基于数据流的织造设备三分量数据清洗算法
2024-08-06彭来湖吴汶糠俞博方辽辽丁春高沈春娅




关键词:数据采集;数据清洗;三分量;箱线图;滑动时间窗
中图分类号:TP301.6 文献标志码:A
0 引言(Introduction)
21世纪,互联网技术正迅速推动一场新的工业革命[1]。生产订单“短频快”将是信息化时代的贸易趋势[2]。织造车间设备多样,并且生产计划排产需依靠大量数据作为支撑。本文研究了织造作业车间数据采集与数据清洗算法,以适应纺织行业须以准确数据作为支撑的发展趋势,满足当今订单形式和柔性作业的要求。
在纺织行业信息化研究中,李佳璇[3]研究了智能工厂的生产设备数据采集与远程监控系统。郑良等[4]基于智能织造车间的数据采集,研究了智能织造车间的数据预处理,但其方法未充分考虑车间数据的多样性。韩梅等[5]采用箱线图识别技术处理异常数据,但该方法必须有大量样本数据作为支撑,不适用于数据采集的初始阶段。田腾等[6]采用滑动窗口的子序列斜率提取特征,并结合置信区间识别特征进行清洗数据,但该方法不适用于设备状态变化引发的采集值变化的情况。
综上所述,织造作业车间的信息化依赖于数据采集。数据采集对系统决策、数据分析、设备监控、数据可视化起决定性作用。织造车间设备量大、设备类型多样,采集数据量大,且对实时性要求较高,并且在采集过程中容易受设备、网络、服务器等的影响而产生脏数据。因此,本文针对织造设备和数据的特点,研究了适用于设备多样性的数据流有向网采集方法。同时,为保证数据的准确性,本研究在数据流的基础上研究了三分量数据清洗算法。
