去中心化场景下的隐私保护联邦学习优化方法
2024-08-15侯泽超董建刚










摘 要:联邦学习的提出为跨数据孤岛的共同学习提供了新的解决方案,然而联邦节点的本地数据的非独立同分布(Non-IID)特性及中心化框架在参与方监管、追责能力和隐私保护手段上的缺失限制了其大规模应用。针对上述问题,提出了基于区块链的可信切片聚合策略(BBTSA)和联邦归因(FedAom)算法。FedAom引入归因思想,基于积分梯度法获取归因,从而定位影响模型决策行为的参数,分级考虑参数敏感性,在局部更新过程中保持和强化全局模型所学习到的关键知识,有效利用共享数据,从而缓解Non-IID问题。BBTSA基于区块链构建去中心化的联邦学习环境,允许联邦节点在无须中心化第三方的情况下,通过在参与方间交换噪声而非权重或梯度参数,基于合作树结构实现对参数的切片混淆,以保护节点隐私。在两种数据集上的不同分布条件下的验证结果显示,FedAom在大多数条件下相比基线方法在稳定性和收敛速度上都有显著提升。而BBTSA能够隐藏客户端的隐私参数,在不影响精度的情况下确保了训练过程的全程监控和隐私安全。
关键词:联邦学习; 区块链; 隐私保护; 非独立同分布; 积分梯度; 归因
中图分类号:TP181;TP309 文献标志码:A
文章编号:1001-3695(2024)08-024-2419-08
doi:10.19734/j.issn.1001-3695.2023.12.0611
Decentralized privacy-preserving optimization method for federated learning
Hou Zechao, Dong Jiangang
(College of Software, Xinjiang University, rümqi 830000, China)
Abstract:The advent of federated learning has unveiled a collaborative approach to learning across data islands, yet its scalability faces challenges from Non-IID local data at federated nodes and insufficient oversight, accountability, and privacy in centralized frameworks. To tackle these issues, this paper proposed a blockchain-based trustworthy slice aggregation(BBTSA) and federated attribution optimization method(FedAom). FedAom adopted attribution thinking, using the integrated gradients method for attribution to identify parameters influencing model decisions. It considered parameter sensitivity in a tiered app-roach, preserving and enhancing key knowledge learned by the global model during local updates. This effectively utilized shared data to mitigate the Non-IID problem. Concurrently, BBTSA employed blockchain to establish a decentralized framework, facilitating noise exchange between nodes instead of direct parameters, with a cooperative tree structure for obfuscation to boost privacy. Validation on diverse distributions across two datasets indicates FedAom notably improves stability and convergence speed over baseline methods in most instances. Simultaneously, BBTSA ensures client privacy without compromising model accuracy, guaranteeing training oversight and privacy protection.
Key words:federated learning; blockchain; privacy protection; Non-IID; integral gradient; attribution
0 引言
近些年来,人工智能技术的快速发展为传统行业注入了新的活力,而这一切都离不开海量数据的驱动[1]。传统的机器学习依赖于集中式的中央服务器,数据以明文的方式传输至服务器并参与训练。此种方式存在两种矛盾:a)数据来源于物流、医疗、卫星等边缘设备,这类数据往往包含如位置信息、健康数据以及涉及国家机密的地形地貌信息等,持有者不愿共享给中央服务器。如多个医疗机构计划开发一套人工智能系统辅助疾病诊断,然而,各机构持有的病历数量难以满足高质量模型的训练需求,而病历的所有权由患者持有,医院在未获得授权的情况下无法共享使用。b)受限于带宽与计算资源等因素,集中式的训练对服务器的硬件要求较大,并且在不受信任的信道中传输数据存在风险[2]。联邦学习[3]是一种由谷歌于2017年提出的可实现数据隐私保护且支持将训练分散到多台设备上的分布式机器学习技术,通过传递梯度(或者参数)而不是隐私数据使得多个参与方可以协作训练一个全局模型。一般来说,联邦学习服务器利用联合平均算法(federated averaging,FedAvg)聚合多个设备的本地模型参数,来更新全局模型。
