基于随机游走的图扩散模型
2024-08-06周安众谢丁峰



关键词:随机游走;图模型;注意力机制;图扩散
中图分类号:TP391 文献标志码:A
0 引言(Introduction)
基于图的深度学习方法在解决许多重要的图问题上取得了成功[1-4],其中一些工作旨在使用注意力机制提取图上的特征信息[5],但存在以下问题。
(1)典型的图方法对于每个节点仅使用非常有限的邻居节点信息,而更大的邻域可以向模型提供更多的信息。一般的方法是通过叠加多个层达到传递全局信息的目的,但是过多的层会导致过度平滑问题[6-7],并且随着层数增加,训练难度会不断增大。
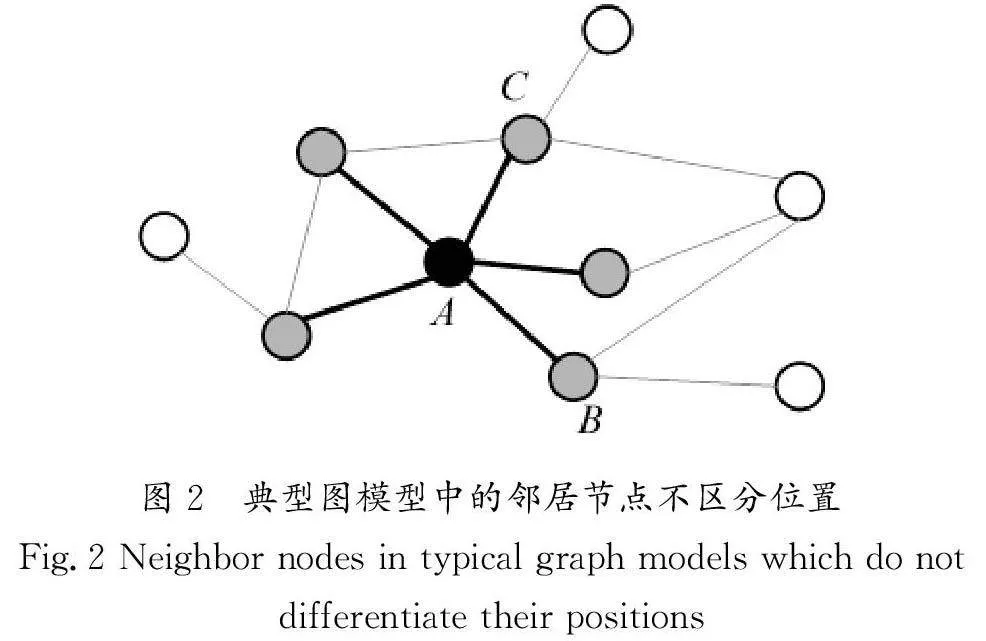
(2)使用图数据的挑战性在于要找到正确的表达图结构的方式,传统方法无法区分邻居的位置关系[8],从而失去了节点相关的拓扑信息。基于注意力机制[5]的方法将邻居特征的加权和作为中心节点的输出特征,但只考虑了特征信息,并没有反映节点不同的结构。ZHOU等[9]提出在注意力机制中引入代表结构信息的可学习向量,但向量的学习增大了参数量和模型复杂度,存在过拟合的现象。
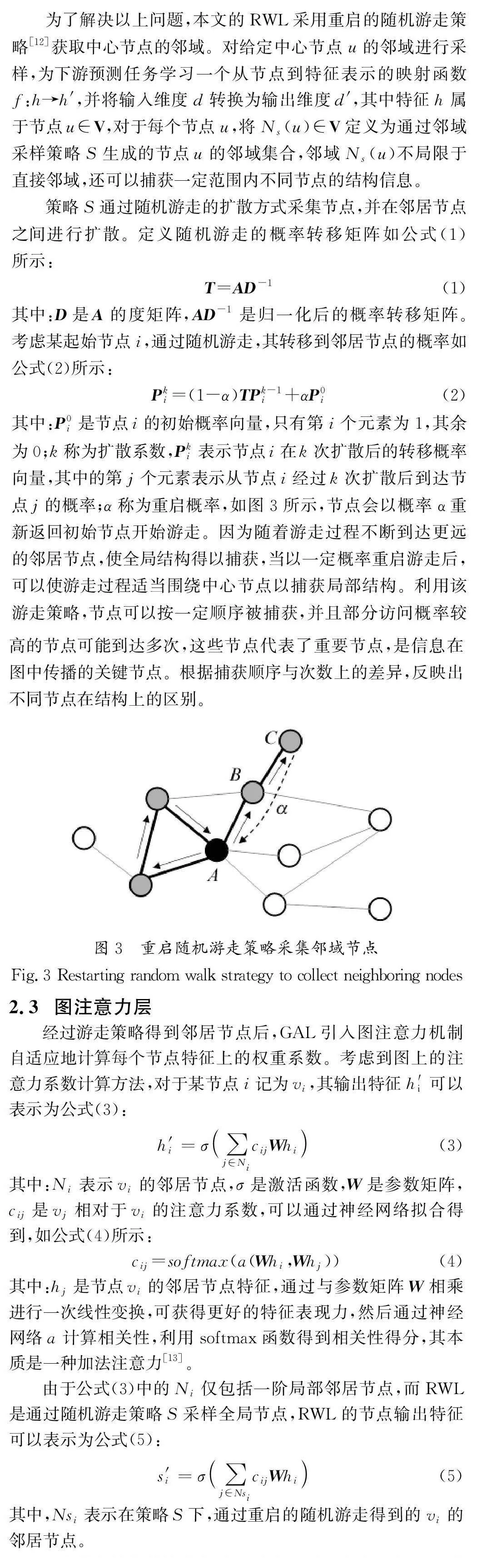
综上所述,本文提出一种随机游走的图扩散模型(GraphDiffusion Model with Random Walks,GDR),该算法通过随机游走的扩散方式[10]访问邻居节点,确保了对每个中心节点的局部邻域进行编码。通过设置游走的相关参数,可以满足控制一定范围内邻域信息的需求。本研究认为,该游走策略产生的邻居节点包含了图的结构,使得在注意力机制计算特征相关性的同时包含了节点的拓扑信息,并且这种扩散方法没有增加模型的参数,使训练更加简单。
1 问题描述(Problem statement)
对于图中节点的分类任务,建立图G=(V,ε,A),其中V是图中的节点集,ε是边集,反映了节点之间的连通性。A∈RN×N 表示G 的邻接矩阵。同时,建立矩阵H ∈RN×d 作为节点的输入特征矩阵,其中N 表示节点数,d 表示输入特征维度。给定图G 的输入特征矩阵H,通过学习一个特征转换函数f 得到输出特征矩阵H'∈RN×d',再通过分类器对输出特征的节点进行分类。
2 模型架构(Model architecture)
2.1 整体架构