1 织造作业车间数据采集(Weaving workshopdata acquisition)
织造企业在信息化转型前,车间的排产多依赖人为操作,织轴、织机、产出等数据也多采用人工方式统计,导致排产方案迟滞性高。因此,织造设备数据信息化对于企业的合理决策至关重要。织造作业车间实施信息化转型后,为满足织造设备数据信息化需求,文章提出了具体的织造作业车间数据采集方案。
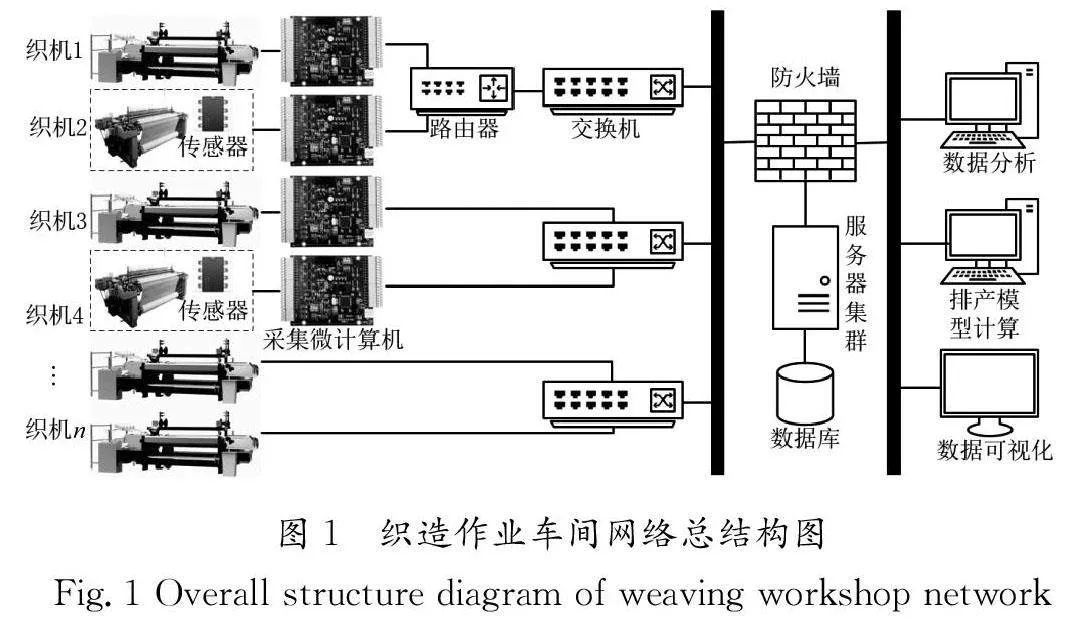
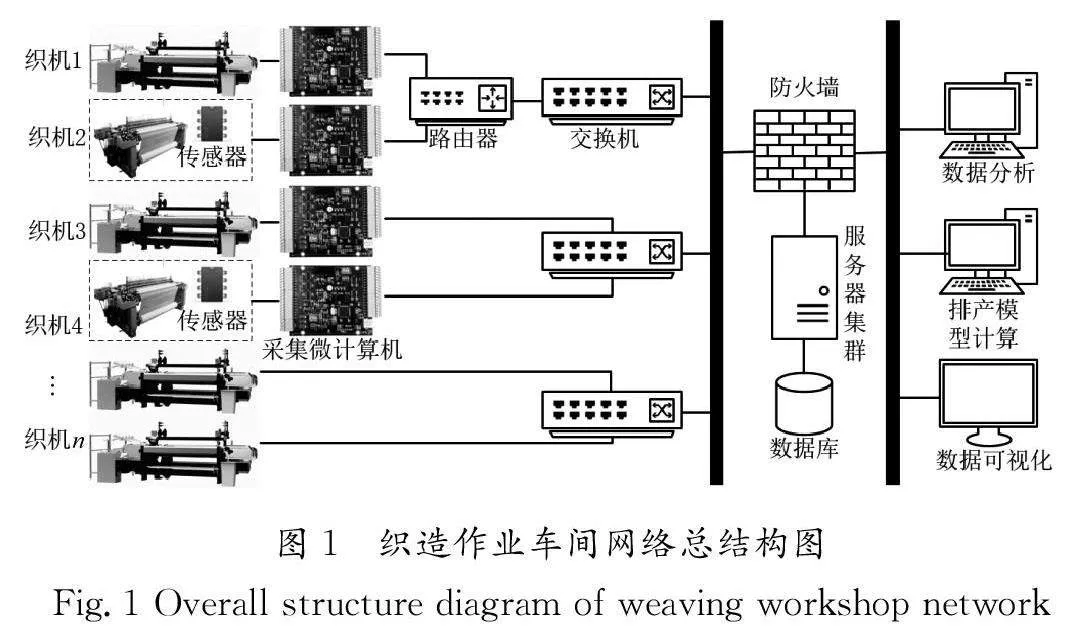
1.1 织造作业车间网络架构
织造车间信息化系统由设备组、网络传输、服务器集群和数据决策端组成。在设备组中,织机的功能包括数据统计和通信,但部分设备的功能不全。由于车间的设备厂家、类型多样,因此需要构建通用性强的网络结构获取各类设备的数据。可以使用采集微计算机与织造设备组成功能完备的设备最小单元。
采集微计算机的主要功能包括通信和脉冲统计,其中通信功能包括与服务器通信和与设备通信,它将服务器下发的指令转发给设备,并接收设备数据上传给服务器;脉冲统计功能是统计脉冲信号数据,然后提供给服务器做转换计算。在网络传输中,可采用有线与无线两种方式,通过路由器、交换机等与服务器集群建立网络通道。在服务器集群中,由多台分布式服务器处理织机数据。
