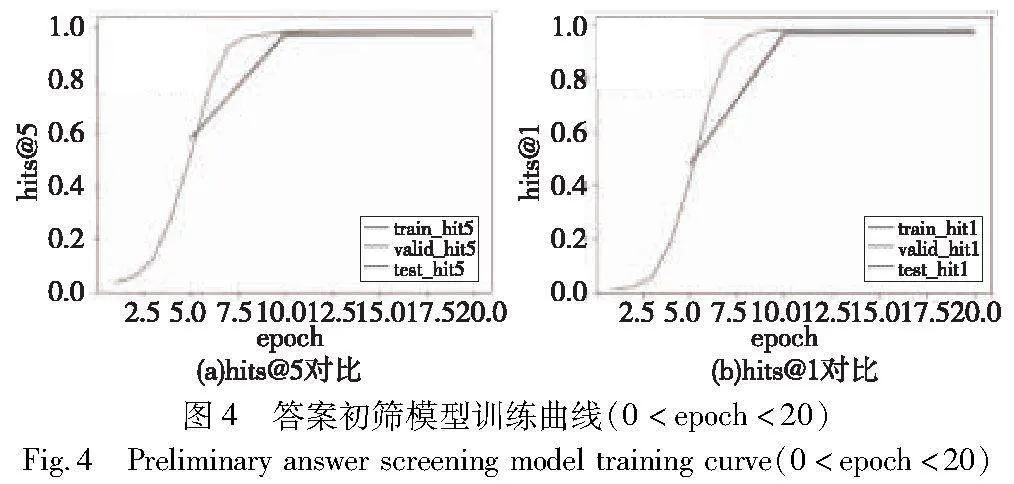
在英文数据集MetaQA上1-hop训练数据上,取k=5,随着epoch的增长在训练集、检验集和测试集上的hits@1和hits@5训练曲线图,分别如图3、4所示。
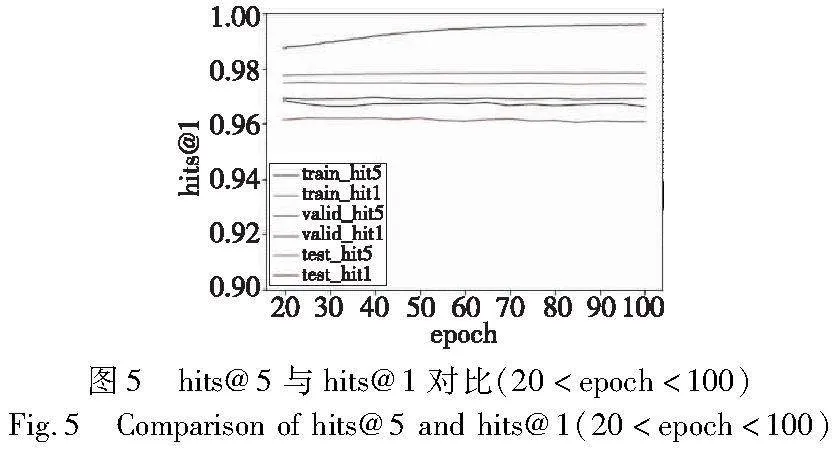
从训练图表中可以观察到,hits@5和hits@1的值在训练轮次epoch=10以前,有显著的增长。当epoch超过10后,两值的增长开始减缓并逐渐稳定。因此,本研究选择epoch=20时的模型作为该阶段的最终模型。
对比epoch=20后的hits@5与hits@1指标,可发现,在验证集和测试集上,hits@5与hits@1之间的差值介于(0.6%,1.1%)。平均来看,hits@5的表现超过hits@1约0.84%。具体如图5所示。
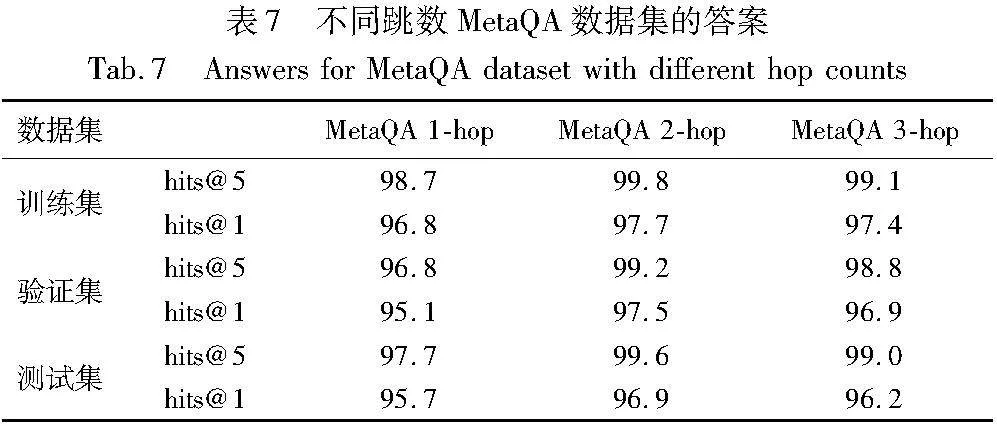
通过实验,发现在MetaQA上2-hop、3-hop数据集上有着类似的训练曲线,具体结果指标数据,如表7所示。
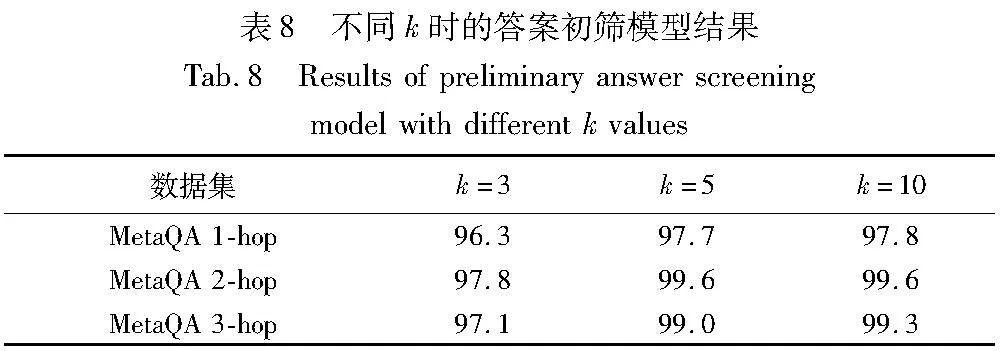
答案初筛阶段,需要选取top-k的三元组,将其作为潜在答案节点,实现粗过滤。K的不同取值对top-k中的答案召回以及后续的重排序模型精度均有影响。本节取不同的k值,来对比具体实验效果。k=3、k=5、k=10时的hits@k,如表8所示。
由表8对比可知,在不同跳数MetaQA数据集上,k=5时的hits@k明显高于k=3,可以判断出部分正确三元组出现在答案初筛阶段排序的第四和第五名,从而使得hits@k指标在k=5时表现更优。再对比hits@k在k=5和k=10时的表现,发现最大差异0.3%,最小差异0%,差异不大。可以推断出,由于问句语义理解阶段的错误或问句本身复杂难以理解,当k继续增大时,hits@k的表示也无法再继续显著提升。另外考虑到k值越大,候选三元组保留越多,会降低答案推理重排序模型效率。为了兼顾模型的效率和表现效果,所以选择k=5,作为该阶段的最终模型参数,即保留top-5三元组作为答案初筛模型的输出。
3.3.2 答案推理重排序模型
本节对答案推理重排序模型进行实验,实验中经过精细化调参,确定了答案推理重排序模型的超参数。具体如表9所示。
答案推理重排序阶段,使用hits@1作为最终的评估指标,将模型预测得到的最高排名答案实体id与知识库中存储的答案实体项进行链接,并与正确答案进行比对,来验证问答的准确率。
以MetaQA上1-hop训练数据为例,随着epoch的增长,hits@1在训练集、检验集和测试集上的表现效果如图6所示。图6(a)(b)分别对应训练100 epoch和20 epoch时,hits@1指标在训练集、验证集和测试集的变化。
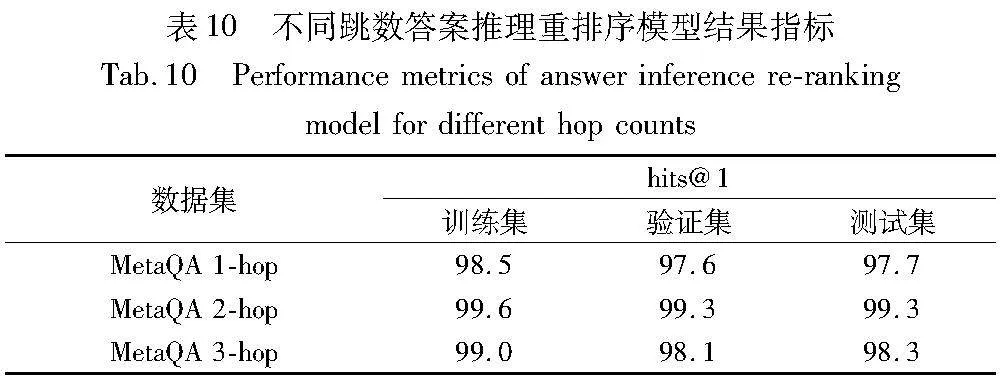
从训练曲线可以看出,epoch=15之前,hits@1值有显著的增长。当epoch值超过15后,hits@1增长开始减缓逐步趋于平缓。因此,本文选择了epoch=20时的模型作为答案推理重排序阶段的最终模型。同样,在MetaQA的2-hop和3-hop训练数据中,也观察到了相似的训练趋势,具体结果指标数据,如表10所示。
4 结束语