若数据在参与方中的分布满足独立同分布(independent and identically distributed,IID)条件时,FedAvg可以达到与集中式学习等效的性能[4],但现实中数据分布往往是非独立同分布(non-independent and identically distributed,Non-IID)的,例如,医院A及B专长于不同的疾病,或者使用的医疗设备型号不同使得样本存在差异。研究者发现Non-IID的训练数据会阻碍FedAvg的收敛速度,甚至无法收敛[5],这是因为数据的异质性会导致客户端模型发生漂移[6]。如图1所示,客户端倾向于优化一个适合本地数据分布的解,使得模型陷入局部最优。此类问题的一个解决思路是构建一个所有节点共享的数据集[7],将其混入客户端的私有数据中参与训练或者由服务器对模型进行微调,这种方法对共享数据的利用效率较低。有研究[8, 9]通过对参数更新的限制来缓解模型漂移现象,然而,受限于深度神经网络(DNN)的权重排列不变性[10],同一权重在不同的任务中所表达的语义信息可能存在差异,如何从更具解释性的角度定位并优化导致漂移现象的参数,具有重要的现实意义。
即使参与方的真实数据不需要离开本地,依然可以利用梯度或模型参数还原出相应的隐私数据,防止此类攻击的常用方法有差分隐私、同态加密、梯度裁剪等,然而这些方法在保护节点隐私的同时也带来了新的挑战。此外,拜占庭节点的存在会对系统的稳定性和安全性形成威胁。
区块链凭借其去中心化、不可否认性、可追溯性等特点,能够满足溯源与追责的需求,星际文件系统(IPFS)可在保障去中心化特性的同时缓解账本的存储压力[11]。
文献[12]展示了归因在引导网络学习上的潜力,其基于积分梯度(integrated grad,IG)[13]与先验框对网络的学习行为进行引导,获得了较好的效果。受此启发,本文提出了一种归因优化方法(attribution optimization method,AOM),并实现了FedAom算法。FedAom引入归因的思想来描述网络的行为,旨在深入找到模型决策行为背后的决定性特征,即“模型作出判断的原因”。FedAom的目标在于保持模型在局部迭代过程中的决策行为与全局模型一致。同时借助数据共享的思路,引入小批量共享数据作为计算模型归因的载体。FedAom在优化过程中加入对决策敏感参数的考量,有效利用共享数据的知识,从而缓解联邦学习环境中的Non-IID问题。另外还设计了一种基于区块链的可信切片聚合策略(blockchain-based trustworthy slice aggregation,BBTSA),参与方无须透露任何与参数相关的信息,基于合作树结构的混淆过程可避免向所有节点广播消息产生的高昂带宽成本,通过合作混淆来破坏模型与参与方的训练样本之间的对应关系,实现了参数的完全匿名性。最终,融合上述两个方案,可以在提高模型准确度的同时实现对客户端的隐私保护,避免了中心化方案可能导致的隐私泄露问题,确保了对训练过程的全程监控。本文的主要贡献如下:
a)设计了一种可信切片聚合策略,在客户端之间传输可抵消的随机噪声而非参数,保护了客户端的隐私且不影响模型精度。基于区块链技术构建了一个去中心化的服务,结合可验证随机函数(verifiable random function,VRF),使客户端成为混淆过程的主导者。通过智能合约(smart contract,SC)实现对客户端身份及合作过程的自动验证与处理,保证训练以及合作过程可信透明。借助IPFS与本文设计的合作树结构可降低链节点的存储压力与带宽成本,提高效率。
b)提出了一种适用于Non-IID数据的归因优化方法。仅利用极少量的共享数据来计算归因,作为模型对全局数据决策敏感性的度量指标。归因方法能够更为准确地描述神经网络对输入特征作出的反应,分级对待模型在训练过程中不同层敏感参数的更新行为,对客户端的模型漂移进行修正,有效地缓解了联邦学习环境中的Non-IID问题。
c)通过实验来评估本文方案,结果表明所提方法在不同的Non-IID数据上的正确率及收敛速度都有所提高。切片聚合策略能有效地实现模型参数的匿名性,且不影响精度。
1 背景知识
1.1 联邦学习
假设联邦学习共有K个参与节点,节点ki的本地私有数据集记为di∈D,di={(xij,yij)}nij=1,其中i∈{0,1,2,…,K},ni表示节点ki的样本数量,D={di}Ki=1则是系统中所有参与节点的数据总和。在第t轮通信中,节点ki利用私有数据di训练一个本地模型θti,ki的目标是最小化本地损失Euclid Math OneLApti:
arg minwti 1ni∑nij=1Euclid Math OneLApti(xij,yij,wti)(1)
联邦学习总目标是通过聚合客户端的wi,获得一个可以使全局损失最小化的模型参数w*global:
arg minw*global1K∑Ki=1Euclid Math OneLApti=1N∑Ki=1∑nij=1Euclid Math OneLApti(xij,yij,wti)(2)
1.2 联邦学习面临的隐私及异构性问题
即使仅共享模型的参数信息,联邦学习的应用依然需要考虑隐私推理攻击、好奇的参与方和中心化的风险。已有研究者展示了深度梯度泄露、模型逆向与成员推理攻击[14]如何威胁节点隐私安全。Zhang等人[15]提出一种基于生成式对抗网络(generative adversarial network,GAN)的隐私推理攻击方案,从公共信息上学习先验,实现了高质量推理,且基于差分隐私的一般性防御方案难以阻止攻击。在此基础上,Chen等人[16]充分利用了被攻击模型的知识,实现了对训练数据的细粒度重构,进一步提升了攻击效果。
