控制失真漂移的HEVC视频自适应隐写算法
2024-08-15朱燕彬徐达文








摘 要:现有自适应视频隐写的成本分配方法主要针对特定变换系数,导致容量较低。此外,失真漂移是HEVC(high efficiency video coding)视频隐写面临的一大挑战。因此,结合HEVC视频编码的帧内帧间过程,提出了一种代价分配方法,以实现高容量、低失真传递的高性能视频自适应隐写。首先,该方法针对HEVC视频编码中的离散正弦变换特征进行研究,分析了这些系数在受到扰动后所产生的误差传播规律。在嵌入过程中,对修改变换系数导致的块内失真、块间失真、帧间失真进行了详细分析,并考虑不同块隐写产生的块间失真差异对块进行分类。该算法充分利用所有的非零变换系数,为不同的载体系数分配了不同的失真代价,将隐秘信息嵌入到对视频质量影响较小的帧中。实验结果表明,与现有的HEVC视频系数域隐写方法相比,该算法在视频码率、视频质量和嵌入容量方面具有一定的优势。
关键词:自适应视频隐写; 失真漂移; HEVC
中图分类号:TP309.7 文献标志码:A
文章编号:1001-3695(2024)08-037-2508-07
doi:10.19734/j.issn.1001-3695.2023.11.0573
HEVC video adaptive steganography algorithmbased on controlling distortion drift
Zhu Yanbin1,2, Xu Dawen2
(1. School of Information Engineering, Chang’an University, Xi’an 710064, China; 2.School of Cyber Science & Engineering, Ningbo University of Technology, Ningbo Zhejiang 315211, China)
Abstract:Existing cost allocation methods for adaptive video steganography mainly focus on specific transform coefficients, resulting in lower capacity. Moreover, distortion drift is a significant challenge for steganography in HEVC videos. Therefore, this paper proposed a cost allocation method that combined the intra-frame and inter-frame processes of HEVC video coding to achieve high-capacity, low-distortion transmission in high-performance adaptive video steganography. Firstly, the method investigated the discrete sine transform features in HEVC video coding, analyzing the error propagation patterns of these coefficients under disturbance. During the embedding processed, it conducted a detailed analysis on the intra-block distortion, inter-block distortion, and inter-frame distortion caused by modifying transform coefficients. The algorithm also took into account the differentiation in inter-block distortion resulting from steganography in different blocks, leading to the classification of blocks. This paper maximized the utilization of all non-zero transform coefficients, allocating distinct distortion costs for various carrier coefficients. The covert