室内动态场景下基于语义关联的视觉SLAM方法
2024-08-15李泳刘宏杰周永录余映












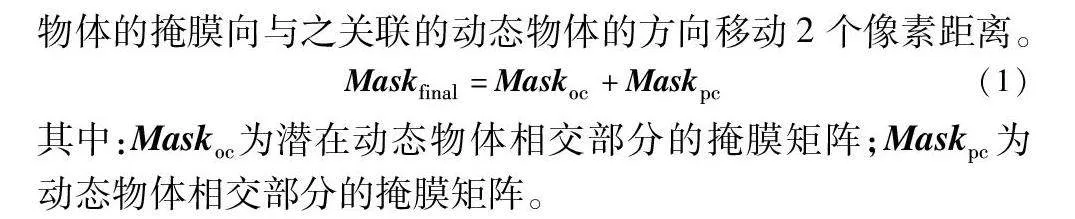

摘 要:针对视觉SLAM在动态场景下鲁棒性不足的问题,提出一种适用于动态场景下的视觉SLAM算法——SAD-SLAM。该算法首先使用GCNv2网络进行特征提取,以获取分布均匀的特征点集合,并加快提取速度。然后使用YOLOv8-seg语义分割网络完成场景内物体的检测,并对推理得到的物体按照是否具备自主运动能力进行划分。同时提出一种语义关联方法,通过对潜在动态物体进行2D和深度层面过滤,以确定潜在动态物体运动的可能性。最后,构建了含有语义信息的稠密3D点云地图,并避免了动态物体的干扰。算法使用TUM数据集及真实场景进行实验验证,结果表明,相较于ORB-SLAM3及其他相关的动态SLAM算法,SAD-SLAM在动态场景下具有更好的定位精度。
关键词:视觉SLAM;深度学习;位姿估计;地图构建;室内动态场景
中图分类号:TP242.6 文献标志码:A 文章编号:1001-3695(2024)08-040-2528-05
doi: 10.19734/j.issn.1001-3695.2023.10.0557
Visual SLAM method based on semantic association in indoor dynamic scenes
Li Yong1, Liu Hongjie1, 2, Zhou Yonglu1, 2, Yu Ying1
(1.School of Information, Yunnan University, Kunming 650000, China; 2. Yunnan Provincial Key Laboratory of Digital Media Technology, Kunming 650223, China)
Abstract:
In order to improve the robustness of visual SLAM in dynamic scenes, this proposed a new visual SLAM algorithm called SAD-SLAM. This algorithm actively extracted features using the GCNv2 network to obtain a set of evenly distributed feature points and accelerate the extraction speed. Additionally, it detected objects within the scene using the YOLOv8-seg semantic segmentation network and classified them based on their ability to move autonomously. Furthermore, it used a semantic association method to filter potential dynamic objects at both the 2D and depth levels, determining their likelihood of movement. Finally, it constructed a dense 3D point cloud map containing semantic information, avoiding interference from dynamic objects. The effectiveness of this algorithm is demonstrated through experiments using the TUM dataset and real-world scenes. The results show that compared to ORB-SLAM3 and other related dynamic SLAM algorithms, SAD-SLAM achieves better positioning accuracy in dynamic scene.
