基于多粒度阅读器和图注意力网络的文档级事件抽取
2024-08-15薛颂东李永豪赵红燕





摘 要:文档级事件抽取面临论元分散和多事件两大挑战,已有工作大多采用逐句抽取候选论元的方式,难以建模跨句的上下文信息。为此,提出了一种基于多粒度阅读器和图注意网络的文档级事件抽取模型,采用多粒度阅读器实现多层次语义编码,通过图注意力网络捕获实体对之间的局部和全局关系,构建基于实体对相似度的剪枝完全图作为伪触发器,全面捕捉文档中的事件和论元。在公共数据集ChFinAnn和DuEE-Fin上进行了实验,结果表明提出的方法改善了论元分散问题,提升了模型事件抽取性能。
关键词:多粒度阅读器; 图注意力网络; 文档级事件抽取
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)08-012-2329-07
doi:10.19734/j.issn.1001-3695.2024.01.0001
Document level event extraction based on multi granularityreaders and graph attention networks
Xue Songdong, Li Yonghao, Zhao Hongyan
(School of Computer Science & Technology, Taiyuan University of Science & Technology, Taiyuan 030024, China)
Abstract:Document level event extraction faces two major challenges: argument dispersion and multiple events. Most exis-ting work adopts the method of extracting candidate arguments sentence by sentence, which makes it difficult to model contextual information across sentences. Therefore, this paper proposed a document level event extraction model based on multi granularity readers and graph attention networks. It used multi-granularity readers to achieve multi-level semantic encoding, and used the graph attention network to capture local and global relations between entity pairs. It constructed a pruned complete graph based on entity pair similarity as a pseudo trigger to comprehensively capture events and arguments in the document. Experiments conducted on the public datasets of ChFinAnn and DuEE-Fin show that the proposed method improves the problem of argument dispersion and enhances model’s event extraction performance.
Key words:multi-granularity reader; graph attention network; document-level event extraction
0 引言
事件抽取(event extraction,EE)旨在从非结构化文本中识别事件及其事件论元(参与事件的实体),是信息抽取的重要任务之一。目前的研究主要集中在句子级事件抽取(sentence level event extraction,SEE)[1]任务上,侧重于从一个句子中识别事件触发词[2]、确定事件类型、识别论元以及判断论元角色。然而,一个事件往往会分布在多个句子或整篇文档中,句子级的事件抽取无法满足人工智能和自然语言处理相关领域的应用需求。因此,近些年来文档级事件抽取引起了学者们的研究热潮。
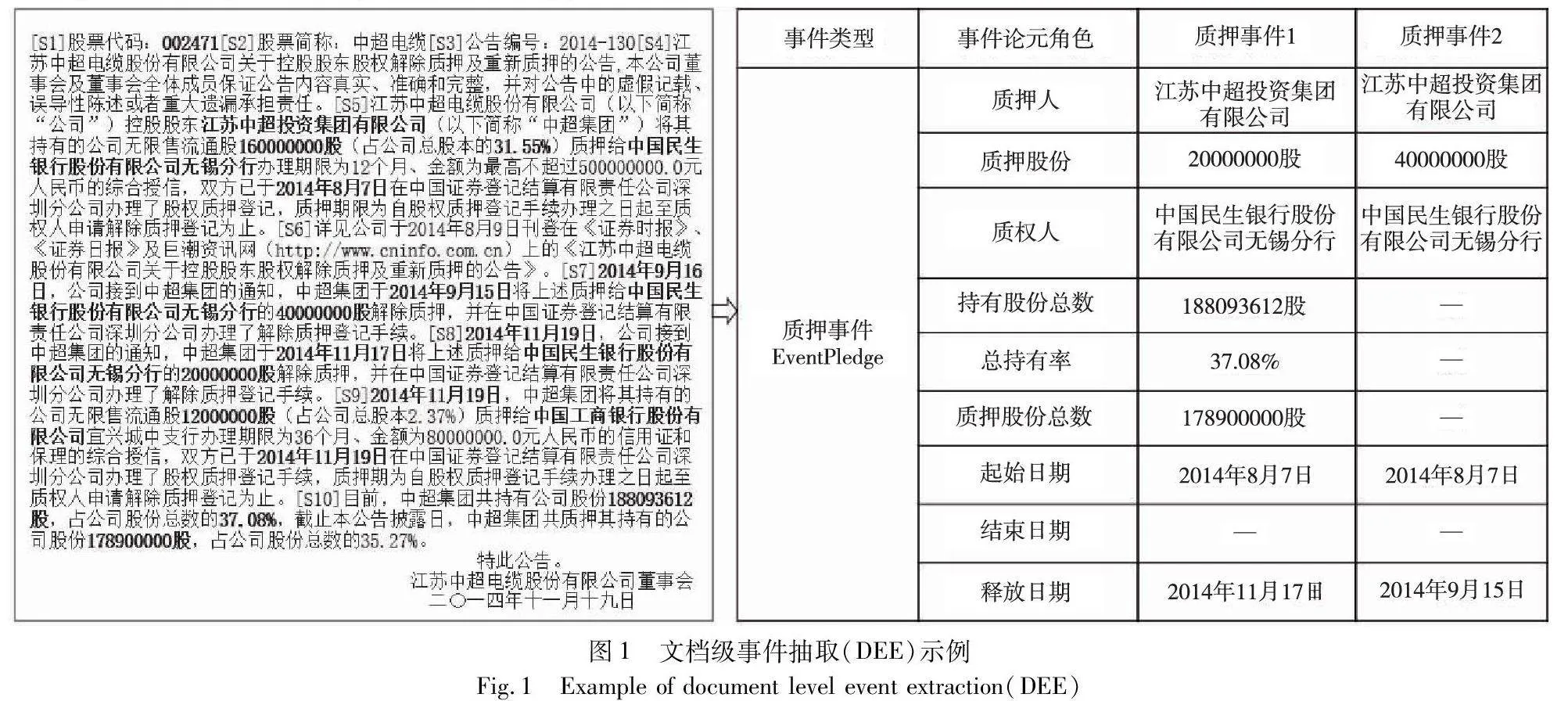
