基于Transformer交互指导的医患对话联合信息抽取方法
2024-08-15林致中王华珍










摘 要:针对电子病历构建过程中难以捕捉信息抽取任务之间的关联性和医患对话上下文信息的问题,提出了一种基于Transformer交互指导的联合信息抽取方法,称为CT-JIE(collaborative Transformer for joint information extraction)。首先,该方法使用滑动窗口并结合Bi-LSTM获取对话中的历史信息,利用标签感知模块捕捉对话语境中与任务标签相关的信息;其次,通过全局注意力模块提高了模型对于症状实体及其状态的上下文感知能力;最后,通过交互指导模块显式地建模了意图识别、槽位填充与状态识别三个任务之间的交互关系,以捕捉多任务之间的复杂语境和关系。实验表明,该方法在IMCS21和CMDD两个数据集上的性能均优于其他基线模型和消融模型,在处理联合信息抽取任务时具有较强的泛化能力和性能优势。
关键词:联合信息抽取; 医患对话; 电子病历; 多任务学习
中图分类号:TP391.1 文献标志码:A
文章编号:1001-3695(2024)08-010-2315-07
doi:10.19734/j.issn.1001-3695.2023.12.0591
CT-JIE: collaborative Transformer for joint information extractionfrom patient-doctor dialogues
Lin Zhizhong, Wang Huazhen
(School of Computer Science & Technology, Huaqiao University, Xiamen Fujian 361000, China)
Abstract:Addressing the challenges of capturing the correlation between information extraction tasks and the contextual information in doctor-patient dialogues during electronic medical record construction, this paper proposed a Transformer-based collaborative information extraction method called CT-JIE(collaborative Transformer for joint information extraction). Firstly, this method utilized a sliding window combined with Bi-LSTM to acquire historical information from the dialogues and employed a label-aware module to capture task-related information in the dialogue context. Secondly, the global attention module enhanced the model’s ability to perceive the context of symptom entities and their status. Finally, the interactive guidance module explicitly modeled the interaction among intent recognition, slot filling, and status recognition tasks to capture the complex contexts and relationships among multiple tasks. Experiments demonstrate that this method outperforms other baseline and ablation models on the IMCS21 and CMDD datasets, showing strong generalization ability and performance advantages in handling joint information extraction tasks.
Key words: joint information extraction; medical dialogues; electronic medical record; multi-task learning
0 引言