Key words:VSLAM; deep learning; pose estimation; mapping; indoor dynamic scene
0 引言
同时定位与地图构建(simultaneous localization and mapping,SLAM)的问题可以描述为:机器人在位置环境中如何确定自身所在的环境地图以及自身在该环境地图中的位置[1]。根据获取外界信息所使用的外部传感器的不同,SLAM可以分为激光SLAM和视觉SLAM(visual SLAM,VSLAM)。相较于激光雷达,相机低廉的成本和丰富的图像信息使其在动态场景中有着更为广泛的应用[2~5]。
根据其视觉里程计(visual odometry,VO)的不同,VSLAM可以分为特征法和直接法两类。特征法通过记录相邻两帧图像的相同特征以完成位姿估计,如Artal等人[6]提出的ORB-SLAM2通过使用ORB特征点(oriented FAST and rotated BRIFF)进行当前帧与上一帧的特征匹配以估算相机位姿。相较于SIFT[7]、SURF[8]等特征点,ORB特征点的计算量更小,适用于对实时性要求较高的SLAM中。Pumarola等人[9]提出一种基于线特征和点特征共用的SLAM方法,在应对低纹理的场景时,该方法通过检测三个连续帧中的线特征对应关系从而完成初始化位姿估计。直接法基于图像光度不变性的假设,通过最小化光度误差从而求得相机位姿。Engel等人[10]提出一种完全基于直接法的DSO方法,同时为避免光照对图像的影响,该方法提出光度标定,从而保证算法更具鲁棒性。然而,由于传统VSLAM算法假设环境为静态的,而在真实环境中,运动物体的存在会对SLAM造成严重干扰,如何提升SLAM在动态场景下的鲁棒性,已成为该领域需要解决的重大问题。
在视觉SLAM中,附着在动态物体上的特征点被认为是异常值,因此不参与maping和tracking。在早期的视觉SLAM中,主要从几何和光流两个角度来决定检测场景中的运动物体。如Zou等人[11]利用重投影误差,将特征从前一帧投影到当前帧,并测量与被跟踪特征的距离,静态和动态特征的分类取决于其重投影距离的大小。Sun等人[12]通过计算连续RGB图像的强度差异并且量化深度图像的分割,完成像素分类,从而获得场景中的静态部分。Klappstein等人[13]根据从光流计算得出的运动度量来定义“场景中存在移动物体”的可能性,而运动度量标准是根据场景中有移动物体的情况下图像点违反光流的程度得出的,图形分割算法则基于运动度量来分割运动物体。
在过去几年,随着深度学习在计算机视觉领域的广泛应用,目标检测、语义分割等任务都有着较高的精度提升。在视觉SLAM中,借助深度学习方法检测或分割出动态物体,以避免动态物体带来的干扰,该方法被认为是可行的。
