FMLogs:基于模板匹配的日志解析方法
2024-08-15章一磊张广泽龚声望苑淑晴




摘 要:日志主要记录软硬件的运行信息,通过查看系统日志,可以找到系统出现的问题及原因,确保系统的稳定性和正常运行。日志解析的目的是将半结构化的原始日志解析为可阅读的日志模板,现有解析方法往往只注重于对原始日志的解析,而忽略了后期模板处理,导致结果的精度不能进一步提高。自此,提出了一种日志解析方法FMLogs(logs parsing based on frequency and MinHash algorithm)。该方法通过设计正则表达式和调节阈值参数以获得最佳性能,同时采用了字符级频率统计和MinHash方法对长度相同和不同的日志模板进行合并。FMLogs在七个真实数据集上进行了广泛的实验,取得了0.924的平均解析准确率和0.983的F1-Score。实验结果表明,FMLogs是一种有效的日志解析方法,在解析日志的同时具有较高的准确性和效率,并能保证性能的稳定。
关键词:日志分析; 解析方法; 数据分析
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)08-030-2461-06
doi:10.19734/j.issn.1001-3695.2023.12.0612
FMLogs: log parsing method based on template matching
Zhang Yilei, Zhang Guangze, Gong Shengwang, Yuan Shuqing
(School of Computer & Information, Anhui Normal University, Wuhu Anhui 241000, China)
Abstract:Logs record the software and hardware running information. By viewing system logs, you can find system faults and causes to ensure system stability and normal running. The purpose of log parsing is to parse semi-structured original logs into readable log templates. The existing parsing methods often only focus on parsing the original logs, but ignore the later template processing. As a result, the accuracy of the results cannot be further improved. Since then, this paper proposed a new log parsing method FMLogs. This method designed regular expressions and adjusted threshold parameters to obtain the best perfor-mance. Meanwhile, it used character-level frequency statistics and MinHash methods to merge log templates with the same length and different log templates. FMLogs conducted extensive experiments on seven real datasets, achieving an average analytic accuracy of 0.924 and an F1-score of 0.983. The experimental results show that FMLogs is an effective log parsing me-thod with high accuracy, high efficiency, and stable performance.