研究者在医疗物联网引入同态加密技术[17],对手无法利用加密后的模型密文推断私人医疗数据,并且可以确保服务器能获得最终的聚合参数,但同态运算会带来较大的计算负担,并且具有中心化的风险。曹世翔等人[18]借助中心化的洗牌机混淆梯度并采用差分隐私增强安全性,牺牲了一定精度,但缺乏对节点身份进行验证的手段。
区块链本质上是一种去中心化的账本,利用共识算法确保账本一致性。通过哈希指针连接成链,保障数据安全和不变性。有研究者[19]结合区块链设计了一种委员会共识方案,由委员会节点对局部模型进行打分,矿工根据评分聚合模型,同时账本将记录非委员会成员的行为,但数据异质可能会影响评分的公正性,并且此过程中需要传输一定的参数。刘炜等人[20]研究了在去中心化环境下保护参与方的隐私参数,结合多种技术进一步提高了系统安全性。Guduri等人[21]设计了一种轻量级联邦学习架构,通过智能合约实现代理重加密。Madni等人[22]引入区块链作为节点身份的验证方,通过点对点的方式自主完成梯度聚合,但参数依然以明文的方式在网络中传输,存在被截取的风险。上述隐私保护方案对比情况如表1所示。
区块链的一个显著优势是允许不受信任的实体在无须依赖集中性的第三方机构的条件下进行可信交互,现有研究未能充分利用这一点,本文基于区块链的此种特性充分调度dh2Z35XV7fLt5GH7nXjHMQ==参与方的主动能力及资源,各参与方在不暴露真实参数的情况下,借助区块链与邻居进行参数混淆,以提升整体的安全性。
由于跨客户端的数据异构性,本地模型偏向于拟合客户端的本地分布,这就导致了模型的漂移。Zhao等人[23]观察到模型权重散度与数据异构度呈正相关,在Non-IID条件下,Fed-Avg算法出现了明显的退化,5%的共享IID数据可显著提升精度,但提供5%的隐私数据对参与方是难以接受的。李志鹏等人[24]提出一种借助全局模型学习到的知识来重构Non-IID数据的方法,生成虚拟数据解决类别不均衡问题,但增加了计算负担。常黎明等人[25]提出一种个性化联邦学习方法,通过deep sets在特征维度上对客户端进行组合,同组客户端将共同训练一个个性化的模型,降低了Non-IID带来的影响。
另有研究者通过正则化本地优化过程,从而修正客户端模型的漂移。Li等人[8]提出联合近端(federated proximal,FedProx)算法,允许客户端执行不同次数的本地更新,通过加入一个近端项,迫使模型更新不会偏离全局模型太远,有效地缓解了联邦学习中数据异构及系统异构的问题。联邦模型对比学习(model-contrastive federated learning,MOON)[26]从模型的表示能力入手,最小化局部模型与全局模型表示能力之间的差异,从而纠正局部训练。Shoham等人[9]将模型漂移看作是终身学习中的知识遗忘问题,提出了联邦曲率(federated curvature,FedCurv)算法,利用Fisher信息矩阵保留对旧任务贡献较大的参数,寻找任务的普适解。FedProx与FedCurv等从权重的角度限制局部更新,有一定的局限性,这影响了模型在多任务学习环境下的能力。
1.3 归因方法
归因方法的目的在于评估输入特征对预测结果的影响,最初用于解释神经网络的预测行为,但近期的研究已经开始探索其在约束和指导模型的学习过程中的能力[12,27]。传统方案仅从权重的角度对偏离行为进行正则化,忽略了权重真实的语义信息。本文基于归因的思想,定位到在对本地分布外样本的预测中表现出更高敏感性的参数,并分级引导wi的更新。一般认为,具有较大梯度的特征值相应的重要性也越大,Shrikumar等人[28]通过将输出偏导数与输入特征相乘,生成锐化的归因图,以揭示特征的重要性和在预测中的强度,本文以G·I指代上述方法。
模型可视为特征提取器m与分类器c的组合,即θi=(m,c)。为更合理地获得对模型的归因行为,基于积分梯度法构建一条连接基线x′与输入x之间的路径,将梯度的路径积分Λ视为G·I中的导数项G,公式为
Λ::=Δx∫1σ=0c(m(x′+σ×Δx))x′dσΔx=x-x′(3)
其中:Λ中的元素αls,i,j指代模型第l层的第s个神经节点中各参数对本层输入的归因敏感度,为简单起见,在无特殊说明的情况下,用αls代而表示;σ为路径的控制变量,本文中σ是一个标量且σ∈[0,1]。利用线性插值法构建x′至x的直线路径γ(σ):
γ(σ)=x′+σ×Δx(4)
其中:Δx=x-x′,沿路径γ(σ)计算路径积分,式(3)可重新修改为
Λpath_γ(σ)=∫1σ=0c(m(γ(σ)))γ(σ)·γ(σ)σdσ(5)
本质上,x与对应的特征图具有相似的构造,故本文的路径构建在特征图与基线之间,且选择黑色图片作为x′。鉴于DNN模型的复杂性,对式(5)进行计算存在困难,利用黎曼积分近似求解会引入过多的噪声[29],缓解此问题的另一个简单有效的方案是通过梯形求和近似积分,将Δx均匀分割成q个小段,q∈Euclid ExtraeBp,沿γ(σ)采样路径点,基于式(5)使用梯形法近似计算αls:
Ll-1s,i,j2qε∑qρ=1cy(m(x′+(ρ-1)Δxq))+cy(m(x′+ρΔxq))Ll-1s,i,j
Ll-1s,i,j=L((x′+ρΔxq)l-1s,i,j,wsl)(6)
以卷积层为例,cy(m(x))指的是模型将输入x预测为真实类别y的置信度,wsl为模型第l层的第s个卷积核的参数,L表示卷积操作,Ll-1s,i,j表示当网络输入为x′+ρΔxq时,对l-1层输出的第s个特征子图与参数wsl执行卷积操作。为避免权重过大,使用ε对值进行平衡。基于式(6)近似计算得到的Λ即可反映出模型对类别y的决策焦点。
2 基于区块链的可信分片聚合FedAom设计与实现
2.1 联邦归因(FedAom)算法
