基于区块链的联邦学习模型聚合方案
2024-08-15罗福林陈云芳陈序张伟


摘 要:传统的中心化联邦学习需要一个受信赖的中央服务器负责模型聚合,容易产生单点故障。现有的去中心化联邦学习方案通常在每个迭代周期临时选举出一个节点负责模型的聚合,但不能保证被选节点的完全可信。为了解决上述问题,提出一种基于区块链的联邦学习模型聚合方案,把模型聚合工作交由众多矿工而非某个单一节点负责,矿工提出不同的候选聚合方案并生成相应区块,然后根据设计的准确率最高链原则确定主链,以达成节点之间的共识;同时,为了抑制恶意训练节点,提出基于质押“训练币”的训练节点选择方案,节点通过质押“训练币”获取参与训练的机会,系统根据模型贡献进行奖惩。仿真实验结果表明,当系统中恶意节点比例分别为10%、20%、30%时,该方案所能达到的准确率比联邦平均(FedAvg)方案分别高8.64、19.89、22.93百分点,且在non-IID数据训练场景下也有良好的表现。综上所述,该方案提高了联邦学习聚合过程的可信度,并能同时保证联邦学习训练效果。
关键词:区块链; 联邦学习; 去中心化; 模型聚合
中图分类号:TP301 文献标志码:A
文章编号:1001-3695(2024)08-005-2277-07
doi:10.19734/j.issn.1001-3695.2023.12.0604
Federated learning model aggregation scheme based on blockchain
Luo Fulin, Chen Yunfang, Chen Xu, Zhang Wei
(School of Computer Science, Nanjing University of Posts & Telecommunications, Nanjing 210023, China)
Abstract:Traditional centralized federated learning relies on a trusted central server for model aggregation, creating a vulnerability to single-point failures. In contrast, existing decentralized federated learning schemes elect a node temporarily in each iteration cycle to aggregate the model, but cannot ensure the complete trustworthiness of the elected node. To solve the aforementioned issues, this paper proposed a blockchain-based federated learning model aggregation approach that assigned the task of model aggregation to numerous miners instead of a single node. Miners proposed various candidate aggregation solutions and generated corresponding blocks, then it determined the main chain based on the higff1afc31ebc6b39c8a00b78715dcca16hest accuracy chain principle to achieve consensus among nodes. Additionally, to counteract malicious training nodes, it introduced a training node selection mechanism based on staking “training coins”, allowing nodes to participate in training by staking “training coins”, with the system rewarding or penalizing them based on their contribution to the model. Simulation results demonstrate that with 10%, 20%, and 30% malicious nodes in the system, the accuracy of this approach is respectively 8.64, 19.89, and 22.93 percent point higher than that of the federated averaging(FedAvg) scheme, and it also performs well in non-IID data training scenarios. In conclusion, this approach enhances the credibility of the federated learning aggregation process and ensures the effectiveness of federated learning training.
Key words:blockchain; federate learning; decentralization; model aggregation