DynaSLAM[14]使用了Mask R-CNN语义分割网络以检测并分割场景中的动态特征点,并通过多视图几何方法对没有先验动态标记的物体进行分割,最终结合两者结果,只要在任意一方被检测出来就认为是动态物体。Detect-SLAM[15]为保证算法的实时性,只对关键帧使用SSD网络进行动态物体的检测,通过特征点的传播将其结果传播到普通帧中。Dynamic-SLAM[16]同样使用SSD网络检测动态物体,同时为避免检测结果的缺漏,依据相邻帧速度不变的特性对其进行补偿。DS-SLAM[17]通过使用SegNet分割场景中的动态物体,并使用moving consistency check来确定动态物体的具体运动情况,若发生运动则视作动态物体,若未运动则视为静态物体。
在室内场景中,上述论文均采用了深度学习方法来获取图像中先验的动态物体的位置,对处于该位置中的特征点进行剔除,并使用其他位置的特征点进行位姿估计。从实验结果来看,该策略是十分有效的。但上述论文在针对提升定位精度这一问题时,对于检测的结果仅考虑了“人”这一类别,然而在实际场景中,仍存在着部分潜在动态物体未被检测并作为动态区域进行剔除。基于此,本文提出了SAD-SLAM,在ORB-SLAM3[18]的基础上,使用RGB-D相机作为获取外界信息的传感器,通过语义关联以筛选出场景中所有的动态物体,从而更好地完成动态场景下的定位与建图。本文的主要工作如下:
a)通过GCNv2进行特征提取,以获得分布更为均匀的特征点集合,避免SLAM在剔除掉过多的动态特征点后导致追踪失败的情况,并加快SLAM在特征提取阶段的提取速度。
b)使用YOLOv8-seg语义分割网络对场景中的物体进行检测,并将推理得到的结果通过人工标记划分为两类,即动态物体和潜在动态物体。同时提出一种语义关联方法,通过考虑潜在动态物体与动态物体在三维空间内的位置关系,将潜在动态物体进行2D和深度层面双层过滤,以决定是否将潜在动态物体视作动态物体处理。在进行位姿估计时仅使用静态特征点,以保证SLAM算法在动态场景下的鲁棒性。
c)构建稠密3D点云地图,并通过添加语义信息以满足移动机器人在进行导航、交互和避障等任务时对地图的高级需求,同时避免了动态物体对地图构建的干扰,保证了地图的可用性。
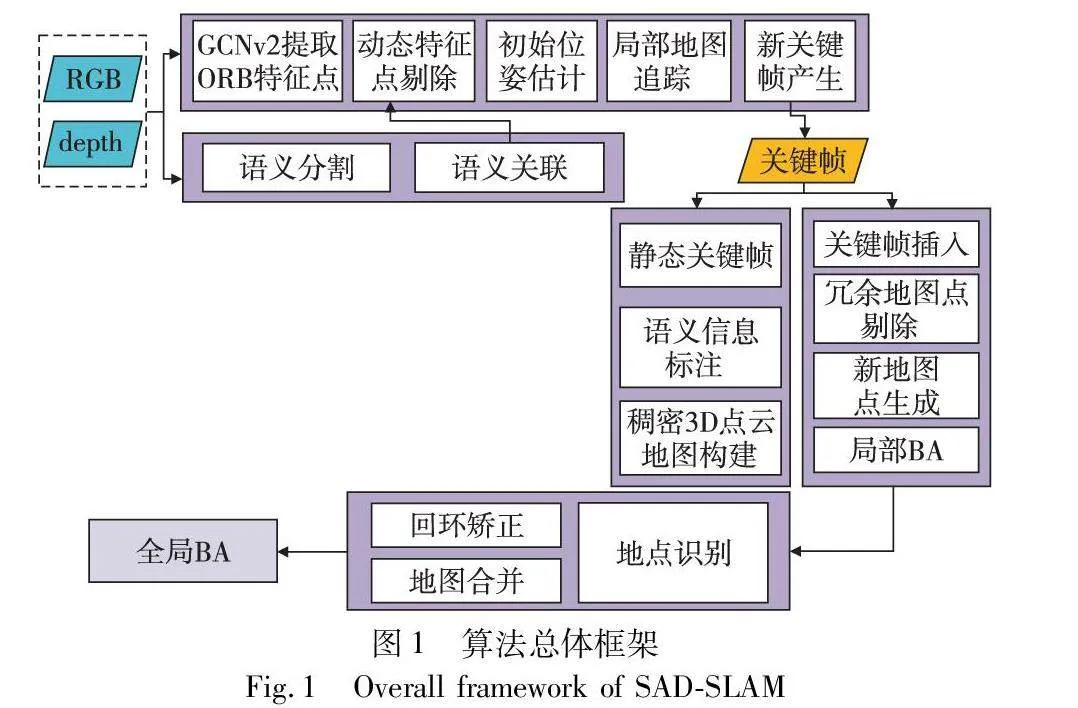
1 算法框架
SAD-SLAM的总体流程如图1所示。在算法开始阶段,对于传入进来的每一组帧,首先使用GCNv2网络提取ORB特征,并使用YOLOv8-Seg完成检测,通过语义关联来最终决定场景中的所有动态物体。在初始位姿估计前,剔除掉所有的动态特征点,仅保留静态特征点参与初始位姿估计。在地图构建过程中,首先对关键帧作进一步筛选,仅使用静态关键帧完成稠密3D点云的地图构建,以避免动态物体带来的干扰。同时,使用不同颜色对地图中的静态物体进行语义标注,从而满足移动机器人对场景中物体的识别。接下来,将对本文所做的改进进行具体介绍。
1.1 GCNv2特征提取