本文提出的GDR模型的整体架构如图1所示,它由多个特征转换模块组成,每个模块包含一个随机游走层(RandomWalk Layer, RWL)和一个图注意力层(Graph AttentionLayer, GAL)。RWL以随机游走的扩散方式获取各中心节点的邻居,这些邻居节点包含结构上的依赖关系,并可继续扩散到更大的邻域。GAL通过图上的注意力机制对RWL层输出的节点及其邻居进行特征转换,注意力机制本质上只针对邻居节点特征加权求和,引入RWL后,节点之间通过结构进行了区分,使模型包含更完备的信息。输入的图数据通过多个特征转换模块后,生成的最终特征进入神经网络分类器中进行节点类别的预测。
2.2 随机游走层
典型的图模型在采集邻居节点时,只使用了每个节点非常有限的邻域范围,GraphSAGE(Graph SAmple and aggreGatE)模型[8]通过随机采样的方式从一阶或二阶邻域中获取节点,GAT模型[5]则直接使用一阶节点,这种局部的邻域通过叠加多层而不断扩大;对于其中一层(图2),作为邻居节点的B 和C,相对中心节点A 没有做结构上的区分,在连接方式上相对A 是没有差别的,而不同的连接方式正是邻居节点拓扑结构的差异。基于注意力机制的特征学习方法最初是在自然语言的背景下开发的,旨在寻找线性文本中连续单词的上下文位置关系,即线性的结构。注意力机制无法对位置进行区分,典型的Transformer模型[11]在原始特征中加入位置信息,是一种人为设计的特征,文献作者没有对其进行详细解释。网络是非线性结构,需要更丰富的邻域范围内的结构信息。SAN(StructuralAttention Network)模型[9]则是在图中引入了一个结构化向量,让模型在训练过程中自动地进行结构化信息的学习,但增加了模型的参数。
整个特征转换模块分为随机游走和图注意力计算两个阶段。随机游走阶段首先利用输入的邻接矩阵A,根据公式(1)计算转移矩阵T,其次根据公式(2)及参数α 和k 计算得到概率矩阵P,最后根据P 中的概率进行随机游走生成邻居节点集合S。图注意力阶段则从上一阶段输出的节点集合S中选择中心节点的邻居,首先利用输入的特征矩阵H,根据公式(4)计算注意力系数,其次根据公式(5)对输入特征进行转换,最后通过神经网络分类器进行类别预测。
3 实验(Experiment)
本文通过转导学习和归纳学习,将GDR模型与其他基准模型在节点分类任务中的性能进行了比较。本节总结了实验设置、结果,并对GDR模型的相关参数进行了简要分析。
3.1 数据集描述
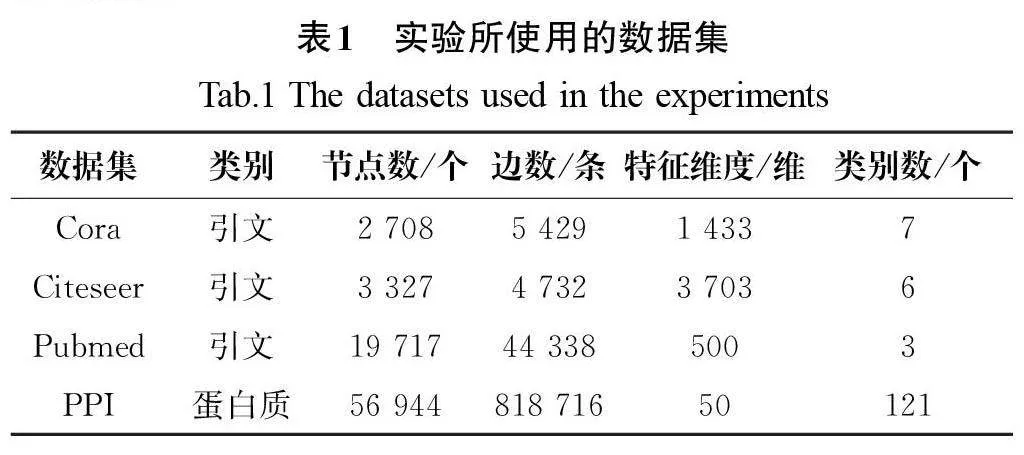