文档级事件抽取(document level event extraction,DEE)是从文档中确定事件类型、识别论元及判断论元角色[3]。与句子级事件抽取相比,文档级事件抽取面临论元分散和多事件两个挑战。论元分散问题是指一个事件的论元可能分散在多个句子中;多事件问题是指一篇文档中可能会同时存在多个事件。如图1所示,该示例来自于ChFinAnn数据集(https://github.com/dolphin-zs/Doc2EDAG),文档级事件抽取的任务就是从左边给定的文档中抽取出所有事件、对应论元以及论元角色,并以结构化形式表示。该文档包含了两个“质押事件”,其中第一个“质押事件”涉及到的事件论元角色包括“质押人、质押股份、质权人、持有股份总数、总持有比率、质押股份总数、起始日期、释放日期”,这些论元分散在文档中的第5、8和10个句子中;第二个“质押事件”涉及到的事件论元角色包括“质押人、质押股份、质权人、起始日期、释放日期”,这些论元分散在文档中的第5和7个句子中。如何从文档的多个句子中识别出每一个事件的多个论元是一项极其复杂和极具挑战性的工作,它不仅需要考虑句内局部信息,还要考虑文档中句间的全局信息。
目前,DEE任务的研究主要分为串行预测和并行预测两种。串行预测先预测事件类型,再确定其预定义的论元角色顺序,然后按照预定义论元角色顺序对论元进行二元分类,判断论元与论元角色是否匹配。DCFEE模型[4]利用远程监督方法扩展训练语料库,对逐个句子提取触发词和论元,将触发词和论元与当前句子连接,利用卷积神经网络(convolutional neural network,CNN)[5]判断当前句子是否为关键句,同时提出一种补全策略,从关键事件所在句子的周围句子中获得论元进行补全,但该方法没有考虑论元识别阶段的误差传递。Doc2EDAG[6]提出将论元识别问题转换为基于论元的有向无环图(directed acyclic graph,DAG)的路径扩展问题,从而实现了无触发词的事件类型检测。确定事件类型后,通过预定义论元角色的顺序生成有向无环图进行识别,由于DAG的每条路径都表示一个事件,所以需要通过论元节点来扩展路径。有向无环图的生成类似于表格的填写,根据预定义论元角色一步步填写论元。通过预定义角色顺序逐个确定论元,理论上可以提取一个文档中的多个事件,解决了文档中的多事件问题。然而当事件论元出现在不同句子时,通过Transformer[7]融合句子和论元信息很难捕获内部依赖关系。为此,GIT模型[8]基于Doc2EDAG提出了异构图和tracker模块,异构图用于捕获不同句子和论元提及之间的全局交互,tracker模块用于存储已解码的事件记录。但在同一事件中,先捕获的论元信息不能考虑到后面捕获的实体信息。张虎等人[9]提出一种基于多粒度实体异构图的篇章级事件抽取方法,该方法主要的创新点在于它结合了句子级和段落级实体抽取,并利用图卷积网络(graph convolution network,GCN)[10]来增强对文档上下文的感知,能够有效地处理跨句信息,从而提高了事件抽取的精度和效果。但同时段落级方法可能忽略了文档中不同部分事件之间更广泛的上下文,而且其相对复杂的模型和较高的资源需求是需要考虑的问题。综上所述,采用串行预测方法对单个论元提取时,仅考虑了前面已识别的论元,无法利用所有论元的上下文语义信息,影响了模型性能。
针对上述文档级事件抽取串行预测方法的局限性,有学者提出并行预测的文档级事件抽取方法,其核心思想是把论元和论元角色的识别问题转换成一种生成任务,不仅能够解决串行预测仅关注局部论元信息的问题,而且极大地提高了模型的解码速度。例如PTPCG模型[11]将论元组合表示为一个修剪的完全图,把重要论元作为一组具有双向连接的伪触发器,其他普通论元以定向方式与这些伪触发器连接,并设计了一种具有非自回归解码策略的高效事件论元组合提取算法。但该模型采用双向长短时记忆网络(bi-directional long short-term memoU0UrENzyRVH+hlcFjvB/WAhguFd4hDMKUbz1+DM1jJo=ry,BiLSTM)[12]提取论元组合,主要关注局部信息,难以捕获全局语义信息,导致实体抽取质量不高。DEE-CF模型[13]通过分割文档为不同的段落,优化了模型抽取范围,能够充分抽取更细致的语义信息。利用BiLSTM获取局部的段落特征信息和全局的文档序列特征信息,结合局部与全局视角的优势,增强了模型对文档级事件的理解能力。DE-RCGNN模型[14]结合了阅读理解和图神经网络来解决篇章级事件抽取中的挑战,有效地利用了论元角色先验信息和篇章级信息来提高事件元素抽取的准确性和整体性能,但该方法需要对每个事件论元角色构建问答,导致样本数量增加,降低了运行效率。
综合考虑上述文档级事件抽取模型的优缺点,本文提出了一种新的非自回归文档级事件抽取模型——基于多粒度阅读器和图注意力网络的文档级事件抽取模型(MGR-GATPCG)。该模型引入多粒度阅读器有效整合分散在不同句子中的论元信息,提高模型对文档全局上下文的捕获能力;提出一种滚雪球式的图注意力网络[15]来增强跨句论元间复杂关系的交互,有助于处理文档中的多事件问题;采用一种非自回归解码策略,并行处理多个论元,提高模型解码速度和效率,而且避免了串行预测中的误差累积问题,使模型在考虑全局信息的同时,快速准确地识别和分类事件论元。总之,本文的主要贡献如下:
a)构建了一种新的基于多粒度阅读器的文档级事件语义表示模型,从局部到全局对文档进行不同粒度语义编码,并提出一种门控机制的信息融合方法,动态地聚合句子级上下文信息和文档级上下文信息,实现局部信息和全局信息的融合。