在基于特征点的视觉SLAM算法中,ORB特征点相较于SIFT、SURF特征点有着提取速度较快的优点,非常适用于实时的SLAM。但其存在着分布不够均匀、易聚集的问题。如图2第一列所示,尽管ORB-SLAM3使用了网格划分的方法来保证ORB特征点的均匀分布,但效果仍不够理想。Tang等人[19]使用了一种基于深度学习的方法来提取特征点,该网络首先通过卷积,由原始灰度图获得低像素、多通道的概率图(probability map)和特征图(feature map)。再通过上采样改变概率图的像素大小,并根据变化后的概率图中各点的概率值确定图中的特征点位置。最后以特征点位置为基础,通过特征图中的对应值和一个二值化网络层提取出每个特征点对应的二值化描述子。在接下来的流程中,本文将对动态特征点进行剔除操作,为避免过多的特征点聚集于动态物体上从而导致追踪失败,本文使用了该方法来替换原有的ORB提取方法,通过LibTorch推理库,使用GPU加快特征点的提取速度。效果如图2第二列所示。
1.2 语义分割
Utralytics YOLOv8是一款囊括了目标检测、目标分割、关键点检测等多项任务的神经网络模型。在动态SLAM中往往更关注于场景中动态物体的位置,基于深度学习的目标检测或者语义分割任务均可以应用于其中。然而,由于仅依赖目标检测获得的物体检测框并不能完全拟合物体的边界,存在大量静态区域,所以本文使用了YOLOv8的语义分割模型来检测场景中的物体。在综合考量了YOLOv8-seg不同模型的分割精度和推理速度后,本文使用YOLOv8l-seg来完成场景中物体的识别,其边界框的全类平均正确率(mAP)为52.3%,掩膜的精度为42.6%。
1.3 语义关联
通常情况下,如水杯、椅子、书本等这些潜在的动态物体是否发生运动,取决于与之关联的动态物体。例如,放在桌面上的水杯,只有当人端起它的时候,它才会离开桌面发生运动。为更好地识别出场景中所有的动态物体并留下足够的静态特征点进行追踪,本文提出一种语义关联方法,对于经过推理所获得的所有物体,按照是否具有自主运动能力将物体划分为两类,即具备自主运动能力的物体和不具备自主运动能力的物体。通过考虑两者的关联情况,从而确定不具备自主运动能力的物体是否有发生运动的可能性。在室内场景中,本文以“人”作为动态物体的代表,对于潜在动态物体,经过2D、depth双层过滤,以最终决定是否将该物体视作动态物体。如图3所示,其中第一行和第二行为原始RGB图像和与之对应的深度图像,第三行为语义分割后的结果,第四行为通过语义关联方法后保留下的动态物体。
1)2D过滤 在经过语义分割网络完成对RGB图像的推理后,获取了图像中所有物体的检测框位置和物体的掩膜(mask)。如图4(b)所示,首先将每个潜在动态物体的检测框与人的检测框进行相交判断,从而滤除了图中的红色物体。由于蓝色物体的检测框虽然与人的检测框相交(参见电子版),但可以明显看出两者并不关联。针对该情况,本文对两者的掩膜进行了转换(将掩膜中的前景部分取值为1,背景取值为0),并对相交部分的两个掩膜矩阵执行加法操作,如式(1)所示。同时,为避免在实际情况中相关联的两个物体由于分割边界的问题从而导致计算错误,在执行加法操作前,本文将潜在动态物体的掩膜向与之关联的动态物体的方向移动2个像素距离。