数据决策端则以服务器集群数据库数据中的数据作为决策基准。织造作业车间网络总结构图如图1所示。
1.2 织机数据采集
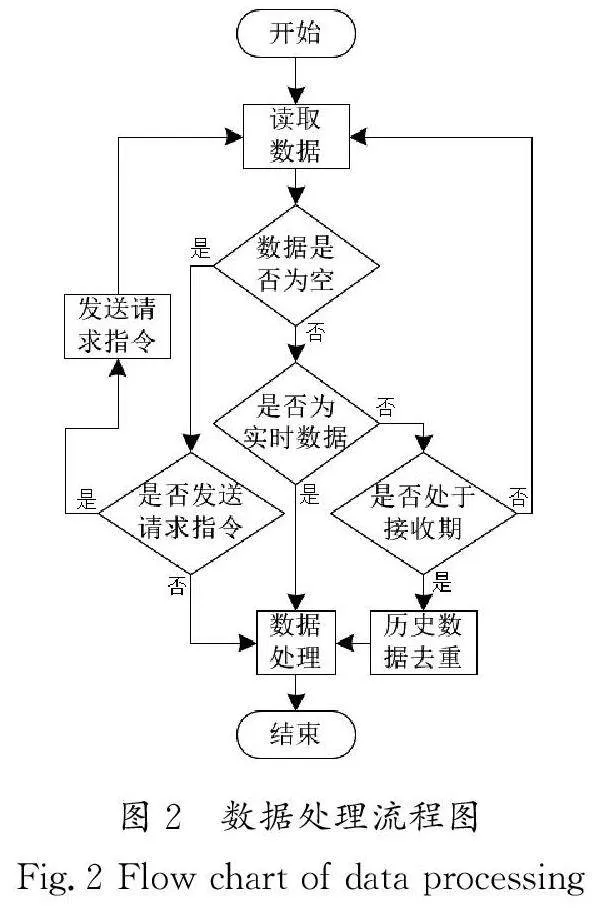
织造设备产生的数据分为设备信息和生产信息,生产信息包括实时数据与历史数据。在数据采集过程中,织造车间的设备多、数据采集频率高,并且在历史数据中会有大量重复的信息,易出现数据粘包/半包、抖动、重复、丢失等情况,导致采集Fig.1 Overall structure diagram of weaving workshop network服务程序数据解析错位、数据插入时序错位、同一数据多次插入、数据丢失等问题,进而产生脏数据。为解决以上问题,本文针对织机的数据特性,提出分频次采集方案和服务器均衡负载方案。在分频次采集方案中,对实时性要求高的数据采用高频采集,对实时性要求低的历史数据采用低频或定时采集,该方式能较好地实现织机数据解耦、削峰。采集织机数据的方式分为两类:第一类是以设备作为从机;第二类是以服务器作为主机,第二类与第一类相反。在这两类主从关系中,设备可主动上传数据,或等待请求指令下发,然后回复请求。针对这两种数据交互方式,分频采集的实现方式为定时请求、定量接收。在服务器均衡负载方案中,将织机划分区域,并将区域中的所有数据唯一映射到服务器集群中的某一台服务器,然后在服务器中将该区域的织机数据分别映射到不同端口中处理数据。数据处理流程图如图2所示。