b)提出了一种滚雪球式的图注意力网络方法,融合句内的论元信息和句间的论元信息,从而增强实体语义表示,为触发器的确定提供了保障。
c)在ChFinAnn和DuEE-Fin数据集上进行大量对比实验,结果表明本文模型的性能在大多评价指标上优于先进的基线模型,并采用消融实验验证了模型各个模块的性能。
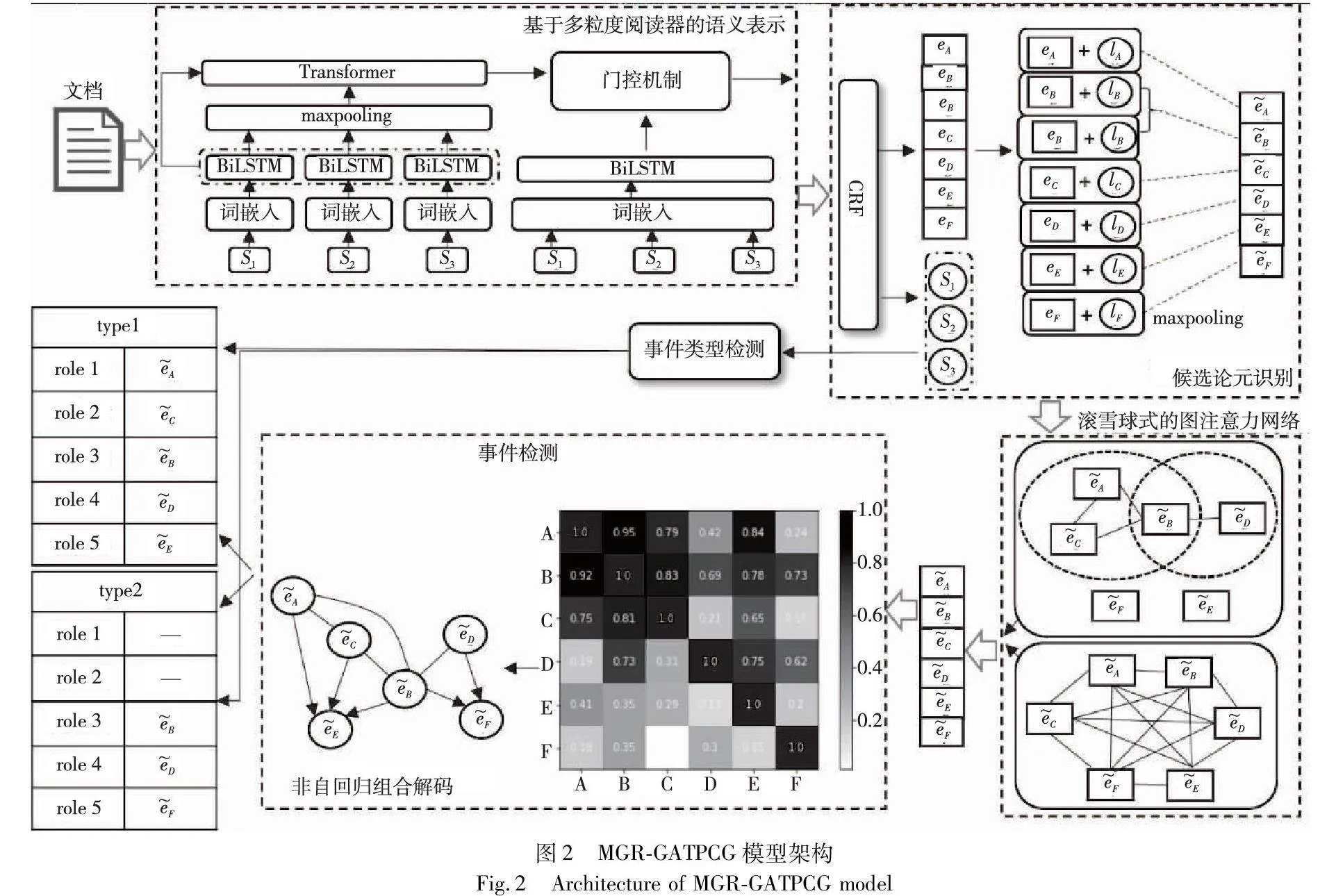
1 MGR-GATPCG模型
本文模型MGR-GATPCG架构如图2所示,包括基于多粒度阅读器的语义表示、候选论元识别、滚雪球式的图注意力网络方法、事件类型检测和事件检测五个子模块。其中基于多粒度阅读器的语义表示模块对文档分别进行文档级和句子级编码,采用一种基于门控机制[16]的信息融合方法来融合不同粒度的信息;候选论元识别模块利用CRF层获取论元提及,将论元提及与预定义论元提及类型拼接后进行最大池化,获得候选论元;滚雪球式的图注意力网络方法模块对论元提及进行局部语义编码和全局语义编码,得到最终论元集;事件类型检测模块对句子采用最大池化方法进行二分类事件类型检测;事件检测模块计算论元对之间的相似度,构建剪枝完全图的相邻矩阵;最后对相邻矩阵解码组合后,进行事件类型、论元角色与论元配对,最终生成事件。
1.1 基于多粒度阅读器的语义表示
虽然同粒度嵌入层的词嵌入的初始化词是相同的,但每个标记的上下文表示在编码时会因其所在句子的上下文或段落的上下文中不同而有所不同。为了实现不同粒度(句子级和文档级)上下文感知的语义表示,本文提出一种基于多粒度阅读器的文档级语义表示方法。首先,模型使用BiLSTM对句子级信息进行编码,以捕获句子内部的细节和上下文语义信息。然后,通过maxpooling对这些句子编码进行整合,并使用Transformer模型强大的自注意力机制来捕获句子之间的复杂关系和全文档的上下文信息。此外,为了在更宏观的层面上捕捉文档的整体结构和长距离依赖关系,直接对文档使用Bi-LSTM进行编码,该编码策略增强了不同粒度的上下文信息处理——从细粒度的句子级编码到粗粒度的文档级编码,使模型不仅能够理解每个句子内的细节信息,同时也能够把握整个文档的结构,为文档级事件抽取提供全面的信息支持。
具体来说,给定一个输入的文档D={Si}Ni=1,它由N个句子组成,其中Si={wj}Mj=1,每个句子由M个单词序列组成。本文模型构建了两个子模块(BiLSTMsent-Transformer和 BiLSTMdoc)分别进行句子级和文档级上下文表示。该模块句子级的上下文表示为{(Si)1…(Si)j},文档级的上下文表示为{(S1)1…(S1)j…(Si)1…(Si)j}。
1.1.1 基于句子级的文档编码
在句子级编码子模块中,首先采用BiLSTMsent依次对文档中的每个句子进行编码,具体表示如下:
{(Si)1,(Si)2,…,(Si)j}=BiLSTMsent({(Si)1,(Si)2,(Si)j})(1)
其中:Si代表第i个句子;(Si)j表示第Si句子中的第j个词嵌入。然后对所有句子内的词嵌入使用maxpooling方法后,使用Transformer对文档中的所有词嵌入和句子表示进行编码,得到基于句子级的文档编码,其中‖用来连接句子表示:
{(S1)1…(S1)j…(Si)1…(Si)j}=
Transformer({(S1)1…(S1)j…(Si)1…(Si)j‖Si})(2)
1.1.2 基于文档级编码
在文档级子编码模块中,本文依然采用一个BiLSTM编码器(BiLSTMdoc)应用于整个文档,以捕获文档中标记间的依赖关系:
{P^(S1)1…P^(S1)j…P^(Si)1…P^(Si)j}=
BiLSTMdoc({(S1)1…(S1)j…(Si)1…(Si)j})(3)
其中:P^(Si)j是经过编码的文档级上下文表示。
1.1.3 融合不同粒度的文档编码
为了融合在句子级((Si)j)和文档级(P^(Si)j)学习到的语义信息,本文提出一种门控融合算法,融合局部语义信息和全局语义信息,具体如式(4)(5)所示。
g(Si)j=sigmoid(w1(Si)j+w2P^(Si)j+b)(4)
p(Si)j=g(Si)j⊙(Si)j+(1-g(Si)j)⊙(Si)j(5)
其中:符号⊙表示门控装置;w1和w2是可训练参数;g(Si)j是门控融合计算的门向量,该向量由句子级表示(Si)j和文档级表示P^(Si)j组成,以控制从两个表示中合并信息的多少;g(Si)j为最终标签序列。
1.2 候选论元识别
通过考虑标签之间的依赖关系,对神经网络的输出进行全局约束,以生成最佳的标签序列。本文在上节网络的输出层之后添加了一个条件随机场(conditional random fields,CRF)[17]层,用于对每个标记位置的标签进行归一化概率计算。
最后,根据文献[6],本文将融合不同粒度的文档编码进行候选论元识别,建模为序列标记任务。通过候选论元识别,从给定的句子Si中获得候选论元集ε= {ei}|Na|i=1,|Na|为识别出的候选论元个数。论元抽取的训练目标是最小化每个句子的负对数似然损失Lner,如式(6)所示。
Lner=-∑Si∈Dlog P(ySi|P(Si)j)(6)
