一种基于多维表示的汉字识别方案
2024-08-06陈成姜明张旻



关键词:汉字识别;特征提取;关键笔形;多任务网络
中图分类号:TP391 文献标志码:A
0 引言(Introduction)
汉字识别技术在图像识别领域占据核心地位,尤其在单据处理和证件验证等应用中发挥了至关重要的作用。然而,现有研究主要集中于背景清晰的图像,而忽视了复杂环境下的识别挑战。图像模糊和噪声显著增大了特征提取的难度,影响了识别准确率。目前,主流方法是基于字符细粒度特征辅助汉字识别,但在复杂场景下提取有效特征仍然面临挑战,暴露了现有方法的不足。因此,如何提升汉字的有效特征提取能力,并通过有限的特征实现字符准确识别,成为当务之急[1]。为此,本文提出一种融合空间信息的关键笔形特征提取方法,仅使用少量的关键特征即可准确识别汉字;同时,通过多任务网络提取多维特征,包括字符、字根和关键笔形,并应用字符相似度算法减少特征噪声,提升识别准确性。通过实验证明,本方法显著提升了汉字在复杂场景下的识别准确率。
1 相关研究(Related work)
目前,基于深度学习的汉字识别主流方法大致可分为基于字符和基于字根两种。以下将详细介绍这两种方法相关技术的发展,以及复杂场景下汉字识别技术的发展情况。
1.1 基于字符的方法
早期的汉字光学字符识别(OCR)方法依赖于模板匹配和规则引擎[2],这在处理数量庞大且形态多样的中文字符时,常面临准确性和扩展性方面的挑战。随着深度学习技术的发展,卷积神经网络(CNN)开始被广泛应用于汉字的识别任务中。随后,循环神经网络(RNN)和长短时记忆网络(LSTM)等模型被应用于建模和识别字符序列。循环卷积神经网络(CRNN)[3]的出现进一步推动了字符识别技术的发展。MORAN(Multi-Object Rectified Attention Network)模型[4]将传统特征与深度学习方法相结合,引入特定领域的知识以增强模型的性能。