基于内容风格增强和特征嵌入优化的人脸活体检测方法
2024-07-31何东郭辉李振东刘昊
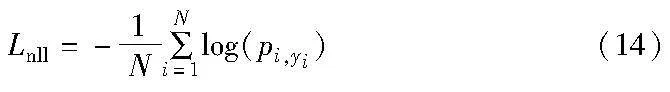
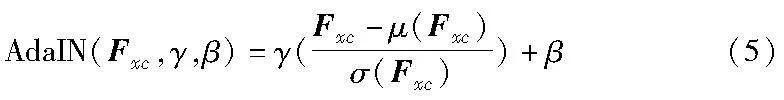


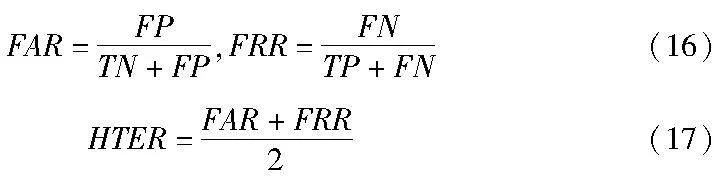
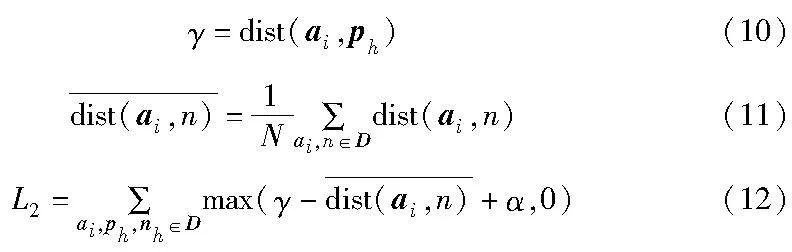


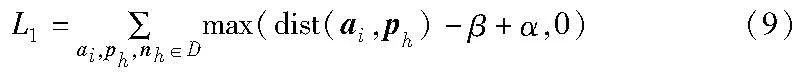

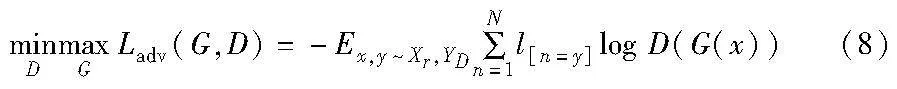
摘 要:针对现有人脸活体检测算法的特征表示不佳,以及在跨数据集上泛化性能较差等问题,提出了一种基于内容风格增强和特征嵌入优化的人脸活体检测方法。首先,使用ResNet-18编码器提取来自多个源域的通用特征,并经过不同注意力机制的两个自适应模块进行分离,增强全局内容特征与局部风格特征表征;其次,基于AdaIN算法将内容特征与风格特征进行有机融合,进一步提升特征表示,并将融合后的特征输入到特定的分类器和域判别器进行对抗训练;最后,采用平均负样本的半难样本三元组挖掘优化特征嵌入,可以兼顾类内聚集和类间排斥,更好地捕捉真实和伪造类别之间的界限。该方法在四个基准数据集CASIA-FASD、REPLAY-ATTACK、MSU-MFSD 和 OULU-NPU上进行训练测试,分别达到了6.33%、12.05%、8.38%、10.59%的准确率,优于现有算法,表明该方法能够显著提升人脸活体检测模型在跨数据集测试中的泛化性能。
关键词:人脸活体检测; 内容和风格特征自适应模块; AdaIN算法; 领域对抗学习; 特征嵌入优化
中图分类号:TP391.41 文献标志码:A
文章编号:1001-3695(2024)06-039-1869-07
doi:10.19734/j.issn.1001-3695.2023.09.0443
Face anti-spoofing method based on content style enhancement andfeature embedding optimization
Abstract:In response to the issues of inadequate feature representation in existing face anti-spoofing algorithms and poor cross-dataset generalization performance, this paper proposed a face anti-spoofing method based on content-style enhancement and feature embedding optimization. Firstly, this method utilized a ResNet-18 encoder to extract generic features from multiple source domains, and then subjected to separation through two self-adaptive modules with different attention mechanisms, enhancing the representation of global content features and local style features. Secondly, based on the AdaIN algorithm, it organically fused content features with style features, further improving the feature representation, and the fused features were subsequently input to specific classifiers and domain discriminators for adversarial training. Finally, by employing average negative samples and semi-hard sample triplet mining to optimize feature embeddings, effectively striking a balance between intra-class cohesion and inter-class discrimination, better capturing the boundaries between genuine and spoofed categories. The proposed method was trained and tested on four benchmark datasets,suchas CASIA-FASD, REPLAY-ATTACK, MSU-MFSD, and OULU-NPU. It achieves accuracy of 6.33%, 12.05%, 8.38% and 10.59% respectively, which are superior to existing algorithms. This indicates that the proposed method can significantly improve the generalization performance of face live detection models in cross-dataset testing.