0 引言
在人工智能飞速发展的时代,数据的重要性愈加凸显,人们对数据的隐私保护也越来越重视。因此在进行需要海量数据支持的机器学习时,数据所有者并不一定愿意分享他们的数据用于模型训练,因为这些数据往往包含着敏感信息,由此造成了“数据孤岛”问题,极大阻碍了人工智能技术和应用的发展。
为了连接“数据孤岛”,Google于2016年提出联邦学习(federate learning,FL)[1],在FL中,各参与方无须共享本地数据,只需上传经本地训练得到的模型梯度,由中央服务器进行聚合得到新一轮的全局模型后广播给各参与方,各参与方在新的全局模型基础上再进行本地训练,重复该过程多轮,以达到分布式训练的效果。联邦平均(FedAvg)方案是联邦学习领域应用最广泛的方法之一,FedAvg按照预设比例从全部节点中随机选择一部分参与训练,训练节点使用自己的本地数据进行训练,并在训练完成后上传训练得到的局部模型,中央服务器将所有上传的局部模型进行加权求和平均得到全局模型。与传统集中式机器学习方法相比,FL不要求参与方共享自己的私有数据,极大地保护了参与方的数据隐私,可以广泛应用于医疗保健、娱乐、电子商务和自动驾驶等场景[2]。但传统的联邦学习需要一个受信赖的中央服务器负责模型的聚合和广播过程,容易产生单点故障,一旦中央服务器受到攻击,整个系统就会崩溃,模型的训练也将被迫中止,鲁棒性较差,并且传统的联邦学习假设所有节点都是诚实的,如果参与训练的节点中混入恶意节点,将会影响最终的模型效果。
区块链是一种建立在P2P网络基础上的去中心化的分布式账本技术,采用分布式的存储架构,且整条链的数据被完整保存在区块链网络中的所有节点上。区块链通过密码学和共识机制来保证数据的不可窜改性,即使个别节点受到攻击,也不会影响整个区块链网络的正常运行[3]。因此,如果利用区块链技术的去中心化节点网络来取代传统联邦学习中的中央服务器,可以很好地解决传统联邦学习的单点故障问题[4]。同时,由于区块链的不可窜改性,存储于区块链上的模型梯度数据也可以得到安全保证。BlockFL[5]和Deepchain[6]就是两种有影响力的去中心化联邦学习解决方案。
目前,除了将区块链用于存储联邦学习过程中产生的模型梯度数据,也有不少工作从其他角度研究区块链技术与联邦学习的结合,例如在激励机制、共识算法和数据隐私保护等方面进行探索。同时,节点选择策略也是一个值得研究的方向,区块链可以帮助跟踪和评估各个节点的贡献,这有助于在未来的迭代中作出更好的节点选择决策,优先选择那些能提供高质量数据或显示出良好训练性能的节点;并且,区块链可以利用智能合约自动执行奖励政策,这可以鼓励更多节点积极参与联邦学习过程,吸引高质量的数据和计算资源。
本文从节点选择的角度进行研究,提出一种基于区块链的去中心化联邦学习模型聚合方案,主要工作和贡献如下:
a)提出矿工负责模型聚合的方法,利用矿工的计算资源完成模型聚合工作,在模型聚合阶段矿工提出不同的候选聚合方案并生成相应区块,然后根据本文提出的准确率最高链原则确定主链以达成节点之间的共识。
b)提出基于质押“训练币”的训练节点选择方案,各节点质押其拥有的“训练币”获取参与训练的机会,系统根据“币龄”随机选取一组训练节点,最后根据模型贡献进行奖惩。
c)在真实数据集CIFAR-10[7]上进行了仿真实验,实验验证了方案的有效性、安全性和鲁棒性。当系统存在30%恶意节点时,本文方案所能达到的准确率比FedAvg方案高22.93百分点,且本文方案在非独立同分布(non-IID)数据训练场景下依然表现良好。
1 去中心化联邦学习相关研究
由于传统联邦学习中央服务器带来的单点故障问题,研究者们将区块链和联邦学习结合起来,利用区块链的去中心化、不可窜改等特性对联邦学习加以改进,改进工作主要包括激励机制、共识算法、数据隐私和模型安全三个方面。
在激励机制方面,文献[8]设计了一种基于区块链的联邦学习平台的竞争激励机制,某一轮中选择的每个训练节点,选择上一轮节点提交的最佳k个模型更新自己的模型,节点的奖励是由下一轮训练节点投票决定的,模型越好意味着将获得更多的奖励。文献[9]提出一种公平的激励机制FGFL,可以有效地实时评估工人的可信度和效用,衡量节点的声誉和贡献,任务发布者最终使用贡献和声誉指标的乘积确定节点的奖励份额。文献[10]提出一种基于区块链的混合激励机制,包括信誉模块和反向拍卖模块,前者用于动态计算每个参与者的声誉分数,后者负责启动拍卖任务,计算价格排名并分配相应的代币奖励。
在共识算法方面,虽然工作量证明(proof-of-work,PoW)是区块链领域使用的主流共识算法,但如果直接在基于区块链的联邦学习(federated learning based on blockchain,BFL)系统中部署PoW,会给系统中的节点带来高成本的计算资源需求。因此,一些研究选择使用PoS或改进PoS作为BFL系统的共识算法[11,12]。此外,还有一些研究提出新的共识算法以更加契合联邦学习。文献[13]提出联邦学习证明(proof of federate learning,PoFL)共识算法,PoFL使用联邦学习任务而不是哈希难题来达成共识,矿工解决的联邦学习任务作为达成共识的工作量证明,使共识过程更加节能。文献[14]提出训练质量证明(proof of training quality,PoQ)共识算法,PoQ将联邦学习的模型训练与共识过程相结合,利用节点的计算资源来保证模型训练的质量。