FANG 等[5] 提出ABINET (Autonomous,Bidirectional and Iterative Language Modeling for Scene TextRecognition)模型,采用端到端的训练模式,结合语言模型捕获文本的全局上下文信息,从而显著提升文本识别的准确性和效率。由于基于字符的方法在某些情形下难以区分相似字符,因此开发更高效的特征提取方法对于提升汉字识别的准确性与鲁棒性至关重要。
1.2 基于字根的方法
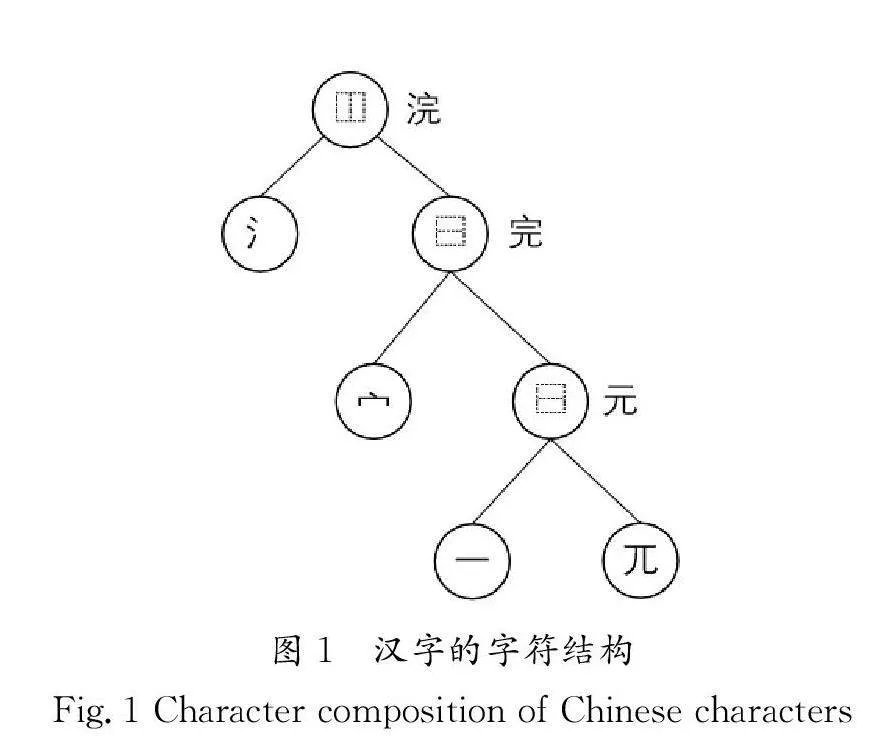
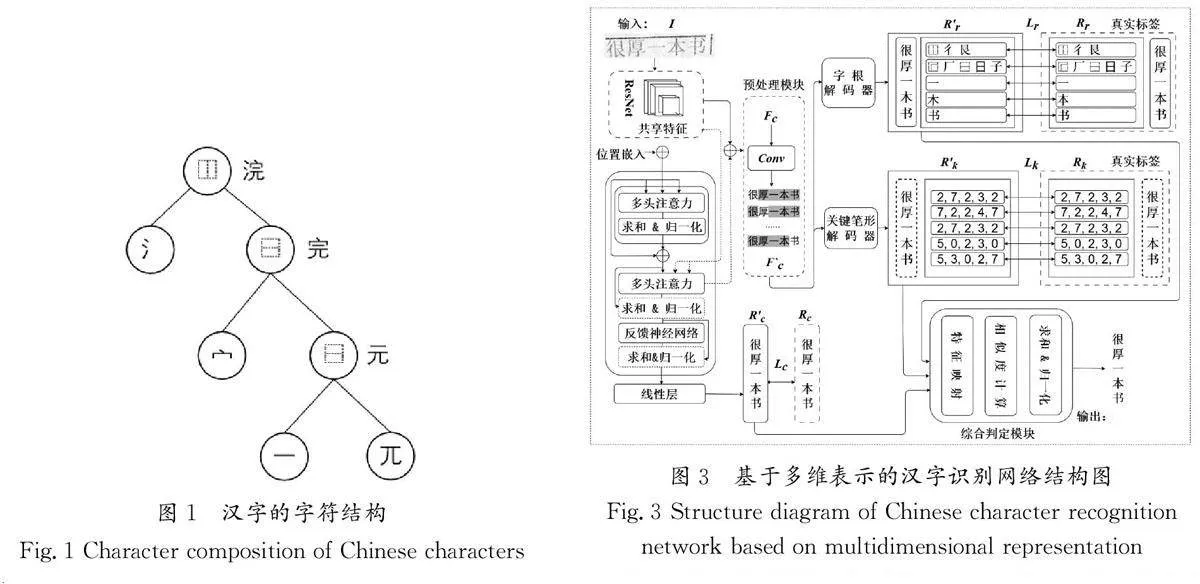
如图1所示,汉字的字符结构遵循国家标准(GB 18030—2005)进行分类,采用递归分层方案对字符进行解析,可以将汉字解构为含有多个结构和字根的树状结构。具体来说,汉字结构可根据UTF-8(Unicode Transformation Format-8 bits)编码标准进一步划分为12个基本类别。汉字基本结构的详细定义如图2所示。
在传统的汉字识别方法中,字根识别通常依赖于预先提取的笔画信息。随后,研究者基于字根的方法采用逐像素匹配算法,直接从汉字图像中提取字根信息。然而,随着深度学习技术的兴起和其在汉字识别领域的广泛应用,研究者开始将字根识别转化为序列预测问题,并将其应用于字符识别,这种方式显著提高了汉字的识别准确率。但是,复杂场景下的汉字识别仍面临不少挑战。
1.3 复杂场景中汉字识别方法
目前,针对复杂场景中文本识别的问题,基于空间变换的网络被用于处理场景文本中的变形汉字[6],进一步增强了模型对复杂场景的适应性。随后,SHI等[7]提出ASTER(Anattentional scene text recognizer with flexible rectification)模型,基于注意力机制创建了一个具有灵活校正能力的场景文本识别器,它融合了注意力机制和自适应文本校正技术,显著提高了在具有复杂背景场景中文本的识别准确率。