Key words:log analysis; analytical method; data analysis
0 引言
随着进入大数据时代,越来越多的软件及系统被投入市场,在开发和维护软件系统的过程中,需要工程师不断地投入精力去保持整个软件系统及环境的稳态平衡。考虑在现实中存在大量的非专业人员参与其中,有限的知识领域使得他们不能更好地操作。因此,有研究者提出通过系统自动解析的日志文件来更好地了解系统的运行[1,2]。
日志文件是软件开发和维护过程中的重要资源,供开发人员和系统管理员使用。通过分析日志文件,开发人员可以通过了解系统的运行状况并进行故障排查。此外,日志文件还可以用于安全审计、合规性检查和故障恢复等方面。常见的日志文件格式包括文本文件、数据库记录或特定格式的二进制文件。日志文件通常按时间戳顺序存储,以便追溯和分析特定时间段的事件。对于开发人员而言,日志文件是不可或缺的重要资源,往往也是他们唯一能够获取的关键信息。日志文件作为系统运行的重要指标之一,日志解析在逐年的研究中性能得到了极大的改善,但是仍存在一些局限,如有些普适的解析方法适用于大众系统日志,而对于某些系统日志则会降低其解析精准度[3],无法做到平衡;而针对极大量的日志,例如,在阿里巴巴的云计算系统中,每小时会以1.2~2亿条日志的速度产出[4],使得解析过程变得缓慢。
近些年来,日志解析得到了国内外研究者广泛的关注,现有的解析可大致分为基于规则驱动、基于代码分析和基于数据驱动的日志解析方法。基于规则驱动的解析方法一般需要使用预定义的规则集来识别和提取日志的信息;基于代码分析的解析方法需要开发人员编写特性的代码去解析日志,通过特定的逻辑和算法来提取模板;基于数据驱动的方法则是通过分析实际数据来推动决策、建模或优化过程。随着日益增加的数据量和日志的多样性,基于规则驱动和基于代码分析的方法出现维护成本高、不灵活和过于依赖人工等缺点,而数据驱动方法逐渐成为主流。基于规则驱动的方法包括Grok[5]、SEC[6]等,基于数据驱动的包括LogMine[7]、LKE[8]、Drain、IPLoM、AEL、Spell[9]、Oilog[10]等。目前数据驱动解析主要采用三类技术。第一种是基于聚类[7,8,11]的算法,在日志解析中,基于聚类的算法旨在将具有相似格式或内容的日志消息归为同一类别,从而可以更好地理解日志数据、检测异常情况以及提取有用的信息。例如,IPLoM [12]通过迭代分割和挖掘的方式来解析日志数据,根据长度、令牌位置和双目标关系将日志消息分组;WT-Parser[13]通过日志单词构成来筛选模板单词用于日志聚类,再采用前缀树的思想提取日志模板;Vue4logs[14]利用信息检索领域常用的向量空间模型对日志数据进行矢量化,并根据日志信息的向量相似度将日志信息分组为事件模板;LPV[15]利用自然语言处理中的向量化方法,将日志消息和日志模板转换为向量,然后通过对向量的聚类对日志消息进行聚类,最后从聚类结果中提取日志模板。虽然基于聚类的算法具有无须标记样、实用性广泛的优点,但是聚类算法对于大规模的日志数据可能需要大量的计算资源和时间。第二种是基于频率的算法,基于频率的算法利用日志行或单词的频率来识别日志模式和结构,在简单和实时性方面具有优势。这类算法认为,日志中常量出现的频率较高,而变量出现的频率较低,通过分析这些频率可以区分日志中的常量与变量,从而实现对日志的解析。例如,feature tree[16]基于频率构建一棵特征树来实现日志解析和模板生成;Logram[17]通过两个步骤自动解析日志消息为静态文本和动态变量,统计日志消息中所有的n-gram频率,并计算每个n-gram的出现次数,最后将常量固定并将参数转换为通配符即可获得日志模板;PatCluster[18]通过统计单词的频率,提取频率最大的单词,对根节点生成的模板进行细化,递归对节点中的所有元素形成模式节点,并生成相应的模板。