为缓解Non-IID数据带来的客户端漂移现象,本文提出了FedAom算法,通过约束局部模型的决策行为以保持和强化全局模型所学习到的关键知识。由于特征是由隐藏层产生的,其受隐藏层的输入以及参数共同影响,而在Non-IID的情况下,不同参与方的样本分布差异较大,使得输入成为一个变量,这让确定关键特征变得更加复杂。因此,本文采用了基于共享数据的策略,收集小批量的共享数据作为计算归因的载体,当输入被固定为从这批共享数据中随机抽取时,归因结果能够更准确地反映出参数在全局数据预测阶段中的敏感性。这种方式有效地将归因的优化转换成了对敏感参数的优化问题。由此,FedAom仅需极少量共享数据计算归因,再利用归因引导优化过程,便可在模型训练中间接进行知识回放,实现对共享数据包含的本地分布外知识的合理利用,从而减少了对数据量的依赖性。FedAom的优化目标同式(2),只是额外引入了输入敏感性损失项Euclid Math OneLApt,ei,IS:
Euclid Math OneLApt,ei,IS=‖∪lnuml=1(L(xi,0,l-1,wi,0,l)Λ^0,lt-L(xi,e,l-1,wi,e,l)Λ^e,lt)‖2(7)
其中:Euclid Math OneLApt,ei,IS表示在第t轮全局通信中ki在本地训练的第e轮epoch的输入敏感性损失,e∈{1,2,…,E},E为节点本地训练的总轮数;L(·)表示将L的输出拉平后的向量;lnum为模型的层数;Λ的每一个元素按顺序作为Λ^e,lt的对角线元素;Λ^e,lt为第t轮的第e次迭代时模型第l层的归因敏感性矩阵。式(8)利用矩阵运算,为重要的特征施加更大的权重,确保对那些关键特征更敏感的参数在更新时受到更多的关注,对这类特征相关的模型参数的更新将产生更大的损失,借此引导模型的学习过程。Λ^e,lt的形式如下:
Λ^e,lt=A100…0
As…000…Aυ(8)
其中:Λ^e,lt是一个具有分块对角结构的矩阵,其中每个块As也是一个对角矩阵。在卷积层,As是一个δ×δ的矩阵,υ与δ分别表示第l层卷积核的数量以及每个通道所含元素的个数。而在全连接层,As是一个标量矩阵,即δ=1,υ则表示全连接层的节点数。以卷积层为例,对应于卷积核s的As表示如下:
AS=α1,1…00…αδ,δ(9)
其中:α是反映模型对输入的敏感程度的权值。当图片比较复杂时,υ与δ的值可能会很大,而Λ^e,lt是一个稀疏矩阵,直接存储Λ^e,lt的空间效率较低,为在不过多丢失对输入敏感性的前提下进一步降低复杂性,对式(6)得到的每个卷积核的归因敏感度αls求均值代替子块As中的元素:
αi,i=1δαls s.t. i∈{1,…,δ}(10)
基于以上方式,模型可以在优化过程中注意到参数与输入之间的潜在联系,对于那些在处理本地外分布输入x时表现出较高敏感性的模型参数,施加更大的惩罚来约束它们的变化,这不仅能更准确地保留关键信息,而且还能在训练过程中有效地避免对不重要信息的过度拟合。FedAom的客户端损失函数为
Euclid Math OneLApi=Euclid Math OneLApi,CE+(β-et/T-1e-1)Euclid Math OneLApi,IS(11)
其中:Euclid Math OneLApi,CE是交叉熵损失函数,此项可引导模型最小化预测值与真实值之间的差异;β为调整优化行为的超参数;T为全局通信的总轮数;Euclid Math OneLApi,IS的系数β-et/T-1e-1将伴随着训练进度减小,使模型在开始的频繁波动期注重于全局知识的保留。
2.2 基于区块链的联邦节点合作方案
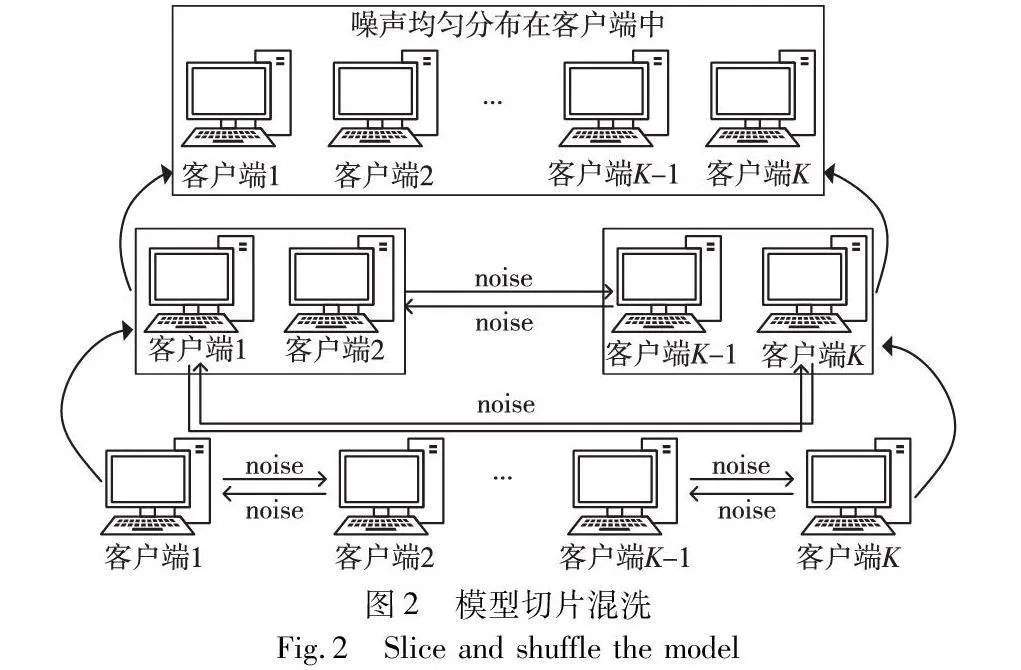
切片聚合策略的目标是切断模型输出概率分布同输入之间的相关性,图2展示了整体流程。参与方之间以层为单位进行切片的交换,引入区块链作为中间方对训练与合作行为进行监督,区块链的存在为联邦节点的交互创造了一个可信的环境,只有经过认证的节点才能参与到合作过程中,且过程透明可审计。BBTSA充分利用这一特性,为联邦节点的可信合作提供保障。然而,即使仅交换模型的部分参数,若双方持有的样本分布相似性较高,恶意的邻居可以借助模型的微调恢复出其余参数。为避免此类攻击,本文的参与方仅需向邻居传送随机噪声,真实参数依然保留在本地,并基于此目的设计了可抵消随机噪声策略,客户端之间无法获取到对方的参数来推断隐私,同时联邦学习服务器仅能访问到混淆之后的参数,避免了好奇的服务器导致的隐私泄露问题。为进一步确保去中心化的特性,联邦节点需同多个邻居进行合作,参与合作的节点需要基于VRF计算随机数及证明,作为参与方的身份声明,区块链将根据账本中的记录与节点上传的可验证随机数构建合作树结构,节点仅需与合作树中每层的邻居建立一次通信,即可将通信建立次数降低到对数级,减小带宽压力。这个过程中,合作双方需要根据双方的样本比值对噪声进行加权,以保证在聚合阶段噪声可以被正确抵消。
以一次合作混淆过程为例,假设本轮参与混淆的节点为ka与kb,a≠b且a,b∈(0,K)。需要交换的层为ltargeta,b={li} κ×lnum」i=1,κ为比例系数, κ×lnum」表示计算参与混淆的目标层的个数并向下取整。首先,ka与kb以各自在本轮中生成的随机数作为种子,从一个标准正态分布中随机采样一个与ltargeta,b具有相同的结构的噪声noisea与noiseb,ka与kb计算各自的参数与噪声之差并保存于本地:
ltargeta=ltargeta-noisea,ltargetb=ltargetb-noiseb(12)
双方根据各自的数据量对噪声进行放缩之后,与对方建立通信并发送结果,实现了隐私参数不动而噪声动的目的。参与方无法从收到的信息中破译出任何有用信息。收到响应之后,双方利用噪声更新本地模型参数:
ltargeta=ltargeta+nbnanoiseb,ltargetb=ltargetb+nanbnoisea(13)
参与方根据合作树结构与每个邻居执行以上步骤,最终获得的模型即为混淆后的模型。服务器接收到的参数是不同参与方的噪声聚集体,从而无法获取到任何有关节点隐私的信息。服务器按照经典的样本比例作为权重对参与方的参数进行聚合,获得最终的全局模型。按照以上通信协议聚合得到的参数中,所有的噪声之和为0,可实现在不影响模型精度的同时保证参与方的隐私安全。