QIAO等[8]提出了SEED(Semantics enhanced encoder-decoder frameworkfor scene text recognition)模型,构建了一种语义增强的编解码器框架,用于场景文本识别。该框架通过结合语义信息提升文本识别的准确性。LU 等[9]提出了一个多方面非局部网络(MASTER),该网络针对场景文本识别任务,通过融合多个视角的非局部特征提高识别精度和鲁棒性。
2 实现细节(Implementation details)
本文提出了一种融合字符、字根和关键笔形的多维表示汉字识别模型(MRCCR)。基于多维表示的汉字识别网络结构图如图3所示,主要由3个部分组成:共享特征提取模块、多任务特征提取网络及多维特征综合判定模块。
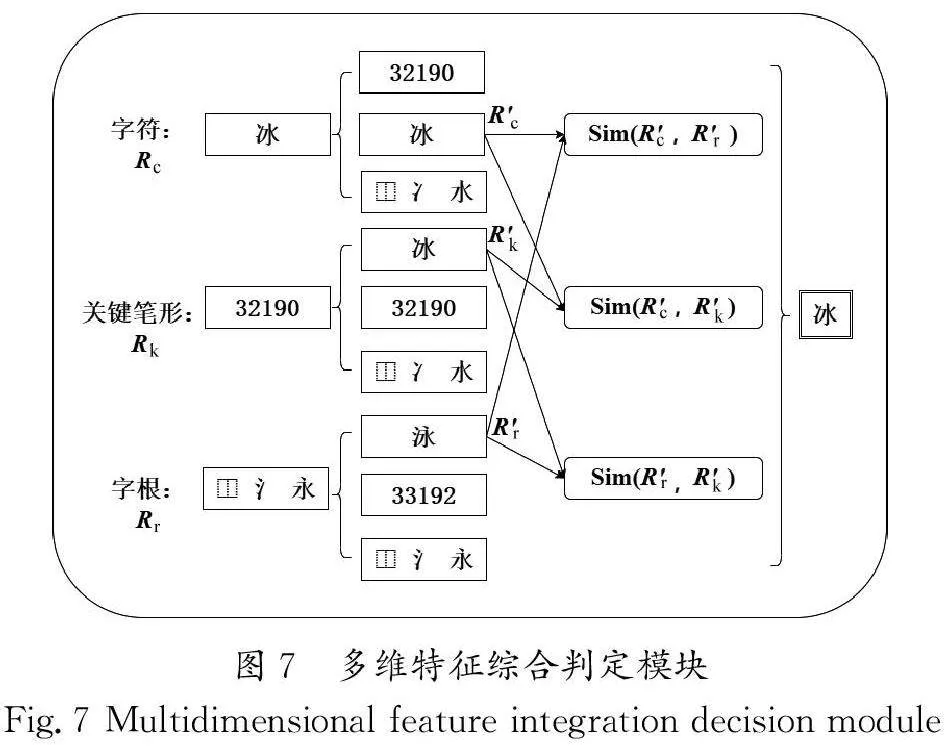
首先,模型利用深度残差网络(ResNet)提取图像的共享特征,为下一步的特征提取和识别任务打下坚实的基础。其次,通过多任务学习策略,模型在特征提取网络中并行提取字符、字根和关键笔形的多层次特征,旨在增强特征的表征性能。再次,通过反向传播机制,模型持续优化共享特征的提取过程,从而增强特征的表达能力和识别精度。最后,在多维特征综合判定模块中,模型对提取的多维特征进行评估和融合,使用相似度算法筛选出关联性高的特征,剔除低相关性特征污染,实现特征的最优融合。此方法有效提升了模型对复杂汉字识别的鲁棒性和准确性。
2.1 融合空间信息的关键笔形特征提取方法
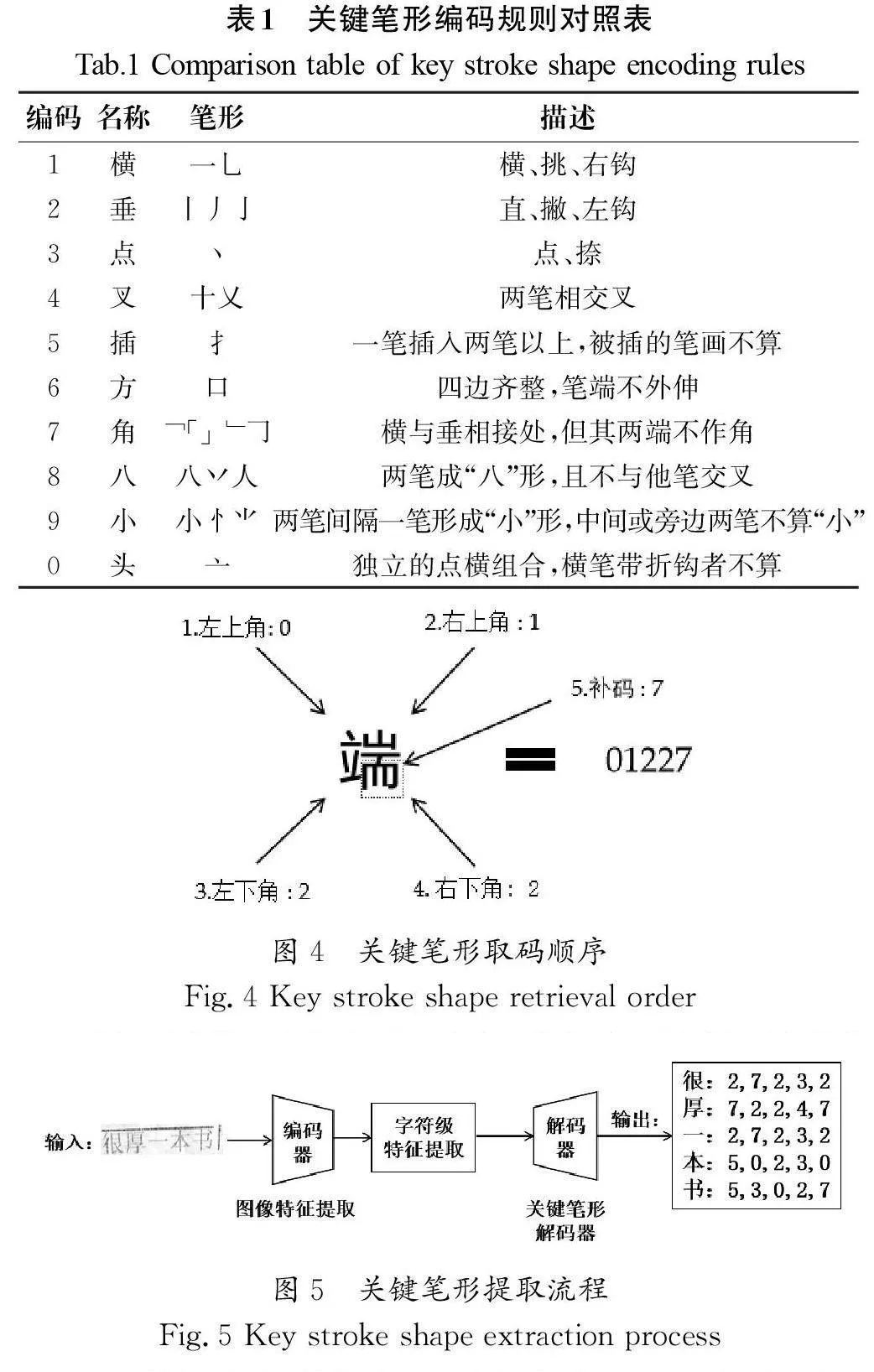
如表1所示,关键笔形的定义依据四角编码标准(CY/T271—2023)进行划分,该方法将汉字中的单笔形或复合笔形进行唯一编号。与传统依赖笔顺的编码方式不同,四角编码方式根据笔画在空间中的位置顺序,从汉字的左上角、右上角、左下角和右下角提取对应的单笔或复合笔画进行编码。