本文提出了基于知识表示学习的KBQA答案推理重排序算法,侧重解决真实业务场景下由于知识图谱稀疏,对问题推理造成阻碍的问题。常规基于信息检索的推理模型往往从实体出发,对实体所在知识库中的子图进行检索,对知识库中的隐式关系缺少分析,造成主题实体到答案实体的路径寻找缺失或与真实答案不相关。本文通过引入知识表示学习,在复数空间实现知识图谱中实体和关系的嵌入,依据ComplEx的复数域得分函数评估构成三元组的合理性,实现对知识图谱中的隐含关系推理。并基于答案初筛模型实现top-k候选答案三元组的粗筛。
此外创新性地基于伪孪生网络,实现了答案推理重排序。将上游核心实体识别任务的输出作为特征融入到下游问答推理阶段的模型中,对答案实体集进行重排序。解决了传统pipeline中,问句语义理解对下游问答推理的错误传播。相较于直接计算三元组和问题语义相似度,孪生网络能够同时表征两者,将知识表示学习模型中得到的三元组嵌入与问句语义解析得到的问句低维向量实现更加精准的距离计算,并且通过对模型的训练能够充分保留三元组和问题中原有的隐含语义、语境等特征。本文提出的基于知识表示学习的KBQA答案推理重排序模型,在CCKS2021运营商知识图谱问答数据集上的表现效果,相对于该竞赛的top方案,其性能略显不足。经分析发现多数bad case都分布在含有限制条件问句的预测上,而模型中并没有对限制条件进行约束,对限制条件添加约束是本文模型未来需要继续优化研究的一个方向。另外,中国移动方提供的非结构化数据很有限,尽管模型训练过程中使用了迁移学习,但是模型更多学习到的仍是通用KBQA属性,而非RPA语料库的专有问答特征。如何快速调整模型以适应各种业务环境的语境,以及在专业领域数据稀缺的情况下如何实施小样本学习,也是未来研究需要改进的方向。
参考文献:
[1]Ghorbanali A,Sohrabi M K,Yaghmaee F. Ensemble transfer learning-based multimodal sentiment analysis using weighted convolutional neural networks[J]. Information Processing & Management, 2022, 59(3): 102929.
[2]Fan Yixing, Xie Xiaohui, Cai Yinqiong, et al. Pre-training methods in information retrieval[J]. Foundations and Trends in Information Retrieval, 2022,16(3): 178-317.
[3]Lin J. A proposed conceptual framework for a representational approach to information retrieval[J]. ACM SIGIR Forum, 2022, 55(2): article No.4.
[4]Abbasiantaeb Z, Momtazi S. Text-based question answering from information retrieval and deep neural network perspectives: a survey[J]. Wiley Interdisciplinary Reviews: Data Mining and Know-ledge Discovery, 2021, 11(6): e1412.