根据二项式定理,本文令κ为1/2,这有利于噪声在每个节点中均匀分布。算法1展示了合作树结构的构建流程。
算法1 基于区块链的联邦节点合作树构建
输入:椭圆曲线Curv;基点G;哈希函数hash(·);随机数random_number;证明proof。
输出:第T轮节点合作树tree。
for ki∈K parallel do //所有节点注册身份信息
随机选择一个整数d∈(1,n-1) //n为G的阶
(ski,pki)←generateKey(Curv,d,G)
registerOnBC(pki) //注册上链
end for
getTreeFromBC(random_number,proof)
if verifyRN&P(random_number,proof) /*验证随机数以及节点身份 */
tree←sort(random_number) //排列节点
end if
return tree
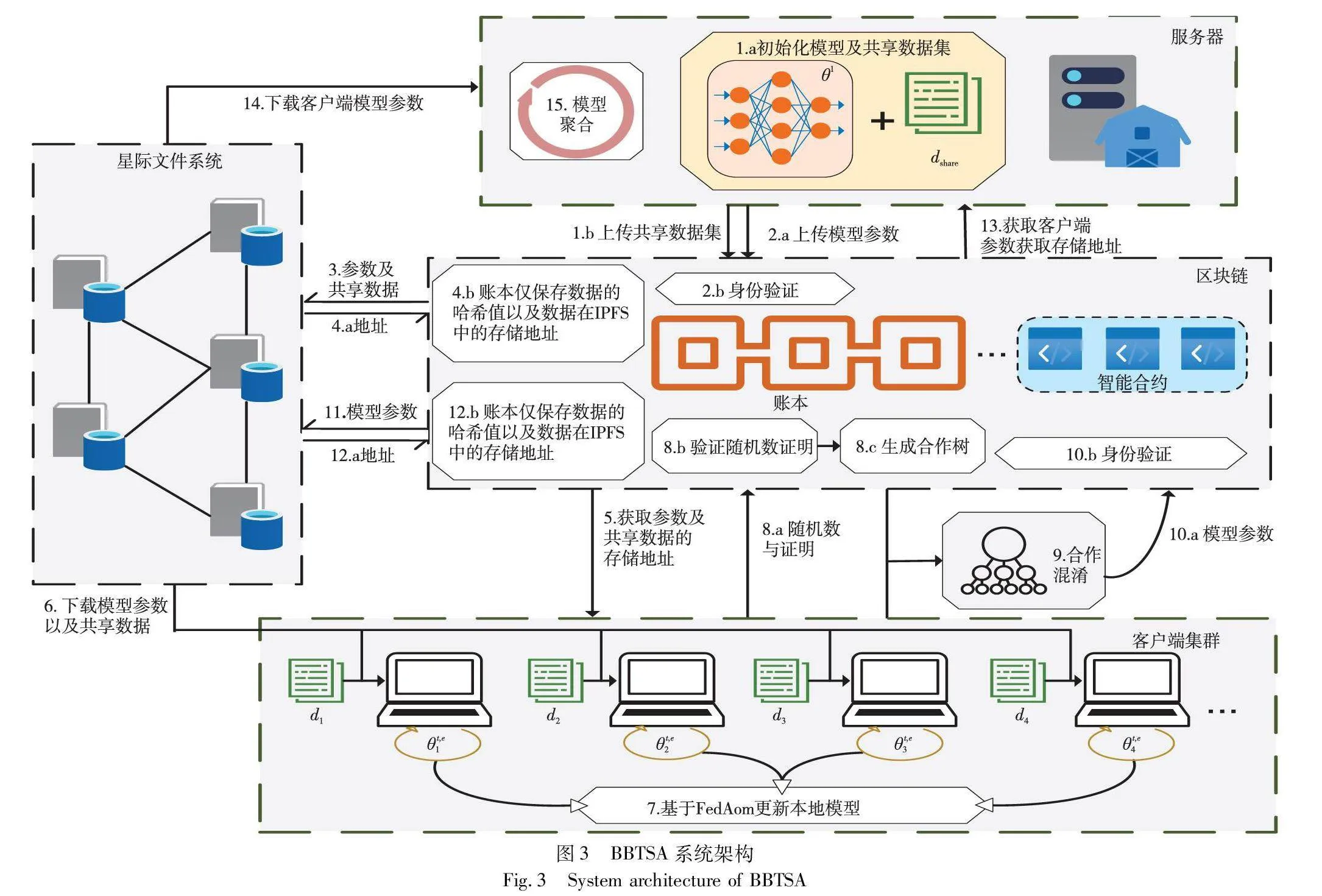
3 系统架构
如图3所示,在BBTSA策略中包含联邦学习服务器、联邦学习参与方和区块链服务三个核心角色。它们之间的特定交互机制形成了BBTSA策略的运行框架。
a)联邦学习服务器(FLServer)。FLServer在BBTSA中扮演着任务管理者的角色,其不仅收集和维护共享数据集,还负责验证来自各参与方的参数更新,并进行聚合以形成全局模型。另外还需要将聚合后的模型参数打包上链,利用区块链技术确保训练过程的不可窜改性和可审计性。
b)联邦学习参与方(client)。client承担着数据提供者和模型训练者的双重角色。参与方借助区块链和IPFS获取本轮全局模型,并基于dshare与FedAom在本地环境中进行训练。同时需要参与合作混淆以实现参数匿名化。这个过程中参与方不仅贡献了自己的数据和计算资源,还充分发挥了本身的主动能力,增强了整体的隐私性。
c)区块链服务(block chain)。区块链服务是BBTSA策略中的信任基础。链节点通过Raft共识协议以及gossip协议以维护一个去中心化的账本,区块链不仅负责验证参与方的身份,协助节点完成混淆,还通过IPFS技术缓解链的存储压力,为模型的混淆过程提供了必要的基础设施支持。
系统中各实体包含以下行为:
a)参与实体使用椭圆曲线算法生成密钥对(SKi,PKi),并将公钥以十六进制字符串的形式交由block chain注册身份,私钥则以安全的方式保存在本地。b)FLServer从部分志愿节点中收集一小部分数据组建全局共享数据集dshare用于计算Λ。
c)FLServer初始化模型θ1并计算模型哈希并与θ1一起上传到block chain。
d)block chain接收模型并验证哈希值,之后将数据存储到IPFS中,并记录存储地址。
e)client从链上查询本轮参数的存储地址后从IPFS中下载模型及dshare,计算哈希值并与账本记录进行对比判断是否被窜改。验证通过后使用本地数据di进行训练。之后计算随机数及证明并向block chain发起请求,并进入等待合作的状态。
f)block chain收集client的请求并验证身份,对合法的client构建合作树tree,记录本次合作并将tree发送给client。
g)client按照tree与合作者建立安全信道并进行切片交换,获得混淆后的模型t,E+1i,计算哈希并记录上链。
h)FLServer根据账本记录获取本轮采样的Ksamp个客户端的混淆模型{t,E+1i}|Ksamp|i=1并检查哈希值,为对合法的参数进行聚合并开启下一轮通信,直至达到设定好的停止条件。
算法2 基于区块链的可信分片聚合FedAom算法
输入:通信总轮数T;局部训练次数E;参与方个数K;客户端采样率r;参与方本地数据集di∈D;本轮参与方的样本总量N;共享数据dshare;目标层比例γ;批量大小B;学习率η;超参数β;动量momentum;学习率衰减ld;权重衰减wd。
输出:第T轮全局模型θT。
初始化全局模型θ1 // 服务器端执行
for t=1 to T do
根据r随机选取客户端Ksamp={k1,k2,…,k r×K」}
for ki∈Ksamp parallel do
下载全局模型θt
for e=1 to E do
θt,e+1i←clientUpdate(di,dshare,θt,ei,η)
end for
uploadToBC(hash(θt,E+1i),θt,E+1i,t) // 记录上链
end for
{t,E+1i}|Ksamp|i=1←sliceAggregation(Ksamp,θt,E+1i,γ)
θt+1=∑|Ksamp|i=1niNt,E+1i //获得下一轮模型m)end for
return θT
clientUpdate(di,dshare,θt,ei,η)
for b=(x+y)∈di in B do
θt,e+1i←根据式(1)(11)本地更新(β,momentum,ld,wd)
end for
return(θt,e+1i)
sliceAggregation(Ksamp,θt,E+1i,γ) //切片聚合
for ki∈Ksamp parallel do
(random_number,proof)←生成随机数与证明(θt,ski)
tree←getTreeFromBC(random_number,proof)
{t,E+1i}|Ksamp|i=1←参与方间切片聚合(tree,θt,E+1i,γ)
end for
return{t,E+1i}|Ksamp|i=1
4 实验结果与分析
4.1 数据集
CIFAR-10物体识别数据集因其涵盖类别的普遍性以及适中的尺寸,成为物体识别领域广泛使用的标准数据集之一。MNIST手写体识别数据集的样本具有较好的一致性,常常作为检验算法的首选。两者在本文的基线方法中也作为重合度最高的数据集出现,为确保实验结果的公平性和可比性,选用MNIST和CIFAR-10作为验证数据集。