在现代医疗信息系统中,电子病历(electronic medical record,EMR)作为一种重要的信息载体,广泛应用于医疗实践中。电子病历记录了患者的临床信息,通常包含多个条目,如主诉、现病史、既往史、辅助检查、诊断和建议等。在电子病历的构建过程中,医生需从医患对话中准确识别出医学信息,判断其所属的条目类别并将其归类到相应的条目下。尽管将医患对话转换为电子病历是医生的基本职责,但这一过程却常常费时费力[1],还要求医生具备较高的分析能力和归类能力[2]。因此,电子病历信息的自动抽取研究成为了新兴的研究领域。
从医患对话中抽取电子病历信息的过程中,医学实体抽取主要涉及对症状、药物、药物类别等实体的准确辨识,意图识别用于将对话文本正确分类到电子病历的条目体系之中,呈现出多对一的意图-条目映射关系。与其他领域对话不同的是,医患对话文本具有更为复杂的实体状态信息。实体阴阳性是基于医患对话上下文后对实体的状态进行的总结,其分为阳性、阴性和不确定三种类别。阳性表示患者自述已出现该症状、疾病等相关或是医生对患者的诊断;阴性则代表患者未患有疾病、症状等相关;而不确定则表示医患对话中未知的实体状态信息。以图1中的对话为例,患者在对话中明确提到自己有咳嗽的症状,因此该症状实体的状态为阳性。
在传统的信息抽取中,独立处理这些任务可能导致信息孤立,从而忽略了它们之间的内在关联性。因此,采用联合信息抽取技术成为解决这一挑战的有效手段。与传统的单一任务处理方法不同,联合信息抽取技术将多个相关任务结合在一起,以便在处理文本时更好地捕捉任务之间的关联性和上下文信息。其主要挑战在于如何加强多个任务之间的交互,进而利用多个任务之间的潜在信息来提升信息抽取的性能。过去的研究采用了共享编码器的多任务框架[3,4],通过共享编码器来同时捕捉任务之间的共享特征,从而在性能上超越了传统的流水线框架。然而,这些方法虽然通过相互增强的方式在一定程度上提高了性能,但仅仅通过共享参数来隐式地建模任务之间的关系。文献[5~7]则显式地将意图信息应用于引导槽位填充任务,取得了先进的性能。但这些方法仅考虑了单向的信息流,未能充分挖掘多个任务之间的交互信息。
与此同时,另一个关键的问题在于传统的方法缺乏一种可靠的机制来有效地捕捉对话之间的上下文相关性信息,以通过对话上下文推断实体的状态。在医患对话中,每一轮对话都会对任务的执行产生影响,对话中的语境信息对于正确理解和抽取信息至关重要。以图1中对话为例,医生询问患者“宝宝平时会打喷嚏吗”,现有的医学信息抽取模型往往只是简单地将槽位与槽值实体抽取为(“症状名”“打喷嚏”),忽视了医学实体的否定信息“不会”,可能会导致错误的信息抽取。因此,医疗领域的医学实体抽取不仅需要捕获实体的存在,还应考虑对话句子上下文之间的关联信息,以抽取实体的阴阳性作为实体的状态辅助信息来准确地刻画实体的存在与否。Vaswani等人[8]提出了一种基于自注意力机制的神经网络Transformer,通过引入自注意力机制来捕捉输入序列中各个位置之间的依赖关系,在多个自然语言处理任务中取得了突破性进展。基于Transformer结构的模型[9]能够有效地处理长距离依赖关系,更好地理解输入序列的上下文信息。
为解决上述两个问题,本文提出了一种基于Transformer交互指导的联合信息抽取模型CT-JIE(collaborative transformer for joint information extraction)。CT-JIE模型主要由三个模块构成,分别为标签感知模块、全局感知模块和交互指导模块。采用IMCS21与CMDD数据集来验证CT-JIE模型在联合信息抽取上的有效性。本文的贡献主要包括以下几个方面:
a)提出了一个基于Transformer交互指导的联合信息抽取模型CT-JIE,通过充分利用医患对话中的意图识别、槽位填充及状态识别等多个任务之间的交互信息,增强了任务输出层的表示能力。
b)采用滑动窗口技术与全局注意力机制,使得模型能够更好地捕获医患对话中的全局上下文信息,以提高多个任务的性能表现。
c)在IMCS21和CMDD数据集上进行了多方面的实验,结果显示CT-JIE模型在各项性能指标上均优于所选的单任务信息抽取模型和双任务信息抽取模型。此外,还进行了消融实验,以更深入地理解CT-JIE的模型设计,证实了其中关键组件的有效性。
1 相关工作
1.1 基于多任务的联合信息抽取技术研究
基于多任务学习的联合信息抽取是一种常见的抽取方法,它将不同子任务视为不同的学习任务,并在一个统一的框架下进行优化和训练。多任务学习可以有效地利用不同任务之间的共享特征和互补信息,从而提高模型的泛化能力和下游任务的性能指标。现有联合抽取模型总体上有两大类[10]:基于共享参数的联合信息抽取模型和基于联合解码的联合信息抽取模型。基于共享参数的联合信息抽取模型是指在不同子任务之间共享一部分或全部的模型参数,从而实现特征共享和知识迁移。Miwa等人[11]提出了一种基于LSTM的端到端关系抽取方法,通过共享LSTM参数来处理实体提取和关系抽取两个任务,将文本中的实体和关系同时进行建模和抽取。Katiyar等人[12]提出了一种在没有依赖树的情况下进行实体提取和关系抽取的联合模型,通过共享卷积神经网络的参数,同时处理实体和关系的抽取任务,从而实现特征共享和模型简化。