第三种是基于启发式的算法,这类算法基于开发人员的经验,通过分析日志的结构、格式和内容来提取有用的信息,并生成可读性强的日志模板,但是对于大规模和复杂的数据集可能难以适用,并且需要持续的专业知识支持。例如,Drain[19]通过构建一个树状结构,将相似的日志消息归类在一起,从而实现日志的解析和模板生成;AEL[20]能够自动识别和标记日志消息中的实体,从而将非结构化的数据转换为结构化的信息;PosParser[21]通过将FTS作为日志特征表示,利用两阶段检查方法和后处理流程对日志进行模板化处理;ML-Parser[22]利用前缀树和基于LCS细粒度处理来达成更好的处理;CLDT[23]结合日志的常量令牌长度特征,利用决策树搜索、相似度计算与事件生成,更新决策树从而生成模板;PrefixGraph[24]利用前缀图并且尽量减少超参数的影响,最后自动提取日志模板。
通常,不同系统会产生不同的日志模块,当开发人员编写应用程序、系统或其他软件时,他们会在代码中插入生成日志的语句。如图1所示,日志通常有以下组成部分:日志级别(例如:“I”“D”“W”等)、日志内容(例如:“shouldBlockL-ocation running…”)、时间戳(例如:“16:13:40.280”)以及日志组件(例如:“PhoneInterfaceManager”)。而日志分析是指对生成的日志文件进行系统性的解析、处理和分析,以提取有价值的信息和洞察。日志分析通常包括以下步骤:收集日志、预处理、数据清洗和过滤、数据解析和转换、分析和挖掘、发现和诊断、报告和可视化。通过日志解析,可以帮助系统管理员及时发现和响应安全事件,防止未经授权的访问以及保护系统和数据的安全性。但是现有的大部分方法都存在着由于模板分区生成不精准而导致的准确率不足的问题,这些问题产生的原因在于没有重视对已生成模板的二次处理,使得部分模板重复或相异模板的融合,降低了最终结果的准确度。
针对以上不足,本文提出了一种新的解析方法FMLogs。为了评估FMLogs的有效性,在七个真实的数据集上进行实验。实验结果表明FMLogs具有较好的准确性。本文的贡献总结如下:a)提出使用首令牌建立ID分组和基于令牌长度的二次分组,避免重复搜索,提高了查找效率;
b)提出采用字符级频率统计应用于日志解析,以更好地计算相同长度的模板之间的相似性;c)提出使用MinHash算法构建倒排索引表,比较给定的两个日志模板,分别获取MinHash签名,利用Jaccard相似度融合模板进一步提高模板精确度。
1 方法
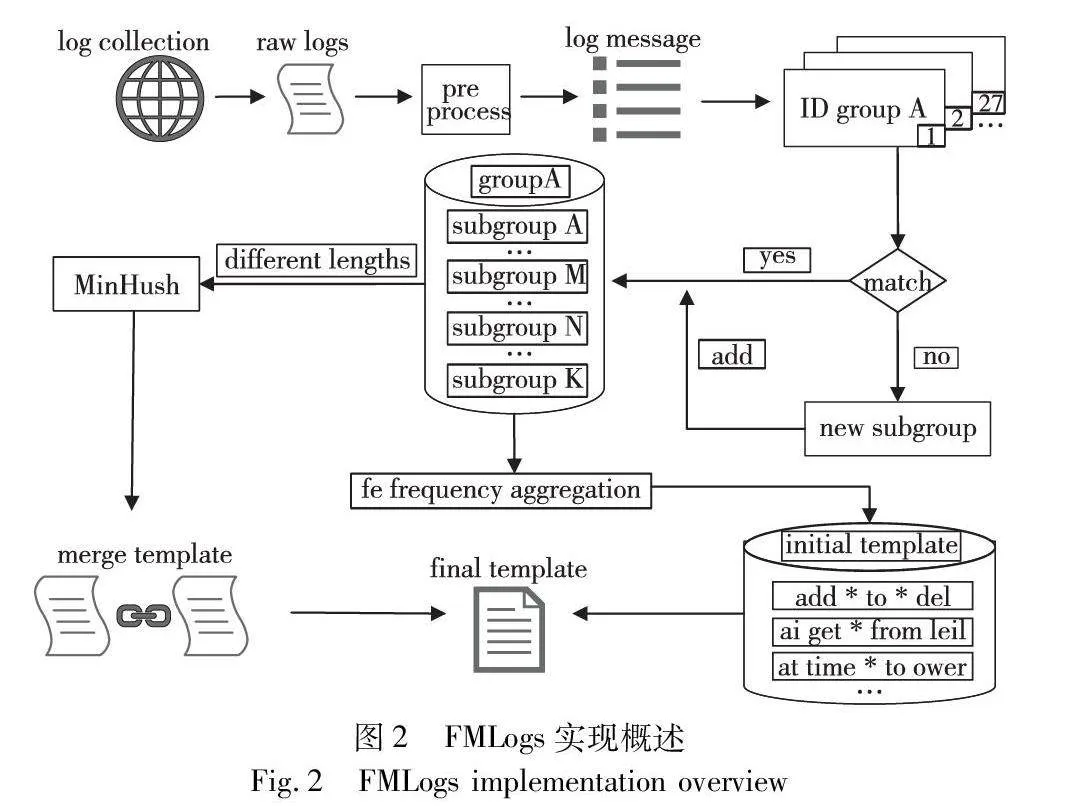
FMLogs模型如图2所示。首先,该方法使用基于领域知识的正则表达式对原始日志进行预处理,以达到最好的处理效果。其次,根据日志消息的首个令牌进行ID分组,然后按照令牌个数将日志消息划分为不重叠的小组。接着,计算每个分区中每个模板的频率统计值,通过向量距离合并相似模板。最后,对不同长度的相似模板进行聚类,计算每个分区中每个模板的MinHash值,对于给定的两个日志模板,分别获取它们的MinHash签名,比较两个签名之间相等的哈希值数量,并除以总共哈希值的数量,得到一个近似的相似度值,这种相似度可以用Jaccard相似度来近似衡量,根据与阈值相比较判断相似模板是否需要融合。综上所述,FMLogs包括预处理、令牌划分、频率统计和模板提取四个部分。
1.1 预处理
在当前的步骤中,该方法通过应用领域知识,对原始日志进行了预处理。一方面,日志通常由日志头部和日志内容两个方面组成,而日志模板通常是由日志内容提取而成,因此使用正则表达式去除日志头部,留下日志内容;另一方面,FMLogs在正则表达式处理的基础上添加了相应的专业领域知识进行进一步的处理,通过通配符〈*〉替换大部分变量,目的是为了后期工作更精准的进行。值得指出的是,尽管正则表达式在替换常见变量方面表现出色,但仍然有许多变量无法被处理,下一步将会在这方面进行深入研究。
1.2 令牌划分