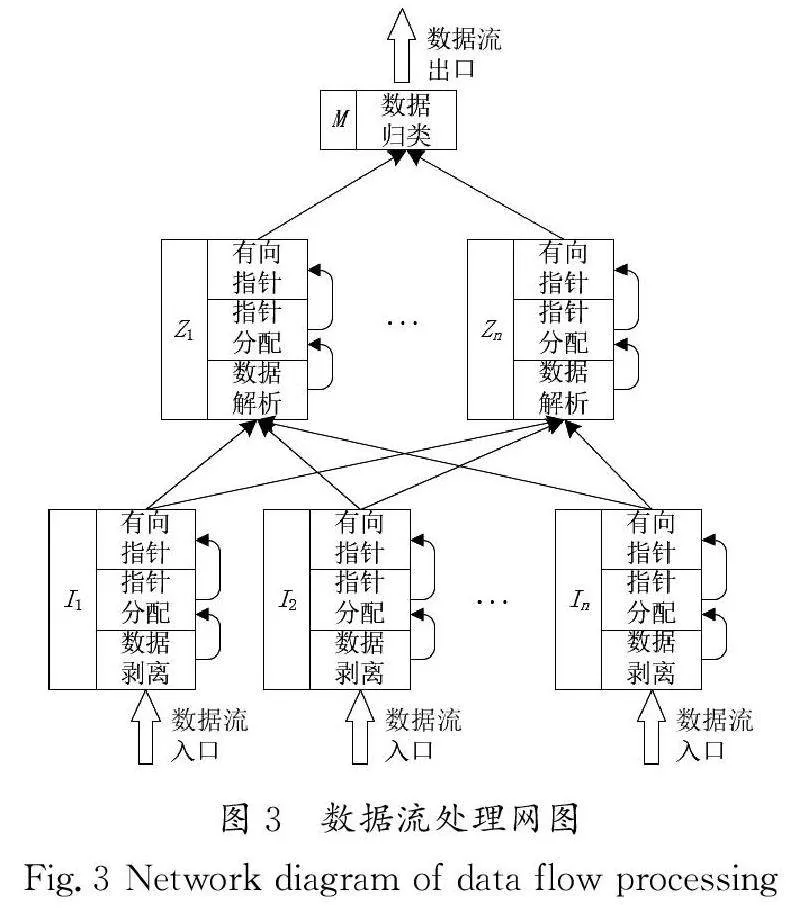
在解析织机数据时,由于设备具有多样性,所以数据传输协议同样具有多样性。为提高数据采集系统的通用性,织机采集方案在接收数据时,应兼容协议的多样性。初步处理数据时,需灵活应对数据的多样性;数据处理完毕后,应确保数据呈现的统一性。因此,本研究基于协议的多样性与数据的统一性特点设计织机数据流处理有向网。如图3所示,数据流处理网中的每一个结点都为独立函数,该流处理网由数据编解码层In、数据解析层Zn、数据归类层M 组成。数据解码层为底层,数据归类层为顶层。其中,底层为数据流入口、顶层为数据流出口。数据流处理网中,自下而上的每一层的函数之间为并列关系,每两层之间为递进关系。由于要适应多种协议与传输方式,所以数据编解码层中的函数最多,并且每个函数对应一种传输方式、通信协议,将织机数据从数据帧中剥离。数据解析层中每一个函数对应一种数据解析方式,其主要作用为从剥离的数据中按协议说明或点位表等解析出所需数据。数据归类层仅有一个函数,其作用为将解析数据归类。
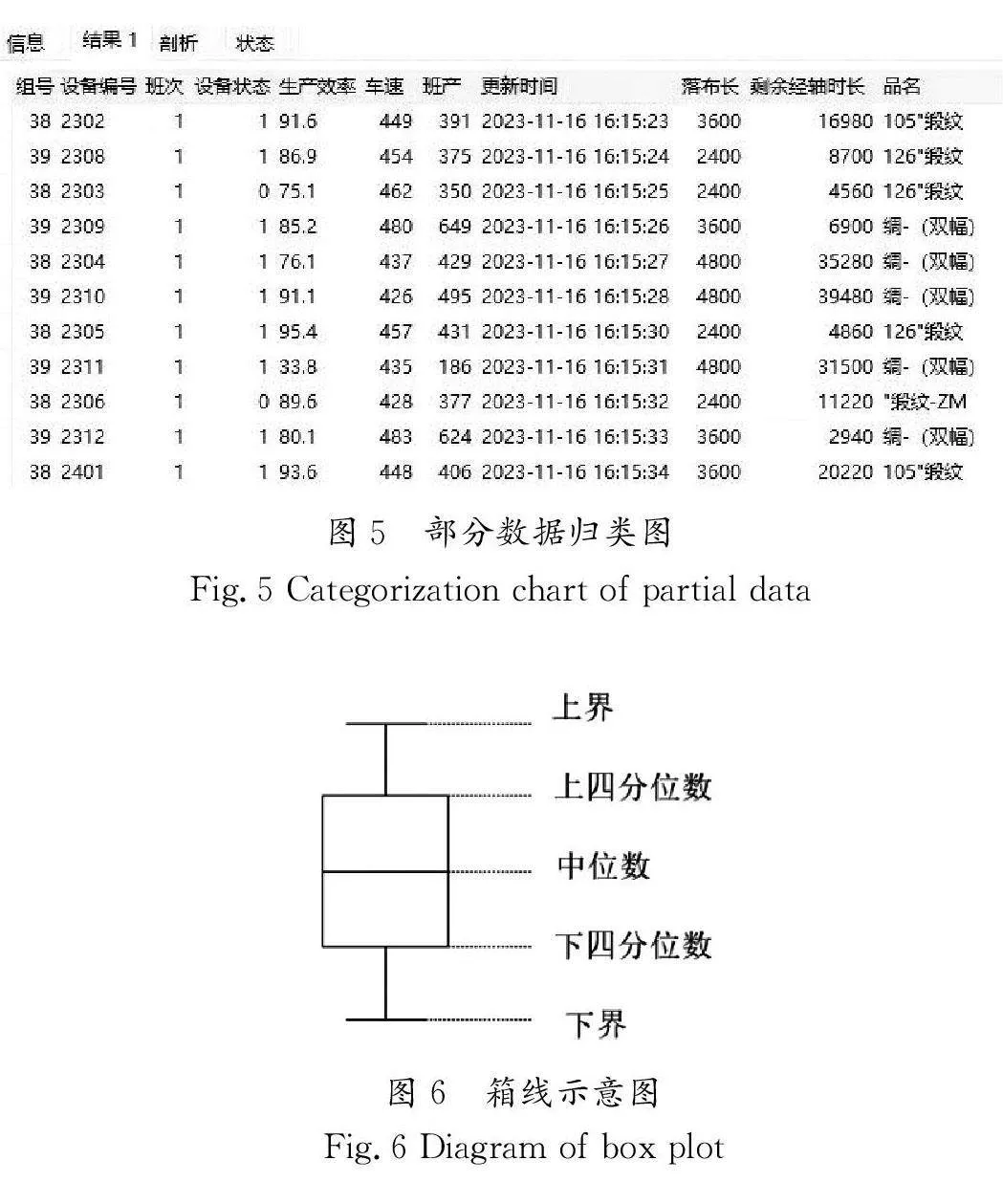
在服务器中接收到的部分设备的原始数据如图4所示,经数据流有向网处理后将数据归类,得到如图5所示的车速、设备编号、设备状态、效率等数据。
2 数据清洗(Data cleaning)
