程序算法识别研究综述
2024-08-17张雅雯张丽萍闫盛魏敏








摘 要:了解程序代码所描述的算法,能帮助程序员理解程序从而开展各项软件工程任务。由于人工理解程序算法要求程序员具备丰富的专业知识并且十分耗时耗力,程序算法识别任务以实现程序算法理解的自动化为主要研究目标,与人工理解相比更为高效、准确。系统整理了程序算法识别领域的相关工作。首先,梳理程序算法识别等相关概念,简介基于知识表示与基于信息检索的方法;其次,将基于代码表征的方法划分为基于序列、基于树和基于图等方法展开详细阐述,并对三类方法作出小结与对比;最后,介绍程序算法识别任务的相关应用领域,分析该任务中尚存的问题并对未来的发展作出展望。
关键词:程序算法识别; 程序理解; 程序代码表征
中图分类号:TP311 文献标志码:A 文章编号:1001-3695(2024)07-003-1940-11
doi:10.19734/j.issn.1001-3695.2023.09.0504
Review of research on program algorithm recognition
Abstract:Understanding the algorithms described in program code can help programmers grasp the program aUUoek8BNZH30HsVhpI0HLw==nd carry out various software engineering tasks. Because manual understanding of program algorithms requires programmers to have rich professional knowledge and is time-consuming and labor-intensive, the main research goal of program algorithm recognition is to achieve automation of program algorithm understanding, which is more efficient and accurate compared to manual understan-ding. This paper systematically organized the relevant work in the field of program algorithm recognition. Firstly, it combed the concepts related to program algorithm recognition and introduced methods based on knowledge representation and information retrieval. Secondly, it divided the code representation based methods into sequence based, tree based and graph based me-thods for detailed elaboration, and made a summary and comparison of the three types of methods. Finally, it introduced the relevant application fields of the program algorithm recognition task, analyzed the remaining problems and made prospects for future development.
Key words:program algorithm recognition; program understanding; program code representation
0 引言
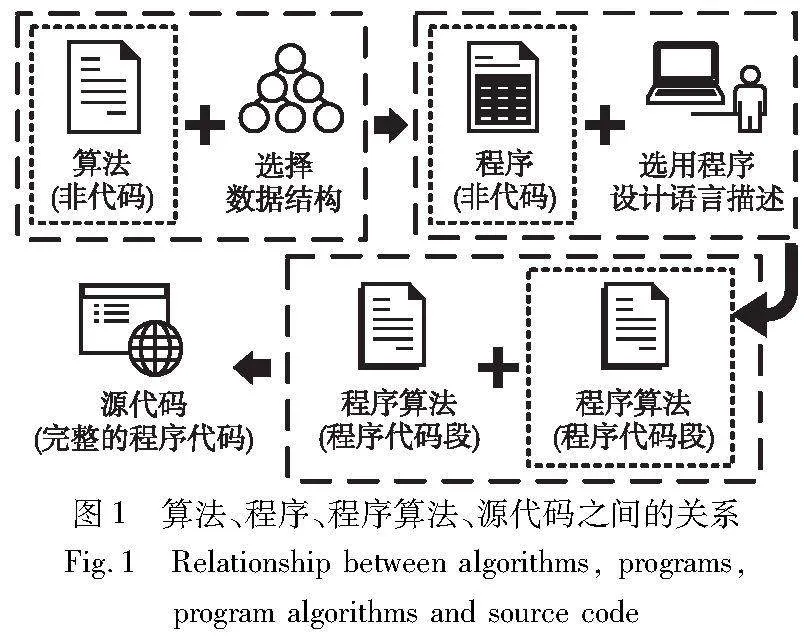
20世纪70年代,计算机科学家Wirth[1]提出公式“programs=algorithms+data structures”,即“算法+数据结构=程序”。其中,算法(algorithm)是解决某一问题或完成某一任务时所采取的具体方法或步骤,选用某(几)种数据结构予以实现算法就形成了程序,程序代码是程序的具体实现,依赖于所使用的程序设计语言。
随着信息化建设的逐步推进,程序代码储备越来越丰富,例如国内开源技术社区OSCHINA(https://www.oschina.net/)中已收录全球知名项目近5万款,及其建立的代码托管平台Gitee(https://gitee.com/)中的代码仓库已达2 000万。识别程序代码所实现的算法,开发人员可以快速了解整个代码完成的任务与实现的功能,在此基础上更加高效地开展代码推荐[2]、代码搜索[3]、逆向工程和软件再工程等任务。例如选取性能更好的算法进行软件复用或根据其思想进行软件重构,发现现行程序代码中的缺陷以更好地维护软件等。然而,对于庞大复杂的程序代码,其中所涉及的算法繁多,程序员如果想要了解语句级或函数级的功能必须阅读程序源代码,这无疑是一项非常繁重的工作。
程序算法识别作为程序理解的一项研究课题,其主要目标是从代码中识别出相关算法的程序代码段[4],实现自动化地理解程序算法。相较于依赖专家先验知识、受限于程序员自身认知水平、费用较高、时间开销较大的人工理解程序算法,自动化理解程序算法效率更高、代价更低。因此,目前的程序算法识别方法逐步由早期的模板匹配、概念定位,向更深入利用程序代码特征发展,即在考虑任务要求后,采用机器学习或深度学习的方法挖掘更深层次的程序代码信息,生成特征向量以识别程序算法,不仅节省了大量的人工劳动,更进一步提高了这一任务的精确度和准确率,增强了具体模型的可扩展性。本文首先,梳理“算法”一词的来源与含义,对“程序算法”以及“程序算法识别”进行定义与说明;其次,对基于知识表示和基于信息检索的程序算法识别方法进行简介,着重阐述基于代码表征的方法,并对每种方法的优缺点展开分析;再次,总结程序算法识别任务的相关应用领域,为其应用提供一定参考;最后,根据程序算法识别研究的现状指出其存在的局限性与不足,为未来程序算法识别任务的研究提供思路。
1 相关概念
“算法”一词的来源可以追溯到希尔伯特提出要构建一组具有“完备性”的公理体系,尽管后来这样的公理体系被证明并不存在,但随着这一证明而遗留的问题推动了算法形式化定义的进程。算法得以定义有助于将其应用于计算机领域解决实际问题,程序代码也因算法更加高效,而复用这类程序算法,能够避免大量重复的编程任务。因此,识别程序算法具有非常重要的研究价值。
1.1 程序算法的含义
20世纪20年代,希尔伯特提出要建立一组公理体系,使得一切数学命题原则上都能凭借这组公理体系经过有限步推断判定真伪,这被称作这组公理体系的“完备性”。然而,库尔特·哥德尔于1931年发表论文,提出不完备性定理,证明了任何无矛盾的包含初等数论的公理体系,必定存在一个用这组公理不能辨别其真伪的不可判定命题[5]。哥德尔不完备性定理留下了一个根本性问题,即对于一个到目前为止尚未发现任何解决方法的具体问题,是否还能找到它的求解方法?需要说明的是,一个“数学问题”是这个问题的无限多个实例的集合。也就是说,发现一种解决问题的方法,意味着能够将这个问题的无限多样性减少到由方法描述给出的有限大小[6]。艾伦·麦席森·图灵希望证明存在一些问题,其无限多样性不能简化至有限大小。为此,图灵将“数学方法”(希尔伯特称为算法)一词的含义形式化,于1936年提出了图灵机,并提出观点:能行可计算函数都是用图灵机可计算的函数。这一论点与阿隆佐·丘奇的“每个能行地可计算的函数都是一般递归的”论点统称为丘奇-图灵论题[7]。文献[8]认为算法是一组有限规则,它给出了一系列解决特定类型问题的操作。严蔚敏等人[9]定义算法是为解决某类问题而规定的一个有限长的操作序列。