共享参数的设置使得模型能够在两个任务之间共享上下文信息,从而提高了模型的性能和泛化能力。Zeng等人[13]提出了一种基于seq2seq框架的联合抽取模型,并引入复制机制来生成多对三元组。Bekoulis等人[14]将实体识别和关系抽取视为一个多头选择问题,并提出了一种共享参数的联合模型。通过使用多头注意力机制来处理实体和关系之间的交互关系,并通过共享参数来增强两个任务之间的关联性。除了基于共享参数的联合信息抽取模型外,还存在一类基于联合解码的方法,旨在通过联合解码的方式更加紧密地捕捉实体和关系之间的语义关联。Katiyar等人[15]利用条件随机场同时建模实体和关系模型,并通过维特比解码算法得到实体和关系的输出结果。Li等人[16]将实体关系抽取看作是一个结构化预测问题,采用结构化感知机算法设计了全局特征,并使用集束搜索进行近似联合解码。Zhang等人[17]提出使用全局归一化解码算法,通过在解码阶段引入全局优化机制,将实体提取和关系分类任务紧密耦合在一起,从而在捕捉关联信息的同时提高了抽取任务的准确性。Wang等人[18]设计了一种新颖的图方案,将联合任务转换为一个有向图,并针对实体关系抽取设计了一套转移系统,从而实现联合实体关系抽取。
综上所述,基于多任务学习的联合信息抽取模型在处理信息抽取任务中表现出了巨大的潜力。这些模型通过将不同子任务统一到一个框架下,有效地利用了任务之间的相关性和共享信息,提高了模型的性能和泛化能力。
1.2 医患对话文本的信息抽取
医患对话文本蕴涵着丰富的医疗信息,这些信息对于医生和患者都至关重要。为了更好地挖掘这些信息,研究人员已经进行了大量相关工作。实体抽取是医患对话文本信息抽取的首要任务之一,它的目标是从对话文本中识别出医学领域相关的实体,例如症状、疾病、药物等,并对它们进行类型和边界的明确标注。Kannan等人[19]采用了半监督学习的策略,结合有标签的实体信息和无标签的对话内容,构建了更加鲁棒和高效的医学实体抽取模型。Peng等人[20]充分利用医患对话文本中的信息,将对话内容与医疗保险相关的实体抽取出来,从而归纳出有关医疗保险的重要信息。扈应等人[21]提出一种结合CRF的神经网络边界组合方法,结合生物医学领域的特征信息进行生物医学命名实体抽取。Zhang等人[22]针对医患对话文本,设计了一种能够识别医学实体、提取关联信息并生成结构化记录的医疗信息提取器。医患对话文本信息抽取的另一个重要的研究方向是主题识别,即从对话中抽取出患者的主诉、既往史、诊断结果等内容,为电子病历的生成提供了有力支持。Song等人[23]提出了一种分层编码-标注器模型,从患者和医生的发言中抽取出有关的问题描述、诊断、治疗和其他等对话句子文本,由此识别并提取出重要发言生成对话摘要。Krishna等人[24]研究了如何从医患对话中抽取出与每个SOAP笔记相关的句子,并组合为SOAP笔记的不同部分。
此外,由于医患对话的多轮性特点,使得信息抽取模型无法很好地分辨对话者所述的内容是否完全真实可靠,所以也有大量的学者聚焦于医学症状实体的状态识别研究工作中。早在2019年,Du等人[25]就提出通过提取症状以及其对应的状态来对医患对话进行医学信息抽取,要求抽取的每个症状与阳性、阴性和不清楚三个状态相关联。Lin等人[26]提出了一个全局注意力机制来捕获医患对话中的症状实体与其对应的状态,并通过构建症状图来建模症状之间的关联。第七届中国健康信息处理会议(CHIP2021)和第一届智能对话诊疗评测比赛(CCL2021)也分别提出了医学实体症状识别的任务,不仅发布了相关的大型医疗数据集,也进一步引发了学者的研究兴趣。与仅从医学对话中提取症状和状态不同,Zhang等人[22]进一步定义了症状、检查、手术和其他信息四类,还定义了每个类别和每个项的状态。他们以窗口滑动的方式对对话进行注释,提出了一种深度神经匹配网络来提取对话中的医学信息。Hu等人[27]提出了一种上下文感知信息提取器CANE,采用局部到全局的机制来建模对话句子之间的上下文联系,有效地抽取出了医患对话中的医学实体项与其状态信息。
综上所述,医患对话文本的信息抽取在医学领域发挥着重要作用,包括实体抽取、主题识别和实体状态识别等任务,有助于将医患对话中的非结构化文本转换为结构化的医学信息,为电子病历生成、医疗决策支持等应用领域提供了有力的数据支持。
2 基于Transformer交互指导的联合信息抽取模型
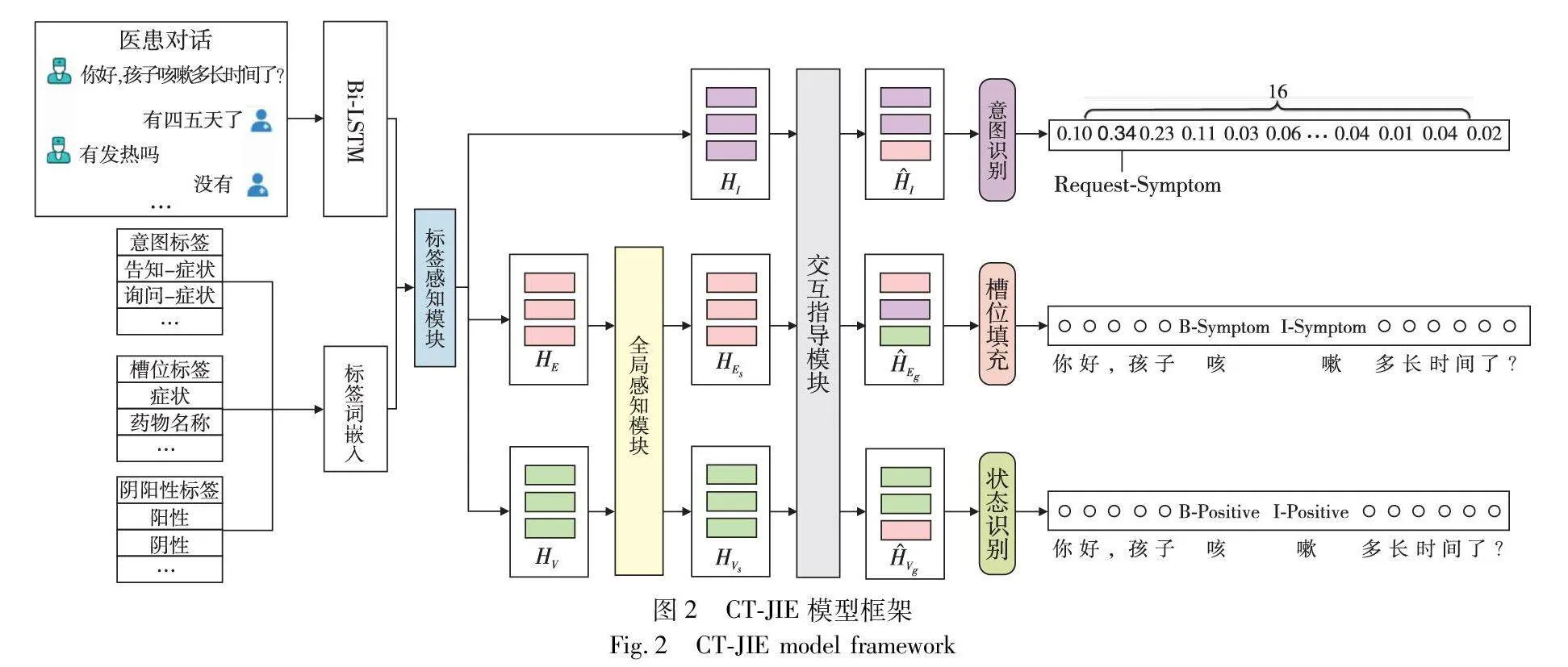
CI-JIE模型架构如图2所示,主要由标签感知模块、全局感知模块和交互指导模块三个模块组成。a)标签感知模块旨在通过注意力机制捕捉对话语境中与任务标签相关的信息,以获得针对性的语义编码表示;b)全局感知模块旨在捕捉目标句子中症状实体与其状态受整个对话样本上下文的影响,通过引入动态注意力机制,对不同对话窗口之间的全局关联性进行建模,从而获取更丰富的上下文信息;c)交互指导模块以Transformer为架构,采用协同交互注意力层代替原生Transformer中的自注意力机制。通过多个任务的交互感知计算,实现了任务表示向量的互相增强。最后,分别针对意图识别、槽位填充和状态识别进行解码,联合输出医患对话文本中的对话意图、医学实体及其对应的状态。
