基于强化和模仿学习的多智能体寻路干扰者鉴别通信机制
2024-08-15李梦甜向颖岑谢志峰马利庄


摘 要:现有的基于通信学习的多智能体路径规划(multi-agent path finding,MAPF)方法大多可扩展性较差或者聚合了过多冗余信息,导致通信低效。为解决以上问题,提出干扰者鉴别通信机制(DIC),通过判断视场(field of view,FOV)中央智能体的决策是否因邻居的存在而改变来学习排除非干扰者的简洁通信,成功过滤了冗余信息。同时进一步实例化DIC,开发了一种新的高度可扩展的分布式MAPF求解器,基于强化和模仿学习的干扰者鉴别通信算法(disruptor identifiable communication based on reinforcement and imitation learning algorithm,DICRIA)。首先,由干扰者鉴别器配合DICRIA的策略输出层识别出干扰者;其次,在两轮通信中分别完成对干扰者与通信意愿发送方的信息更新;最后,DICRIA根据各模块的编码结果输出最终决策。实验结果表明,DICRIA的性能几乎在所有环境设置下都优于其他同类求解器,且相比基线求解器,成功率平均提高了5.2%。尤其在大尺寸地图的密集型问题实例下,DICRIA的成功率相比基线求解器甚至提高了44.5%。
关键词:多智能体; 路径规划; 强化学习; 模仿学习; 干扰者鉴别通信
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)08-032-2474-07
doi:10.19734/j.issn.1001-3695.2023.11.0555
Disruptor identifiable communication based on reinforcement and
imitation learning for multi-agent path finding
Li Mengtian1a,1b, Xiang Yingcen1a, Xie Zhifeng1a,1b, Ma Lizhuang1b,2
(1.a.Dept. of Film & Television Engineering, b. Shanghai Film Special Effects Engineering Technology Research Center, Shanghai University, Shanghai 200072, China; 2.Dept. of Computer Science & Engineering, Shanghai Jiao Tong University, Shanghai 200240, China)
Abstract:Most of the existing MAPF methods based on communication learning have poor scalability or aggregate too much redundant information, resulting in inefficient communication. To solve these problems, this paper proposed disruptor identifiable communication(DIC), which learned concise communication excluding non-disruptors by judging whether the agent in the center of the field of view would change its decision-making due to the presence of neighbors, and successfully filtered out redundant information. At the same time, this paper further instantiated DIC and developed a new highly scalable distributed MAPF solver: disruptor identifiable communication based on reinforcement and imitation learning algorithm(DICRIA). Firstly, the disruptor discriminator and the policy output layer of DICRIA identified the disruptor. Secondly, the algorithm updated the information of the disruptor and the communication wish sender in two rounds of communication respectively. Finally, DICRIA output the final policy