一种有效的周期高效用序列模式增量挖掘算法
2024-08-15荀亚玲任姿芊闫海博




摘 要:周期高效用序列模式挖掘(PHUSPM)因其能够发现时间序列中更具实际价值的规律性模式而备受关注,但现有的PHUSPM算法难以有效地处理数据集的增量更新,且未考虑大规模数据下算法的向下闭包性和复杂性。针对该问题,提出了IncPUS-Miner算法,有效地实现了周期高效用序列模式(PHUSPs)的增量挖掘。IncPUS-Miner引入了一种名为pu-tree的新型数据结构,每个树节点对应一个更新效用列表(UUL)用于存储相应序列的辅助信息,当有增量数据加入时,该结构使得项目信息能够灵活更新,从而增强了算法的动态适应性和可扩展性。此外,还提出了两种新的序列效用上界PUB和EUB,以及两种相应的剪枝策略,有效地减少了计算负担。实验结果表明,在真实数据集上,IncPUS-Miner算法可以有效地增量挖掘PHUSPs,与其他算法相比,在运行效率和内存消耗上展现出了优越的性能。
关键词:增量挖掘; 高效用序列模式; 周期序列模式; 序列模式挖掘
中图分类号:TP301.6 文献标志码:A
文章编号:1001-3695(2024)08-008-2301-08
doi:10.19734/j.issn.1001-3695.2023.12.0607
Effective incremental mining algorithm forperiodic high-utility sequential patterns
Xun Yaling, Ren Ziqian, Yan Haibo
(College of Computer Science & Technology, Taiyuan University of Science & Technology, Taiyuan 030024, China)
Abstract:Periodic high utility sequential pattern mining(PHUSPM) has attracted much attention because it can find more practical regular patterns in time series. 0WckXHg/1zH9NyqfpE2D7w==However, existing PHUSPM algorithms struggle to effectively handle incremental updates and overlook the downward closure property and complexity of the algorithm in large-scale data. To solve this problem, this paper proposed an IncPUS-Miner algorithm, which effectively realized the incremental mining of periodic high-utility sequential patterns(PHUSPs). IncPUS-Miner introduced a novel data structure called pu-tree. Each tree node corresponded to an updated utility list(UUL) to store the auxiliary information of the corresponding sequence. When incremental data was added, this structure allowed flexible updates to project information, thereby enhancing the dynamic adaptability and scalability of the algorithm. In addition, this paper proposed two new upper boundsdn8fJNqDdQNk1RMoa5x/Zw== of sequence utility, PUB and EUB, and two corresponding pruning stra-tegies, which effectively reduced the computational burden. The experimental results show that the IncPUS-Miner algorithm effectively realizes the incremental mining of PHUSPs on real data, and shows superior performance compared with other algorithms.
Key words:incremental mining; high utility sequential pattern; periodic sequential pattern; sequential pattern mining
0 引言
高效用序列模式挖掘(HUSPM)是数据挖掘的焦点之一,其任务是在定量序列中找到所有具有高效用的子序列[1]。HUSPM的效用度量与传统序列模式挖掘[2]的支持度量不同,不具有单调性或反单调性,无法直接用于搜索空间剪枝[3]。因此,如何制定更有效的效用上限,以优化搜索空间并提高性能是HUSPM面临的挑战之一[4,5]。
随着大数据时代的兴起,新数据不断产生。由于静态方法需要重新扫描整个数据集执行挖掘,导致增量挖掘过程非常耗时。因此,一些能够有效处理增量数据的序列数据挖掘算法应运而生[6~12]。Yun等人[7]提出了基于索引列表的增量高效用模式挖掘(IIHUM)算法,仅需一次数据集扫描。Kim等人[8]提出了基于树状结构的高平均效用项集(IMHAUI)的增量挖掘算法。Wang等人[9]采用基于候选模式树结构的算法来实现增量挖掘高效用序列模式。这些增量算法旨在处理高效用模式的问题,未考虑模式的周期性约束。毛伊敏等人[10]提出了改进的并行关联规则增量挖掘算法,为处理大规模数据集的挖掘提供了有效方法。