2.1 标签感知模块
本文信息抽取模型的输出形式为标签词典预测向量,即向量中每个维度值是由信息抽取模型的当前输入数据实例来决定的。本文使用滑动窗口方法来为对话样本构建对话窗口,同时通过注意力机制捕捉对话语境中与特定标签相关的信息,从而获得更有针对性的语义编码表示。
给定医患对话样本D=(X1,X2,…,Xn),其中n为对话样本中对话句子的数量,Xi表示医生或患者所述的句子。针对目标句子Xi及其历史句子构建一个固定大小为L的对话窗口Pi={Xi,Xi-1,…,Xi-L+1}。如果i<L,则在对话窗口内填充空字符串,从而可将医患对话样本D构建成一系列的对话窗口{P1,P2,…,Pn}。如图3所示,针对目标句X4和X5分别构建其对话窗口,滑动窗口的滑动步长为1。
之后再将对话窗口Pi内的每一个句子进行拼接后得到XTW=(x1,x2,…,xT),其中T为输入文本的字符数。将XTW送入Bi-LSTM层获得窗口对话文本的输出向量hTW,作为目标句子的语义编码表示。接着将对话意图、槽位实体和状态标签词典分别进行嵌入,获得对话意图标签词典矩阵WI∈Rd×Ilabel,槽位实体标签词典矩阵WE∈Rd×Elabel和状态标签词典矩阵WV∈Rd×Vlabel,其中d代表维度,Ilabel、Elabel、Vlabel分别代表意图标签、槽位标签和状态标签的数量。然后通过注意力机制来捕捉目标句子语义编码在标签词典上的注意力分布,使模型能够在对话窗口文本的基础上关注特定标签词典中与目标句子相关的信息。分别得到意图、槽位实体和状态的标签词典感知表示计算公式HI、HE和HV,如式(1)和(2)所示。
A=softmax(hTWW)(1)
H=hTW+AW(2)
其中:W是标签词典的嵌入矩阵。
2.2 全局感知模块
目标句子中症状实体的状态不仅由当前对话窗口的上下文决定,还会受到后续对话窗口中相关信息的影响。因此本文引入动态注意力机制探究对话窗口之间的全局关联性,捕获整个对话样本之间的上下文信息。例如,在当前对话窗口中提及“胸痛”,那么模型将在后续的对话窗口中为“胸痛”以及如“我有”“我曾患有”等关于状态的描述词分配较高的注意力值,给当前窗口的实体与状态判别提供更有针对性的语境信息。具体做法如下,首先将第i个对话窗口{Xi,Xi-1,…,Xi-L+1}的状态标签词典感知表示HVi与后续对话窗口的状态标签词典感知表示{HVi+1,…,HVM}进行注意力分数的计算,如式(3)和(4)所示。
sij=HTViWgHVj(3)
aij=softmax(sij)(4)
其中:j=1,2,…,M,M为第i个对话窗口的后续对话窗口的数量;Wg是可训练的矩阵参数。
在动态注意力机制中,注意力分数越高,表示两者具有更高的相关性,关注注意力分数高的窗口也会帮助模型捕捉到整个对话样本中全局上下文更为关键的信息。因此本文首先找到注意力分数最高的后续窗口,然后将其状态标签词典感知表示HVg与当前窗口的状态标签词典感知表示HVi进行相加,得到状态标签词典全局感知表示HVs,如式(5)和(6)所示。
HVg=HVargmaxj(aij)(5)
HVs=HVi+HVg(6)
其中:如果当前窗口为对话样本中的最后一个窗口,即M=0时,HVg将被设定为零向量。与此类似,再将当前对话窗口的槽位实体标签词典感知表示HEi与后续对话窗口进行同上述一样的操作,得到槽位实体标签词典全局感知表示HEs。
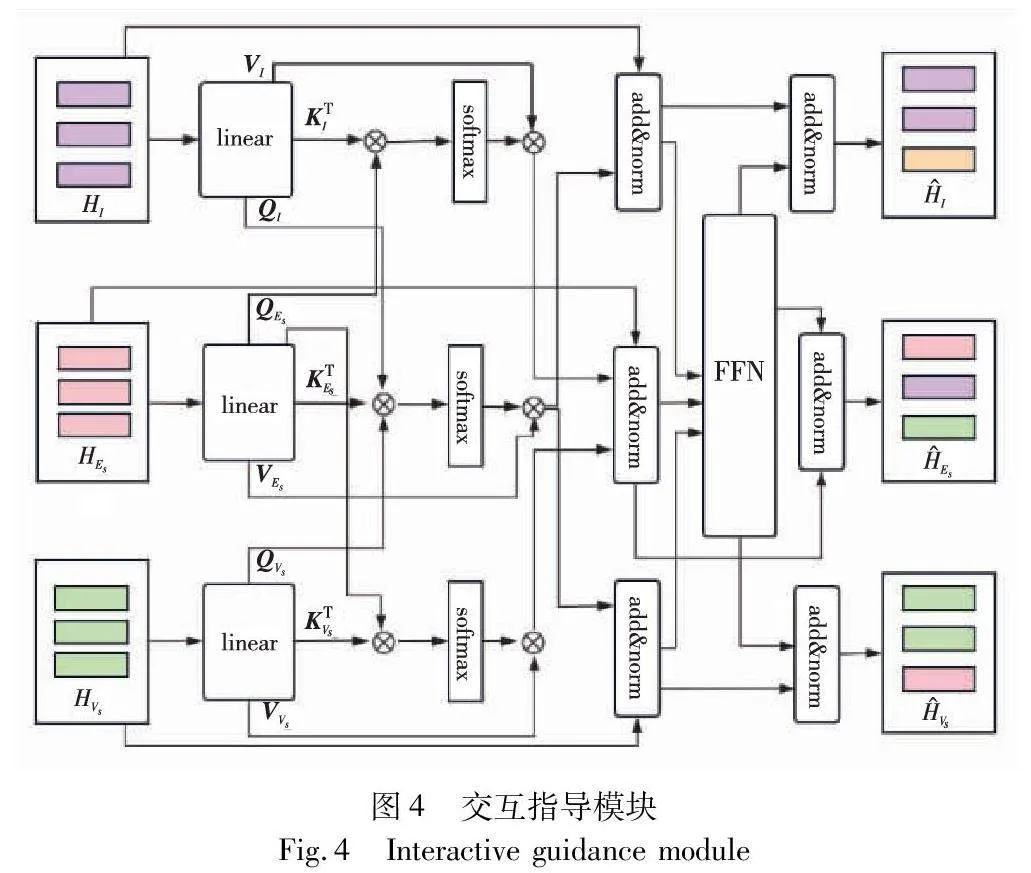
2.3 交互指导模块
在原生的Transformer中,每个子层都由自注意力和前馈网络层组成。通过自注意力机制,Transformer能够在输入序列中建立全局的依赖关系,使得每个位置的表示能够考虑整个序列的信息。然而,在处理多任务场景时,这种全局依赖性无法充分捕捉不同任务之间的局部关联性。因此,本文提出一个以Transformer为基础架构的设计,其中引入了协同交互注意力层替换传统Transformer中的自注意力机制,旨在通过显示建模多个任务之间的交互关系,构建多个任务之间的多向连接。这种协同交互的方式使得任一任务表示向量的更新都受到其他两个任务的影响,能够更充分地利用不同任务之间的语境和关联信息。同时,针对前馈网络进行改进,隐式地融合共享多个任务之间的信息。具体技术图如图4所示。
与Transformer相同,首先通过不同类型的线性投影函数,将标签词典感知表示HI、HEs与HVs投影为QI,QEs,QVs=queries(HI,HEs,HVs)、KI,KEs,KVs=keys(HI,HEs,HVs)和VI,VEs,VVs=values(HI,HEs,HVs)。为获取槽位表示并融合相应的意图信息,以QI作为查询向量,KEs作为键向量,VEs作为值向量,利用注意力机制计算注意力分数,得到对槽位感知的意图表示CI。
