融合多情感的语音驱动虚拟说话人生成方法
2024-08-15李帅帅何向真张跃洲王嘉欣











摘 要:虚拟说话人生成是人工智能领域的一个重要研究方向,旨在通过计算机生成具有逼真语音的虚拟说话人。然而,现有方法往往忽视情绪表达、生成的人脸图像面部细节缺乏真实感,限制了虚拟说话人的表现能力和交互性。为解决这一问题,提出一种基于Transformer的生成对抗网络(generative adversarial network,GAN)方法,用于生成具有不同情绪的虚拟说话人(GANLTB)。该方法基于GAN架构,生成器采用Transformer模型处理语音和图像特征,结合情绪条件信息和潜在空间向量,生成带有指定情绪的语音和图像。判别器用于评估生成结果的真实性,并提供梯度信号指导生成器训练。通过引入双三次插值法,进一步提升了虚拟说话人生成的图像质量,使得虚拟说话人的面部细节更加清晰可见,表情更加自然和生动。使用情感多样性数据集(CREMA-D)验证了该方法,通过主观评估和客观指标,评估了生成的语音和图像的情绪表达能力和质量。实验结果表明,该方法能够生成具有多样化和逼真情绪表达的虚拟说话人。相比目前其他先进方法,所提方法在流畅度和逼真度等细节上都更加清晰,带来了更好的真实感。
关键词:虚拟说话人;生成对抗网络;Transformer;多情感表达;语音驱动
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)08-043-2546-08
doi: 10.19734/j.issn.1001-3695.2023.10.0559
Multi-emotion driven virtual speaker generation method integrating multiple emotions
Li Shuaishuaia,b, He Xiangzhena,b, Zhang Yuezhoua,b, Wang Jiaxina,b
(a.Key Laboratory of Linguistic & Cultural Computing Ministry of Education, b.Key Laboratory of Ethnic Language & Cultural Intelligent Information Processing, Northwest Minzu University, Lanzhou 730030, China)
Abstract:
Virtual speaker generation is an important research direction in the field of artificial intelligence, aiming to gene-rate virtual speakers with realistic voices through computers. However, existing methods often neglect emotional expression and the facial details of the generated face images lack realism, which limit the performance and interactivity of the virtual spea-kers. To address this issue, this paper proposed a Transformer-based generative adversarial network (GAN) method for generating virtual speakers with different emotions(GANLTB). This method was based on the GAN network architecture, where the generator used a Transformer model to process speech and image features, combined with emotional condition information and latent space vectors, generating voice and images with specified emotions. It used the discriminator to assess the authenticity of the generated results and provide gradient signals to guide the training of the generator. By introducing BiCubic interpolation, it further enhanced the image quality of the virtual speaker generation, making the facial