为优化编码的唯一性并减少重复,编码过程中会在靠近右下角(第四角)的上方额外选取一个笔画作为补充编码。若该补充笔画与右上角的编码相同,则此补充编码记为0。以“端”字为例(图4),按照四角编码的规则,其左上角的笔画编码为“亠”,右上角的笔画编码为“丨”,左下角的笔画编码为“ ”,右下角的笔画编码为“亅”,并以“”作为补充编码。综上,通过对照笔画标准,“端”字的四角编码确定为“0,1,2,2,7”。
关键笔形提取流程如图5所示。首先,将图片输入编码器中提取初步字符特征及注意力矩阵。其次,将注意力矩阵与对应位置的卷积特征图点乘,并采用1×1的卷积层进行特征压缩,得到字符级别图像特征。再次,将字符级特征输入关键笔形解码器中进行解码。最后,输出相应的关键笔形编码。
基于关键笔形的特征提取方法在编码过程中,不仅保留了特征序列的前后关系,还将笔形之间的空间关系融入特征序列中。传统的汉字细粒度特征以特征序列的形式展开,仅包含了特征之间的前后关系,未能充分反映特征之间的空间关系。采用基于关键笔形的特征编码方式,能够为特征提取提供更丰富的空间特征,从而提升提取特征的信息量。
2.3 多维表征提取模块
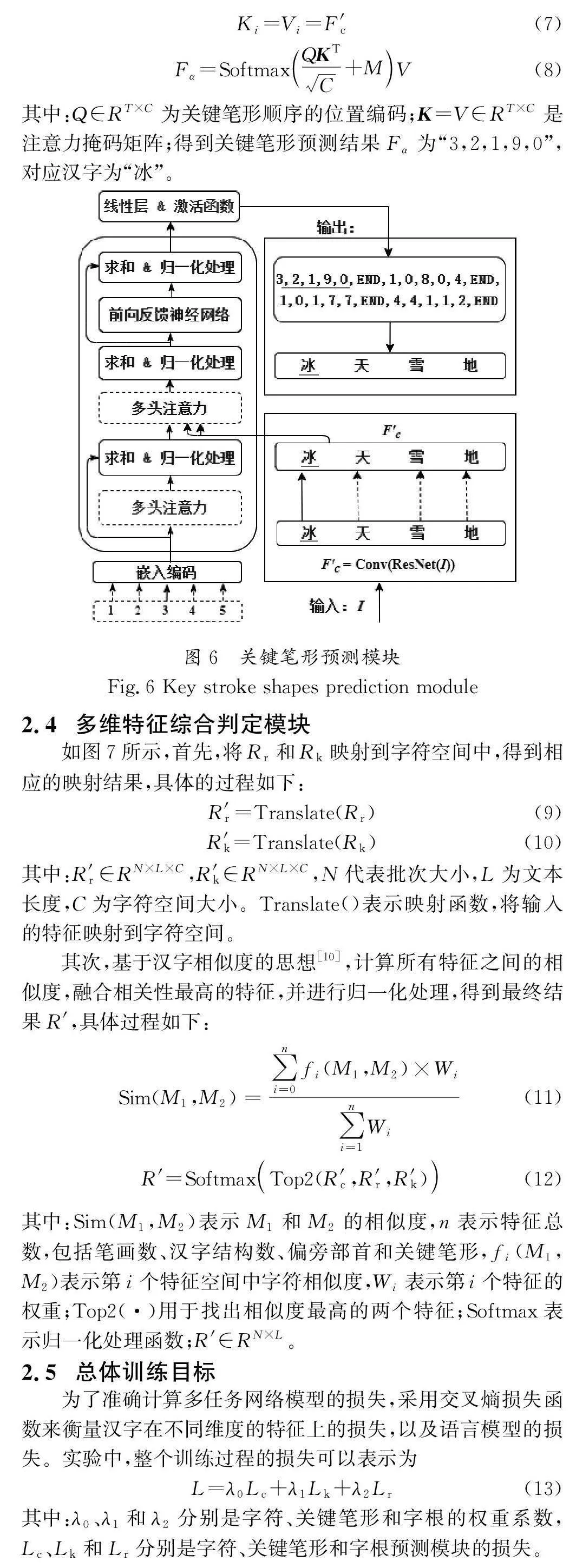
汉字的细粒度特征具有多种表示形式,例如字符、字根和关键笔形特征。表2展示了汉字“浣”涵盖的多维特征。为了提取字符、字根和关键笔形3个维度的特征,设计了多维表征提取模块。该模块通过多任务的方式,利用字符、字根和关键笔形3个特征预测模块,分别提取相应的特征。
通过合理设置权衡系数,可以确保模型在各个方面的损失得到平衡,从而更好地优化模型的性能。
3 实验(Experiments)
3.1 数据集
为了更好地比较模型在中文数据集的性能,在中文文本识别通用数据集(CTR)[11]上比较当前基准模型。此外,为更好地适应复杂场景下的印刷文本识别需求,基于Text Render5创建了4个复杂场景印刷文本数据集。