在数据隐私和模型安全方面,主要是为了保证参与方的数据隐私不被泄露以及训练得到的模型的机密性和完整性。文献[15]提出一种基于区块链的联邦学习系统,通过集成联邦学习和区块链训练和保存模型更新来保护隐私,同时使用分布式哈希表在每个客户端上本地保存数据,以解决雾计算隐私泄露和中毒攻击相关的问题。文献[16]提出了一种基于分片的区块链协议,可以很好地保护模型梯度参数和模型聚合,防止训练过程受到拜占庭攻击。文献[17]提出使用差分隐私技术来保护联邦学习参与方的数据隐私,且经过训练的局部模型由发送方进行加密和签名,以防止攻击者和冒名顶替者窃取模型,保护模型安全。
还有一些工作从联邦学习节点选择的角度引入区块链。节点选择包括两类,一类是选择哪些节点参与训练,另一类是选择哪些训练节点上传的局部模型参与聚合。在选择训练节点方面,文献[18]采用声誉值来衡量参与节点的可靠性和可信度,选取声誉值高的节点参与训练,并且使用区块链来计算和保存节点的声誉值,利用区块链的不可窜改性,实现安全的声誉管理。但是,声誉评分易受节点的主观影响,导致评分不够准确和公正,且声誉与奖励并无直接关联,无法对参与节点进行有效激励。文献[19]提出了一种基于区块链的细粒度信誉系统,通过前端向联邦学习系统的所有参与者提供信誉信息的访问,系统信誉分数的哈希值被报告给链上智能合约,智能合约汇总并计算每个节点的信誉,以进行节点选择。在选择局部模型方面,文献[20]提出建立一个由少数诚实节点组成的委员会,训练节点上传的局部模型由委员会进行验证并打分,每个训练节点的得分取n个(委员会成员数量)分数的中位数,最后根据分数从高到低选取m个(根据聚合所需要的局部模型个数而定)梯度更新保存到区块链上并进行聚合。然而,委员会成员在打分时会更加偏好拥有与自己本地数据分布相同数据的训练节点,这导致该方案在非独立同分布(non-IID)数据训练场景下可能会有较差的表现。
尽管现有的联邦学习和区块链结合的方案提出了基于声誉机制的节点选择以及委员会模型来验证和选择局部模型,但这些方法存在一定的局限性。声誉机制容易受到主观因素的影响,导致评分的准确性和公正性得不到保证,同时,依赖于少数委员会成员的模型选择不能代表所有节点成员,在处理非独立同分布数据时可能会出现偏差。本文从节点选择的角度研究区块链与联邦学习的结合,首先提出将区块链的共识过程和联邦学习的模型聚合过程进行整合,由众多矿工完成聚合工作,聚合方案优劣的唯一评判标准就是准确率,确保客观公正;在此基础上,提出基于质押“训练币”的训练节点选择方案,节点被选中参与训练的概率与其所持有的“训练币”数量有直接关系,而节点持有的“训练币”数量的增减则取决于节点是否对准确率最高的聚合方案作出贡献。相比于根据声誉进行选择,该方案能够避免某些节点的主观偏见以及恶意打分,且“训练币”作为区块链系统中的一种代币,可以辅助完成联邦学习后期的奖励分配和贡献确定环节,能够对参与节点产生更好的激励作用。
2 基于区块链的模型聚合方案
2.1 框架结构
根据BFL系统中节点的职能,可以将BFL系统模型分为解耦模型、耦合模型和重叠模型三类[21]。在解耦模型中,一个节点只能在联邦学习系统和区块链系统两者之一上工作;在耦合模型中,节点拥有双重身份,可以同时充当这两个系统的工作节点;重叠模型则是一种折中方案,节点的角色能够进行动态调整,自由选择工作身份。
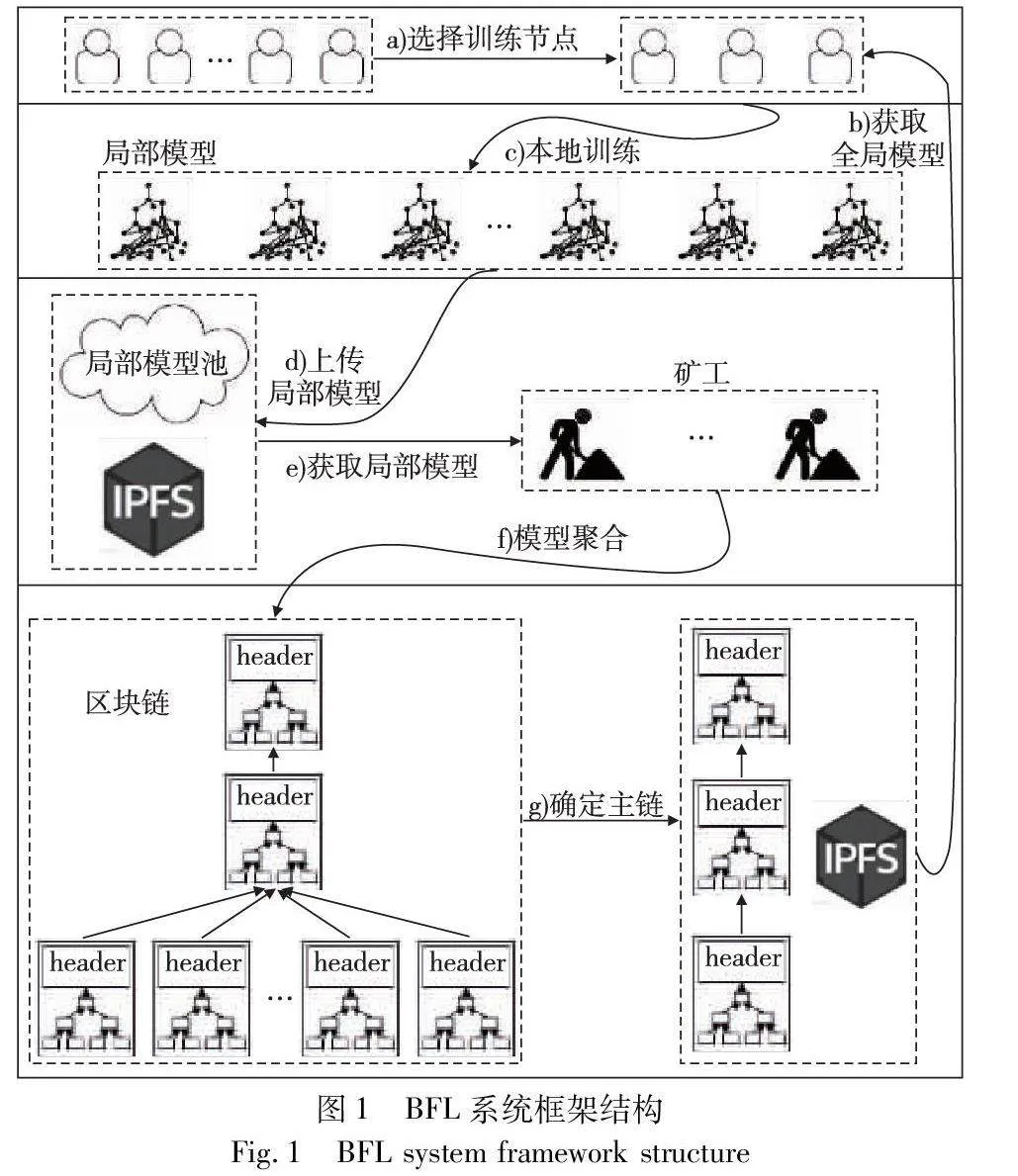
本文设计的BFL系统基于重叠模型,系统中的每个节点既可以作为训练节点参与联邦学习的训练,也可以作为区块链系统中的矿工节点负责生成和验证区块。BFL系统的框架结构如图1所示,联邦学习过程的每个迭代周期由七个步骤组成。为了保证模型安全以及实现权限控制,本文框架中所使用的区块链为联盟区块链,只有经过授权的节点才能访问联邦学习过程中的信息。且考虑到参与联邦学习的节点所拥有的存储能力的不一致,框架中引入星际文件系统(interplanetary file system,IPFS),将每一个迭代周期中各训练节点训练得到的局部模型和更新后的全局模型参数存放至IPFS,区块链中只保存相应数据在IPFS中的索引地址,降低节点维护区块链的存储成本。
联邦学习过程的一个完整迭代周期包括如下步骤:
a)根据本文提出的训练节点选择方案,从所有节点中选出一部分参与该轮训练;
b)训练节点根据所维护的区块链最新区块中保存的索引地址,从IPFS获取上一轮聚合得到的全局模型;
c)在上一轮全局模型的基础上,各训练节点使用自己的私有数据在本地进行训练,得到新一轮的局部模型;
d)各训练节点将自己训练得到的局部模型上传至IPFS,并将其在IPFS中的索引地址放入局部模型池;
e)当最后一个训练节点训练完毕并提交其局部模型后,矿工根据索引地址从IPFS中获取所有局部模型;
f)矿工根据所有训练节点本轮提交的局部模型开始竞争提出聚合方案,并使用公共测试集验证准确率,然后将根据各自提出的聚合方案所得到的全局模型上传至IPFS,最后生成相应区块;
g)模型聚合步骤限定的时间结束后,根据准确率最高链原则确定主链,位于主链上的区块的产出矿工获得本轮挖矿奖励。
2.2 准确率最高链原则
在区块链技术领域中,共识机制一般分为两类,一类是基于竞争的共识机制,另一类是基于通信的共识机制。前者首先在链上追加区块,然后达成共识,而后者则是在追加区块之前达成协议。对于基于竞争的共识机制,最常用的两类共识原则就是最长链原则和最重链原则。最长链原则规定包含最多区块的链,即最长的链是主链,区块链网络中的节点应基于主链生成新的区块;而最重链原则强调区块链的有效性不仅由链的长度决定,还取决于区块的权重,这个权重通常根据PoW或其他共识算法的规则来确定,最重链原则规定链上所有区块权重之和最大的链是主链。
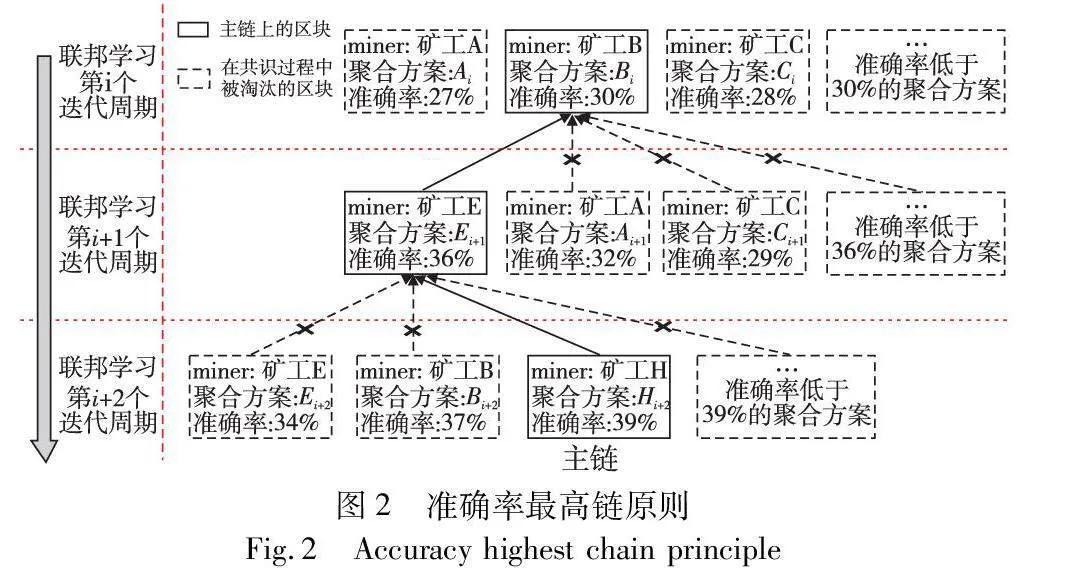
本文针对所提出的基于区块链的去中心化联邦学习模型聚合方案,提出准确率最高链原则用于确定主链,以达成共识。在本文设计的区块结构中,每个区块会包含一种聚合方案以及该聚合方案在公共测试集上的准确率。准确率最高链原则规定,链上所有区块所包含的聚合方案在公共测试集上的准确率之和最高的链为主链,如图2所示。