周期性高效用序列模式挖掘(PHUSPM)发现的模式不仅具有高效用特性,还呈现周期性出现规律[13],在实际应用中具有重要意义[14]。例如,在市场分析中,分析消费者购买习惯的周期性和高效用模式可帮助商家优化促销策略。在基因序列分析中[15],寻找具有特定周期性和高效用的模式有助于理解生物过程中的重要事件。近年来,Fournier-Viger及其团队[16]提出了PHM算法,用于寻找周期性高效用项集。Dinh等人[13]提出PHUSPM算法,但由于未采用剪枝策略,导致执行时间长且内存占用大。Dinh等人[17]提出了基于PUSP结构的PUSOM算法,可以发现序列数据库中的所有PHUSPs,但不适用于动态数据集。尽管已有一些有效的周期性高效用序列模式挖掘算法,PHUSPs挖掘仍面临以下问题和挑战:
a)数据集的增量更新。传统的PHUSPM算法在处理新数据时需要重新从头开始挖掘,导致大量重复开销,难以有效应对数据集变化。
b)向下闭包性。周期高效用模式挖掘考虑向下闭包性质,增加了算法复杂性,特别是在处理动态序列数据时需要不断更新向下闭包性。
c)复杂性和效率。现代大规模数据集的增加使得周期高效用模式挖掘算法需要在保持高效性的同时处理复杂性。设计更高效的数据结构和算法是必要的,以在大规模数据上进行快速挖掘。
针对上述问题,本文提出一种新的增量挖掘算法IncPUS-Miner,允许在现有模式的基础上高效地更新和增加新模式,而无须重新扫描整个数据集,从而减少了不必要的开销。其主要贡献总结如下:
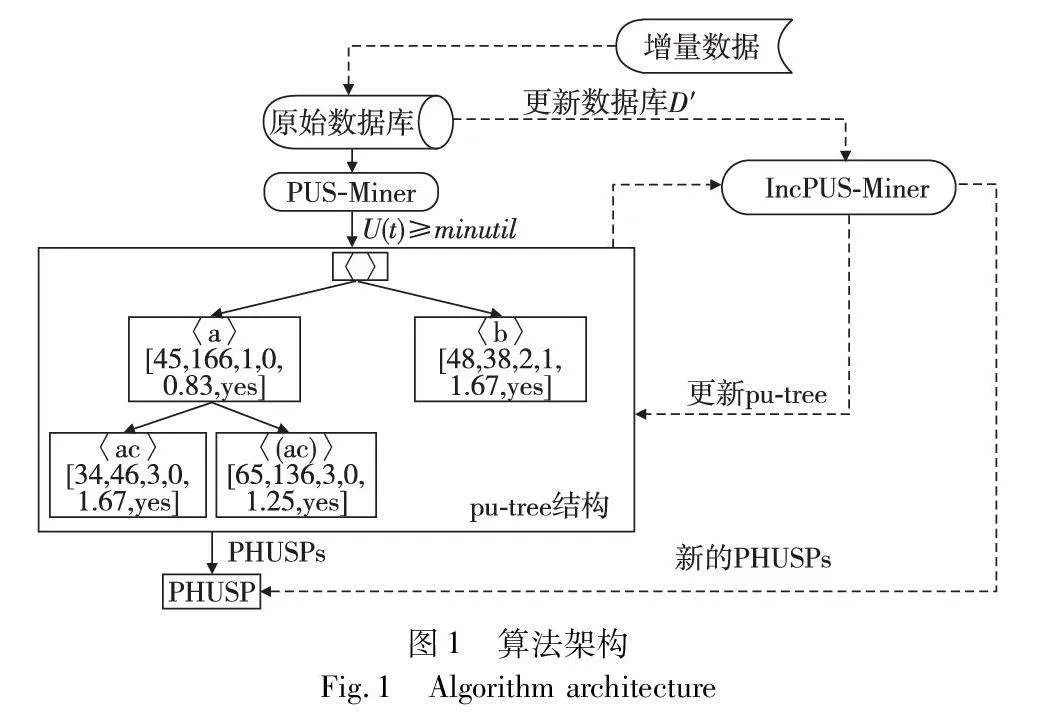
a)提出一种新的数据结构,称为pu-tree,并设计了树节点更新效用列表(UUL),用于存储相应序列的辅助信息,以便在数据更新时快速获取序列的效用等辅助信息,避免不必要的重复计算开销。基于该数据结构提出一个新的增量周期性高效用模式挖掘算法IncPUS-Miner,以有效挖掘大规模和不断更新的序列数据中的周期性高效用模式。
b)为了减少冗余计算,定义了两个新的序列效用上界,分别称为PUB和EUB,并提出了两种相应的剪枝策略,以显著提高挖掘效率。
c)在真实数据集上进行大量的实验表明,IncPUS-Miner算法能够有效地增量挖掘PHUSPs,算法性能优于其他对比算法。
1 相关定义
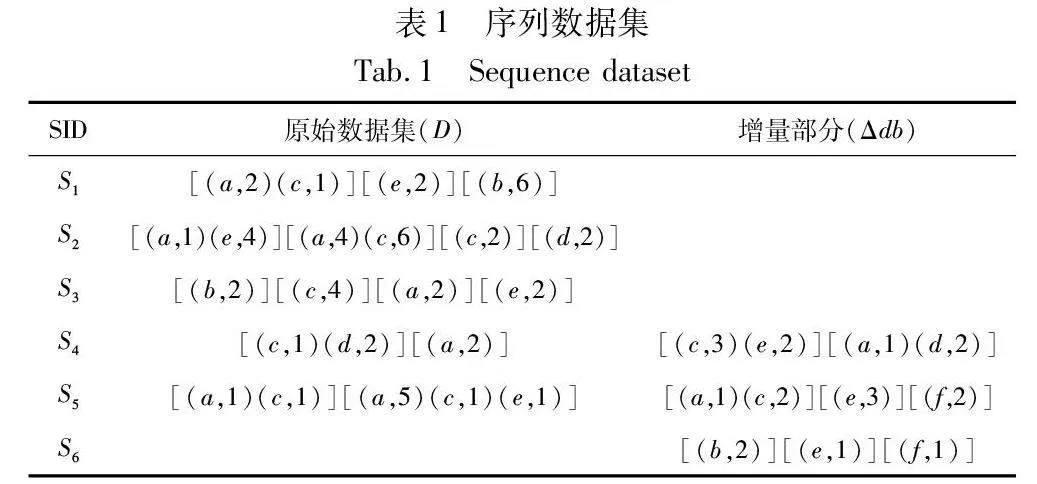
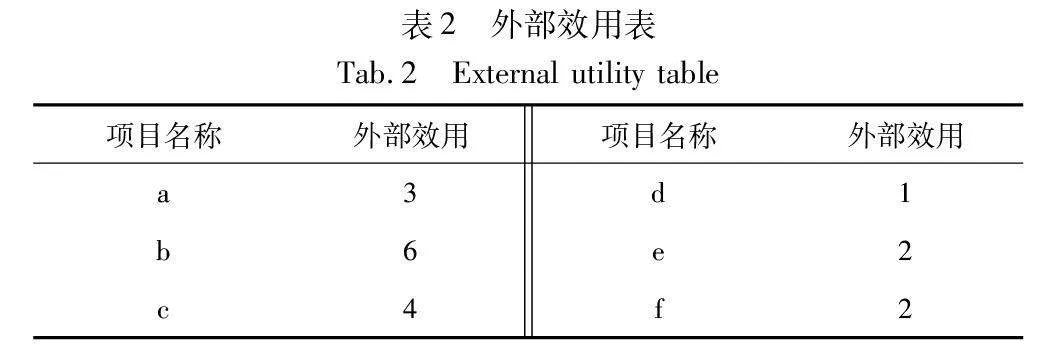
I={i1,i2,…,in},n≥1是一组包含n个项目的有限集。序列数据库中每个项记为(ik,qk),其中ik∈I(1≤k≤n),qk表示内部效用值,外部效用值用p(ik)表示。在表1所示的序列数据集中,(a,2)表示项目a的内部效用值为2。表2体现了每个项目对应的外部效用,如a的外部效用值为3。
T=[(i1,q1),(i2,q2),…,(im,qm)]可以表示为一条事务。一般情况下,事务中的项目顺序按照字典顺序来排序。表1给出的序列数据库包含6条序列,每个序列Si(1≤i≤6)又包含多条事务T。比如S1中包含了3条事务,分别是T1=[(a,2)(c,1)],T2=[(e,2)],T3=[(b,6)]。
模式t属于项集,它的表示方法有t1=〈(i1i2i3)〉和t2=〈i1i2i3〉,模式t1表示包含的三个项存在于同一事务中,而模式t2表示三个项各自存在于不同事务里。
定义1 项目效用。对于项目i,其在序列S的第j个事务中的效用定义为
U(i,j,S)=q(i,j,S)×p(i)(1)
例1 U(a, 1, S2)= 3,U(a , 2, S2)= 12。
定义2 项集效用。项集X在序列S的第j个事务中的效用被定义为
U(X,j,S)=∑i∈XU(i,j,S)(2)
例2 U(〈ac〉,〈1,2〉,S2)=U(a,1,S2)+U(c,2,S2)=27。
定义3 模式在序列中的效用。模式t在序列S中的效用记为U(t,S),定义为模式t在序列S中的所有实例效用的最大值。其中,〈j1,j2,…,j|s|〉是模式t在序列S中出现的事务号的集合。
U(t,S)=max{∑i∈tU(i,〈j1,j2,…,j|S|〉,S)}(3)
例3 给定一个模式t=〈ac〉,它在序列S2出现的事务号集合为〈〈1,2〉,〈1,3〉,〈2,3〉〉,故U(〈ac〉,S2)=max{U(〈ac〉,〈1,2〉,S2),U(〈ac〉,〈1,3〉,S2),U(〈ac〉,〈2,3〉,S2)}=max{27,11,20}=27。
定义4 模式在数据集中的效用。模式t在数据集D中的效用记为
UD(t)=∑S∈D∧tSU(t,S)(4)
定义5 高效用序列模式。当模式t的效用UD(t)≥minutil时,模式t为序列数据库D中的高效用序列模式,否则认为模式t是低效用模式。其中,minutil是用户给定的最小效用阈值。
例4 给定模式t=〈ac〉,minutil为20,根据表1所示,模式t=〈ac〉只出现在S2和S5两个序列中,所以UD(〈ac〉)=U(〈ac〉,S2)+U(〈ac〉,S5)=27+7=34。34>20,因此,模式t=〈ac〉是高效用模式。
给定数据集D={S1,S2,…,Sn}和模式t,模式t在数据集D中出现的序列列表为S(t,D)={Si1,Si2,…,Sik},其中1≤i1<i2<…< ik≤n,Sik是指第ik条序列。模式t在D中的扩展序列列表为g(t,D)={Si0,Si1,Si2,…,Sik},Sid(Si0)=0。
定义6 模式的周期。在g(t,D)中连续出现的两个序列之间相距的序列数称为这两个序列的周期,记为per,即式(5)。Si(k+1)是指数据集D中的最后一条序列,Sid(Si(k+1))=|D|=n。