实验使用的数据集如表1所示,在3个引文数据集上预测文档类别以评估本文模型的转导学习能力,包括Citeseer、Cora和Pubmed[14]。数据集包含文档的特征向量集合及文档之间的引用链接列表,以此构造出邻接矩阵和特征矩阵,训练过程中使用了图中所有节点的特征向量。归纳任务部分采用了生物医学领域的蛋白质相互作用(Protein-Protein Interaction,PPI)数据集[8],由对应于不同蛋白质组织的图组成,共有24张图,每个图的平均节点数为2 372个,节点特征维度为50维,由位置基因集、基序基因集和免疫学特征组成,该数据集中一个节点同时拥有多个标签,并且用于测试任务的图在训练期间没有被使用。
3.2 实验设置
对于引文数据集,采用一个特征转换模块的GDR模型。其中,RWL的重启概率α 为0.1,扩散系数k 为10。GAL则主要参考了GAT模型进行设置,采用8个注意力层组成的多头注意力结构,每个头输出8个维度的特征(总共64个特征),使用ELU激活函数进行非线性变换,最后一层是softmax分类。由于引文数据集较小,模型采用了λ=0.005的L2正则化方法。
PPI数据集用于评价模型在跨图上的归纳学习能力,采用了3个特征转换模块,RWL的重启概率α 为0.1,扩散系统k 为20,GAL的设置同样参照了GAT 模型的做法,以方便对比模型改进的效果。前两个GAL是4个注意力层组成的多头注意力结构,每个头输出256维的特征(总共1 024维),采用ELU激活函数。最后一层是单头的注意力层,输出维度为类别数,由于每个节点属于多个类别,因此分类采用了logistic函数。
3.3 基准模型
对于引文数据集,选用的对比模型为GAT和GCN[7],以及GCN在使用多阶Chebyshev截断时的效果。对于PPI数据集,除了与注意力模型GAT进行对比,还比较了GraphSAGE模型中提出的4种不同的聚合方法。这些方法在小范围邻域内采样节点并通过某种聚合函数计算输出特征,如GrapshSAGE-GCN采用了GCN的图卷积操作作为聚合函数,GraphSAGE-mean 直接取所有采样特征的平均值,GraphSAGE-LSTM将采样的邻居特征随机排序后输入LSTM进行聚合,GraphSAGE-pooling将节点特征经过全连接的神经网络后进行最大池化聚合。
3.4 实验结果
