多粒度检测引导的无人机图像多目标检测算法研究
2024-08-01张楠


关键词:无人机图像;多目标检测;小目标检测;图像超分辨率;深度学习
中图分类号:TP751.1;TP391.41 文献标识码:A
0 引言
无人机遥感系统在各个领域展现出了巨大的潜力和应用前景。然而,无人机图像的目标检测依然是一个重要且具有挑战性的任务[1]。目标检测旨在识别数字图像中特定类别的视觉对象,并确定其在图像中的位置。在无人机图像数据检测中,小目标检测因其识别难度大、应用价值高而备受关注[2]。对于小目标的检测,通常有两种提升模型检测精确度的途径,分别为模型内特征融合机制和区域搜索策略[3]。
模型内特征融合机制可以结合不同层次的特征信息,使模型更好地捕捉小目标的细微特征[4]。例如,窦同旭等[5] 提出的改进型算法模型YOLOADOP,其通过调整检测分支、设计解耦头以及优化损失函数和标签分配策略,显著提高了无人机影像中小目标的检测效果。该模型在VisDrone 数据集上的表现优于YOLOv5 模型,具有更好的检测效果。韩兴勃等[6] 在YOLOv5 的基础上引入了残差连接与跨层注意力,提升了模型对遥感图像中小目标的检测能力,验证了底层特征图和注意力机制在提升小目标检测性能方面的重要作用。杨慧剑等[7]针对航拍图像中小目标检测准确率不高的问题,提出了基于YOLOv5 的改进算法。该算法通过整合卷积块的注意力模块(convolutional block attentionmodule,CBAM), 将空间金字塔池化(spatialpyramid pooling,SPP)替换为空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP),在特征金字塔网络(feature pyramid network,FPN)结构中添加检测头,有效提升了小目标的检测精度,mAP_0.5指标增加了6.9%,证明其可以有效检测航拍图像中的小目标。Tan 等[8] 提出的MFF-FPN 模型,利用ResNet50 作为骨干网络并引入注意力机制,显著提升了该模型在临床胸主动脉夹层及其并发症检测中的小目标检测精度。然而,只为小目标设置特征融合的方法仅能够在图像噪声分布与模型预训练相似的场景下,使模型检测的表现有所提升,但模型难以应用到所有场景。