per(t,ik)=Sid(Si(k+1))-Sid(Sik)(5)
例5 根据表1的数据集D(n=5),模式t=〈ac〉的扩展序列列表g(〈ac〉,D)={S0,S2,S5},即i0=0,i1=2,i2=5。根据式(5),得到per(〈ac〉,i0)=2-0=2,per(〈ac〉,i1)=5-2=3,per(〈ac〉,i2)=n-5=0,因此per(〈ac〉)={2,3,0}。对于模式t=〈(ac)〉,它表示项目a和c存在于同一事务中,它的序列列表S(〈(ac)〉,D)={S1,S2,S5}, g(〈(ac)〉,D)={S0,S1,S2,S5},计算得到per(〈(ac)〉)={1,1,3,0}。
下面介绍三个周期性度量,分别是最大周期度量、最小周期度量和平均周期度量。这三种度量为用户发现PHUSPs提供了更多的灵活性,比如,用户可以选择通过使用三种度量或只使用最大周期度量来找到序列数据库中的周期模式。
定义7 周期性度量。模式t最大周期值记为maxper(t)=max(per(t)),最小周期值是minper(t)=min(per(t)),平均周期值是avgper(t)=∑per(t)|per(t)|。
例6 根据定义6中的示例可知,模式t=〈ac〉的周期per(〈ac〉)={2,3,0},那么模式t的最大周期值为maxper(t)=max{2,3,0}=3,最小周期值是minper(t)=min{2,3,0}=0,平均周期值是avgper(t)=5/3=1.67。
绝大多数的周期模式挖掘算法仅仅依赖于最大周期度量(maxPer),这可能导致一些模式由于满足最大周期约束而被挖掘出来,尽管它们只在少数序列中出现。这种单一度量的方法存在不足之处。因此,本文算法选择综合三种度量,以提供更多灵活性给用户的同时,确保挖掘出更有实际意义的模式。
定义8 周期高效用序列模式。给定模式t以及5个用户给定的阈值(minutil,maxPer,minPer,maxAvg,minAvg)。如果模式t同时满足以下两个条件,则被称为周期高效用模式(PHUSP):a)模式t满足定义5,即UD(t)≥minutil;b)模式t满足maxper(t)≤maxPer,minper(t)≥minPer且minAvg≤avgper(t)≤maxAvg。
定义9 插入序列。当序列S插入数据集D后,独立构成一条新的序列时,将S称为插入序列。在表1中,S6是插入序列。
定义10 附加序列。当序列S插入数据集D后,附加在原始数据集中的序列S0结尾,从而形成S0·S形式的新序列,这样的序列称为附加序列。在表1中,S4和S5是附加序列。
定义11 模式连接。模式的扩展分为I-连接和S-连接[5]。对于给定模式t,I-连接指的是将与模式t在同一事务中存在的项i附加到t后,形成一个新的项集,表示为〈t⊕i〉。类似地,S-连接表示将模式t后续事务中的项i附加到t后,形成一个新的项集,表示为〈ti〉。这两种连接方式是模式扩展的关键策略。
2 IncPUS-Miner算法
IncPUS-Miner算法采用pu-tree结构,通过效用列表存储序列的相关信息,以便在更新数据时快速获取相关信息。同时设计了两个序列效用上界及两种剪枝策略,缩减了算法的搜索空间,以进一步提高算法性能。
2.1 序列效用上界
在文献[5]中提出了两个效用上界,即前缀扩展效用(PEU)和简化序列效用(RSU)。PEU上界策略需要计算模式t在序列中每次出现时的效用值及当下位置的剩余效用之和,再选择最大值作为模式在该序列的PEU值,这样的计算过程复杂。为了提高挖掘效率,在本节中提出了两个新的序列效用上界,称为前缀-效用上界(PUB)和扩展-效用上界(EUB),在2.1.1节和2.1.2节中分别给出了定义。
2.1.1 前缀-效用上界(PUB)
假如模式t在序列S中出现的位置为j:〈j1,j2,…,jm〉,模式t在序列S中的PUB值定义如式(6),j1是指模式t首次出现的位置。模式t的PUB值表示如式(7)所示。
PUB(t,S)=Umax(t,S)+RU(t,j1,S) RU>00其他(6)
PUB(t)=∑t∈S∩S∈DPUB(t,S)(7)
模式t在序列S中的PUB值指的是模式t在序列中出现的最大效用值与模式t首次出现位置的剩余效用值之和。
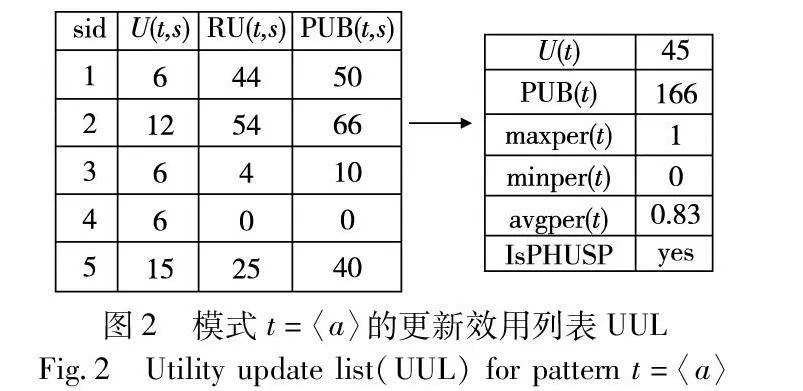
例7 在表1的原始数据集D中,模式t=〈a〉在序列S1中的PUB值表示为PUB(t,S1)=U(〈a〉,S1)+RU(〈a〉,1,S1)=6+44=50,同理计算得到PUB(t,S2)=12+54=66,PUB(t,S3)=6+4=10,PUB(t,S4)=0,PUB(t,S5)=15+25=40。因此,模式t在数据集D中的PUB值表示为PUB(〈a〉)=166。
定理1 向下闭包性质。给定两个模式t和t′,如果t′包含t(t′是t的扩展模式),那么满足PUB(t′)≤PUB(t)。
证明 假设序列S中存在两个模式t和t′,模式t′是t的扩展模式,表示为t′=t·t″。模式t在序列S中首次出现位置的剩余效用为RU(t,j1,S),且RU(t,j1,S)≥Umax(t″)+RU(t″,j1,S),根据式(6),可得PUB(t,S)≥Umax(t,S)+Umax(t″)+RU(t″,j1,S),又因为RU(t″,j1,S)=RU(t′,j1,S),所以PUB(t,S)≥PUB(t′,S)。
例8 给定两个模式t=〈a〉和t′=〈ac〉,t′是t的扩展模式。在表1的原始数据集D中,模式t=〈a〉出现在序列S1、S2、S3、S4、S5中,模式t′=〈ac〉只出现在序列S2、S5中,计算得到PUB(〈a〉)=166,PUB(〈ac〉)=46。由此可以得出,如果模式t′是模式t的超集,则满足PUB(t′)≤PUB(t)。
定理2 给定一个模式t,对于它的每个扩展模式t′,都满足U(t′)≤PUB(t)。