在进行模板归纳之前需要对日志进行粗粒度的处理,尽管前文中提到的预处理方案极大地降低了模板生成的难度,但仍然需要进行进一步的处理。在现有方法中,如Vue4Logs中提出了对每个令牌建立倒排索引,通过对令牌进行编号生成唯一ID标识,从而进行相似性识别并建立模板。而相较于其他方法,FMLogs将根据模板首令牌对模板进行第一次粗粒度分区,然后在此基础上根据长度进一步对所生成的模板进行二次分区。方法中将相同长度的模板放入同一组,在IPLoM中证明了相同长度的日志消息更有可能具有相同的模板。例如,日志模板“BLOCK* ask〈*〉 to delete 〈*〉”包含6个token。可以直观地得出结论,具有此模板的日志共享相同数量的令牌,例如“BLOCK* ask 10.250.18:500 to delete blk_-51”。但是,不同长度的日志消息可能具有相同的模板,例如“BLOCK* ask 10.250.17:50010 to delete blk_-85817 blk_-65376955”,虽然包含7个token,但日志模板为“BLOCK* ask 〈*〉 to delete 〈*〉〈*〉”,很明显这个日志模板可以与上一个日志模板相融合,这个问题通过MinHush处理得到解决。
1.3 计算频率统计值
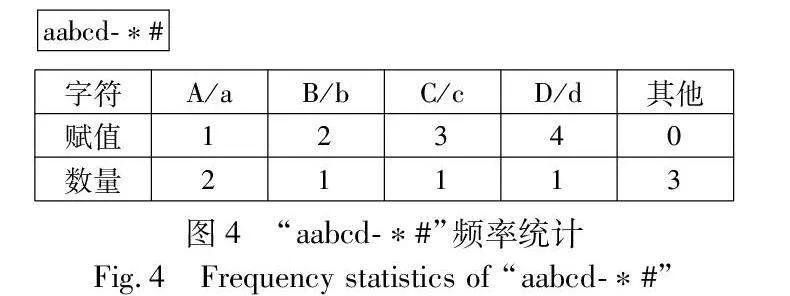
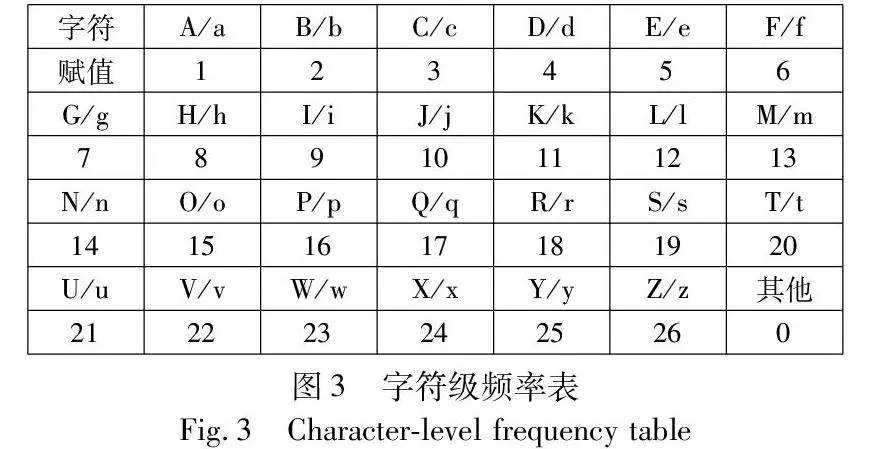
为了判断二级分组中的两个日志模板是否应该合并在一起,需要对模板作出一定的判断,与PosParser通过令牌长度和个数的对比不同,FMLogs首先设定e表示二级分组中不同的日志模板,例如,ei,j={e1,e2,e3,…,en}表示序号为i的一级分组下的序号为j的二级分组中的日志模板。此外,拼写相似的单词将被视为完全不同的单词。然后将每个单词表示为字符级频率f(e)(图3),计算每个分组中每个模板的f(e)值,并通过向量距离合并相似模板,这样的判断提高了模板的融合精准度。
将特征的长度固定为27,其中符号(其他)共用一个位置0,字母(大写和小写一起)放在剩下的26个位置。如图4所示,假设W(e)=“aabcd-*#”,长度为7,字母“a”在这个单词中出现了2次,因此,可以计算出f(e)=11。
然后利用dist表示两日志模板的相似程度,这里dist表示为日志e1,e2的字符级频率与日志长度之比的差值来计算,如果距离dist(e1,e2)小于阈值γ,则这两个分支是相似的。距离dist(e1,e2)的公式如下:
dist(e1,e2)=‖f(e1)‖f(e1)‖-f(e2)‖f(e2)‖‖(1)
根据日志的f(e)值和日志的长度比之差,设置阈值判断在相同长度时是否需要合并。例如,单词“received(8.875)”和“receiving(10.222)”之间的差值为1.347,单词“block”和“blocked(1.171 4)”之间的距离为0.275。随着日志模板长度的增加,差异也会变小。日志信息“Received block 〈*〉 of size 〈*〉 from /〈*〉(7.4545)”与“Receiving block 〈*〉 of size 〈*〉 from/〈*〉(7.852 9)”之间的距离仅为0.398 3,这比单个单词之间的差异要小得多。
1.4 合并模板
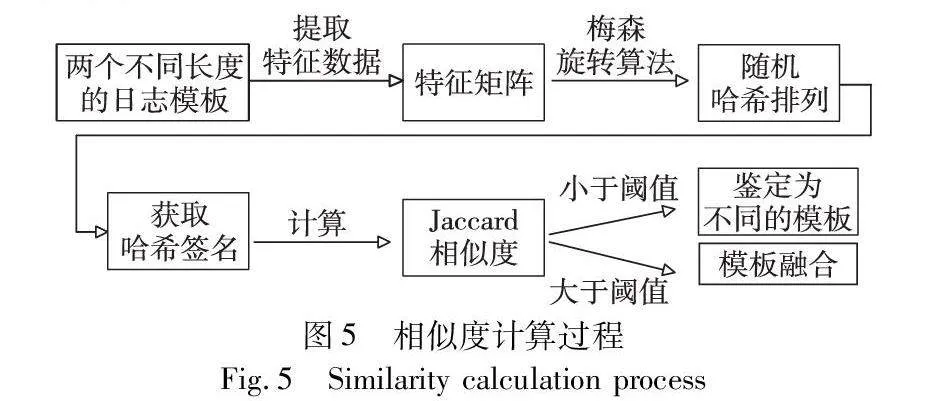
通常情况下,研究者通过迭代集合内的所有元素,以计算它们之间相同元素的数量,从而度量集合的相似性。然而,当处理大规模数据集时,特征空间的维度会急剧膨胀,这意味着计算每个元素之间的相似性将会变得非常耗时。为了应对这种情况,模型中提出应用MinHash模板合并方法,过程如图5所示。该方法用于判断不同长度的模板是否需要进行合并,并最终得到最优的模板。通过这种方式,该方法能够有效地减少特征空间的维度,从而加速相似性计算的过程。
MinHash是基于Jaccard指数相似度的一种算法:
Jaccard(A,B)=‖A∩B‖‖A∪B‖(2)
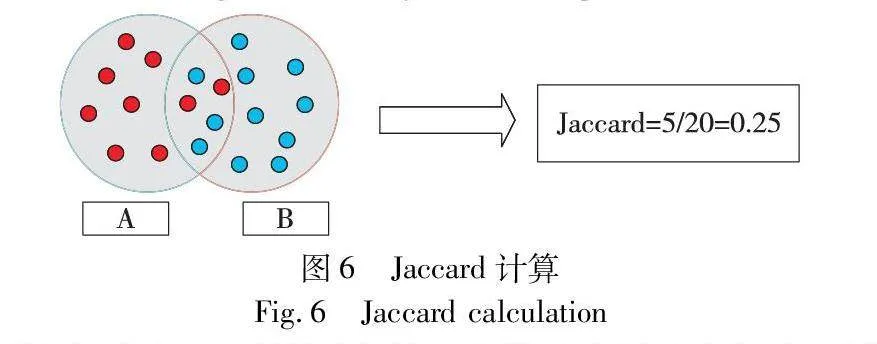