Key words:face anti-spoofing detection; content and style feature self-adaptation modules; AdaIN algorithm; domain adversarial learning; feature embedding optimization
0 引言
在过去几十年里,随着人脸识别技术的迅猛发展,人脸识别已经广泛应用于人们的日常生活,包括智能门禁、手机面部解锁、金融支付等领域。但人脸不同于指纹、虹膜和签名等对象,不需要待识别者额外进行某些动作配合,加之社交平台的开放性,使得一些用户的照片能够很容易被获取。因此,如果将这些照片呈现给识别传感器,就可能骗过人脸识别系统的身份识别。除此之外,目前的人脸识别系统还面临着视频重放、3D面具等多种欺骗形式,这严重威胁到人脸识别系统的安全性和可信度。人脸活体检测亦称人脸反欺诈,是一种检测待识别对象是真正人脸还是伪造人脸的技术。随着人脸识别技术在社会各行各业中越来越广泛的应用,为了保障人脸识别系统的安全性,研发具有人脸活体检测能力的安全可信识别系统是十分必要的。
目前,研究人员已提出一系列的人脸活体检测算法,在早期,经典的手工描述符(例如,LBP 、SIFT 、HOG 和DoG)被设计用于从各种颜色空间(RGB、HSV和YCbCr)中提取有效的欺骗模式,已经大量用于人脸活体检测。根据特征提取的差异主要分为基于纹理特征[1]、图像质量[2]、生理信号[3]和三维结构[4]的方法,其优点在于它们通过不同方式提取特征,从而提供多层次、多角度的活体检测,适用于一些简单的场景和常见的攻击类型。但这些方法存在人工设计成本高、无法提取高级特征和对攻击手段敏感等缺点,难以有效应对当前多样化的攻击和复杂的应用场景。随着深度学习技术的广泛应用,针对上述问题,提出了一系列基于深度学习技术[5~12]的人脸活体检测方法,它们普遍具有准确度高、泛化能力强、自动特征提取、抗攻击性等多重优点,但缺点是难以捕捉高级抽象特征和特征表达能力不足,例如基于二分类的人脸活体检测[8,9],简单直接的同时难以捕捉高级抽象特征,无法适应不断演化的伪造技术;为了让深度学习模型能够更好地学习内在的欺骗线索,文献[10,11]采用对比学习得到高级语义特征,扩大活脸和攻击脸之间的特征差距,增强模型性能。
然而,上述方法大多数都是根据预先确定的情景和攻击来训练深度学习模型,因此很容易让模型在几个特定的领域和攻击类型上过度拟合,进而导致跨数据集模型泛化性能差的问题。针对这类问题,研究人员提出了域泛化(domain generalization,DG)方法[12~15],使得模型在不访问任何目标数据的情况下,也能显式地挖掘出多个源域之间的关系,从而更好地泛化到不可见的域中。但是,这些域泛化方法通常将输入数据看做一个整体,没有对人脸活体检测中输入图像的风格和内容特征分开考虑。真实人脸和伪造人脸的特征一般可以分为局部纹理特征和全局内容特征:前者包括一些活性相关的纹理信息以及域特定的外部因素,它在欺骗中占据着重要的比例;而后者涵盖了全局语义特征和物理属性,一般用来表示人脸的类别、背景环境、相机以及照明等领域的内容特征空间。根据已有的研究可知,大多数欺骗线索都蕴藏在微妙的局部纹理特征中,比如局部图像失真、3D掩模边缘以及剪切照片边缘等。