在整个生产流程中,织造作业车间的织机数量多、数据采集量大,易导致数据在网络传输过程中产生错误数据。因此,初步采集的数据经过归类后,并不能直接使用。整个数据链路在初步采集后,还应对数据进行清洗,只有确保数据正确,才能将数据持久化。
在织造过程中,根据数据变化趋势,可将其分为常分量、增分量和状态分量3个类别。其中,常分量数据为定值,不随时间变化而变化,如工艺参数设定值、工艺参数实时值等;增分量数据会随着设备生产时间的推移而逐渐增大;状态分量数据为状态值的合集,例如设备运行状态为二值变量(运行、停止)。为保证作业车间采集数据的实时性、准确性,并结合织造数据的特性,通过三分量清洗算法对数据进行预处理。针对织机的三分量数据,采用改进箱线图法对常分量数据进行清洗,采用改进滑动时间窗法对增分量数据和状态分量数据进行清洗。
2.1 常分量数据清洗
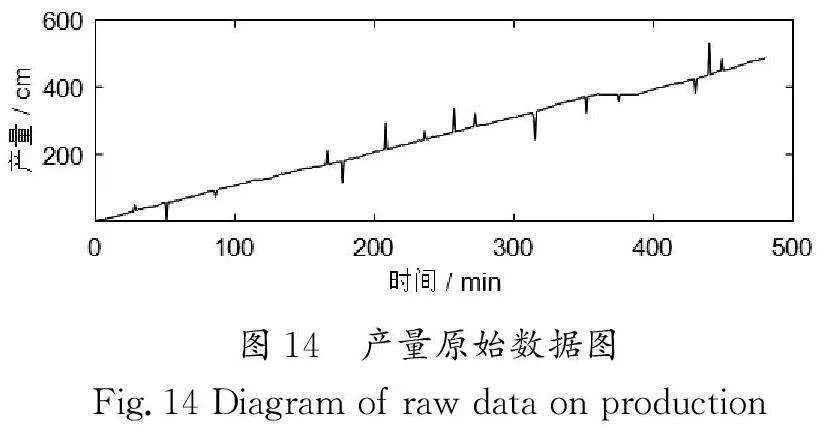
在常分量数据中,可使用四分位数将采集的所有数据分为四等份,并结合箱线图的上界、下界和3个四分位数共5个量化标准,分析数据的集中趋势、分散性、偏离度及潜在异常值[7]。箱线示意图如图6所示。
常分量数据在设备和采集系统正常时,设备运行实时值会围绕设定值随时间变化而波动,如工艺参数值。但是,每台设备都有其独立性,为确保数据的准确性并保留设备的独立性,本文引入参数设定值S计算加权箱线图的上、下界。