在Jaccard算法中,A和B为两个相交的集合,Jaccard相似度定义为:在集合A和B的并集区域上落在公共区的元素,如图6所示。
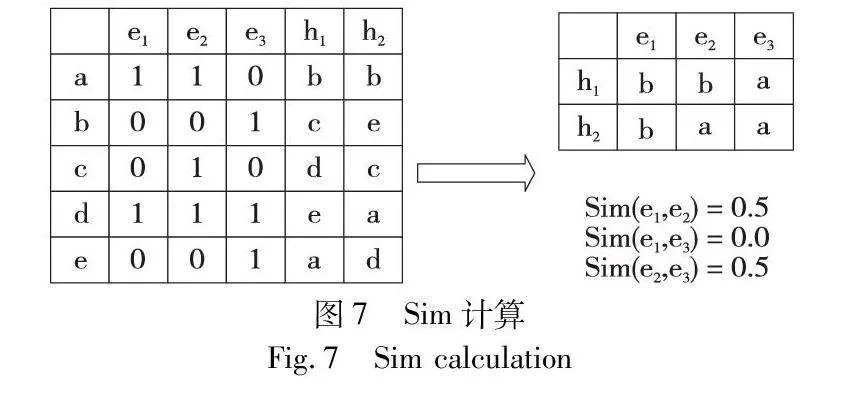
利用MinHash计算两个日志模板的相似度,可以按照以下步骤进行。首先对于每个日志模板,去除其中的无关信息,如时间戳、具体数值或字符串等,只保留日志模板中的关键词或变量部分。随后针对输入日志建立矩阵,为了完整地检索到日志的每一个字符,矩阵将覆盖所有的日志。例如,日志e1:ad;e2:acd;e3:bde,建立对应矩阵如图7所示,当然实际上的矩阵远远大于图示。
然后对每个日志模板的集合进行MinHash签名的计算,这里运用梅森旋转算法随机生成N-1组随机排列,并依次将集合中的每个关键词或变量应用于这些排列,得到对应的哈希值,取最小的哈希值作为该集合的MinHash签名。最后,对于给定的两个日志模板,分别获取它们的MinHash签名(图7)。比较这两个签名之间相等的哈希值数量,并除以总共哈希值的数量,得到一个近似的相似值。该方法将相似值与事先设定好的阈值进行比较来判断两模板是否相融。
2 实验
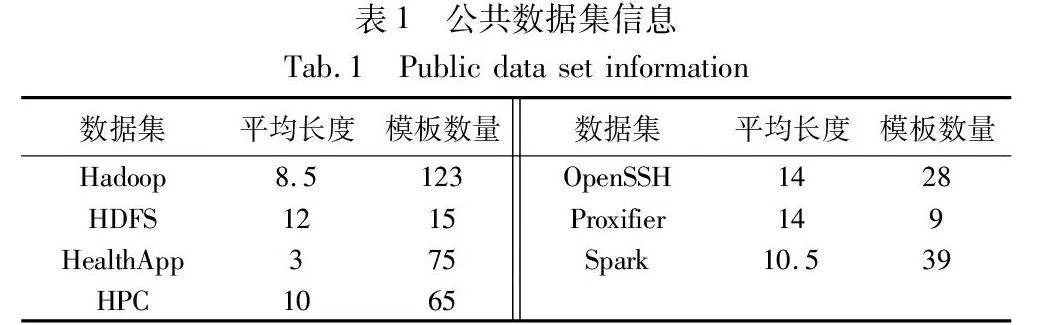
该模型在几个具有代表性的基准数据集[25]上进行了评估了工作, 表1给出了这些数据集的统计数据。
2.1 数据集
以下是部分数据集解释。
a)Hadoop:Hadoop日志数据集是由Hadoop集群生成的各种日志信息组成的集合,对于集群管理、性能优化、故障排除和系统分析都具有重要意义。
b)HDFS:HDFS日志数据集记录了Hadoop分布式文件系统中文件和元数据的操作、状态变化等信息。这些日志对于监视、故障排除、性能优化和数据分析都具有重要意义,可以帮助维护HDFS集群的健康状态和高效运行。
c)Spark:Spark日志数据集是指由Apache Spark生成的日志信息的集合。其中包含了关于Spark应用程序执行过程、性能指标、任务调度等方面的日志记录。
d)OpenSSH:OpenSSH 是一个开源的 SSH(Secure Shell)工具套件,它允许加密的远程登录、命令执行等。当使用 SSH 连接到服务器时,OpenSSH 会在服务器上生成日志数据。
2.2 基线方法
FMLogs会选取九种不同的解析方法作为基线比较,在本节中将主要介绍其中四种,它们将作为该模型研究的参考点。这些方法包括 Sepll、Drain、Brain[26]和 MoLFI等。Sepll采用了一种基于最长公共子序列的方法来解析系统事件日志。它具有动态提取日志模式的能力,并以流方式维护已发现的消息类型。此外,Sepll还提出了一种自动发现由拼写识别的参数字段语义的方法。Drain方法具备实时分析日志的能力。为了提高解析速度,Drain使用了一个固定深度的解析树,该树对专门设计的解析规则进行编码。此外,Drain在异常检测任务中,对日志分析有着优秀的结果。Brain方法是一种新的稳定日志解析方法,它根据最长的公共模式创建初始组,并利用双向树对常量字进行分层补全,有效地形成完整的日志模板。MoLFI方法将日志消息识别问题重新定义为一个多目标问题,它使用一种进化的方法来解决这个问题,通过剪裁 NSGA-Ⅱ算法来搜索帕累托最优消息模板集的解空间。
2.3 评价指标
异常检测作为一项二元任务,该方法使用聚类算法的典型评价指标F-measure[27,28]来评价日志解析方法的准确性。准确性的定义如下:
accuracy=TP+TNTP+FP+TN+FN(3)
precision和recall的定义如下:
precision=TPTP+FP(4)
recall=TPTP+FN(5)
F-measure是precision和recall的谐波平均值,定义如下:
F-measure=2×precision×recallprecision+recall(6)