Maskfinal=Maskoc+Maskpc(1)
其中:Maskoc为潜在动态物体相交部分的掩膜矩阵;Maskpc为动态物体相交部分的掩膜矩阵。
对于最终得到的矩阵Maskfinal,若其中存在值为2的元素,则认为两者在2D层面上是相交的。如图4(c)所示,经过2D过滤,从而保留了余下的物体。
2)深度过滤
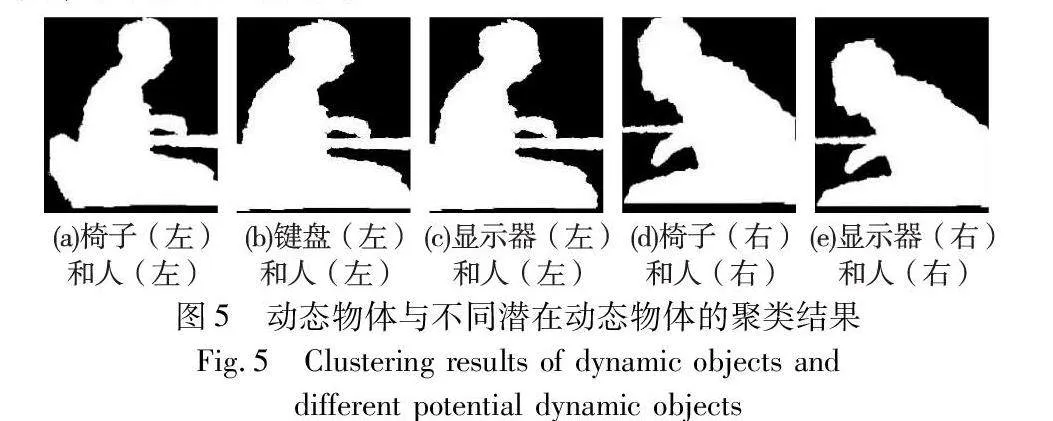
由于视觉误差的作用,仅从2D平面判断两个物体是否关联是不够严谨的。所以,本文对2D平面关联的两个物体进一步进行了深度过滤。深度图不同于RGB图像,它是一维的,而K-means聚类可以很好地利用该特性判断两个在2D平面上关联的物体在深度上是否保持一致。取每一对相交检测框的最大外接矩形,并在深度图的对应位置进行聚类,结果如图5所示。
通过对潜在动态物体经过语义分割获得的掩膜和经过K-means聚类得到的掩膜进行对比,从而决定该潜在物体在深度上是否与动态物体关联。
在此,同样对转换后的两个掩膜矩阵执行加法操作,并计算结果矩阵Maskdepth中元素值为2的元素个数。通过设置合适的阈值υ,若其相似率大于该阈值,则认为两者在深度上是关联的,将该潜在动态物体归入动态物体中。相似率计算公式如式(3)所示。
Maskdepth=Maskk+Masky(2)
其中:Maskk为潜在动态物体通过K-means聚类所得到的掩膜矩阵,Masky为潜在动态物体通过语义分割得到的掩膜矩阵。
ρ=NM(3)
其中:M 为潜在动态物体通过语义分割获得的掩膜矩阵中前景的元素个数;N为Maskdepth 中元素值为2的元素个数;ρ 为相似率。
如图6(b)所示,经过2D、depth双层过滤,最终确定了场景中所有具有运动可能性的物体。在经过GCNv2网络获取的特征点集合中,若特征点位于动态物体上,则认为该点为异常值。在追踪过程中,通过剔除所有的动态特征点,仅使用剩下的静态特征点进行初始位姿估计以保证SLAM的定位精度。
1.4 稠密3D点云地图构建
关键帧作为连续几帧中具有代表性的一帧,一方面降低了相邻关键帧中的信息冗余度,另一方面由于在SLAM中会将普通帧的深度投影到关键帧上,所以关键帧可以看作是普通帧滤波和优化的结果。同时,关键帧作为SLAM中后端优化过程的输入,从一定程度上提高了计算效率。为避免计算资源的浪费,本文使用关键帧来完成稠密3D点云地图构建,如图7所示。