CI=softmax(QIKTEsd)VEs(7)
其中:d代表查询向量QI的维度。接着将CI加到原始的意图表示HI上进行层归一化操作,得到与槽位信息进行交互注意力计算后的意图表示H′I,如式(8)所示。
H′I=LN(HI+CI)(8)
其中:LN(·)代表层归一化。同样,为了使得状态表示能够受到槽位信息的影响,将QVs作为查询向量,KEs作为键向量,VEs作为值向量来获取槽位感知的状态表示H′Vs。在交互指导的过程中,槽位的表示会同时受到意图与状态的影响。因此,在获取槽位的增强表示时应对意图和状态都进行感知计算。然后将计算后的包含意图信息的槽位表示HIEs与包含状态信息的槽位表示HVEs相加后得到槽位表示H′Es,如式(9)所示。
H′Es=HIEs+HVEs(9)
最后,通过前馈网络FFN隐式地融合多个任务的信息,再将H′I、H′Es和H′Vs分别与FFN(HISV)拼接得到最终输出的意图表示H^I、槽位表示H^Es和状态表示H^Vs,如式(10)~(13)所示。
HISV=H′I⊕H′Es⊕H′Vs(10)
H^I=LN(H′I+FFN(HISV))(11)
H^Es=LN(H′Es+FFN(HISV))(12)
H^Vs=LN(H′Vs+FFN(HISV))(13)
2.4 联合训练
对于意图识别任务,采用交叉熵损失函数作为损失函数:
Lossintent=-∑iyi·log(pi)(14)
其中:yi是真实的意图标签字典向量;pi是模型预测的意图概率向量,其维度是意图类别数量Ilabel。
对于槽位填充与状态识别任务,引入CRF层作为标签序列识别器输出槽位实体的预测向量P(y^s|Os)以及状态的预测向量P(y^v|Ov),如式(15)~(18)所示。
Os=WSH^Es+bEs(15)
P(y^s|Os)=∑i=1escore(y^si-1,y^si,Os)∑ys∑i=1escore(ysi-1,ysi,Os)(16)
Ov=WVH^Vs+bVs(17)
P(y^v|Ov)=∑i=1escore(y^vi,y^vi-1,Ov)∑yv∑i=1escore(yvi-1,yvi,Ov)(18)
其中:P(y^s|Os)为给定观测序列Os下标注序列y^s的概率向量,其计算公式中的score为标签ysi-1到ysi的状态转移得分;P(y^v|Ov)为给定观测序列Ov下标注序列y^v的概率向量,其计算公式中的score为标签yvi-1到yvi的状态转移得分。
采用最小化负似然对数来计算槽位填充和状态识别的损失,如式(19)和(20)所示。
Lossslot=-log(P(y^s|Os))(19)
Lossstatus=-log(P(y^v|Os))(20)
最后,采用动态权重平均的方法[28]计算出意图识别、槽位填充与状态识别在当前时间步的权重wintent、wslot和wstatus。获得最终的损失Losstotal,如式(21)所示。
Losstotal=wintent·Lossintent+wslot·Lossslot+wstatus·Lossstatus(21)
在不同训练阶段将使用不同的权重分配,即较大损失的任务在权重中会占据更大的比例,以便更多地影响模型参数的更新。针对Losstotal进行优化迭代计算,直至达到停止条件,从而获得基于Transformer交互指导的联合信息抽取模型 CT-JIE。
3 实验与分析
3.1 实验设置
本文采用预训练的skip-gram[29]嵌入向量进行中文字符的嵌入表示,维度为300。采用的Bi-LSTM隐藏层是128维,前馈网络是300维,优化器是RAdam[30]。此外,还采用早停策略和动态损失的优化策略。
3.2 数据集
本文实验在智能对话诊疗数据集(IMCS21)[31]与中文医学诊断数据集(CMDD)[26]上进行。IMCS21数据集被选用以全面验证模型的整体抽取性能,充分评估模型在意图识别、槽位填充和状态识别等多个任务上的表现。CMDD数据集则被用于深入研究模型在槽位实体与其状态联合抽取的准确性。
3.2.1 IMCS21数据集
IMCS21数据集收集了真实的在线医患对话,并进行了多层次的人工标注,包括槽位实体、对话意图、症状状态标签等,其中实体类型数量为5,对话意图类型数量为16,症状状态标签包含阴性、阳性和不确定三种状态,样本集规模为4 116个医患对话样本。IMCS21数据集信息汇总如表1所示。
3.2.2 CMDD数据集
在本文中,将CMDD数据集转换为滑动窗口的对话格式,参照Hu等人[27]的设置,将窗口大小设置为5。处理后的CMDD数据集包含2 067个对话和87 005个对话窗口,涵盖了160个症状,其中每个症状都包含阳性、阴性与未知三种状态。
3.3 基线模型
为了对意图识别、槽位填充和状态识别三任务联合信息模型CT-JIE进行对比研究,本文选择单任务信息抽取模型,另外还引入聚焦意图识别和槽位填充的双任务联合信息模型进行对比。基线模型信息如下所述。
3.3.1 单任务信息抽取模型