其中:true positive(TP)表示若两个日志消息具有相同的日志事件,则分配到同一日志组;false positive(FP)表示若两个日志消息不具有相同的日志消息,但是分配到了同一日志组;false negative(FN)表示若两个日志消息具有相同的日志消息,但是分配到了不同日志组;true negative(TN)表示若两个日志消息具有不同的日志消息,而且分配到了不同日志组;precision表示实际异常在所有检测到的异常中所占的比例;recall表示检测到的真实异常的百分比。
2.4 实验设置
该算法在使用12 generation Core i7-12650H,6 GB RAM,RTX 3060 GDDR6 graphics card的Windows 11上运行所有的实验,使用Python 3.8实现日志解析。为了避免偏差,将每个实验进行10次取其平均。
2.5 精准性评价
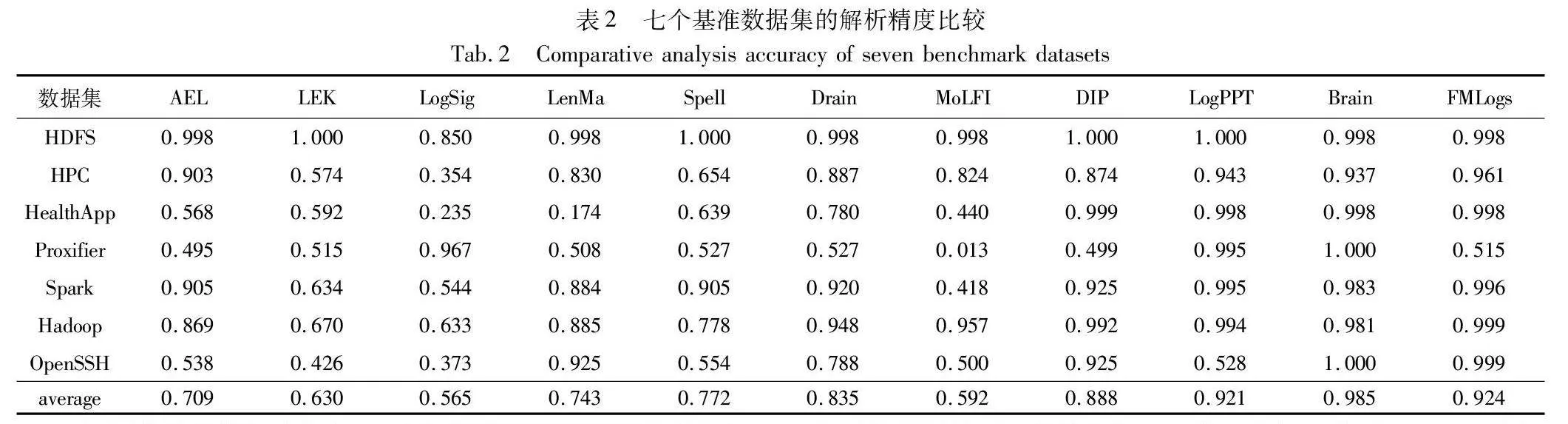
该算法按照LogPai提供的7个日志解析器代码的方式进行了提取,并在七个不同的基准数据集上评估了它们的性能,还与近年来优秀的方法DIP[29]、LogPPT[30]和Brain相比较。同时使用相同的方法对FMLogs进行了评估,得到了它在这九个数据集上的性能表现。表2汇总了这九个日志解析器在七个基准数据集上的性能评估结果。
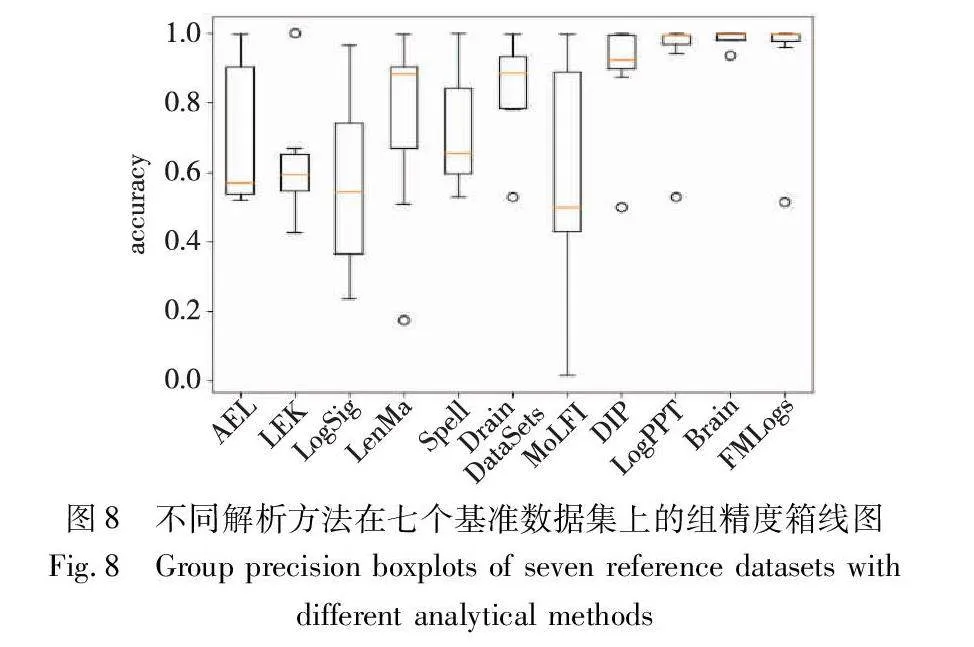
本节将深入分析和讨论日志解析方法FMLogs的实验结果,以及与其他常见方法的比较。该算法将关注不同数据集上的accuracy表现,并探讨其含义和重要性。首先,从表中可以明显看出FMLogs 在绝大部分的数据集上都表现出色,其accuracy分数都接近达到1.000。表明了FMLogs在各种不同领域的日志解析任务中都具有出色的准确性。在HealthApp数据集中,其余方法的accuracy普遍较低,而FMLogs则是达到了0.998。另一个值得注意的数据集是Proxifier,其中FMLogs在accuracy方面表现并不是那么出色,取得了0.515的分数,相比于其他方法的accuracy并不那么突出。经过实验数据分析,由于Proxifier数据集日志模板数量较少且为长尾分布,在融合模板时缺少某些模板,而导致属于此模板的大量日志的检测错误,从而致使精准度略微下降。但总体而言,FMLogs的平均accuracy为0.924,明显高于绝大部分方法的平均accuracy。这表明FMLogs在不同数据集和领域的日志解析中都具有出色的性能。由FMLogs在七个基准数据集的组精度箱线图(图8)可知,FMLogs的高准确性为用户提供了可靠的解析结果,有助于从日志数据中获取准确的信息和见解。
通过这些分析和讨论,得出了关于日志解析方法FMLogs的实验结果的重要结论:FMLogs具有广泛适用性,在多个数据集和领域的日志解析任务中都表现出色,具有高度准确的解析能力;其次,FMLogs性能相比其余方法较好,FMLogs的平均accuracy明显高于其他方法,用户可以依靠FMLogs来准确地解析日志数据。综上所述,FMLogs是一个强大的日志解析方法,具有卓越的准确性和适用性。然而,在实际应用中,仍需考虑数据集和需求的特定情况,以选择最适合的解析方法。
2.6 性能评价
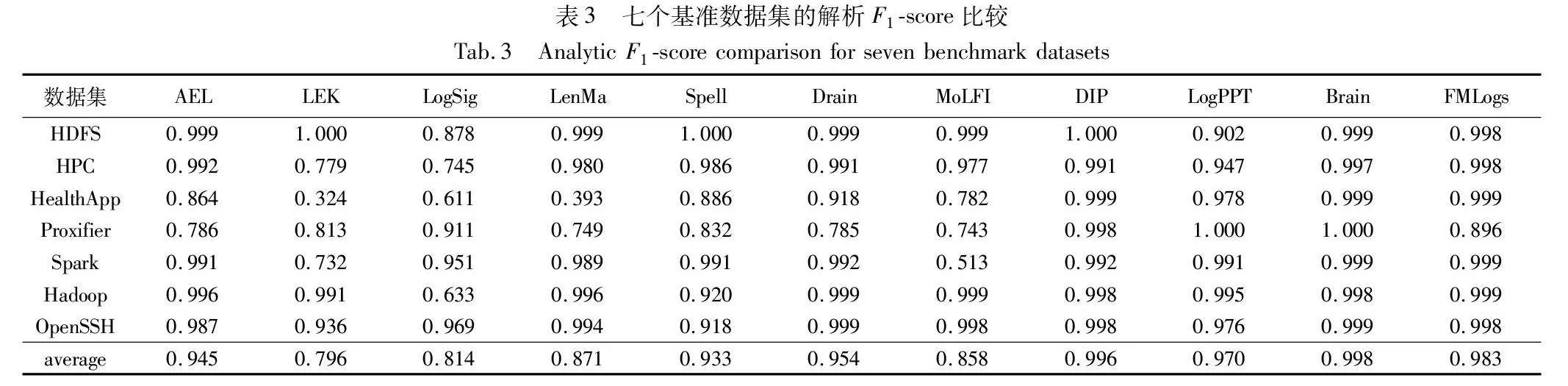
本节将讨论关于日志解析方法FMLogs的实验结果,并将其与其他常见的日志解析方法进行比较。该算法将专注于评估这些方法的性能,特别是使用F1-score来衡量它们在日志解析任务中的准确性和效果。在实验中,使用了一组日志数据集,并对不同的日志解析方法进行了评估,如表3所示。