证明 假设模式t出现在序列S中,p是S中t的实例扩展位置(即模式t最后项出现的位置)。由于t是t′的前缀,若假设t′=t·t″,其中t″不为空集。那么模式t′在S中的效用包括两部分:一是模式t的扩展位置p处的效用;二是t″的效用(t″一定出现在扩展位置p之后)。因此,模式t′的效用可以表示为U(t′)=U(t)+U(t″),U(t″)属于剩余序列的一个子序列。而PUB(t)=Umax(t)+RU(t,j1),即模式t在序列S中出现的最大效用值与模式t首次出现位置的剩余效用值(即最大剩余效用值)之和。由于U(t)<Umax(t),U(t″)<RU(t,j1),可以得到U(t′)≤PUB(t)。
2.1.2 扩展-效用上界(EUB)
假如在序列S中,模式t′由模式t经过I-连接或S-连接扩展而来,模式t′在序列S中的EUB值记为EUB(t′,S),表示如式(8)所示。模式t′在数据集D中的EUB值记为EUB(t′),表示如式(9)所示。
EUB(t′,S)=PUB(t,S) tS∧t′S0其他(8)
EUB(t′)=∑S∈DEUB(t′,S)(9)
定理3 给定一个模式t,对于它的每个扩展模式t′,都满足U(t′)≤ EUB(t′)。
证明 假设模式t可以通过I-连接或S-连接扩展生成模式t′。根据定理2的证明可知,U(t′)≤PUB(t),在式(8)中表示EUB(t′,S)=PUB(t,S),因此,可以推出U(t′)≤EUB(t′)的结论。
2.2 剪枝策略
根据PUB和EUB这两个效用上界,对应提出了两种剪枝策略,即前缀效用上界策略和扩展效用上界策略。
策略1 前缀效用上界策略。假设t和minutil分别是候选模式和最小效用阈值。如果PUB(t)≤minutil,那么算法不需要检查模式t及其扩展后代。
该剪枝策略可以防止算法考虑没有希望的项,因为PUB上界具有向下闭包属性,当PUB(t)≤minutil时,就认为模式t及它的所有扩展模式都是无用的。
策略2 扩展效用上界策略。设t和minutil分别是候选模式和当前最小效用阈值,模式t通过I-连接或S-连接扩展生成模式t′。当EUB(t)≤minutil时,算法将停止扩展模式t′。
根据定理3,EUB(t)是模式t以及它所有后代的效用上界,因此,当EUB(t)<minutil时,以t为根的子树可以安全地修剪,并不会影响挖掘结果。
由于需要考虑模式的周期性约束,下面介绍第三种剪枝策略[16]。
定理4 最大周期值单调性。给定两个模式t和t′,其中t′是t的扩展模式。因此,maxper(t′)≥maxper(t)。
证明 若S(t′)和S(t)是分别包含模式t′和t的序列集合。由于tt′,所以S(t′)S(t)。当S(t′)=S(t)时,模式t和t′有相同的周期,即maxper(t)=maxper(t′)。若S(t′)S(t)时,per(t′)中的任何周期都不能小于per(t)中的周期,所以maxper (t′)>maxper(t)。
策略3 最大周期阈值修剪策略。假设t是一个出现在数据库D中的高效用模式,maxPer是用户给定的最大周期阈值。如果maxper(t)>maxPer,则模式t及其后代都不是周期高效用模式。
根据定义8,如果模式t不满足maxper(t)>maxPer,那么模式t就不是周期高效用模式。通过定理4可知,模式t的所有后代的maxper值都大于maxPer,故它们都不是PHUSPs。
2.3 pu-tree结构
文献[10]提出了一种有效的基于候选模式树结构的增量算法,该算法能够在不断更新的数据库中挖掘高效用序列模式,但未考虑模式的周期性。为了更全面地处理模式的效用和周期相关数据,提出了一种新的数据结构,称为pu-tree。该结构以树状形式组织,其中每个树节点代表一个项目,每个树路径代表一个模式或模式的一部分。算法扫描一次数据库后,构建这个树,并将模式的相关信息都存储在该树节点的更新效用列表(UUL)中,以便在不需要重新计算的情况下快速获取模式的相关信息。UUL包含的内容有:
a)U(t):模式t在输入数据集中的效用值,即模式t在所有序列中的最大效用值之和。
b)PUB(t):模式t在输入数据集中的PUB值,即模式t在所有序列中的PUB值之和。
c)maxper(t)、minper(t)、avgper(t):模式t在输入数据集中的最大周期值、最小周期值和平均周期值。
d)IsPHUSP:若模式t是周期高效用模式,就记为yes,否则记为no。
2.4 算法描述
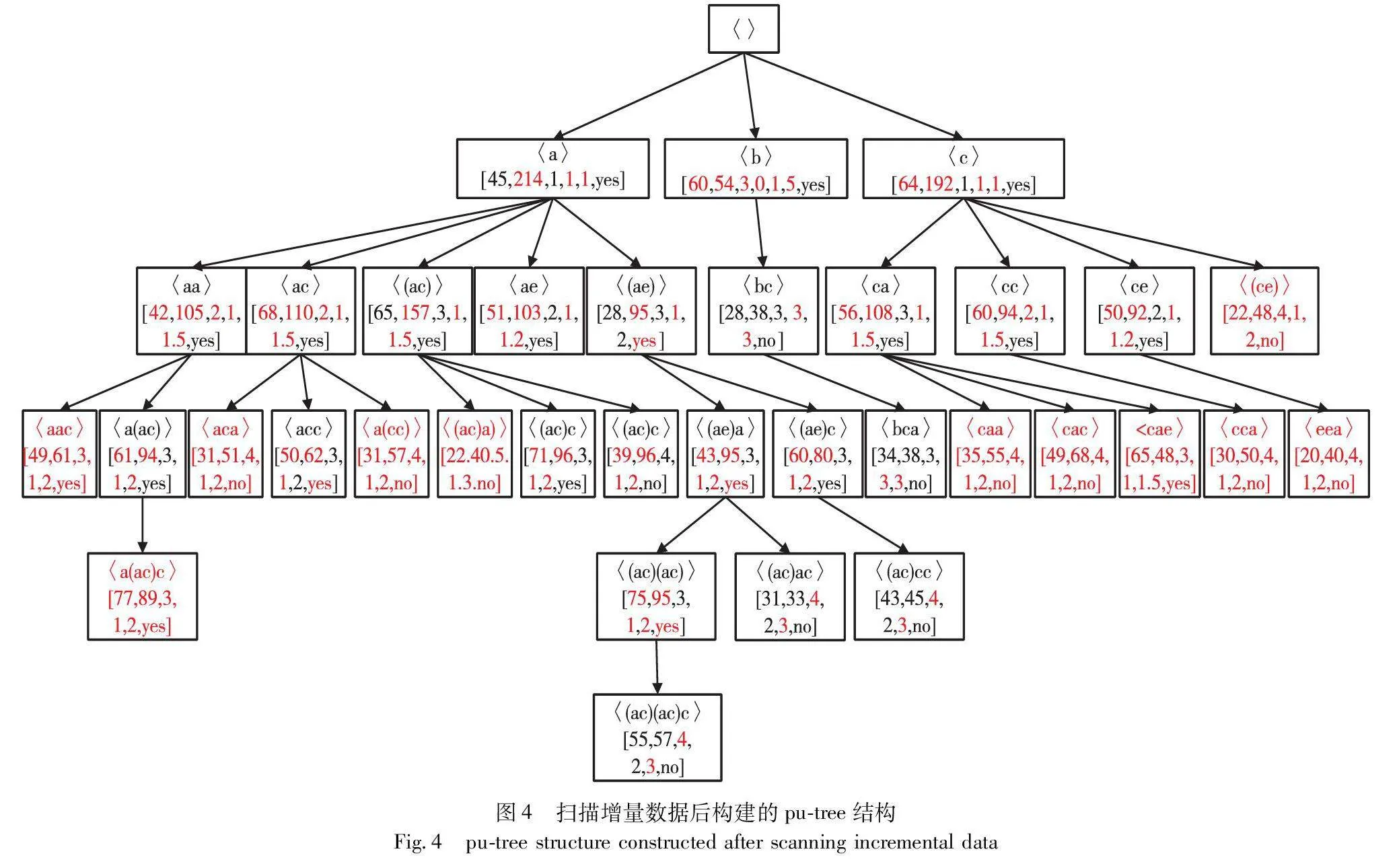
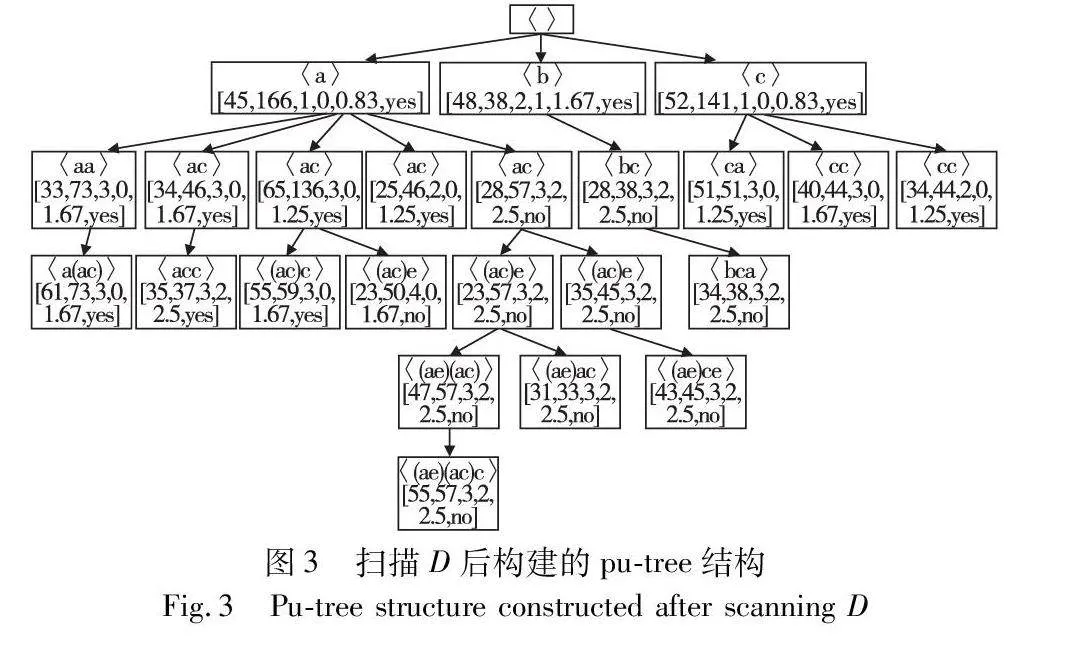
IncPUS-Miner包括初始和增量两个阶段。在初始阶段,提出了算法PUS-Miner,实现从原始数据库D中挖掘PHUSPs。当加入增量数据后, IncPUS-Miner算法能够有效处理增量数据,更新pu-tree结构,挖掘出新的PHUSPs。现设定阈值:minutil=30,maxPer=3,minPer=0,minAvg=0.5,maxAvg=2。根据表1的示例数据集,在图1展现了所提出的增量挖掘方法的整体体系结构。图2展示了扫描原始数据集D后,模式t=〈a〉的UUL列表结构示例。图3显示了扫描原始数据集D后构建的pu-tree结构,图4是加入增量数据后的pu-tree结构。
2.4.1 初始挖掘阶段
如算法1所示,PUS-Miner算法的主要思路是构建候选模式树pu-tree,再以深度优先搜索(DFS)的方式从原始数据集中提取具有高效用值的模式(PHUSP)。在处理每个节点t时,PUS-Miner首先检查PUB(t)是否小于minutil。若PUB(t)小于minutil,那么PUS-Miner可以跳过节点t的扩展步骤。当PUB(t)大于或等于minutil时,PUS-Miner会扫描D中t的投影数据库,以查找所有具有高EUB值的扩展序列t′。对于每个t′,PUS-Miner会构建相应的节点结构,将其作为t的子节点。如果t′是一个周期性高效用模式,PUS-Miner将其添加到PHUSP集中,并以t′为输入递归调用PUS-Miner算法,以继续扩展t′。由于应用了效用上界剪枝策略,算法PUS-Miner可以考虑较少的项目集,优化了算法的时间复杂度。