本文将“使用程序设计语言实现求解某一问题所使用算法的程序代码”称为“程序算法”,程序算法识别任务则是从源代码中找出表达某个算法的程序代码段。算法、程序、程序算法、源代码之间关系如图1所示。
1.2 相关研究
在研究初期,学者们或依赖预定义的规则和知识库,或采用搜索和匹配技术实现程序算法的识别,这两种方法可以被概括为基于知识表示的方法与基于信息检索的方法。
1.2.1 基于知识表示的方法
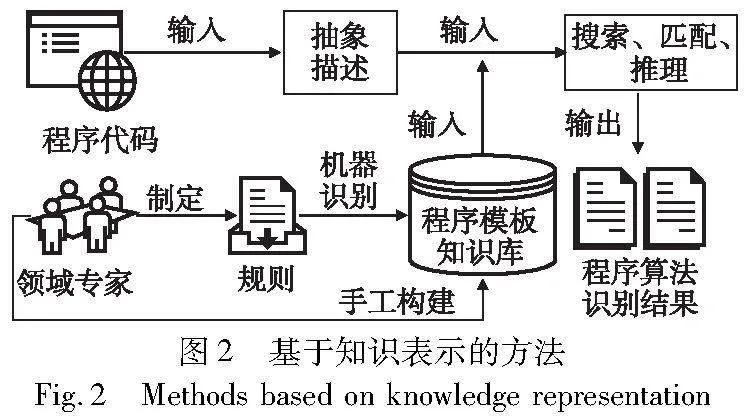
基于知识表示的方法以实现某种算法的程序代码都有固定模式为前提,将待识别程序代码中的概念和逻辑结构进行抽象,通过搜索、匹配和推理等手段在程序模板知识库中寻找与之相匹配的程序描述模板,从而实现程序算法识别。其中,所使用的知识库或由专家手工构建,或通过专家利用先验知识制定规则,之后使用机器识别相关知识,其过程如图2所示。
Murray[10]在Talus和Proust[11]项目中使用“框架”表示程序知识,并建立使用框架集描述的plan(程序代码片段)库。当识别一段程序代码时,首先将其转换为使用框架描述的plan,然后在plan库中进行匹配来识别此plan的含义。这种方法存在许多不足,例如Proust识别plan能力有限,扩展调试知识困难,只能处理少数小型程序代码等。除了利用现有的plan库,文献[12]通过分解技术将程序代码分解为事件(events)和切片(slices)两种片段,由于events和slices的表示形式不同,所以分别为这两种片段构建相应的plan库进行匹配,并利用5个随机选中的Pascal代码中的92个循环对进行评估[13]。虽然这两种分解技术对程序算法识别任务产生了一定的积极影响,但程序切片的知识库在结构和内容上更加复杂,与常用的自动化分解技术相比,需要更多的人力资源和专业知识以设计知识库。
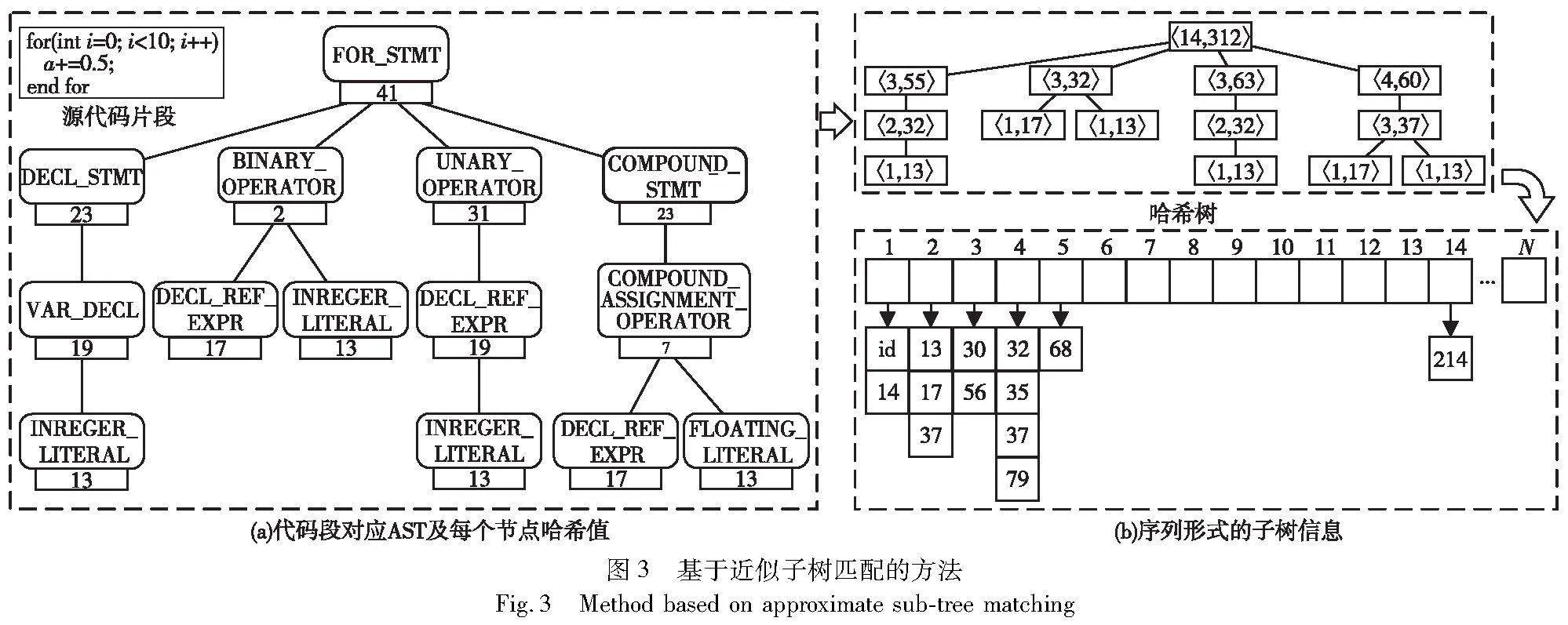
上述方法通过构建或利用已有的表示程序知识的框架实现了程序算法识别,另一方面,还可以通过程序代码特征匹配的手段。文献[2]提出一种基于近似子树匹配的方法,如图3所示。首先,遍历源代码建立抽象语法树(abstract syntax tree,AST),依据树节点功能对其进行分类,将相似节点映射为相同哈希值;其次,通过〈节点号,哈希值〉元组表示当前节点所位于子树的信息,并以所有子树的哈希值之和作为整棵AST的哈希值,完成树连接;接着,以序列的形式对AST进行存储。最后,在哈希树中获取相同节点号的哈希值列表,使用二进制搜索方法搜索相似哈希值完成匹配。该方法虽然具有很高的召回率,但当哈希值列表较长时,搜索耗费的时长也会随之增长。此外,将整棵哈希树以序列形式存储,尤其对于大规模代码而言,将会产生大量额外的存储成本与计算开销。王甜甜等人[14]也利用了特征匹配的思想,采用最大公共子序列算法对缺陷程序代码和示例程序代码的AST进行匹配,从而识别、定位了学生程序代码中的缺陷。
不同于通过匹配的方式识别程序算法,Harandi等人[15]创建了一个基于知识的程序分析工具PAT。该工具使用一个面向对象的框架重新表示编程概念,并使用基于启发式的概念识别机制从代码中推导出高级的功能概念,从而实现了程序代码自动分析。尽管该方法在面对库中涵盖程序算法不全这一问题时,能够通过推理识别程序算法,但仍受限于启发式知识的局限性与主观性,导致部分功能概念依然无法被识别。
总而言之,尽管这类方法实现起来较为简单,在数据稀疏的情况下,可以利用现有的规则与程序模板知识库,但这就对库中的内容提出了非常严格的要求,必须具备高度的准确性和完整性。然而一方面,程序模板知识库的构建和维护需要耗费大量的人力和专业知识,使得库中的内容具有一定的主观性,同时限制了该方法的扩展性和适用范围。另一方面,算法也随着数学、计算机科学等学科的发展而在源源不断地产生,库中知识存在覆盖不全面的情况,这就要求及时地对知识库作出扩展与更新,对于精确地识别程序算法均会产生一定的影响。
1.2.2 基于信息检索的方法
在软件开发过程中,会随之产生大量的文档和源代码注释,能够说明程序代码的功能、逻辑结构和实现算法等内容,有效利用这些信息完成程序算法识别任务是基于信息检索方法的研究目标。其流程如图4所示,将程序员视角下代码中的各种计算单元使用units集合表示,将用户视角中能够表明用户观点的各类说明文档或注释通过features集合表达,基于信息检索完成概念定位[16],在本文中即找到units中元素与features元素之间的关联。在信息检索方法中,经典模型有向量空间模型(vector space model,VSM)和主题模型。其中,主题模型主要包括潜在语义分析(latent semantic analysis,LSA;又称为潜在语义索引,latent semantic index,LSI)和隐含狄利克雷分布(latent Dirichlet allocation,LDA)。
VSM由Salton等人[17]于1969年提出,在进行概念定位时,可利用VSM基于词袋模型将说明文档和程序代码分别表征为向量,如果向量相似则可以认为这段程序代码所实现的算法即为该说明文档所描述的算法。但是,在将代码的相关文本内容转换为向量时,经典的VSM认为词与词之间是相互独立的,割裂了文本本身的语义关联,使机器理解计算机领域中的专有术语或表达方式从而识别程序代码中所蕴涵的算法更加困难。
相较之下,主题模型假设词与词之间存在紧密联系,通过抽取出若干组关键词作为文档集的主题,以表达文档集的中心思想。Marcus等人[18]根据代码模块与代码文件之间的关系生成图,图中的节点和边分别表示代码模块以及模块之间的关系,同时定义了两种类型的边。其中,语义相似边主要利用LSI技术,从程序代码和说明文档中提取能够说明代码含义的关键词向量,当两代码模块对应向量之间的余弦距离低于阈值时,则边存在。接着,基于此图对代码模块进行聚类,以实现对指定模块的识别。Poshyvanyk等人[19]认为仅基于LSI技术的概念定位所得到的结果具有不确定性,因此提出基于执行场景和信息检索方法的概率排序进行概念定位。实验结果表明,概念定位的有效性得到显著提高。除此之外,还有研究者通过LDA模型[20]分别挖掘说明文档和程序代码的topic,再基于主题分布计算两者之间的相似度,最终实现概念定位[21]。
相比于VSM,LSA考虑到了文本自身的语义信息,LDA模型通过挖掘文档的topic能够找到没有相同词的两个文档之间的联系。此外,传统的自然语言模型需要定义语法和词典,但对于程序代码而言,标识符等已形成了自己的语言,然而并没有对其进行定义的语法或形态学规则,导致部分模型在处理程序代码文档时适用性较差。而LSA模型无须使用预定义的语法或词汇表[19],这就支持程序员在编程时能够定义词表之外且具有隐含意义的变量名[22],因此LSA模型更适合处理程序代码这类特殊的文本文档。