according to the coding results of each module. Experimental results show that DICRIA’s performance is better than other similar solvers in almost all environment settings, and the algorithm increases the success rate by 5.2% on average compared to the baseline solver. Especially in dense problem instances with large-size maps, the algorithm even increases the success rate of DICRIA by 44.5% compared to the baseline solver.
Key words:multi-agent; path finding; reinforcement learning; imitation learning; disruptor identifiable communication(DIC)
0 引言
多智能体路径规划(MAPF)是为多个智能体寻找从起始位置到目标位置的无冲突路径集合的问题。MAPF在许多领域都有着广泛的应用,如城市道路网络[1]、火车调度[2]、多机器人系统[3]等。
按照规划方式不同,MAPF算法分为集中式规划算法和分布式执行算法。集中式规划算法是经典的MAPF算法,主要分为基于A*搜索[4~8]、基于冲突搜索[9~13]、基于代价增长树[14~16]和基于规约[17,18]四种。然而,这些集中式规划方法的局限性在于它们通常无法在保持高质量解决方案的同时扩展到更大的问题规模(更大的地图、更多的智能体),且由于计算成本较高,往往无法满足实际应用中的频繁实时重新规划的需求。关于传统集中式规划算法的详细介绍可参考文献[19]。
分布式执行算法是人工智能领域兴起的基于学习的MAPF算法,由于采取部分可观测性下的去中心化规划,而在解决实际部署中的频繁重规划问题上表现出了较大的潜力,近年来引起了越来越多的关注。仅依赖局部观测的去中心化规划能够让MAPF问题轻松地扩展到任意的世界大小(地图尺寸),但也严重限制了智能体可用的信息量,使它们难以完成需要高度协作的密集型MAPF任务。部分学者将强化学习与模仿学习相结合,采用传统集中式规划算法作为专家算法为强化学习提供指导[20,21],但由专家演示提供的着眼全局的指导信息不足以使智能体学会高效合作。另一部分学者则通过引入可学习的通信方法[22~25],允许智能体共享其信息,以弥补局部观测信息量受限的缺陷。这相当于间接扩大了FOV的范围,使智能体能够获取到其他智能体FOV内的观测信息,从而增加单个智能体可用的信息量并促进团队合作。但大多数采用通信的基于学习的MAPF方法的可扩展性都非常有限,通常无法在大小为40×40的地图上解决包含超过64个智能体的问题实例。先进的SCRIMP[26]通过基于改进Transformer的全局通信来聚合上一个时间步所有智能体的消息,虽然有效缓解了可扩展性的问题,却也造成了通信冗余,而这会在一定程度上损害智能体间的合作。并且,通信过去的消息(上一个时间步的消息)还存在滞后性的问题。因此,为多智能体路径规划设计一个能够解决以上问题的通信机制十分重要且必要。
针对上述方法的局限性,本文提出干扰者鉴别通信机制DIC,并进一步将其实例化,开发了一个新的基于强化和模仿学习的MAPF求解器DICRIA。DIC通过忽略其他邻居,只与那些对自身决策有影响的干扰者邻居进行通信,有效避免了聚合不相关的信息,从而避免了通信冗余问题;同时降低了通信频率,能够提高多智能体规划任务中的通信效率,帮助智能体更好地学会合作。具体地,其核心组件干扰者鉴别器将原始局部观测与掩蔽局部观测编码后的结果输入到DICRIA的策略输出层,根据决策差异识别出对中央智能体实际有影响的干扰者邻居。而后通信将分为发送通信意愿与给予反馈的两轮过程。首轮过程中,智能体向干扰者发送携带有自身信息的通信意愿,干扰者根据接收到的通信意愿更新信息并反馈更新后的结果。在第二轮中,完成对意愿发送方信息的更新。DICRIA结合两轮通信所聚合的信息与其他组成部分的编码结果,并据此输出最终的决策。实验结果表明,本文新MAPF求解器几乎在所有环境下,均在规划平均所耗时间步数、冲突率及成功率上优于其他最先进的同类求解器,并通过消融实验证明了本文提出的通信机制的有效性。本文的主要贡献总结如下:
a)提出一种适用于MAPF问题的新通信机制:干扰者鉴别通信,简称DIC。其核心组件是干扰者鉴别器。在通信之前,由干扰者鉴别器为每个智能体鉴别其FOV内的干扰者,通过只与干扰者进行通信,DIC有效避免了通信冗余。并且,DIC可与任意集中训练分散执行的强化学习框架兼容。
b)实例化DIC,开发了一种新的高度可扩展的分布式MAPF求解器:基于强化和模仿学习的干扰者鉴别通信算法DICRIA。智能体根据其视场内的局部观测及由DIC聚合的干扰者信息独立做决策。