通用数据集CTR的场景数据集包含背景复杂的、模糊的、字体不同的和遮挡的636 455个文本样本。网页数据集训练集数据一共包含140 589张中英文网页文本图像。文本数据集是由Text Render5生成的文本样式文本图像。语料库来自维基百科、电影、亚马逊和百度。该数据集共包含500000个数据集。手写数据集一共包含116 643张文本图像。
对于复杂场景的数据集,按照影响因素划分为以下4类。①遮挡(来自前景):描述前景物体或文字对目标文字的遮挡。②倾斜或弯曲(来自字符):对字符本身的倾斜或弯曲现象进行评估。③背景混淆(来自背景):背景中的其他元素或纹理可能对目标文字造成干扰。④图片模糊(图像来源,像素损失):涉及图像采集、处理或传输过程中可能产生的模糊或像素损失。通过考量以上4类影响因素,研究人员能更全面地评估模型在复杂场景下印刷文本识别的性能和鲁棒性。每个数据集分别包含10 000张图片。
所有数据集的训练集、测试集和验证集的数据量均按照8∶1∶1的比例进行划分,采用随机操作的方式对这些样本进行洗牌。
3.2 实现细节
在本次实验中,采用PyTorch作为深度学习框架,并利用NVIDIA RTX 3090 GPU进行高效计算,内存容量为24 GB,为模型训练提供了充足的资源。优化器选用ADADELTA,初始学习率设定为1.0。同时,动量设为0.9,权重衰减为1e-4。
为确保模型对图像细节的准确识别,将输入文本图像的分辨率固定为32×32。此外,每批训练数据的数量设置为64,这一设置有助于提高识别的准确性。
3.3 实验结果
3.3.1 模型评估指标
本研究选取度量精度(Accuracy, ACC)和归一化编辑距离(Normalized Edit Distance, NED)作为评估模型性能的关键指标。通过结果的可视化分析,本文直观地展示了算法在处理复杂场景下的识别能力。
在进行性能评估前,本研究实施了一系列的数据预处理步骤,包括删除文本中所有的空格、将所有英文字符统一转换为小写字母,以及将繁体中文字符统一转换为简体中文字符,旨在消除不必要的变异性,为计算提供了标准化的数据基础。