区块链的每一层分别对应联邦学习一个迭代周期的聚合过程,在聚合过程中,众多矿工可以提出不同的候选聚合方案并生成相应的区块,然后依据准确率最高链原则确定每一层位于主链上的区块。如图2所示,在联邦学习第i+1个迭代周期,在众多矿工生成的区块中,其中矿工E、A、C提出的聚合方案在公共测试集上的准确率分别为36%、32%、29%,依据准确率最高链原则,矿工E所提聚合方案准确率最高,因此矿工E所提区块为区块链第i+1层位于主链的区块。在联邦学习第i+2个迭代周期中所产生的区块应基于联邦学习第i+1个迭代周期中矿工E所产生的区块,同理可得,矿工H在第i+2个迭代周期中所提区块为区块链第i+2层位于主链的区块。
与最长链原则以及最重链原则不同的是,准确率最高链原则在区块链的每一层只会进行一次确定主链的共识过程,确定后不再更改,即使之后有矿工提出了比当前主链上准确率更高的聚合方案并生成区块,该区块也不会被网络中的节点所承认。因为在联邦学习中,一旦确定了主链,达成了共识,就会开始进行下一轮训练,而下一轮的训练是基于上一轮中所确定的主链上最后一个区块中所包含的聚合方案的,如果已经基于主链训练多轮后修改之前的区块,那么从修改的那一层开始,后续所做的训练工作都是无用的,系统不得不从修改的那一层开始重新进行训练,极大浪费了系统的计算资源。因此,本文在每一层生成区块时设置了一个限定时间,不在该限定时间内生成的区块被认为是无效的,限定时间结束后进行本轮共识过程,详细内容见2.3节。
2.3 基于准确率最高链原则的模型聚合方案
传统的联邦学习中,模型聚合由中央服务器负责,各节点将自己训练得到的局部模型发送给中央服务器,服务器根据聚合规则进行聚合,得到新一轮的全局模型并进行广播。在目前已有的去中心化联邦学习框架中,大多是根据一些预设规则选择或选举某一个节点临时充当中央服务器,负责本轮模型的聚合和广播工作。在一组局部模型中,可能有一些并不适合参与本轮聚合,甚至还可能存在恶意节点上传的毒害局部模型,如果将其用于聚合将会影响全局模型的效果以及后续的训练过程。因此,必须有选择地对训练节点提交的局部模型进行聚合,而选择哪些局部模型参与聚合,则是聚合工作要考虑的首要问题。为了筛选出对全局模型有利的局部模型,并找到最佳的聚合方案,最直接的方法就是对所有局部模型以及所有可能的聚合方案进行验证,但是如果只使用一个节点负责聚合工作,验证所有可能的聚合方案所需要的时间会非常长,从而降低联邦学习的效率。
因此,在本文提出的去中心化联邦学习模型聚合方案中,不使用某个单一的节点完成模型的聚合,而是将模型聚合工作交给众多矿工,利用矿工的计算资源完成聚合,并将矿工提出的聚合方案作为其竞争生成区块并获得奖励的衡量条件。模型聚合阶段的主要流程如下:
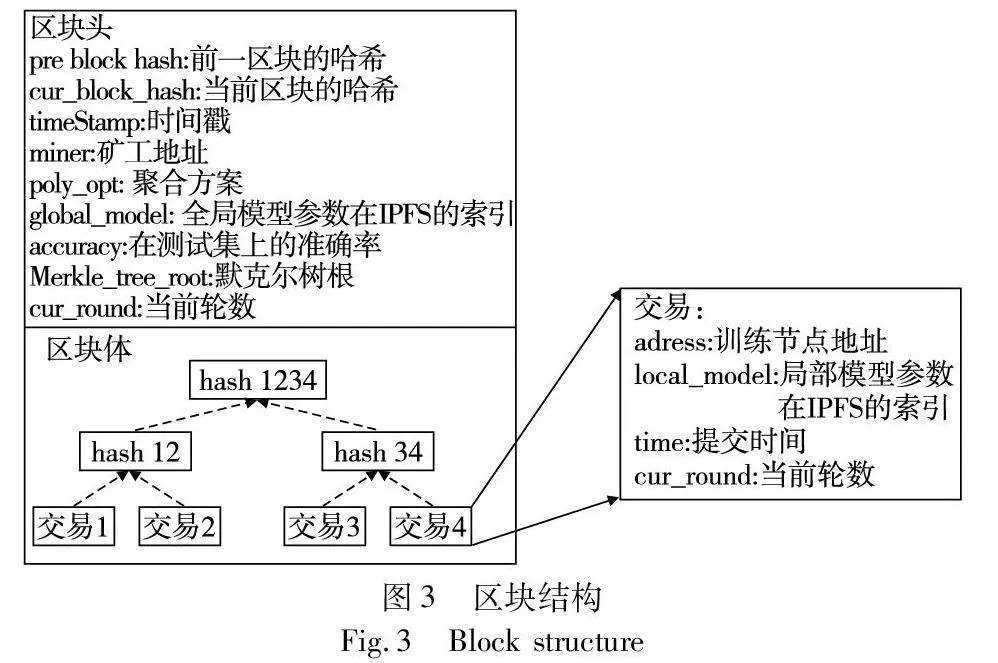
a)把每个训练节点提交局部模型看作是发起一个交易,当最后一个训练节点完成训练并提交其局部模型后,记录此刻时间,矿工可以根据交易信息中包含的索引地址从IPFS获取本轮所有提交的局部模型,并提出各自的聚合方案以及生成相应区块,每个区块所包含的信息如图3所示。
其中每个矿工生成的区块中的区块体部分应该是一致的,都包含本轮所有训练节点提交的局部模型。区块头中的poly_opt是该区块提出的聚合方案,记录该聚合方案使用了哪些训练节点上传的局部模型;global_model是一个IPFS的索引地址,根据该地址可以从IPFS得到由该聚合方案进行聚合所得到的模型梯度;accuracy则是根据该聚合方案聚合得到的全局模型在测试集上的准确率,所有矿工共用一个测试集,且该准确率由矿工自行测试并上传,为防止矿工虚报,在共识过程中所有矿工都可以验证其他矿工提出的聚合方案以及相应准确率。
b)在限定时间LIMIT_TIME之内,矿工可以提出多个聚合方案并生成相应区块,最终根据区块中的时间戳信息判断该区块是否有效。LIMIT_TIME应根据参与训练的节点数、聚合需要的最少局部模型数量、验证一个聚合方案的时间以及矿工的数量动态调整。LIMIT_TIME的计算公式为
LIMIT_TIME=T×∑Ni=LCiNM(1)
其中:N为参与训练的节点数;L(L≤N)为至少需要聚合的局部模型个数;T为验证一个聚合方案的时间;M为矿工的数量;CiN表示从N个局部模型中选择i个。假设N为10,L为5,则一共有∑10i=5Ci10,即638种聚合方案。
LIMIT_TIME设置得太小,会导致矿工来不及验证所有聚合方案,提出的聚合方案中可能不包含最佳方案;设置得太大,则会增加系统的时间开销。之所以设置LIMIT_TIME,是为了防止有恶意矿工为了获得更多奖励发动块扣留攻击,在找到高准确率的聚合方案后隐瞒不公布,待联邦学习进入下一轮后再将其公布出来,使得所有节点不得不重新确定主链,影响整个联邦学习。
c)限定时间结束后,矿工停止生成区块,所有节点根据准确率最高链原则确定主链,即链上包含的所有区块中,提出的聚合方案在测试集上的准确率之和最高的链为主链,后续的模型聚合阶段矿工应基于主链生成新的区块。
确定主链后即可开始联邦学习下一个迭代周期,选出新一轮训练节点后,训练节点根据主链上的最新区块中包含的索引地址,从IPFS获取新一轮的全局模型,并进行本地训练。
2.4 基于质押“训练币”的训练节点选择方案
PoS是区块链网络中一种常用的共识算法,其采用伪随机选举方式,从一组节点中选择一个验证者生成下一区块。主要思想是通过节点质押代币的方式,根据各节点的“币龄”来选择验证者,“币龄”越大,被选中的概率也越大。其中“币龄”为节点质押的代币数量与节点持有代币时长的乘积,为了防止权益大的节点主宰区块链,当一个节点被选为验证者后,其“币龄”将会清零。