details of the virtual speaker clearer and the expressions more natural and vivid. The method was validated using a diverse emotional dataset CREMA-D, through subjective evaluation and objective indicators to assess the emotional expression ability and quality of the generated speech and images. Experimental results show that the method can generate virtual speakers with diverse and realistic emotional expressions. Compared to other currently advanced methods, the proposed method is clearer in details such as fluency and realism, bringing a better sense of reality.
Key words:virtual speaker; GAN; Transformer; multi-emotion expression; voice-driven
0 引言
虚拟说话人生成技术是人工智能领域中备受关注的研究方向之一,其旨在通过深度学习模型生成具有逼真语音的虚拟角色,从而提升用户交互体验的真实感和自然度。然而,目前的虚拟说话人生成方法常常忽略情感的表达,这一点对于提高虚拟说话人的逼真度和交互性至关重要。情感表达的缺乏限制了虚拟说话人与用户之间的情感沟通,这在一定程度上阻碍了用户体验的提升。特别是在教育、心理健康支持、客户服务和人机交互等领域,情感表达的重要性不言而喻。
因此,研究如何生成融合多情感表达的虚拟说话人不仅是技术挑战,也是提升虚拟说话人应用效果的关键。在未来的研究和应用中,通过深度学习和人工智能技术,使虚拟说话人能够更准确和自然地表达各种情绪,将极大地提升其在各个应用领域的实用性和交互性。
情绪是人类交流和表达的重要组成部分,它能够赋予语言以情感色彩,使交流更加丰富和有意义。在虚拟说话人生成中引入情绪表达的能力将极大地提升其逼真度和交互体验,使虚拟说话人更接近于真实的人类语音。因此,为了充分发挥虚拟说话人的潜力并提高其实用性,需要探索如何在生成过程中准确、自然地表达不同情绪。人的六种不同情绪如图1所示。
近些年,随着各种深度学习模型层出不穷,GAN的各种变体在图像生成领域展现出强大的生成能力。DCGAN(deep convolutional GAN)[1]是GAN的一个重要变体,它使用深度卷积神经网络作为生成器和判别器,使得图像生成更加稳定和逼真。StyleGAN[2]通过引入潜在空间的样式变化来控制图像的生成风格。它在图像生成方面取得了显著的进展,并被广泛用于生成艺术和逼真的人脸图像。Transformer最初是为了解决自然语言处理任务而设计的,并在该领域取得了巨大成功。近年来,研究人员开始将Transformer应用于图像生成领域,Image Transformer[3]将Transformer应用于图像生成并取得了良好效果。DINet[4]通过对嘴部动作进行编码特征映射,实现了高分辨率人脸视频配音。MCNet[5]设计了一个身份表征网络,生成的人脸说话视频具有逼真的动态姿态和表情。
本文提出将GAN和Transformer模型进行结合来生成具有不同情绪的虚拟说话人。通过让生成器网络和判别器网络相互竞争和协作来生成逼真的样本。Transformer作为生成器的一部分,利用其强大的序列建模能力,通过自注意力机制来捕获语音和图像中的全局和局部特征,同时利用GAN的判别器提供梯度信号指导生成器的训练。为了解决图像分辨率的问题,研究中采用了双三次插值(BiCubic)[6]方法,有效地提高了生成图像的清晰度和真实性。通过将BiCubic插值方法与GAN相结合,改进了虚拟说话人图像的质量,使其形象更加逼真。
1 相关工作
虚拟说话人生成是一个多学科交叉的研究领域,涉及到语音处理、图像生成、情感识别等多个方面。宋一飞等人[7]针对当前虚拟说话人研究中的热点问题,从数据集、关键技术、评估策略三个方面,对虚拟说话人视频生成技术及研究现状做一个较系统的梳理与总结。本章将介绍与本研究相关的一些工作,并加入提高图像分辨率的相关内容。
a)虚拟说话人生成方法:传统的虚拟说话人生成方法主要基于统计模型和规则系统。其中,基于隐马尔可夫模型(hidden Markov model, HMM)[8]的方法被广泛应用于语音合成领域,通过建模声学和语言特征来生成语音。在图像生成方面,一些方法使用基于规则的系统来生成具有特定情绪的图像。然而,这些方法在情绪表达和图像质量方面存在一定的限制。