information was then embedded into frames that minimally impacted video quality. Experimental results indicate that, compared to existing HEVC video coefficient domain steganography methods, the proposed algorithm demonstrates advantages in terms of video bitrate, video quality, and embedding capacity.
Key words:adaptive video steganography; distortion drift; HEVC
0 引言
随着信息技术的快速发展和互联网的普及,人们对保护和传输敏感信息的需求越来越迫切。在此背景下,隐写技术作为一种信息隐藏技术,在保密通信等领域被广泛应用。隐写技术通过在媒介中嵌入隐秘信息,使其对未经授权的人不可察觉,旨在提供安全、可靠且隐蔽的通信手段,同时确保信息的完整性和保密性。
视频隐写[1,2]是一种重要的隐写技术,它利用视频作为载体来隐藏和传输隐秘信息。相对于传统的文本或图像隐写,基于视频的隐写技术具有更高的隐蔽性和嵌入容量。视频作为具有丰富多媒体特性的载体,为隐写术提供了广阔的应用空间。
视频隐写一般可分为空间域隐写和压缩域隐写两类。空间域隐写借鉴了图像领域中的经典算法进行隐写,即在视频帧的原始像素上进行隐写,而另一种则是结合视频编码压缩域隐写。HEVC(high efficiency video coding)是一种高效的视频编码标准,能够提供更好的视频质量和更低的比特率[3]。因此,HEVC视频在广播、视频会议、互联网传输等高清视频领域得到广泛应用。在HEVC隐写中,隐秘信息被嵌入到压缩视频的特定部分,如帧内预测模式(intra prediction mode,IPM)[4~6]、运动矢量(motion vector,MV)[7~9]、预测单元划分模式(partition mode of prediction unit)[10,11]、量化离散余弦变换(quantified discrete cosine transform,QDCT)系数或量化离散正弦变换(quantified discrete sine transform,QDST)系数[12~17]以及样点自适应补偿(sample adaptive offset,SAO)[18]等。与H.264/AVC相比,HEVC在DCT的基础上引入了DST,并引入了自适应滤波、递归阻塞等新特性。因基于变换系数的HEVC视频隐写算法具有较高的嵌入容量而得到较多的研究。Chang等人[12]和Van等人[13]提出了基于HEVC标准的数据隐藏算法,通过修改DST系数的奇偶性来嵌入隐秘信息。但是这种隐写造成的失真,会随着编码的帧内预测而扩散,产生失真漂移。为了避免隐写造成的帧内失真漂移,Liu等人[14]提出将隐秘信息嵌入4×4 TU(transform unit)块的DST系数中,在满足帧内预测方向的三个条件的位置用多个系数隐写一位隐秘信息,以防止HEVC下的失真漂移。Chang等人[15]对4×4 TU和8×8 TU块进行分析,设计更大块中的多系数耦合,避免失真漂移。随着隐写术的发展,STC(syndrome-trellis code)[19]成为了一种广泛应用的隐写编码,研究者们相继提出了基于STC隐写编码的若干种视频自适应隐写方案。Zhou等人[16]提出了一种基于DCT/DST系数和BLB(block based)失真模型的HEVC隐写算法。BLB失真模型同时考虑了块间失真和块内失真,该算法采用帧内无误差传播的方法将隐秘信息隐藏在小块中,在消除块间失真的同时大大提高了嵌入容量。Yang等人[17]提出了基于失真补偿的HEVC视频隐写算法,通过设计一种包含块内失真、帧间失真影响、块纹理复杂度和系数组代价的自适应函数,来指导STC向那些嵌入影响小、块纹理复杂度高的区域嵌入隐秘信息。Yang等人[17]还提出了一种可以抵抗基于CER隐写分析的HEVC隐写算法。现有的这些视频隐写框架的代价分配方法都是利用耦合系数进行隐写设计,如文献[14,15]都是对块实现多系数耦合进行隐写,这导致在该部分的隐写会引起比特率的增长。以往工作大多只在小块中采用帧内无错误传播的方法嵌入数据。较大的块通常避免隐藏数据,因为在大块编码图像的平坦区域隐写,会带来明显的失真。然而,随着分辨率的提高,HEVC视频中更多的是大尺寸的块。如果不使用大尺寸块来隐藏数据,则大量数据隐藏空间未被充分利用。另一方面,这种帧内无错误传播的隐写方法会增加码率。总的来说,现有的视频隐写框架和其代价分配方法的局限性限制了隐写视频的编码性能。