基于信息检索的方法已在文件级和函数级程序代码中取得较为精确的定位效果,但是这种定位粒度较粗,对于语句级程序算法仍需消耗大量人力做进一步确认。对此,岳雷等人[23]提出一种语句级定位方法。首先,检索已有的与待识别代码的相关文档相似度较高的说明文档或注释,提取对应的已识别的程序算法语句;其次,根据待识别代码及其相关文档的文本相似度确定可能的程序算法;最后,计算可能的程序算法与已识别的语句级程序算法的相似度并降序排列,实现语句级定位。该方法在识别更多的语句级程序算法的同时,节省了时间开销。然而,其依赖于程序算法的相关文档以及已识别的程序算法,可能无法有效定位新颖的程序算法或变体。
综上,与基于知识表示的方法相比较,基于信息检索的方法更为客观,无须依赖领域知识先验地构建规则或程序模板知识库,而是利用已有的相关文档,通过检索的方式更快速地识别程序算法,节省了大量人力。然而一方面,自然语言与程序设计语言之间存在一定差异,即程序代码的说明文档与其本身具有一定的差别,这类方法没有充分考虑到这种差异性。另一方面,该类方法的识别结果很大程度上受所使用文档的影响,且代码的描述文档往往存在介绍不全、描述不准甚至缺少相关文档的状况,这就导致基于信息检索的方法存在一定局限性。
2 基于代码表征的程序算法识别方法
事实上,每种算法在具体实现时都会体现出不同的代码特征,这些特征包括代码行数、变量个数、循环个数、控制结构、数据流结构等,但基于知识表示与基于信息检索的方法并没有充分利用这部分信息。
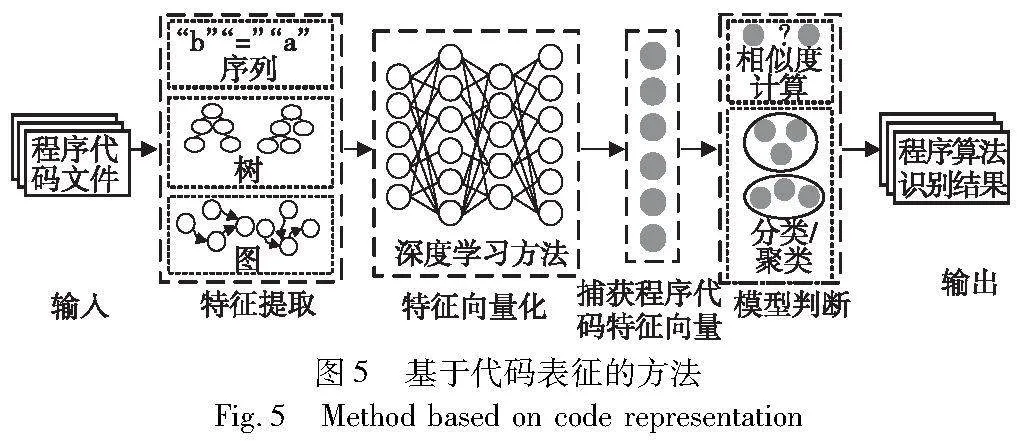
基于代码表征的方法在不同程序算法具有不同特征值的假设下,以代码特征能够体现程序功能或算法为前提,从一种或多种角度提取程序代码中的特征并生成相应的向量,最终达到程序算法识别的目的。在利用程序代码特征时,传统方法常通过手工提取特征,然后基于统计学原理对其进行表征[24]。这种方法虽然能够借助知识引导,但所提取的特征具有主观性,还会造成信息的损失。2012年,Hindle等人[25]提出了代码的自然性假设(natural ness hypothesis),证明了源代码具有与自然语言相似的特性。由此机器学习方法开始被应用于代码表征,减少了程序算法识别任务中大量的人工参与。后来,深度学习的应用使得自然语言处理取得了更好的效果,逐渐有学者尝试将深度学习方法也应用于程序代码表征,以挖掘其更深层次的复杂特征[26]。由于语义等价问题不可判定,是停机问题[27]的直接推论,所以在利用深度学习等方法表征程序代码的基础上,有学者将程序算法识别问题转换为向量相似性判断、向量分类和向量聚类等问题,如图5所示。首先,提取程序代码特征,通过序列、树或图对代码予以组织,生成目标算法与待识别算法相应的特征向量[28];其次,计算两向量之间的距离等并设置距离阈值;最后,通过向量相似性判断、向量分类或向量聚类完成程序算法识别任务,即当两向量之间的距离低于阈值时,两程序算法被判定为相似,或者在分类与聚类时被分为或聚为一类,则认为这两段程序代码描述的是同一算法。
2.1 基于序列的方法
随着自然语言处理技术的发展,任意文本都可以被表示为词序列,并生成词序列的向量表示。程序代码作为一种特殊的文本,被表示为词序列时主要有两种方式:a)不对源代码做任何处理,直接将其转换为词序列;b)对源代码进行词法分析后得到一个词汇序列,该序列也称为token序列。
显然,在获取词序列时,与解析源代码相比,不对源代码进行处理更加节省时间,但是这样将会导致其中大量的词法信息丢失,使得最终得到的序列特征并不够充分。而在token化程序代码时,使用不同的转换规则将会产生不同的token串,对后续工作也会产生一定的影响。张冬梅等人[29]通过自定义转换规则,规避了不同变量名和函数名对于表示结果的影响。然后,为从token中提取体现其上下文关系的深层信息,采用能够缓解程序代码长期依赖问题的双向长短期记忆(bi-directional long short-term memory,Bi-LSTM)网络提取行级与全局特征。同时,由于不同token与不同行对程序算法识别任务具有不同程度的影响,引入注意力机制调整重要token及代码行的权重,最终将代码相似行检测的召回率以及精确度分别提高至91%和97%,但是由于转换规则以自定义的方式制定,也使得该方法对于某些程序设计语言或代码库可能并不完全适用。
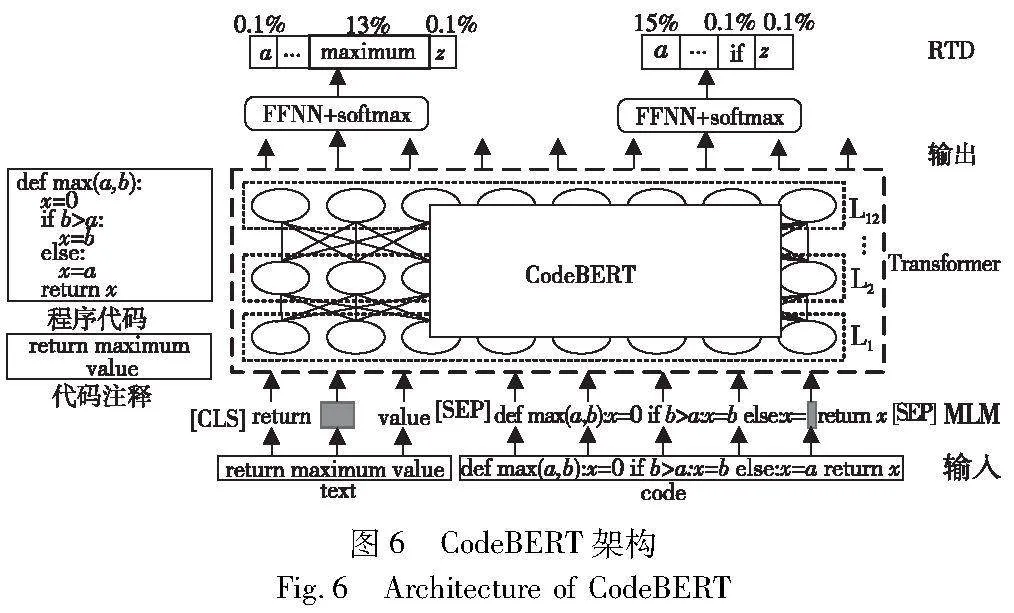
文献[30]提出目前已知的首个大型自然语言-编程语言(natural language-programming language,NL-PL)预训练模型CodeBERT。如图6所示,该模型以双峰NL-PL对和单峰数据作为输入,并将NL-PL对设置为带有特殊分隔符的片段,即“[CLS],自然语言文本词汇序列,[SEP],程序代码token序列,[EOS]”。接着,以掩码语言建模(masked language modeling,MLM)和替换标记检测(replaced token detection,RTD)为训练目标,基于多层双向的Transformer学习代码中不同token之间的上下文关系以及语义信息并生成向量表示。其中,Transformer共有12层,每一层中有12个自注意力头,这使得模型在每一层中都可以充分考虑序列中的不同位置,不仅能够更好地学习不同token之间的上下文关系,还具备处理长依赖问题的能力。成思强等人[31]基于CodeBERT提出CBBCC模型,将CodeBERT所生成的向量表示用于POJ-104数据集进行代码分类,是首个将BERT预训练模型引入代码分类任务的模型。实验结果表明,与TBCNN、CVRNN和ASTNN等模型相比,该模型能够保持各项分类指标都在98%以上,且在精确度上比最优模型提高了1.1%。值得一提的是,CodeBERT使用Python、Java、JavaScript等六种常用程序设计语言实现的代码作为训练数据,当应用该模型于C#语言时,仍能取得很好的效果,这表明CodeBERT具有很强的泛化能力,可以识别多种语言的程序算法。CodeT5[32]同样以NL-PL对作为模型的输入,与CodeBERT不同的是,其采用编码器-解码器结构,以遮盖片段预测(masked span prediction,MSP)、标识符标注(identifier tagging,IT)和遮盖标识符预测(masked identifier prediction,MIP)等作为预训练任务,更加关注token中标识符所蕴涵的代码语义信息,能够同时支持代码理解以及生成任务。尽管上述方法在多种语言、多项任务中都取得了不错的效果,却都忽视了程序代码中所蕴涵的丰富的结构信息与数据流信息。
除token序列之外,由于程序代码中的应用程序接口(application programming interface,API)也能体现程序代码的功能,所以API序列也有一定的研究价值,例如总结API序列,构建API知识与程序代码所实现功能的描述之间的映射,并将其应用于程序算法识别,但是由于具有不同特征的API序列其功能可能一致,导致这种方法的扩展性较差。Huang等人[33]提出一种API嵌入模型API2vec,使得两个特征不同但上下文相似的API在嵌入空间中能够更加接近,然后利用K-means算法对API2vec所生成向量进行聚类,获取功能相近的API类簇,从而增大了功能识别对API特征变化的弹性。
如若在词法分析的基础上将程序代码映射为一组二进制数,就能得到代码的指纹。2007年,Google公司提出Simhash算法,将该算法应用于代码相似性判定,核心思想是通过指纹判断代码的相似度,指纹越接近,代码越相似。然而在实验过程中,李玫等人[34]发现在大规模数据集中存在行覆盖的现象,为消除高频出现但所包含语义信息较少的代码行对指纹生成的影响,其对基于文本的行粒度相似哈希算法进行优化,提出根据不同编程语言的特性筛选代码行,进一步提高了代码相似性检测的精确度。但是该方法在程序代码文件较小或包含语义信息较少、两程序代码总行数差距较大时,存在未能识别出程序算法的情况。