因此,可以将图像表示分解为全局和局部特征,即内容和风格特征,自适应地整合它们的相关性并提升图像表征能力,从而有效增强人脸活体检测算法的性能。最近,Wang等人[13]提出一种基于批量规范化(batch normalization,BN)和实例规范化(instance normalization,IN)的人脸活体检测算法,从输入中获取内容和风格特征。但由于BN提取的特征本质上对于域移动较脆弱,而IN提取的特征可能会丢失一些鉴别信息,所以两者在领域泛化方面都具有一定的局限性。此外,文献[16]强调了难样本三元组损失在增强类内紧凑性和类间差异性方面的重要作用。而在人脸活体检测中,各个领域内不同类别的样本往往比同类样本更相似,这会导致模型学习的广义特征空间识别能力显著下降。针对该问题,Jia等人[12]提出了非对称三元组损失,能够在分离不同类别的同时,使假脸特征空间更加分散而真脸特征空间更加聚集。Shao等人[17]采用双力三重挖掘约束,使得每个主体到其域内正样本的距离小于其域内负样本的距离,而每个主体跨域的正样本的距离小于负样本的距离。
不同于上述方法,本文提出了一种基于内容风格增强和特征嵌入优化的方法(content style enhancement and feature embedding optimization,CSEFO),通过两个结合不同注意力机制的自适应模块,有效地将完整图像的内容和风格表示进行分离,自适应地整合局部特征与全局特征的相关性并提升它们的表征能力。相对于现有的域泛化人脸活体检测方法,本文考虑从数据图像的风格和内容方向两个不同的侧重点去增强特征表示,从而解决现有方法在跨数据集上模型泛化性能较差的问题。与此同时,考虑到传统的两阶段方法在大规模人脸活体检测数据集上训练效率低下的问题,本文还引入了自适应实例归一化(adaptive instance normalization,AdaIN)层[18]。AdaIN根据增强的内容和风格表示自动地调整参数,实现了一种实时、高效的端到端特征级融合,使其在现实世界的大规模训练中更具适用性。此外,针对在人脸活体检测数据集中,各个数据领域内由于部分不同类别的样本比同类样本具有更高的相似性而导致模型学习的特征空间识别能力下降的问题,本文采用平均负样本的半难样本三元组挖掘策略,减少类内特征聚类过程中硬负样本的阻碍,从而降低相似特征对模型性能的影响。同时,本文调整特征空间中的样本分布,优化特征嵌入,增强同类样本的相似性,加大不同类别之间的差异性,进一步增强了模型的表征能力,使其在特征空间中能更好地区分真实人脸和伪造人脸,并在四个被广泛用于人脸活体检测研究的公开数据集上进行了实验验证。
1 本文方法
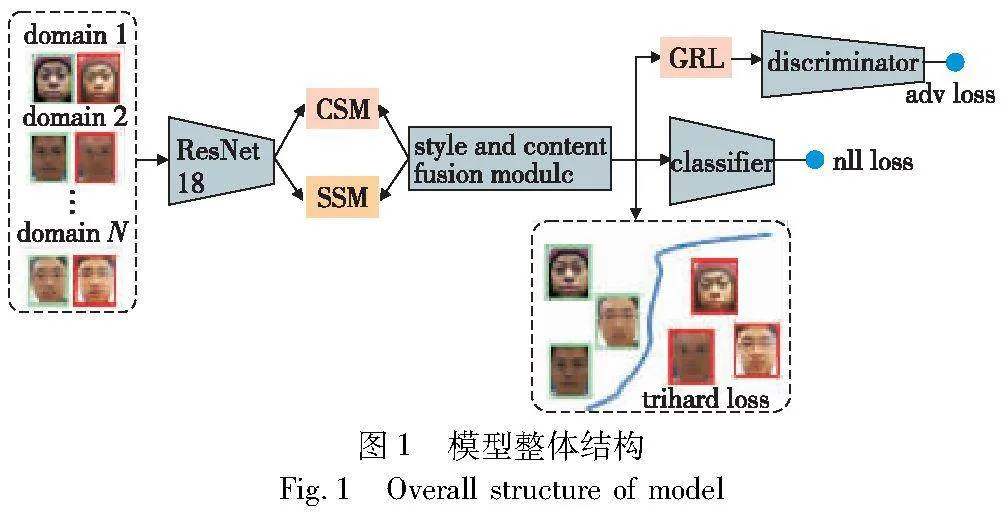