9060d614ba55de8809e947de6864a0ae在面对这两个问题的挑战时,首先推导出了一个综合考虑块内、块间和帧间失真的畸变模型。接着,为了提高数据块的嵌入效率并减少块内失真,提出了STC框架作为一种新的嵌入方法。本文算法根据HEVC视频编码特性,对视频的特征和嵌入要求进行了分析,以起到动态调整隐写参数的效果,实现隐蔽性和视觉质量之间的平衡。具体而言,在视频的变换域中嵌入隐秘信息,利用视频的冗余和感知模型来确保隐秘信息对于正常观看者不可察觉。实验验证了本文算法有更好的隐写效果。
1 HEVC帧内变换编码与失真分析
在编码中,HEVC采用分块概念,并定义了编码树单元(coding tree units,CTU)、编码单元(coding units,CU)、预测单元(prediction units,PU) 和变换单元(transform units,TU)。其中PU是进行预测运算的基本单元。HEVC通过四叉树划分方法对CU进行划分,并支持从8×8到64×64大小的CU。对于一个2N×2N的CU,帧内预测单元可选模式有划分为N×N或者2N×2N的块。
1.1 HEVC中的DCT/DST变换过程
变换单元是HEVC变换、量化与熵编码的基本单位。在HEVC编码中,TU块的大小有32×32、16×16、8×8、4×4四种不同的尺寸。与H.264/AVC不同的是,HEVC标准规定,在帧内4×4模式亮度分量残差编码中使用4×4整数DST,而在32×32、16×16、8×8块中使用的是整数DCT。以4×4的块为例,整个DST变换过程如下:
假设RP4×4表示的是该块的亮度残差系数:
RP4×4=R00R01R02R03R10R11R12R13R20R21R22R23R30R31R32R33(1)
DST系数矩阵RDST4×4可表示为
RDST4×4=HRP4×4HT=Q00Q01Q02Q03Q10Q11Q12Q13Q20Q21Q22Q23Q30Q31Q32Q33(2)
其中:矩阵H为HEVC编码过程中的DST矩阵;HT是矩阵H的转置矩阵。
H=ABCDCC0-CD-A-CBB-DC-A A=29,B=55,C=74,D=84(3)
在完成DST后,HEVC对DST系数进行量化处理,该过程可用式(4)描述。
RQDST4×4=RDST4×4×MF2qbits+T_shift(4)
其中:qbits和MF是中间变量,定义如下
qbits=14+floorQP6(5)
MF=2qbitsQstep(6)
其中:T_shift是DST的比例因子;Qstep是由量化参数QP确定的量化步长。最后,对量化后的QDST系数RQDST4×4进行熵编码,得到视频码流。
在解码阶段,首先对视频比特流进行熵解码,获得QDST系数RQDST4×4′。然后对QDST系数反量化得到DST系数RDST4×4′。其过程如下:
RDST4×4′= RQDST4×4′×Qstep ×26-shift(7)
其中:shift为中间变量。
shift=6+floor(QP6)-IT_shift(8)
其中:IT_shift为逆DST的比例因子。最后,对解码得到的RDST4×4′执行逆DST,重构残差Rr4×4可以表示为
Rr4×4=HTRDST4×4′H(9)
最终,将预测值与残差值相加,可以得到该块的重构像素即
Pb=Pp+Rr4×4(10)
其中:Pb表示当前块的像素值;Pp表示当前块的预测值。
1.2 块内失真分析
在对HEVC的DST域进行隐写时,需要对DST系数进行修改,从而嵌入隐秘信息。假设矩阵Δ表示的是隐秘信息矩阵,则隐写后的残差矩阵表示为R′QDST4×4:
R′QDST4×4=RQDST4×4+Δ(11)
其中:Δ是通过数据隐藏加入DST系数矩阵。Δ(i,j)=0表示不修改RQDCT4×4的(i,j)位置的值。Δ表示为
Δ=00000000000±10000(12)
对隐写后的残差矩阵进行反量化得到R′DST4×4,对隐写后的系数矩阵进行解码,重构残差可以表示为
R′r4×4=IDST(R′DST4×4)=HT(R′QDST4×4×Qstep×26-shift)H(13)
隐写前后残差的差值可以表示为
ΔRr4×4=Rr′4×4-Rr4×4=HTΔR′r4×4H(14)
由上述公式可知,对DST系数进行隐写时,块内像素残差会发生变化,从而导致该部分像素发生变化,产生块内失真。通过上式分析可知,块间失真影响像素中的残差值,即块内失真影响式(10)中的重构残差Rr4×4。
1.3 块间失真分析
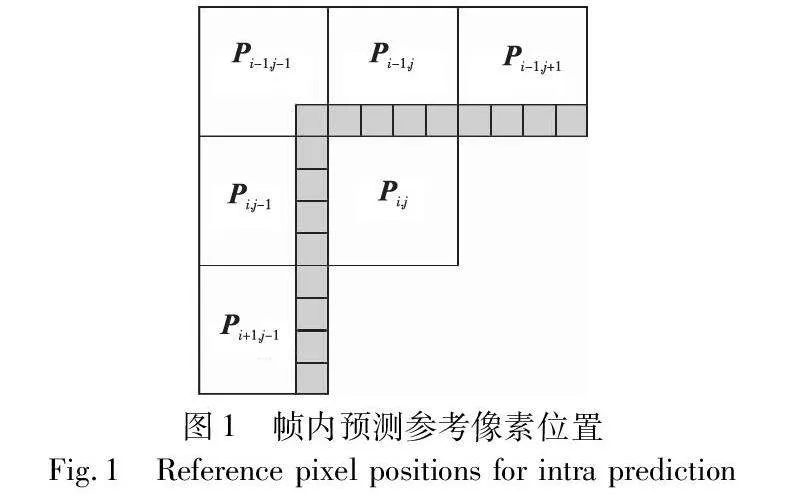