本文提出的训练节点选择方案借鉴了PoS的思想,提出节点通过质押“训练币”来获取参与训练的机会。当节点经过授权加入联盟链时,系统会给节点发放k个初始“训练币”,在联邦学习的每个迭代周期的训练节点选择阶段,节点会质押其拥有的“训练币”,系统根据“币龄”的大小,随机选择一组节点作为本轮的训练节点。其中“币龄”是节点持有“训练币”的数量与节点持有币的时长的乘积,这里的时长是指联邦学习的迭代周期数。
在联邦学习第1个迭代周期,由于每个节点的“币龄”都是相同的,所以每个节点被选为训练节点的概率也是相同的,但是从第2个迭代周期开始,某些节点的“币龄”就会发生改变,从而各个节点被选为训练节点的概率也会发生变化。假设在联邦学习每个迭代周期,系统中有n个节点,节点集合为S={S1,S2,…,Si,…,Sn},每个节点当前拥有的“训练币”数量为B={B1,B2,…,Bi,…,Bn},每个节点持有其“训练币”的时长为R={R1,R2,…,Ri,…,Rn},本轮参与训练的节点集合为Train_S,Train_S是S的一个子集。则节点Si在该轮被选择为训练节点,即节点Si被选入子集Train_S的概率为
Pi=Bi×Ri∑nk=1Bk×Rk(2)
当一组节点被选中作为训练节点后,Train_S集合中所有节点的持有“训练币”的时长需从1重新计算,如果Train_S集合中某个节点训练的局部模型被用于本轮主链上的区块所记录的聚合方案,即本轮准确率最高的聚合方案中,将该节点质押的“训练币”全部返还,并额外奖励其p个“训练币”,否则只返还该节点所质押的q%(0<q<100)“训练币”。该训练节点选择过程伪代码如算法1所示。
算法1 训练节点选择
输入:B,S,R。
输出:Train_S。
1 for Si:i=1,2,…,n:
2 Pi=Bi×Ri∑nk=1Bk×Rk //计算每个节点被选择的概率
3 Train_S=SelectNodes(S,P) //根据概率随机选择训练节点
4 for Si:i=1,2,…,n:
5 if Si not in Train_S: //如果节点Si未被选为训练节点
6 Ri+=1
7 else
8 Ri=1
9 aggr = {aggr1,aggr2,…,aggrn} //矿工提出聚合方案
10 best_aggr=MaxAccuracy(aggr)// 准确率最高聚合方案
11 for Si in Train_S:
12 if Si in best_aggr: /*如果节点Si训练的局部模型参与了准确率最高方案的聚合*/
13 Bi+=p
14 else
15 Bi *=q%
16 end
该训练节点选择方案可以在一定程度上抑制恶意节点,降低它们被选为训练节点的概率。在联邦学习的整个过程中,相比恶意节点,行为诚实、为联邦学习作出积极贡献的节点将有更大的概率被选中成为训练节点;同时,由于资源限制而在某些轮次未被选中的诚实节点,随着它们持有“训练币”的时长增加,也能获得成为训练节点并获取奖励的机会。该方案综合考虑节点的历史贡献、当前资源及诚实程度,既能惩罚恶意节点,也让诚实节点获得更多参与训练的机会,从长远看可以促进联邦学习的健康发展。
3 实验分析
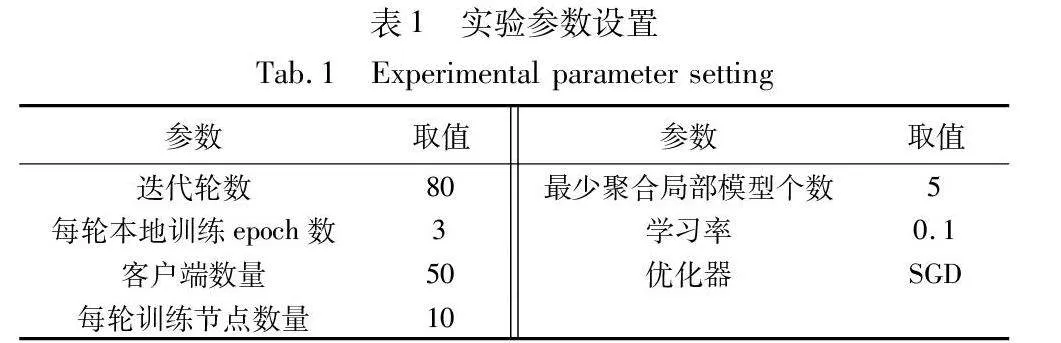
为了验证本文方案的有效性,实验在64位Windows操作系统,CPU为Intel i5-12490F 6核 3.00 GHz,GPU为RTX2080,内存为16 GB的计算机上运行。实验所使用的数据集为CIFAR-10[7],CIFAR-10是一个用于普适物体识别的计算机视觉数据集,包含50 000个训练样本和10 000个测试样本,每个样本都是一张32×32的RGB彩色图片,总共10个类别。实验将训练集平均分成80份,每份包含625个训练样本,但只使用了其中50份数据进行联邦学习训练。实验中的网络模型选用ResNet50网络,它由49个卷积层和1个全连接层组成。在模拟恶意节点时利用标签反转进行攻击,将CIFAR-10数据集中的源标签全部改为目标标签“3”。实验所涉及的一些其他参数的设置如表1所示。
3.1 训练节点选择实验
为了验证本文所提训练节点选择方案的有效性,实验在50个客户端中分别设置5、10、15、20个恶意节点,联邦学习终止条件为达到80轮迭代,实验中本文训练节点选择方案参数设置k为10,p为10,q为20,即联邦学习系统为每个节点发放10个初始“训练币”,如果节点训练的局部模型被用于聚合本轮最优全局模型,则额外奖励该节点10个“训练币”,否则只返还该节点20%所质押的“训练币”以示惩罚。
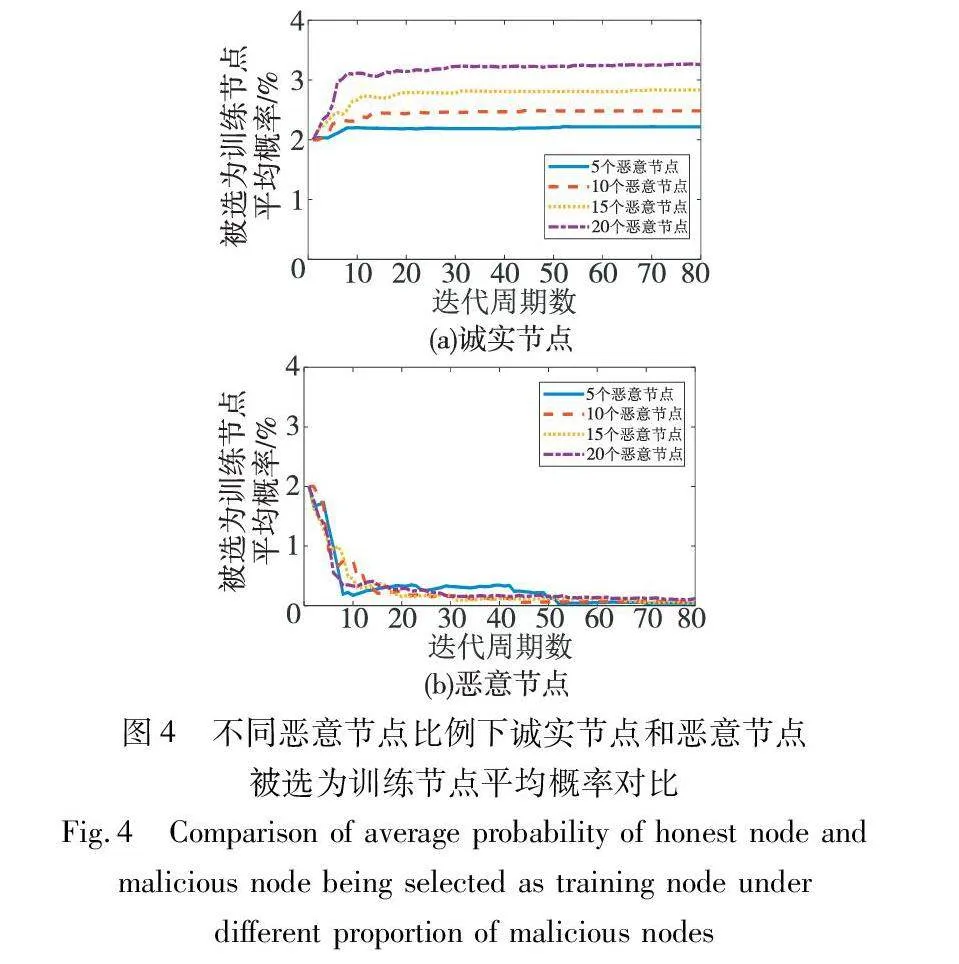
实验在使用本文训练节点选择方案情况下,在联邦学习每一轮迭代开始时统计诚实节点和恶意节点拥有的币龄,并分别计算系统中诚实节点和恶意节点在每一轮迭代中被选为训练节点的平均概率,结果如图4所示。节点总数为50,每一轮迭代选择10个节点作为训练节点,所以初始时每个节点被选择的概率都是2%。随着联邦学习迭代周期的增加,诚实节点由于积极为训练模型作出贡献受到奖励,所以它们被选择的平均概率能一直保持甚至超过2%。与之相反,恶意节点在迭代过程中被系统惩罚,被选择的平均概率会一直下降并趋于0。
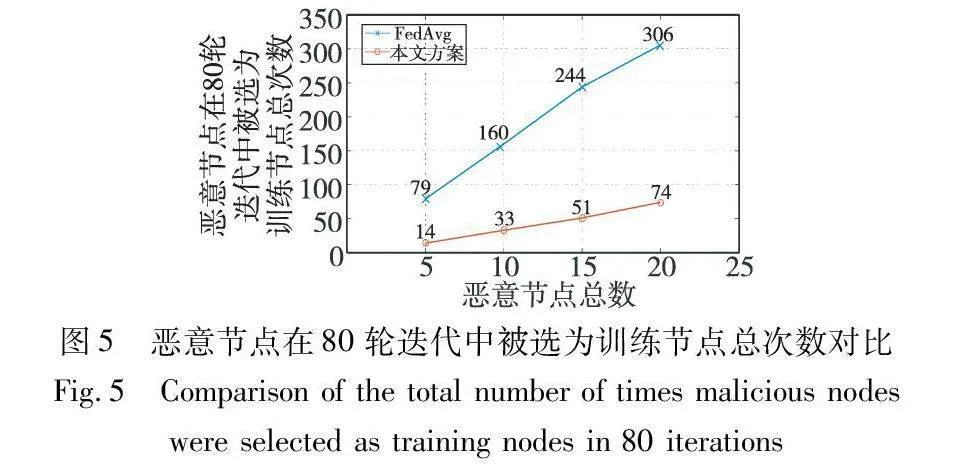
实验分别统计FedAvg方案和本文训练节点选择方案在联邦学习80轮迭代过程中选择恶意节点参与训练的总次数,统计结果如图5所示。随着恶意节点的比例增加,虽然本文方案选择恶意节点作为训练节点的总次数也在小幅增长,但是相比于FedAvg方案,无论是增长的幅度还是选择恶意节点参与训练的总次数都大大减少,在联邦学习80轮迭代过程中选择恶意节点参与训练的总次数只有FedAvg方案的20%左右。