利用度量精度对模型的识别准确率进行量化评估。为了全面评估长文本图像的识别性能,本研究还引入了归一化编辑距离作为评估指标,以衡量模型对于长文本识别的综合能力。ACC和NED的取值范围均为[0,1],其中较高的值代表模型具有更好的性能表现。
3.3.2 应用于通用数据集的结果对比
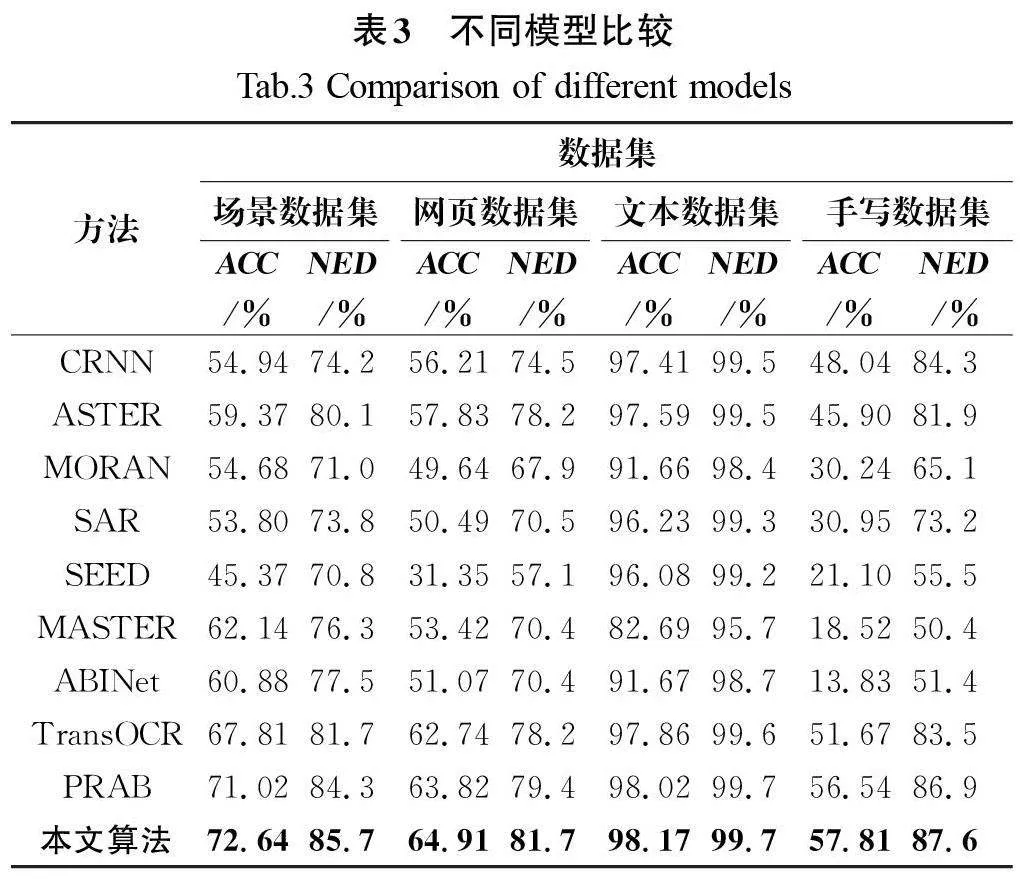
在场景数据集、网页数据集、文本数据集、手写数据集中,本文提出的MRCCR算法均优于当前较先进的算法。使用字符精度(CACC)作为评估指标。
表3的对比结果表明,本研究提出的算法在文本数据集上达到了最高的准确率,超越了现有的PRAB模型。这一结果主要归功于算法采用了多维表征模型,该模型通过提取多层次特征,显著提高了识别的准确性。
在文本数据集中,约有1.20%的样本未能被成功识别。这些失败案例多涉及复杂情形,例如印刷文本的结构模糊或轮廓不清晰,这对算法中的关键笔形监督模块构成了挑战。对于网页数据集,由于数据量较小,所有模型的准确率普遍较低。然而,当从数据集中剔除非中文文本,仅针对中文字符进行准确率计算时,本研究提出的算法识别准确率高达91.56%。其中,中文字符仅占据所有字符的44.9%。复杂场景下的文本基准,因其包含复杂的现实背景及噪声干扰(例如模糊和遮挡)而更具挑战性。与基于Transformer的PRAB模型相比,本文提出的MRCCR算法在复杂场景文本识别方面取得了显著提升,性能提高了1.62百分点。这一显著提升可能源于MRCCR算法所采用的三层分解表征监督,与现有技术相比,该算法对复杂背景和噪声的抗干扰能力更强,展现出更强的鲁棒性。在手写数据集上,尽管手写数据集因潦草书写导致所有基准模型性能普遍欠佳,但引入基于关键笔形特征的算法后,性能仍有所提升。
3.3.3 复杂场景数据集实验分析