2.2 增分量数据清洗
增分量数据主要为班产量、落布长等。这类数据在规定时间段内随时间而正增长,在设备出现异常停机、疵点处理停机时,会停止增长。在采集过程中,除换班时清零数据外,不会出现负增长。由于织机的生产速度会随着设定速度而波动,该特性使得设备在正常运行时的增分量数据数值基本为线程增长。因此,基于增分量数据线性增长的特性,为保证数据的准确性和最小化数据清洗时间开销,在清洗数据时引入设备状态的滑动时间窗法清洗增分量数据。
2.3 状态分量数据清洗
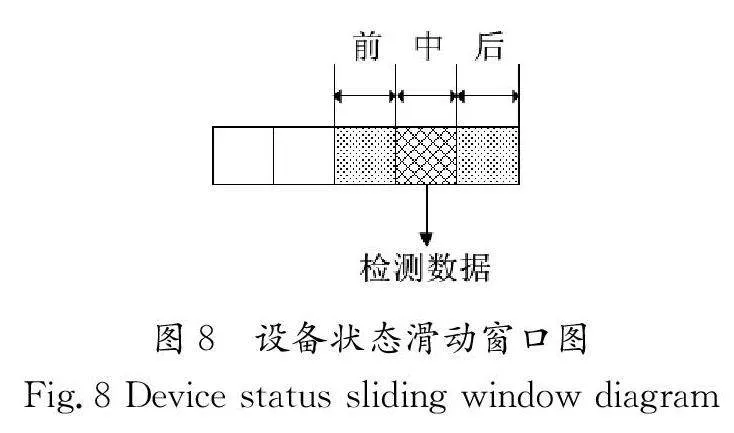
若状态分量采集频率高、单个数据量小,则可在清洗过程中将滑动时间窗滞后一次,使被检测数据置于滑动窗口中心,通过窗口内的所有数据对状态分量数据的异常抖动进行检测,此时滑动窗口被分为前、中、后3个部分,若前、后的状态分量数据相同,中间与前、后的状态分量数据不同时,则判定为数据抖动,设备状态滑动窗口图如图8所示。
3 实验验证(Experimental verification)
为检测本文数据清洗方法的可靠性,以实际生产环境为前提,将是否在采集数据时对数据进行清洗作为变量,分别对三分量清洗算法中的改进箱线图法、滑动时间窗法处理的常分量、增分量和状态分量进行实验。鉴于在采集过程中采集次数与采集时间成正比增加且采集间隔时间短,因此在实验中以采集次数替代时间。
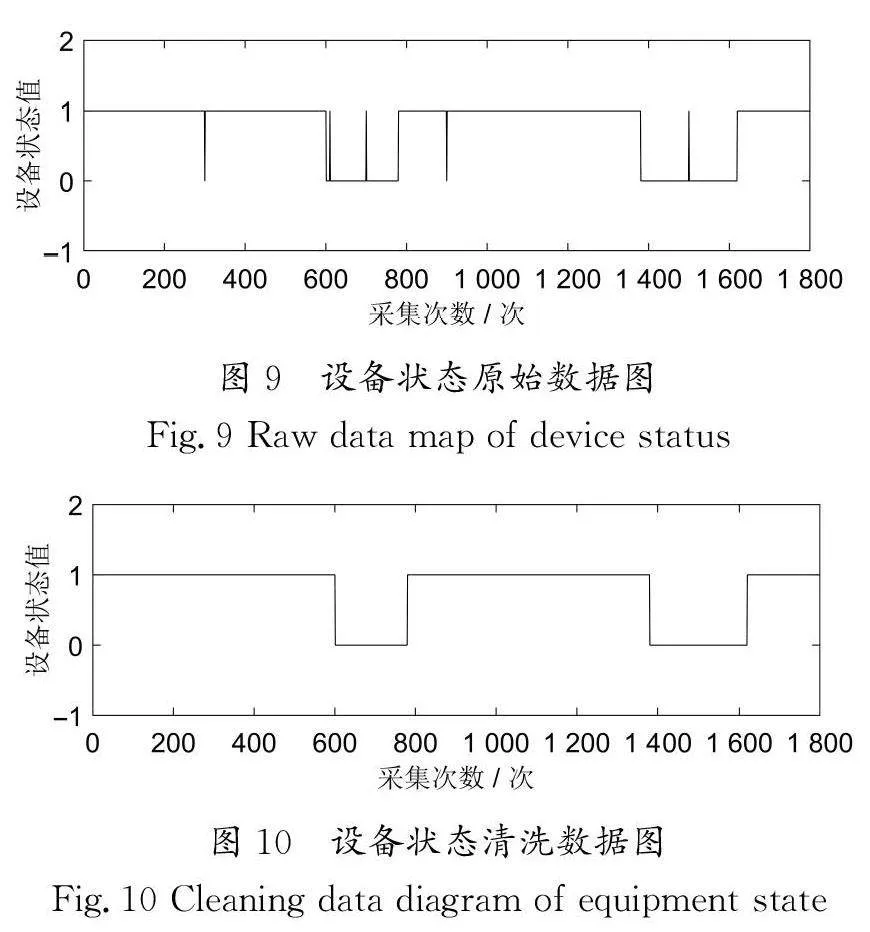