图7(a)是本文为ORB-SLAM3添加的稠密3D点云地图构建模块,可以看出,由于物体的运动导致其构造的地图很难应用于实际需求中。同时,伴随着移动机器人导航、交互等任务对地图的要求越来越高,一般形式的地图已无法满足。为保证移动机器人能够更好地识别地图中的物体,本文对地图中的物体进行了语义标注。通过语义分割及语义关联过程后,区分了场景中的动态物体和静态物体。对于静态物体,对其掩膜使用不同的颜色加以替换,效果如图7(b)所示;在动态场景下,通过对关键帧进一步筛选,仅使用静态关键帧进行地图构建,从而避免动态物体对地图构建的影响,保证了地图的可用性,效果如图7(c)所示。
2 实验验证及分析
本文的定位精度实验使用公开的TUM RGB-D数据集,通过与ORB-SLAM3及其他相关的动态SLAM算法进行对比,以验证SAD-SLAM在动态场景下的可行性和鲁棒性。同时,通过构建真实的动态场景,完成了真实场景下的动态特征点滤除实验。最后,给出了本文改进的各个模块的计算时间。本文实验平台为AMD R5 CPU,NVIDIA RTX 2080 GPU,16 GB内存,操作系统为Ubuntu 20.04。表1给出了算法在进行实验时所设置的一些参数。
2.1 TUM RGB-D数据集
绝对轨迹误差(absolute trajectory error,ATE)为算法估计位姿与真实位姿之间的差值,用于评估整体SLAM算法的性能。相对轨迹误差(relative pose error,RPE)为算法估计位姿与真实位姿之间的差值在经过一段时间后相对上次计算的差值的变化量,用于评估SLAM的漂移误差。本文使用上述两种误差对算法的定位精度进行综合评估[20]。
表2~4中给出了ORB-SLAM3和SAD-SLAM定位误差的具体数值,并使用RMSE、Mean、Median、S.D对ATE和RPE进行衡量。对于每一个序列,均进行了10次实验,并取每项结果的平均值以保证算法的可靠性。同时,提升量的计算公式如式(4)所示。
η=ο-εο×100%(4)
其中:ο 为ORB-SLAM3的定位精度值;ε 为SAD-SLAM的定位精度值;η 为提升量。
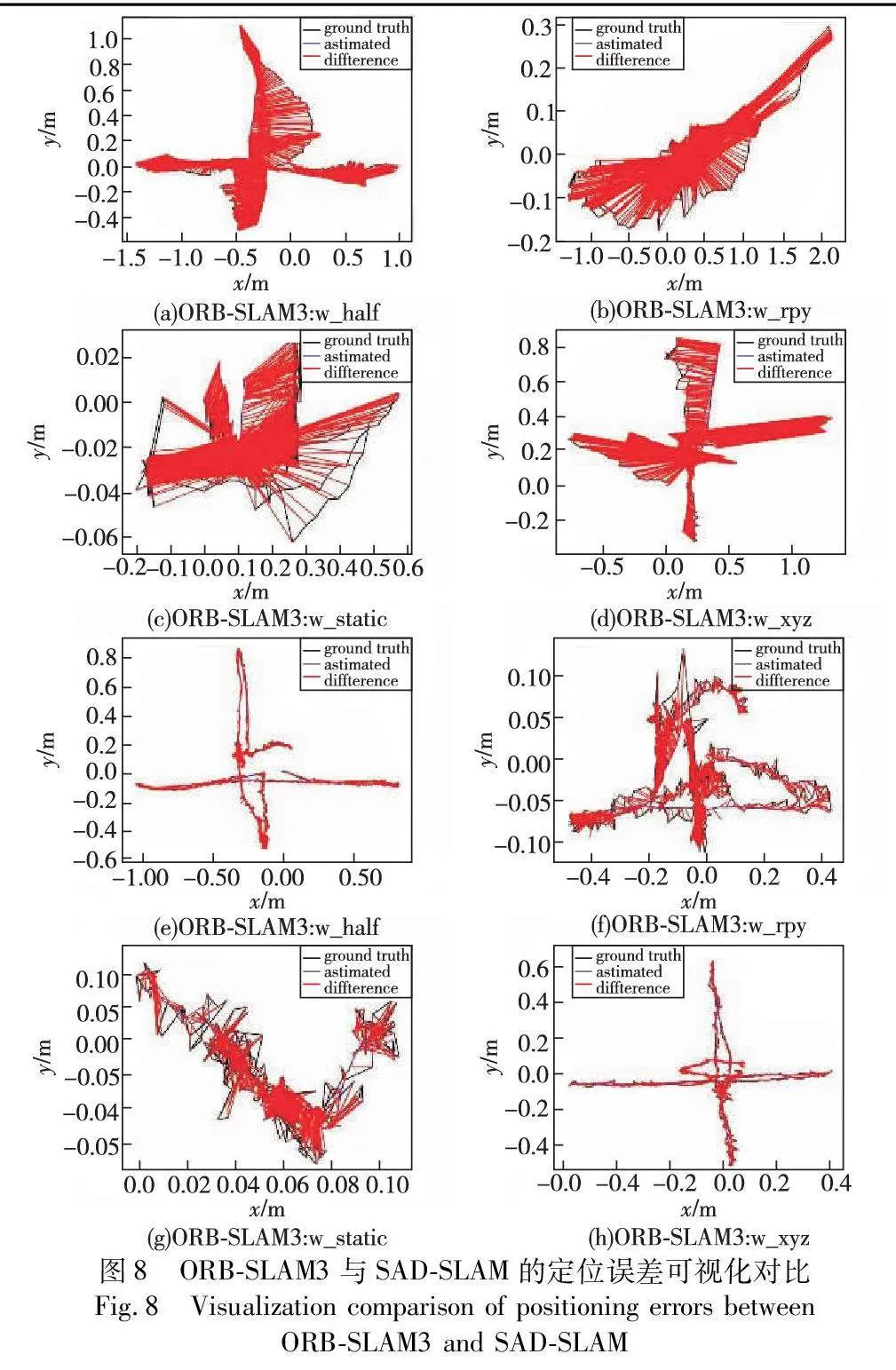
从表2~4中可以看出,在四个高动态序列中,SAD-SLAM相较于ORB-SLAM3有着极大的定位精度提升。在ATE中,RMSE和S.D的平均提升分别为95%、94.75%。同时,本文给出了动态序列下算法对每一帧估计的位姿与实际位姿的可视化对比,如图8所示,红色线条越长(参见电子版),则表示误差越大。由此可以看出,本文通过对ORB-SLAM3算法作出的改进,有效提高了算法在动态场景下的定位精度,提升了算法的鲁棒性。
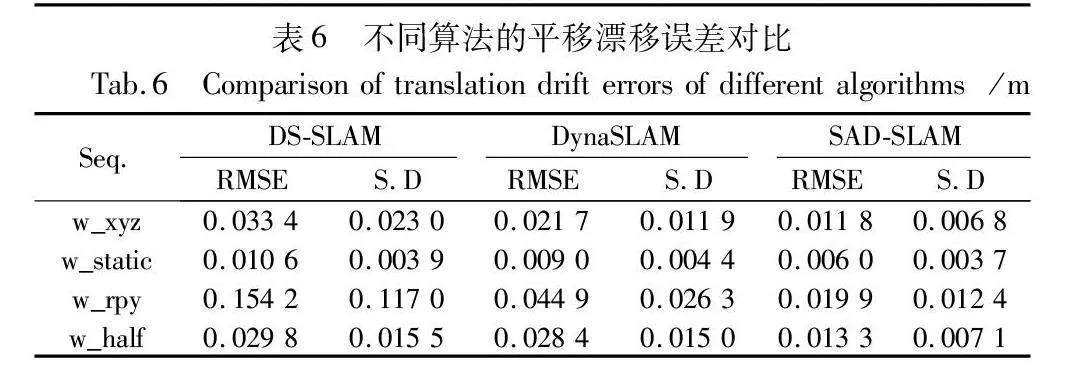
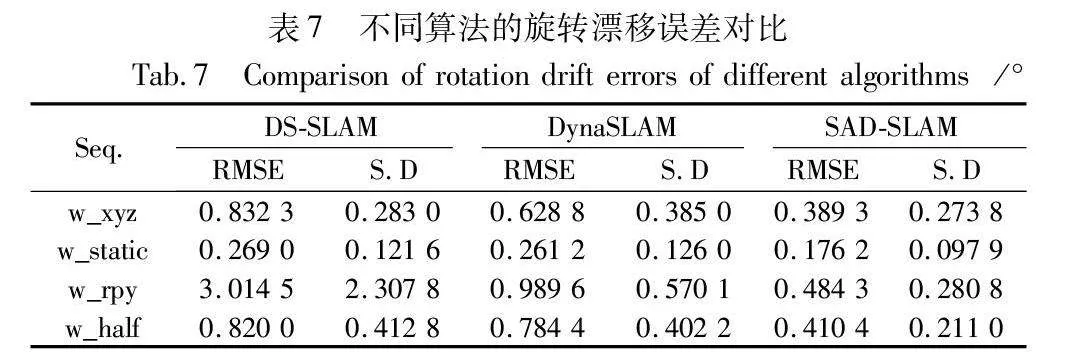
表5~7给出了SAD-SLAM与DS-SLAM和DynaSLAM在高动态序列下的误差对比,并使用RMSE和S.D作为衡量标准。其中DS-SLAM使用SegNet语义分割网络完成场景中动态物体的检测,而DynaSLAM则使用Mask R-CNN。