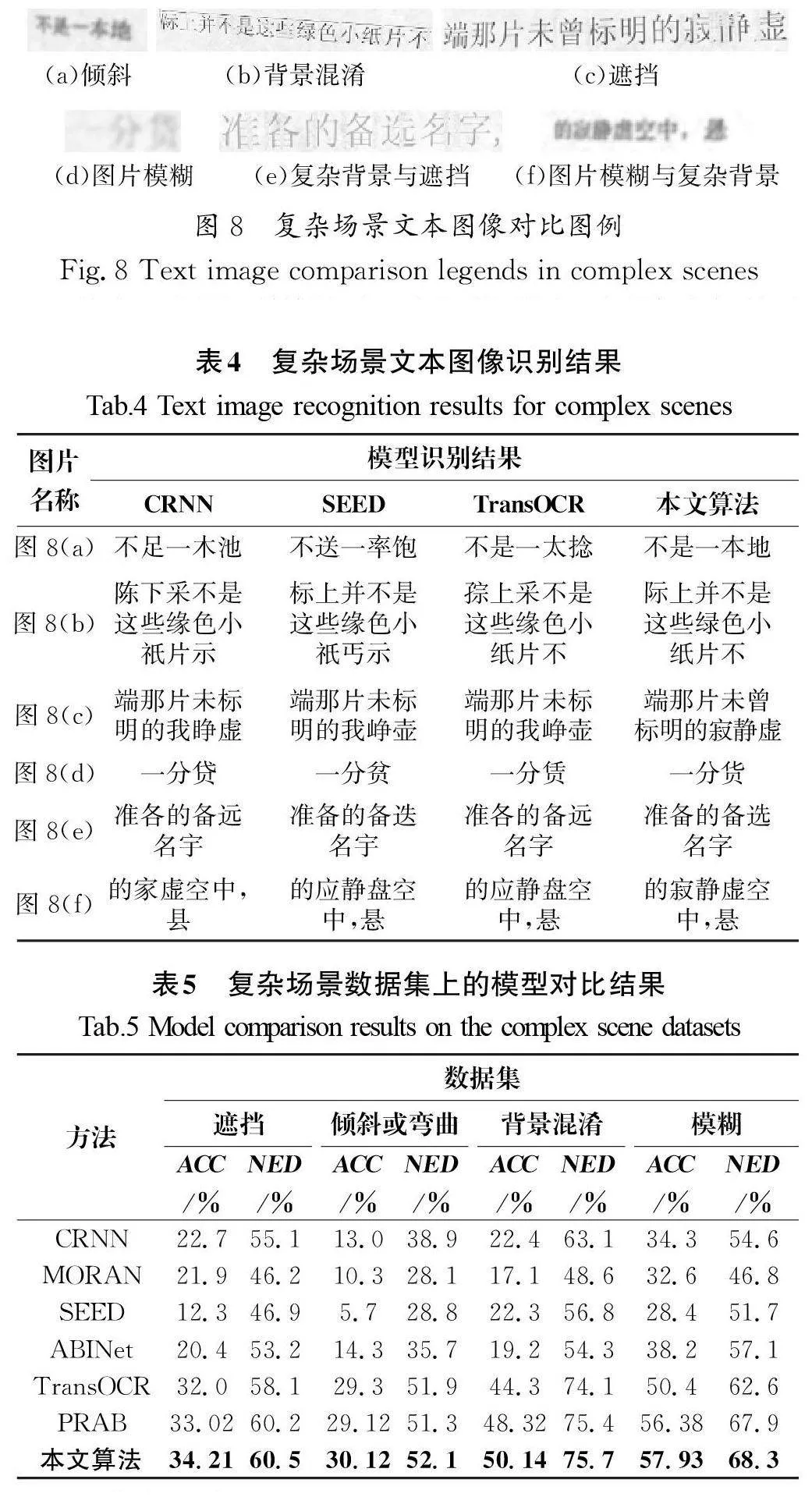
从Text Render5生成的文本数据集的测试集中,选取了一些倾斜、遮盖、背景模糊、遮挡等复杂场景下的文本图像(图8),对比同一个图片在4种不同模型下的识别结果。
从表4中的识别结果可以看出,针对图8中的复杂场景下文本图片的识别,本文算法相较于其他3种算法,在图像缺失、字符扭曲及背景模糊的场景下具有较好识别效果。例如在对图8(d)的识别中,由于图片模糊,特征提取困难,CRNN、SEED及TransOCR模型均未正确识别出汉字“贷”,而本文提出的方法基于空间提取关键笔形,可以更好地提取文本图像的特征,以少量关键特征表示汉字,进而正确识别出了该字符。
结合表4和表5的实验结果可以看出,相较于其他算法,本文提出的算法在处理模糊场景数据集时展现出较强的适应性。这一优势主要归功于应用了多维表征融合识别算法,它结合注意力机制,利用多层次信息提取特征,显著提升识别器的处理能力。该算法能轻松应对不常见的文本布局,如倾斜、弯曲等复杂情况,同时有效降低了由前景遮挡或背景混乱引发的噪声干扰。通过精确捕捉关键特征,本文提出的算法能显著提高汉字识别的准确性。
3.4 消融实验
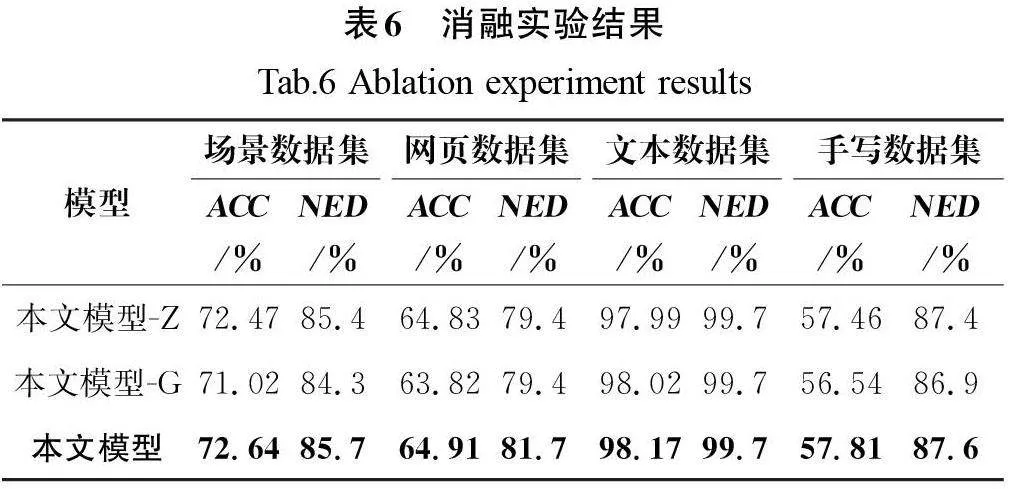
为了验证本文提出模型的有效性,在通用数据集上对关键笔形预测模块和综合判定模块进行了消融实验。首先,通过从多维表征识别模型中移除关键笔形预测模块,并在没有此模块的情况下进行实验,分析了该模块的影响,以证明其对提高汉字识别的性能的贡献。其次,在验证综合判定模块的有效性时,采用了一种替代融合机制,即将特征通过平均融合并归一化的方式。为了便于对比,将去除关键笔形预测模块和综合判定模块的版本定义为基础模型,同时为了方便比较,使用“-G”表示在模型中去除关键笔形特征模块,使用“-Z”表示在模型中去除综合判定模块。
3.4.1 关键笔形消融实验