c)本文在一系列具有不同团队规模、环境规模、障碍物密度的问题实例中进行了多方面的对比实验。实验结果证明了DICRIA在三项标准MAPF指标上的性能普遍优于其他先进的同类求解器。最突出的是,DICRIA成功地将基线求解器的成功率平均提高了5.2%,在密集型环境下,甚至提高了44.5%。
1 问题定义
1.1 MAPF问题定义
经典的MAPF以无向图G=(V,E)和智能体集合A={a1,…,an}作为输入,A中包含n个智能体。V为可通行的位置顶点集合,E为V中相邻点间的连通边的集合。每一个ai∈A都有一个唯一的起始顶点si∈V和一个唯一的目标顶点gi∈V。时间被离散化为时间步,在每一个时间步长上,智能体可以移动到相邻的顶点,也可以在当前位置顶点等待。智能体的路径是从si开始,到gi结束的由相邻(表示移动动作)或相同(表示等待动作)的顶点组成的序列。通常假设智能体到达目标后便永远停留在目标位置上。路径的长度计算为智能体向目标移动的过程中执行的动作总数(包括移动和等待两种动作),即其消耗的时间步数。智能体必须避免顶点冲突和交换冲突。当两个智能体在同一个时间步上占据相同的顶点将发生顶点冲突,以相反的方向穿过同一条边时将发生交换冲突。MAPF的解决方案是一组无冲突的路径,由n个智能体的路径组成。目标通常是最小化路径成本总和,即所有智能体到达其目标所消耗的时间步数之和。有关MAPF问题更全面的定义可参考文献[27]。
1.2 RL环境设置
与上述经典MAPF问题一致,本文将RL环境设置为离散的2D四邻域网格环境,其中智能体、目标和障碍物各自占据一个网格单元。环境地图是一个L×L的矩阵,其中0代表空单元格,1代表障碍物,地图边界之外的所有点均被视为障碍。每个问题实例中,本文在环境地图上为n个智能体从空单元格中随机选择非重复的起始位置和相应的目标位置,并且确保每对起始-目标位置之间的连通性。动作空间的大小设置为5,包括原地等待和上下左右四个方向的移动动作。在每个时间步上执行决策动作之前,先检查动作是否会导致冲突,若存在冲突则触发冲突处理机制(将在第3章阐述)对动作进行调整,并允许智能体同时执行调整后的动作。当所有智能体均到达目标,或达到预定义的时间限制时(256个时间步),终止对问题实例的求解。本文假设通信不受障碍物阻碍。
MAPF环境被设置为部分可观察,这更符合现实应用中机器人视野受限的实际情况。每个智能体只能访问其视场(FOV)内的信息,FOV的大小为l×l,本文实验中将l设置为奇数,以确保智能体位于FOV的中心。
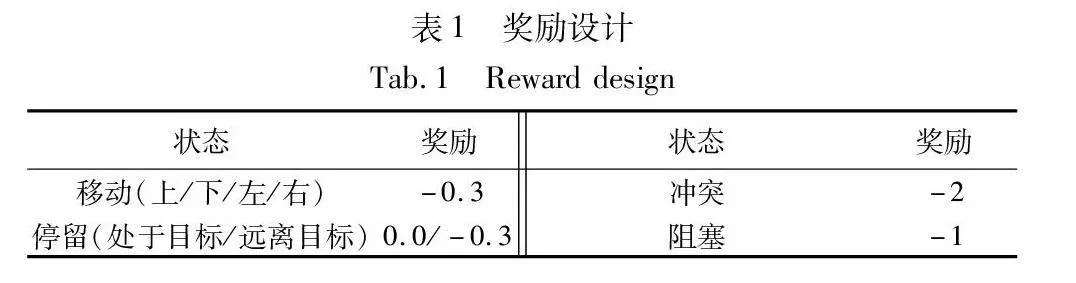
本文奖励设计同SCRIMP[26],如表1所示。对除了位于目标位置之外的所有状态都给予负奖励以促进目标的达成。
2 干扰者鉴别通信机制DIC
受I2C[28]的启发,本文提出了一种新的通信机制,称为干扰者鉴别通信机制DIC。DIC有效弥补了现有MAPF求解器通信机制的缺陷,避免了聚合过多无用信息而造成通信冗余、降低通信效率的问题。
I2C通过两个决策概率(考虑影响者时,被影响者的决策概率;掩蔽影响者时,被影响者的决策概率)之间的KL散度来度量一个智能体对另一个智能体决策的影响程度。当KL散度很小时,被影响的智能体选择不与影响者通信;当KL散度较大,超过预定义的阈值时,则进行通信。然而,I2C的局限性在于KL散度阈值的设置高度依赖于经验实验,且在不同的问题中差异较大,具有偶然性。此外,I2C还需要已知所有其他智能体的联合观测和动作,而在现实的MAPF问题中,具有局部观测性的智能体通常只能观察到有限范围内其他智能体的存在,且无法预测它们的动作。为此,本文提出DIC,其不依赖联合观测和动作,更适用于MAPF问题。
DIC的核心思想是,在训练和执行期间有选择的与部分邻居进行通信。本文认为,距离较近的智能体彼此之间并不总是相关的,并不是所有邻居都能提供有效信息。如果对邻居的信息不作筛选和判断,同SCRIMP一样全盘接收,容易获取到来自其他智能体的不相关且冗余的信息,聚合过多无用信息会间接降低实际有效的信息的正向指导效力,甚至会误导模型,从而导致不明智的决策,损害智能体之间的合作。因此,有必要在通信之前对邻居的信息进行筛选,为每个智能体找出那些能够为其决策提供有效信息的相关邻居,只与它们进行通信,能有效过滤冗余信息,降低通信成本,且有助于智能体更好地学习合作。而只有当邻居智能体的存在引起FOV中央智能体的决策调整时,DIC才确定该邻居是相关的和有影响力的。本文将那些会对中央智能体的决策产生影响的邻居称为干扰者(disruptor)。对干扰者的判断仅基于智能体的局部观测来学习,因此能够在大规模的多智能体规划问题中通过分散执行的方式有效部署。
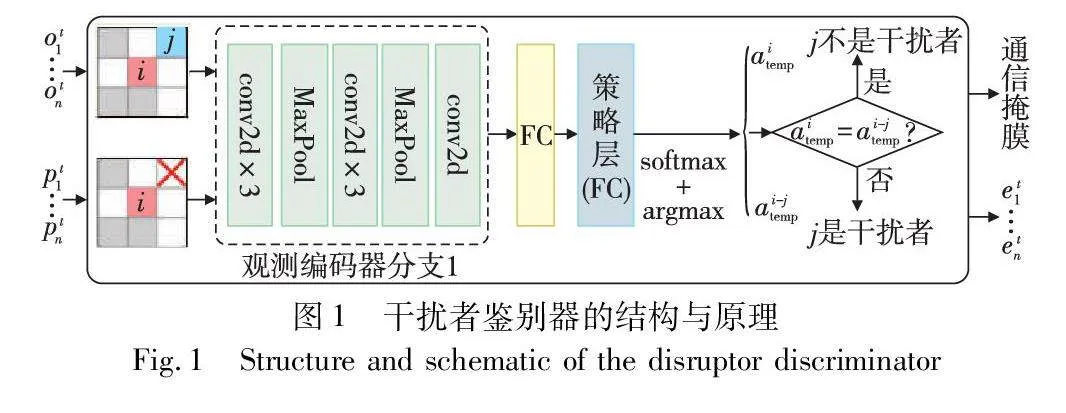