其中:ySi是输入序列Si的黄金标签序列;P(Si)j为预测的标签序列,在推理过程中,该文采用Viterbi[18]算法解码最大概率标签序列。
本文在词嵌入级层上采用最大池化(maxpooling)操作以获得最终候选论元嵌入i,该方法已被文献[6]证明了对下游子模块有效。通过查找嵌入表将预测的论元类型转换为向量。将论元ei与论元类型嵌入li拼接起来,得到论元提及表示i =(ei‖li)∈Euclid ExtraaBpda,其中da=dh+dl, dl表示li的维数。最后,对一个论元的所有提及表示进行聚合,然后通过最大池化方法确定最终候选论元的标签序列。
1.3 滚雪球式的图注意力网络方法
为了更好地建模论元语义表示,本文使用了图注意力网络对论元集ε={i}|ε|i=1进行局部编码和全局编码。
首先,根据文档级事件抽取存在的知识进行句内论元语义交互和句间论元语义交互。句内论元语义交互的依据是基于在同一句子中的论元更有可能是同一事件的论元的先验知识。句间论元语义交互的依据是包含相同论元的句子往往叙述相同的事件。基于以上知识以及文献[19],本文使用图注意力网络对实体集进行局部编码和全局编码。
a)局部语义编码。本文采用一个图注意力网络,在不同句子中提取相同论元提及,然后将这些不同句子中的所有相关论元提及与当前论元提及连接组成局部图注意力网络。例如,在图2滚雪球式的图注意力网络方法中,候选论元A、B和C在同一句子中,B和D在同一句子中,E和F分别在另外的单独句子中。由于B同时在两个句子中,则对A、B、C和D四个候选论元进行局部语义编码。
b)全局语义编码。与整个文档中的论元进行交互的方法可以在更宏观的层面上理解事件的上下文,包括跨句子或跨段落的论元关系。同时,在处理包含多个相互关联事件的长文档时,能够提供更丰富的语义信息,从而提高事件抽取的准确性和效率。往往数据集中句子中出现的单个候选论元很大可能是起始日期或者结束日期,局部语义编码无法获取文档全部的论元信息。为此,在全局语义编码中候选论元的邻接矩阵由它与所有的其他论元提及连接组成全局图注意力网络。
一般来说,GAT层的输入是一个无向无权图G =(V,E),邻接矩阵F和G分别代表局部注意力网络和全局注意力网络的边,节点属性向量为论元集ε。本文用D′表示GAT输出。为了获得图中不同节点对被关注节点的重要性,本文在图中采用了注意力机制,注意力评分αij表示邻居节点j对被关注节点i的重要程度:
αij=exp(σ(aT[Wi‖Wj]))∑k∈Niexp(σ(aT[Wi‖Wk]))(7)
其中:σ为LeakyReLU[20]激活函数;a∈Euclid ExtraaBp2D′为全连通层;W∈Euclid ExtraaBpD′×D为权重矩阵;Ni为节点i的邻居。
模型采用带有K个头的多头注意机制从不同的表征子空间中捕获更多的信息,得到最终实体集ε′={e′i}|ε|i=1,如式(8)所示。
e′i=σ(1k∑Kk=1∑j∈NiαkijWkj)(8)
其中:αkij表示第k个注意力机制计算得到的归一化注意力系数;Wk是相应输入线性变化的权重矩阵;e′i为平均K个头的GAT输出特征。
1.4 事件类型检测
对于文档D,本文遵循文献[6],对每种事件类型进行二元分类。将事件检测Ldet的损失函数定义为二元交叉熵损失。通过对预测序列中每个句子表示P(Si)j作最大池化,获得文档中每个句子的文档感知表示hSi。由于文档中会包含多种事件类型,为了预测文档中的事件类型,对文档表示hSi上的每种事件类型进行二元分类。这里将文档感知表示hSi输送到多个前馈网络中,以判断每个事件预测是否为空:
ydec=softmax(hSiWte)(9)
其中:Wte∈Euclid ExtraaBpd×2表示t种事件的可学习参数,t∈T,T是数据集中所有预定义的事件类型。最后使用得到的预测值ydec和黄金数据yi求二元交叉熵损失函数:
Ldec=-[yilog ydec+(1-yi)log(1-ydec)](10)
1.5 事件检测
1.5.1 完全图构建
在文档级事件抽取任务的研究中,传统的触发词识别方法面临着明显的局限性,即单一句子或局部文本片段往往不足以准确识别和分类复杂事件。这是因为事件的全貌可能分散在文档的多个部分,包括跨句子甚至跨段落的信息。为了克服这些限制,本文提出了一个创新的模型设计,结合了伪触发器和完全图的构建,旨在全面捕捉文档中的事件和论元之间的关系。
为此,本文模型引入了伪触发器,即不依赖于传统意义上的触发词,而且根据触发器常有的两个作用:a)触发器可用于识别论元组合;b)触发器可用于区分不同的论元组合,实现对论元间关系的全面捕捉,采用了完全图的构建方法。为此,本文设计了一个重要性分数来评估论元可以作为伪触发器的可能性。形式上,通过缩放点积[6]作为重要性分数:
ei=e′i×WTi+bi(11)
ej=e′j×WTj+bj(12)
Aij=eTiejdk(13)
其中:Aij表示相似度矩阵;Wi、Wj∈Euclid ExtraaBpda×da和bi、bj ∈Euclid ExtraaBpda是语义空间线性投影的可训练参数。对于论元集中的任意两个伪触发器a(i)t和a(j)t,它们是双向连接的,其中相邻矩阵y(i,j)A=y(j,i)A=1。对于论元集中的伪触发器a(i)t和普通论元a(j)0,它们之间用一个定向链接连接,即y(i,j)A= 1。此外,每个论元a(i)都有一个自循环连接,即y(i,i)A=1。重要性分数Aij作为预测分数,在训练中,本文使用二元交叉熵函数来表示组合损失:
Lcomb=-1|A|∑j∑i[y(i,j)Alog Aij+(1-y(i,j)A)log(1-Aij)](14)
在重要性分数Aij中,通过式(15)确定候选论元之间的联系,其中γ为阈值。
ij=1 Aij≥γ0otherwise(15)
1.5.2 非自回归组合解码
基于预测的相邻矩阵ij,使用非自回归解码算法提取事件论元组合。本文采用文献[11]提出的方法,首先,通过分析节点的出度信息,可以识别所有的伪触发器,并将它们组成一个集合。伪触发器是指具有非零出度(除了自循环)的论元。对于只有一个伪触发器的情况,所有的组合都是以该伪触发器为中心的树结构。对于伪触发器数量大于1的情况,采用Brown-Kerbosch(BK)算法[21]来查找所有可能的集合。这样可以对事件触发器进行更准确的识别和分类。
在每个集合中,本文利用伪触发器的邻居节点执行交集操作,以找到共同共享的普通论元。普通论元是指在集合中不是伪触发器的普通论元。通过提取普通论元,可以更全面地描述事件,并捕捉到不同论元之间的关系和联系。通过这种组合方式,可以建立事件的整体框架结构,并进一步推断和预测事件的其他属性。由于非自回归解码不涉及基于DAG的多步骤图链接依赖,所以该方法具有较快的训练和推理速度。
1.5.3 事件记录生成
从修剪的完全图中获得论元组合集之后,下一步是将这些组合填充到事件表中,使所有的组合都与事件类型和论元角色匹配。本文遵从文献[11],对于所有事件类型TP={tj}|Tp|j=1和论元角色组合C,执行笛卡尔积,得到所有类型组合对{〈tj,rk〉|1≤j≤|TP|,1≤k≤|C|}。对于每一对〈tj,rk〉,使用事件相关的前馈神经网络(feedforward neural network,FNN)作为分类器来获得角色rk中所有论元εk的可能论元角色。损失函数采用二元交叉熵函数,如式(16)(17)所示。
p(j)role(tj|rk)=sigmoid(FFNj(εk))(16)
Lrole=-∑k∑i[y(j,k)rolelog p(j)role(tj|rk)+(1-y(j,k)role)log(1-log p(j)role(tj|rk))](17)
其中:y(j,k)role角色是最符合ck的黄金答案。为了适应角色分类的损失计算,每个预测组合都使用黄金组合进行评估,它们具有相同的事件类型和相同的参数。其余不匹配的论元不参与损失计算。
1.6 优化
MGR-PTPCG模型是一个端到端的模型,在训练时采用联合训练策略[22]。总损失为所有损失的加权和,表示为
Lall=λ1Lner+λ2Ldet+λ3Lcomb+λ4Lrole(18)
其中:λ1、λ2、λ3、λ4是超参数,用于平衡各种损失。
2 实验
2.1 数据集
本文使用文献[6]的公共数据集ChFinAnn和百度发布的金融领域数据集DuEE-Fin来评估本文模型。其中ChFinAnn数据集采用大量的金融文本构建。它由32 040个文档组成,是迄今为止最大的文档级事件抽取数据集。它主要关注股权冻结(EF)、股权回购(ER)、股权减持(EU)、股权增持(EO)和股权质押(EP)五种事件类型,共有35种不同的论元角色。本文遵循数据集的标准分割,根据8∶1∶1的比例划分了训练集、验证集和测试集。在该数据集中,每个文档大约包含20个句子,平均由912个词组成。每个事件记录平均涉及6句话,29%的文档包含了多个事件。DuEE-Fin共包含13个已定义好的事件类型和1.15万篇中文篇章(存在部分非目标篇章作为负样例),其中6 900个作为训练集,1 150个作为验证集,3 450个作为测试集。
2.2 实验设置与实现方法
实验环境:Intel Xeon Platinum 8358P CPU @ 2.60 GHz 100 GB内存,Linux,GPU处理器为4块RTX 3090(24 GB)的独立显卡。
a)实现方法与模型架构设置。本文模型使用PyTorch框架实现。MGR-PTPCG模型包括基于多粒度阅读器的语义表示、候选论元识别、滚雪球式的图注意力网络方法、事件类型检测和事件检测五个子模块。基于多粒度阅读器的语义表示模块采用两层BiLSTM进行文档级编码,使用两层BiLSTM进行句子级编码,同时使用两层Transformer对经过maxpooling的句子进行句子级编码,使用门控机制融合文档级编码和句子级编码,以便进行事件检测和论元提取。候选论元识别模块将经过CRF得到的实体论元与实体论元类型拼接得到候选论元集。滚雪球式的图注意力网络模块采用了两个图注意网络组成的局部注意力和全局注意力进行论元编码,通过门控机制动态融合论元上下文信息。事件类型检测模块中,使用softmax对经过多粒度阅读器的语义表示的句子进行二元分类,确定事件类型。事件检测模块中,对候选论元集进行缩放点积作为重要性分数,γ为阈值确定候选论元之间的联系,生成完全图。对所有事件类型和论元角色通过笛卡尔积作组合,对每个类型与角色对使用FFFM2NIozSOZfNCQIXjL4DHjGrgJ4OH/N7mwU+UHSLU+A=N作分类器来获得符合该角色的候选论元。