以上实验可以证明本文所提出的联邦学习训练节点选择方案在系统存在恶意节点时,能够在一定程度上抑制恶意节点,降低恶意节点被选为训练节点的概率,从而能在有限的联邦学习迭代周期中将更多的训练机会分配给诚实节点,提高模型的训练效果。
3.2 模型聚合实验
为了验证本文模型聚合方案的有效性,分别从系统存在不同恶意节点比例下模型准确率、使用非独立同分布(non-IID)数据训练情况下的模型准确率、LIMIT_TIME的设置这三个方面进行实验。实验将本文方案与FedAvg[1]、BFLC[20]以及FedPNS[22]进行对比,联邦学习终止条件为迭代80轮。BFLC方案实验中设置委员会由5个诚实节点组成,委员会成员使用自己的数据集进行验证并打分,每一轮选取得分最高的5个局部模型进行聚合。FedPNS方案的思想是根据局部模型梯度与全局模型梯度的内积来识别并排除不利的局部更新,从而找出每轮参与聚合的最优子集,并根据最优聚合的输出动态改变每个节点被选择的概率。在本文实验中,根据文献[22]中的说明,将FedPNS方案中的参数α设为2,β设为0.7,这两个参数用于控制节点被选概率下降的大小。
3.2.1 不同恶意节点比例下模型准确率
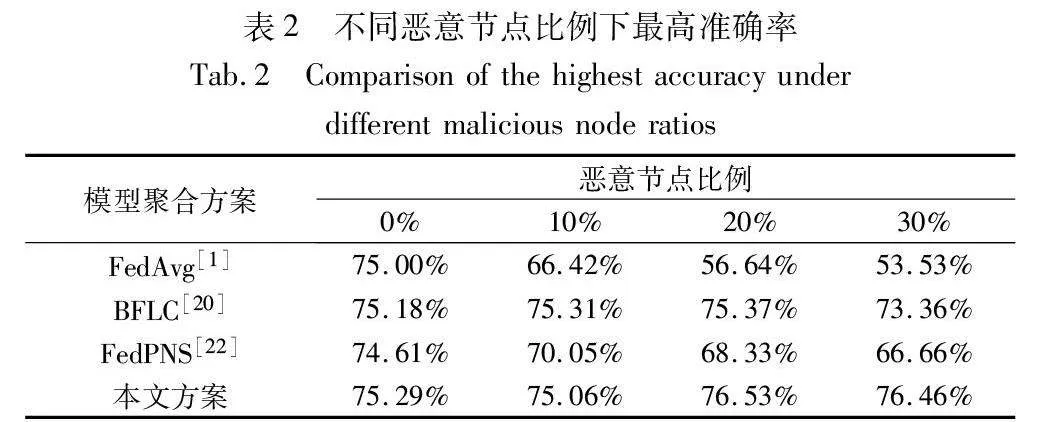
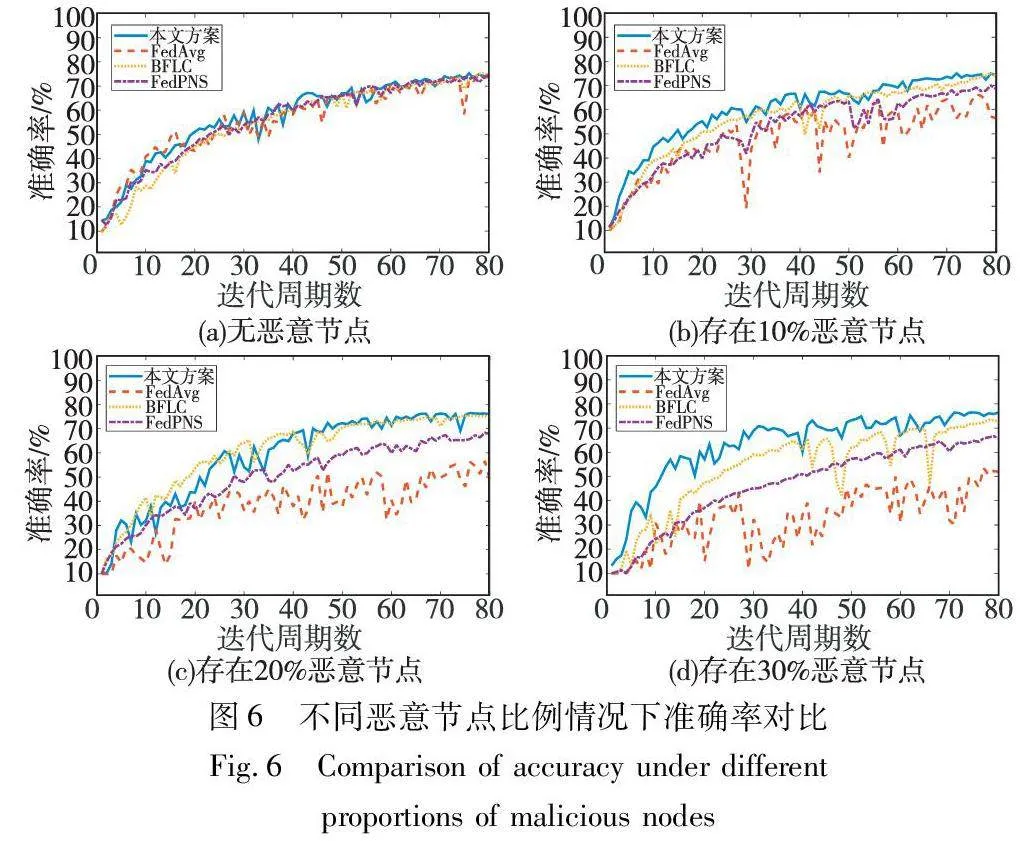
实验分别在无恶意节点、存在10%恶意节点、存在20%恶意节点、存在30%恶意节点的情况下测试模型准确率,即存在恶意节点时,训练得到的模型在CIFAR-10数据集的测试集上分类正确的样本占总样本的比例。实验结果如图6所示。
当系统中无恶意节点时,本文方案和FedAvg方案的准确率几乎相同,但是当系统中存在恶意节点时,本文方案的准确率明显高于FedAvg方案,且随着恶意节点比例的增加,本文方案依然能保持较高的准确率。在这四种不同恶意节点比例情况下,本文方案和FedAvg、BFLC以及FedPNS方案所能达到的最高准确率如表2所示。当系统中恶意节点比例分别为10%、20%、30%时,本文方案的准确率比FedAvg方案分别高8.64、19.89、22.93百分点。
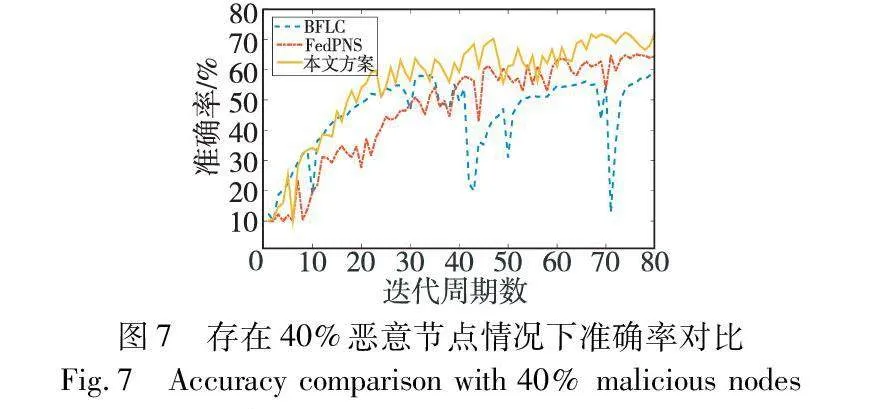
为了进一步比较本文方案和BFLC以及FedPNS在系统存在大量恶意节点情况下的模型训练效果,实验将恶意节点数量增加到40%。结果表明,虽然本文方案所能达到的最高准确率相比于更少恶意节点情况下有所下降,但仍能达到70%以上,而BFLC方案在系统存在40%恶意节点情况下,最高准确率低于60%,且在训练过程中准确率出现了非常大的波动,FedPNS方案所能达到的最高准确率同样低于本文方案,如图7所示。这进一步验证了本文方案在应对大量恶意节点的场景下,仍然能够保持更好的模型训练效果。
3.2.2 non-IID数据训练情况下模型准确率
在实际的联邦学习应用中,本地客户端的数据往往是non-IID的,即不同客户端的数据可能拥有不同的分布,这给模型的训练带来了很大的挑战。因此,验证联邦学习方案在non-IID数据下的性能,对于评估方案的鲁棒性和适用范围具有重要意义。
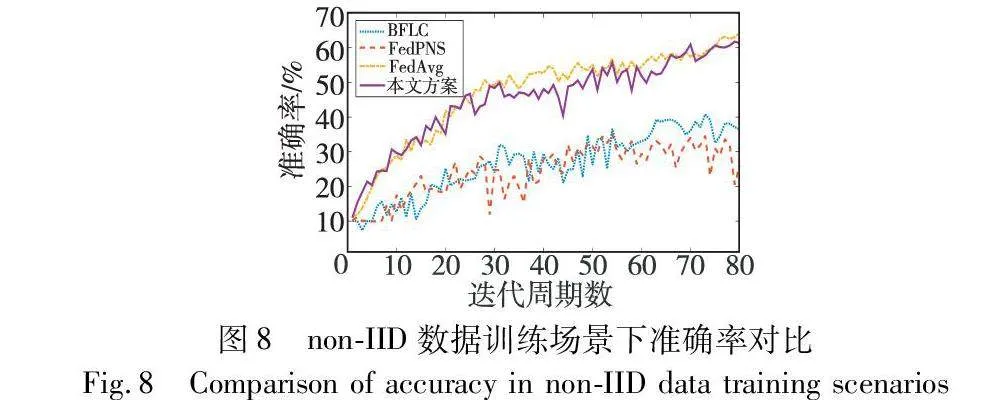
为了评估本文模型聚合方案在non-IID数据训练下的表现,实验划分了一份non-IID的数据集。具体地,就是将CIFAR-10数据集按照标签类别进行划分,使得50个节点所拥有的数据量各不相同,且不同节点只拥有某些特定类别的数据,例如1号节点可能只拥有标签为“2”和标签为“5”的数据。在本文实验中,划分的这份non-IID数据集仅使用了CIFAR-10数据集50 000个训练样本中的一部分。在此训练场景下,实验测试了本文方案、FedAvg以及BFLC的准确率。实验结果如图8所示,可以看出,在non-IID数据训练情况下,本文方案所能达到的准确率相比于在正常数据集上的训练有一定程度的下降,略低于FedPNS方案,但是仍明显优于FedAvg和BFLC。这表明本文方案在non-IID数据训练场景下仍表现良好,具有较强的鲁棒性和适用性。
3.2.3 LIMIT_TIME设置
如2.2节所述,在所有训练节点提交局部模型后,需设置一个限定时间LIMIT_TIME,作为所有矿工提出并验证聚合方案以及生成有效区块的时间。LIMIT_TIME必须设置为合适大小才能保证系统达到最优性能。如果设置得过小,矿工验证聚合方案的时间太少,可能来不及验证所有聚合方案,提出的准确率最高方案并不一定最优;如果设置得过大,矿工验证完所有聚合方案后还有时间剩余,平白增加系统的时间开销,降低联邦学习的效率。
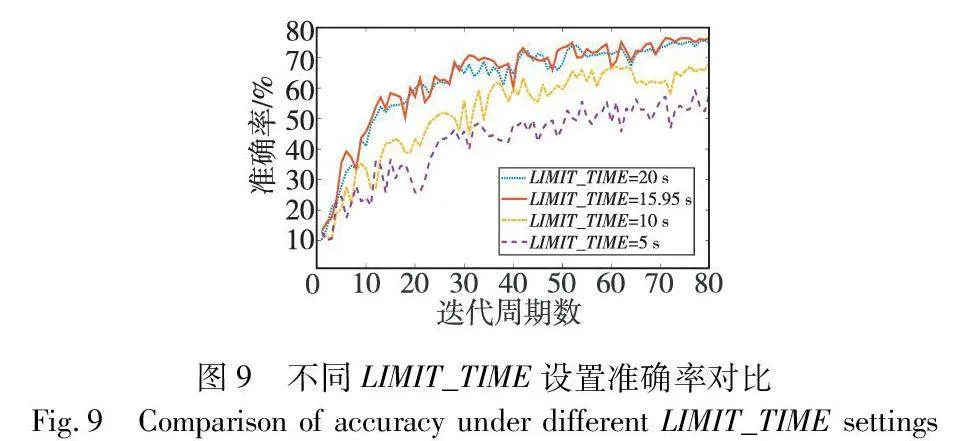
为了验证式(1)的有效性,实验在系统存在30%恶意节点、矿工数量为40的情况下进行,实验所用计算机验证一次聚合方案的时间约为1 s,根据式(1)计算可得LIMIT_TIME应设置为15.95 s。实验设置不同的LIMIT_TIME并对比准确率,假设所有节点不会中途退出,且实验参数不会中途更改,即LIMIT_TIME无须动态变化,实验结果如图9所示。
可以看到,当LIMIT_TIME设置得比15.95 s更小时,联邦学习所能达到的准确率也随之降低,且LIMIT_TIME越小,准确率越低;当LIMIT_TIME设置得比15.95 s大时,联邦学习所能达到的准确率也并无明显提高。
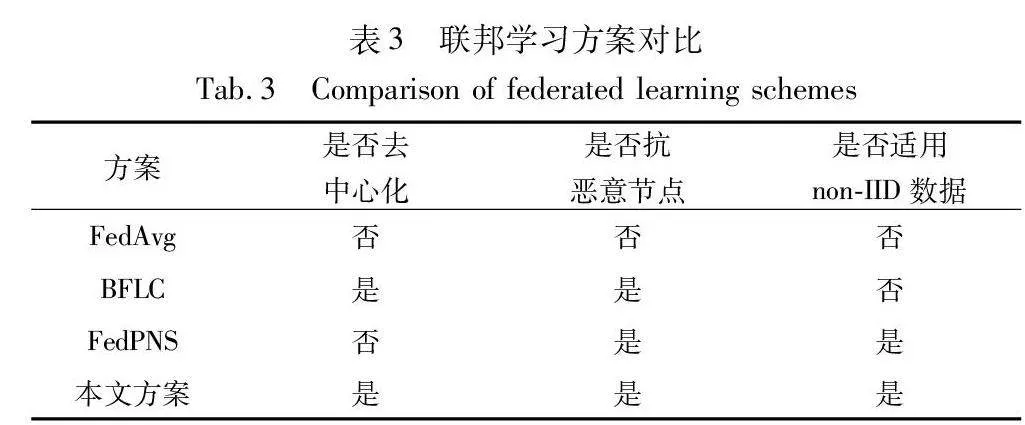