在HEVC编码中,PU块都采用帧内预测模式进行预测编码。预测模式共有35种,分为33种角度模式,平面(模式0:Planar)和直流(模式1:DC)模式。如图1所示,在预测模式中灰色块表示相邻块的像素重建值,用作参考像素,Pi,j表示预测块。
根据1.1节可知,在DST域进行隐写会改变该块内的残差值,从而影响像素值。当图1中预测块(Pi-1,j-1,Pi-1,j,Pi-1,j+1,Pi,j-1,Pi+1,j-1)进行隐写后产生块内失真,其块内像素发生变化,参考像素的像素值也发生变化。在HEVC的帧内预测过程中,由于参考像素发生改变,导致当前块Pi,j的预测像素产生误差。即当前块的预测值发生变化,导致块间失真漂移。同样地,32×32、16×16、8×8也会产生失真漂移。帧内预测使得在参考块中由隐写术引起的失真传播到它们的预测块中,产生失真漂移,会大大降低视频质量。通过上述分析可知,块间失真影响像素中的预测值,即式(10)中的预测值PP。
1.4 帧间失真漂移
帧间预测是视频编码中的关键步骤,通过利用先前编码的参考帧来预测当前帧的像素值,以减小视频序列中的冗余信息。该过程首先进行运动估计,通过比较当前帧与参考帧的块,找到相似位置的运动矢量。然后,通过运动矢量进行运动补偿,从参考帧中提取相应位置的块,并将其叠加到当前帧的预测位置上,形成一个预测块。最后,计算当前帧实际像素值与预测块之间的残差,将残差信息进行编码传递。
帧间预测使得在参考帧中由隐写引起的失真传播到它们的预测帧中。隐写引起帧间失真传递的主要原因与视频编码中的帧间预测误差传递相似。隐写涉及在视频中隐藏信息,而帧间失真传递是指由于视频编码过程中的一些因素导致信息的失真逐渐传递到后续帧。导致帧间失真传递有几方面原因:首先,隐写引起的失真不仅会影响嵌入点所在的帧,还可能通过帧间预测传递到后续的帧。由于帧间预测是通过比较相邻帧之间的差异来实现的,一旦某一帧发生失真,这种失真可能在接下来的预测中得到传递和累积。其次,隐写可能会对视频中的运动矢量产生干扰,所以运动估计是基于原始帧内容进行的。嵌入导致的像素值变化可能使得运动估计算法难以准确地找到相似的块,从而引入额外的运动估计误差。最后,隐写可能会导致视频中的像素值发生微小变化,这些微小变化在量化阶段可能被显著放大。量化误差的引入可能导致失真在编码过程中逐渐传递,影响后续帧的质量。
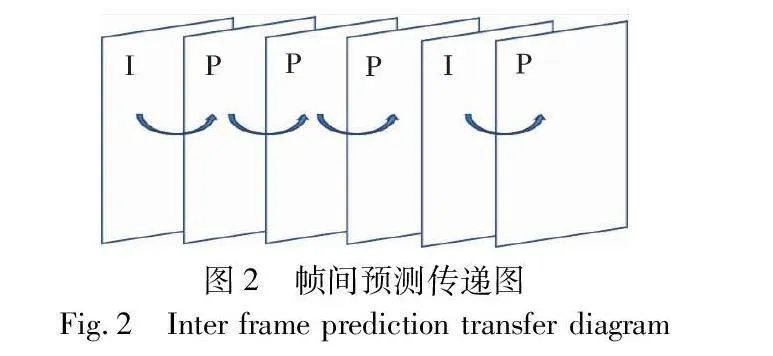
在视频编码中,一个GOP(group of pictures)包括I帧和P帧。其中,I帧通过帧内预测编码减小空间冗余,P帧通过帧间预测减小时间冗余。使用帧间预测时,由于隐写引起的失真会传播到预测帧中。如图2所示,P帧通过参考I帧进行帧间预测,因此在I帧进行隐写产生的失真将通过帧间预测传递到P1、P2、P3帧。同样,P1帧进行隐写产生的失真传递到P2、P3帧,而P2帧的失真传递到P3帧。这种失真的传递现象在视频编码中会影响隐写的稳定性和质量。通过上述分析可知,帧间失真影响式(10)中的预测值PP。
综上,通过1.2~1.4节的分析可知,在编码的变换量化过程中会产生不可避免的编码失真,在对视频进行隐写过程中,帧内和帧间对预测值产生影响而造成隐写失真。最终的预测像素值可以表示为
Pb=Pp′+R′r4×4(15)
其中:P′p表示隐写后当前块的预测值;R′r4×4表示隐写后的残差值。
2 失真漂移传播
通过第1章中的分析可知,修改DST系数将引起块间失真、块内失真和帧间失真,针对以上三部分的失真,本文从三方面进行代价设计,实现一种高效的视频自适应隐写方案。
2.1 块内失真漂移
如第1章所示,对块内的QDST系数进行修改后,会导致块内的QDST系数发生变化,从而导致像素发生变化,产生了块内的失真,所以将块内失真φ[RQDCT(m,n)]定义为
φ-[RQDCT(m,n)]=∑3i=0∑3j=0R-b″(i,j)-Rb′(i,j)Pb′(i,j)(16)
φ+[RQDCT(m,n)]=∑3i=0∑3j=0R+b″(i,j)-Rb′(i,j)Pb′(i,j)(17)
其中:|·|为绝对值函数;φ-[RQDCT(m,n)]和φ+[RQDCT(m,n)]分别对应RQDCT(m,n)-1和RQDCT(m,n)+1(0≤m,n≤3)隐写操作后的失真值;R-b″(i,j)和R+b″(i,j)表示将DCT系数块中位置(m,n)处的值写入隐秘信息“+1”和“-1”对应的残差值;Rb′(i,j)表示未隐写的残差值;Pb′(i,j)为未隐写的重构像素。
2.2 块间失真漂移
对QDST系数进行隐写产生块内失真,作为被参考像素,通过帧内预测将失真传递到相邻块。此部分的失真传递主要是由参考像素决定,所以本文根据当前块的预测模式定义该块的块间失真μ[RQDCT(m,n)]:
μ-[RQDCT(m,n)]=∑k∈V∑h∈UR-b″(k)-Rb′(k)Pb′(h)(18)
μ+[RQDCT(m,n)]=∑k∈V∑h∈UR+b″(k)-Rb′(k)Pb′(h)(19)
其中:V和U表示不同的像素集合;Rb′(k)为隐写前的残差值;Rb″(k)为隐写后的残差值;Pb′(h)为不进行隐写的重建像素。对于不同的块种类,定义不同的V。
类型1如图3所示,P(i+1,j-1)∈{2,3,…,26}∩P(i+1,j)∈{2,3,…,10},即左下块具有预测模式2、3、…、26,下块预测模式2、3、…、10或DC。当预测块满足此条件时,p4,1,p4,2,p4,3,p4,4的失真不会传递到左下块和下块。相邻块在帧内预测过程中会产生失真,此时的块间失真主要由p1,4,p2,4,p3,4,p4,4传递。此时的集合V包含p1,4,p2,4,p3,4,p4,4。
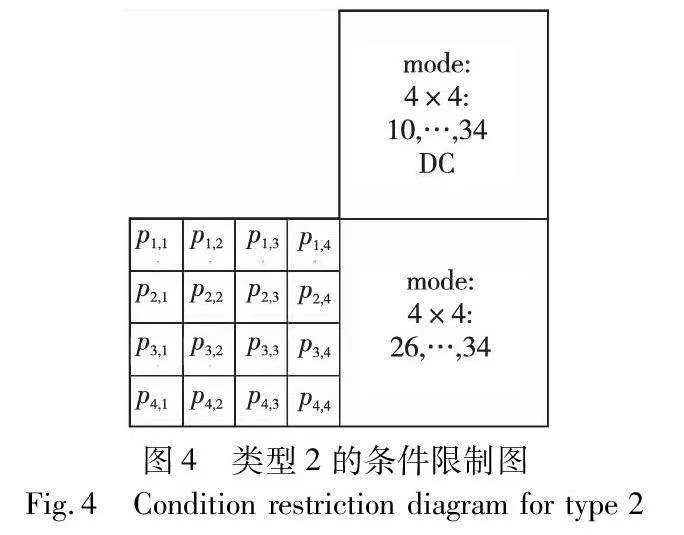
类型2如图4所示,P(i-1,j+1)∈{10,11,…,34}∩P(i,j+1)∈{26,27,…,34},即右上块具有预测模式10、11、…、34或DC,右块预测模式为26、27、…、34。当预测块满足此条件时,p1,4,p2,4,p3,4,p4,4的失真不会传递到右上和右块。相邻块在帧内预测过程中会产生失真,此时失真主要由p4,1,p4,2,p4,3,p4,4引起。此时的集合V包含p4,1,p4,2,p4,3,p4,4。
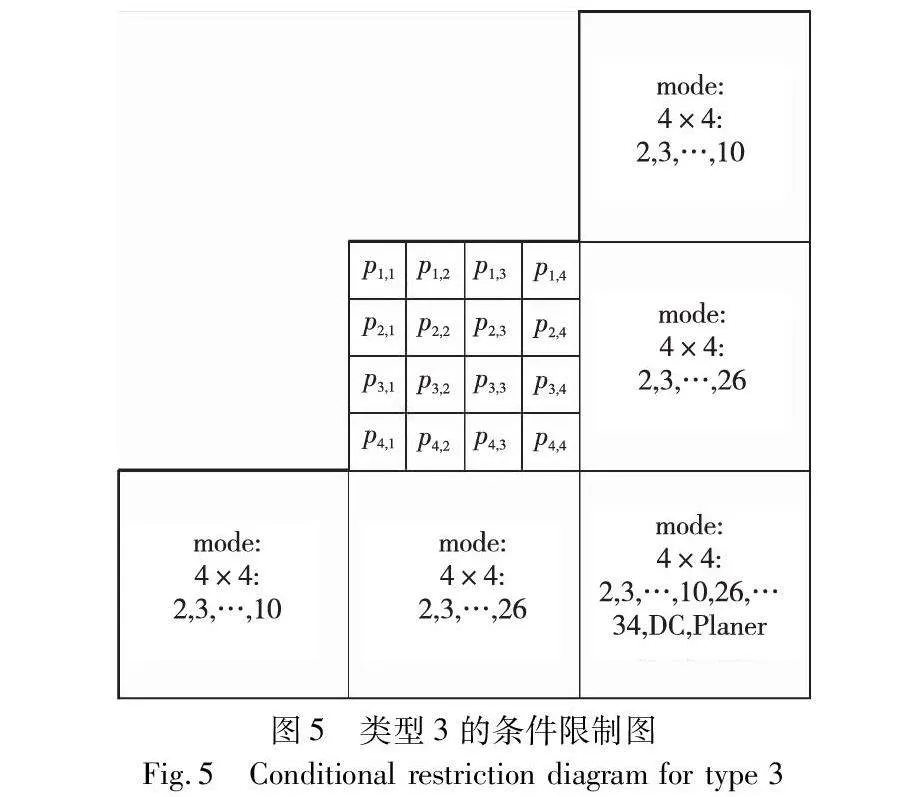
类型3如图5所示,P(i+1,j-1)∈{2,3,…,26}∩P(i+1,j)∈{2,3,…,10}∩P(i-1,j+1)∈{10,11,…,34}∩P(i,j+1)∈{26,27,…,34}∩P(i+1,j+1)∈{2,3,…,10,26,…,34,DC,Planer},即左下块具有预测模式2、3、…、26,下块预测模式2、3、…、10或DC,右上块具有预测模式10、11、…、34、DC,右块预测模式为26、27、…、34,右下块预测模式为2、3、…、10、26、27、…、34或DC、Plannar。当满足该条件时,对该块进行隐写导致产生的块内失真不会造成块间失真。此时的集合V为空。
对于块间失真,第三种块间失真不会产生块间失真的传递,其失真最小。因此,在对I帧进行隐写时,应优先选择第三种情况的块进行隐写。
2.3 帧间失真传递
HEVC的帧间编码是利用已编码帧预测得到当前帧。主要原理是在参考帧中选择最佳匹配块作为当前块的预测,表明参考帧的失真会传递到预测帧,即前一帧的失真会产生累积。
帧间预测使得在参考帧中由隐写术引起的失真传播到它们的预测帧中,所以定义θ(d)使GOP中每个帧的失真呈下降趋势。定义帧间失真为
θ(d)=1mod(d,pre)(20)
其中:mod(d,pre)表示d帧在该GOP中的位置,此处的pre为GOP中的帧数。
2.4 提出的代价函数
视频隐写中,通过对视频进行失真分析,可以得到相应的失真函数来度量嵌入过程中引入的失真。失真函数用于测量隐写后的视频与原始视频之间的差异。
具体而言,本文考虑块内失真、块间失真和帧间失真三个部分的失真。这些部分代表了视频隐写中可能引起的失真来源。最终的失真代价由这三个部分的失真值共同决定。具体失真函数可以表示为
ρ-[RQDCT(m,n)]=f(φ-[RQDCT(m,n)],μ-[RQDCT(m,n)],θ(d))=
(αφ-[RQDCT(m,n)]+βμ-[RQDCT(m,n)])×θ(d)(21)
ρ+[RQDCT(m,n)]=
f(φ+[RQDCT(m,n)],μ+[RQDCT(m,n)],θ(d))=
(αφ+[RQDCT(m,n)]+βμ+[RQDCT(m,n)])×θ(d)(22)
其中:φ、μ、θ分别是块内失真、块间失真和帧间失真;α和β为控制因子,用于调整代价函数的比例,影响块内、块间和帧间失真的相对权重;φ表示块内失真,表示单个块内失真程度,可以帮助选择对块内失真影响更小的点;μ表示该块对相邻块的失真影响,可以帮助选择对相邻块影响更小的嵌入点;θ表示视频帧之间的失真,有助于控制信息嵌入的稳定性。通过综合考虑这些失真来源并设计合适的隐写算法,可以在保持视频质量的同时实现有效的隐写嵌入。
2.5 隐写框架
假设载体序列记为x={x1,x2,x3,…,xn}。这里的n表示载体元素的数量。xi表示为第i个载体元素。在载体元素x中嵌入隐秘信息s后的序列为y={y1,y2,y3,…,yn}。