本文模型整体结构如图1所示。以在ImageNet上预训练好的ResNet-18[19]为主干特征提取网络,将所提取的特征输入到内容自适应模块(content self-adaptation module,CSM)和风格自适应模块(style self-adaptation module,SSM)中,分别强化两种特征的表征能力。随后,通过内容风格特征融合模块将增强后的内容和风格特征进行有机融合,产生新的组合特征,并将其输入特定的分类器进行分类。同时,采用领域鉴别器进行对抗训练,随着数据采集条件和环境的多变,领域之间的差异也变得显著,对抗训练在此发挥关键作用,助力模型准确捕捉数据的本质特征,更好地适应领域间的变化,即使在未知领域中仍能够有效泛化,确保其持续可靠的性能。此外,通过一种平均负样本的半难样本三元组挖掘算法,挑选恰当的正负样本。据此调整特征空间中的样本分布,以优化特征嵌入,从而增强模型的表征能力和改进相似度度量。这可以显著提升模型的分类准确性以及在各种场景下的泛化能力,为整个人脸活体检测方法切实带来性能提升。
1.1 内容和风格自适应模块
如图1所示,在内容和风格自适应模块中,首先使用经过预训练的ResNet-18作为通用特征提取器,对所有域的图像进行特征提取。这个特征提取过程将原始图像从其各自的特征空间映射到了一个通用的特征空间,然后将获得的通用特征输入内容自适应模块CSM和风格自适应模块SSM。更具体地说,先将来自多个源域的图像批次输入到通用特征提取器F中,从中得到特征表示Fx;再将Fx分别传递给内容自适应模块CSM和风格自适应模块SSM。通过这两个自适应模块,将Fx分解成内容特征Fxc和风格特征Fxs,这种分解能够有效地将内容和风格信息进行自适应分离,增强内容特征和风格特征的相关性,并提升它们的表征能力。这种内容和风格自适应模块的设计,充分利用了通用特征提取器的能力,并通过独立的模块对内容和风格进行拆解和特征表示增强,从而为模型提供了更丰富的上下文信息,有助于在后续的处理中更好地捕获图像的内在特征。
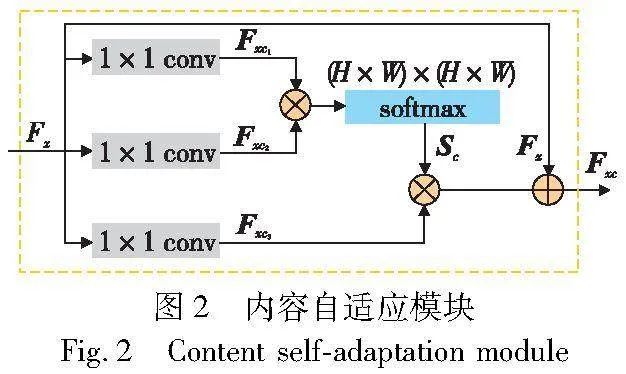
基于位置的内容自适应模块CSM使用位置注意力来捕获特征图内各个位置之间的关联性。如图2所示,通过自主学习每一位置的权重,将更广泛的上下文信息转换为局部特征,从而使模型更加集中于图像中关键的空间位置。这种处理方式有助于提升内容特征的表示能力,让模型能够更为精准地关注图像内重要的空间要素。
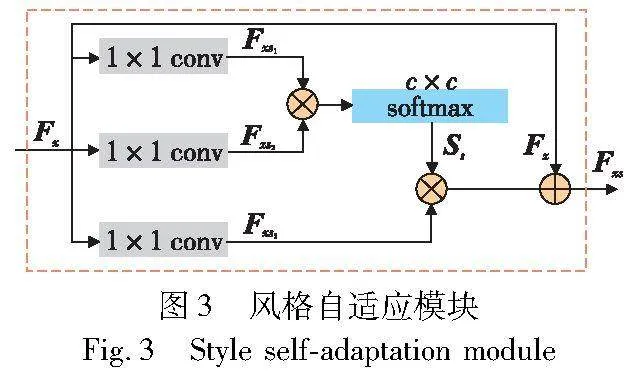
基于图像通道的风格自适应模块SSM则运用通道注意力集中关照特征图内各个通道之间的关联性,如图3所示,它借助全局信息,智能地调整每个通道的权重。由于每一通道内涵盖特定类别的信息,且不同的语义响应相互交织,通过探索通道之间的相互依赖关系能够强调互相关联的特征映射,进而提升特定语义的特征表现。此过程既强化了重要特征通道,又抑制了其他非重要特征通道。而且,特征图之间的通道式内积呈现出了图像的风格。具体过程与位置注意力模块一样,但位置注意力模块是去掉矩阵的通道数据,而通道注意力模块是去掉空间数据增强风格特征的表示。
1.2 内容和风格特征融合模块
AdaIN是一种用于图像风格迁移和图像合成的技术,通过将内容图像的特征图归一化,并使用风格图像的均值和标准差对其进行重新缩放和偏移,从而将内容图像的特征统计信息调整为类似风格图像的分布,实现内容和风格的融合。在内容和风格特征融合模块中,主要基于AdaIN算法,将由上一节中的CSM以及SSM得到的内容增强特征Fxc和风格增强特征Fxs进行融合,以进一步改进特征表示。具体来说,通过将内容特征Fxc的特征进行实例归一化,使其统计特性接近于风格特征Fxs,计算公式如下:
其中:σ(·)和μ(·)分别表示特征的均值和标准差;而γ和β是根据风格增强特征Fxs生成的仿射参数,计算公式为
γ,β=MLP(AMP(Fxs))(6)
其中:MLP代表多层感知器,通过多阶非线性变换深化了对数据的抽象特征学习;而AMP则表示自适应最大池化,这是一种能够自主调整的池化方法。为实现内容与风格的融合,本文将AdaIN层的输出与内容特征Fxc逐元素相加,得到了融合的增强特征S(Fxc,Fxs),具体的计算方式为
S(Fxc,Fxs)=AdaIN(Fxc,γ,β)+Fxc(7)
1.3 领域对抗学习模块
由于不同领域的伪造人脸分布差异显著,很难为伪造人脸寻找一个紧凑和通用的特征空间,所以在得到融合的增强特征S后,本文通过对抗学习方法最小化多个源域的真实人脸的分布差异,使得不同来源的真实人脸特征不可区分,从而增强模型的泛化性能。如图1所示,将融合后的增强特征S输入域判别器D,域判别器D用于区分输入特征的不同来源。在学习过程中,领域特征提取器的参数通过最大化领域判别器的损失函数进行优化,而领域判别器的参数则采用相反的目标进行优化。为了降低训练复杂度,在领域特征提取器和领域判别器之间引入了一个梯度反转层(gradient reverse layer,GRL)[20],可以在反向传播过程中通过乘以负标量反转梯度方向。由于涉及多个源域,本文采用标准的交叉熵损失,在对抗学习下优化网络,具体计算公式为
其中:YD是域标签集;N是不同数据域的数量;G表示特征生成器;D表示域判别器。
1.4 平均负样本的半难样本三元组挖掘
在人脸活体检测中,由于攻击类型和数据库采集方式的多样性,导致伪造人脸之间的分布差异很大;且有些伪造人脸图像与真实人脸图像之间的差异较小,如图4(c);而其他伪造人脸图像与真实人脸的差异较大,如图4(b)(d)。对于那些差异较大的伪造人脸,模型可以轻易地将它们与真实人脸区分开,因此这些负样本对模型的训练帮助有限。为了更好地训练模型,需要引入差异较小的伪造人脸图像,挖掘相对较难的样本三元组,使得模型能够更好地区分它们。
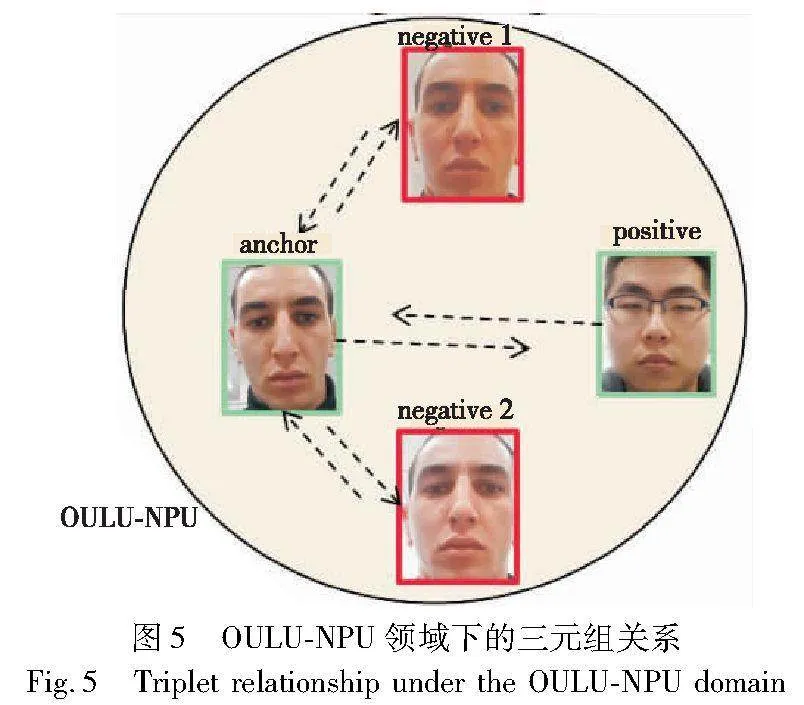
在打印和重放攻击中,当将伪造人脸作为锚样本时,不同类别的负样本(真实人脸)与同一批的正样本(伪造人脸)之间可能具有相似的特征,如图4(a)(c)。而将真实人脸作为锚样本时,同一个人的假脸之间往往具有相似的面部特征,而非同一个人的真实脸之间往往具有不同的面部特征,这使得领域中的每个真脸锚样本的相同身份的负样本比不同身份的正样本更相似,如图5所示。这种相似性可能破坏锚样本与正样本之间的聚集性和锚样本与负样本之间的排斥性,使得模型学习到的广义特征空间的识别能力下降。为解决这个问题,本文提出了一种平均负样本的半难样本三元组挖掘优化特征嵌入,能够更好地分别聚集不同领域的真脸和假脸,并且让提取的所有领域的真脸和假脸在特征空间更加分散,产生更好的决策边界,从而增强模型的表征能力和改进相似度度量,提高检测效果。