基于序列方法的对比如表1所示。这种方法比较简单,能够关注到程序代码中token的位置信息,计算代价较低且高效,尤其是在对大规模的程序代码进行表示时,可以应用于任意编程语言。而且经过词法解析后所得的token序列保留了程序代码的词法信息,token化时所遵循的转换规则使得代码表示更加灵活。然而,程序代码不同于普通文本,其具有强结构性,这种方法极容易丢失程序代码中的结构信息,以致于无法很好地建模程序代码。此外,对于指纹而言,尽管程序源代码未发生变化,如果重新进行编译,指纹也可能改变,这也为程序算法的识别带来了很大的不便。
2.2 基于树的方法
如果修改程序代码但不改变其执行结构,例如修改其中的变量名、函数名、数据类型和书写风格等,那么从结构的角度讲,两段程序代码是一致的[35]。在结构级表征程序代码的方法中,通过语法分析将其表示为AST,从而保留程序代码的结构信息是较为常用的方法。如图7所示,AST中的每一个节点及其子节点表示程序代码中的某一代码片段,非终结符对应其中的中间节点,如while、if等,终结符对应其中的叶子节点,如变量名a和b、常量名、方法名等。
由于传统方法中AST关键节点的字面含义不同会导致匹配失败的问题未能得到解决,比如“for”和“while”的字面意思虽不同,但都实现了循环的功能,魏敏等人[36]提出了一种基于程序向量树和聚类的学生程序算法识别方法AR-PVTK。首先将程序代码表示为AST,为其叶子节点赋予对应的词向量表示,将AST转换为程序向量树并将其编码为定长向量,采用K-means聚类算法将实现同一种算法的代码映射到向量空间中相近的位置,从而完成程序算法的识别。由于在生成叶子节点的向量表示时融入了语法信息,所以能够有效规避语法形式多样化的问题。
将程序代码表示为AST后,在生成相应的特征向量时,采用何种遍历方式将会直接影响代码表征的速度与质量。如基于结构的遍历方法(structure-based traversal,SBT),其生成的原始序列中包含源代码的标识符,内容上也有许多重复,且SBT使用一对括号表示树结构,不利于结构信息的编码。彭斌等人[37]基于SBT提出了面向约简的抽象语法树遍历方法RAST,以图7中虚线部分节点结构为例,具体方法如图8所示。
首先,使用SBT遍历AST生成SBT序列,然后使用先序遍历AST所得序列号替换SBT序列中的括号,并将SBT序列划分为序列号序列和节点序列。其次,采用驼峰式转换拆分节点序列值(比如将“isTrue”拆分为“is”、“True”),将原始节点对应序列号赋值给每个拆分后的词,以解决词汇量过大的问题。最后,针对递归神经网络处理程序代码时不能很好地解决长依赖问题,利用卷积神经网络(convolutional neural networks,CNN)中的卷积层分别中从token向量和RAST向量中提取词法与语法特征,生成最终的向量表示,最大程度地保存了程序代码的结构信息。
然而,在利用AST表示大规模程序代码时,相应的AST规模亦非常庞大,此时对应的AST节点必然繁多,遍历所有树节点也必将耗时,同时很容易在训练模型时出现梯度消失或梯度1爆炸的问题。为解决这类问题,龚丹等人[38]将代码转换为AST,选取其关键节点类型作为特征表示,经过后序遍历AST得到每个节点最终的特征向量。接着引入局部敏感哈希算法,对特征向量进行哈希处理,然后采用欧氏距离度量相似度。该方法将一个在大型数据集合中寻找相似特征向量的问题转换为在一个较小的数据集合中,大幅地降低了时间复杂度。但是这一方法受到哈希函数的限制,相似的特征向量也有可能被映射至不同的小数据集合中,导致相似性判定出现误差。Zhang等人[39]通过证明将整棵AST切割为一系列子树有利于表达程序代码的语义信息,提出了一种新的基于AST与神经网络的代码表征模型ASTNN。首先,将整棵AST按照语句进行切割;其次,捕获语句的词法与句法信息,将每一棵切割所得的语句树编码为向量,得到语句向量序列;最后,采用双向门控循环单元(bi-directional gated recurrent unit,Bi-GRU)生成最终的程序代码向量表示,以提升循环层捕捉代码长依赖信息的能力,捕获程序代码所蕴涵的自然性。金岩磊等人[40]参考树切割的思想,为进一步利用程序代码中的结构与语义信息,使用通过TBCNN改进的ASTNN模型对AST进行编码,获取每棵AST的向量表示,接着利用叠加的双向循环神经网络更全面地捕获代码块之间的序列信息,通过拼接两个时间方向隐藏单元输出,最终得到整个程序代码的向量表示,并通过分类识别程序代码所描述的算法。Hua等人[41]也利用了这种思想,提出基于Transformer的代码分类模型TBCC。首先,将子树扁平化为序列,为显示地区分每棵子树,在每棵子树对应的序列中添加特殊标记“[SEP]”;其次,由于Transformer中的自注意力模块不包含循环或卷积单元,导致难以处理序列中的顺序关系,其将代码元素的位置信息通过嵌入的方式引入模型;最后,利用Transformer对拥有特殊标记的序列进行编码,通过该模型中的多头自注意力机制捕捉不同代码元素之间的上下文关系,关注到了整个序列的各个位置。实验结果表明,相较于基于CNN和循环神经网络(recurrent netural network,RNN)的方法,TBCC对程序代码中的长依赖关系更加敏感,梯度消失和梯度爆炸的问题得以有效缓解。然而与此同时,Transformer常常需要大量的计算与存储开销,这对于十分庞大的AST而言,几乎是无法实现的。对此,Zhang等人[42]构建了一个由图卷积神经网络和注意力机制组成的代码学习器,将大量token转换为几个蕴涵丰富语义信息的token,很大程度上减少了输入的token数量。此外,在Transformer的编码器中引入跨代码注意力模块来学习代码表示,进一步捕捉代码片段之间的相似性。实验结果表明,该方法无须大量的计算成本,大大降低了基于Transformer的程序算法识别模型的计算开销。
基于树方法的对比如表2所示。这类方法关注到了程序代码的强结构性,相较于基于序列的代码组织方式,树结构可以直观地展示程序代码的逻辑结构,准确反映其中的层次结构、控制流程等,非常利于捕捉结构信息,在生成向量表示时,还能够将词法与语法信息相融合。然而,对于大规模程序代码,尽管将其切割为子树能够有效缓解梯度消失等问题,提高代码表征效率,但与此同时,会随之产生额外的计算开销,包括分割整棵AST、遍历子树等。除此之外,不同于自然语言,程序代码必须是可执行的,即其具有可执行性,而基于树的方法虽然保存了其中的结构特征,却并未关注到程序代码动态运行时的语义信息,例如数据流信息和控制流信息等。
2.3 基于图的方法
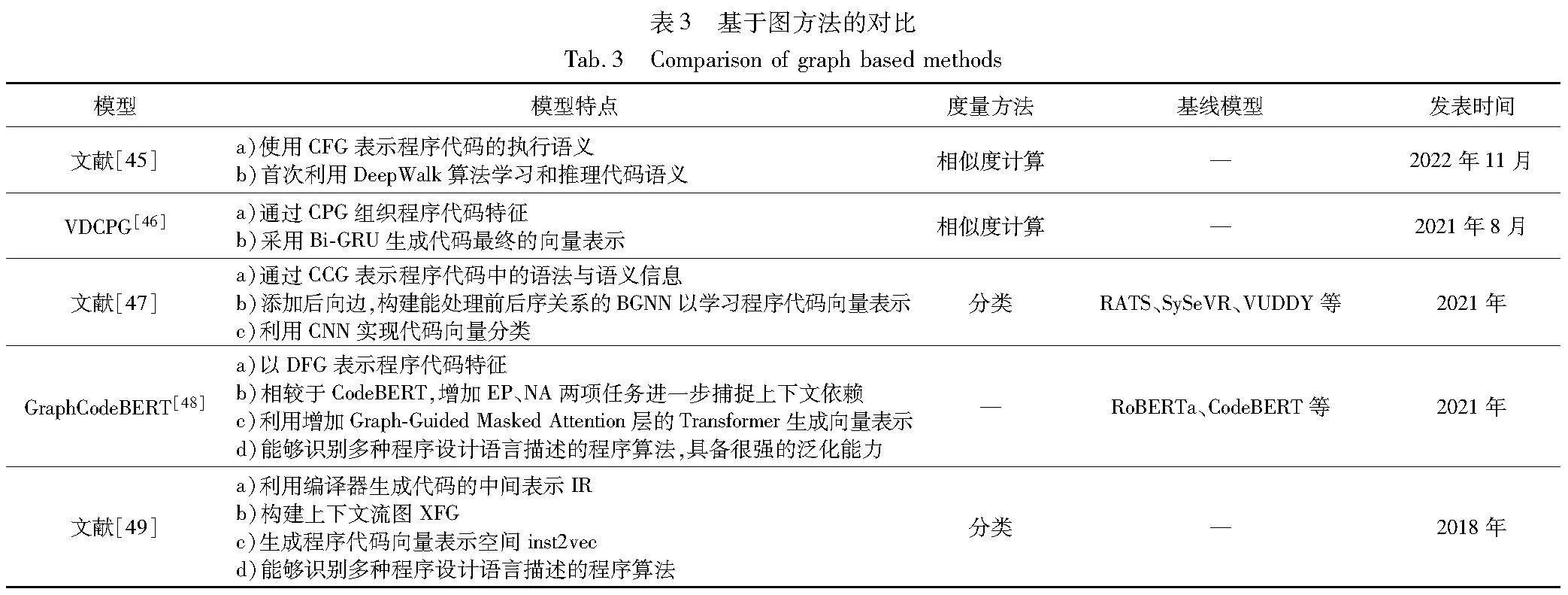
对于两段结构相同的代码,其执行路径[43]可能不同,所表达的语义可能也不一样。金芝等人[44]认为,提取程序代码的数据流和(或)控制流信息的过程,可以看作是从问题求解视角出发的程序代码语义理解。基于图的代码表征方法主要使用根据程序代码生成的数据流图(data flowing graph,DFG)、控制流图(control flowing graph,CFG)、程序依赖图(program dependence graph,PDG)等,其中,数据流表示程序代码中数据的流向,控制流表示其中逻辑的走向,程序依赖图主要用于表示数据和控制的依赖关系,不仅能表征语法信息,还可以表征语义信息。梁瑶等人[45]针对token和AST对代码执行语义信息无法充分利用的缺点,使用CFG表示代码的执行语义,并首次使用基于随机游走的图嵌入算法DeepWalk学习和推理代码中的语义信息。与word2vec和doc2vec方法相比,DeepWalk作为一种针对图结构的算法,能够更好地学习图结构、获取图中节点在上下文中的信息,但当CFG结构非常繁杂时,基于随机游走的方法可能无法充分地学习其中复杂的语义信息。