图9与图10分别表示同一台设备在同一时间段不使用和使用数据清洗方法的设备状态图,设备状态值为0时停机,设备状态值为1时运行,可以看出,数据清洗前出现明显的抖动状态,数据清洗后没有出现抖动状态。
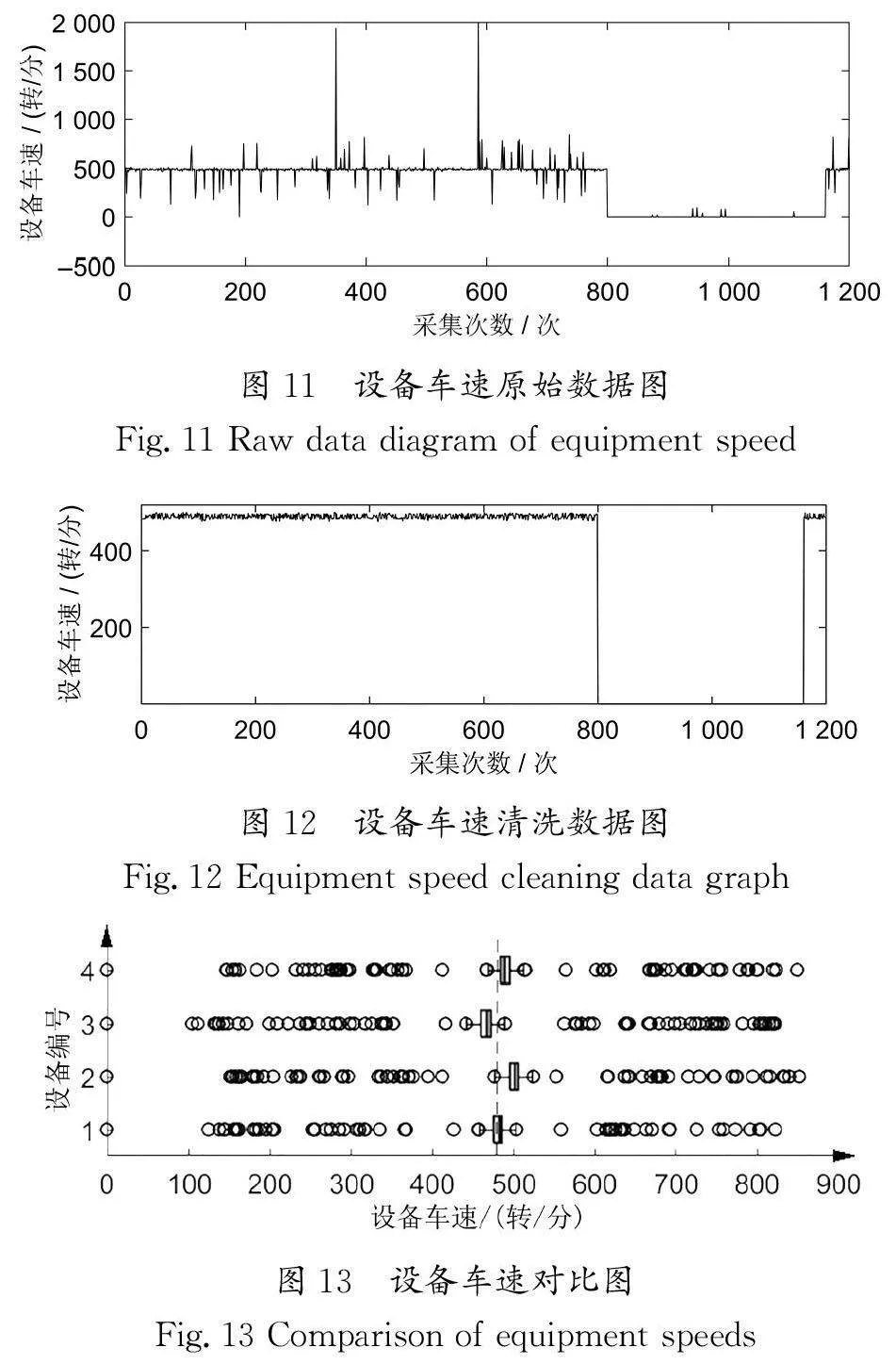
由于常分量数据中对织机车速的实时性要求高且采集频率高,所以对常分量数据的实验,选用最容易产生脏数据的织机车速作为加权箱线图实验对象。图11和图12为随时间变化的织机车速数据。其中,图11为设备车速原始数据,图12为设备车速清洗数据。可以看出,在未经数据清洗的图11中原始数据产生了较多不符实际生产的数据突变点,在停机状态时应为零的车速出现了非零异常值。在经过加权箱线图处理后的图12中实时车速无异常突变点,设备停机时无非零值,证明了箱线图法能保证设备数据的准确性。
图13中为4台设定车速均相同的设备在同一时间段的车速采集数据箱线图,可以看出,3号设备实际车速低于设定值,2号、4号设备实际车速高于实际值,1号设备实际车速与设定值相近。以上结果证明了在三分量清洗算法中,通过对箱线图进行加权处理,清洗算法有效地识别出设备的独立性。
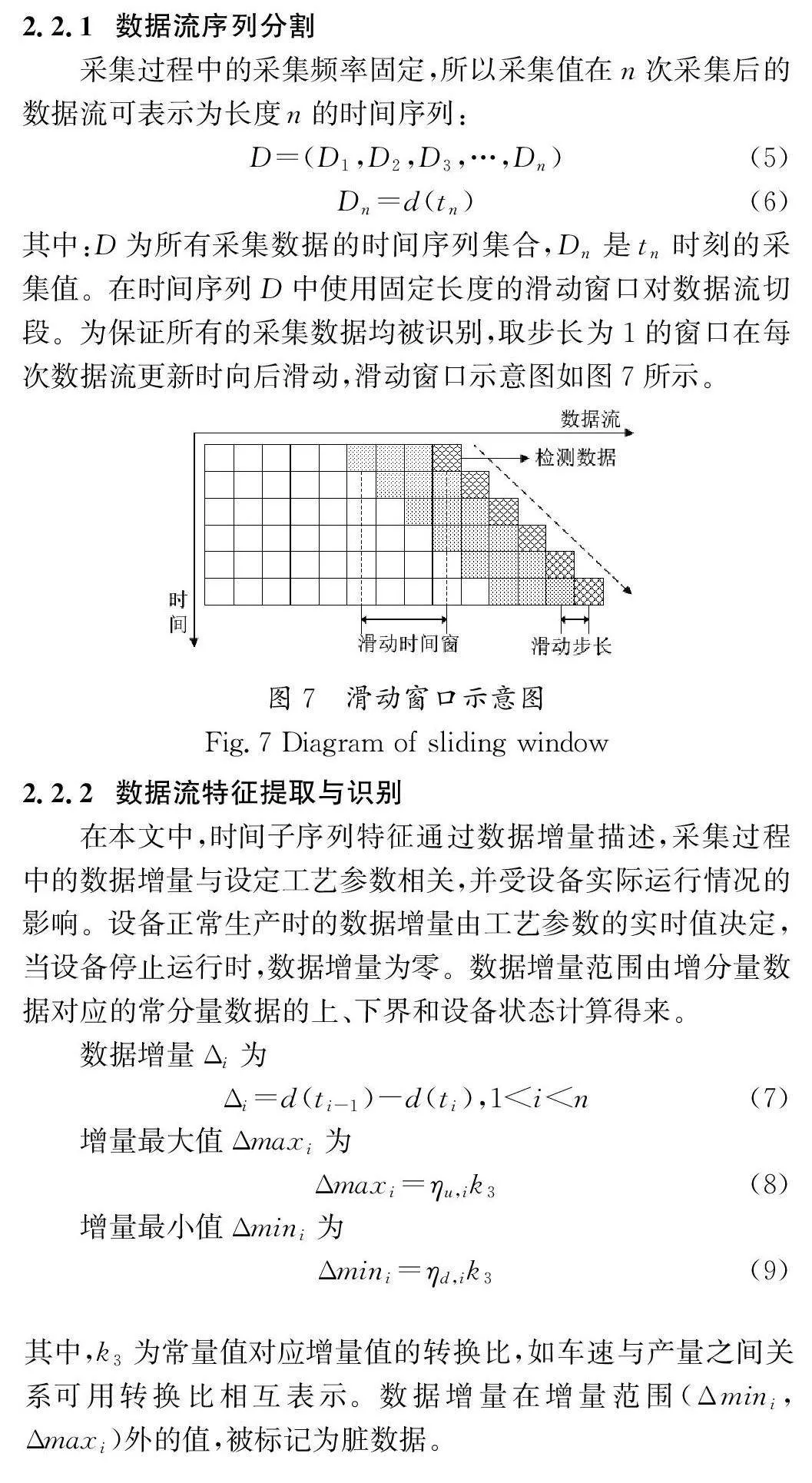