b)参数设置。图注意力网络用了八个多头注意力,输入维度为800,激活函数采用LeakyReLU函数。使用与文献[6]相同的词汇表,并随机初始化dh=768和dl=32的所有嵌入。使用Adam[23] 优化器,学习率为5E-4, 批量训练大小为32。λ1、λ2、λ3、λ4的权重分别为0.05、1.0、1.0、1.0,γ为0.5。按照文献[6]的设置,本文训练了100个epoch。
2.3 基线模型
为了验证本文模型的有效性,本实验采用的基线模型如下:
a)DCFEE[4]:提出了一种关键事件检测方法,以指导事件表,该事件表中填充了来自关键事件提及和周围句子的论元。DCFEE有两个版本,DCFEE-o只从一个文档中提取一个事件,而DCFEE-m是从一个文档中提取多个事件。
b)Doc2EDAG[6]:提出了一种DEE的端到端模型,该模型将DEE转换为基于实体路径扩展填充事件表的事件抽取模式。有一个简单的Doc2EDAG基线,名为GreedyDec,它只贪婪地填充一个事件表条目。
c)PTPCG[11]:使用非自回归解码算法,对在自动选择的伪触发器的指导下构造的剪枝完全图进行事件论元组合提取。
d)MEHG[9]:提出一种结合句子级和段落级的文档级实体抽取,并利用图卷积神经网络来增强对文档的上下文感知,之后使用与GIT相同的实体路径扩展填充时的事件抽取模式。
e)DE-RCGNN[14]:提出一种结合阅读理解和图神经网络的模型来解决篇章级事件抽取中的挑战,利用论元角色先验信息和篇章级信息来提高事件元素抽取的准确性和整体性能。
2.4 评估模型
本文采用了Doc2EDAG模型使用的评价准则,并选择在开发集上F1得分最高的检查点在测试集上进行评估。具体来说,对于每个篇章的所有黄金事件,采用不放回的方式预测事件类型相同且论元角色正确数量最多的事件,并以此作为模型的预测结果,分别采用精度(P)、召回率(R)和F1值(F1分数)进行评测。由于事件类型通常包括多个角色,所以论元角色评测采用Micro-F1指标。 计算过程如式(19)~(21)所示。
p=nrightargpredarg s(19)
R=nrightarggoldarg s(20)
F1=2×precision×recallprecision+recall(21)
其中:nrightarg是指事件类型相同且论元角色正确的数量;predarg s是所有预测论元的数量;gold arg s是所有黄金论元的数量。
2.5 实验结果
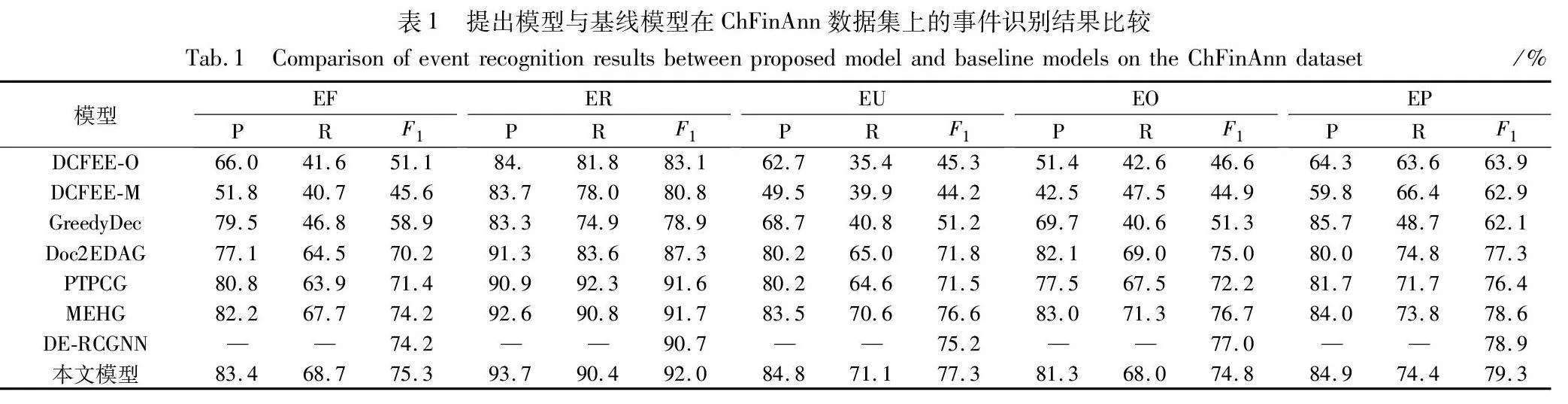
2.5.1 在ChFinAnn数据集上的实验
本文首先在ChFinAnn的测试集上进行了实验,实验结果如表1所示。从结果可以看出:MGR-GATPCG模型在大部分事件类型上均取得了最好的F1值;与MEHG模型相比,在EF、ER、EU、EP 上的F1值分别提高了1.1、0.3、0.7、0.7百分点,与DE-RCGNN模型相比,本文模型在EF、ER、EU、EP上的F1分别提高了1.1、1.3、2.1、0.4百分点。这一性能的提升主要归因于本文模型融合了句子级和文档级的语义信息,以及它有效地利用图注意力网络获取更全面的语义信息。模型特别在EF、ER、EU、EP事件类型上展现出优越的性能,这证明了其在捕获文档中复杂事件结构和细节方面的有效性。尤其是,在处理那些跨句子或跨段落的事件时,本文模型能够更准确地识别和链接相关的信息,从而提高了事件抽取的准确度。虽然在EO任务上,本文模型性能并未达到最佳,分析原因可能包括非自回归模型在论元角色和论元交互生成任务上的训练难度较高,以及ChFinAnn数据集在EO任务上的占比最高,导致模型容易过拟合。
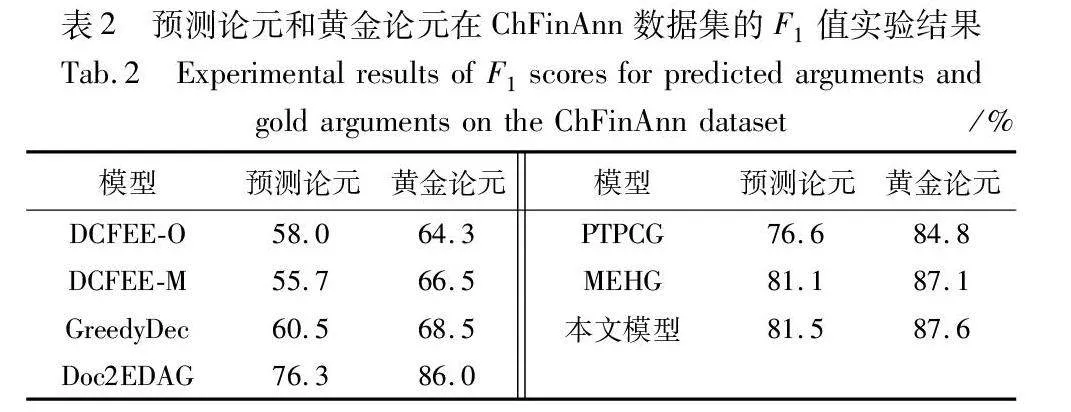
2.5.2 基于预测论元vs基于黄金论元的实验比较
为了证明论元质量对事件抽取效果的影响,本文将采用黄金论元代替预测论元进行事件检测和论元识别任务,比较不同模型使用预测论元和黄金论元时的F1值。从实验结果表2可以看出,当采用黄金论元替代预测论元进行事件检测和论元识别任务时,所有模型的性能都有所提高。这一点在模型中表现尤为明显,其采用黄金论元得到的F1值达到了87.6%,不仅高于其他模型,而且比采用预测论元时高出了6.1百分点。这一结果强调了优化论元识别精度的重要性。模型通过引入多粒度阅读器和图注意网络,有效提高了论元识别的准确性,并增强了论元对的语义编码,从而在采用预测论元时就已经展现出了较高的性能。此外,滚雪球式的图注意网络方法进一步增强了模型处理黄金论元时的性能,使其在论元质量较高时能够更好地捕捉事件的复杂性和细节,从而提高了事件抽取的整体效果。
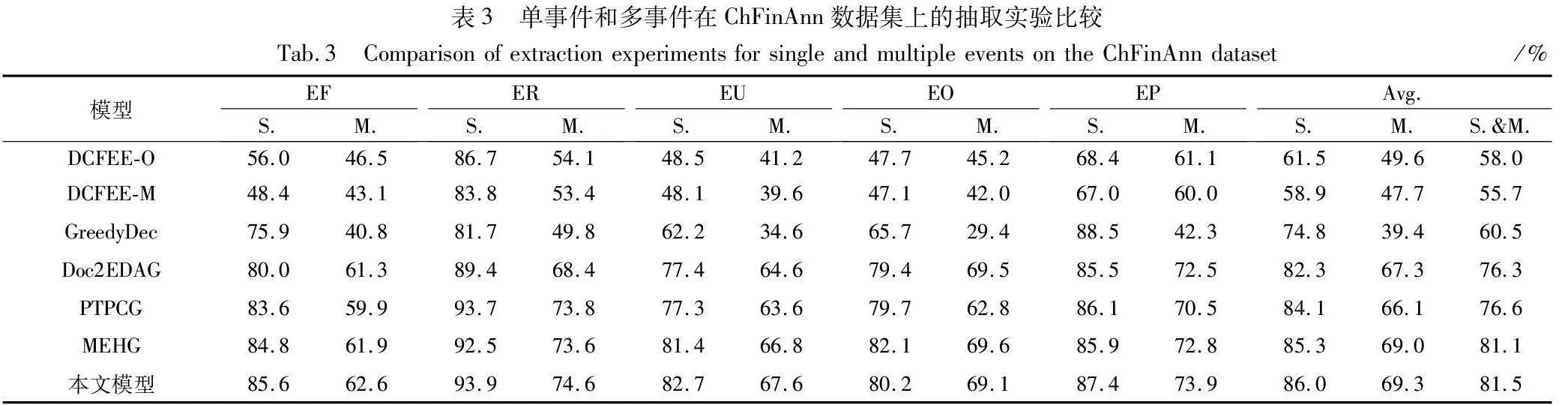
2.5.3 单事件和多事件抽取实验
为了进一步验证本文模型在ChFinAnn数据集上的每种事件类型下的F1综合表示,对文档级事件抽取任务的性能,本文将数据集分为单事件(S)和多事件(M)进行实验。具体方法是根据文档的索引对事件类型进行标记,单事件表示一个文档只涉及一个事件类型,而多事件表示一个文档涉及多个同类型或不同类型的事件,实验结果如表3所示。