表2给出了在3个引文数据集上针对测试节点的分类准确率。从表2中可以看出,在对比方法中,GDR模型在3个引文数据集上都取得了最高准确率,并且注意力机制中的参数设置完全参考GAT模型,可以认为性能的提升来自RWL的随机游走策略,表明通过扩散得到的邻居节点提供了更多的信息。相比于SAN模型通过引入训练时可学习的结构化向量的方法,游走策略没有给模型增加训练时的参数,因此不容易过拟合。
通过调整重启概率α 和扩散系数k,观察游走策略的作用。图4显示了α 取值的变化对测试集准确率的影响。虽然针对不同数据集的最佳取值略有不同,但是起伏变化基本一致,重启概率在0.1~0.2时表现最佳,表明一定的重启概率使游走兼顾了局部与全局结构,并带来了性能的提升。由于不同的图数据具有不同的结构,因此在训练时需要针对具体的数据集调整该参数取值。
图5显示了扩散系数k 取不同值时,对模型分类结果的影响。随着k 值的增加,准确率呈现上升趋势,证明随机游走的扩散策略对模型性能的提升是有益的。如图5所示,使用适当的k 值(例如取值为10)有效地近似精确结果已经足够,更大的取值带来的效果提升不明显,而且可能会因为更多邻居节点的加入而导致GAL的过拟合。
表3总结了不同方法在PPI数据集0e1GpSYVhisAwu5eLy9rC1LhCZSC57I8NQ0rxnLOzvQ=上的归纳学习结果比较,采用GraphSAGE模型中的评价方法测试了模型在未见节点上的micro F1值。由于GDR模型采用的是有监督的学习,所以本研究比较的是GraphSAGE模型的有监督版本。本文方法在对比中取得了明显优势。GraphSAGE模型在选取邻居节点时,使用的采样策略没有区分节点之间的相对关系,证明了本文方法在获取结构信息上具有优势。GAT模型在获取邻域时,只使用一阶邻居节点,而GDR模型在游走时可通过设置扩散系数传播到更大的邻域,体现了扩散的效果。SAN模型与本文方法取得了同样的得分,但需要训练一个有参数的向量矩阵,增加了模型的复杂度,而本文方法在训练上更加简单。
4 结论(Conclusion)
本文提出了一种基于随机游走策略的图扩散模型,可用于图节点的分类。该模型在经典的图注意力模型基础上增加了一个随机游走层,能有效地提取图数据中更大邻域范围内的节点信息,使注意力机制同时考虑了节点的结构和特征。在多个引文数据集及一个蛋白质网络数据集上的实验表明,该模型对节点的分类结果优于现有的经典模型,证明了随机游走策略的有效性。
作者简介:
周安众(1986-),男,硕士,讲师。研究领域:大数据技术,人工智能。
谢丁峰(1978-),男,硕士,副教授。研究领域:大数据技术,人工智能。