本文选择多个单任务信息抽取模型分别在IMCS21与CMDD数据集上进行对比实验,具体信息如表2所示。
3.3.2 意图识别和槽位填充的双任务联合信息模型
实验采用的双任务信息抽取模型具体信息如表3所示。
3.4 实验结果
3.4.1 CT-JIE的联合信息抽取性能展示
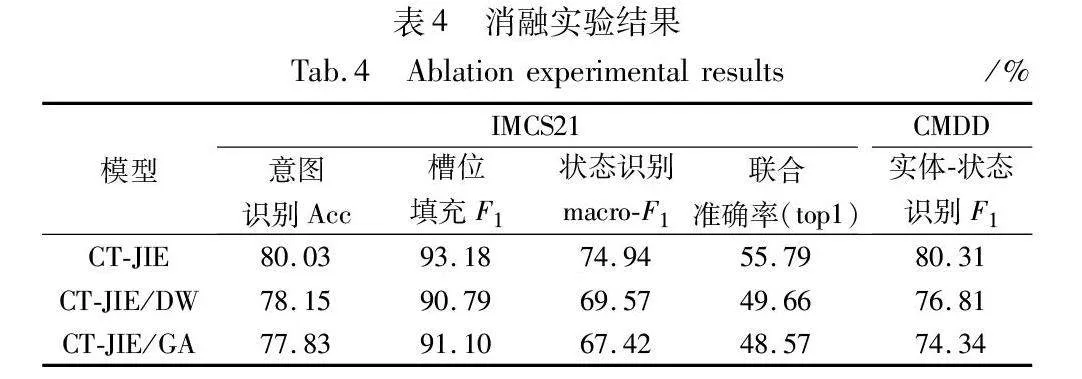
在本节中,首先通过消融实验来评估CT-JIE模型的有效性。实验分别在IMCS21与CMDD数据集上进行。消融实验结果如表4所示。其中,CT-JIE/DW指的是从CT-JIE模型中去除滑动窗口技术,CT-JIE/GA指的是从CT-JIE模型中去除全局感知模块。
表4中的结果表明,去除滑动窗口的输入形式会导致CT-JIE模型在IMCS数据集上意图识别的accracy、槽位填充的F1值和状态识2acf7862bbd45990af4c0a3a8a25c426别的macro-F1值分别下降1.88、2.39和5.37百分点,在CMDD数据集上的实体-状态联合识别的F1值下降3.50百分点。这是因为通过窗口整合多句文本进行输入,可以有效地获得目标句的历史信息。此外,如果不进行全局注意力机制计算,模型性能在IMCS数据集上会下降2.20、2.08和7.52百分点,在CMDD数据集上会下降5.97百分点。这说明全局注意力对状态识别任务有着较大的提升,因为它将下文中最具信息的窗口嵌入到当前的窗口,以帮助窗口捕捉状态的变化。
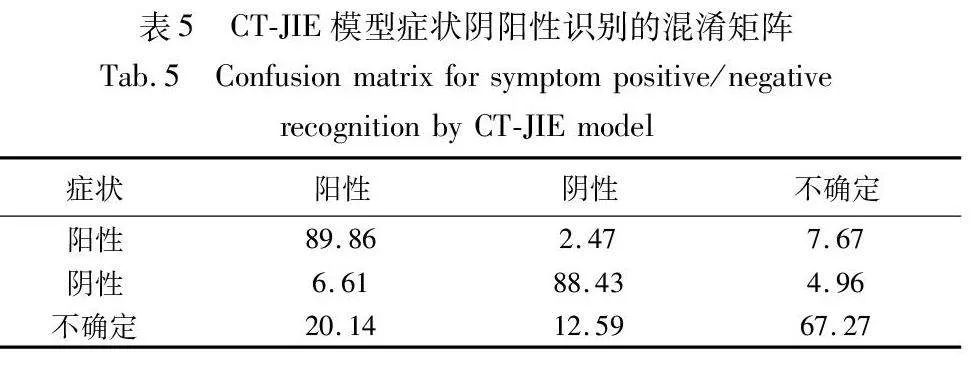
接着通过混淆矩阵进一步评估CT-JIE模型的有效性。采用IMCS数据集上的验证集数据对症状阴阳性识别任务进行分析,预测结果的混淆矩阵如表5所示。从混淆矩阵性能展示结果看,数值越高代表类别分类效果越好。观察可知,模型针对“不确定”类别的判别准确率较低,主要是因为数据集样本中包含“不确定”的信息较少,模型很难学习到完整的特征。模型在“阳性”与“不确定”之间的误分类占比最大,在阴阳性之间的误分类情况较少,证明模型能够有效判断阴阳性。
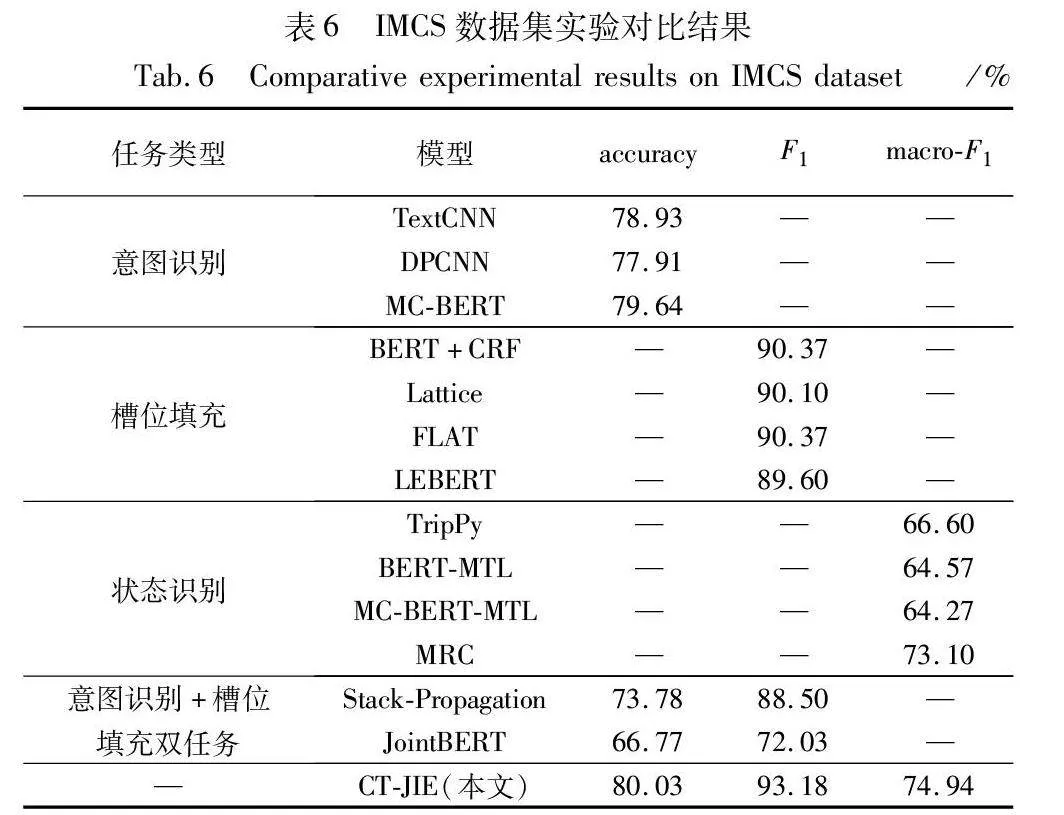
3.4.2 CT-JIE与基线模型的对比展示
表6和7分别展示了CT-JIE模型与基线模型在IMCS21和CMDD数据集上的性能指标的对比结果。
从结果上来说,可以得到以下观察结果:
a)从整体的实验结果上来看,CT-JIE模型在IMCS数据集上的意图识别accuracy、槽位填充F1值和状态识别的macro-F1为80.03%、93.18%和74.94%,均超过了对比的基线模型。同时,CT-JIE模型在CMDD数据集上的实体-状态识别任务F1为80.31%,在实体-状态的联合识别中取得了较好的性能,证明本文模型的有效性。
b)CT-JIE模型相较于单任务的基线模型的性能提升微弱,这一现象可以解释为CT-JIE模型的设计重点放在了多任务联合信息的抽取上,而单任务基线模型更专注于各自任务的性能。CT-JIE模型的联合信息抽取结构可能会引入一定的复杂性和冗余性,使得模型在单任务性能上的提升受到限制。
c)CT-JIE模型相较于双任务模型有着不错的性能提升,这是因为CT-JIE模型引入了交互指导模块,使得CT-JIE模型充分利用了任务之间的信息交互。此外,实体-状态识别实验也展示出状态阴阳性识别与槽位填充之间存在一定的关联性,CT-JIE模型的设计允许这两个任务之间的信息共享和交互,从而使得模型的整体性能得到提升。
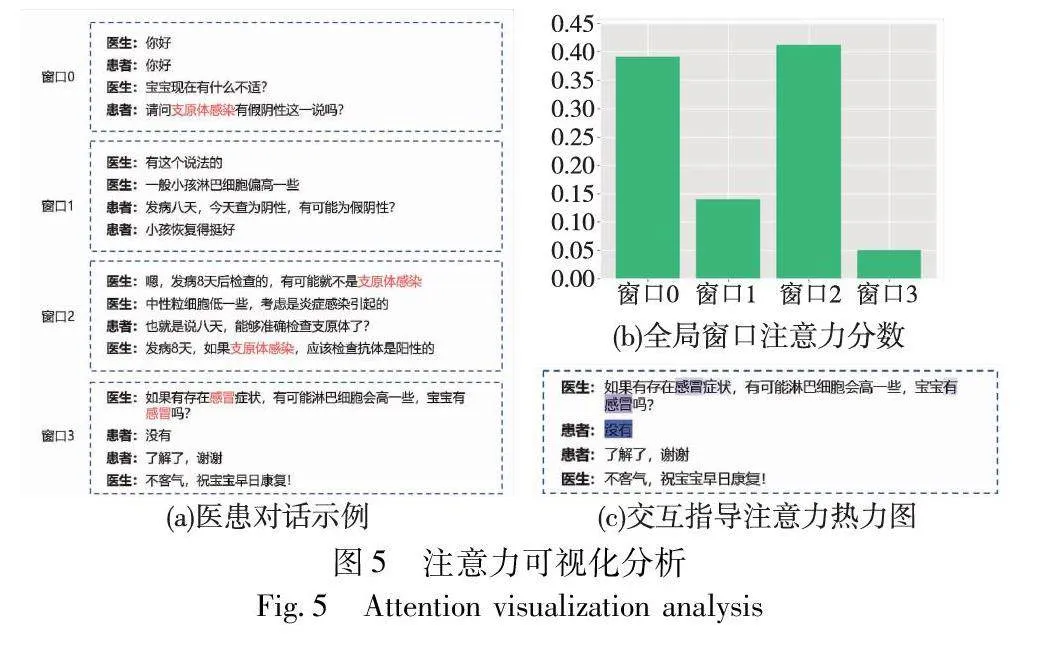
3.4.3 模型注意力可视化
本文使用可视化技术展示CT-JIE模型在一个预测样本上的全局注意力效果。图5(a)展示了预测的医患对话样本示例,其中窗口0代表当前的输入窗口对话,窗口1~3为后续窗口。通过全局注意力机制计算当前窗口和后续窗口之间的交互注意力分数,结果如图5(b)所示。观察可知,窗口2与当前窗口有着最高的交互注意力分数,能够有效地帮助当前窗口0针对“支原体感染”的阴阳性状态进行预测,有效地提高了预测的上下文感知能力,而传统的方法在不考虑窗口2的情况下很难在此种情况下进行准确的预测。如窗口0中患者针对“支原体感染”这一症状产生疑问,并不能直接根据当前窗口来判别“支原体感染”的发生状态。而在结合窗口2中提示的“有可能就不是支原体感染”后,模型能够有效地判别“支原体感染”为“阴性”。同时,本文还探究了同一窗口内槽位实体与状态阴阳性通过交互指导后的关联性,注意力权重的热力图如图5(c)所示。在窗口3中,医生所述的“感冒”与后续患者的回答“没有”的注意力值相对较高,说明模型在窗口中能够正确捕获实体与状态之间的联系。
4 结束语