所有模型在处理单事件文档时的性能普遍优于多事件文档。这一现象表明,文档中事件数量的增加给事件抽取任务带来了额外的复杂性。特别是对于多事件文档,事件之间可能存在相互作用和依赖,这要求模型不仅要能够识别出事件本身,还要准确理解和表示这些事件之间的关系。
特别是在处理多事件文档上,本文模型的优势更为明显。这一结果可能归因于模型采用了多粒度阅读器语义表示和滚雪球式的图注意网络,这些技术提高了模型对文档中不同粒度信息的捕获能力,以及对事件之间复杂关系的建模能力。多粒度阅读器能够从不同层次上理解文档,捕获从细节到整体的不同信息,这对于识别和区分文档中的单个或多个事件至关重要。滚雪球式的图注意力网络通过动态构建和更新论云之间的关系图,有效地增强了模型对论元间复杂相互作用的理解。这种方法有助于处理包含多个相关事件的复杂文档。
2.5.4 在DuEE-Fin数据集上的实验
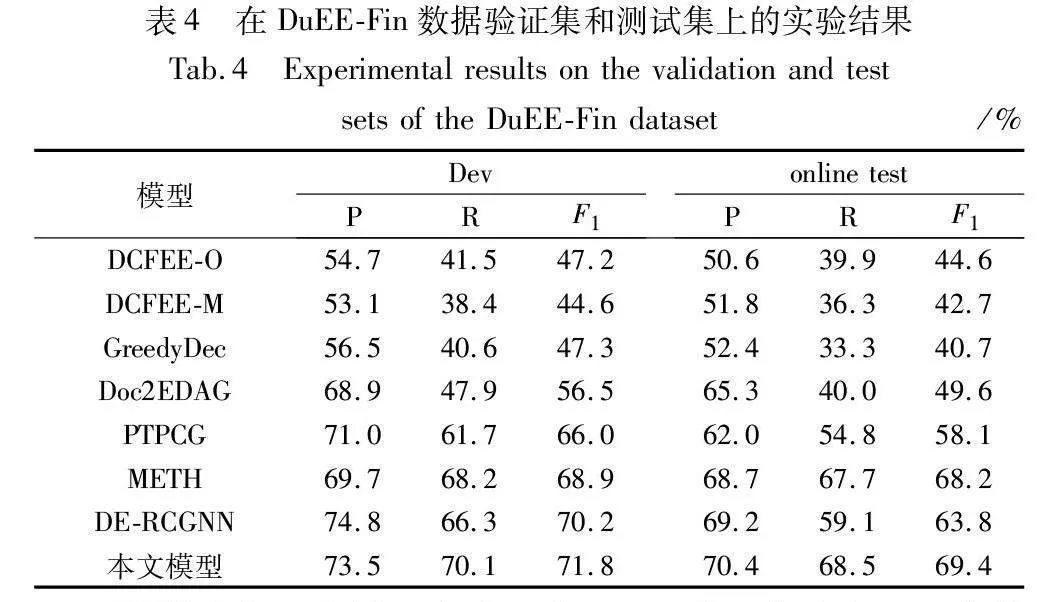
为了进一步验证本文模型的通用性,本文也在DuEE-Fin数据集上进行了实验,实验结果如表4所示。
从结果看,本文模型在验证集和测试集上都取得了最优的性能,这表明该模型在准确性、完整性和泛化能力方面均表现出色。这是由于模型可能采用了多粒度阅读器,能够同时捕获句子级和文档级的信息,从而提高了对文档全局语义的理解能力。这使得模型在处理论元分散和多事件问题时更为有效。通过图注意力网络,模型能够捕获论元对之间的复杂语义关系,全面丰富的语义表示有助于模型更准确地理解和抽取与事件相关的信息。
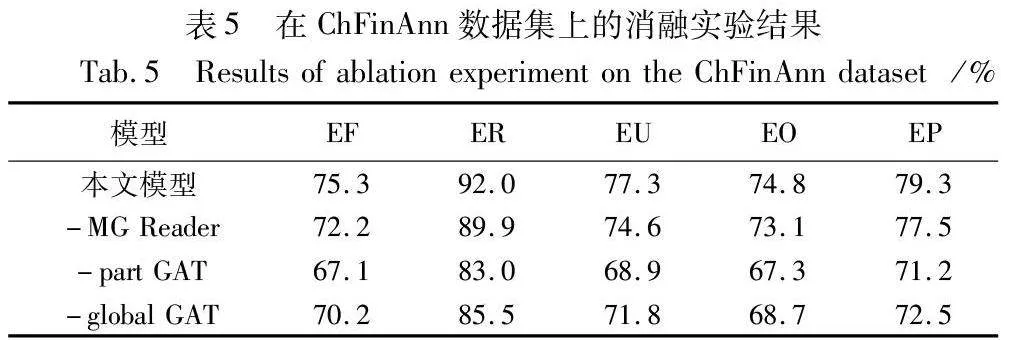
2.5.5 消融实验
为了进一步评估模型各个模块的贡献,本文进行了以下的消融实验,结果如表5所示。其中,-MG-reader表示去掉多粒度阅读器;-part GAT表示去掉局部图注意网络;-global GAT表示去掉全局图注意网络。
从表5的实验结果可以看出,在MGR-GATPCG模型的基础上去掉多粒度阅读器的语义表示模块后,EF、ER、EU、EO、EP的F1值分别下降了3.1、2.1、2.7、1.7、1.8百分点,反映了多粒度阅读器在提升文档编码的精细度和论元识别精度方面的关键作用。多粒度阅读器通过捕捉文档不同层次的语义信息,为模型提供了丰富的上下文表示,从而增强了模型对事件结构和论元关系的理解。去掉局部GAT模块后,EF、ER、EU、EO、EP的F1值分别下降了8.2、9.0、8.4、7.5、8.1百分点,F1值下降最多,局部GAT在促进句内论元与句间论元之间的语义编码和相互作用中发挥了至关重要的作用。局部GAT通过精细化的注意力机制,强化了模型对于句内外论元关系的捕捉,对于维护事件的内部一致性和上下文关联性至关重要。去掉全局GAT模块后,EF、ER、EU、EO、EP的F1值分别下降了5.1、6.5、5.5、6.1、6.8百分点。全局GAT的去除虽然对模型性能的影响略小于局部GAT,但仍然十分显著,特别是在提供全局语义信息和支持跨句子论元关系构建方面。全局GAT通过整合文档级别的信息,确保了模型能够理解和利用跨越多个句子的论元关系,对于处理文档中分散的、跨句子的论元及其相互作用极为关键。
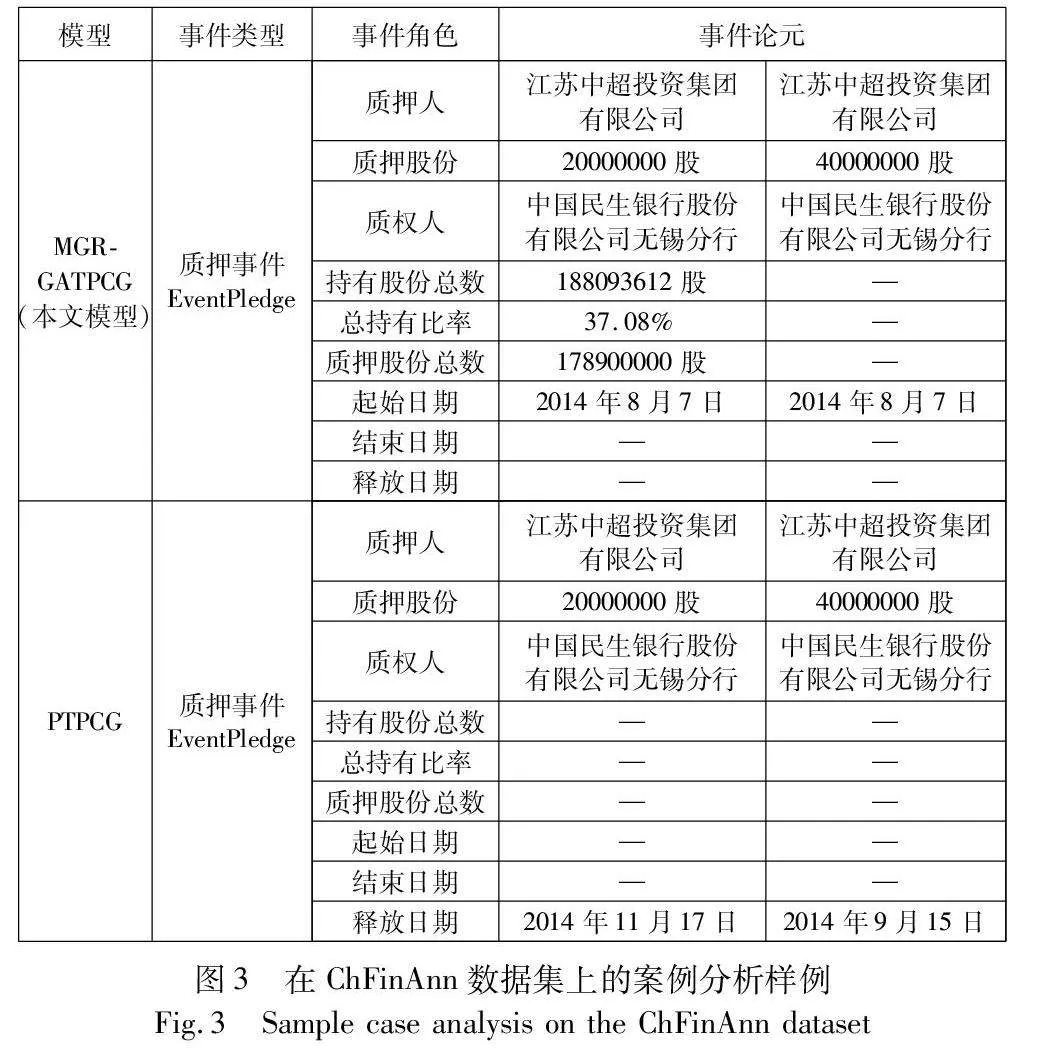
2.6 案例分析
为了进一步分析所提模型的效果,对本文模型MGR-GATPCG和PTPCG模型的图1股权质押(event pledge,EP)事件案例预测结果进行比较,如图3所示。从图中可以看出本文模型正确预测了持有股份总数、总持有比率、质押股份总数和起始日期的事件记录,而PTPCG预测不到起始日期、总持有比率等事件论元角色。将PTPCG模型的错误预测归为两类。首先,PTPCG未能充分考虑更多的上下文信息,降低了论元识别的精度,影响了最终事件抽取的效果;其次,PTPCG未能充分提取跨句之间论元的交互,不能帮助论元对获取更多语义信息。本文模型通过基于多粒度阅读器的语义表示和滚雪球的图注意力网络方法提升了论元识别的精度,从而促进了论元对的语义交互,提升了事件抽取的性能。
3 结束语
本文提出了一种基于多粒度阅读器的语义表示模型对文档进行不同粒度的编码,以获取更细致的语义信息,进而改善因抽取特征不充分而造成的事件类型及论元标签错误问题;采用滚雪球式的图注意网络方法对论元对进行局部编码和全局编码,增强了事件抽取的上下文语义表示,从而提升了论元识别和事件抽取性能。大量实验对比证明了本文模型的有效性。未来的工作中,将会进一步探索外部知识在事件抽取和论元识别任务上的应用。
参考文献:
[1]朱艺娜, 曹阳, 钟靖越, 等. 事件抽取技术研究综述[J]. 计算机科学, 2022,49(12): 264-273. (Zhu Yina, Cao Yang, Zhong Jingyue, et al. A review of event extraction technology[J]. Compu-ter Science, 2022, 49(12): 264-273.)