肖添明等人[46]针对AST中缺少与控制相关信息的问题,从整合AST、CFG、PDG三种表示形式的代码属性图(code property graph,CPG)中提取出AST序列和CFG序列保存代码的结构信息,并针对Bi-LSTM模型参数较多、训练时间较长、易发生过拟合等问题,选用其变体Bi-GRU生成特征向量。实验结果表明,相较于单一使用AST的表征方式,该方法对于代码相似性检测最大可提高35%的精确率以及22%的召回率。尽管PDG中包含了程序代码中的数据流信息,但是在初步提取特征时,更多关注的是CPG中的结构特征而忽略了数据流信息,这可能造成部分语义信息的丢失。为保留程序代码结构特征的同时,利用其运行时产生的数据流与控制流信息,文献[47]首先依据程序代码的AST、CFG、DFG构建了能够体现数据流向和控制依赖的代码复合图(code composite graph,CCG);其次,在传统的图神经网络中添加后向边,构建了能够处理前后序数据的双向图神经网络(bi-directional graph neural network,BGNN),以从CCG中学习代码的上下文特征,生成最终的节点表示;最后,考虑到程序算法或许在整体代码中只占较小比例,从整个CCG中很难学到程序算法的语义信息,因此利用CNN进一步提取主要特征并生成代码向量表示,通过分类器实现程序代码分类。
对于程序设计语言来讲,其种类非常丰富,不同的语言具有不同的特性,这一特点也称为代码语言的多样性,为程序算法识别任务带来了新的挑战。在面对这一问题时,已有模型通过大量的包括多种语言的语料对模型进行预训练以突破这一难题,例如前文所提及的CodeBERT,但与code2seq在部分任务上相比,该模型效果略低。这或许是因为code2seq使用AST作为模型输入,体现了程序代码的结构特征,而CodeBERT仅以源代码作为输入。对此,文献[48]基于CodeBERT提出了新的预训练模型GraphCodeBERT。首先,将程序代码解析为AST并从中提取变量的序列;其次,利用序列和AST构建DFG,引入程序代码的语义信息,同时避免AST的深层层次结构带来不必要的信息;接着,基于增添了graph-guided masked attention层的Transformer对所提取的代码特征进行编码,以更好地将图结构融入Transformer。与CodeBERT相比,其还增加了边预测(edge prediction,EP)和节点对齐(node alignment,NA)两项任务,分别学习程序代码中数值的流向以及DFG与源代码之间的对应关系,进一步学习代码上下文信息。针对代码语言多样性这一问题,Ben-Nun等人[49]也提供了解决思路,设计了新的程序代码分类模型,如图9所示。首先,通过LLVM编译器得到程序代码的中间表示(intermediate representation,IR);其次,将数据流和控制流信息融入IR,构建上下文流图(conte-Xtual flow graph,XFG),为IR提供上下文表示。接着,根据XFG训练程序代码的向量表示空间inst2vec,从而生成代码的向量表示并使用RNN分类程序代码。实验结果表明,该模型的准确率高于TBCNN模型。由于该方法在表征程序代码时,通过LLVM编译器将由高级程序设计语言编写的源代码转换为编译语言描述的中间码,使得该模型可以生成不同程序设计语言实现的程序代码的向量表示,实现了让分类任务独立于程序设计语言,打破了一个方法只能识别一种语言的程序算法的局限。但由于其依赖于LLVM编译器,所以与基于CodeBERT的模型相比,该方法的迁移性较差。
基于图方法的对比如表3所示。这类方法能够捕捉程序代码在动态运行时随之产生的数据流和控制流等信息,一些方法将AST与DFG和(或)CFG相融合,既保留了语法特征又保持了语义特征,可以更好地捕获程序代码中的上下文依赖,例如变量的作用域、函数的调用关系等。然而一方面,尽管某类方法能够识别多种语言的程序算法,但是这需要使用大量语料对模型进行预训练,而依赖于PDG的基于图的方法通常需要一个PDG生成器,对于不同程序设计语言的技术隔阂依然存在。另一方面,基于图的方法涉及语法解析、语义分析等过程,对于复杂庞大的程序代码而言,在表征时会消耗巨大的时间与计算资源。
2.4 其他方法
上述三类基于代码表征的方法首先将程序代码表示为序列、树或图,在此基础上生成程序代码最终的向量表示,其优缺点对比如表4所示。然而,这些表征方式都不是代码词汇的直接向量表示,对于词向量,也是通过训练得到标识符对应的词向量,这同样会造成程序代码信息的丢失,而简单使用统计学原理表征代码,又无法体现其语法和语义信息。为解决此问题,谢春丽等人[50]提出了一种融合统计信息的卷积神经网络源代码相似性检测方法,将程序代码表示为词嵌入向量,而非获取标识符对应词向量,然后采用CNN直接挖掘代码中隐藏的语法及语义信息,通过余弦距离度量代码之间的相似性,以提升相似性检测的精度。尽管该方法融入了程序代码中词的统计信息,但未充分考虑其中的保留字和操作符等不同的词汇类型。
还有学者将程序算法识别问题与图像检测任务相结合。文献[51]对程序代码使用语法高亮并将其转换为图像,基于图像之间的相似度完成代码检测。文献[52]将程序代码的二进制文件转换为灰度图,然后利用所设计的基于灰度图像处理的深度学习模型MalMKNet识别代码功能。郑珏等人[53]不仅利用灰度图像,还将带有API函数调用与操作码的混合序列作为代码特征,最终通过基于CNN的多特征分类器实现代码分类。以上方法利用计算机视觉技术,从一定程度上规避了程序代码语法与语义表征的复杂性,但同样丢失了这部分信息,且与源代码相比,利用图像表征的结果并不易于理解和解释。
2.5 小结
基于代码表征方法从程序代码本身出发,以其表征作为方法核心,能够保持其中的强结构性、长依赖性、数据流和控制流等信息,既不依赖专家的先验知识,又无须相关的说明文档,节省了大量人力,降低了因此产生误差的几率。但是,这一类方法对于大规模异构的程序算法,当程序代码提取后的特征非常庞大时,识别过程的计算规模与开销也十分巨大。其次,在对程序代码进行表征时,特征粒度的选择具有主观性,这会对识别结果造成影响。此外,在利用相似性判断、分类等方法完成任务时,需要大量的有标签数据对模型进行训练,而且存在程序代码被判定为相似或者被分为或聚为一类时,其对应算法并不相同的状况,即这类方法存在误识别的情况。总言之,上述三类程序算法识别方法(基于知识表示、基于信息检索与基于代码表征的方法)各有优势与不足,其优缺点对比如表5所示。
3 相关应用领域
随着程序算法识别技术的发展,尤其是应用机器学习、深度学习方法帮助挖掘深层次的程序代码信息,程序算法的识别更加快速、精确,得到了广泛的应用。不仅可以用于支撑程序理解,帮助程序员进行软件复用、维护等软件工程,还可以用于优化、诊断和验证程序,辅助编程教育等。
3.1 代码优化与变换
代码优化是指在不改变程序代码运行结果的前提下对其进行变换,使其占用内存更少、处理速度更快等。算法级优化作为从程序所使用算法角度出发的优化方法,是实现代码优化的关键所在。