DIC对干扰者的判断由干扰者鉴别器来完成,图1显示了鉴别器的结构与完整的鉴别流程。在3×3的FOV中,灰色方格代表障碍物,彩色方格代表智能体,红色的“×”表示从智能体i的局部观测中掩蔽掉智能体j(参见电子版)。以简单的局部场景为例,假设智能体i的FOV内只有一个邻居智能体j。智能体i的局部观测表示为oi(原始局部观测),从oi中掩蔽掉智能体j,得到i的掩蔽局部观测oi-j。通过在oi中将j对应位置处的信息设置为某个特殊的值(例如0)来实现这种掩蔽。然后,智能体i分别基于oi和oi-j,使用决策模型(跳过通信块)计算出两个临时的决策,对应生成两个临时的动作。具体地,利用本文决策模型中观测编码器的第一个分支(将在第3.1节阐述),oi和oi-j作为其输入值,将该分支的输出结果经过一个全连接(FC)层处理后直接输入到策略输出头(将在第3.4节阐述),为i的两种局部观测分别计算出对应动作空间中所有动作的概率分布,并将概率最大的动作确定为最终的临时动作aitemp和ai-jtemp。如果aitemp和ai-jtemp相互匹配,则意味着智能体j的存在不会影响i的决策,即j与i不相关,不是i的干扰者,i不与j通信;否则,j确定为i的干扰者,i需要与j进行通信。
当为智能体i鉴别出所有干扰者j之后,DIC的通信将分两轮进行。本文将这两轮的通信过程形象化地描述为智能体之间发送通信意愿(wish)以及给予反馈(feedback)的信息交流过程。在第一轮中,智能体i向其所有干扰者j发送wish,wish中包含自身信息以及邻居的相对位置。干扰者可能收到来自不同意愿发送者的wish,并根据收到的所有wish更新自身的信息。在第二轮中,所有干扰者j将feedback回复给智能体i,feedback中包含更新后的自身信息及邻居的相对位置。智能体i根据接收到的feedback完成信息的更新。
3 MAPF求解算法DICRIA
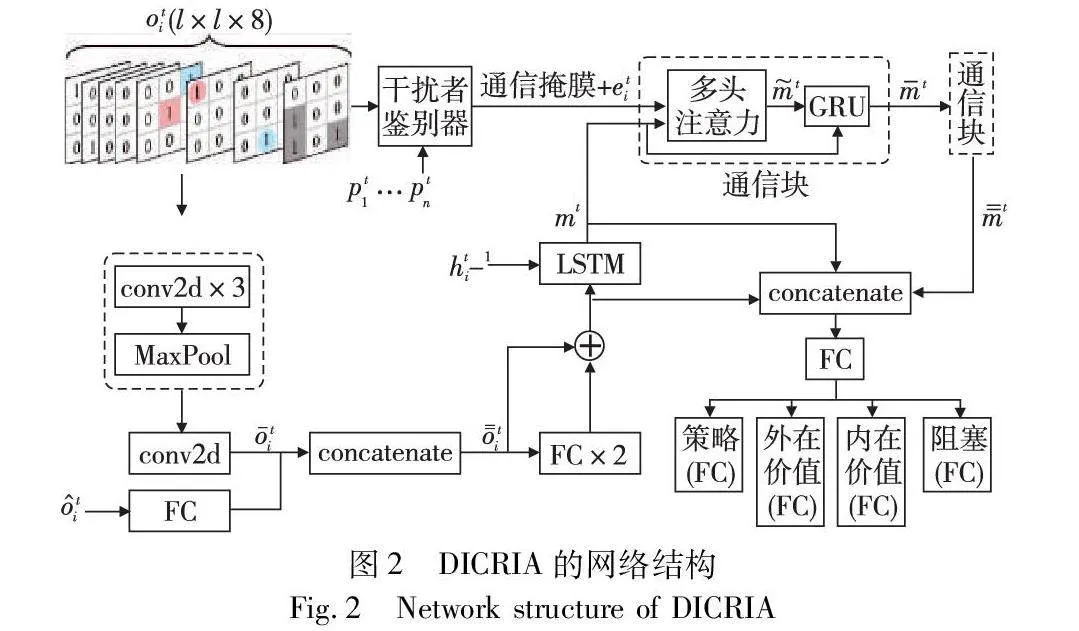
本文参考SCRIMP[26],为解决 MAPF问题开发了一种新的求解器:DICRIA,其实例化了在第2章详细介绍的新通信机制。DICRIA的网络结构如图2所示,由观测编码器(绿色)、干扰者鉴别器(黄色)、通信模块(紫色)和输出头(蓝色)四个主要部分组成(参见电子版)。干扰者鉴别器的详情如图1所示。FOV内8通道的局部观测以3×3的网格示例,其中彩色方块表示智能体,彩色圆形表示颜色对应的智能体的目标,灰色方块表示障碍物。本章将分别描述这四个组成部分。
3.1 观测编码器
观测编码器由7个卷积层、2个最大池化层、3个全连接(FC)层和1个LSTM单元组成。在LSTM单元之前,被分成了两条并行的分支,分别处理当前时间步智能体的局部观测和智能体的观测向量两个不同的输入值。
分支1的输入,即当前时间步智能体的局部观测oti(i=1,…,n)的形状为l×l×8,由8个二进制矩阵组成。前四个是DHC[23]提出的启发式通道,分别对应上下左右四个移动动作,当且仅当智能体通过采取该动作更接近其目标时,对应通道上的相应位置被标记为1,以此编码单智能体最短路径的多种选择。其余四个通道分别表示智能体的位置、中心智能体自己的目标位置(如果在FOV内)、FOV内其他智能体目标的投影位置以及FOV内的障碍物。分支2的输入是智能体的观测向量ti,包含7个分量:智能体当前位置与其目标沿x轴的归一化距离dxti、沿y轴的归一化距离dyti、总欧氏距离dti、外在奖励ret-1i、内在奖励rit-1i、智能体上一个时间步的位置与其在缓冲区中存储的历史位置间的最小欧氏距离dmint-1i(均在第3.4节介绍)以及上一个时间步的动作at-1i。
智能体i的局部观测oti首先通过分支1被编码为ti,具体经过了两个相同的子模块(3个卷积和1个最大池化层)和一个单独的卷积层。同时,长度为7的观测向量ti在分支2中由一个FC层独立编码,然后将分支2的输出与ti串连得到o=ti。接着,o=ti与其自身经过两个FC层编码后的结果相加,并和上一个时间步LSTM的输出ht-1i一起输入LSTM单元,从而赋予了智能体跨时间步聚合过去信息的能力。
3.2 干扰者鉴别器
该鉴别器需要当前时间步智能体的局部观测oti和当前位置pti作为输入,根据oti计算出掩蔽局部观测oti-j(j∈Ni,Ni是i的FOV内所有邻居智能体的集合),根据pti计算邻居智能体在FOV内的相对位置eti。然后,按照第2章中描述的鉴别流程,为每个智能体找出各自的干扰者,由此确定t时刻,i的通信范围为Ci={j|aitemp≠ai-jtemp}j∈Ni,aitemp和ai-jtemp为第2章中描述的临时动作。Ci最终被编码为通信掩膜,并和eti一起作为干扰者鉴别器的输出值馈入通信模块。
3.3 通信模块
通信模块由两个相同的计算块组成,分别对应两轮通信。通信采用图卷积,以多头点积注意力[29]作为卷积核,后跟一个GRU。本文将两轮通信描述为智能体之间发送通信意愿(wish)和给予反馈(feedback)的过程。
在第一轮中,智能体i向所有的干扰者j∈Ci发送wish,wish中包含自身信息,即oti和ti经过观测编码器处理后的输出信息mti∈mt(mt是LSTM单元的输出值),以及邻居智能体的相对位置eti。干扰者可能收到来自不同意愿发送者的多条wish,由此干扰者j的wish接收范围可表示为C~j={i|j∈Ci}。然后,干扰者j根据收到的所有wish使用多头点积注意力更新自身信息mtj∈mt,同时保持意愿发送方i的信息在本轮不变,得到第一轮通信的输出结果t。具体地,在每个独立的注意力头h中,首先将i∈j的自身信息mti通过矩阵WhQ映射为query,再将mti与eti的串连分别通过矩阵WhK和WhV映射为key和value。干扰者j与i∈j在第h个注意力头中的关系则可以计算为