b)生成对抗网络(GAN):GAN是一种强大的生成模型,通过让生成器网络和判别器网络相互竞争和协作来生成逼真的样本。Eskimez等人[9]提出了一种新的方法来渲染语音驱动的说话人脸生成中的视觉情感表达,设计了一个端到端的说话人脸生成系统。该系统以语音、单个面部图像和分类情感标签为输入,生成与语音同步并表达条件情感的说话人脸视频。年福东等人[10]提出基于关键点表示的语音驱动说话人脸视频生成方法,通过连续的唇部关键点和头部关键点序列及模板图像最终生成面部人脸视频。Christos等人[11]2022年提出Free-HeadGAN,实现一个标准的3D关键点估计器,它可以回归3D姿势和表情相关的变形,一个凝视估计网络和一个建立在HeadGAN架构上的生成器,实现了更高的照片真实感。在虚拟说话人脸生成领域,GAN被应用于生成语音和图像。通过训练生成器网络来生成逼真的语音和图像样本,并通过判别器网络对其进行评估和反馈,GAN方法在虚拟说话人脸生成方面取得了显著的进展。
c)Transformer模型:Transformer[12]是一种基于注意力机制的神经网络模型,最初被应用于自然语言处理领域,如机器翻译和文本生成。Lee等人[13]提出将视觉Transformer(vision Transformers,ViT)架构集成到生成对抗网络中(ViTGAN),显著提升了图像和视频生成的效果。在虚拟说话人脸生成中,Transformer模型可以用于处理语音和图像特征,提高生成的语音和图像的质量和准确性。此外,Transformer模型还被应用于图像超分辨率重建任务,通过学习低分辨率到高分辨率的映射关系,提高生成图像的细节和分辨率。陈凯等人[14]提出的MCTN利用Transformer与CNN多分支并联结构和Deformer结构,在人脸关键点检测方面性能大幅超越基于卷积网络的关键点检测算法。
d)情感识别和情感合成:情感识别和情感合成是虚拟说话人生成中的重要任务。情感识别旨在从语音和图像中准确识别出表达的情感。一些研究利用深度学习方法构建情感分类器,以识别和分析情感。Aggarwal等人[15]探索了不同的特征提取方法,以有效解决语音情感识别问题。
e)图像分辨率提高方法:图像的分辨率是虚拟说话人脸生成中一个重要的考虑因素。为了提高生成图像的质量和细节保持能力,研究者提出了多种方法来提高图像分辨率。Wang等人[16]提出了GFP-GAN,它利用了封装在预训练人脸GAN中丰富多样的先验,通过空间特征变换层,将生成式面部先验(GFP)融合到人脸恢复过程中,此方法能够很好地平衡真实感和保真度。陈贵强等人[17]提出一种半监督算法Cycle-SRNet,通过重建模型恢复出具有真实效果的高分辨率人脸图像,引入感知损失函数保持人脸结构相似性,以更好地恢复面部特征。
本文在图像生成领域结合Transformer-GAN方法和Bi-Cubic技术,克服传统方法中对图像特征提取的局限性,获得更加清晰和逼真的高分辨率图像,从而提高虚拟说话人脸生成的质量和表现能力。
2 研究方法
2.1 数据预处理
利用Dlib库对视频进行处理,提取了每帧中人脸的68个关键点坐标。通过逐帧的面部检测和关键点预测,将视频中的人脸关键点信息提取出来,为后续的人脸分析和应用提供了基础数据。这个过程可以用于人脸识别、表情识别等任务,为对视频中的人脸进行深入分析和理解提供了重要支持。对视频每隔四帧截取一帧。人脸68个关键点提取结果如图2所示。
在这项研究中,使用情绪作为输入条件。其目的是使语言和情绪条件脱钩。这使本文能够在人脸视频的生成过程中生成特定情绪。图2显示了该系统的概述,其采用了GAN框架,本文的生成器网络架构使用情绪条件输入。此研究使用两个鉴别器网络,其中一个区分视频中表达的情绪,另一个区分真实视频帧和生成的视频帧。基本框架如图3所示。
根据GAN的组成结构可以知道,GAN的整个过程为:G产生一个自创的假数据和真数据放在一起让D来区分,在这种不停的较量中,G就生成出接近真实的数据。所以GAN主要的应用场景就是能够学习出这样模拟分布的数据,并且可以用模拟分布代替原始数据。在GAN中,定义值V来衡量真实样本和生成样本之间的差异,如式(1)所示。
V(D,G)=Ex-Pdata(x)[log D(x)]+
Ex-Pz(z)[log(1-D(G(z))]](1)
其中:x为真实样本;z为生成样本;Pdata为真实样本分布;Pz为生成样本分布。判别器D要求该值尽可能大,而生成器G希望该值尽可能小。判别器D的目标是使得x与z非常容易区分,即D(X)趋近于1而D(G(z))趋近于0;生成器G的目标是使生成样本尽可能像真实样本,即D(G(z))趋近于1。因此GAN的目标便是:
minGmaxD V(D,G)(2)
判别器的输出值尽可能大,生成器的输出值尽可能小。判别器和生成器之间相互博弈,使得生成器的生成效果更好。
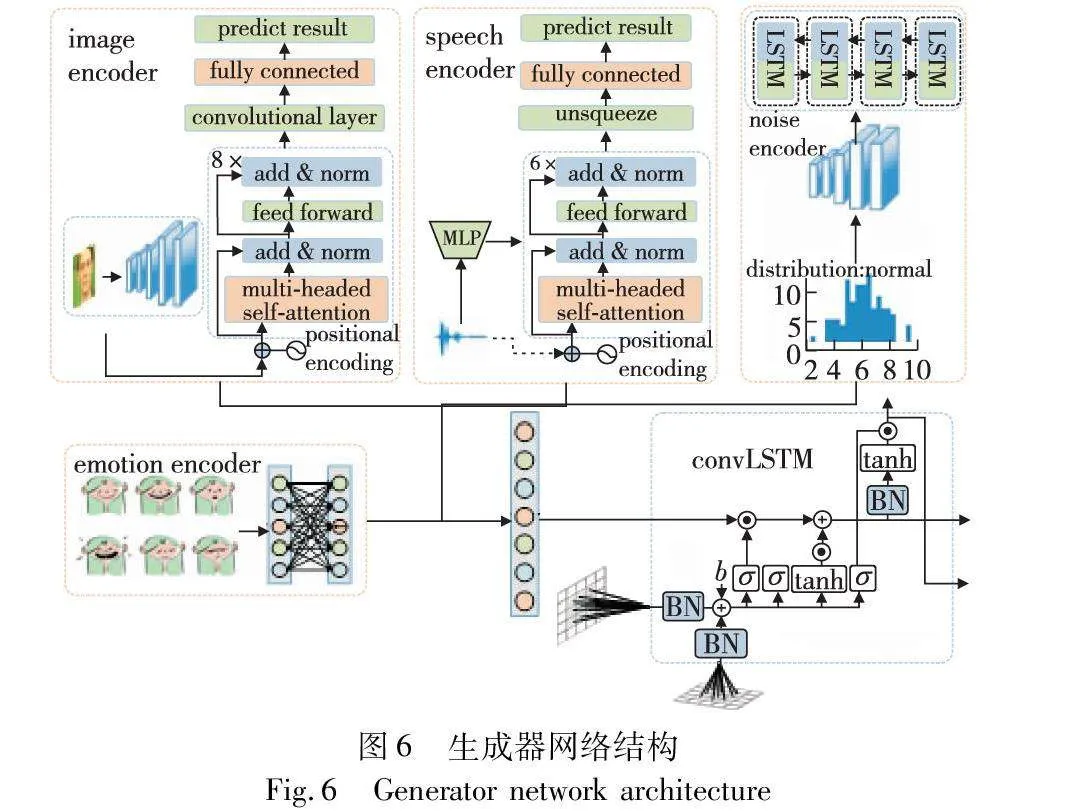
2.2 生成器模块
生成器模块包含以下子网络:语音编码器、图像编码器、噪声编码器和情绪编码器以及视频解码器。生成器模块的整体组成部分如式(3)所示。