程序算法识别任务一方面可以确定当前程序所使用算法,判断代码实际运行的效率,如果效果较差,则可以在语义一致性的前提下,用性能更好的算法替换性能较差的算法。另一方面,在移植代码时,所识别出的高效程序算法能够帮助程序员快速变换和移植程序代码[54]。例如通过识别程序代码中的数据依赖,从而减少数据之间的依赖关系,使代码能够并行计算[55],优化运行时间,降低资源消耗。
3.2 程序理解
程序算法识别作为程序理解的一项研究课题,通过识别出程序代码所实现的算法,帮助程序员理解代码,支撑着程序理解的发展。程序员在进行各项软件工程任务时,例如软件复用与维护,可以通过代码搜索的手段获取待实现或维护功能相应的代码或说明文档等。功能强大的代码搜索引擎Krugle和Google code就通过特征定位技术实现算法识别,并据此为用户提供所需要的代码。CodeBERT和GraphCodeBERT也可以在代码片段和自然语言描述之间进行相似性匹配[30,48],从而实现代码的搜索和推荐,辅助程序员完成各类软件工程任务。
3.3 程序诊断及验证
大大小小的程序代码中都可能存在漏洞,复用这种存在软件缺陷或漏洞的代码很可能导致程序代码运行低效,甚至威胁计算机系统安全。有研究数据表明,在软件开发过程中,常包含5%~20%的重复代码;在开源项目中,代码复用率甚至可能超过50%[56]。
程序诊断指通过分析和调试程序,识别和定位程序中的错误和异常等,发掘产生这些问题的原因所在[57]。程序验证指通过形式化方法和技术,对程序的正确性进行全面和系统的证明与检查。通过识别程序算法,计算机能自动检测程序代码片段,发现其中存在的安全漏洞、缺陷和性能较差的程序算法,减少复用脆弱性代码等行为为代码安全带来的致命隐患[46]。
3.4 编程教育
在编程教育方面,程序算法识别任务同样发挥着重要作用。一方面,所识别出的程序算法可用于构建和扩充算法演示系统,例如VisuAIgo(https://visualgo.net/zh)以及Algorithm Visualizer(https://algorithm-visualizer.org/),教师可以通过这些系统更为形象地向学生介绍算法,让其能够更加直观地理解算法的含义与具体思路。另一方面,程序算法识别技术可以识别学生程序所使用的算法,来判断学生作业是否完成或正确,并为学生完成作业提供参考。
赵亮等人[58]构建了一个大数据算法库教学实验平台,该平台中包括分类、聚类等常用算法,用户按系统要求实现某算法后上传程序代码文件,系统后台验证其正确性,如若正确会将其加入算法列表。文献[15]通过输出缺陷代码与示例代码相应的语法树,对未匹配的结构和语句进行标记,从而辅助学生理解个人代码出错的原因。Gao等人[59]基于代码相似性设计了一种聚类算法,可以生成针对给定编程问题的所有正确解的聚类,为教师和学生实现编程作业一题多解给予一定的启示和帮助。文献[42]利用所识别出的程序算法搭建了算法推荐系统,通过关键词匹配为编程学习过程中遇到困难的学习者推荐算法。大部分参与者认为,这种算法推荐能够为编程问题“一题多解”提供思路。
4 发展趋势与展望
程序算法识别任务通过自动化地理解程序算法,既能够高效辅助开发人员完成各项软件工程任务,又可以助力编程教育事业的快速发展。随着程序算法识别技术的不断更新,所捕获的代码信息也更加丰富,准确率与效率也在稳步提升。尽管如此,程序算法识别任务也依然面临着众多问题与挑战。
4.1 现有方法自身具有局限性
基于知识表示的方法对于程序模板知识库中的知识有极高的要求,只有仔细分析一个算法,才能正确定义该算法的模板。如果在这个过程中出错,识别结果自然会受到影响。同样,基于信息检索的方法也对代码格式及其说明文档提出了要求,例如需要说明文档充分、内容正确等,但代码说明文件常写于设计较大规模软件时,对于学生程序代码,大多只有甚至没有注释,不便于程序算法的自动化识别。
基于代码表征的方法在从程序代码中提取特征时,粒度往往难以确定,常由研究人员根据任务需求选择表征方式。基于树和图的方法在建模时相对复杂,识别大规模程序代码中的算法时,时间复杂度和空间复杂度会大幅度上升。随着深度学习技术的发展,将其应用于程序算法识别逐渐成为趋势,但在深入挖掘程序代码信息的同时,如何降低运算开销也十分重要。
4.2 构造能够保持代码多种特性的程序算法识别大模型
相较于自然语言,程序设计语言具有更多特性。首先,程序代码可以表示为AST,具有强结构性;其次,程序代码具有更加明显的环境相关性,当程序代码中的元素脱离上下文环境时,其语义信息可能丢失;最后,程序代码具备长依赖性,例如程序代码中的变量,有的定义于代码首,却用于代码尾,再如局部变量和方法,只用于局部区域,这也加长了上下文的直接依赖。而在表征程序代码时可能会破坏这种特性,不利于程序语义信息的挖掘。目前,这一问题已经引起研究人员的注意,逐步将基于自注意力机制的神经网络大模型Transformer用于代码表征从而缓解长依赖等问题。由于大模型采用了大量程序设计语言描述的语料训练模型,使其学到了一些有关程序设计语言的语法、语义和结构等,具备了一定的程序算法理解能力。未来,如何充分利用大模型针对程序代码所具备的特性进一步构造适用于程序算法识别任务的代码大模型,是一项非常值得研究的内容。
4.3 建立适用于程序算法识别任务的评估指标
在对不同的程序算法识别方法进行评估时,一方面,所采用的评估指标也各不相同,不利于横向比较各个方法与模型的优劣。另一方面,目前常用的评估指标如精确率、召回率等主要应用于自然语言处理领域,对于程序算法识别领域是否适用还需进一步探究。此外,在使用传统指标评价代码大模型时,评估效果可能过高,或许难以满足大模型的评价需求。因此,如何从反映程序算法识别结果的准确性、完整性、鲁棒性等方面,深入探索这一任务的评估方向、探讨现有评估指标的适用性、设立统一的评估指标是一项亟待解决的问题。
4.4 打破模态壁垒以更加高效地表征程序代码
跨模态表征能够通过利用多模态数据之间的互补性剔除冗余内容,获取更有效的特征表示[60]。当前的程序算法识别任务,既能够基于代码文本,又能够利用融合自然语言文本和代码文本双模态的数据,还可以通过代码图像予以实现,但尚未扩展至多模态数据。未来如何充分融合代码文本、自然语言文本与代码图像等多模态资源,通过跨模态表征手段进一步捕捉更高效的代码特征表示,在提升代码自身特征利用率以及程序算法识别精确率的同时,降低计算资源为模态扩展能力带来的限制是一个值得探索的方向。
针对上述问题,仍然需要研究者们付出坚持不懈的努力,打破现有方法自身局限性,减少甚至消除表征时对于程序代码特性的破坏,采用多模态大模型学习程序代码表征,充分利用其中所蕴涵的更深层次的信息,通过统一的评估指标对各个方法与模型展开评价,让程序算法识别任务更好地服务于程序理解、软件工程和编程教育等行业。
5 结束语
程序算法识别以自动化理解程序算法为主要研究目标,推动了软件工程、编程教育等众多领域快速发展,目前程序算法识别方法主要分为基于知识表示、基于信息检索以及基于代码表征的方法三类。本文首先对算法、程序算法的概念进行梳理,并且对基于知识表示和基于信息检索的方法进行简介;其次,将基于代码表征的方法划分为基于序列、基于树和基于图的方法展开详细阐述,总结对比了各个方法的优势与劣势;接着,对程序算法识别任务在代码变换与优化、程序诊断及验证、程序理解和编程教育等多个方面的应用进行介绍;最后,针对程序算法识别任务中尚存的缺陷从四个方面提出展望,期待程序算法识别任务进一步推动多个领域高质量地发展。
参考文献:
[1]Wirth N. Algorithms+data structures=programs[M]. USA: Prentice Hall PTR, 1978.