假设数据样本来自三个不同源域,训练时每一批样本中有来自不同源域相同数量的真实人脸和伪造人脸样本,将所有领域的真实人脸归为一类,而把所有领域的伪造人脸归为另一类。由于一些硬负样本比一般的正样本有更多的相似特征,这比不同类别之间的排斥更妨碍类内的聚集。因此,对真假人脸进行两类平均负样本的半难样本三元组挖掘,可以侧重于类内特征聚集过程中消除难负样本的阻碍。在难样本三元组损失中,将锚样本和硬负样本之间的欧几里德距离转换为一个批次内的常数,这样就在梯度中消除了硬负样本的影响,使得网络模型可以集中地学习类内的共同特征,如式(9)所示。
其中:ai是一小批样本D中第i个锚样本的特征表示;ph是一批样本D中与ai属于同一类别的正样本的特征表示;nh是一批样本D中与ai属于不同类别的负样本的特征表示;dist(ai,ph) 是特征向量ai和ph之间的欧几里德距离;α是一个正数,表示正负样本之间的最小距离差异;而β=dist(ai,nh)是在批次D中动态计算的,因此它在批次内是恒定的,但批次之间是可变的,可以消除硬负样本的影响。
但是,如果完全消除硬负样本的影响,也就完全消除了类之间的排斥,当不同类的特征向量之间的距离很近时,这可能会损害网络的检测性能。因此,平均负样本的半难样本三元组挖掘需要同时强调类间排斥,即真假人脸之间的排斥,如式(10)~(12)所示。
其中:L2降低了负样本对同一批样本中类内聚集的影响,保留了不同类之间的排斥功能,从而扩大了不同类别之间的距离。
综上所述,平均负样本的半难样本三元组损失函数如下:
Ltri=L1+L2(13)
本文采用平均负样本的半难样本三元组挖掘损失,通过针对真实和伪造类别进行难样本的三元组挖掘,从而优化特征嵌入,更好地捕捉真实和伪造类别之间的界限,有助于模型更准确地学习真实和伪造类别的边界,进而在未知领域中呈现更出色的人脸活体检测效果。
1.5 分类器模块
鉴于所有源域数据都已经标记,因此这里加入了一个有监督的分类器,以内容和风格特征融合模块的输出作为输入,并在网络训练过程中,在模型的输出层使用负对数似然损失作为分类器的损失函数。对于分类问题,该损失函数衡量了模型的输出概率分布与真实标签分布之间的差异,其计算公式为
其中:N是一批训练样本的数量;yi是第i个样本的实际类别标签;Pi,yi是第i个样本中实际类别标签yi对应的预测概率,通过log_softmax()计算得到。
1.6 模型损失函数
综上所述,本文采用端到端的方式训练模型,总体损失函数包括分类损失、对抗损失和平均负样本的半难样本三元组损失三种,具体计算公式如下:
Lall=Lnll+λ1Ladv+λ2Ltri(15)
其中:λ1和λ2为两个超参数,在文本中分别设备为0.5和0.5,用于平衡不同损失函数的比例。
2 实验与分析
2.1 数据集
本文使用四个广泛用于人脸活体检测研究的公开数据集进行实验验证。
a)CASIA-FASD数据集[21]包含600个真实人脸视频和伪造人脸视频,按照低、中、高图像质量分成三组,每组有4个视频,其中1个为真,其余3个分别是扭曲打印图像、剪切图像和视频重放三种攻击。
b)REPLAY-ATTACK数据集[22]包含1 300个真实人脸视频和伪造人脸视频,主要是在不同的人物、光照条件、设备和攻击方式下采集。
c)MSU-MFSD数据集[23]由35名被试者的280个真实和虚假人脸视频组成。真实视频采用电脑和手机两种采集方式,欺骗视频分为三类,依次是高分辨率视频回放、手机视频回放和打印攻击。