whji=softmax(WhQmtj·(WhK[mti,eti])TdK)(1)
其中:dK是keys的维度。在每个注意力头h中,以whji为权重对value进行加权求和,并将所有头的输出串连后通过一个神经网络层fnn,得到干扰者j的注意力输出值tj:
tj=fnn(concat(∑i∈jwhjiWhV[mti,eti],h∈Euclid Math OneHAp))(2)
最后,将干扰者j计算注意力前的自身信息mtj与tj经过GRU聚合,得到最终更新后的信息tj。
在第二轮中,所有干扰者j将feedback回复给智能体i,feedback中包含更新后j的自身信息(j的第一轮通信结果tj)及etj。同理,意愿发送方i根据收到的所有feedback(来自j∈Ci)完成对自身信息的更新,更新方法与第一轮相同。与此同时,干扰者的信息在本轮保持不变。经过两轮通信之后,通信模块的最终输出为m=t。
3.4 输出头
输出头由5个全连接(FC)层组成。其中,一个是公共FC层,用于编码LSTM单元的输入(不包括ht-1i),LSTM单元的输出mt以及通信模块的输出m=t三者的串连。余下的FC层用于将公共FC层的输出分别编码成策略(policy)、外在奖励的预测状态值(extrinsic value)、内在奖励的预测状态值(intrinsic value)及可学习的阻塞预测值(blocking)四个不同的输出值。
policy是模型的决策,即当前时间步智能体的策略。具体为动作空间中每个动作的概率值,概率值最大的动作便是模型为智能体选出的在当前时间步的最佳动作。
本文采用了SCRIMP对冲突决策的处理机制和用于鼓励探索的内在奖励设计。当模型输出的决策将导致冲突时,则会触发冲突处理机制。该机制以使未来收益最大化为准则,进行比较判断,选出一个胜者智能体来执行其首选动作,与之冲突的其他智能体则重新选择一个新动作,以此来解决智能体间的冲突。当与障碍物冲突时,则使智能体停留在原地并给予惩罚。而内在奖励是指远离熟悉的区域所获得的奖励,相对地,执行动作空间中的动作而获得的奖励被称为外在奖励。当智能体的当前位置与其历史位置间的距离超过一个阈值时,便给予内在奖励,以此鼓励探索,从而增大其到达目标的可能性。外在和内在奖励的预测状态值便是模型对当前时间步所能获得的真实外在和内在奖励的估计,这两个输出值同时也在冲突处理机制中用于打破对称性,帮助选择最终被允许执行首选动作的胜者智能体。
最后,blocking用于指示一个智能体是否阻碍其他智能体更早到达其目标,并隐式地帮助智能体理解它们可能受到的额外阻塞惩罚(表1)。
关于冲突处理机制和内在奖励的详细介绍、两个预测状态值和blocking更具体的用法及作用请参见SCRIMP[26]。训练使用的损失函数及超参数的设置均同SCRIMP,具体见下一节。
3.5 训练设置
在MAPF问题中,一个问题实例的完整求解过程被称为一个episode。设置一个episode的最大求解时间为256个时间步,超过时限仍未完成求解的问题实例被判定为求解失败。训练的截止时间为3×107个时间步,由外层while循环来判断是否达到训练的终止条件。在每一轮while循环开始之前,根据预定的比例随机选择网络是通过IL还是RL进行训练,IL被选中的概率设置为0.1。在每一轮while循环中,本文借助Ray 1.2.0使用16个进程并行收集数据,并将epoch设置为10,batch size设置为1 024。优化器选用Adam优化器,lr为10-5。策略优化的损失函数如下:
Lπ(θ)=1T1n∑Tt=1∑ni=1min(rti(θ)AtiEuclid ExtravBp,clip(rti(θ),1-,1+)AtiEuclid ExtravBp)(3)
rti(θ)=πθi(ati∣oti,ti,ht-1i,mt1,…,mtn)πθoldi(ati∣oti,ti,ht-1i,mt1,…,mtn)(4)
其中:θ表示神经网络的参数;rti(θ)是裁剪概率比;πθi和πθoldi分别是智能体i的新旧策略;是裁剪超参数,值为0.2;AtiEuclid ExtravBp是优势函数的截断版。
4 实验评估
本文模型在第1章描述的环境中进行训练和测试。训练时,每个问题实例中环境地图的尺寸被随机确定为10、25或40,障碍物的密度从0~0.5的三角分布中随机采样,峰值为0.33(与基线算法相同),且智能体个数固定为8。本文为测试设置了5种不同的地图尺寸和智能体个数的组合:{[8,10],[16,20],[32,30],[64,40],[128,40]},前者是智能体个数,并将每种组合的障碍物密度固定为0、0.15和0.3(DHC[23]和PICO[25]的最高测试密度)。为每种组合的每个障碍物密度各随机生成100个问题实例,总共在100×3×5=1500个问题实例上进行了实验评估。除非特别说明,在训练和测试阶段FOV的大小均被设置为3×3。