[5]Venant A, Lareau F. Predicates and entities in abstract meaning representation[C]//Proc of the 7th International Conference on Depen-dency Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2023: 32-41.
[6]Luo Kangqi, Lin Fengli, Luo Xusheng, et al. Knowledge base question answering via encoding of complex query graphs[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 2185-2194.
[7]Kapanipathi P, Abdelaziz I, Ravishankar S, et al. Question answe-ring over knowledge bases by leveraging semantic parsing and neuro-symbolic reasoning[EB/OL]. (2020-12-03). https://arxiv.org/abs/ 2012.01707.
[8]Sun Yawei, Zhang Lingling, Cheng Gong, et al. SPARQA: skeleton-based semantic parsing for complex questions over knowledge bases[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 8952-8959.
[9]Qiu Yunqi, Wang Yuanzhuo, Jin Xiaolong, et al. Stepwise reasoning for multi-relation question answering over knowledge graph with weak supervision[C]//Proc of the 13th International Conference on Web Search and Data Mining. New York: ACM Press, 2020: 474-482.
[10]Saha A, Ansari G A, Laddha A, et al. Complex program induction for querying knowledge bases in the absence of gold programs[J]. Trans of the Association for Computational Linguistics, 2019, 7: 185-200.
[11]Li Tianle, Ma Xueguang, Zhuang A, et al. Few-shot in-context lear-ning for knowledge base question answering[EB/OL]. (2023-05-04). https://arxiv.org/abs/2305.01750.