针对上述方法泛化能力较弱的问题,部分学者考虑在模型内设计区域搜索策略,将计算资源聚焦于最有可能包含目标的图像区域,降低小目标检测的难度。Lu 等[9] 利用邻接矩阵和缩放预测将计算资源自适应地定向至小目标所在的子区域,从而集中处理更有可能包含目标的区域。Alexe 等[10] 引入了一种上下文驱动的搜索方法,利用对象的上下文关系和其在图像中的典型分布,预测目标可能存在的位置。上述搜索策略的制定,偏向于模型关注训练集上目标的典型分布模式,而在无人机航拍图像的检测任务中的目标通常会随机分布,因此当前区域搜索策略还具备一定的提升空间。
1 粒度检测引导的多目标检测算法
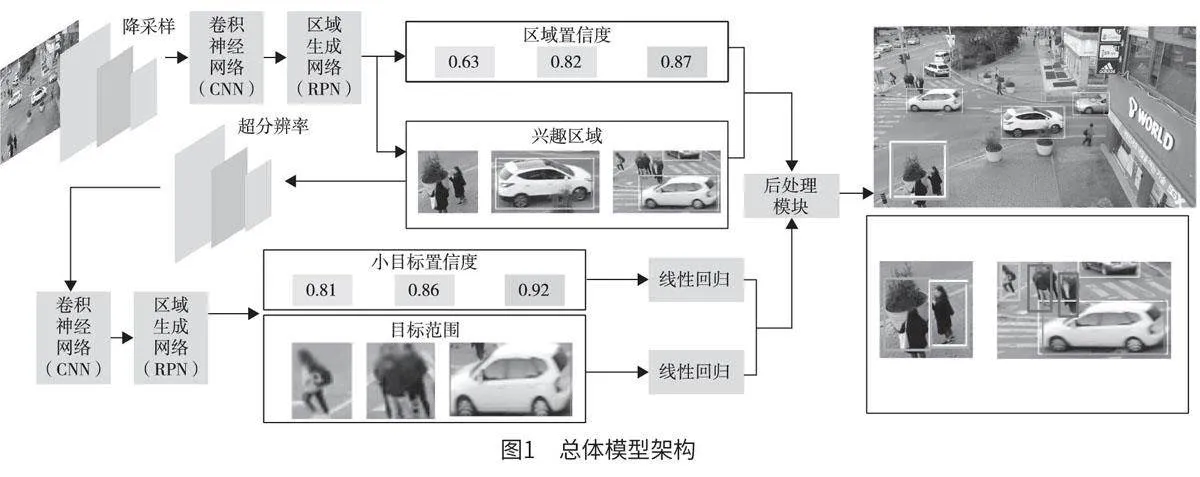
本文提出的粒度检测引导的多目标检测算法检测流程为:首先,对降采样的低分辨率图像进行目标检测,标记潜在目标所在区域,再对这些区域进行重采样和超分辨率处理,并且由细粒度检测器进一步精确识别小目标。其次,使用目标识别模块对潜在目标区域进行多目标识别。最后,通过后处理算法融合粗、细粒度检测结果。该算法主要包含3 个关键模块:重采样与超分辨率处理模块、多目标识别模块、后处理模块。总体模型架构如图1 所示。
1.1 重采样与超分辨率处理模块
重采样与超分辨率处理模块连接了多粒度图像特征。在粗粒度目标识别阶段,采用该模块对图像进行降采样,以减少对计算资源的消耗;在细粒度目标识别阶段,采用该模块可增强兴趣区域的图像质量,在细粒度检测阶段能够更清晰、准确地识别小目标。
本文选用单一图像超分辨率技术(single imagesuper resolution,SISR)网络[11] 作为重采样与超分辨率处理模块,且令重采样与超分辨率模块在网络中共享参数,以实现对本地数据集具有较好的重建效果。
1.2 多目标识别模块
在多目标识别模块中,采用目标检测器对图像中的物体进行识别与标记。目标检测器在模型中有两种不同的应用场景,对于粗粒度图像,其可以对大型个体目标与包含多个小目标的兴趣区域位置进行标记;对于细粒度图像,其可以识别小目标并标记相对位置。本文采用Faster R-CNN 作为多目标识别模块。首先,通过对图像中的前景和背景内容进行判别,并利用区域提议网络生成高概率包含目标的提议框。其次,这些提议框被进一步送入分类及回归的检测头部网络中,以确定提议框的具体类别及其精确的边界框坐标。