本文使用PyTorch 1.11.0编写代码,Python版本为3.7。全部实验在配备有两个NVIDIA GeForce RTX 4090 GPUs和一个Intel Xeon Gold 6133 CPU @ 2.50 GHz(80核,160线程)的服务器上运行,系统环境为Ubuntu 20.04。
4.1 与基线求解器比较
本文测试了DICRIA与基线求解器SCRIMP在EL、CR和SR三项指标上的性能。其中:EL表示求解一个问题实例所消耗的时间步数(最晚到达目标的智能体的路径长度);CR表示与包括地图边界的静态障碍物的冲突率,计算方式为式(5);SR表示成功求解(所有智能体均在时限内到达目标)的实例在全部测试实例中的占比,衡量在给定时限内完成MAPF任务的能力。EL和CR越小代表策略越好,SR越大越好。SCRIMP的FOV大小设置为其原工作中的3×3,与本文设置相同。
CR=冲突数EL×智能体数×100%(5)
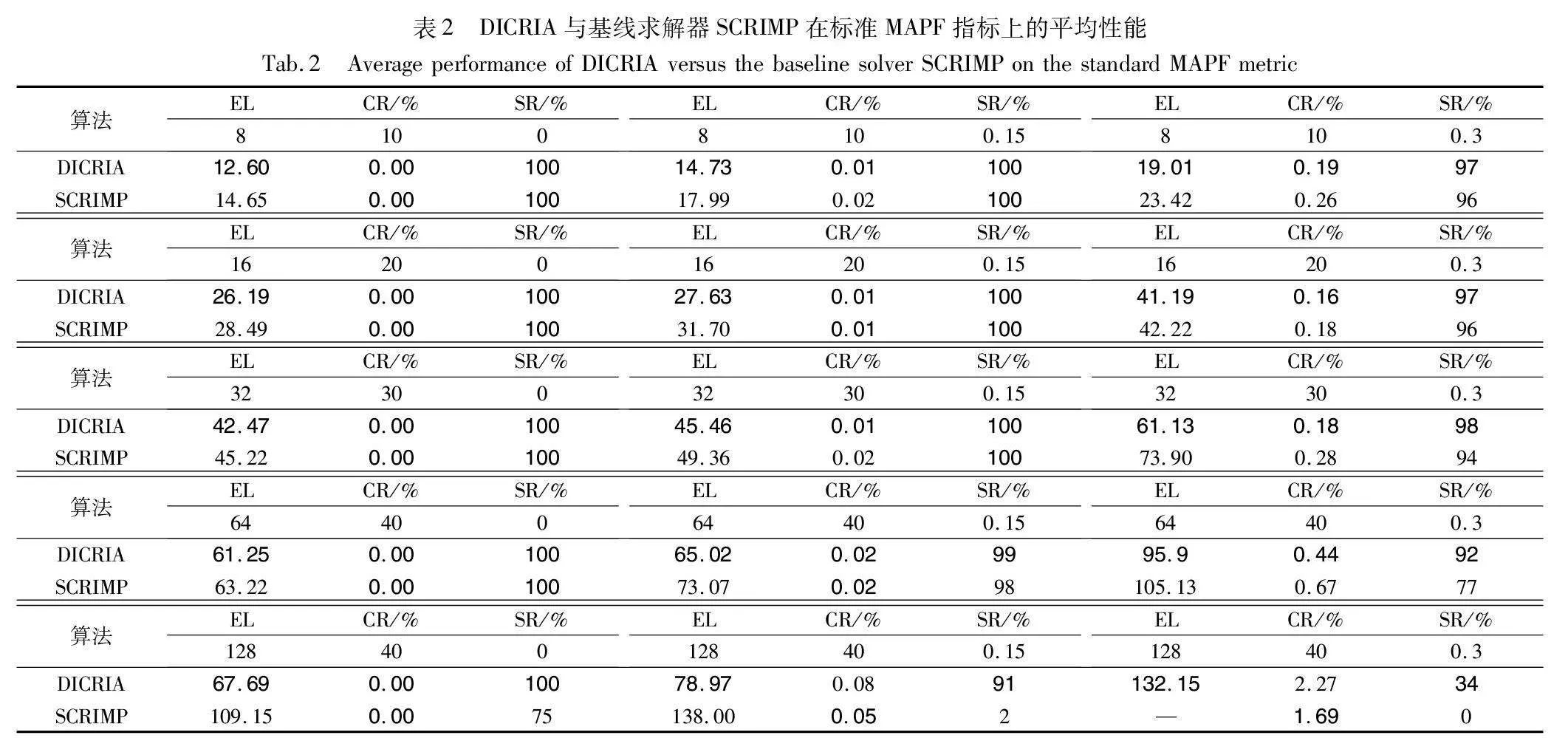
表2展示了在各项指标上的比较结果。在不同环境配置中,智能体个数在8、16、32、64和128之间变动;地图大小在10~40变动;障碍物密度在0、0.15和0.3之间变动。所有数据均为相应环境配置下随机生成的100个问题实例上测试结果的平均值。表中,EL的计算排除了求解失败的情况(超过256个时间步);“—”表示无有效结果。每种环境配置下,各项指标最好的结果以粗体显示。
如表2所示,在EL和SR这两项指标上,DICRIA在所有情况下均优于SCRIMP。在其无法解决的环境配置下,DICRIA仍然具有相当的成功率。尤其在地图大小为40×40,障碍物密度为0.15,包含128个智能体的密集型实例下,本文求解器的成功率是91%,而SCRIMP仅为2%,DICRIA的成功率相比SCRIMP甚至提高了44.5%。在地图尺寸(40×40)和智能体个数(128)保持不变时,将障碍物的密度从0.15增加到0.3,SCRIMP将无法完成任何任务,成功率为0%,而DICRIA仍然具有34%的成功率。这主要是因为SCRIMP采用全局通信机制,无论距离远近,无论是否相关,每个智能体都会与环境中的所有其他智能体进行通信,而这显然会聚合大量冗余信息。虽然其通信机制中的可学习权重能够区分信息的重要性,在一定程度上缓解这一问题,但在全局通信所引入的大量无关信息面前,这一点补救措施所起的作用十分有限。尤其在此密集型的问题实例下,SCRIMP全局通信机制的缺陷更是加倍体现了出来,最终导致了0%成功率这一糟糕的结果。与之相反,全局通信的劣势正是本文新通信机制的优势所在。DIC在局部FOV内筛选通信对象,只与实际相关的干扰者邻居交换信息。不仅从距离上摒除了“远房亲戚”无关信息的干扰,而且还会对近邻是否影响自身决策作进一步的判断,故而能够有效过滤冗余信息,并以显著的优势超越全局通信机制,获得可观的成功率。统计结果显示,本文成功将基线求解器的SR平均提高了5.2%。
在CR方面,DICRIA在绝大多数情况下优于SCRIMP,但在[128,40,0.15]和[128,40,0.3]的环境配置下略高于SCRIMP的CR值。造成这种情况的一个可能的原因是,在密集型环境中,大量智能体试图抢占有限的可移动的位置节点,导致彼此的决策具有较强的相关性,SCRIMP通过全局通信而引入的更完备的信息将更有利于智能体在此环境下进行全局范围内的协调,而DICRIA基于局部FOV的通信机制却不可避免地具有一定程度上的局部最优性问题。但这种差异仅在个别情况下存在,且微乎其微,并不影响最终的成功率。
4.2 与其他MAPF求解器比较
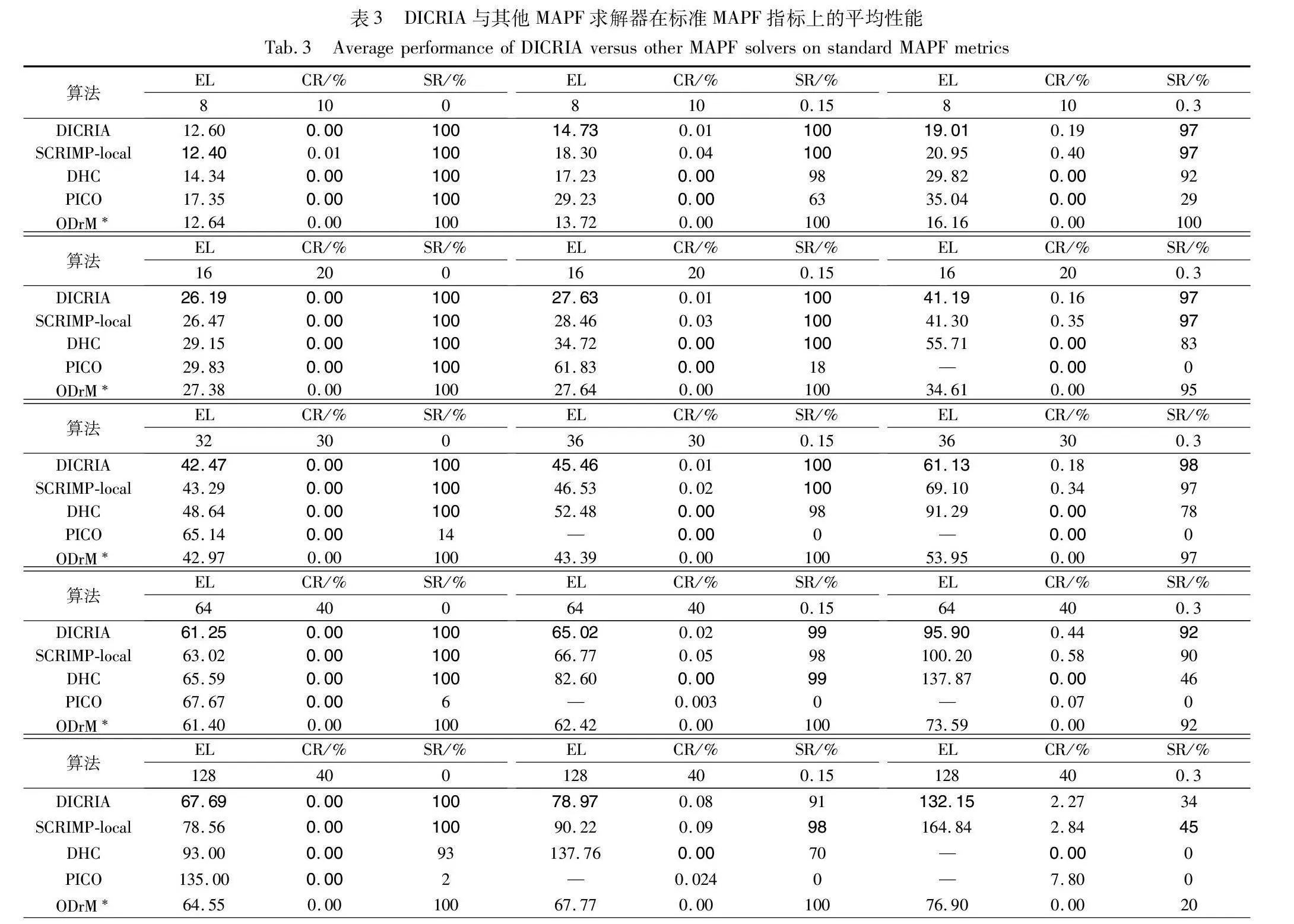
本文将DICRIA与其他先进的基于学习的MAPF求解器进行了比较,包括DHC[23]、PICO[25]以及SCRIMP-local[26]。其中,DHC和PICO的实现来自各自的文献,且FOV的大小均保留其工作中的原始设置,分别为9×9和11×11。SCRIMP-local是本文通过限制通信范围得到的SCRIMP的扩展版本,规定只与欧氏距离不超过5的邻居进行通信,其FOV大小同SCRIMP,为3×3。此外,本文还额外测试了传统集中式算法ODrM*[6],作为性能参考。
表3显示了在不同环境配置的问题实例下,不同算法的三项标准MAPF指标的平均性能。与表2相同,EL的计算排除了求解失败的情况(基于学习的方法超过256个时间步,ODrM*超过5 min未完成求解);“—”表示无有效结果。除了ODrM*,其他算法在各项指标上的最好结果以粗体显示。总体而言,DICRIA几乎在所有情况下都具有最低的EL值,这意味着相比其他求解器,DICRIA获得了路径最短即质量最高的解。