[2]Shao Yichao, Huang Zhiqiu, Li Weiwei, et al. Fast code recommendation via approximate sub-tree matching[J]. Frontiers of Information Technology & Electronic Engineering, 2022,23(8): 1205-1216.
[3]魏敏, 张丽萍. 代码搜索方法研究进展[J]. 计算机应用研究, 2021,38(11): 3215-3221,3230. (Wei Min, Zhang Liping. Research progress of code search methods[J]. Application Research of Computer, 2021,38(11): 3215-3221,3230.)
[4]鲁强, 李效恋, 王智广. 程序算法识别研究综述[J]. 计算机应用, 2012,32(10): 2863-2868. (Lu Qiang, Li Xiaolian, Wang Zhiguang. Survey on program algorithm recognition research[J]. Journal of Computer Applications, 2012,32(10): 2863-2868.)
[5]唐良荣, 唐建湘, 范丰仙, 等. 计算机导论: 计算思维和应用技术 [M]. 北京: 清华大学出版社, 2015. (Tang Liangrong, Tang Jianxiang, Fan Fengxian, et al. Introduction to computer science: computational thinking and applied technology[M]. Beijing: Tsinghua University Press, 2015.)
[6]Hill R K. What an algorithm is[J]. Philosophy & Technology, 2016,29(1): 35-59.
[7]郝宁湘. 丘奇——图灵论点与认知递归计算假说[J]. 自然辩证法研究, 1997,13(11): 19-23. (Hao Ningxiang. Church Turing’s argument and the hypothesis of cognitive recursive computing[J]. Research on Dialectics of Nature, 1997,13(11): 19-23.)
[8]Knuth D E. The art of computer programming[M]. [S.l.]: Pearson Education, 1997.
[9]严蔚敏, 李冬梅, 吴伟民. 数据结构[M]. 北京: 人民邮电出版社: 2015. (Yan Weimin, Li Dongmei, Wu Weimin. Data structure[M]. Beijing: People’s Post and Telecommunications Publishing House, 2015.)
[10]Murray W R. Automatic program debugging for intelligent tutoring systems[M]. [S.l.]: Morgan Kaufmann Publishers Inc.,1989.
[11]Johnson W L, Soloway E. PROUST: knowledge-based program understanding[J]. IEEE Trans on Software Engineering, 1985, SE-11(3): 267-275.
[12]Abd-El-Hafiz S K. Effects of decomposition techniques on knowledge-based program understanding[C]//Proc of Proc International Confe-rence on Software Maintenance. Piscataway, NJ: IEEE Press, 1997: 21-30.
[13]Abd-El-Hafiz S K. Evaluation of a knowledge-based approach to program understanding[C]//Proc of Proc of International Conference on Software Maintenance. Piscataway, NJ: IEEE Press, 1996: 275-284.
[14]王甜甜, 许家欢, 王克朝, 等. 示例演化驱动的学生程序自动修复[J]. 软件学报, 2019,30(5): 1256-1268. (Wang Tiantian, Xu Jiahuan, Wang Kechao, et al. Example-evolution-driven automatic repair of student programs[J]. Journal of Software, 2019,30(5): 1256-1268.)
[15]Harandi M T, Ning J Q. Knowledge-based program analysis[J]. IEEE Software, 1990,7(1): 74-81.
[16]Wang Shaowei, Lo D, Xing Zhenchang, et al. Concern localization using information retrieval: an empirical study on Linux kernel[C]//Proc of the 18th Working Conference on Reverse Engineering. Pisca-taway, NJ: IEEE Press, 2011: 92-96.
[17]Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620.
[18]Marcus A, Maletic J I, Sergeyev A. Recovery of traceability links between software documentation and source code[J]. International Journal of Software Engineering and Knowledge Engineering, 2005,15(5): 811-836.
[19]Poshyvanyk D, Gueheneuc Y G, Marcus A, et al. Feature location using probabilistic ranking of methods based on execution scenarios and information retrieval[J]. IEEE Trans on Software Enginee-ring, 2007,33(6): 420-432.
[20]唐焕玲, 卫红敏, 王育林, 等. 结合LDA与word2vec的文本语义增强方法[J]. 计算机工程与应用, 2022,58(13): 135-145. (Tang Huanling, Wei Hongmin, Wang Yulin, et al. Text semantic enhancement method combining LDA and word2vec[J]. Computer Engineering and Applications, 2022,58(13): 135-145.)
[21]李政亮, 陈翔, 蒋智威, 等. 基于信息检索的软件缺陷定位方法综述[J]. 软件学报, 2021,32(2): 247-276. (Li Zhengliang, Chen Xiang, Jiang Zhiwei, et al. Survey on information retrieval-based software bug localization methods[J]. Journal of Software, 2021, 32(2): 247-276.)
[22]Maletic J I, Marcus A. Using latent semantic analysis to identify similarities in source code to support program understanding[C]//Proc of the 12th IEEE Internationals Conference on Tools with Artificial Intelligence. Piscataway, NJ: IEEE Press, 2000: 46-53.
[23]岳雷, 崔展齐, 陈翔, 等. 基于历史缺陷信息检索的语句级软件缺陷定位方法[J/OL]. 软件学报. (2023-09-08). https://kns.cnki.net/kcms/ detail/11.2560.TP.20230906.1508.001.html. (Yue Lei, Cui Zhanqi, Chen Xiang, et al. Statement level software bug localization based on historical bug information retrieval[J/OL]. Journal of Software. (2023-09-08). https://kns.cnki.net/kcms/detail/11.2560. TP.20230906.1508.001.html.)
[24]Jiang Lingxiao, Misherghi G, Su Zhendong, et al. DECKARD: sca-lable and accurate tree-based detection of code clones [C]//Proc of the 29th International Conference on Software Engineering. Pisca-taway, NJ: IEEE Press, 2007: 96-105.
[25]Hindle A, Barr E T, Gabel M, et al. On the naturalness of software[J]. Communications of the ACM, 2016, 59(5): 122-131.
[26]White M, Tufano M, Vendome C, et al. Deep learning code fragments for code clone detection[C]//Proc of the 31st IEEE/ACM International Conference on Automated Software Engineering. Pisca-taway, NJ: IEEE Press, 2016: 87-98.
[27]Nievergelt J. On the time required for timing: the halting problem rephrased[J]. IEEE Trans on Computers, 1970,100(5): 458-459.
[28]张祥平, 刘建勋. 基于深度学习的代码表征及其应用综述[J]. 计算机科学与探索, 2022,16(9): 2011-2029. (Zhang Xiangping, Liu Jianxun. Overview of deep learning-based code representation and its applications[J]. Computer Science and Exploration, 2022,16(9): 2011-2029.)
[29]张冬梅, 陈永乐, 杨玉丽. 基于分层特征的代码克隆检测方法[J]. 计算机工程, 2021,47(10): 125-131. (Zhang Dongmei, Chen Yongle, Yang Yuli. Code clone detection method based on hie-rarchical feature[J]. Computer Engineering, 2021,47(10): 125-131.)
[30]Feng Zhangyin, Guo Daya, Tang Duyu, et al. CodeBERT: a pre-trained model for programming and natural languages[EB/OL]. (2020-09-18). https://arxiv.org/abs/2002.08155.