Gall=(Eaudio+Eimage+Enoise+Eemotion+Evideo)(3)
a)语音编码器:此模块实现基于Transformer模型的编码。输入的语音特征向量经过一定维度映射后输入到多个编码层中进行特征抽取和表示学习,编码器中使用了多头自注意力机制和前馈神经网络隐藏层来提取语音特征的高级表示。堆叠多个编码层,可以更加抽象地表示语音特征。头数可控制特征表达的复杂度,编码层数可控制模型深度和记忆能力。添加一个前馈神经网络隐藏层,最后通过残差连接和层归一化的方式输出编码层的结果。整个模型中使用了归一化和dropout技术用于训练时的模型加速和泛化性能提升。
b)图像编码器:用于对图像进行特征提取。该模块由一个序列化的卷积层和多个编码器层组成,编码器层由多头自注意力、多头交叉注意力和前馈神经网络隐藏层组成,用于逐渐抽象提取图像特征。在前向传播过程中,该模型首先将输入的图像通过卷积层得到特征图,然后依次送入多个编码器层进行特征提取,并记录每个编码器层的输出,最后将该模型的输出特征图和记录的编码器层输出的特征图进行拼接,并通过一层卷积输出该模型的最终特征表示。其中,在编码器层中使用的多头自注意力、多头交叉注意力和前馈神经网络隐藏层均为高性能的深度学习技术,能够有效地提高模型对图像特征的提取能力和表达能力。
c)噪声编码器:用于生成噪声张量。该模块中使用一个LSTM模块用于对生成的噪声张量进行处理。在前向传播过程中,输入的是语音段的噪声向量,通过normal分布将该向量中的每个元素随机采样出一个噪声张量,使用LSTM层对生成的噪声张量进行处理,并输出经过处理后的噪声张量作为本模块的最终输出。整个过程中,该模型主要利用随机采样和LSTM技术来生成一定长度的噪声序列,用于模拟真实语音中的噪声成分,进而提高模型的抗干扰能力。
d)情绪编码器:此模块用于对情感条件进行处理。该模块中主要有一个包含2个线性层和2个LeakyReLU激活函数的全连接神经网络。在前向传播中,输入的是一个6维的情感向量,经过定义的全连接神经网络,首先对这个情感向量进行线性变换,然后再经过LeakyReLU非线性激活函数的处理,最后输出的是一个512维的特征向量,作为本模块的最终输出,用作语音合成模型的情绪条件输入。整个过程中,该模型主要利用全连接神经网络及激活函数来对情感向量进行特征提取和处理,将其转换为一个描述情感的特征向量,进而实现语音合成的情感控制功能。情绪编码器的组成部分包括六种情绪分类,其组成如式(4)所示。
E=(Eanger+Edisgust+Efear+Ehappiness+Eneutrality+Esadness)(4)
e)视频解码器:该解码器模块主要用于将给定的图像、语音、噪声、情感条件等信息解码为一个连续的视频序列。此模块设定了一些参数,包括卷积神经网络的过滤器个数、卷积层的数量及大小、一个全连接层。将输入的图像、语音、噪声、情感条件通过该全连接层进行特征提取和处理,得到一个特征向量作为全网络的输入,并定义了一些卷积层、反卷积层、dropout层等操作,对输入数据进行处理和特征提取。在正向传播中,输入的是图像条件、噪声、情感向量等信息,通过流程中的特征提取、dropout和上采样方式,将输入数据转换为一个视频序列,最后用tanh进行输出,生成一段具有情感的、连续的视频。其中的卷积操作采用了反卷积、LSTM等方法,能有效处理如时间序列数据等类型的信息,实现了该模型对输入信息的有效解码,同时通过dropout进行随机化,降低过拟合问题的出现。
通过融合图像条件、语音特征、噪声特征和情感特征,建立一个解码器模型,从而能够生成高分辨率的合成图像。模型的核心是多层卷积网络,其中包含特殊的conv2DLSTM层用于更好地处理特征图。模型的训练过程中使用dropout层以减少过拟合。最后,输出层将特征图合并为一个高分辨率图像输出。
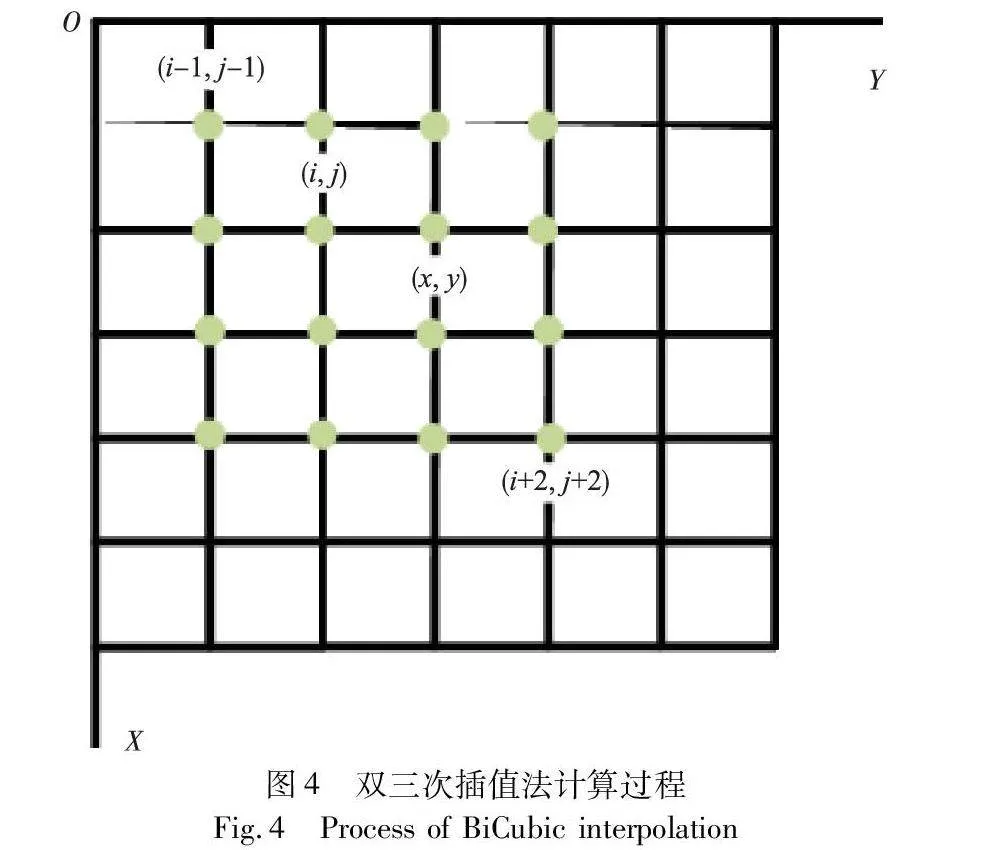
在图像生成过程中,解码器合成高分辨率图像时采用双三次插值法,双三次插值法采用样条函数进行插值计算,这种函数具有光滑且连续的特性,因此能够更好地保留图像的细节信息,减少失真和模糊现象,进而提升图像分辨率。同时,它利用了更多的像素点进行插值计算,相比双线性插值法,提供了更高的插值精度。双三次插值法计算方法如图4所示。
假设要对原图像进行放大,放大倍数为s倍,需要生成一个新的图像。对于新图像中的每个像素点(i, j),需要找到其在原图像中的对应位置(i, j),然后利用周围的像素点进行插值计算。假设原图像的尺寸为W×H,放大后的图像尺寸为(Wk×Hk)。对于新图像中的像素点(x, y),其在原图像中的对应位置为(i, j),计算公式如下:
i=xk(5)
j=yk(6)
然后以(i, j)为中心,取周围的16个像素点,构成4×4的像素块。在x轴方向进行三次样条插值:首先对像素块的每一列进行三次样条插值,得到中间结果(i, j),其中插值大小为0到1之间的小数。然后在y轴方向进行三次样条插值:对中间结果(i, j)在y轴方向进行三次样条插值,得到最终的插值结果(x, y)。插值公式如下:
S(x)=1-2|x|2+|x|3 0≤|x|<1
4-8|x|+5|x|2-|x|31≤|x|<2
0|x|≥2 (7)
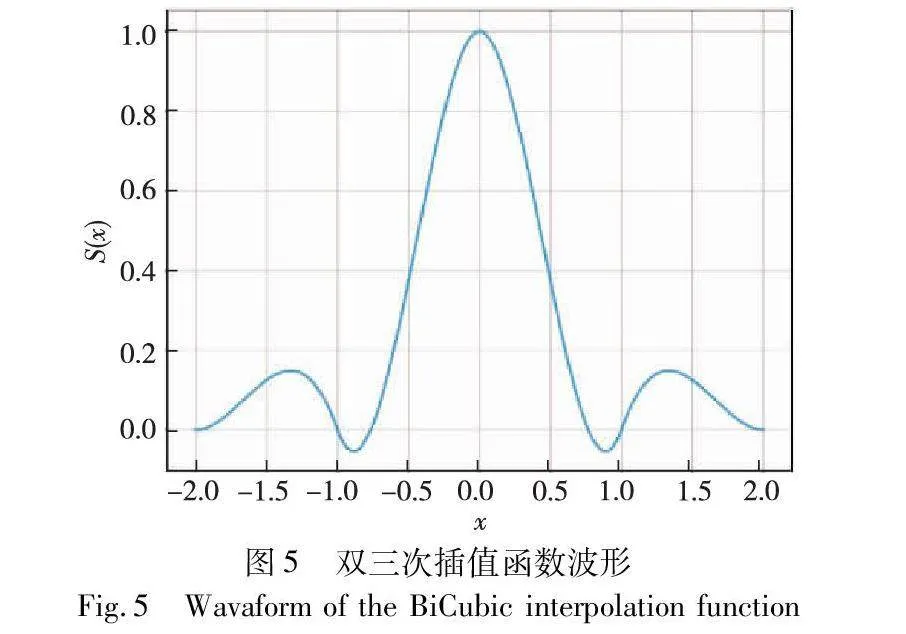
求出BiCubic函数中的参数x,从而获得上面所说的16个像素所对应的权重S(x)。该函数的波形如图5所示。
对于插值的像素点(x,y),选择附近的4×4个点进行加权求和。按如下公式进行计算:
f(x,y)=∑3i=0∑3j=0f(xi,yj)S(x-xi)S(y-yj)(8)
其中:(x,y)表示插值的像素点;(xi,yj)表示现有采样位置;f(xi,yj)表示现有位置的像素值;S表示像素点到附近点的距离。
最终,生成器的整体网络结构如图6所示。
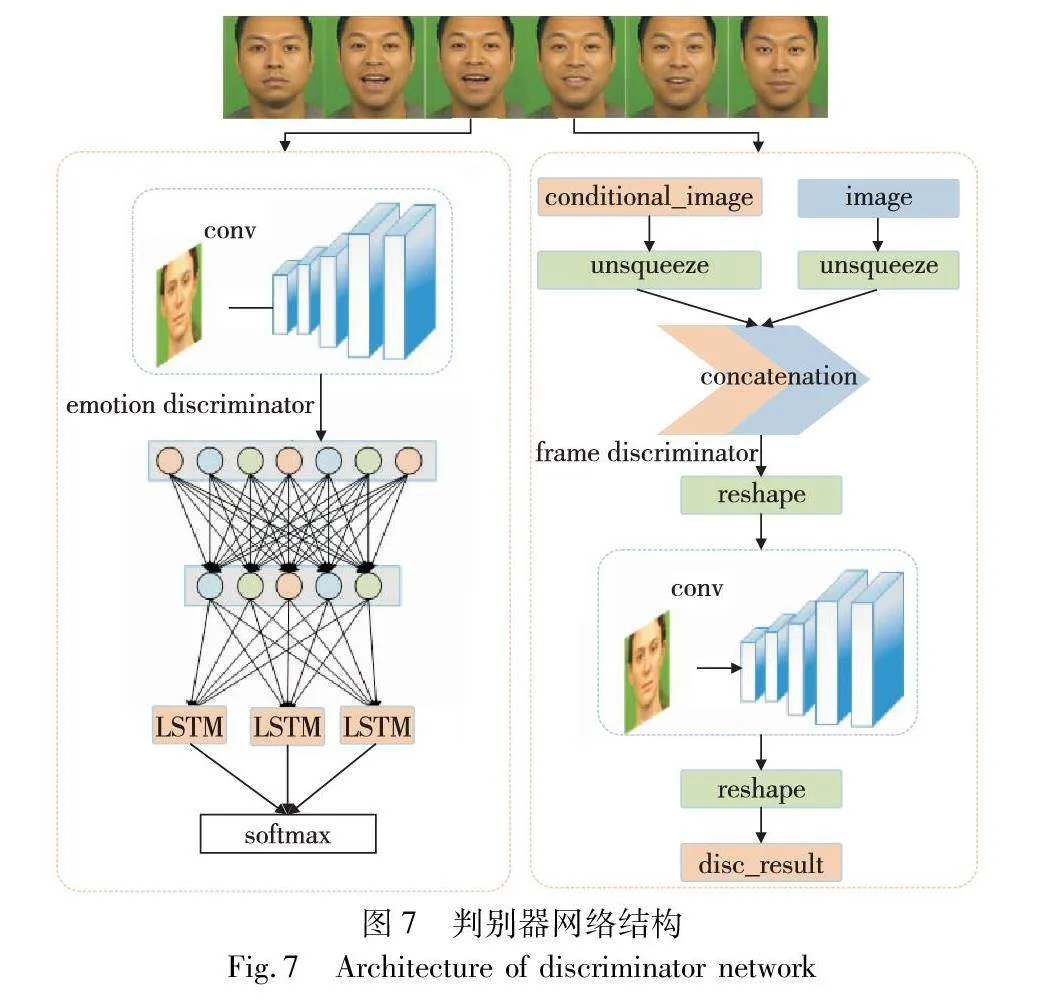
2.3 判别器模块
判别器模块包含视频帧判别器和情绪判别器两个部分。
a)视频帧判别器:此模块用于实现卷积神经网络的前向传播和计算梯度惩罚。整个网络由多个连续的卷积层组成,每个卷积层进一步提取特征信息,输出层由线性和激活函数组成。优化器在初始化方法中被设置为Adam,也可以使用RMSprop进行优化,调度器用于定期更新学习率。前向传播方法接受输入并提取特征,特征向量最终通过输出层进行分类。梯度惩罚方法通过随机插值和反向传播来实现,以计算梯度惩罚的平均值和梯度惩罚平均值的算术平方。
b)情绪判别器:该模型用于图像分类任务,这个模型由多个前馈神经层、一个全连接层和一个循环神经层组成。使用给定的滤波器大小和卷积核大小定义了对输入图像进行卷积运算的5层卷积神经层。在模型的前向传递过程中,模型会首先进行卷积运算来提取图像的特征。随后,这些特征通过全连接层进行降维以提高模型的计算效率,并输入到长短时记忆(LSTM)层中,从而获取一个整体上对输入序列的理解。最后通过全连接层,基于输入序列的最后一个时间步骤的隐藏状态,完成分类任务,生成一个输出向量。
此外,该神经网络还提供了一个用于计算梯度惩罚的函数。该函数可以用于在训练卷积神经网络过程中,以一种有效的方式改善网络输出的性能表现。通过计算交错真实和生成数据的插值点,并将其传递到神经网络中,该函数能够对模型梯度的大小进行惩罚,从而加强了模型对输入数据的鲁棒性。判别器模块网络结构如图7所示。
2.4 目标函数
在原始GAN中,生成器和判别器通过对抗学习进行训练,其中生成器的目标是使得生成样本的判别器输出尽量接近真实样本的判别器输出,试图生成逼真的样本来欺骗判别器,而判别器则通过输出区分真实样本和生成样本。然而,传统GAN的训练过程可能出现模型崩溃(mode collapse)和不稳定等问题。Wasserstein GAN (WGAN)的提出者Arjovsky等人[18]把Wasserstein 距离作为衡量生成样本与真实样本之间差异的指标,这使得训练过程更加稳定。WGAN-GP[19]则进一步改进了WGAN,引入了梯度惩罚机制来解决WGAN中的权重裁剪问题。GAN-GP的主要思想是通过判别器输出与生成样本之间的插值点计算梯度,并强制使这些梯度的范数接近于1,来对判别器进行惩罚。这个梯度惩罚项是添加到判别器的损失函数中,以促使判别器学习更稳定的梯度。GAN-GP的梯度惩罚计算方法如式(9)所示。
L=E-Pp[D()]-Ex-Pr[D(x)]+
λE-P[(‖D()‖k-1)2](9)
其中:E~P对随机插值点进行期望操作;ΔD()是判别器在随机插值点的梯度;是样本video和生成video的随机插值。
除此以外还有其他多个目标函数:用于改善口腔音频同步的MRM损失、用于改善图像质量的感知损失、用于图像质量的帧GAN损失和用于情绪表达的情绪GAN损失。
a)口腔区域掩码(MRM)损失[20]:MRM损失是口腔区域周围生成的视频和地面实况视频之间的加权L1重建损失。它使用以口腔坐标的平均位置为中心的2D高斯作为权重。MRM的直觉是手动将网络的注意力驱动到口腔区域,以提高口腔音频同步。
LMRM1=Lmasked1+Lmasked1+αJFD(10)
其中:LMRM1表示有噪声语音的掩码重建损失;JFD表示鉴别器的成本;α表示权重。
b)感知损失:使用预先训练的VGG-19网络[21],并从生成的视频和地面实况视频中计算以下层的中间特征:4、9、18、27和36。通过将生成视频和真实视频的尺寸进行调整,将其展平为二维张量。然后,通过VGG-19模型获取生成视频和真实视频在预定义层级的特征表示。注意,为了避免梯度传播到VGG-19模型,对真实视频的特征表示断开了梯度计算。随后,对于每个特征层,计算生成视频特征表示与真实视频特征表示之间的均方误差,以提高图像质量。
Lperceptual2=1CjHjWj‖φj(y)-φj()‖22(11)
其中: j表示网络的第j层;CjHjWj第j层的特征图的大小。最后,将所有特征层的均方误差相加,得到最终的感知损失。感知损失的目的是衡量生成视频和真实视频在特征层级上的差异,以便促使生成视频更接近真实视频的特征表示。
总的来说,均方误差(MSE)损失用于计算生成视频和真实视频在预定义特征层级上的特征表示之间的差异,从而衡量生成视频的感知质量。