本文研究了医学信息抽取任务中的多个关键问题,包括意图识别、槽位填充和状态识别,以及它们之间的共享特征和互补信息等特性。通过对这些问题的深入研究和探索,本文提出了一种基于Transformer交互指导的联合信息抽取模型CT-JIE。CT-JIE通过滑动窗口和Bi-LSTM结合的方式获取对话上下文信息,并利用标签感知、全局注意力和交互指导模块实现了意图识别、槽位填充和状态识别任务的协同学习。本文在IMCS21和CMDD数据集上进行了广泛的实验,结果表明CT-JIE模型较其他的单任务与双任务信息抽取模型在意图识别、槽位填充和状态识别多个任务上均取得了较好的性能提升。本文展示了多任务交互指导方法在医学信息抽取任务中的优越性能,将为医疗信息处理领域的智能化和自动化提供更强的支持和推动,为医患对话的信息抽取、电子病历的撰写和医学自然语言处理的研究等方面带来积极的影响。
参考文献:
[1]Wachter R, Goldsmith J. To combat physician burnout and improve care, fix the electronic health record[EB/OL].(2018-03-30). https://hbr.org/2018/03/to-combat-physician-burnout-and-improve-care-fix-the-electronic-health-record.
[2]陆志敏, 陆萍. 全科医生岗位胜任力指标的探索性分析[J]. 中国全科医学, 2019, 22(28): 3495. (Lu Zhimin, Lu Ping. An exploratory analysis of post competency indicators for general practitioners[J]. Chinese Journal of General Practice, 2019, 22(28): 3495.)
[3]Liu Bing, Lane I. Attention-based recurrent neural network models for joint intent detection and slot filling[C]//Proc of the 17th Annual Conference of the International Speech Communication Association. Red Hook,NY: Curran Associates Inc., 2016: 685-689.
[4]Zhang Xiaodong, Wang Houfeng. A joint model of intent determination and slot filling for spoken language understanding[C]//Proc of the 25th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 2993-2999.
[5]Goo C W, Gao Guang, Hsu Y K, et al. Slot-gated modeling for joint slot filling and intent prediction[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Red Hook,NY: Curran Associates Inc., 2018: 753-757.
[6]Li Changliang, Li Liang, Qi Ji. A self-attentive model with gate mecha-nism for spoken language understanding[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 3824-3833.
[7]Qin Libo, Che Wanxiang, Li Yangming, et al. A stack-propagation framework with token-level intent detection for spoken language understanding[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 2078-2087.
[8]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[9]郑巧月, 段友祥, 孙岐峰. 基于Transformer和双重注意力融合的分层交互答案选择模型[J]. 计算机应用研究, 2022, 39(11): 3320-3326. (Zheng Qiaoyue, Duan Youxiang, Sun Qifeng. Hierarchical interactive answer selection model based on transformer and dual attention fusion[J]. Application Research of Computers, 2022, 39(11): 3320-3326.)