a)CIFAR-10是一个包含60 000张尺寸为32×32的彩色图片的物体识别数据集,其中又可以分为包含50 000张图片的训练集和10 000张的测试集。CIFAR-10共有十个类,包括交通工具和动物等物体,不同类的样本分布较均匀。
b)MNIST是一个涵盖十个类别(0~9)的手写数字图片数据集。它包含60 000个训练样本和10 000个测试样本,每个样本都是尺寸为28×28的单通道图片。
为增强模型的鲁棒性,本文还对训练集进行了数据增强操作,包括随机裁剪、水平翻转和随机遮挡。增强结果如图4所示,图(a)(b)分别代表原始样本与经过增强操作后的样本。
4.2 实验设置
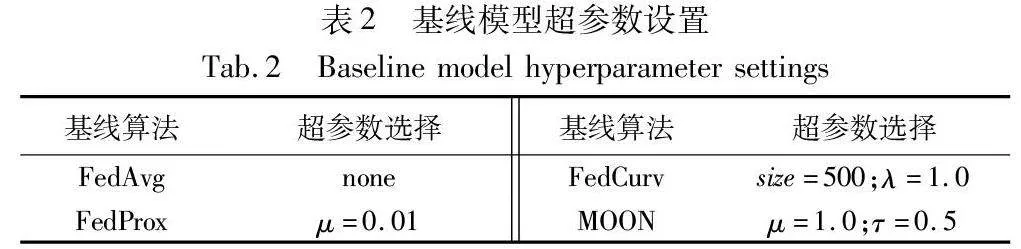
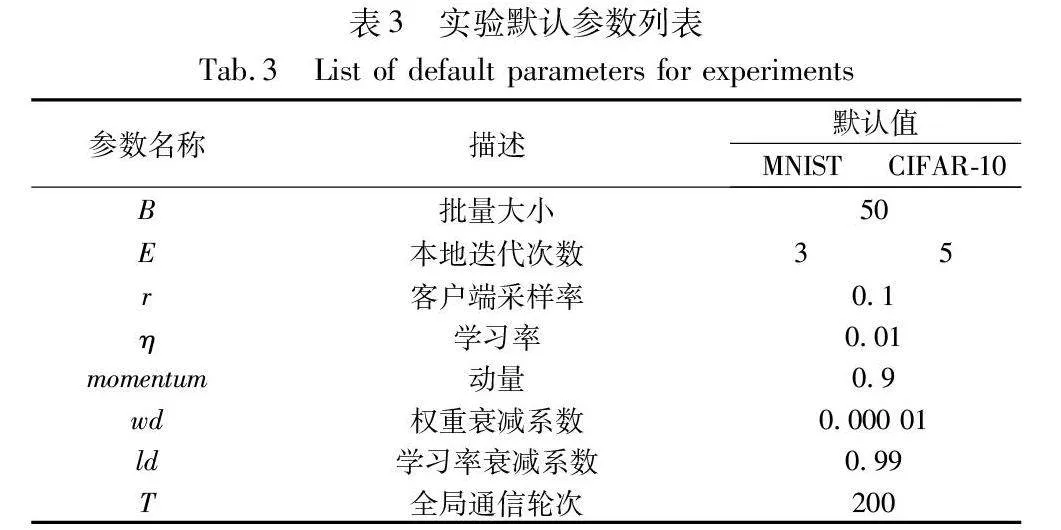
本实验选用Python 3.8作为编程语言,基于PyTorch 1.11+CUDA 11.3在PyCharm 2021中完成编码,实验宿主机配置为Intel Xeon Platinum 8255C与NVIDIA RTX 3080 10 GB,操作系统为Ubuntu 20.04。同时基于Hyperledger Fabric 2.2构建了一个联盟链环境,链码使用Go语言编写,客户端与链码的交互通过fabric-sdk-go工具实现。实验模拟了由100个client参与的联邦学习系统,并选用FedAvg[3]、FedProx[8]、FedCurv[9]与MOON[26]算法作为对比基线。基线模型的超参数遵照原文设置。每种算法的超参数选择展示在表2中。
FedAom的参数β与ε分别取1.0和7.0,损失项系数控制损失项的介入慢慢变小。本文从每类训练数据中随机抽取5个样本组建dshare。对于CIFAR-10来说,dshare的尺寸仅为全局数据的0.1%。其他未指定参数默认设置为表3中的值。
为了确保公平性,FedAom与基线算法采用相同的模型结构和参数设置。本文使用了自定义的CNN模型,该模型包含两个5×5的卷积层和两个全连接层,其中最后一层拥有512个神经元。每一层都通过ReLU函数进行激活,卷积层之间以及与全连接层的连接处还设置了2×2的最大池化层,并使用SGD作为优化器。
4.3 模拟Non-IID条件
理想的联邦学习环境下,各个客户端本地的特征分布、标签分布以及样本量应当一致,这样服务器可以获得优质的全局模型。然而客户端之间的数据分布往往存在严重的差异,为模拟真实的联邦学习环境,本文使用Dirichlet分布函数[26]对实验数据进行分区,根据αDirichlet对数据集进行划分,之后将分区后的数据分发给每个客户端,以此来模拟Non-IID环境。αDirichlet控制着数据的均匀程度,αDirichlet越大则数据分布越均匀,反之则客户端之间的分布就更偏斜,Non-IID程度越严重。另外还增加了另一个分布条件,将CIFAR-10的每类样本均匀地进行分片,每个分片含有同一类别的固定数量的样本,让客户端随机地从分片中抽取预定数量的片段,以模拟标签不平衡的分布。
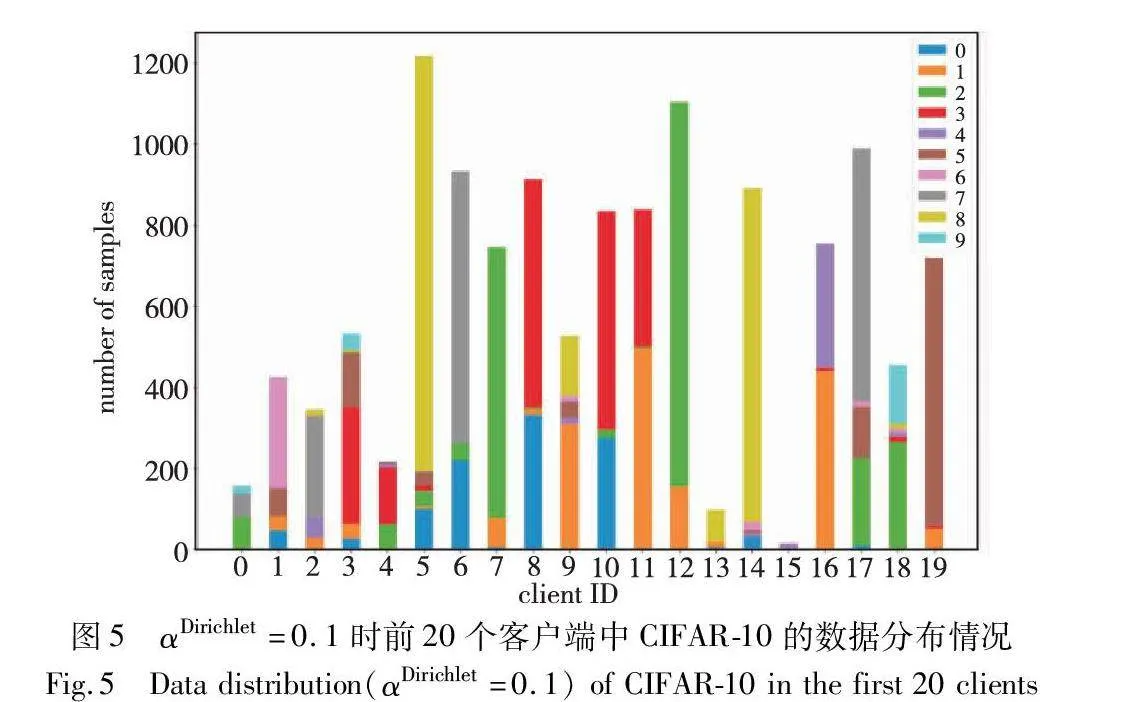
为评估FedAom在严重Non-IID环境下的效果,分别在多种分布条件下对FedAom的表现展开实验。以CIFAR-10为例,当αDirichlet=0.1时,前20个客户端的数据分布如图5所示,横坐标为客户端编号,纵坐标为样本的总量,不同的颜色则指代不同类型的数据,每个柱中通过不同颜色数据的堆叠展示了数据的分布情况。
4.4 精度对比
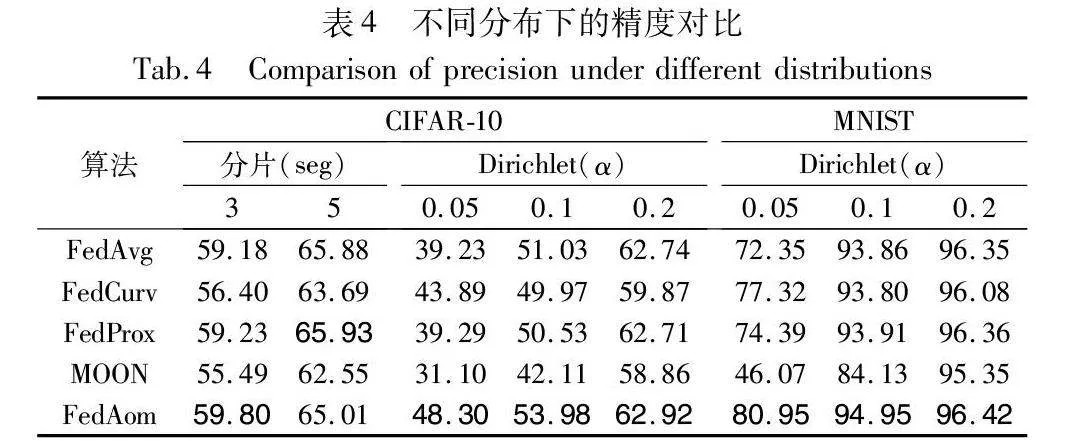
表4详细展示了FedAom与其他方法在各种分布设置下的精度差异。为了最大程度地减少误差的影响,选择每种算法最后20轮的精度均值作为其真实精度。通过对表4的分析可以清楚地发现,在大多数非独立同分布(Non-IID)的条件下,FedAom相较于其他方法展现出了较高的预测精度。
观察不同的分布条件下各算法的分类精度,可以发现,不同组实验中FedProx与FedAvg的精度相差很小。随着αDirichlet的增大,数据分布趋于均匀,各算法之间的差异逐渐缩小,由Non-IID引发的模型漂移现象得到缓解,使得FedAvg算法能够聚合到更高质量的全局模型,本文的实验结论也印证了这一点。而当Non-IID程度逐渐变大时,FedAom的提升将更加显著,这是由于基于归因的思想设计的FedAom可以从模型决策行为的角度上迫使参数保留对全局数据分布的敏感性,借助全局模型的归因行为在优化过程中实现更有效的知识回放。相比于传统的构建共享数据池的方案,FedAom能够更高效地利用共享数据,从而降低参与方的隐私成本。
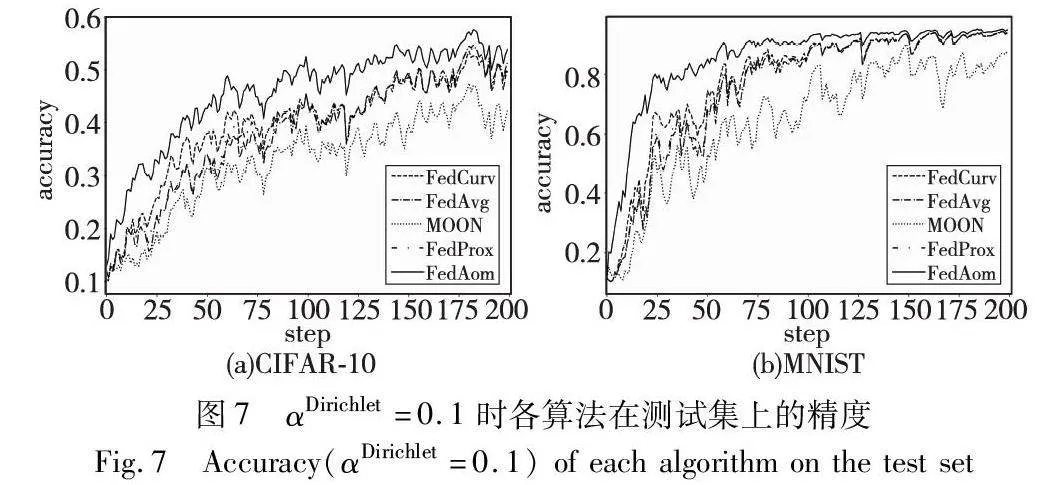
在本文设置的所有分布条件下,FedAom都展示出了更快的收敛速度。图6、7分别展示了αDirichlet取0.2与0.1在不同数据集下的训练曲线,观察发现,αDirichlet取0.1时,严重的数据偏斜加剧了客户端模型对全局知识的遗忘,这导致全局模型出现较大的振荡。而较小的αDirichlet会使得曲线更加平稳。MOON对数据偏斜更加敏感。FedAom对比其他算法收敛的更快,在MNIST数据集上,FedAom到第75轮左右即可达到90%的平均正确率,而FedAvg则在120轮左右,相比之下本文方法可节约37.5%的通信开销。
总的来说,本文的损失项可以更好地保留全局知识,加快训练速度,FedAom聚合得到的全局模型能够更大程度上缓解Non-IID分布带来的不利影响,更快地达到预期精度,从而降低通信成本,这表明FedAom更适合处理Non-IID的情况。
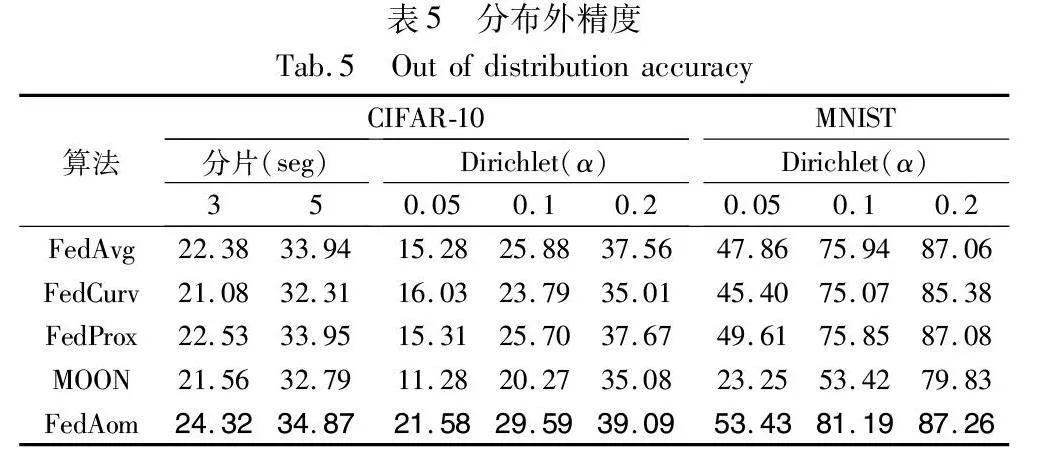
4.5 模型漂移程度