c)帧判别器损失:为了进一步提高图像质量,特别是清晰度,本文使用了由帧判别器计算的帧GAN损失。帧判别器损失的计算过程中先将生成视频序列和真实视频序列调整为相同的尺寸,以确保它们具有相同的维度;然后把对应位置的元素进行绝对值差运算,得到每个像素位置上的绝对值误差;最后对所有像素位置上的绝对值误差求平均,得到帧判别器损失。之所以使用平均绝对误差损失,是因为它对异常敏感,当生成的输出与真实数据之间存在较大的偏差时,平均绝对误差损失更能体现出这种差异,促使生成器更好地逼近真实数据分布。本文使用Wasserstein GAN进行更稳定的训练,而不是普通的GAN损失。
JFD=Ex-PR[fw(x)]-Ex-Pr[fw(x)](12)
其中: fw表示判别器网络。
d)情绪判别器损失:为了确保生成视频中的情绪表达,本文使用情绪鉴别器计算的情绪GAN损失,这是一种使用六个情绪类加一个“假”类的分类交叉熵损失。采用交叉熵损失函数计算此过程,对于每个样本,首先将它的真实标签进行one-hot编码,然后计算模型对该样本的预测概率向量。接下来,将预测概率向量和真实标签的one-hot向量相乘,并将所有类别的乘积求和,最后取负号得到交叉熵损失。
交叉熵损失的作用是最小化模型的预测值与真实标签之间的差距,使模型更好地拟合训练数据并泛化到未见过的数据。在情绪分类任务中,交叉熵损失帮助模型理解情绪类别之间的区别,并使得模型可以对输入的样本进行正确的情绪分类。在训练过程中,通过反向传播算法来优化模型参数,使交叉熵损失逐渐减小,从而提高情绪分类器的性能。
JED(x,y)=-∑Ci=1xilog yi(13)
其中:xi表示真实标签的第i个元素;yi表示模型预测x属于第i个类别的概率。交叉熵损失的本质是衡量两个概率分布之间的距离。当两个概率分布越接近时,交叉熵损失越小,表示模型预测结果越准确。
生成器步骤的完整目标函数如下:
JGEN=αLMRM1+βLperceptual2+γJFD+δJED(14)
其中:JGEN表示生成器损失;LMRM1表示口腔损失;Lperceptual表示感知损失;JFD表示帧判别器损失;JPD表示情绪判别器损失;α、β、γ、δ是每个损失函数各自的权重。
3 实验与分析
3.1 数据集
为了验证本文算法的有效性,在三个典型的数据集CREMA-D[22]、LRW-1000[23]、MEAD[24]上分别进行验证,本文将视频分辨率下采样到125×125,采样率处理为每秒25帧(FPS),将音频下采样到8 kHz。本文把数据集按照训练集(70%)、验证集(15%)和测试集(15%)随机划分,以确保公平地比较。在测试过程中,输入到生成器网络的条件图像都来自相同的真实视频,其中条件图像是视频的第一帧。
3.2 实验参数
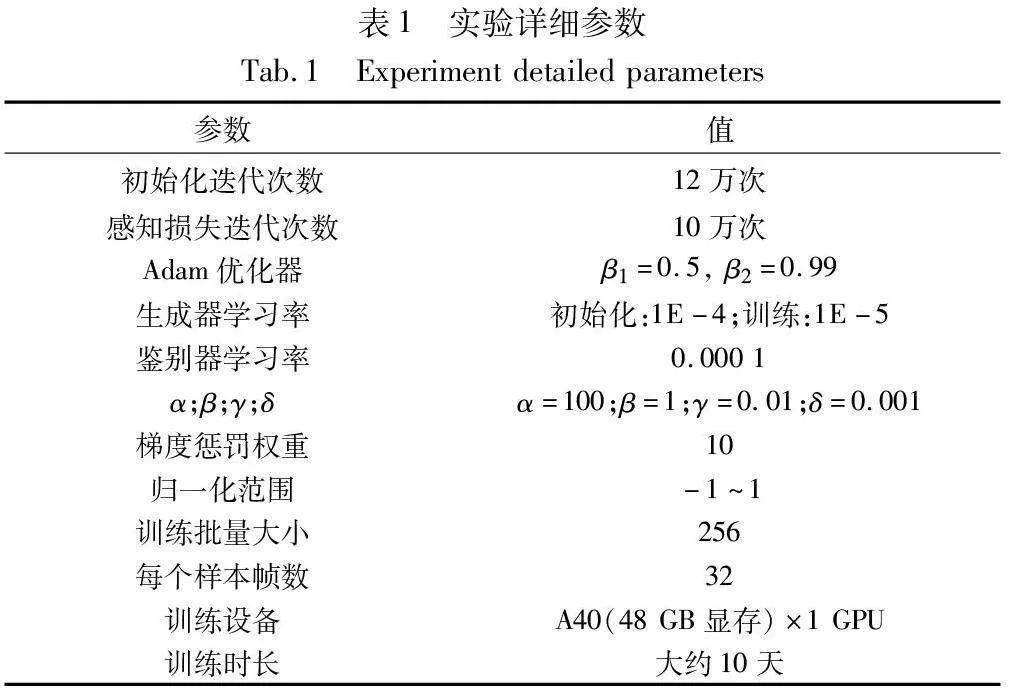
为了实现高质量的虚拟说话人脸生成,本文采用了一种基于感知损失的预训练策略,通过使用MRM(mean representation matching)损失进行12万次迭代的初始化训练。这个初始化过程帮助网络更好地捕捉情感表达和语音特征,为后续的全目标函数训练奠定基础。实验过程使用的详细参数如表1所示。
3.3 对比实验
本文使用生成视频帧和真实视频帧之间的峰值信噪比(PSNR)和结构相似性(SSIM)来评估生成视频的图像质量。为了测量视听同步,本文使用了从生成视频帧和真实视频帧中提取的地标之间的归一化地标距离(NLMD)。对于PSNR和SSIM,值越高越好;对于NLMD,值越低越好。
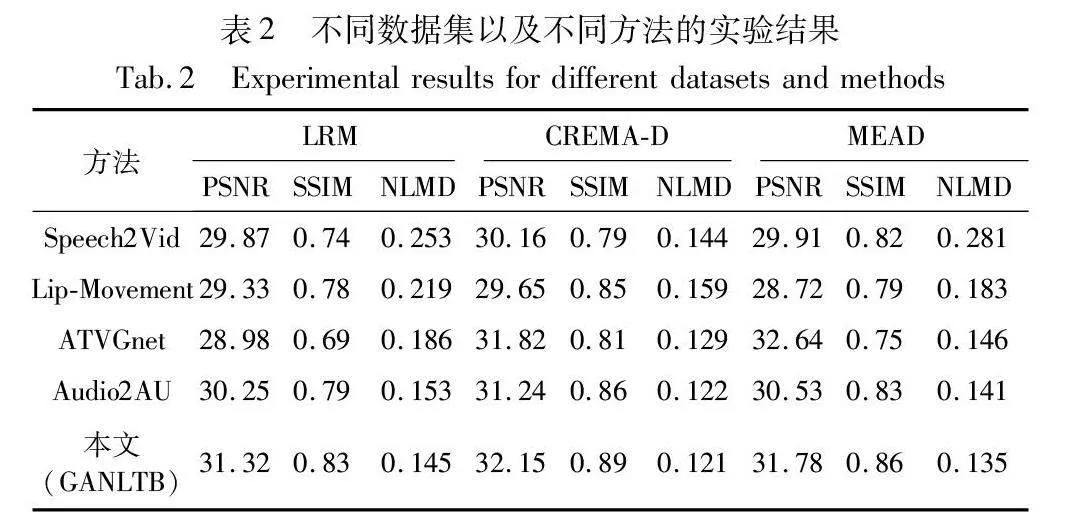
实验对比多个说话人脸视频生成模型,包括Speech2Vid、Lip-Movement、ATVGnet、Audio2AU以及笔者自己的方法。把各个模型的表现进行评估和对比,得出Speech2Vid[25]模型在生成说话人脸视频时,利用语音信息辅助生成视频,从语音到视频的转换能力相对较弱,导致生成的说话人脸视频在细节和逼真度方面表现一般。Lip-Movement[26]模型通过对嘴部运动的建模,实现了从嘴部动作到说话人脸视频的生成。然而,由于只考虑了局部的嘴部信息,生成的视频整体表现不够完整和自然。ATVGnet[27]模型采用生成对抗网络结构,通过对抗训练来提高视频生成的质量,其表现在人脸图像生成方面相对较好,但在情感表达和细节还原方面存在一定的限制。Audio-2AU[28]使用循环神经网络,从嘴部的角度对口型精度进行优化,提出了一个Audio-to-AU模块来预测语音中与语音相关的AU信息。不过在整体的面部动作协调性方面还有一定的完善空间。本文方法结合了Transformer和GAN,以及使用双三次插值法提升图像分辨率,能够更好地捕捉语音和视频之间的关系,并生成具有多样性和逼真情感表达的人脸视频,在整体逼真度和表现能力方面表现出一定优势。