3.3 方案对比总结
通过上述实验,可以看到本文方案在多个关键方面与现有的其他方案有显著的不同,表3对比了本文方案与其他方案在若干重要特性上的表现。
在联邦学习领域,FedAvg方案作为一种广泛使用的方法,虽然在普遍情况下表现良好,但它并没有充分考虑恶意节点的影响,这在安全性要求较高的应用场景中可能成为一个重要的局限。而BFLC方案通过引入区块链技术,有效提高了系统对恶意节点的抵抗能力,但它并不适用于non-IID数据训练场景,限制了在数据多样性环境中的应用。FedPNS方案虽然在处理恶意节点和适应non-IID数据训练方面表现出色,但它仍然是一个中心化的解决方案,这可能带来中心化系统所固有的风险和局限。本文方案则结合了区块链的去中心化优势,能够在保证准确率的同时,有效地应对大量恶意节点的挑战,并且同样适用于non-IID数据训练场景。这使得本文方案在安全性、适应性和去中心化等多个维度上展现出较其他方案更加全面和均衡的性能优势。
4 结束语
本文从联邦学习模型聚合以及节点选择的角度研究区块链与联邦学习的结合,提出一种基于区块链的去中心化联邦学习模型聚合方案,将聚合工作交给众多矿工而非某个单一节点完成,利用矿工的计算资源来完成模型聚合,并且把矿工所提出的聚合方案在公共测试集上的准确率作为达成共识的标准,将区块链的共识过程和联邦学习的模型聚合过程进行整合,大大降低了联邦学习系统的计算负担,且保证了模型聚合方案的最优性。同时,基于该模型聚合方案,提出在训练节点选择阶段使用“训练币”,根据“币龄”的大小随机选取训练节点,提高积极对系统做贡献节点的被选中概率,同时降低恶意节点的机会。实验结果表明,本文方案在系统存在大量恶意节点时仍然能保持较高的准确率,具有较好的安全性和鲁棒性。但在选择聚合方案时只根据准确率进行贪心选择,有可能会陷入局部最优,下一步将研究设计更公平且有效的选择策略,以提高联邦学习训练效果。
参考文献:
[1]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of International Conference on Artificial Intelligence and Statistics. San Francisco: Morgan Kaufmann, 2017: 1273-1282.
[2]Banabilah S, Aloqaily M, Alsayed E, et al. Federated learning review: fundamentals, enabling technologies, and future applications[J]. Information Processing & Management, 2022,59(6): 103061.
[3]Berdik D, Otoum S, Schmidt N, et al. A survey on blockchain for information systems management and security[J]. Information Processing & Management, 2021, 58(1): 102397.
[4]李凌霄, 袁莎, 金银玉. 基于区块链的联邦学习技术综述[J]. 计算机应用研究, 2021,38(11): 3222-3230. (Li Lingxiao, Yuan Sha, Jin Yinyu. Review of blockchain-based federated learning[J]. Application Research of Computers, 2021, 38(11): 3222-3230.)
[5]Kim H, Park J, Bennis M, et al. Blockchained on-device federated learning[J]. IEEE Communications Letters, 2019, 24(6): 1279-1283.
[6]Weng Jiasi, Weng Jian, Zhang Jilian, et al. DeepChain: auditable and privacy-preserving deep learning with blockchain-based incentive[J]. IEEE Trans on Dependable and Secure Computing, 2019,18(5): 2438-2455.
[7]Krizhevsky A. Learning multiple layers of features from tiny images[D]. Toronto :University of Toronto, 2009.
[8]Toyoda K, Zhang A N. Mechanism design for an incentive-aware blockchain-enabled federated learning platform[C]//Proc of IEEE International Conference on Big Data. Piscataway, NJ: IEEE Press, 2019: 395-403.
[9]Gao Liang, Li Li, Chen Yingwen, et al. FGFL: a blockchain-based fair incentive governor for federated learning[J]. Journal of Parallel and Distributed Computing, 2022, 163: 283-299.