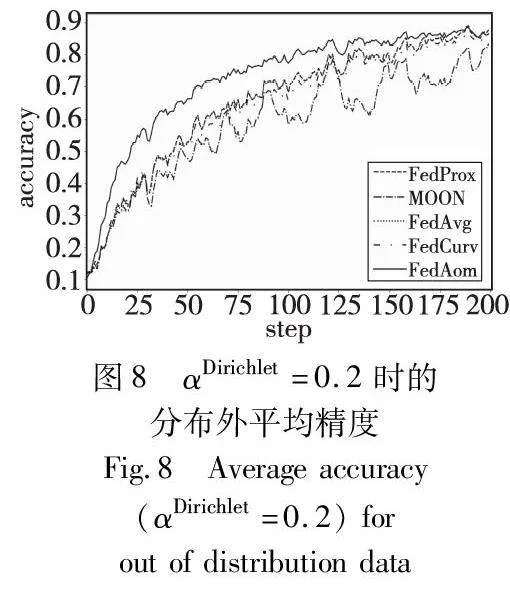
客户端数据的Non-IID分布使得全局模型的本地更新将偏离全局最优解。对客户端的本地分布而言,全局数据属于本地分布外(out of distribution, OOD)数据。直观上,如果客户端模型对本地占比较低的数据具有较好的预测精度,那么可以认为模型继承了全局模型对这类样本的知识。通过将每个客户端模型在本地数据类别精度与该类样本在本地数据中的占比倒数相乘并平均,作为模型的分布外精度,具体情况如表5所示。图8展示了αDirichlet=0.2时不同方法对本地分布外样本的加权预测精度。由图可知, FedAom相比其他算法在分布外数据上取得了最佳效果。这说明本文的正则项可以很好地引导局部更新朝全局最优解靠近,同时保留更多全局信息并加快全局模型的收敛。进一步观察发现,随着训练的进行,FedAom聚合得到的全局模型与其他方法的差异逐渐减小,这是因为更高精度的全局模型产生更清晰的归因。积分梯度路径选择和近似方法引入的噪声对归因的影响也会体现出来。选择高质量的基线和路径,以及更好的近似方法可以进一步改善FedAom的表现,但这超出了本文的讨论范围。
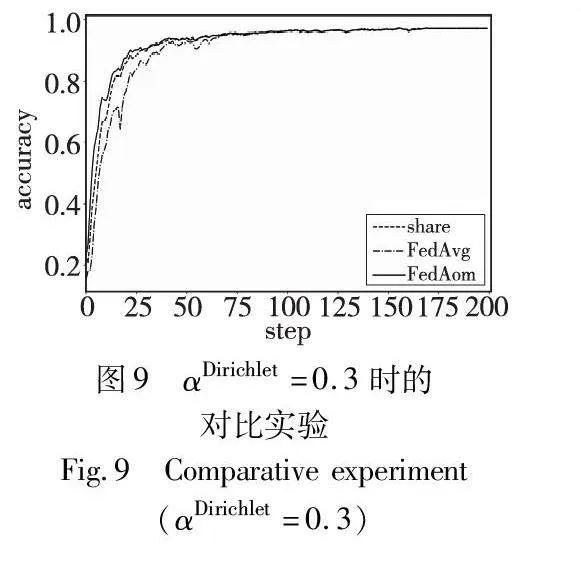
4.6 有效性实验
FedAom利用少量全局数据计算归因,利用归因间接地对本地模型进行知识回放。为了使实验结果更加清晰,本文选择了MNIST作为数据集,并在Dirichlet分布中进行模拟,以验证FedAom对全局数据的利用效率。相应的对比方案则将收集到的数据共享给所有的客户端,并作为本地数据参与训练,其他的实验参数保持默认设置,结果如图9所示。其中share表示共享数据的方法,FedAvg表示原始的联邦学习方法。
结果显示,无论是本文方法还是通过共享数据的方法,都可以提高联邦学习的收敛速度,这是由于两种方式都在局部训练过程中进行了知识回放。在联邦学习的参与方随机采样过程中,很有可能选中到具有较大样本偏差的客户端,从而影响本轮模型的质量。例如,在第20轮通信时,FedAvg显示出显著下降,相比之下,Share和本文方法只有轻微波动,表明本文方法能更有效地稳定训练过程。这得益于FedAom在归因层面上确保局部模型与全局模型的因果关系更紧密,优化了训练效率。实验结果显示,FedAom能够更高效合理地利用相同的共享数据,降低对数据量的依赖。
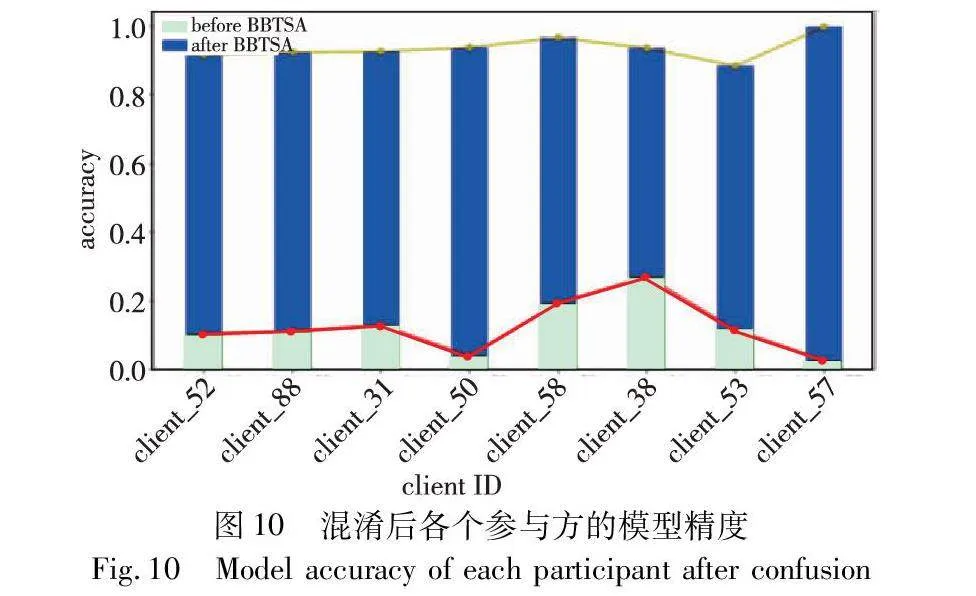
4.7 分片混淆结果验证
BBTSA在基于区块链的去中心化环境中,通过让参与方自主执行切片混淆过程,从而达到匿名的目的。为探究本文方法能否成功完成预定的目标,本节选择了在FedAvg最后一轮通信中的8个节点的本地模型进行实验。分别测试了合作混淆前后各参与方的本地模型在其本地数据上的预测精度,结果如图10所示。
经过混淆后,所有参与方的本地模型参数将叠加大量的随机噪声,直觉上,当噪声的方差足够大时,参数中保留的隐私信息将无法被辩别。通过实验结果可以看出,BBTSA可以使得混淆后的模型难以正确辨别训练集中的样本。混淆后,各节点的训练集平均准确率接近10%,这相当于随机猜测。综上所述,BBTSA使得节点可以在没有中心化的第三方机构介入下,利用节点的主动能力对参数进行混淆,进而提升隐私性。
4.8 防御能力
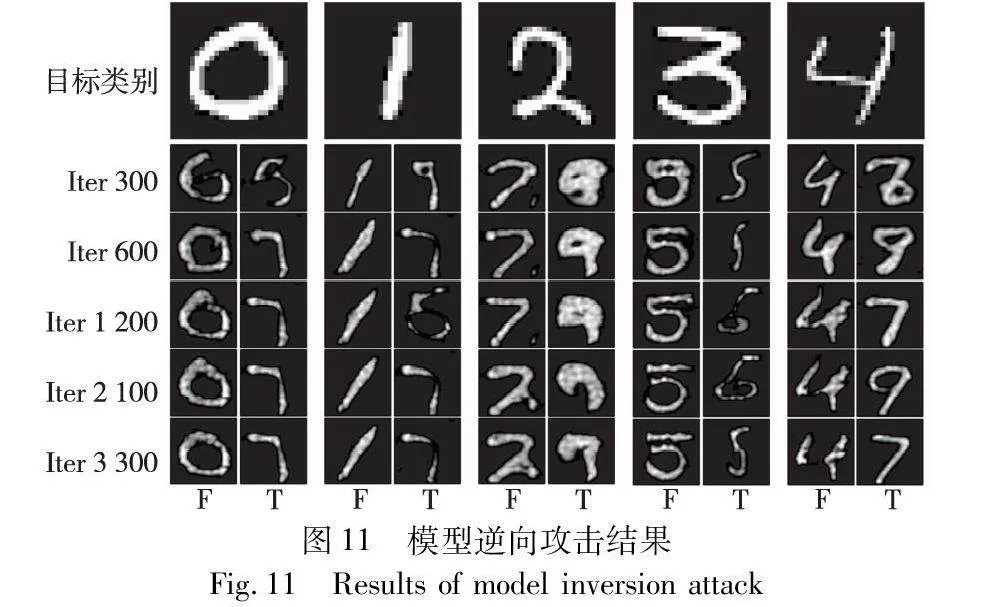
由于在本文中传输的参数为模型权重而非梯度值,所以针对梯度的攻击如深度梯度泄露DLG并不适用。而在针对模型参数的逆向推理攻击中,基于GAN的方法显得尤为有效。KEDMI[16]利用先验知识和目标模型来学习敏感信息分布,相比GMI[15]有更好的攻击效果。为测试BBTSA对这类攻击的防御能力,将遵循与不遵循BBTSA的参与方本地模型选为KEDMI攻击的目标。实验根据文献[16]的要求重新划分了参与方的样本并进行训练,且严格遵照原文中报告的设置和实验细节。结果如图11所示,其中T与F分别表示参与方遵循与不遵循BBTSA。
实验结果显示,即使在迭代300次后,KEDMI仍未能有效地学习到目标模型中的隐私知识,导致输出结果模仿先验分布样本,例如将“3”错误重建为“5”。而随着迭代的进行,未遵循BBTSA的参与方的重建结果将更接近于真实样本,而遵循BBTSA的模型重建结果则依然偏向于先验样本。由于参与方缺乏数字“4”的训练样本,攻击者难以从目标模型中提取出足够的相关知识,导致KEDMI对“4”的重构效果并不理想。这种情况下,攻击者可根据重建样本的质量进一步推断出参与方的标签分布信息。
BBTSA利用了参与方的主动能力,借助区块链的去中心化特性,在避免将原始参数传输给不可信第三方的前提下,完成了参数匿名化。实验表明即使充分学习到先验知识的生成对抗攻击方案也难以准确重建参与方的隐私数据。
5 结束语
本文着眼于联邦节点的隐私安全以及如何克服Non-IID引发的模型漂移问题,提出了联邦归因算法(FedAom)与基于区块链的联邦节点合作方案(BBTSA)。FedAom通过共享数据进行模型归因,指导本地更新,加速全局模型收敛,同时保留全局知识。而BBTSA在去中心化环境中通过切片混淆实现参数的完全匿名化,并降低了分发噪声的带宽消耗,在无须中心化的第三方机构介入的情况下,实现了对隐私参数的保护,且不会对全局模型造成负面影响。
然而,本文方法需要计算积分梯度,这增加了额外的计算量。近似方法引入的噪声会对全局模型产生影响,并且未考虑节点宕机可能导致的问题。后期将考虑如何以更低的成本,获得更加精确的归因以及解决节点掉线问题。
参考文献:
[1]Wang Yaqing, Yao Quanming, Kwok J T, et al. Generalizing from a few examples: a survey on few-shot learning[J]. ACM Computing Surveys, 2020, 53(3): article No.63.