首先可以看到,在这些日志解析方法中,DIP、Brain和FMLogs都取得了相当高的F1-score,分别为0.996、0.998和0.983,这表明它们在解析日志时表现出色,几乎完美地捕捉了所需信息。另一方面,LEK 和LogSig 的F1-score明显较低,分别为0.796和0.814,这可能是因为它们在解析日志时存在一些局限性,无法很好地应对复杂的日志数据。Drain和 AEL方法表现良好,分别达到了0.954和 0.945的F1-score,这表明它们在日志解析任务中具有很高的准确性。最后,LenMa、Spell、MoLFI和LogPPT方法的F1-score分别为0.871、0.933、0.858和0.970,它们在性能上表现良好,但相对于DIP、Brain和FMLogs方法,仍有改进的空间。综合来看,根据实验结果,日志解析方法FMLogs表现出色,达到了0.983的F1-score,几乎都能满足日志解析任务的需求。这意味着FMLogs是一个较为优秀的工具,适用于各种日志数据集和应用场景。但也需要注意,不同的数据集和需求可能导致性能不同,因此在实际应用中需要进一步评估和调整。总的来说,通过这些实验结果,得出了关于不同日志解析方法性能的重要见解,这有助于研究人员和从业者选择最适合其特定需求的解析方法。
2.7 阈值参数分析
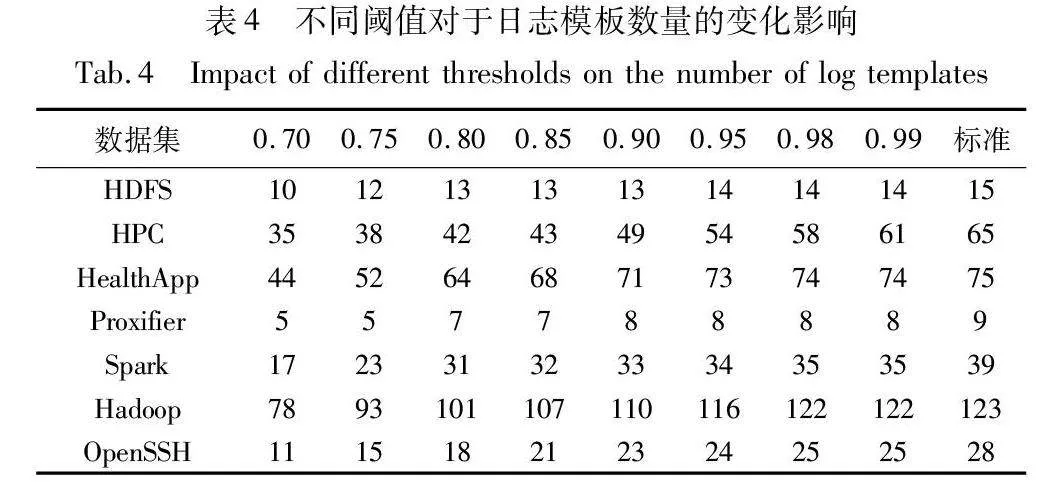
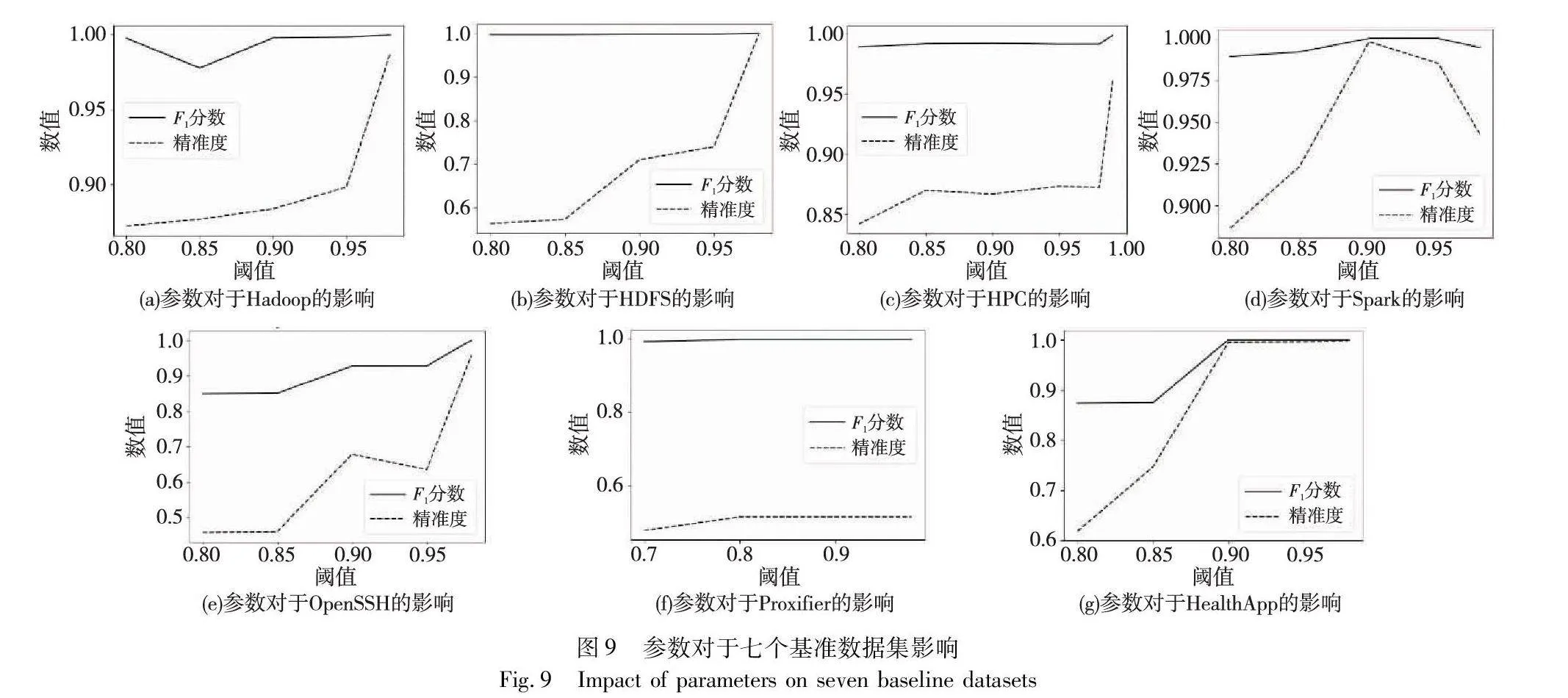
不同的阈值对于模板生成的精准度和F1-score有着一定的影响,如图9所示,可以得出一些结论。通过比较不同数据集在不同阈值下的性能表现,可以发现当阈值s大于0.90时,模板匹配的性能变得更加稳定。相反,当阈值s位于[0.7,0.85],FMLogs的性能较差,可能是由合并不同的模板导致的。这些发现对于数据集的分析和处理具有重要意义,可以根据不同的数据集选择合适的阈值来优化模板匹配的性能。例如,在处理Hadoop数据集时,选择较高的阈值(如s=0.98)可以获得更准确的结果,而在处理Spark数据集时,较高的阈值反而效果达不到最好。这种个性化的参数选择可以提高整体系统的性能和效率。另外,还注意到在HPC数据集上,阈值s从0.8一直增加到0.99,F1-score分数和精准度也在逐步提高。这表明在某些情况下,进一步增加阈值可能会带来更好的性能。然而,对于其他数据集,性能在某个特定的阈值达到最佳,并且进一步增加阈值可能导致性能下降。
表4具体给出了在不同阈值下模板数量的变化程度,在确定最佳参数后,可以将其应用于原始数据集以实现高效的模板匹配;同时通过图9对比可知,并不是模板数量越接近准确数量就越好,接近的同时可能会使相近但并不相同的日志划分到同一模板,从而造成精准度的下降。由此,通过对多个数据集进行实验和分析,得出了关于阈值选择对模板匹配性能的影响的一些重要结论,这些结论为实验提供了指导,以优化数据集处理过程中的模板匹配任务。同时,该方法还展示了如何根据不同数据集的特点选择合适的阈值,从而实现更好的性能和效果。
3 结束语
日志解析是实现日志异常检测的关键一步,为了克服现有解析器的局限性,提出了一种基于模板匹配的日志解析方法(FMLogs)。采用字符集频率统计和最小哈希算法对模板进行合并。在七个真实的基准日志数据集上评估和比较FMLogs与AEL、LEK、LogSig、LenMa、Spell、Drain、MoLFI和Brain的性能。评估结果表明,FMLogs在解析日志的同时具有较高的准确性和效率,并保证了稳定的性能。未来,在基于部署FMLogs的生产环境中,笔者会进一步评估其实践中的可扩展性和有效性,并专注于将FMLogs的结果用于其他自动日志分析,如异常检测、故障诊断。
参考文献:
[1]He Shilin, He Pinjia, Chen Zhuangbin, et al. A survey on automated log analysis for reliability engineering[J]. ACM Computing Surveys, 2021, 54(6): 1-37.
[2]Shang Weiyi . Log engineering: towards systematic log mining to support the development of ultra-large scale software systems[D]. Canada: Queen’s University, 2014.