[10]孙长志. 基于深度学习的联合实体关系抽取[D]. 上海: 华东师范大学, 2019. (Sun Changzhi. Joint entity relationship extraction based on deep learning[D]. Shanghai: East China Normal University, 2019.)
[11]Miwa M, Bansal M. End-to-end relation extraction using LSTMs on sequences and tree structures[C]//Proc of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 1105-1116.
[12]Katiyar A, Cardie C. Going out on a limb: joint extraction of entity mentions and relations without dependency trees[C]//Proc of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2017: 917-928.
[13]Zeng Daojian, Zhang Haoran, Liu Qianying. CopyMTL: copy mechanism for joint extraction of entities and relations with multi-task lear-ning[C]//Proc of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 9507-9514.
[14]Bekoulis G, Deleu J, Demeester T, et al. Joint entity recognition and relation extraction as a multi-head selection problem[J]. Expert Systems with Applications, 2018, 114: 34-45.
[15]Katiyar A, Cardie C. Investigating LSTMs for joint extraction of opinion entities and relations[C]//Proc of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2016: 919-929.
[16]Li Qi, Ji Heng. Incremental joint extraction of entity mentions and relations[C]//Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 402-412.
[17]Zhang Meishan, Zhang Yue, Fu Guohong. End-to-end neural relation extraction with global optimization[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2017: 1730-1740.
[18]Wang Shaolei, Zhang Yue, Che Wanxiang, et al. Joint extraction of entities and relations based on a novel graph scheme[C]//Proc of the 27th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 4461-4467.
[19]Kannan A, Chen K, Jaunzeikare D, et al. Semi-supervised learning for information extraction from dialogue[C]//Proc of the 19th Annual Conference of the International Speech Communication Association. Red Hook,NY: Curran Associates Inc., 2018: 2077-2081.
[20]Peng Shuang, Zhou Mengdi, Yang Minghui, et al. A Dialogue-based information extraction system for medical insurance assessment[M]//Findings of the Association for Computational Linguistics. 2021: 654-633.
[21]扈应, 陈艳平, 黄瑞章, 等. 结合CRF的边界组合生物医学命名实体识别[J]. 计算机应用研究, 2021, 38(7): 2025-2031. (Hu Ying, Chen Yanping, Huang Ruizhang, et al. Boundary combination biomedical named entity recognition combined with CRF[J]. Application Research of Computers, 2021, 38(7): 2025-2031.)
[22]Zhang Yuanzhe, Jiang Zhongtao, Zhang Tao, et al. MIE: a medical information extractor towards medical dialogues[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 6460-6469.
[23]Song Yan, Tian Yuanhe, Wang Nan, et al. Summarizing medical conversations via identifying important utterances[C]//Proc of the 28th International Conference on Computational Linguistics. Stroudsburg, PA: ACL, 2020: 717-729.
[24]Krishna K, Khosla S, Bigham J P, et al. Generating SOAP notes from doctor-patient conversations using modular summarization techniques[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2021: 4958-4972.
[25]Du Nan, Chen Kai, Anjuli K, et al. Extracting symptoms and their status from clinical conversations[C]//Proc of the 57th Annual Mee-ting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 915-925.
[26]Lin Xinzhu, He Xiahui, Chen Qin, et al. Enhancing dialogue symptom diagnosis with global attention and symptom graph[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Proces-sing. Stroudsburg, PA: ACL, 2019: 5033-5042.
[27]Hu Gangqiang, Lyu Shengfei, Wu Xingyu, et al. Contextual-aware information extractor with adaptive objective for Chinese medical dialogues[J]. IEEE Trans on Asian and Low-Resource Language Information Processing, 2022, 21(5): 1-21.
[28]Liu Sshikun, Johns E, Davison A J. End-to-end multi-task learning with attention[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 1871-1880.
[29]Mikolov T, Sutskever I, Chen Kai, et al. Distributed representations of words and phrases and their compositionality[C]//Proc of the 26th International Conference on Neural Information Processing Systems. New York: ACM Press, 2013: 3111-3119.
[30]Liu Liyuan, Jiang Haoming, He Pengcheng, et al. On the variance of the adaptive learning rate and beyond[C]//Proc of the 8th Internatio-nal Conference on Learning Representations. 2020.
[31]Chen Wei, Li Zhiwei, Fang Hongyi, et al. A benchmark for automatic medical consultation system: frameworks, tasks and datasets[J]. Bioinformatics, 2023, 39(1): 817.
[32]Kim Y. Convolutional neural networks for sentence classification[C]//Proc of Conference on Empirical Methods in Natural Language Proces-sing. Stroudsburg, PA: ACL, 2014: 1746-1751.
[33]Johnson R, Zhang Tong. Deep pyramid convolutional neural networks for text categorization[C]//Proc of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2017: 562-570.
[34]Zhang Ningyu, Jia Qianghuai, Yin Kangping, et al. Conceptualized representation learning for Chinese biomedical text mining[EB/OL]. (2020)[2023-12-01]. https://arxiv. org/pdf/2008.10813.pdf.
[35]Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2019: 4171-4186.
[36]Zhang Yue, Yang Jie. Chinese NER using lattice LSTM[C]//Proc of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2018: 1554-1564.
[37]Li Xiaonan, Yan Hang, Qiu Xipeng, et al. FLAT: Chinese NER using flat-lattice Transformer[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2020: 6836-6842.
[38]Liu Wei, Fu Xiyan, Zhang Yue, et al. Lexicon enhanced Chinese sequence labeling using BERT adapter[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2021: 5847-5858.
[39]Heck M, Van Niekerk C, Lubis N, et al. TripPy: a triple copy strategy for value independent neural dialog state tracking[C]//Proc of the 21st Annual Meeting of the Special Interest Group on Discourse and Dialogue. Stroudsburg, PA: ACL, 2020: 35-44.
[40]Zhao Xiongjun, Cheng Yingjie, Xiang Weiming, et al. A knowledge-aware machine reading comprehension framework for dialogue symptom diagnosis[C]//Proc of IEEE International Conference on Bioinforma-tics and Biomedicine. Piscataway, NJ: IEEE Press, 2021: 1185-1190.
[41]Chen Qian, Zhuo Zhu, Wang Wen. BERT for joint intent classification and slot filling[EB/OL]. (2019)[2023-12-01]. https://arxiv.org/pdf/1902.10909.pdf.