关于CR,DICRIA的CR始终低于SCRIMP-local,但大多数情况下还是高于DHC和PICO的。这可能是因为本文的内在奖励设置鼓励智能体探索新的区域,在此过程中遇到障碍的可能性会不可避免地增加。相比之下,DHC和PICO倾向于让智能体留在熟悉的区域,以此逃避探索未知可能带来的惩罚,因为长期停留在安全区会具有更低的CR值。然而,在成功率上DICRIA完胜DHC与PICO。尤其当智能体增加到32个以上,环境规模扩大到30×30时,DHC与PICO表现出了明显的性能下降,PICO几乎无法完成任何实例的求解。
本文注意到在[128,40,0.15]和[128,40,0.3]的环境配置下,DICRIA的SR低于SCRIMP-local。本文怀疑这是因为在密集型环境中,由于智能体决策的强相关性,个体的决策对更远处的其他智能体仍会造成影响。DICRIA依靠3×3的FOV范围来筛选通信对象,可能并没有覆盖到全部潜在的干扰者,所能获取到的信息量在该情况下也显得不够充分,不足以支持智能体学会良好的配合。而SCRIMP-local由于额外设置了更大的通信范围(欧氏距离不超过5),更能满足密集环境下的通信需求,又因为减轻了原版SCRIMP全局通信冗余的问题,从而获得了更高的成功率。在第4.3节中,当FOV的大小调整为5×5时,在同样的环境配置(128个智能体,地图大小40×40,障碍物密度0.15和0.3)下, DICRIA的SR分别为99%和55%,均超越了SCRIMP-local(98%和45%),验证了这一猜想。
此外,DICRIA在大多数情况下与传统算法ODrM*具有相似的性能。特别是在需要智能体高度协作的最困难任务中(128个智能体,地图大小40×40,障碍物密度0.3),DICRIA的成功率(34%)明显超越了ODrM*(20%)。
4.3 FOV大小的影响
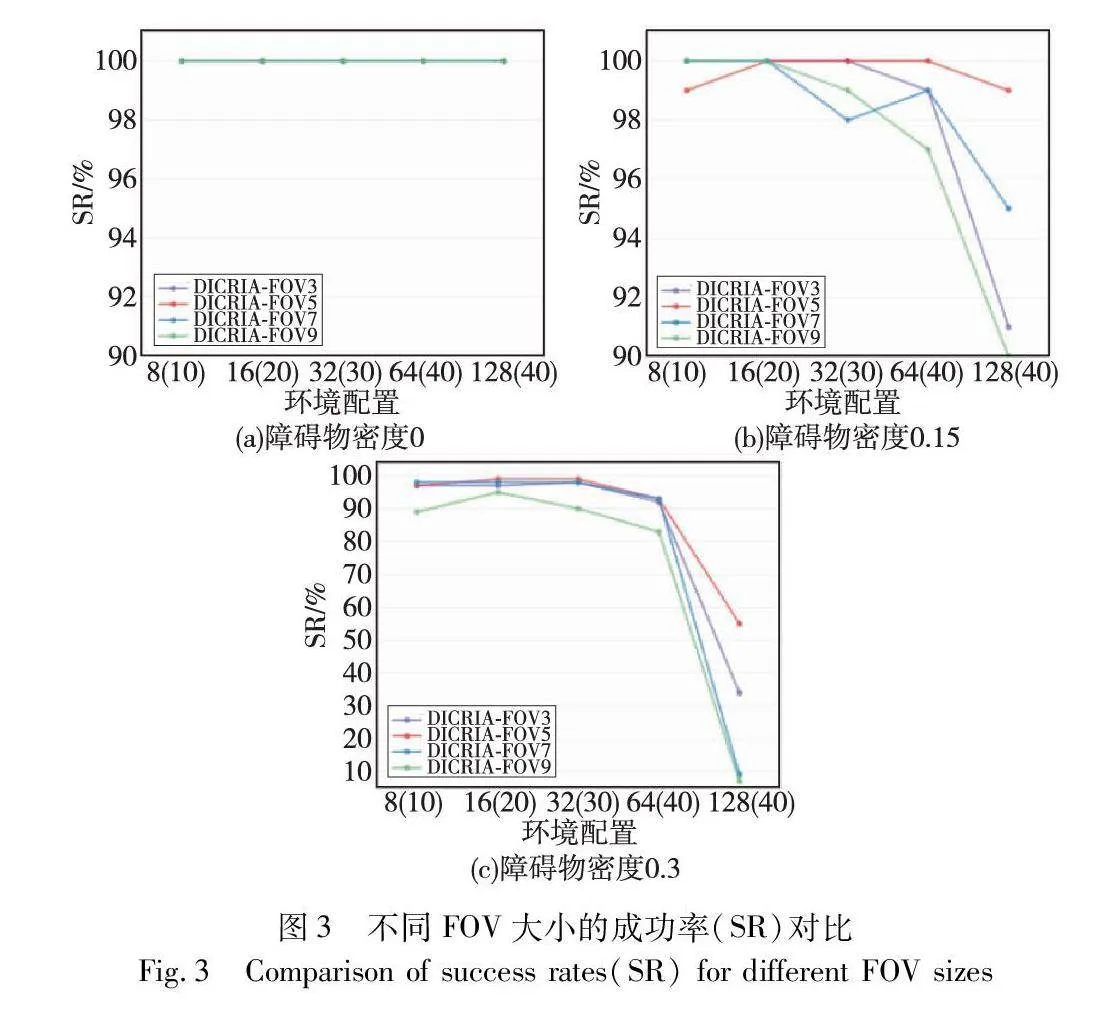
本文进一步测试了不同FOV的大小对模型性能的影响。根据测试结果发现,相较于SR,改变FOV的大小对EL和CR的影响并不明显,因此图3只展示了在SR上的对比结果。图中,8、16、32、64、128是智能体个数,括号中为对应的环境地图的尺寸。图3(a)~(c)分别是障碍物密度为0、0.15和0.3时的结果。如图3所示,当FOV的大小为5×5时,DICRIA实现了最佳性能。值得注意的是,随着FOV尺寸的增大,训练和测试时间也明显增长,因此需要在模型性能与时间成本之间有所权衡。
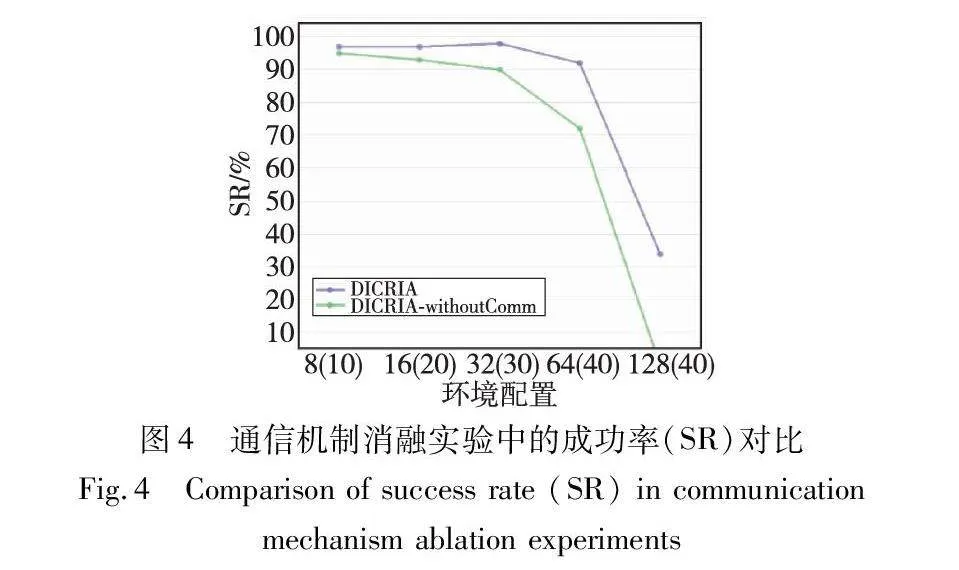
4.4 通信的消融
为了验证本文通信机制的有效性,通过完全删除干扰者鉴别器及通信模块,开发了DICRIA的无通信版本——DICRIA-withoutComm。同时为了提高训练和评估的速度,仍然将FOV的大小设置为3×3(与训练原始DICRIA的设置相同),而不是采用在第4.3节确定的性能最佳的5×5。图4只展示在对比最明显且最重要的指标SR上的结果。障碍物密度固定为0.3。显然,在智能体分布较密集的大型环境中,DICRIA-withoutComm表现出了性能的急剧下降,该结果充分证明了DIC的有效性。
5 结束语
在基于RL或IL的MAPF求解方案中引入通信的学习被证明是一种有效的方法,可以解决部分可观测性下完全去中心化规划导致的可用信息量受限的问题。本文考虑到现有基于学习的MAPF求解器通信方法的局限性,提出干扰者鉴别通信机制DIC。DIC凭借由干扰者鉴别器根据原始局部观测与掩蔽局部观测求得的决策差异来识别FOV内的干扰者,通过排除非干扰者的简洁通信过程而有效过滤掉了不相关的信息,避免了通信冗余。本文又进一步实例化了DIC,开发了一种新的基于强化和模仿学习的MAPF求解器:DICRIA,既保留了DIC能够实现高效通信的优点,还具有较高的可扩展性。在一系列具有不同环境配置的问题实例上的实验结果表明,DICRIA在三项标准MAPF指标上的性能普遍优于其他最先进的同类求解器。几乎在所有环境配置中,本文模型具有比基线求解器及其扩展版本更低的CR值。这说明通过筛选和收集相关的、实际有影响力的干扰者的信息进行通信,DICRIA有效加强了智能体间的合作,使得它们能够以更协调的方式完成任务。本文还成功地将基线求解器的SR平均提高了5.2%。特别在大尺寸地图的密集型问题实例下,DICRIA的成功率相比基线求解器,提升高达44.5%。此外,对通信机制的消融实验充分证明了DIC的有效性。
最后,需要说明的一点是,虽然本文的干扰者鉴别通信机制给模型带来了实际的性能提升,且具有诸多上述优点,但干扰者鉴别器筛选通信对象、过滤冗余信息的过程也将产生额外的计算成本。将在未来的工作中,探寻能够更好地平衡成本与性能的优化方案。
参考文献:
[1]Choudhury S, Solovery K, Kochenderfer M,et al. Coordinated multi-agent pathfinding for drones and trucks over road networks[C]//Proc of the 21st International Conference on Autonomous Agents and Multiagent Systems. London: AAMAS Press, 2022: 272-280.