算法1 PUS-Miner(t)
输入:序列数据集D;模式t的投影数据集D|t;最小效用阈值ε;最大周期阈值maxPer;最小周期阈值minPer;最大平均周期阈值maxAvg;最小平均周期阈值minAvg。
输出:PHUSPs的集合(PHUSP)。
1 scan D to calculate the utility values of all 1-pattern;
//扫描数据集D,计算所有1-模式的效用值
2 remove the utility values of 1-pattern less than ε;
//移除效用值小于ε的1-模式
3 initialize an set PHUSP; //初始化PHUSP集
4 scan D|t once to find extend-pattern,
add I-Extension items of t to i-list;
add S-Extension items of t to s-list;
//扫描模式t的投影数据集D,发现模式t的所有扩展项
5 remove low EUB items from i-list and s-list; /*从扩展模式列表i-list和s-list中删除低EUB值的项*/
6 for each item i∈i-list and s-list do
//对于i-list和s-list中的每个项
7 if i∈i-list then //如果项i存在于i-list中
8 t′←〈t⊕i〉 //经I-连接,模式t和项i组成新模式t′
9 if i∈s-list then //如果项i存在于s-list中
10 t′←〈ti〉 //经S-连接,模式t和项i组成新模式t′
11 BuildNode(t′) and add t′ to pu-tree;
//构造模式t′的树节点,并添加它到结构pu-tree中
12 if(maxper(t′)≤maxPer) then //剪枝策略3
13 if(PUB(t′)≥ε) //剪枝策略1
14 IsPeriodic(S(t′),minPer,maxPer,maxAvg,minAvg)
//调用IsPeriodic方法,判断t′是否满足其余周期度量
15 if true then //若满足
16 insert t′ into PHUSP; //将模式t′存入PHUSP集
17 PUS-Miner(t′); //递归调用PUS-Miner(t′),继续扩展t′
18 return;
2.4.2 增量挖掘阶段
载入增量数据后,原始数据集D更新为D′。数据集D′可以看作两部分:一部分是数据集更新时并没有发生改变的序列,将这部分称为无更新数据,记为NDB;另一部分是在数据集更新时有发生变化的序列,称为更新数据,记为UDB。例如,在表1中,NDB包含序列S1、S2、S3,UDB包含序列S4、S5、S6、S7。另外,对于数据集更新后的每个模式t,都必须考虑以下两种情况:
a)模式t在D和D′中都属于周期高效用模式;
b)模式t在D中不属于周期高效用模式,但在D′中属于周期高效用模式。
算法2 IncPUS-Miner(t)
输入:更新数据集D′;模式t的投影数据集D′|t;最小效用阈值ε;最大周期阈值maxPer;最小周期阈值minPer;最大平均周期阈值maxAvg;最小平均周期阈值minAvg;PHUSP集。
输出:新的PHUSPs集(PHUSP)。
1 if all sequences in UDB|t are empty sequences then
2 return;//当更新数据UDB为空时,返回
3 if PUBD′(t)<ε then
4 return; //当模式t的PUB值小于ε时,返回
5 scan D′|t to calculate the EUB of all t’s extension sequences;
//扫描模式t的投影数据集D′,计算EUB(t′)
6 for each t’s extension sequences t′∈D′ do
7 if EUBD′(t′)≥ε then //剪枝策略2
8 if t′∈UDB then //若模式t′属于更新数据
9 if t′∈pu-tree then//模式t′已存在于pu-tree结构
10 UpdateNode(t′);
//更新模式t′在pu-tree结构中的相关信息
11 IncPUS-Miner (t′);//递归调用IncPUS-Miner方法
12 else //若模式t′不存在于pu-tree结构
13 BuildNode(t′) and add t′ to pu-tree;
//构造模式t′的树节点,并添加它到结构pu-tree中
14 if (maxper(t′)≤maxPer) then //剪枝策略3
15 if(PUB(t′)≥ε) then //剪枝策略1
16 IsPeriodic(S(t′), minPer, maxPer, maxAvg, minAvg)
//调用IsPeriodic方法,判断t′是否满足其余周期度量
17 if true then //若满足
18 insert t′ into PHUSP; //将t′存入PHUSP集
19 PUS-Miner(t′); /*递归调用PUS-Miner(t′),继续扩展模式t′*/
20 else
21 skip node t′;//跳过模式t′
2.4.3 IsPeriodic方法
在算法3中体现了IsPeriodic方法的具体操作,该方法用来判断高效用模式是否具有周期性。IsPeriodic方法首先扫描模式t出现的序列集S(t),计算其最小周期值、最大周期值和平均周期值(第1~3行)。如果t是一个周期模式(第4行),则该过程返回true(第5行);否则,返回false(第7行)。
算法3 IsPeriodic方法