本文方法在对比实验中使用CREMA-D、LRW-1000、MEAD数据集,展现出了较好的说话人脸视频生成能力,但仍有改进空间。不同模型在人脸图像生成方面有各自的优势和局限性,未来可以继续深入研究和改进,以进一步提升虚拟说话人脸视频生成的质量和真实感。不同数据集以及不同方法的实验结果对比如表2所示。
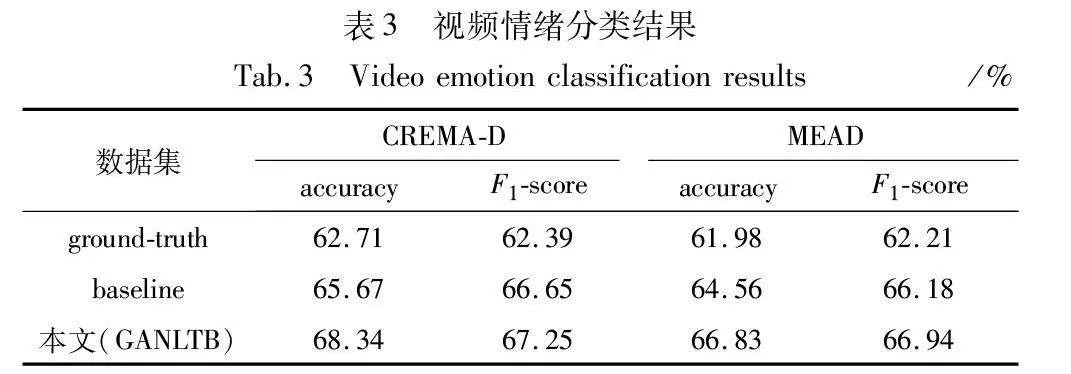
为了验证生成的视频中的情绪表达,使用CREMA-D、MEAD数据集训练了一个基于视频的情感识别网络,结果如表3所示。然后,本文对地面实况视频和笔者生成的测试集视频中的情绪进行了分类,结果如表3所示。基于真实视频CREMAD数据集的六类情感分类准确率为68.34%,MEAD数据集的六类情感分类准确率为66.83%,表明基于视频的情感分类器的有效性。
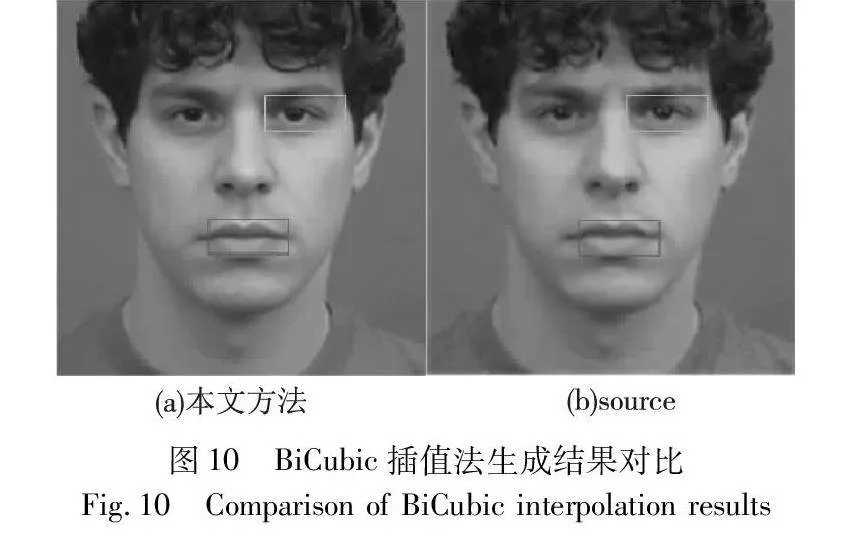
采用了双三次插值法将原始方法生成的128×128像素的人脸图像提升分辨率到256×256像素,如表4所示。相比较基线实验,图像的细节清晰度得到了显著增强,面部特征更加清晰可辨,使得虚拟说话人的形象更加真实和生动。其次,图像的纹理和质感得到了有效还原,使得人脸图像更具自然感。通过双三次插值法,图像的边缘和轮廓线条得到了更好的保持,减少了图像变形和锯齿效应,提高了生成图像的视觉质量。
3.4 实验视觉效果
1)长视频的生成结果
当设置生成10 s左右的长视频时,基线以及其他方法生成的视频对输入的语音、唇形动作就会变形,越来越不符合真实说话唇形动作。使用本文方法生成长视频时,很明显,本文视频更加符合真实说话人的唇形动作,结果如图8所示。
2)情绪分类结果
当设置生成人的不同情绪时,本文基线生成的视频结果看起来并没有很真实地表达出人类的六种明确的情绪:愤怒、厌恶、恐惧、幸福、中立和悲伤。使用本文方法由相同的条件图像和语音生成六种不同的情绪时,本研究结果看起来更加符合人在不同状态下表现出来的情绪,对比结果如图9所示。
3)像素提升质量
在实验过程中,本文采用双三次插值法用于提升生成的图像分辨率。相对于简单的放大算法,双三次插值法可以更好地保留图像细节和平滑性,从而在提高分辨率的同时减少图像的锐化和失真。使得虚拟说话人在表情、
眼神、嘴唇等方面表现更加细腻和真实。使用双三次插值法生成的图像结果如图10所示。
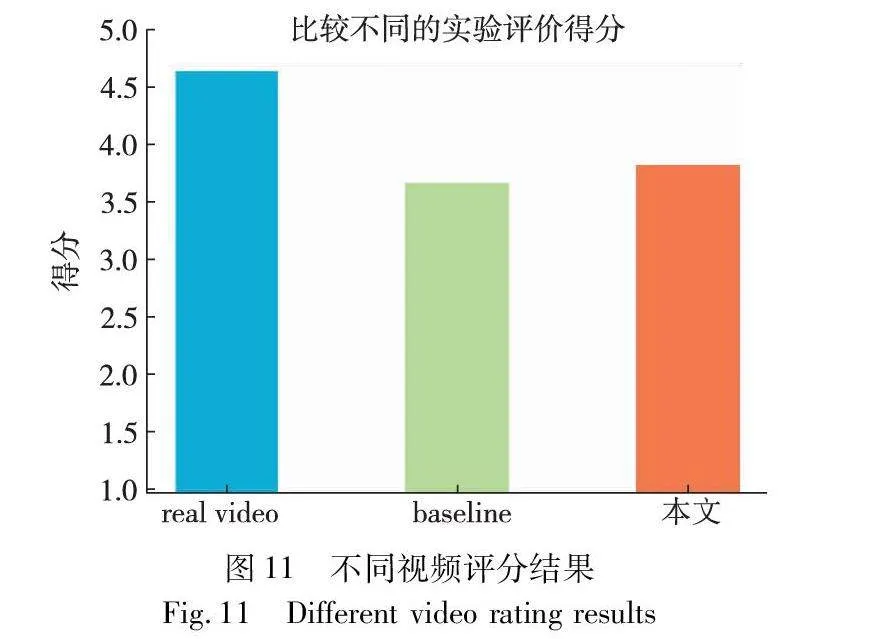
4)人工对生成视频质量评分
为了评价实验生成的视频真实性,挑选出50人从1分到5分对视频质量进行评分。评价者对所有视频质量的平均得分分别为4.65、3.68、3.84。结果表明,该实验生成的视频比基线视频质量略好,但是相比较真实视频仍有很大差距。分析认为生成的视频在分辨率和流畅度上还不足以媲美真实视频,这也是接下来本文重要的研究方向。评分结果如图11所示。
3.5 应用分析
1)应用场景分析
由于本文实验数据使用的全为英语数据集,所以生成的虚拟说话人脸可模拟真实英语教师,提供更自然的语言学习体验,如表5所示。在语言学习应用中,它可以展示英语的发音和口型,使学习更加生动有趣。
2)应用结果评价
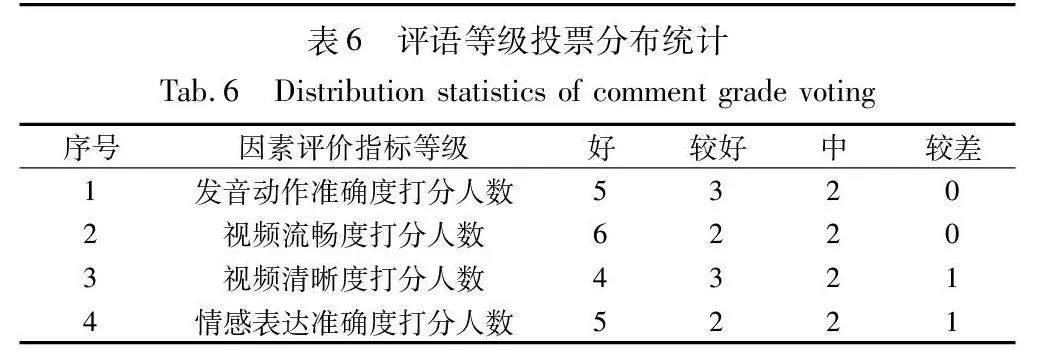
为了验证虚拟英语教师角色的应用成果,本文组织了10名人员对虚拟英语教师的教学效果从好、较好、中、较差等四个评语等级进行投票,四项评语等级投票分布如表6所示。
3.6 消融实验
为了测试本文所提出的融合多情感的语音驱动虚拟说话人生成方法(GANLTB)各个模块的有效性,首先评估虚拟说话人效果基线,使用一个标准的GAN来生成虚拟说话人的语音和人脸图像,这将作为实验的控制条件。添加LSTM和Transformer模块,分别用于提取语音和人脸图像的特征,作用是捕捉更多的上下文信息,并提高虚拟说话人的语音和图像一致性。最后应用BiCubic插值技术,通过提高人脸图像的分辨率来进一步改善虚拟说话人的逼真度。由表7中的PSNR、SSIM以及NLMD指标可知GANLTB方法的语音合成流利性、语调和情感传达,人脸图像的逼真度,包括细节、表情和一致性,都要优于基础模型,生成的虚拟说话人脸的整体质量也有显著提升。
4 结束语
本文提出了一种新的基于GAN的网络结构,使用Transformer模块进行图像生成,并能够从任意一张图像中准确和详细地重建人脸,同时生成拥有六种不同情绪的视频。本文方法生成的视频可以控制不同情绪,且每种情绪相互独立。同时,该方法生成的视频质量在视频长度和真实度方面优于其他方法。
尽管已经取得了较优的效果,但是在生成高分辨率视频的过程中还有很大的改进空间。未来,笔者计划进一步研究一些提高图像分辨率的方法,能够在生成高分辨率图像中取得良好的效果,这是未来工作中的重点。最后,笔者希望在接下来的工作中能够生成3D视频,从而让视频更具真实效果,能够真正参与到未来的3D影视作品中。
参考文献:
[1]Radford A,Metz L,Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks [EB/OL]. (2016-01-07). https://arxiv.org/abs/1511.06434.