在STC模型中,ρ(xi,yi)表示x变为y的失真。当x上的嵌入操作相互独立时,每个载体单元的嵌入失真可以被认为是加性的。对于加性失真,STC可以逼近平均失真的下界。那么总的失真函数可以表达为D(x,y)=∑ni=1ρ(xi,yi)(23)
STC的嵌入和提取映射可以表示为
Emb(x,m)=argminy∈C(m)D(x,y)(24)
m=H·y(25)
其中:m是嵌入消息向量;H是奇偶校验矩阵;C(m)={z∈{0,1}n|Hz=m}是m对应的余集。数据提取器可以在接收到y后通过计算H·y来提取消息。
3 实验结果与分析
本章将对实验数据集及其参数进行介绍,并将该实验方案与现有三种方案在隐写容量、视频质量、比特增长率(BIR)等性能方面进行对比。
3.1 视频数据集
本文采用了不同分辨率(416×240、832×480、1024×768、1280×720、1920×1080)的八个视频序列作为实验数据集,所有的视频序列均为未压缩的,并以4∶2∶0的YUV色彩空间存储。本文选取了视频前10个GOP的视频帧,并采用IPPP编码结构对其进行编码处理,QP的取值分别为20、25。实验在HEVC参考软件HM16.7下进行。具体的参数如表1所示。3lCb035Tmdf2F9XN2oN1lw==
3.2 嵌入容量
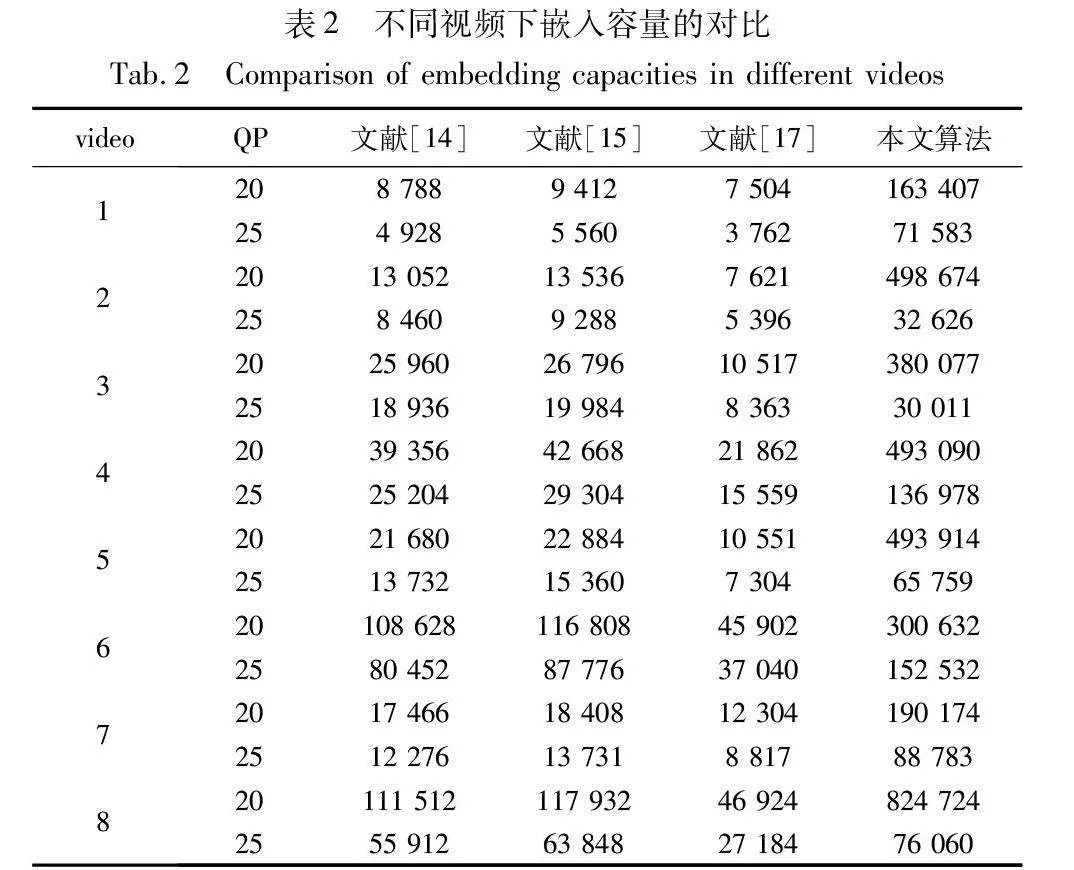
现有HEVC视频DST域隐写操作,通常是对多个DST系数进行适当的修改,以实现多系数耦合,防止由于嵌入操作导致的失真偏移。这涉及在I帧中针对多个DST系数进行调整,使其包括零和非零元素。本文算法选择了所有的非零DST系数进行隐写,嵌入容量更大。为了更好地比较用于隐写的载体数量,本文选取了几个不同分辨率的视频序列在不同的QP下进行比较说明,具体实验结果如表2所示。
本文算法的隐写容量与QP呈反比例关系,即随着QP的降低,载体元素的隐写容量逐渐增加。从理论上来说,这是因为随着QP的降低,视频画面内容的保真度越高,视频内容越清晰,所表现出来的纹理细节更细致,因此每个视频块需要使用更多的比特位来进行编码,从而提供了更多的隐写载体空间,提升了隐写容量。同时,隐写容量也与视频的分辨率成正比关系,即一般情况下,分辨率越高,载体元素越多,这是因为高分辨率视频具有更多的像素点,从而提供更多的隐写载体。
与其他算法相比,本文算法使用了所有的非零系数,这意味着在每个视频块中,所有非零的变换系数都被用于隐写信息的嵌入,从而最大化了隐写容量。举例来说,以视频1为例,当QP为20时,本文算法的隐写容量为163 407 bit,要比文献[14,15,17]的容量大。同样,当QP为25时,本文算法的隐写容量为71 583 bit,也同样大于其他算法。在表中的其他视频也有类似的结果,表明本文算法具有更大的容量优势。
3.3 隐写视频的视觉质量
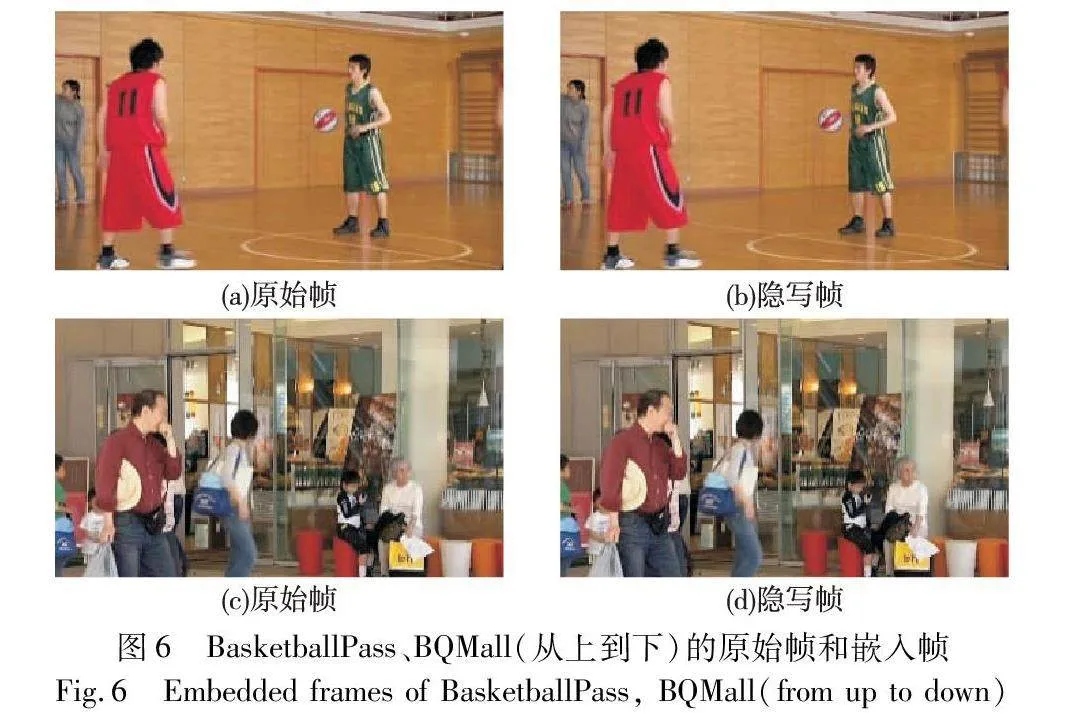
当量化参数(QP)设为20时,BasketballPass和BQMall视频图像的质量如图6所示。图6(a)(c)为原始帧,图6(b)(d)为隐写的嵌入帧,隐写后的视频没有明显的失真。这是由于STC框架通过定义代价函数来确定最佳的信息嵌入方法,以最小化块内失真的影响,确保视频图像的高质量。
基于QDCT系数的隐写技术会改变视频压缩过程中的编码参数和变换系数,进而影响视频的编码性能。本文使用PSNR来度量隐写视频的视觉质量,并通过比较隐写前后未压缩的视频序列以及解码后的重构视频序列来计算PSNR。
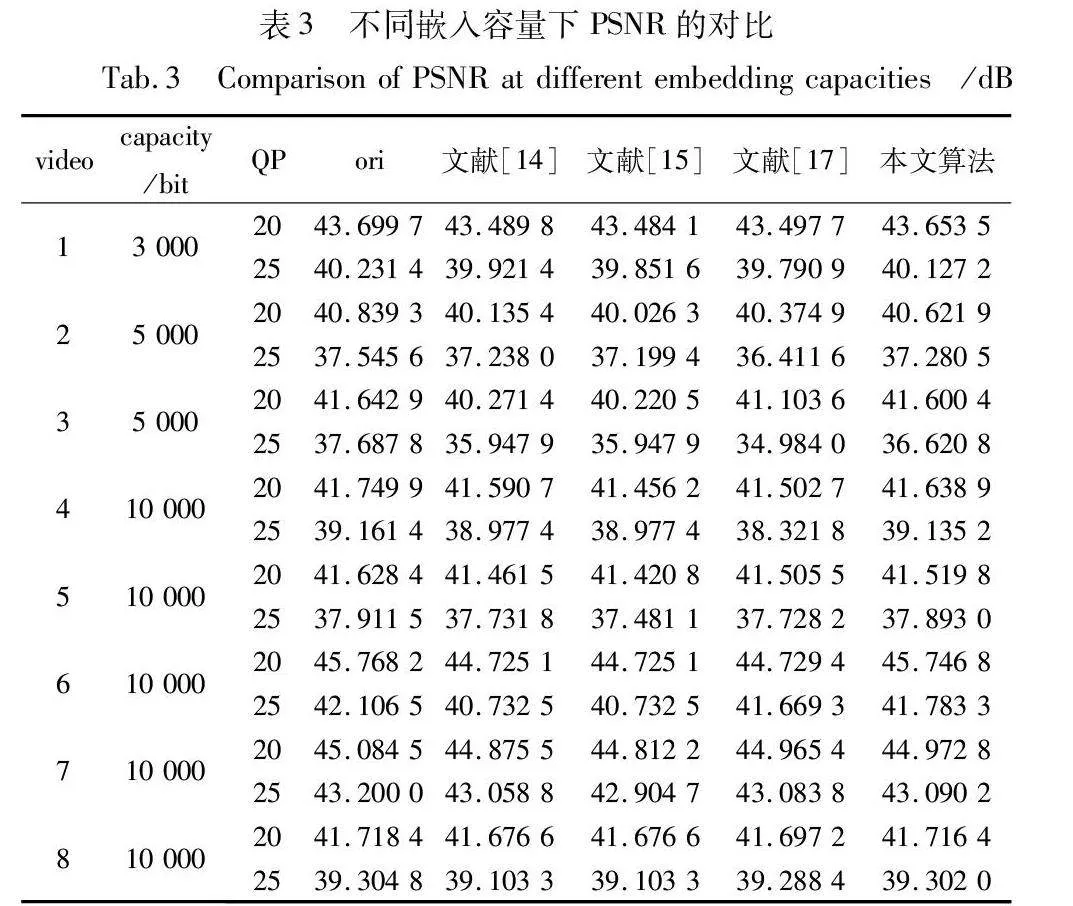
为了比较文献[14,15,17]和本文算法的视频质量,本文设置固定的有效载荷(嵌入容量)来进行比较。表3中给出了在不同嵌入容量下的PSNR值对比,其中ori为原始视频的PSNR。
在相同的GOP(40帧的IPPP)和QP设置下,可以观察到在不同的嵌入容量条件下,本文算法的视频质量PSNR普遍优于其他三种方法(文献[14,15,17])。举例来说,以视频1为例,当嵌入容量为3 000 bit时,本文算法的PSNR为43.653 5 dB,而文献[14,15,17]的PSNR分别为43.489 8 dB、43.484 1 dB和43.497 7 dB,表明本算法隐写视频质量相对更好。类似地,在不同嵌入容量下的其他视频也表现出类似的趋势,表明本文算法在保持较高嵌入容量的同时,能够提供更好的视频质量。
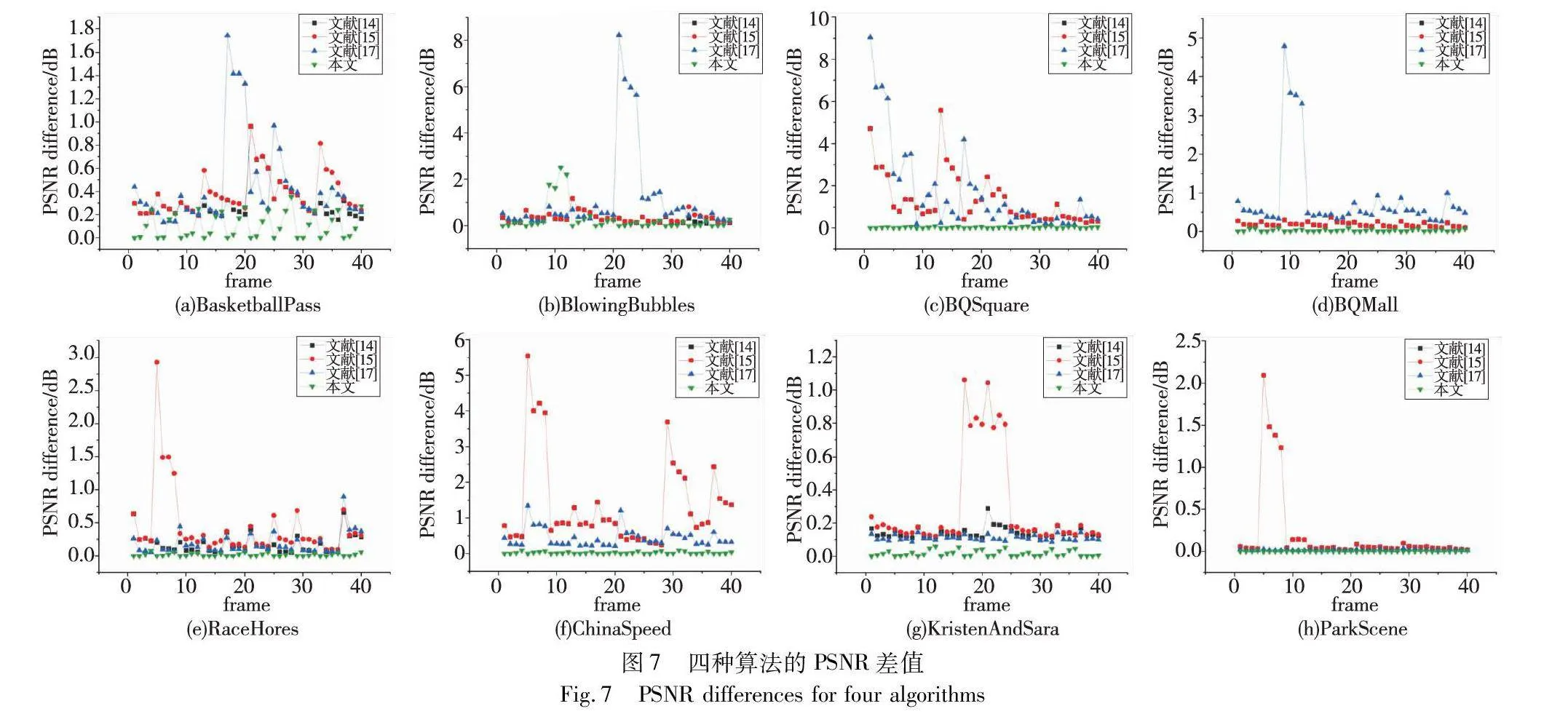
为比较文献[14,15,17]和本文算法的视觉质量,设置QP:25隐写视频的PSNR差值进行对比。文献[14,15,17]和本文算法的PSNR差值如图7所示。