输入:模式t出现的序列集S(t); 最大周期阈值maxPer;最小周期阈值minPer;最大平均周期阈值maxAvg;最小平均周期阈值 minAvg。
输出:如果模式t是周期模式,返回true;否则,返回flase。
1 calculate maxper(t)=max(per(t));//计算t的最大周期值
2 calculate minper(t)=min(per(t));//计算t的最小周期值
3 calculate avgper(t) = |S|/(S(t)+1);//计算t的平均周期值
4 if (maxper(t)≤maxPer & minper(t)≥minPer & minAvg≤avgper(t)≤maxAvg) then //判断模式t是否满足周期性条件
5 return true; //若满足,返回true
6 else
7 return false; //若不满足,返回false
3 实验评价
为了评估IncPUS-Miner算法的有效性,选择了三种先进的算法作为对比算法,分别为PHM算法[16]、PUSOM算法[17]和FHUQI- Miner算法[18]。
3.1 实验环境
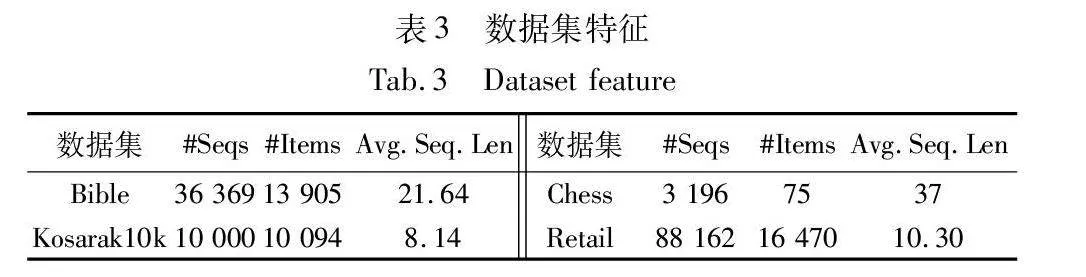
实验运行环境为一台1.90 GHz CPU和16 GB内存,运行64位微软Windows 11的计算机,基于Java编写。实验使用了4个真实数据集来评估算法的性能,其特征总结如表3所示。所有的数据集来自SPMF数据库[19]。
Bible是稠密数据集,它包含36 369个序列和13 905个不同项目。Kosarak10k是稀疏数据集,它包含了从一个匈牙利新闻门户网站收集的10 000个点击流数据序列。Chess数据集和Retail数据集都是具有合成效用值的真实数据集。Chess数据集是稠密数据集,Retail数据集是高度稀疏的数据集。
3.2 增量挖掘结果的准确性
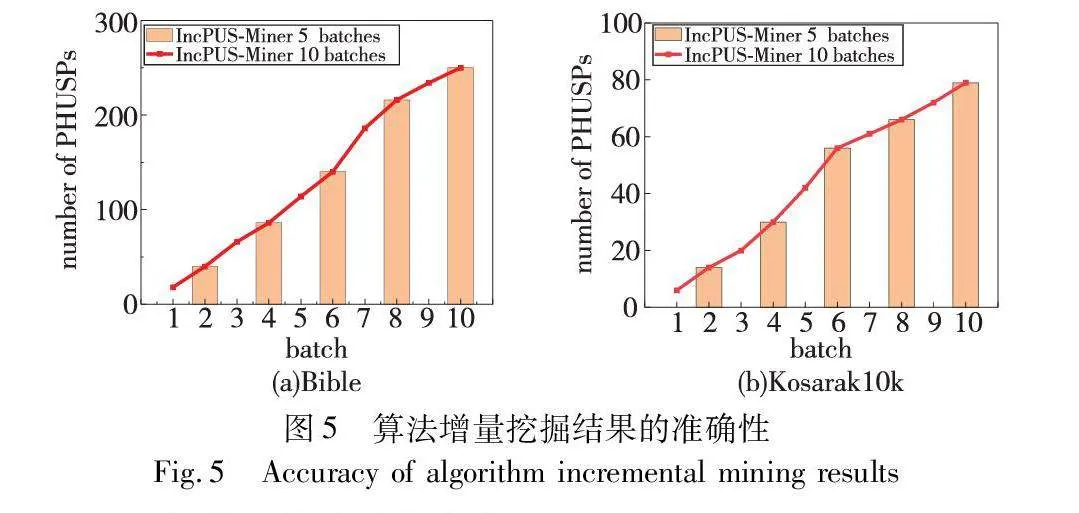
本节对IncPUS-Miner算法增量挖掘的准确性进行了实验。选择了稠密数据集Bible和稀疏数据集Kosarak10k,minutil分别设置为100 000和10 000,其余参数设为固定值(maxPer=100,maxAvg=20,minPer=minAvg=1)。
在实验中,每个数据集被分为5批、10批。IncPUS-Miner算法的挖掘结果如图5所示。可以看出,随着批次的加入,算法发现的PHUSPs数量也在增加,且相同数据集在不同批次下挖掘模式的最终数量是相等的。因此,IncPUS-Miner算法可以有效地处理增量数据,逐步挖掘所有PHUSPs。
3.3 所提剪枝策略的有效性
本组实验将提出的两个新的效用上界(PUB,EUB)与前人提出的上界(PEU,RSU)[10]进行对比,以评估其在模式挖掘中的性能。采用四个真实数据集进行实验,以确保比较的全面性和可靠性,如图6所示。由于剪枝策略是针对模式效用提出的,故将最小效用阈值(minutil)作为X轴,挖掘过程中算法的运行时间与内存占用情况作为Y轴。通过分析实验结果,应用所提剪枝策略的IncPUS-Miner算法在运行时间和内存占用方面都优于应用传统效用上界的IncPUS-Miner算法。因此,所提的剪枝策略可以有效减少算法搜索空间,节省时间与内存消耗。
3.4 参数对算法的影响及算法性能评估
在实际应用中,为了合理设置IncPUS-Miner相关参数,需考虑数据集特征和研究问题需求。在3.4.1节和3.4.2节中分别评估了参数minutil和maxPer对算法性能的影响。
3.4.1 minutil对算法效率的影响
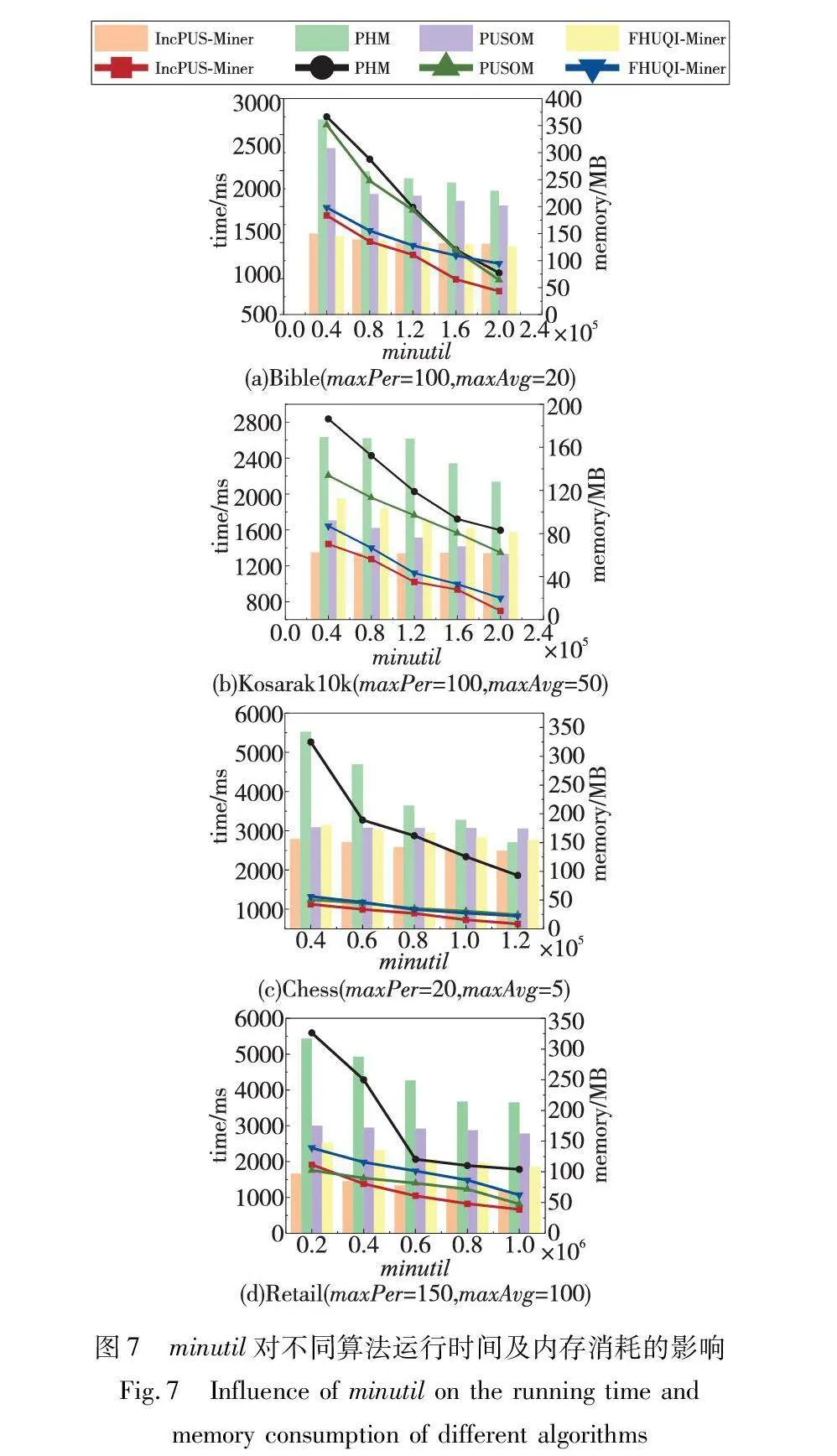
本组实验旨在通过对每个数据集设置不同的最小效用阈值(即minutil)来评估算法的性能。实验将IncPUS-Miner算法与三个对比算法在数据集上进行比较,并将参数minPer和minAvg设置为1,剩余参数maxPer和maxAvg在每个数据集都设定为经验值,具体数值在图7中体现。
通过分析图7发现,随着最小效用阈值的增加,满足条件的项集逐渐减少,导致算法的运行时间下降。值得注意的是,IncPUS-Miner算法在所有情况下的运行时间均低于其他对比算法,这得益于提出的pu-tree结构和剪枝策略,它们共同作用有效提高了挖掘效率。pu-tree结构使算法能够更快速且精准地定位潜在高效项目集,而剪枝策略则进一步减少了搜索空间,从而降低了计算成本。这两个因素共同确保了IncPUS-Miner在不同最小效用阈值下都能取得较快的运行速度。
与静态挖掘PHUSPs算法相比,增量挖掘PHUSPs需要考虑新添加的事务,这更为复杂。通过比较四种算法在内存使用方面的性能可以看出,IncPUS-Miner算法比其他三种算法消耗更少的内存。在密集数据集中的PHUSPs数量相对较大,会生成更多的候选项集。因此,IncPUS-Miner算法在稀疏数据集上有更好的效果。
实验结果表明,IncPUS-Miner算法在处理各种数据集时都表现出优越的性能,可以有效地逐步挖掘PHUSPs。
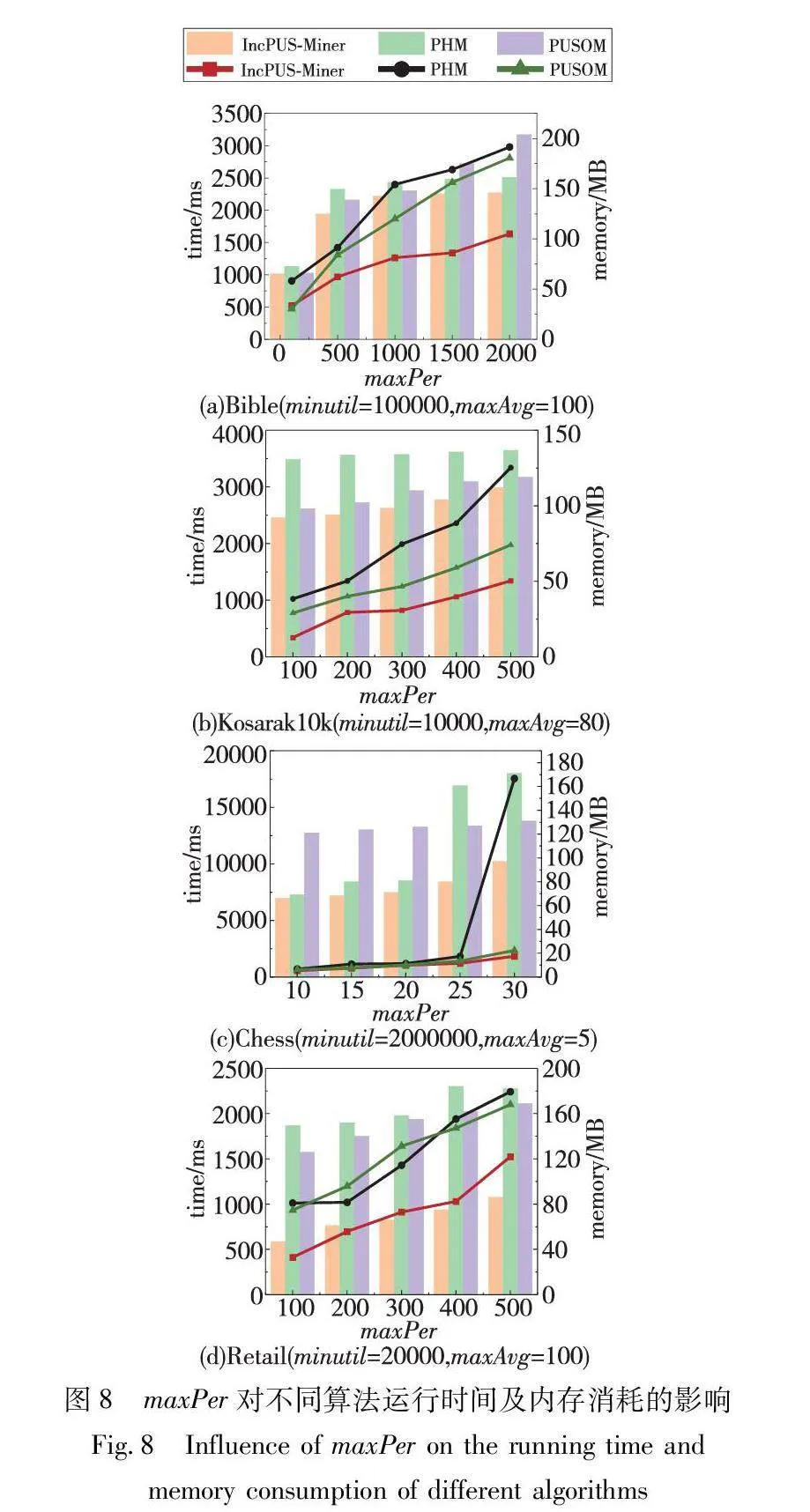
3.4.2 maxPer对算法效率的影响
本组实验研究了最大周期阈值(maxPer)对算法性能产生的影响。由于参数maxPer对FHUQI- Miner算法没有影响,实验只对比了PHM、PUSOM和IncPUS-Miner三种算法,并记录了它们在不同maxPer值下的运行时间与内存消耗情况。在图8中呈现的实验结果可知,随着maxPer值的增加,所有算法的运行时间和内存消耗均呈上升趋势。这是因为随着maxPer值的增大,满足周期性的高效用模式数量也随之增加,使得算法需要处理更多的模式,因而在执行过程中消耗更多的计算资源和内存空间。对于特定问题场景,通过合理设置maxPer值,可以在满足性能需求的同时减少不必要的计算负担。