d)OULU-NPU数据集[24]是基于55个人物的4 950个视频,由6种手机前置摄像头在3个不同的(光照条件和背景场景)地点收集,真实与攻击比例为1∶4。
2.2 数据预处理
上述数据集包含图像和视频数据,对于视频数据,以特定的间隔提取图像帧,对于图像数据,使用MTCNN算法[25]对输入图像进行人脸检测和对齐,将所有的图像裁剪为256×256×3的大小作为RGB输入信号,并对数据进行统一的随机中心裁剪、随机水平翻转以及标准化等预处理操作。
2.3 实验设置
在本实验中,采用了NVIDIA GeForce RTX 2080Ti显卡作为硬件环境,编程语言为Python 3.9,并使用PyTorch深度学习框架选择了随机梯度下降作为模型的优化器,将动量参数设置为0.9,以增加训练的稳定性。为了控制模型的复杂度,权值衰减设置为5E-4。在训练过程中,数据的批量大小为120,而初始学习率设定为0.01,每经过100轮训练将学习率减半,以便更好地引导模型收敛。
2.4 评价指标
在实验中,采用了半全错误率(half total error rate,HTER)和曲线下的面积(area under curve,AUC)作为评价指标,用于衡量算法的优劣。其中,半全错误率是错误拒绝率(FRR)和错误接受率(FAR)总和的一半,其计算公式如式(16)(17)所示。
其中:TP、FP、TN和FN分别表示真正例、假正例、真负例和假负例;FAR表示错误接受率;FRR表示错误拒绝率。而曲线下的面积(AUC)是指在ROC曲线上方的面积,ROC曲线是用于评估分类模型性能的工具。AUC的取值在0~1,当AUC越接近1时,说明模型的性能越好。
2.5 实验结果分析
2.5.1 跨数据集实验
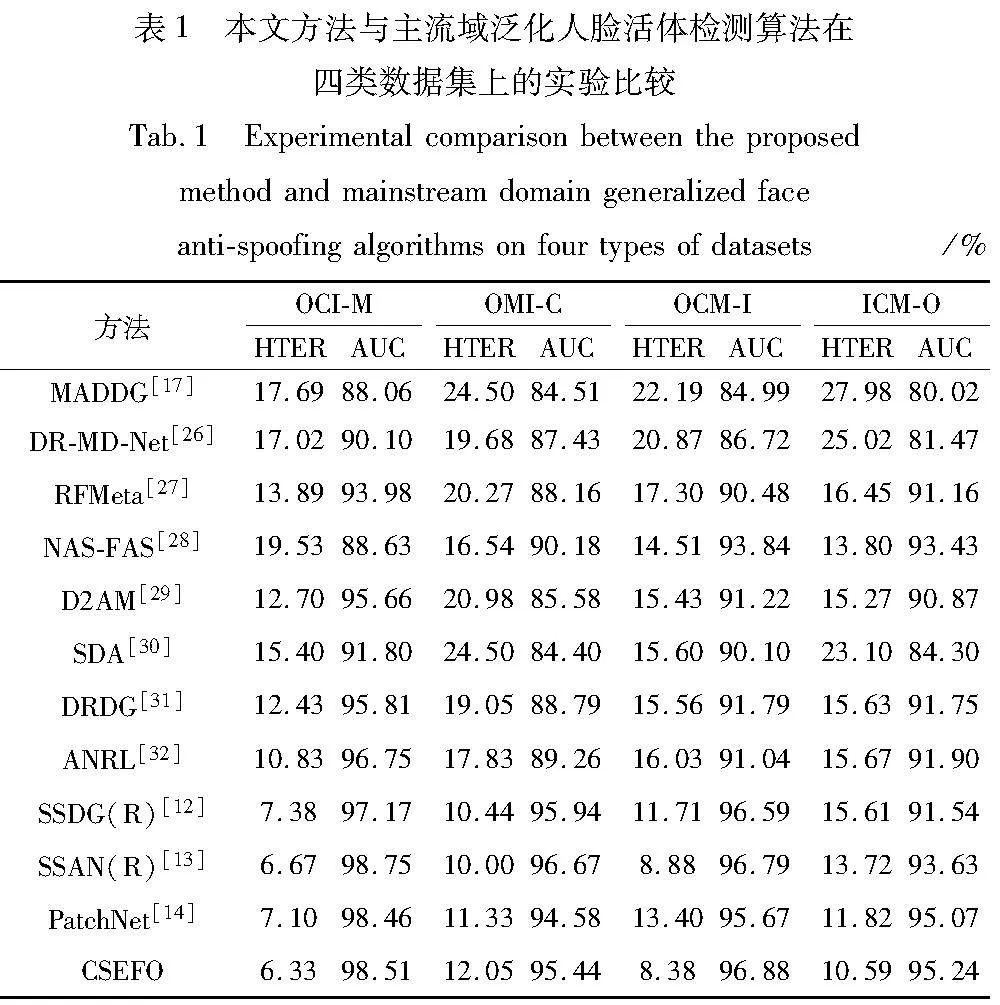
为了验证本文方法在跨数据集场景下的泛化能力,本节进行了跨数据集测试实验,选用的四个数据集都是用不同的捕获设备、攻击类型、照明条件、背景场景和种族收集的,因此,这些数据集之间存在明显的领域差异。根据先前的工作,采用留一测试协议的方式评估算法的性能。具体来说,将每个数据集均视为一个领域,随机选取一个数据集作为测试的目标域,其余三个数据集作为训练时的源域。因此,总共有OCI-M、OMI-C、OCM-I和ICM-O四个测试任务,其中OCI-M表示是在OULU-NPU、MSU-MFSD和REPLAY-ATTACK上训练,而在CASIA-FASD上测试的协议,另外三个类似。实验结果如表1所示,可以看出,以ResNet为主干的本文算法在四个跨领域评估设置下超越了大多数现有方法。与MADDG、SSDG-M、SSAN等对抗域泛化方法相比较,在大多数场景下,本文方法都达到了最优效果。它可以在人脸活体检测中将完整的图像表示分离为内容和风格特征,并分别增强其特征表示,进而可以较好地提高跨场景活体检测模型的泛化能力。另外,SSAN虽然使用了BN和IN的结构来更好地分离内容和风格,但由于BN提取的特征本质上对于域移动较脆弱,而IN提取的特征可能会丢失一些鉴别信息,这使得其在领域泛化方面存在一定的局限性。从表1实验结果可以看出,除了在OMI-C测试场景中,SSAN方法都不如本文所采取的两个基于独特的注意力机制的内容和风格特征自适应模块;而在OMI-C测试任务下,本文方法性能不如SSAN(R),这主要是因为SSAN(R)方法中的IN结构注重于保留样本内的特征信息,容易丢失一些有助于分类鉴别信息的全局特征,比如背景信息中的照片剪切位置和视频的莫尔条纹。然而,由于CASIA-FASD数据集中存在较多的低分辨率图像数据,其局部特征更加显著,而背景或场景信息类的全局特征差异并不明显,所以只看OMI-C测试结果,其性能结果较优。但根据其他最新的数据集测试结果和整体来看,本文方法在实际应用场景中的性能更加优异。