[2]赵宇豪, 陈艳平, 黄瑞章, 等. 基于跨度回归的中文事件触发词抽取[J]. 应用科学学报, 2023,41(1): 95-106. (Zhao Yuhao, Chen Yanping, Huang Ruizhang, et al. Chinese event triggered word extraction based on span regression[J]. Journal of Applied Science, 2023, 41(1): 95-106.)
[3]王人玉, 项威, 王邦, 等. 文档级事件抽取研究综述[J]. 中文信息学报, 2023, 37(6): 1-14. (Wang Renyu, Xiang Wei, Wang Bang, et al. A review of research on document level event extraction[J]. Journal of Chinese Information Processing, 2023, 37(6): 1-14.)
[4]Hang Yang, Chen Yubo, Liu Kang, et al. DCFEE: a document-level Chinese financial event extraction system based on automatically labeled training data[C]//Proc of ACL 2018, System Demonstrations. Stroudsburg, PA: Association for Computational Linguistics, 2018: 50-55.
[5]O’Shea K, Nash R. An introduction to convolutional neural networks [EB/OL]. (2015-12-02). https://arxiv.org/abs/1511.08458.
[6]Zheng Shun, Cao Wei, Xu Wei, et al. Doc2EDAG: an end-to-end document-level framework for Chinese financial event extraction[EB/OL]. (2019-09-23). https://arxiv.org/abs/1904.07535.
[7]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [EB/OL]. (2023-08-02). https://arxiv.org/abs/1706.03762.
[8]Xu Runxin, Liu Tianyu, Li Lei, et al. Document-level event extraction via heterogeneous graph-based interaction model with a tracker[EB/OL]. (2021-05-31). https://arxiv.org/abs/2105.14924.
[9]张虎, 张广军. 基于多粒度实体异构图的篇章级事件抽取方法[J]. 计算机科学, 2023, 50(5): 255-261. (Zhang Hu, Zhang Guangjun. Document-level event extraction based on multi-granularity entity heterogeneous graph[J]. Computer Science, 2023, 50(5): 255-261.)
[10]徐冰冰, 岑科廷, 黄俊杰, 等. 图卷积神经网络综述[J]. 计算机学报, 2020, 43(5): 755-780. (Xu Bingbing, Cen Keting, Huang Junjie, et al. Overview of graph convolutional neural networks[J]. Journal of Computer Science, 2020, 43(5): 755-780.)
[11]Zhu Tong, Qu Xiaoye, Chen Wenliang, et al. Efficient document-level event extraction via pseudo-trigger-aware pruned complete graph[EB/OL]. (2022-10-04). https://arxiv.org/abs/2112.06013.
[12]Sepp H, Jürgen S. Long short-term memory[J]. Neural Computer, 1997, 9(8): 1735-1780.
[13]葛君伟, 乔蒙蒙, 方义秋. 基于上下文融合的文档级事件抽取方法[J]. 计算机应用研究, 2022, 39(1): 48-53. (Ge Junwei, Qiao Mengmeng, Fang Yiqiu. Document level event extraction method based on context fusion[J]. Application Research of Computers, 2022, 39(1): 48-53.)
[14]张亚君, 谭红叶. 基于阅读理解与图神经网络的篇章级事件抽取[J]. 中文信息学报, 2023, 37(8): 95-103. (Zhang Yajun, Tan Hongye. Document-level event extraction based on reading comprehension and graph neural networks[J]. Journal of Chinese Information Processing, 2023, 37(8): 95-103.)
[15]Velickovic P, Cucurull G, Casanova A, et al. Graph attention networks[EB/OL]. (2017-10-30). https://arxiv.org/abs/1710.10903.
[16]陈佳丽, 洪宇, 王捷, 等. 利用门控机制融合依存与语义信息的事件检测方法[J]. 中文信息学报, 2020, 34(8): 51-60. (Chen Jiali, Hong Yu, Wang Jie, et al. Combination of dependency and semantic information via gated mechanism for event detection[J]. Journal of Chinese Information Processing, 2020, 34(8): 51-60.)
[17]Lafferty J D, McCallum A, Pereira F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]//Proc of the 18th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers Inc., 2001: 282-289.
[18]Forney G D. The Viterbi algorithm[J]. Proc of the IEEE, 1973, 61(3): 268-278.
[19]Huang Yusheng, Jia Weijia. Exploring sentence community for document-level event extraction[M]//Moens M F, Huang Xuanjing, Specia L, et al. Findings of the Association for Computational Linguistics: EMNLP 2021. Stroudsburg, PA: Association for Computational Linguistics, 2021: 340-351.
[20]Xu Bing, Wang Naiyan, Chen Tianqi, et al. Empirical evaluation of rectified activations in convolutional network[EB/OL]. (2015-05-05). https://arxiv.org/abs/1505.00853.
[21]Bron C, Kerbosch J. Algorithm 457: finding all cliques of an undirected graph[J]. Communications of the ACM, 1973, 16(9): 575-577.
[22]Bengio S, Vinyals O, Jaitly N, et al. Scheduled sampling for sequence prediction with recurrent neural networks[EB/OL]. (2015-06-09). https://arxiv.org/abs/1506.03099.
[23]Kinga D P, Ba J. A method for stochastic optimization[EB/OL]. (2014-12-22). https://arxiv.org/abs/1412.6980.