通过比较不同算法的性能变化情况可以看出,IncPUS-Miner算法在各个maxPer值下表现出明显的优势。具体而言,相对于其他两种算法,IncPUS-Miner算法在高maxPer值情境下的运行时间和内存消耗增长更为缓慢,这表明该算法在处理大规模周期模式的数据时具有更强的适应性。
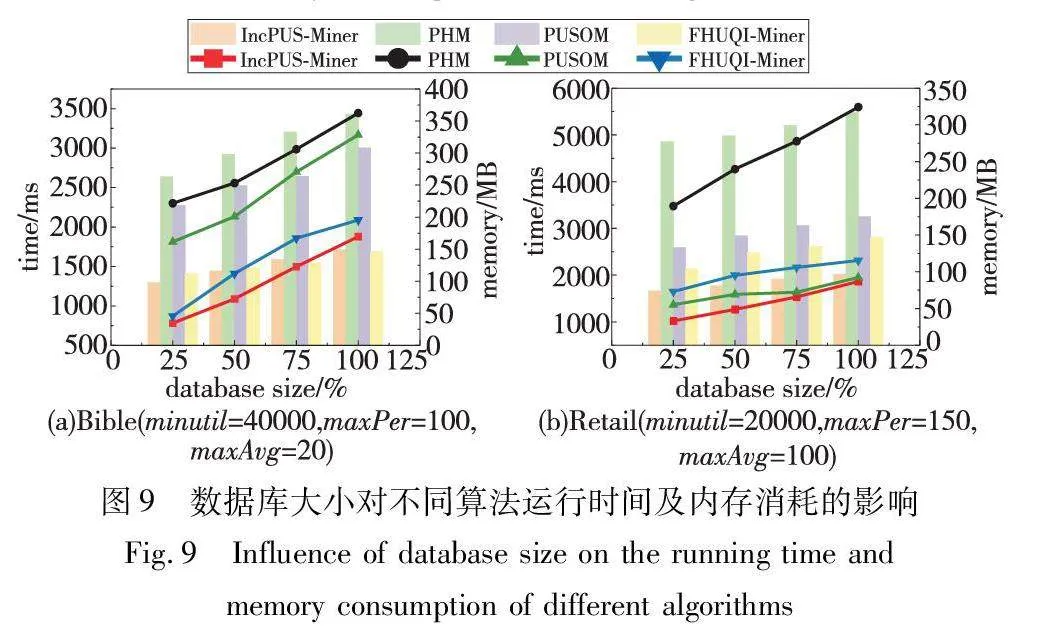
3.5 可扩展性
该组实验选择数据集Bible和Retail评估了数据库大小及增量数据对IncPUS-Miner算法整体性能的影响。依据上述实验,将参数minPer和minAvg固定设置为1,并以25%的增量改变数据库的大小,比较了四种算法在运行时间和内存消耗方面的性能,实验结果如图9所示。从图9可以看出,PHM算法在数据集上的运行时间和内存消耗明显高于其他四种算法。这是因为PHM算法采用的事务加权利用率(TWU)度量较为宽泛,使得算法需要处理更多的候选模式。另外,该算法在处理新数据时需要重新从头开始挖掘模式,进一步增加了运行时间和内存消耗的负担。因此, PHM算法在处理增量数据挖掘任务时显得不够适用。与之相对,IncPUS-Miner算法在逐渐增大的序列数据集中展现出更为优越的性能。这是因为IncPUS-Miner算法采用的pu-tree结构在处理增量数据时不仅可以有效地维护和更新模式的信息,而且能够支持算法在增量情境下的高效运行;其次,算法采用的剪枝策略可以有效减少冗余计算,随着数据集规模的增大,该剪枝策略能够精确地确定哪些模式是无用的,从而更早地进行剪枝,减少候选模式的数量,提高了算法在挖掘过程中的效率。
4 基因序列应用分析
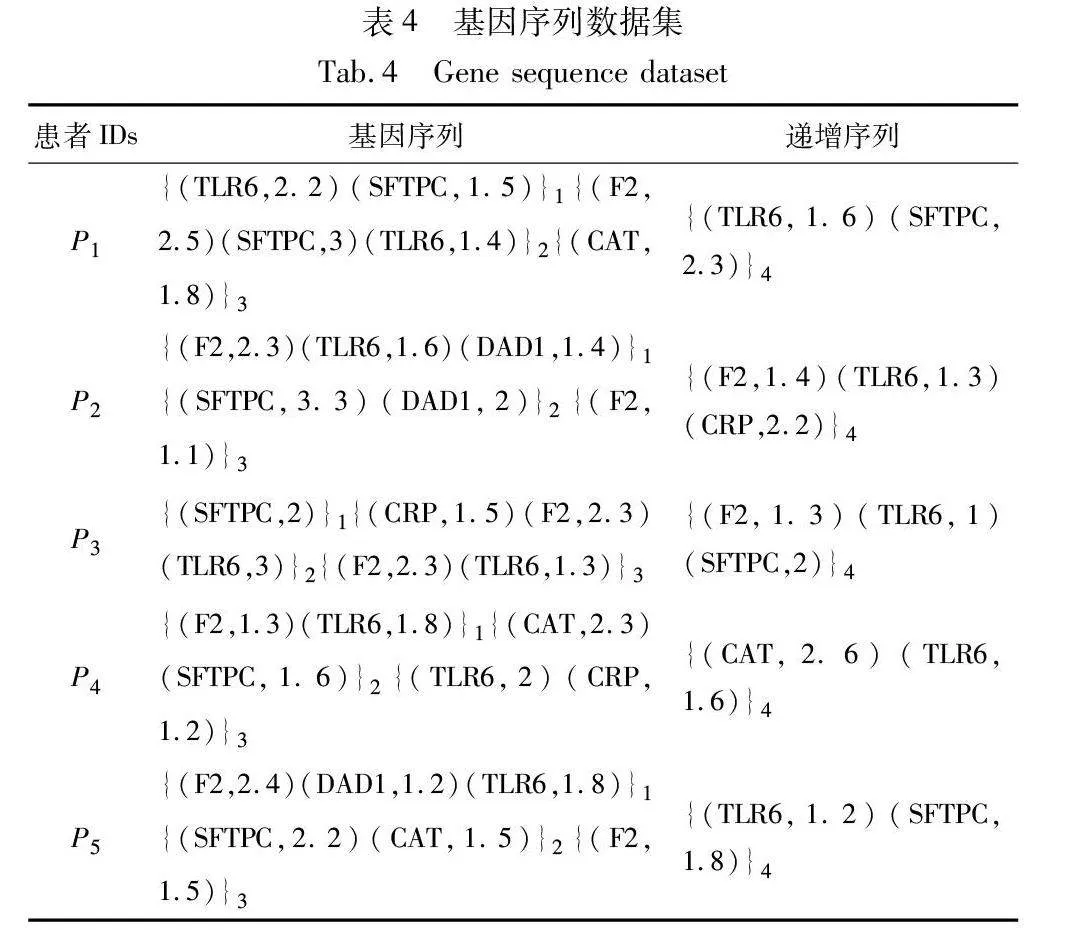
在生物医学领域中,考虑到一些基因在特定疾病中的重要性以及在生物治疗下的时间特性,通过PHUSPM分析有助于识别在特定疾病的发病机制中重要的基因调控序列模式。
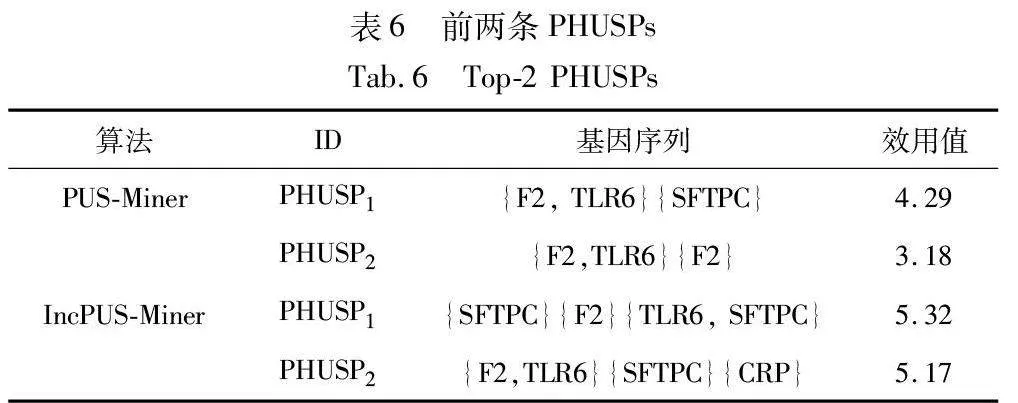
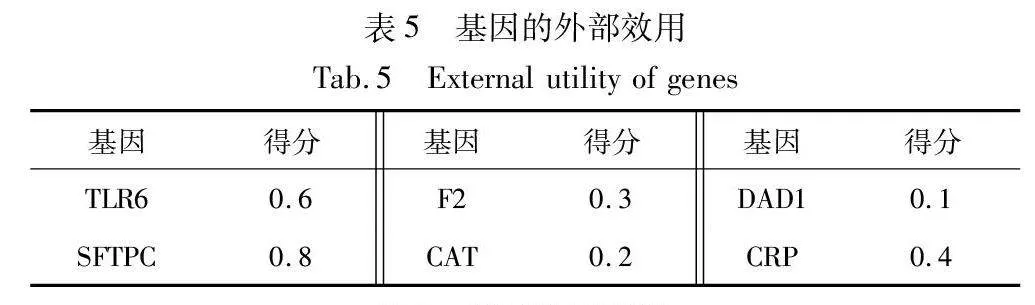
表4呈现了一个基因序列数据集的实例。第一列标识了六个肺炎患者的ID,其余列提供了在TP1、TP2、TP3、TP4这四个时间点上七种基因的基因表达值(内部效用)。基因的外部效用应该代表基因对引发肺炎的重要性,这里使用DisGeNET提出的基因-疾病关联评分(score)作为每个基因的外部效用,如表5所示。通过PUS-Miner和IncPUS-Miner算法进行挖掘分析,提取挖掘结果中的前两条PHUSPs记录在表6中。
观察表6的挖掘结果发现,IncPUS-Miner算法能够及时捕捉到新的基因调控模式,这些模式很可能与肺炎的发生和发展密切相关。随着病患者基因数据的积累,该算法允许实时更新模型,能够实时挖掘出在不同阶段的肺炎中起关键作用的基因调控序列,从而更全面地理解基因在特定疾病发病机制中的作用。从总体结果来看,该算法能够更有效地探索基因与疾病之间的关系,为生物医学领域数据分析提供了有益的工具。
5 结束语
针对PHUSPs的增量挖掘问题,设计了一种高效的算法IncPUS-Miner。IncPUS-Miner算法依赖于pu-tree结构和更新效用列表(UUL)来促进增量挖掘过程。pu-tree结构可以有效处理新数据,UUL用来存储简洁的辅助信息,以消除冗余计算,提高算法整体效率。此外,还介绍了两个新的序列效用上界以及对应的剪枝策略,有助于更准确地确定无用模式,并在挖掘过程中更早地进行剪枝,从而减少执行时间和内存使用。实验结果表明,IncPUS-Miner算法可以有效地从增量数据库中挖掘PHUSPs,且在执行时间和内存使用方面优于其他算法,该算法为解决PHUSPs的增量挖掘问题提供了可靠且高效的解决方案,为应对资源有限性的实际应用场景提供了显著的优势。未来研究将专注于自适应策略,通过智能调整算法参数,更好地适应不同数据分布的变化,从而提升算法在实时环境中的性能表现。
参考文献:
[1]Fournier-Viger P, Lin J C W, Kiran R U, et al. A survey of sequential pattern mining[J]. Data Science and Pattern Recognition, 2017,1(1): 54-77.
[2]吴军, 欧阳艾嘉, 张琳. 基于标准置换检验的差异序列模式挖掘算法[J]. 计算机应用研究, 2021, 38(3): 710-713. (Wu Jun, Ouyang Aijia, Zhang Lin. Mining discriminative sequential patterns based on standard permutation testing[J]. Application Research of Computers, 2021, 38(3): 710-713.)
[3]Gan Wensheng, Lin J C W, Zhang Jiexiong, et al. Fast utility mining on sequence data[J]. IEEE Trans on Cybernetics, 2021,51(2): 487-500.
[4]Ahmed C F, Tanbeer S K, Jeong B S. A novel approach for mining high-utility sequential patterns in sequence databases[J]. ETRI Journal, 2010,32(5): 676-686.
[5]Wang Junzhe, Huang J L, Chen Yicheng. On efficiently mining high utility sequential patterns[J]. Knowledge & Information Systems, 2016, 49(2): 597-627.