[2]Mohanty S, Nygren E, Laurent F, et al. Flatland-RL: multi-agent reinforcement learning on trains[EB/OL]. (2020-12-11). https://arxiv.org/abs/2012.05893.
[3]Cartucho J, Ventura R, Veloso M. Robust object recognition through symbiotic deep learning in mobile robots[C]//Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE Press, 2018: 2336-2341.
[4]Ferguson D, Likhachev M, Stentz A. A guide to heuristic-based path planning[C]//Proc of International Workshop on Planningunder Uncertainty for Autonomous Systems: International Conference on Automated Planning and Scheduling. Palo Alto, CA: AAAI Press, 2005: 9-18.
[5]Standley T. Finding optimal solutions to cooperative pathfinding problems[C]//Proc of the 24th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2010: 173-178.
[6]Wagner G, Choset H. Subdimensional expansion for multirobot path planning[J]. Artificial Intelligence, 2015, 219(2): 1-24.
[7]Ren Zhongqiang, Rathinam S, Likhachev M, et al. Enhanced multi-objective A* using balanced binary search trees[C]// Proc of the 15th International Symposium on Combinatorial Search. Palo Alto, CA: AAAI Press, 2022: 162-170.
[8]Ren Zhongqiang, Rathinam S, Choset H. Loosely synchronized search for multi-agent path finding with asynchronous actions[C]//Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE Press, 2021: 9714-9719.
[9]Sharon G, Stern R, Felner A,et al. Conflict-based search for optimal multi-agent pathfinding[J]. Artificial Intelligence, 2015, 219(2): 40-66.
[10]Barer M, Sharon G, Stern R,et al. Suboptimal variants of the conflict-based search algorithm for the multi-agent pathfinding problem[C]//Proc of the 21st European Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2014: 961-962.
[11]Rahman M, Alam M A, Islam M M,et al. An adaptive agent-specific sub-optimal bounding approach for multi-agent path finding[J]. IEEE Access, 2022, 10: 22226-22237.
[12]Li Jiaoyang, Ruml W, Koening S. EECBS: a bounded-suboptimal search for multi-agent path finding[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 12353-12362.
[13]Andreychuk A, Yakovlev K, Surynek P,et al. Multi-agent pathfin-ding with continuous time[J]. Artificial Intelligence, 2022, 305: 103662.
[14]Shaaron G, Stern R, Goldenberg M,et al. The increasing cost tree search for optimal multi-agent pathfinding[J]. Artificial Intelligence, 2013, 195: 470-495.
[15]Walker T T, Sturtevant N R, Felner A. Extended increasing cost tree search for non-unit cost domains[C]//Proc of the 27th International Joint Conference on Artificial Intelligence.Palo Alto, CA: AAAI Press, 2018: 534-540.
[16]Walker T T, Sturtevant N R,Felner A, et al. Conflict-based increa-sing cost search[C]//Proc of the 31st International Conference on Automated Planning and Scheduling. Palo Alto, CA: AAAI Press, 2021: 385-395.
[17]Yu Jingjin, LaValle S M. Planning optimal paths for multiple robots on graphs[C]//Proc of International Conference on Robotics and Automation.Piscataway, NJ: IEEE Press, 2013: 3612-3617.
[18]Surynek P, Felner A, Stern R,et al. Efficient SAT approach to multi-agent path finding under the sum of costs objective[C]//Proc of the 22nd European Conference on Artificial Intelligence. [S.l.]: IOS Press, 2016: 810-818.
[19]刘志飞, 曹雷, 赖俊, 等. 多智能体路径规划综述[J]. 计算机工程与应用, 2022, 58(20): 43-62. (Liu Zhifei, Cao Lei, Lai Jun, et al. Summary of multi-agent path planning[J]. Computer Engineering and Applications, 2022, 58(20): 43-62.)
[20]Sartoretti G, Kerr J, Shi Yunfei, et al. PRIMAL: pathfinding via reinforcement and imitation multi-agent learning[J]. IEEE Robotics and Automation Letters, 2019,4(3): 2378-2385.
[21]Lin Chen, Wang Yaonan, Yang Mo,et al. Multi-agent path finding using deep reinforcement learning coupled with hot supervision con-trastive loss[J]. IEEE Trans on Industrial Electronics, 2023, 70(7): 7032-7040.
[22]Li Qingbiao, Lin Weizhe, Liu Zhe,et al. Message-aware graph attention networks for large-scale multi-robot path planning[J]. IEEE Robotics and Automation Letters, 2021, 6(3): 5533-5540.
[23]Ma Ziyuan, Luo Yudong, Ma Hang. Distributed heuristic multi-agent path finding with communication[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway, NJ: IEEE Press, 2021: 8699-8705.
[24]Ma Ziyuan, Luo Yudong, Pan Jia. Learning selective communication for multi-agent path finding[J]. IEEE Robotics and Automation Letters, 2021,7(2): 1455-1462.
[25]Li Wenhao, Chen Hongjun, Jin Bo,et al. Multi-agent path finding with prioritized communication learning[C]//Proc of International Conference on Robotics and Automation. Piscataway, NJ: IEEE Press, 2022: 10695-10701.
[26]Wang Yutong, Xiang Bairan, Huang Shinan,et al. SCRIMP: scalable communication for reinforcement and imitation learning based multi-agent pathfinding[C]//Proc of International Conference on Autonomous Agents and Multiagent Systems. London: AAMAS Press, 2023: 2598-2600.
[27]Stern R, Sturtevant N, Felner A,et al. Multi-agent pathfinding: definitions, variants, and benchmarks[C]//Proc of the 12th Annual Symposium on Combinatorial Search. Palo Alto, CA: AAAI Press, 2019: 151-159.
[28]Ding Ziluo, Huang Tiejun, Lu Zongqing. Learning individually inferred communication for multi-agent cooperation[C]//Proc of the 34th Annual Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 22069-22079.
[29]Vaswani A, Shazeer N, Parmar N,et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2017: 5998-6008.