[12]Gao Feng, Ping Qing, Thattai G, et al. Transform-retrieve-generate: natural language-centric outside-knowledge visual question answering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5057-5067.
[13]Sun Haitian, Bedrax-Weiss T, Cohen W W. PullNet: open domain question answering with iterative retrieval on knowledge bases and text [EB/OL]. (2019-04-21). https://arxiv.org/abs/1904.09537.
[14]Xiong Wenhan, Yu Mo, Chang Shiyu, et al. Improving question answering over incomplete KBS with knowledge-aware reader[EB/OL]. (2019-05-31). https://arxiv.org/abs/1905.07098.
[15]Han Jiale, Cheng Bo, Wang Xu. Open domain question answering based on text enhanced knowledge graph with hyperedge infusion[C]//Proc of Findings of Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 1475-1481.
[16]Saxena A, Tripathi A, Talukdar P. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 4498-4507.
[17]Han Jiale, Cheng Bo, Wang Xu. Two-phase hypergraph based reasoning with dynamic relations for multi-hop KBQA[C]//Proc of the 29th International Joint Conference on Artificial Intelligence. New York: ACM Press, 2020: 3615-3621.
[18]He Gaole, Lan Yunshi, Jiang Jing, et al. Improving multi-hop knowledge base question answering by learning intermediate supervision signals[C]//Proc of the 14th ACM International Conference on Web Search and Data Mining. New York: ACM Press, 2021: 553-561.
[19]Zhang Xiaoyu, Xin Xin, Li Dongdong, et al. Variational reasoning over incomplete knowledge graphs for conversational recommendation[C]//Proc of the 16th ACM International Conference on Web Search and Data Mining. New York: ACM Press, 2023: 231-239.
[20]Wang Yanda, Chen Weitong, Pi Dechang, et al. Adversarially regularized medication recommendation model with multi-hop memory network[J]. Knowledge and Information Systems, 2021, 63(1): 125-142.
[21]Trouillon T, Welbl J, Riedel S, et al. Complex embeddings for simple link prediction[C]//Proc of the 33rd International Conference on Machine Learning. [S.l.]: JMLR.org, 2016: 2071-2080.
[22]Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[C]//Proc of the 26th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2013: 2787-2795.
[23]Nickel M, Rosasco L, Poggio T. Holographic embeddings of know-ledge graphs[C]//Proc of the 30th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 1955-1961.
[24]Nickel M, Tresp V, Kriegel H P. A three-way model for collective learning on multi-relational data[C]//Proc of the 28th International Conference on International Conference on Machine Learning. [S.l.]: Omnipress, 2011: 809-816.
[25]张鸿志, 李如寐, 王思睿, 等. 基于预训练语言模型的检索-匹配式知识图谱问答系统[EB/OL]. (2021) [2024-01-02]. https://bj.bcebos.com/v1/conference/ccks2020/eval_paper/ccks2020_eval_paper_1_4_2.pdf. (Zhang Hongzhi, Li Rumei, Wang Sirui, et al. Retrieval-matching knowledge graph question answering system based on pre-trained language model[EB/OL]. (2021) [2024-01-02].https://bj.bcebos.com/v1/conference/ccks2020/eval_paper/ccks2020_eval_paper_1_4_2.pdf.)
[26]Xu Kun, Lai Yuxuan, Feng Yansong, et al. Enhancing key-value memory neural networks for knowledge based question answering[C]//Proc of Conference on North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2019: 2937-2947.
[27]Sun Haitian, Dhingra B, Zaheer M, et al. Open domain question answering using early fusion of knowledge bases and text[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 4231-4242.
[28]Shi Jiaxin, Cao Shulin, Hou Lei, et al. TransferNet: an effective and transparent framework for multi-hop question answering over relation graph[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2021: 4149-4158.
[29]汪洲, 侯依宁, 汪美玲, 等. 基于特征融合的中文知识库问答方法[EB/OL]. (2021) [2024-01-02]. https://bj.bcebos.com/v1/conference/ ccks2020/eval_paper/ccks2020_eval_paper_1_4_1.pdf. (Wang Zhou, Hou Yining, Wang Meiling, et al. Chinese knowledge base question answering method based on feature fusion[EB/OL]. (2021) [2024-01-02]. https://bj.bcebos.com/v1/conference/ccks2020/eval_paper/ccks2020_ eval_paper_1_4_1. pdf.)
[30]Tan Yiming, Zhang Xinyu, Chen Yongrui, et al. CLRN: a reasoning network for multi-relation question answering over cross-lingual know-ledge graphs[J]. Expert Systems with Applications: An International Journal, 2023, 231(C): 120721.