[10]Qi Minfeng, Wang Ziyuan, Chen Shiping, et al. A hybrid incentive mechanism for decentralized federated learning[J]. Distributed Ledger Technologies: Research and Practice, 2022,1(1): 1-15.
[11]Ramanan P, Nakayama K. BAFFLE: blockchain based aggregator free federated learning[C]//Proc of IEEE International Conference on Blockchain. Piscataway, NJ: IEEE Press, 2020: 72-81.
[12]Yu Feng, Lin Hui, Wang Xiaoding, et al. Blockchain-empowered secure federated learning system: architecture and applications[J]. Computer Communications, 2022,196: 55-65.
[13]Qu Xidi, Wang Shengling, Hu Qin, et al. Proof of federated lear-ning: a novel energy-recycling consensus algorithm[J]. IEEE Trans on Parallel and Distributed Systems, 2021, 32(8): 2074-2085.
[14]Lu Yunlong, Huang Xiaohong, Dai Yueyue, et al. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT[J]. IEEE Trans on Industrial Informatics, 2019, 16(6): 4177-4186.
[15]Jin Hai, Dai Xiaohai, Xiao Jiang, et al. Cross-cluster federated learning and blockchain for Internet of medical Things[J]. IEEE Internet of Things Journal, 2021, 8(21): 15776-15784.
[16]Zhou Sicong, Huang Huawei, Chen Wuhui, et al. Pirate: a blockchain-based secure framework of distributed machine learning in 5G networks[J]. IEEE Network, 2020, 34(6): 84-91.
[17]Zhao Yang, Zhao Jun, Jiang Linshan, et al. Privacy-preserving blockchain-based federated learning for IoT devices[J]. IEEE Internet of Things Journal, 2020, 8(3): 1817-1829.
[18]Kang Jiawen, Xiong Zehui, Niyato D, et al. Incentive mechanism for reliable federated learning: a joint optimization approach to combining reputation and contract theory[J]. IEEE Internet of Things Journal, 2019, 6(6): 10700-10714.
[19]Ur Rehman M H, Salah K, Damiani E, et al. Towards blockchain-based reputation-aware federated learning[C]//Proc of IEEE Confe-rence on Computer Communications Workshops. Piscataway, NJ: IEEE Press, 2020: 183-188.
[20]Li Yuzheng, Chen Chuan, Liu Nan, et al. A blockchain-based decentralized federated learning framework with committee consensus[J]. IEEE Network, 2020, 35(1): 234-241.
[21]Zhu Juncen, Cao Jiannong, Saxena D, et al. Blockchain-empowered federated learning: challenges, solutions, and future directions[J]. ACM Computing Surveys, 2023, 55(11): 1-31.
[22]Wu Hongda, Wang Ping. Node selection toward faster convergence for federated learning on non-IID data[J]. IEEE Trans on Network Science and Engineering, 2022, 9(5): 3099-3111.