[3]Le V H, Zhang Hongyu. Log-based anomaly detection without log parsing[C]//Proc of the 36th IEEE/ACM International Conference on Automated Software Engineering. Piscataway,NJ:IEEE Press, 2021: 492-504.
[4]Mi Haibo, Wang Huaimin, Zhou yangfan, et al. Toward fine-grained, unsupervised, scalable performance diagnoseS+AFHR8/8o8ckvzAocxw==sis for production cloud computing systems[J].IEEE Trans on Parallel and Distributed Systems, 2013, 24(6): 1245-1255.
[5]Ramati R, Reback G. A beginner’s guide to logstash grok[EB/OL]. https://logz.io/blog/logstash-grok.
[6]Vaarandi R, Blumbergs B, al瘙塂kan E. Simple event correlator best practices for creating scalable configurations[C]//Proc of IEEE International Multi-Disciplinary Conference on Cognitive Methods in Situation Awareness and Decision. Piscataway,NJ:IEEE Press, 2015: 96-100.
[7]Fu Qiang, Lou Guanglou, Wang Yi, et al. Execution anomaly detection in distributed systems through unstructured log analysis[C]//Proc of IEEE International Conference on Data Mining. Piscataway,NJ:IEEE Press, 2009:149-158.
[8]Hamooni H, Debnath B, Xu Jianwu, et al. LogMine: fast pattern recognition for log analytics[C]//Proc of the 25th ACM International Conference on Information and Knowledge Management. New York:ACM Press, 2016: 1573-1582.
[9]Du Min, Li Feifei. Spell: streaming parsing of system event logs[C]//Proc of the 16th IEEE International Conference on Data Mi-ning.Piscataway,NJ:IEEE Press, 2016:859-864.
[10]Duan Xiaoyu, Ying Shi, Cheng Hailong, et al. OILog: an online incremental log keyword extraction approach based on MDP-LSTM neural network[J]. Information Systems, 2021, 95:101618.
[11]Tang Liang, Li Tao, Perng C S. LogSig: generating system events from raw textual logs[C]//Proc of the 20th ACM International Conference on Information and Knowledge Management. New York:ACM Press, 2011:785-794.
[12]Jiang ZhenMing, Hassan A E, Flora P, et al. Abstracting execution logs to execution events for enterprise applications(short paper)[C]//Proc of the 8th International Conference on Quality Software.2008: 181-186.
[13]李修远,朱国胜,孙文和,等. WT-Parser:一种有效的在线日志解析方法[J].长江信息通信, 2023,36(5): 145-149.(Li Xiuyuan, Zhu Guosheng, Sun Wenhe, et al. WT-Parser: an effective online log parsing method[J].Changjiang Information & Communication, 2023,36(5):145-149.)
[14]Boyagane I, Katulanda O, Ranathunga S,et al. Vue4logs-automatic structuring of heterogeneous computer system logs[EB/OL]. (2022-02-14). https://arxiv.org/abs/2202.07504.
[15]Xiao Tong, Quan Zhe, Wang Zhijie, et al. LPV: a log parser based on vectorization for offline and online log parsing[C]//Proc of IEEE International Conference on Data Mining. Piscataway,NJ:IEEE Press, 2020:1346-1351.
[16]Zhang Shenglin, Meng Weibin, Bu Jiahao, et al. Syslog processing for switch failure diagnosis and prediction in datacenter networks[C]//Proc of the 25th IEEE/ACM International Symposium on Qua-lity of Service.2017: 1-10.
[17]Dai Hetong, Li Heng, Shang Weiyi, et al. Logram: efficient log parsing using n-gram dictionaries[EB/OL].(2020-01-07)[2023-12-04]. https://arxiv.org/abs/2001.03038.
[18]Bai Yu, Chi Yongwei, Zhao Danhao. PatCluster: a top-down log parsing method based on frequent words[J]. IEEE Access, 2023, 11:8275-8282.
[19]He Pinjia, Zhu Jieming, Zheng Zibin, et al. Drain: an online log parsing approach with fixed depth tree[C]//Proc of IEEE International Conference on Web Services. Piscataway,NJ:IEEE Press, 2017: 33-40.
[20]Makanju A A, Zincir-Heywood A N, Milios E E. Clustering event logs using iterative partitioning[C]//Proc of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM Press, 2009: 1255-1264.
[21]蒋金钊,傅媛媛,徐建.基于词性标注的启发式在线日志解析方法[J].计算机应用研究, 2024,41(1): 217-221. (Jiang Jinzhao, Fu Yuanyuan, Xu Jian. Heuristic online log parsing method based on part-of-speech tagging[J].Application Research of Computers, 2024,41(1): 217-221.)
[22]蒲嘉宸,王鹏,汪卫. ML-Parser:一种高效的在线日志解析方法[J].计算机应用与软件, 2022,39(1):45-52. (Pu Jiachen, Wang Peng, Wang Wei. ML-Parser: an efficient online log parsing method[J]. Computer Applications and Software, 2022,39(1):45-52.)
[23]葛志辉,邱晨,李陶深,等.一种提升细粒度日志解析准确度的方法[J].小型微型计算机系统, 2021,42(10): 2140-2144. (Ge Zhihui, Qiu Chen, Li Taoshen, et al. A method to improve the accuracy of fine-grained log analysis[J].Journal of Chinese Computer Systems, 2019,42(10):2140-2144.)
[24]Chu Guojun, Wang Jingyu, Qi Qi, et al. Prefix-Graph: a versatile log parsing approach merging prefix tree with probabilistic graph[C]//Proc of the 37th IEEE International Conference on Data Engineering. Piscataway,NJ:IEEE Press, 2021.
[25]Zhao Xiaoqing, Jiang Zhongyuan, Ma Jianfeng. A survey of deep anomaly detection for system logs[C]//Proc of IEEE International Joint Conference on Neural Networks. Piscataway,NJ:IEEE Press, 2022:1-8.
[26]Yu Siyu, He Pinjia, Chen Ningjiang, et al. Brain: log parsing with bidirectional parallel tree[J].IEEE Trans on Services Computing, 2023,16(5): 3224-3237.
[27]Manning C, Raghavan P, Schutze H. Introduction to information retrieval[M]. Cambridge: Cambridge University Press, 2008.
[28]Evaluation of clustering[EB/OL]. (2009-04-07)[2023-11-20] http://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html.
[29]Daniel P, Xie Mengjun. DIP: a log parser based on “disagreement index token” conditions[C]//Proc of ACM Southeast Conference. New York:ACM Press, 2022: 113-122.
[30]Le V H, Zhang Hongyu. Log parsing with prompt-based few-shot learning[C]/Proc of the 45th IEEE/ACM International Conference on Software Engineering. 2023:2438-2449.