本文设计的算法在Linux 系统且版本为Ubuntu18.04 的环境下运行, 选用了2 块NVIDIA RTX2080Ti 11 GB GPU,CPU 型号为Intel Core i9 10980XE,其拥有系统内存为64 G 的实验平台。
在模型超参数设置上,检测器特征提取阶段选用预训练的CNN ResNet101 残差网络参数。模型训练时选用随机梯度下降(stochastic gradient descent,SGD)优化器,设置学习率为0.001,训练20 个训练轮次。
3 模型效果验证
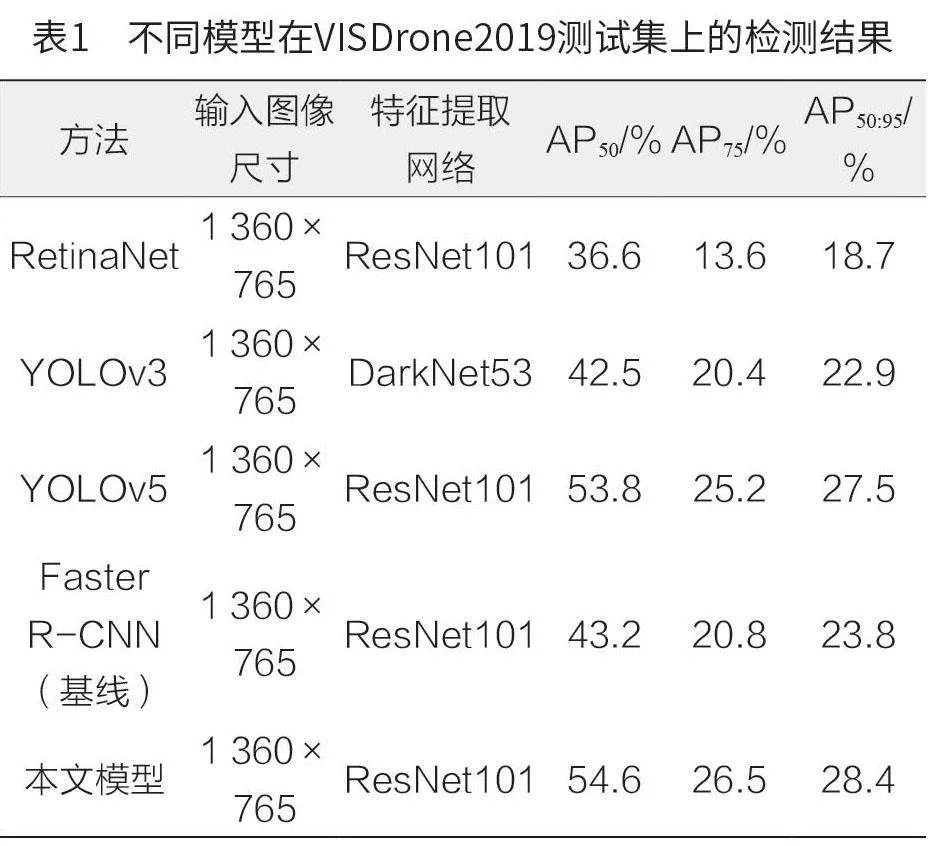
在保持特征提取网络、图像处理尺寸以及其他关键超参数一致的前提下,将本文模型与传统的多阶段目标检测策略进行比较,评估本文提出的模型在无人机航拍图像识别任务上的性能。在模型验证试验中,特征提取阶段均采用预训练的ResNet101网络作为基础。不同模型在VISDrone2019 测试集上的检测结果如表1 所示。其中,AP、AP、AP 分别表示IoU 为0.5 时的mAP、IoU 为0.75时的mAP 和IoU 为0.5 ~ 0.95 时以0.05 步长递进的所有IoU 阈值下的mAP 平均值。
由表1 可知,本文模型在多目标检测任务中表现优于极限模型及当前主流目标检测算法,本文模型的AP、AP 和AP指标分别比YOLOv5 模型高了1.49%、5.16% 和3.27%。
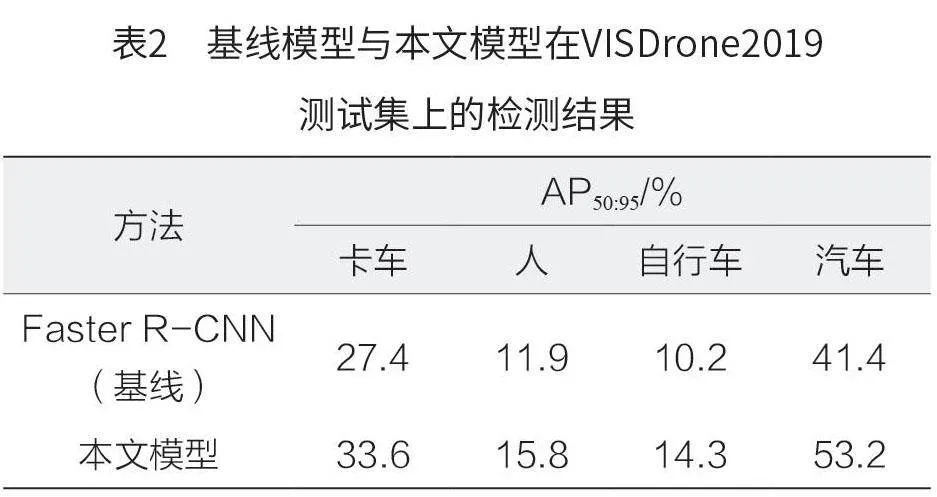
本文还探究了模型在对同类别目标的识别表现,如表2 所示。相较于Faster R-CNN(基线),本文模型在大目标的识别方面具有更大优势,而小目标识别性能优势较小,但其整体识别性能仍有较大提升。
4 结论
本文提出的方法在处理尺寸中等至较大的物体时具有明显的优势,而对于极小尺寸的物体,尽管挑战依然存在,但该方法仍能实现一定程度的准确率提升,证明了其在航拍图像小目标检测领域的有效性和先进性。