[6]Han Meng, Shan Zhihui, Han Qiang. Incrementally updating high utility quantitative itemsets mining algorithm[J]. Journal of Intelligent & Fuzzy Systems, 2022, 43: 2435-2448.
[7]Yun U, Nam H, Lee G, et al. Efficient approach for incremental high utility pattern mining with indexed list structure[J]. Future Generation Computer Systems, 2019, 95: 221-239.
[8]Kim D, Yun U. Efficient algorithm for mining high average utility itemsets in incremental transaction databases[J]. Applied Intelligence, 2017, 47(1): 114-131.
[9]Wang Junzhe, Huang J L. Incremental mining of high utility sequential patterns in incremental databases[C]//Proc of the 25th ACM International on Conference on Information and Knowledge Management. New York: ACM Press, 2016: 2341-2346.
[10]毛伊敏, 邓千虎, 邓小鸿, 等. 改进的并行关联规则增量挖掘算法[J]. 计算机应用研究, 2021,38(10): 2974-2980. (Mao Yimin, Deng Qianhu, Deng Xiaohong, et al. Improved parallel association rules incremental mining algorithm[J]. Application Research of Computers, 2021, 38(10): 2974-2980.)
[11]Yun U, Ryang H, Lee G, et al. An efficient algorithm for mining high utility patterns from incremental databases with one database scan[J]. Knowledge-Based Systems, 2017, 124: 188-206.
[12]Wang Junzhe, Huang Jiunlong. On incremental high utility sequential pattern mining[J]. ACM Trans on Intelligent Systems and Technology, 2018, 9(5): 1-26.
[13]Dinh T, Huynh V N, Le B. Mining periodic high utility sequential patterns[C]//Proc of Asian Conference on Intelligent Information and Database Systems. Cham: Springer, 2017: 545-555.
[14]Xie Shiyong, Zhao Long. An efficient algorithm for mining stable periodic high-utility sequential patterns[J]. Symmetry, 2022, 14(10): 2032.
[15]Zihayat M, Davoudi H, An A. Top-k utility-based gene regulation sequential pattern discovery[C]//Proc of IEEE International Confe-rence on Bioinformatics and Biomedicine. Piscataway,NJ: IEEE Press, 2016: 266-273.
[16]Fournier-Viger P, Lin J C W, Duong Q H, et al. PHM: mining perio-dic high-utility itemsets[M]//Perner P.Advances in Data Mining. Cham: Springer, 2016: 64-79.
[17]Dinh D T, Le B, Fournier-Viger P, et al. An efficient algorithm for mining periodic high-utility sequential patterns[J]. Applied Intelligence, 2018, 48(12): 4694-4714.
[18]Nouioua M, Fournier-Viger P, Wu C W, et al. FHUQI-Miner: fast high utility quantitative itemset mining[J]. Applied Intelligence, 2021, 51: 6785-6809.
[19]Fournier-Viger P, Gomariz A, Gueniche T, et al. SPMF: a Java open-source pattern mining library[J]. The Journal of Machine Learning Research, 2014,15(1): 3389-3393.