[2]Khwanmuang S,Phongthawee P,Sangkloy P,et al. StyleGAN salon: multi-view latent optimization for pose-invariant hairstyle transfer [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2023: 8609-8618.
[3]Touvron H,Cord M,Sablayrolles A,et al. Going deeper with image transformers [C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2021: 32-42.
[4]Zhang Zhimeng,Hu Zhipeng,Deng Wenjin,et al. DINet: deformation inpainting network for realistic face visually dubbing on high resolution video [EB/OL]. (2023-03-07). https://arxiv.org/abs/2303.03988.
[5]Hong F T,Xu Dan. Implicit identity representation conditioned memory compensation network for talking head video generation [C]// Proc ofIEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2023: 23062-23072.
[6]Keys R. Cubic convolution interpolation for digital image processing [J]. IEEE Trans on Acoustics,Speech,and Signal Proces-sing,1981,29(6): 1153-1160.
[7]宋一飞,张炜,陈智能,等. 数字说话人视频生成综述[J]. 计算机辅助设计与图形学学报,2023,35(10):1457-1468. (Song Yifei,Zhang Wei,Chen Zhineng,et al. A review of video generation for digital speakers [J]. Journal of Computer-Aided Design and Graphics,2023,35(10):1457-1468.)
[8]Rabiner L,Juang B. An introduction to hidden Markov models [J]. IEEE ASSP Magazine,1986,3(1): 4-16.
[9]Eskimez S E,Zhang You,Duan Zhiyao. Speech driven talking face generation from a single image and an emotion condition [J]. IEEE Trans on Multimedia,2021,24: 3480-3490.
[10]年福东,王文涛,王妍,等. 基于关键点表示的语音驱动说话人脸视频生成 [J]. 模式识别与人工智能,2021,34(6):572-580. (Nian Fudong,Wang Wentao,Wang Yan,et al. Speech-driven talking face video generation based on keypoint representation [J]. Pattern Recognition and Artificial Intelligence,2021,34(6): 572-580.)
[11]Christos D M,Ververas E,Sharmanska V,et al. Free-HeadGAN: neural talking head synthesis with explicit gaze control [EB/OL]. (2022-08-03). https://arxiv.org/abs/2208.02210.
[12]Vaswani A,Shazeer N,Parmar N,et al. Attention is all you need [C]// Advances in Neural Information Processing Systems. 2017.
[13]Lee K,Chang Huiwen,Jiang Lu,et al. VitGAN: training GANs with vision transformers [EB/OL]. (2021). https://arxiv.org/abs/2107.04589.
[14]陈凯,林珊玲,林坚普,等. 基于Transformer人像关键点检测网络的研究 [J]. 计算机应用研究,2023,40(6): 1870-1881. (Chen Kai,Lin Shanling,Lin Jianpu,et al. Research on Transformer-based portrait keypoint detection network [J]. Application Research of Computers,2023,40(6): 1870-1881.)
[15]Aggarwal A,Srivastava A,Agarwal A,et al. Two-way feature extraction for speech emotion recognition using deep learning [J]. Sensors,2022,22(6): 2378.
[16]Wang Xintao,Li Yu,Zhang Honglun,et al. Towards real-world blind face restoration with generative facial prior[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2021:9164-9174.
[17]陈贵强,何军,罗顺茺. 基于改进CycleGAN的视频监控人脸超分辨率恢复算法 [J]. 计算机应用研究,2021,38(10): 3172-3176. (Chen Guiqiang,He Jun,Luo Shunzhi. A super-resolution recovery algorithm for video surveillance faces based on improved CycleGAN [J]. Application Research of Computers,2021,38(10): 3172-3176.)
[18]Arjovsky M,Chintala S,Bottou L. Wasserstein GAN [EB/OL]. (2017-12-06). https://arxiv.org/abs/1701. 07875.
[19]Gulrajani I,Ahmed F,Arjovsky M,et al. Improved training of Wasserstein GANs [C]// Advances in Neural Information Processing Systems. Cambridge,MA: MIT Press,2017: 5767-5777.
[20]Eskimez S E,Maddox R K,Xu Chenliang,et al. End-to-end generation of talking faces from noisy speech [C]//Proc of IEEE International Conference on Acoustics,Speech and Signal Processing. Pisca-taway,NJ:IEEE Press,2020: 1948-1952.
[21]Simonyan K,Zisserman A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2014). https://arxiv.org/abs/ 1409. 1556.
[22]Cao Houwei,Cooper D G,Keutmann M K,et al. CREMA-D: crowd-sourced emotional multimodal actors dataset [J]. IEEE Trans on Affective Computing,2014,5(4): 377-390.
[23]Yang Shuang,Zhang Yuanhang,Feng Dalu,et al. LRW-1000: a natu-rally-distributed large-scale benchmark for lip reading in the wild [C]// Proc of the 14th IEEE International Conference on Automatic Face & Gesture Recognition. Piscataway,NJ:IEEE Press,2019: 1-8.
[24]Wang Kaisiyuan,Wu Qianyi,Song Linsen,et al. MEAD: a large-scale audio-visual dataset for emotional talking-face generation [C]// Proc of European Conference on Computer Vision. 2020: 700-717.
[25]Chung J S,Jamaludin A,Zisserman A. You said that? [EB/OL]. (2017-07-18). https://arxiv.org/abs/1705.02966.
[26]Chen Lele,Li Zhiheng,Maddox R K,et al. Lip movements generation at a glance [C]// Proc of European Conference on Computer Vision. Cham: Springer International Publishing,2018: 520-535.
[27]Suwajanakorn S,Seitz S M,Kemelmacher-Shlizerman I. Synthesizing Obama: learning lip sync from audio [J]. ACM Trans on Graphi-cs,2017,36(4): 1-13.
[28]Chen Sen,Liu Zhilei,Liu Jiaxing,et al. Talking head generation with audio and speech related facial action units [EB/OL]. (2021-10-19). https://arxiv.org/abs/2110.09951.