在ATE的对比中,SAD-SLAM在其中三个序列中取得最优值;在RPE的对比中,SAD-SLAM取得所有序列的最优值。其主要原因在于本文提出的语义关联方法,根据潜在动态物体与动态物体的位置关系判断潜在动态物体是否需要作为动态物体处理,在最大程度上保证了动态区域与静态区域的精细划分。由此可以表明,相较于其他动态SLAM算法,SAD-SLAM在动态场景下的表现要更为优秀。
2.2 真实场景下动态特征点滤除实验
在真实场景中,本文使用了leTMC520 RGB-D相机对SAD-SLAM进行了动态特征点滤除实验。如图9所示,第一列给出了使用GCNv2网络提取ORB特征点集合的分布情况;第二列为语义分割的结果;第三列为经语义关联后保留下来的动态物体;在第四列中,绿色特征点为有效、可用的,而红色特征点则被认为是异常值。可以看出,在经过语义关联后,本文不仅剔除了动态物体(人)上的特征点,同时,与之关联的潜在动态物体(椅子)上的特征点同样被剔除,从而保证了对场景中动态、静态特征点更为精细的划分。
2.3 耗时分析
在该部分,本文使用了高动态序列w_half,共1 021帧图像完成SAD-SLAM的耗时分析。首先对比了ORB-SLAM3中的特征提取时间和使用GCNv2的特征提取时间。然后通过对添加的每个模块进行单独测试,更具体地表现每个模块的耗时情况,结果如表8所示。
3 结束语
通过使用RGB-D相机,在ORB-SLAM3的基础上,本文提出一种适用于动态场景下的视觉SLAM方法——SAD-SLAM。首先使用GCNv2网络提取特征点,以获取分布均匀的特征点集合并加快提取速度。然后通过YOLOv8-seg语义分割网络完成对场景中物体的识别,并根据语义关联结果以确定场景中所有的动态物体,仅保留静态特征点参与位姿估计以提高定位精度。同时,本文构建了动态场景下含有语义信息的稠密3D点云地图,以满足移动机器人对地图的高级需求。最后,通过使用TUM RGB-D数据集和真实环境对本文算法进行实验,结果表明本文算法在动态场景下的定位精度要优于ORB-SLAM3和其他相关的动态SLAM。
本文使用了深度学习方法对ORB-SLAM3中的部分模块进行改进,以提升算法在动态场景下的鲁棒性,然而基本的位姿估计仍依靠明确的数学模型,未来考虑使用神经网络构造端到端的动态SLAM算法。
参考文献:
[1]陈卫东,张飞. 移动机器人的同步自定位与地图创建研究发展 [J]. 控制理论与应用,2005,22(3): 455-460. (Chen Weidong,Zhang Fei. Research and development of simultaneous localization and mapping for mobile robots [J]. Control Theory and Applications,2005,22(3): 455-460.)