[2]Ma Xu, Wang Chen, Chen Xiaofeng. Trusted data sharing with flexible access control based on blockchain[J]. Computer Standards & Interfaces, 2021, 78: 103543.
[3]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of Conference on Artificial Intelligence and Statistics.[S.l.]: PMLR, 2017: 1273-1282.
[4]Nilsson A, Smith S, Ulm G, et al. A performance evaluation of federated learning algorithms[C]//Proc of the 2nd Workshop on Distributed Infrastructures for Deep Learning. New York: ACM Press, 2018: 1-8.
[5]Li Xiang, Huang Kaixuan, Yang Wenhao, et al. On the convergence of FedAvg on Non-IID data[EB/OL]. (2020-06-25). https://arxiv.org/abs/1907.02189.
[6]Gao Liang, Fu Huazhu, Li Li, et al. FEDDC: federated learning with Non-IID data via local drift decoupling and correction[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 10102-10111.
[7]张红艳, 张玉, 曹灿明. 一种解决数据异构问题的联邦学习方法[J]. 计算机应用研究, 2024, 41(3): 713-720. (Zhang Hong-yan, Zhang Yu, Cao Canming. Effective method to solve problem of data heterogeneity in federated learning[J]. Application Research of Computers, 2024, 41(3): 713-720.)
[8]Li Tian, Sahu A K, Zaheer M, et al. Federated optimization in hete-rogeneous networks[EB/OL]. (2020-04-21). https://arxiv.org/abs/1812.06127.
[9]Shoham N, Avidor T, Keren A, et al. Overcoming forgetting in fede-rated learning on Non-IID data[EB/OL]. (2019-10-17). https://arxiv.org/abs/1910.07796.
[10]Wang Hongyi, Yurochkin M, Sun Yuekai, et al. Federated learning with matched averaging [EB/OL]. (2020-02-15). https://arxiv.org/abs/2002.06440.
[11]Mahmoud N, Aly A, Abdelkader H. Enhancing blockchain-based ride-sharing services using IPFS[J]. Intelligent Systems with Applications, 2022, 16: 200135.
[12]Bonnard J, Dapogny A, Dhombres F, et al. Privileged attribution constrained deep networks for facial expression recognition[C]//Proc of the 26th International Conference on Pattern Recognition. Piscata-way, NJ: IEEE Press, 2022: 1055-1061.
[13]Sundararajan M, Taly A, Yan Qiqi. Axiomatic attribution for deep networks[C]//Proc of the 34th International Conference on Machine Learning.[S.l.]: PMLR, 2017: 3319-3328.
[14]Ge Lina, Li Haiao, Wang Xiao, et al. A review of secure federated learning: privacy leakage threats, protection technologies, challenges and future directions[J]. Neurocomputing, 2023,561: 126897.
[15]Zhang Yuheng, Jia Ruoxi, Pei Hengzhi, et al. The secret revealer: generative model-inversion attacks against deep neural networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 253-261.
[16]Chen Si, Kahla M, Jia Ruoxi, et al. Knowledge-enriched distributional model inversion attacks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 16178-16187.
[17]Om Kumar C U, Gajendran S, Bhavadharini R M, et al. EHR privacy preservation using federated learning with DQRE-Scnet for healthcare application domains[J]. Knowledge-Based Systems, 2023, 275(C): 110638.
[18]曹世翔, 陈超梦, 唐朋, 等. 基于函数机制的差分隐私联邦学习算法[J]. 计算机学报, 2023,46(10): 2178-2195. (Cao Shi-xiang, Chen Chaomeng, Tang Peng, et al. Differentially private fede-rated learning with functional mechanism[J]. Chinese Journal of Computers, 2023, 46(10): 2178-2195.)
[19]Zhang Wei, Wang Ziwei, Li Xiang. Blockchain-based decentralized federated transfer learning methodology for collaborative machinery fault diagnosis[J]. Reliability Engineering & System Safety, 2023, 229: 108885.
[20]刘炜, 唐琮轲, 马杰, 等. 基于区块链和动态评估的隐私保护联邦学习模型[J]. 计算机研究与发展, 2023, 60(11): 2583-2593. (Liu Wei, Tang Chongke, Ma Jie, et al. A federated learning model for privacy protection based on blockchain and dynamic evaluation[J]. Journal of Computer Research and Development, 2023, 60(11): 2583-2593.)
[21]Guduri M, Chakraborty C, Maheswari U, et al. Blockchain-based federated learning technique for privacy preservation and security of smart electronic health records[J]. IEEE Trans on Consumer Electronics, 2024, 70(1): 2608-2617.
[22]Madni H, Umer R, Foresti G. Blockchain-based swarm learning for the mitigation of gradient leakage in federated learning[J]. IEEE Access, 2023, 11: 16549-16556.
[23]Zhao Yue, Li Meng, Lai Liangzhen, et al. Federated learning with Non-IID data[EB/OL]. (2018-06-02). https://arxiv.org/abs/1806.00582.
[24]李志鹏, 国雍, 陈耀佛, 等. 基于数据生成的类别均衡联邦学习[J]. 计算机学报, 2023,46(3): 609-625. (Li Zhipeng, Guo Yong, Chen Yaofo, et al. Class-balanced federated learning based on data generation[J]. Chinese Journal of Computers, 2023, 46(3): 609-625.)
[25]常黎明, 刘颜红, 徐恕贞. 基于数据分布的聚类联邦学习[J]. 计算机应用研究, 2023, 40(6): 1697-1701. (Chang Liming, Liu Yanhong, Xu Shuzhen. Clustering federated learning based on data distribution[J]. Application Research of Computers, 2023, 40(6): 1697-1701.)
[26]Li Qinbin, He Bingsheng, Song D. Model-contrastive federated lear-ning[EB/OL]. (2021-03-30). https://arxiv.org/abs/2103.16257.
[27]Erion G, Janizek J D, Sturmfels P, et al. Improving performance of deep learning models with axiomatic attribution priors and expected gradients[J]. Nature Machine Intelligence, 2021, 3(7): 620-631.
[28]Shrikumar A, Greenside P, Kundaje A. Learning important features through propagating activation differences[C]//Proc of the 34th International Conference on Machine Learning.[S.l.]: PMLR, 2017: 3145-3153.
[29]Yang Ruo, Wang Binghui, Bilgic M. IDGI: a framework to eliminate explanation noise from integrated gradients[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 23725-23734.