在滑动时间窗的实验中,以设备产量作为实验对象。图14为部分班次生产过程中的产量原始数据,可以看出,数据在设备运行时出现锯齿状数据异常,并在设备停机时仍然会有产量波动甚至出现了负增长。图15为数据清洗后的设备产量,在设备运行期间,产量增长值无波动、设备停机时无产量变动、生产过程中无负增长,证明本文提出的滑动时间窗清洗方法可行且有效。
4 结论(Conclusion)
本文研究了针对多样化设备的织造作业车间数据采集方案,并基于该方案,结合织造车间数据的特点——常分量、增分量和状态分量数据,深入探讨了三分量数据清洗算法。该算法通过动态权重因子改进箱线图,以适应采集初期样本不足的情况,通过引入设备状态改进滑动时间窗数据清洗算法,有效地清洗了状态量数据抖动、常量和增量的错误数据,证明三分量数据清洗算法在数据采集过程中能够准确识别和剔除脏数据,确保所采集数据的准确性。然而,在长时间持续且数值异常偏大的情况下,该清洗方法可能会失效。因此,未来的研究应着重于优化对长期存在的、极端脏数据的特征提取与识别能力。
作者简介:
彭来湖(1980-),男,博士,副教授。研究领域:智能装备与嵌入式控制技术,工业互联网通信。
吴汶糠(1998-),男,硕士生,助理工程师。研究领域:纺织智能制造。
俞博(1996-),男,博士生,工程师。研究领域:纺织智能制造。
方辽辽(1998-),男,博士生,工程师。研究领域:纺织智能制造。
丁春高(1977-),男,本科,工程师。研究领域:自动化控制技术。
沈春娅(1993-),女,博士,工程师。研究领域:纺织智能制造。本文通信作者。