如表6所示,在去除关键笔形表征模块后,本文提出的模型在各类数据集上的性能均出现了下降趋势。具体而言,在场景数据集、网页数据集、文本数据集和手写数据集上,性能分别降低了1.62百分点、1.09百分点、0.15百分点和1.27百分点。可以看出,手写数据集和场景数据集的性能下降最为显著,这主要是因为这两个数据集包含的背景复杂性和遮盖等挑战性因素较多。关键笔形模块旨在提升特征提取能力,去除该模块后,特征提取的增益被取消,进而导致识别准确性降低。
3.4.2 综合判定模块消融实验
表6中的测试结果表明,删除综合判定模块后,模型的整体准确率略有下降,例如在文本数据集上识别字符的正确率从98.17%下降到97.99%,下降了0.18百分点。进一步可以判断出综合判定模块可以去除特征噪声,选取最佳字符,使预测精度略有提高。
实验结果显示,关键笔形模块对于提升汉字识别的准确性起到了关键作用。通过采用多维表征融合的汉字识别策略,不仅整体提高了汉字识别能力,还增强了在复杂场景下的识别准确性。此外,消融实验的结果也进一步印证了本文模型的有效性。
4 结论(Conclusion)
本研究致力于提升在复杂场景中汉字的有效特征提取能力,以提高汉字识别的准确性。首先,提出了一种基于空间的关键笔画特征提取方法,将空间信息融合到特征序列中,实现了使用最少的关键特征对汉字进行准确标识。在此基础上,本研究进一步提出了一种基于多维表示的汉字识别方案,该方案利用注意力机制结合多任务网络,有效提取了汉字字符、字根及关键笔画的多维度特征,从而提高了在复杂场景中的关键特征提取水平。此外,通过应用字符相似度算法去除特征中的噪声,进一步提高了字符的识别准确率。实验结果表明,基于多维表征的汉字识别方案在复杂场景中的汉字识别能力优于基线模型。
作者简介:
陈成(1997-),男,硕士。研究领域:自然语言处理,图像识别。
姜明(1974-),男,博士,教授。研究领域:自然语言处理,图像识别。本文通信作者。
张旻(1977-),男,博士,讲师。研究领域:自然语言处理,图像识别。