[2]权美香,朴松昊,李国. 视觉SLAM综述 [J]. 智能系统学报,2016,11(6): 768-776. (Quan Meixiang,Piao Songhao,Li Guo. An overview of visual SLAM [J]. CAAI Trans on Intelligent Systems,2016,11(6): 768-776.)
[3]Cadena C,Carlone L,Carrillo H,et al. Past,present,and future of simultaneous localization and mapping: toward the robust-perception age [J]. IEEE Trans on Robotics,2016,32(6):1309-1322.
[4]Pacheco J F,Ascencio J R,Mancha J M R,et al. Visual simultaneous localization and mapping: a survey [J]. Artificial Intelligence Review: An International Science and Engineering Journal,2015,43(1): 55-81.
[5]Takafumi T,Hideaki U,Sei I. Visual SLAM algorithms: a survey from 2010 to 2016 [J]. IPSJ Trans on Computer Vision and Applications,2017,9: 1-11.
[6]Artal R M,Tardos J D. ORB-SLAM2: an open-source SLAM system for monocular,stereo and RGB-D cameras [J]. IEEE Trans on Robotics,2017,33(5): 1255-1265.
[7]Lowe D G. Distinctive image feature from scale-invariant keypoints [J]. International Journal of Computer Vision,2017,60(2): 91-110.
[8]Bay H,Ess A,Tuytelaars T,et al. SURF: speeded up robust features [C]// Proc of European Conference Computer Vision. Berlin: Springer,2006: 404-417.
[9]Pumarola A,Vakhitov A,Agudo A,et al. PL-SLAM: real-time monocular visual SLAM with points and lines [C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway,NJ:IEEE Press,2017: 4503-4508.
[10]Engel J,Koltun V,Cremers D. Direct sparse odometry [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2017: 611-625.
[11]Zou Danping,Tan Ping. CoSLAM: collaborative visual SLAM in dynamic environments [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2013,35(2): 354-366.
[12]Sun Yuxiang,Liu Ming,Meng Max Q-H. Improving RGB-D SLAM in dynamic environments: a motion removal approach [J]. Robotics and Autonomous Systems,2017,89: 110-122.
[13]Klappstein J,Vaudrey T,Rabe C,et al. Moving object segmentation using optical flow and depth information [C]// Advances in Image and Vicko Technology: the 3rd Pacific Rim Sympoisum.
Berlin: Springer,2009: 611-623.
[14]Bescos B,Facil J M,Civera J,et al. DynaSLAM: tracking,mapping,and inpainting in dynamic scenes [J]. IEEE Robotics and Automation Letters,2018,3(4): 4076-4083.
[15]Zhong Fangwei,Wang Sheng,Zhang Ziqi,et al. Detect-SLAM: ma-king object detection and SLAM mutually beneficial [C]//Proc of IEEE Winter Conference on Applications of Computer Vision. Pisca-taway,NJ:IEEE Press,2018: 1001-1010.
[16]Xiao Linhui,Wang Jinge,Qiu Xiaosong,et al. Dynamic-SLAM: semantic monocular visual localization and mapping based on deep learning in dynamic environment [J]. Robotics and Autonomous Systems,2019,117: 1-16.
[17]Yu Chao,Liu Zuxin,Liu Xinjun,et al. DS-SLAM: a semantic visual SLAM towards dynamic environments[C]//Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway,NJ:IEEE Press,2018: 1168-1174.
[18]Campos C,Elvira R,Rodriguez J G,et al. ORB-SLAM3: an accurate open-source library for visual,visual-inertial,and multi-map SLAM [J]. IEEE Trans on Robotics,2021,37(6): 1873-1890.
[19]Tang Jiexiong,Ericson L,Folkesson J,et al. GCNv2: efficient correspondence prediction for real-time SLAM [J]. IEEE Robotics and Automation Letters,2019,4(4): 3505-3512.
[20]Sturm J,Engelhard N,Endres F,et al. A bench-mark for the evaluation of RGB-D SLAM systems [C]//Proc of IEEE/RSJ International Conference on Intelligent Robotics and Systems. Piscataway,NJ:IEEE Press,2012: 573-580.