[31]成思强, 刘建勋, 彭珍连, 等. 以CodeBERT为基础的代码分类研究[J]. 计算机工程与应用, 2023,59(24): 277-288. (Cheng Siqiang, Liu Jianxun, Peng Zhenlian, et al. CodeBERT based code classification method[J]. Computer Engineering and Applications, 2023,59(24): 277-288.)
[32]Wang Yue, Wang Weishi, Joty S, et al. Codet5: identifier-aware unified pre-trained encoder-decoder models for code understanding and generation [EB/OL]. (2021-09-02). https://arxiv.org/abs/2109.00859.
[33]Huang Lu, Xue Jingfeng, Wang Yong, et al. EAODroid: Android malware detection based on enhanced API order[J]. Chinese Journal of Electronics, 2023, 32(5): 1169-1178.
[34]李玫, 高庆, 马森, 等. 面向代码相似性检测的相似哈希改进方法 [J]. 软件学报, 2021,32(7): 2242-2259. (Li Mei, Gao Qing, Ma Sen, et al. Enhanced simhash algorithm for code similarity detection[J]. Journal of Software Science, 2021, 32(7): 2242-2259.)
[35]谢春丽, 梁瑶, 王霞. 深度学习在代码表征中的应用综述[J]. 计算机工程与应用, 2021,57(20): 53-63. (Xie Chunli, Liang Yao, Wang Xia. Survey of deep learning applied in code representation[J]. Computer Engineering and Applications, 2021, 57(20): 53-63.)
[36]魏敏, 张丽萍, 闫盛. 基于程序向量树和聚类的学生程序算法识别方法[J]. 计算机工程与设计, 2022,43(10): 2790-2798. (Wei Min, Zhang Liping, Yan Sheng. Student program algorithm recognition based on program vector tree and clustering[J]. Compu-ter Engineering and Design, 2022, 43(10): 2790-2798.)
[37]彭斌, 李征, 刘勇, 等. 基于卷积神经网络的代码注释自动生成方法[J]. 计算机科学, 2021,48(12): 117-124. (Peng Bin, Li Zheng, Liu Yong, et al. A method for automatica code comments generation method based on convolutionalneural networks[J]. Computer Science, 2021, 48(12): 117-124.)
[38]龚丹, 王甜甜, 苏小红, 等. 基于软件历史仓库和抽象语法树的相似缺陷识别方法[J]. 系统工程与电子技术, 2020,42(10): 2399-2408. (Gong Dan, Wang Tiantian, Su Xiaohong, et al. Identification method of similar bugs based on software repository and abstract syntax tree[J]. Systems Engineering and Electronic Technology, 2020, 42(10): 2399-2408.)
[39]Zhang Jian, Wang Xu, Zhang Hongyu, et al. A novel neural source code representation based on abstract syntax tree[C]//Proc of the 41st International Conference on Software Engineering. Piscataway, NJ: IEEE Press, 2019: 783-794.
[40]金岩磊, 秦冠军, 姜凯, 等. 基于结构和语义的代码分类以及聚类方法[J]. 计算机应用与软件, 2023,40(7): 1-6,33. (Jin Yanlei, Qin Guanjun, Jiang Kai, et al. Code classification and clustering methods based on structure and semantics information[J]. Computer Applications and Software, 2023,40(7): 1-6,33.)
[41]Hua Wei,Liu Guangzhong.Transformer-based networks over tree structures for code classification[J]. Applied Intelligence, 2022,52: 8895-8909.
[42]Zhang Aiping, Fang Liming, Ge Chunpeng, et al. Efficient Transformer with code token learner for code clone detection[J]. Journal of Systems and Software, 2023, 197: 111557.
[43]杨克, 贺也平, 马恒太, 等. 精准执行可达性分析: 理论与应用[J]. 软件学报, 2018, 29(1): 1-22. (Yang Ke,He Yeping,Ma Hengtai,et al. Precise execution reachability analysis:theory and app-lication[J]. Journal of Software, 2018,29(1): 1-22.)
[44]金芝, 刘芳, 李戈. 程序理解: 现状与未来[J]. 软件学报, 2019, 30(1): 110-126. (Jin Zhi, Liu Fang, Li Ge. Program comprehension: present and future[J]. Journal of Software, 2019, 30(1): 110-126.)
[45]梁瑶, 谢春丽, 王文捷. 基于图嵌入的代码相似性度量[J]. 计算机科学, 2022,49(S2): 801-806. (Liang Yao, Xie Chunli, Wang Wenjie. Code similarity measurement based on graph embedding[J]. Computer Science, 2022, 49(S2): 801-806.)
[46]肖添明, 管剑波, 蹇松雷, 等. 基于代码属性图和Bi-GRU的软件脆弱性检测方法[J]. 计算机研究与发展, 2021,58(8): 1668-1685. (Xiao Tianming, Guan Jianbo, Jian Songlei, et al. Software vulnerability detection method based on code property graph and Bi-GRU[J]. Computer Research and Development, 2021, 58(8): 1668-1685.)
[47]Cao Sicong, Sun Xiaobing, Bo Lili, et al. BGNN4VD: constructing bidirectional graph neural-network for vulnerability detection[J]. Information and Software Technology, 2021, 136: 106576.
[48]Guo Daya, Ren Shuo, Lu Shuai, et al. GraphCodeBERT:pre-training code representations with data flow[EB/OL].(2021-09-13).https://arxiv.org/abs/2009.08366.
[49]Ben-Nun T, Jakobovits A S, Hoefler T. Neural code comprehension: a learnable representation of code semantics[C]//Proc of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 3589-3601.
[50]谢春丽, 蔺疆旭, 刘小洋, 等. 改进的卷积神经网络源代码相似性度量方法[J]. 应用数学和力学, 2019, 40(11): 1235-1245. (Xie Chunli, Lin Jiangxu, Liu Xiaoyang, et al. Improved convolutional neural network source code similarity measurement method[J]. Applied Mathematics and Mechanics, 2019, 40(11): 1235-1245.)
[51]Ragkhitwetsagul C, Krinke J, Marnette B. A picture is worth a thousand words: code clone detection based on image similarity[C]//Proc of the 12th International Workshop on Software Clones. Pisca-taway, NJ: IEEE Press, 2018: 44-50.
[52]张丹丹, 宋亚飞, 刘曙. MalMKNet: 一种用于恶意代码分类的多尺度卷积神经网络[J]. 电子学报, 2023, 51(5): 1359-1369. (Zhang Dandan, Song Yafei, Liu Shu. MalMKNet: a multi-scale convolutional neural network used for malware classification[J]. Journal of Electronic Science, 2023, 51(5): 1359-1369.)
[53]郑珏, 欧毓毅. 基于卷积神经网络与多特征融合恶意代码分类方法[J]. 计算机应用研究, 2022,39(1): 240-244. (Zheng Jue, Ou Yuyi. Malware classification method based on convolutional neural network and multi-feature fusion[J]. Application Research of Computers, 2022, 39(1): 240-244.)
[54]张学令. 程序优化与程序变换方法的研究[D]. 合肥: 中国科学技术大学, 2014. (Zhang Xueling. The research on program optimization and program trans94ec4def9f404eeebaa44f1713c7fc7919c1ef93c6004adcef67e9705c805919formation methods[D]. Hefei: University of Science and Technology of China, 2014.)
[55]Alluru K, Jeganathan L. Code optimizations for parallelization of programs using data dependence identifier[J]. International Journal of Advanced Computer Science and Applications, 2021,12(10): 837-846.
[56]陈小全, 薛锐. 程序漏洞: 原因、利用与缓解——以C和C++语言为例[J]. 信息安全学报, 2017, 2(4): 41-56. (Chen Xiaoquan, Xue Rui. Cause, exploitation and mitigation of program vulnerability—C and C++ language as an example[J]. Journal of Information Security, 2017, 2(4): 41-56.)
[57]徐俊洁. 多故障程序的概率诊断方法研究[D]. 大连: 大连海事大学, 2016. (Xu Junjie. Probabilistic diagnosis methods for multi-fault programs[D]. Dalian: Dalian Maritime University, 2016.)
[58]赵亮, 陈志奎. 大数据算法库教学实验平台设计与实现[J]. 实验技术与管理, 2020,37(6): 197-201,206. (Zhao Liang, Chen Zhikui. Design and realization of teaching and experimental platform for big data algorithm library[J]. Experimental Technology and Management, 2020, 37(6): 197-201,206.)
[59]Gao Lei, Wan Bo, Fang Cheng, et al. Automatic clustering of diffe-rent solutions to programming assignments in computing education[C]//Proc of ACM Conference on Global Computing Education. New York: ACM Press, 2019: 164-170.
[60]刘华峰, 陈静静, 李亮, 等. 跨模态表征与生成技术[J]. 中国图象图形学报, 2023, 28(6): 1608-1629. (Liu Huafeng, Chen Jingjing, Li Liang, et al. Cross-modal representation learning and generation [J]. Chinese Journal of Image and Graphics, 2023, 28(6): 1608-1629.)