从图7可以看出,对I帧的大量隐写,在帧间编码之后,会对P帧产生较大的失真,即影响整个视频的质量变化。图7显示了每个算法的PSNR差值。可以看出,PSNR差值随帧和算法的不同而变化。如图7(a)所示在这四种算法中,本文算法在大多数帧上始终表现出最低的PSNR差值,这表明其可以更好地保留视频质量并降低失真。文献[14,15]显示出相似的PSNR差值,是因为文献[15]的算法增加了8×8块的隐写,隐写量未到达一定值时,不会在8×8块中进行隐写。本文算法在保持图像质量方面有一定的改进,与文献[14,15,17]相比,PSNR差值始终较低。
3.4 比特率变化
视频编码质量也可以通过比特率的提高来体现。一般来说,根据视频编码标准中的率失真优化(rate distortion optimization,RDO),提高比特率可以获得更好的视觉质量。然而,在视频隐写中,由于嵌入信息会改变一些系数,隐写导致的比特率提高与常规情况完全不同。
在视频隐写中,本文将隐秘信息嵌入到系数的最低比特位中。这样,一个DCT系数的最低比特位的改变代表着嵌入了一比特的信息。因此,在DCT系数中嵌入信息时,会导致一些DCT系数的最低比特位发生改变,从而影响比特率。嵌入的信息越多,导致DCT系数最低比特位改变的次数就越多,比特率也随之增加。
在相同的隐写容量下,较低的比特率增长意味着更高的压缩效率和更紧凑的数据表示。这表示隐写信息被嵌入到视频中所需的额外比特数相对较少,使得媒体文件更小。较低的比特率增长有助于减小隐写引入的影响,提供更高的隐写嵌入效率,同时保持更好的视频质量和更高的传输效率。
对于其他三个算法,它们通过耦合系数进行隐写,避免失真漂移,需要修改更多的系数和更多的零系数,因此本文算法有更低的比特率增长(bit increase ratio,BIR)。BIR定义为
BIR=bitstego-bitoribitori×100%(26)
其中:bitstego、bitori分别表示隐写后和隐写前的比特率。
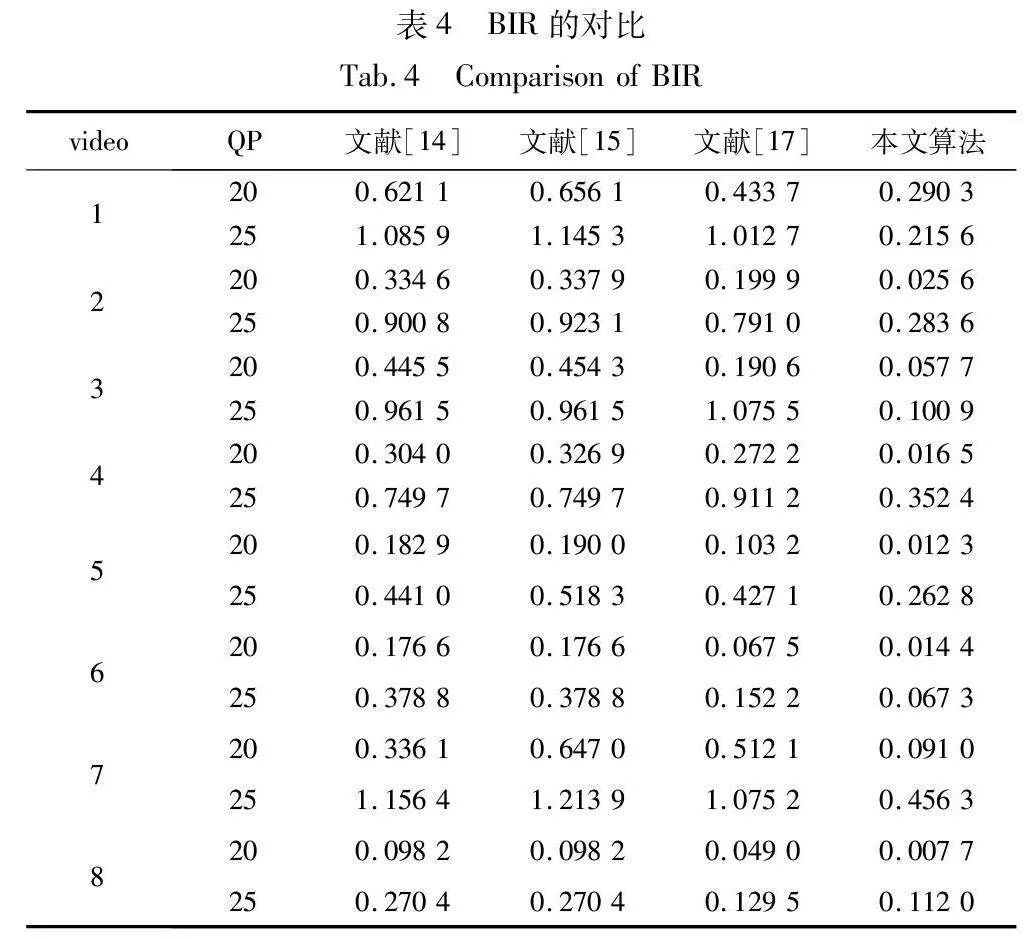
表4所示是在QP为20和25时,不同分辨率视频在相同嵌入容量下的BIR对比。BIR用于衡量隐写算法对视频质量的影响程度,数值越小,表示视频质量的损失越小。
从表4可以观察到,在相同嵌入容量下,本文算法的BIR与其他三种方法相比增加较少,表明本文算法在保持较高嵌入容量的同时,对视频质量的影响较小。从理论角度来看,其他三种算法修改更多的系数(包含非零系数),而本文算法修改了更少的非零系数,从而实现了更小的BIR。
3.5 抗隐写分析
隐写分析是评价隐写算法性能的一种指标,用于检测和评估载体是否包含隐藏的信息。本文采用Wang等人[20]提出的隐写分析算法对视频隐写算法进行对比实验。使用表1列出的视频序列作为本文的数据集,并将其分为测试集和训练集,比例为1∶1。所有的视频序列被均匀地划分成10个不同的子序列,最终得到80个原始子序列和80个隐写子序列。经过50次随机分割数据集后的重复实验,并计算其平均值。实验结果如表5所示。
根据实验结果,观察到本文算法表现出一定的优势,其隐写分析结果为51.43%,表明本文算法在抗隐写分析方面具有较好的性能。
3.6 关于比例因子的讨论
对于算法中不同的(α,β)会有不同的成本,进而导致隐写视频的编码性能和安全性的差异。α和β分别表示块内块间畸变的影响。通过分析可知,块间失真漂移会导致较大的视频视觉质量的下降,设置β值比α更大。在几个视频上设置不同的值,得到平均PSNR、BIR如表6所示。
由表6可以看出,在不同的α和β设置下,平均PSNR的最大值为38.922 5 dB,平均BIR的最小值为0.194 8。由于算法在设置(α,β)=(0.3,0.7)时,在PSNR和BIR方面获得较好的编码性能,所以在实验中采用该设置值。
4 结束语
本文提出了一种高容量的HEVC视频自适应隐写算法,通过对块内、块间和帧间失真的分析,设计了一种代价分配方法。该方法充分利用了所有非零变换系数,并对嵌入过程进行了合理的设计,以控制失真漂移,提高编码性能和安全性。实验结果表明,在相同的嵌入容量下,与其他三种方法相比,本文算法在视频质量、比特率影响和安全性方面均表现更优。未来研究可以进一步提升视频隐写的安全性,探索并设计非加性视频隐写算法,以扩展其在不同应用领域的潜在应用。
参考文献:
[1]Valandar M Y, Ayubi P, Barani M J, et al. A chaotic video steganography technique for carrying different types of secret messages[J]. Journal of Information Security and Applications, 2022, 66: article ID103160.
[2]翟黎明. 数字视频隐写与隐写分析方法研究[D]. 武汉: 武汉大学, 2020. (Zhai Liming. Research on steganography and steganalysis in digital videos[D]. Wuhan: Wuhan University, 2020.)
[3]Sullivan G J, Ohm J R, Han W J, et al. Overview of the high efficiency video coding(HEVC) standard[J]. IEEE Trans on Circuits & Systems for Video Technology, 2013, 22(12): 1649-1668.
[4]徐健, 王让定, 黄美玲, 等. 一种基于预测模式差值的HEVC信息隐藏算法[J]. 光电子·激光, 2015, 26(9): 1753-1760. (Xu Jian, Wang Rangding, Huang Meiling, et al. A data hiding algorithm for HEVC based on the differences of intra prediction modes[J]. Journal of Optoelectronics·Letters, 2015, 26(9): 1753-1760.)
[5]Dong Yi, Jiang Xinghao, Li Zhaohong, et al. Multi-channel HEVC steganography by minimizing IPM steganographic distortions[J]. IEEE Trans on Multimedia, 2023, 25: 2698-2709.
[6]Wang Jie, Yin Xuemei, Chen Yifang, et al. An adaptive IPM-based HEVC video steganography via minimizing non-additive distortion[J]. IEEE Trans on Dependable and Secure Computing, 2023, 20(4): 2896-2912.
[7]邱枫, 钮可, 李军, 等. 基于运动矢量多直方图修正的视频可逆隐写算法[J]. 计算机应用研究, 2022,39(11): 3470-3474. (Qiu Feng, Niu Ke, Li Jun, et al. Video steganography algorithm based on motion vector and multi histogram modification[J]. Application Research of Computers, 2022, 39(11): 3470-3474.)
[8]Zhai Liming, Wang Lina, Ren Yanzhen. Multi-domain embedding strategies for video steganography by combining partition modes and motion vectors[C]//Proc of IEEE International Conference on Multimedia and Expo. Piscataway, NJ: IEEE Press, 2019: 1402-1407.
[9]Liu Shuowei, Liu Beibei, Hu Yongjian, et al. Non-degraded adaptive HEVC steganography by advanced motion vector prediction[J]. IEEE Signal Processing Letters, 2021, 28: 1843-1847.
[10]He Songhan, Xu Dawen, Yang Lin. Adaptive HEVC video stegano-graphy with high performance based on Attention-Net and PU partition modes[J]. IEEE Trans on Multimedia, 2023, 26: 687-700.
[11]He Songhan, Xu Dawen, Yang Lin. HEVC video information hiding scheme based on adaptive double-layer embedding strategy[J]. Journal of Visual Communication and Image Representation, 2022, 87: 103549.
[12]Chang P C, Chung K L, Chen J J, et al. An error propagation free data hiding algorithm in HEVC intra-coded frames [C]//Proc of Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway, NJ: IEEE Press, 2013: 1-9.
[13]Van L P, De Praeter J, Van Wallendael G, et al. Out-of-the-loop information hiding for HEVC video[C]//Proc of IEEE International Conference on Image Processing. Piscataway, NJ: IEEE Press, 2015: 3610-3614.
[14]Liu Yunxia, Liu Shuyang, Zhao Hongguo, et al. A new data hiding method for H.265/HEVC video streams without intra-frame distortion drift[J]. Multimedia Tools & Applications, 2019, 78: 6459-6486.
[15]Chang P C, Chung K L, Chen J J, et al. A DCT/DST-based error propagation-free data hiding algorithm for HEVC intra-coded frames[J]. Journal of Visual Communication & Image Representation, 2014, 25(2): 239-253.
[16]Zhou Aijun, Jiang Xinghao, Sun Tanfeng, et al. A HEVC stegano-graphy algorithm based on DCT/DST coefficients with BLB distortion model[C]//Proc of the 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics. Piscataway, NJ: IEEE Press, 2021: 1-9.
[17]Yang Lin, Xu Dawen, Wang Rangding, et al. Adaptive HEVC video steganography based on distortion compensation optimization[J]. Journal of Information Security and Applications, 2023, 73: 103442.
[18]Cui Yabing, Yao Yuanzhi, Yu Nenghai. Defining embedding distortion for sample adaptive offset-based HEVC video steganography[C]//Proc of the 22nd International Workshop on Multimedia Signal Processing. Piscataway, NJ: IEEE Press, 2020: 1-6.
[19]Filler T, Judas J, Fridrich J. Minimizing embedding impact in stega-nography using trellis-coded quantization[C]//Proc of Media Forensics and Security Ⅱ. [S.l.]: SPIE, 2010: 38-51.
[20]Wang Yu, Cao Yun, Zhao Xianfeng. Video steganalysis based on centralized error detection in spatial domain[C]//Proc of Internatio-nal Conference on Information Security & Cryptology. Cham: Sprin-ger, 2016: 472-483.
[21]Yang Lin, Wang Rangding, Xu Dawen, et al. Centralized error distribution-preserving adaptive steganography for HEVC[J]. IEEE Trans on Multimedia, 2024, 26: 4255-4270