2.5.2 消融性实验
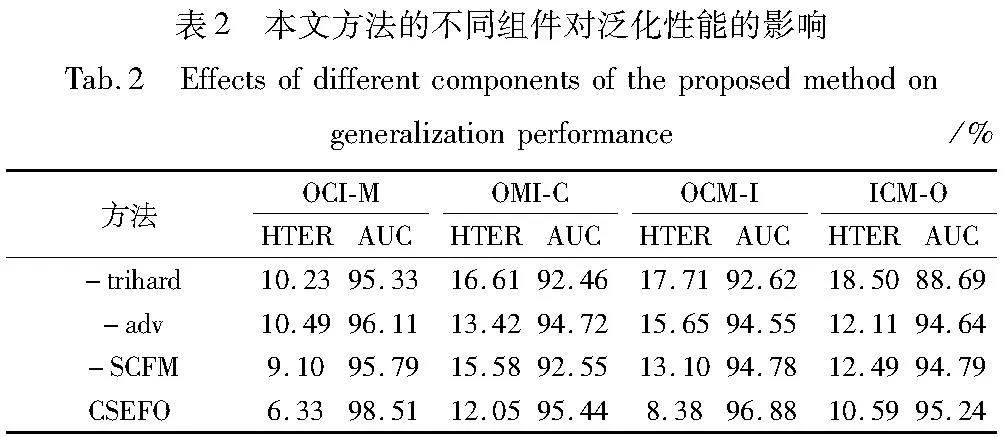
为了验证本文方法各个组成部分的贡献,通过分别去掉 模型中的内容和风格自适应模块、领域对抗学习和平均负样本的半难样本三元组挖掘来进行消融实验,从而验证各个组成部分的作用。所有结果都以相同的方式测量,消融实验的结果如表2所示。表中“-SCFM”表示去掉内容和风格自适应模块,“-adv”表示去掉域鉴别器,“-trihard”表示去掉平均负样本的半难样本三元组损失。从表2中的数据可以看出,首先,当移除任何一个模块后,模型的测试精度都会出现下降,这明显表明了所有模块对于提升泛化性能的积极影响。另外,相比于去掉其他模块,去掉平均负样本的半难样本三元组损失对结果产生了更大的影响,这说明了优化特征嵌入对于整个模型性能提高的重要性。
2.5.3 有限源域实验
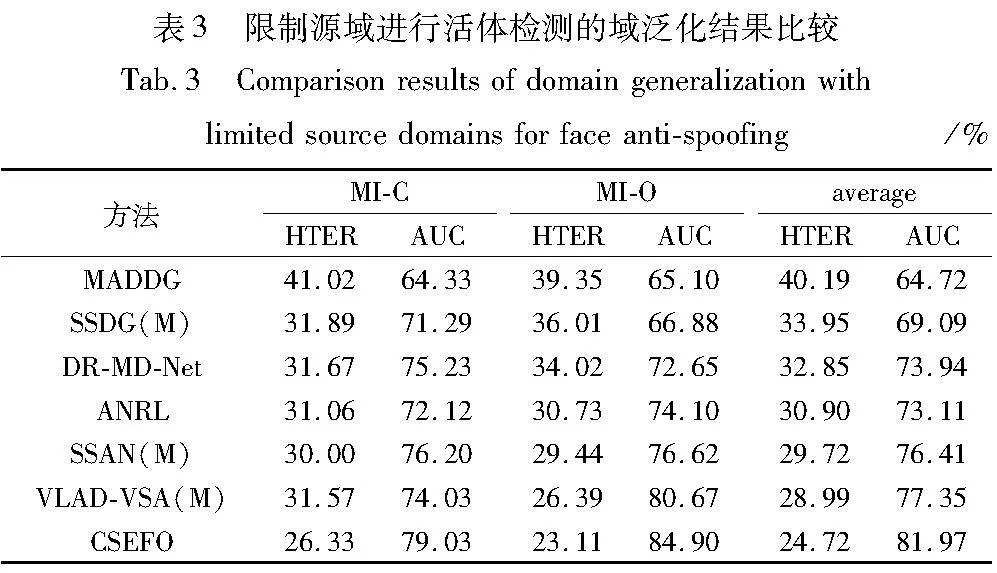
本文通过限制源域的数量来进一步评估本文方法的泛化性能,如表3所示。选择MSU-MFSD和REPLAY-ATTACK这两个分布差异较大的数据集作为源域,而剩下的OULU-NPU和CASIA-FASD数据集分别用来测试,总共有MI-C和MI-O两个测试任务。从表3中可以看出,尽管源数据有限,但本文方法实现了最低的HTER和最高的AUC,这证明了本文方法在挑战性任务中的良好泛化能力。
3 可视化和分析
3.1 注意力可视化
本文使用Grad-CAM方法[33]来进行注意力可视化分析。基于模型的梯度信息,通过计算特定类别的输出相对于特征图的梯度,用于确定哪些区域对于该类别的预测贡献较大,然后,通过对梯度和特征图进行加权求和,生成一个类激活映射(class activation map,CAM)。生成的类激活映射可以叠加到原始图像上,将图像中对预测结果影响最大的区域可视化出来,即标识出对于模型分类决策最有影响力的区域。如图6所示,第一至三列均为真实人脸,其余列为伪造人脸;第一行为原始图像,其余行为OCM-I训练任务下CSM、SSM和SCF模块激活区的可视化,其中,SCF为内容和风格特征融合模块。可以观察到,无论是真实人脸还是伪造人脸,内容特征自适应模块都侧重于人脸面部区域(如眼睛、鼻子和嘴巴),而风格特征自适应模块侧重背景、光照、边缘等区域。当增强的内容和风格融合后,会表现出不同的激活特性:a)对于真实人脸,本文方法侧重于人脸区域寻找判断线索;b)而对于伪造人脸,可以根据不同的攻击关注不同的区域,除了在人脸面部区域寻找判断线索外,本文方法也将关注来自风格特征区域的欺骗线索,比如在打印攻击中的剪切照片边缘等,这表示通过自适应模块增强内容特征和风格特征的相关性并提升它们的表征能力后,有助于模型更准确地捕捉区分性特征,从而提高模型的准确性。
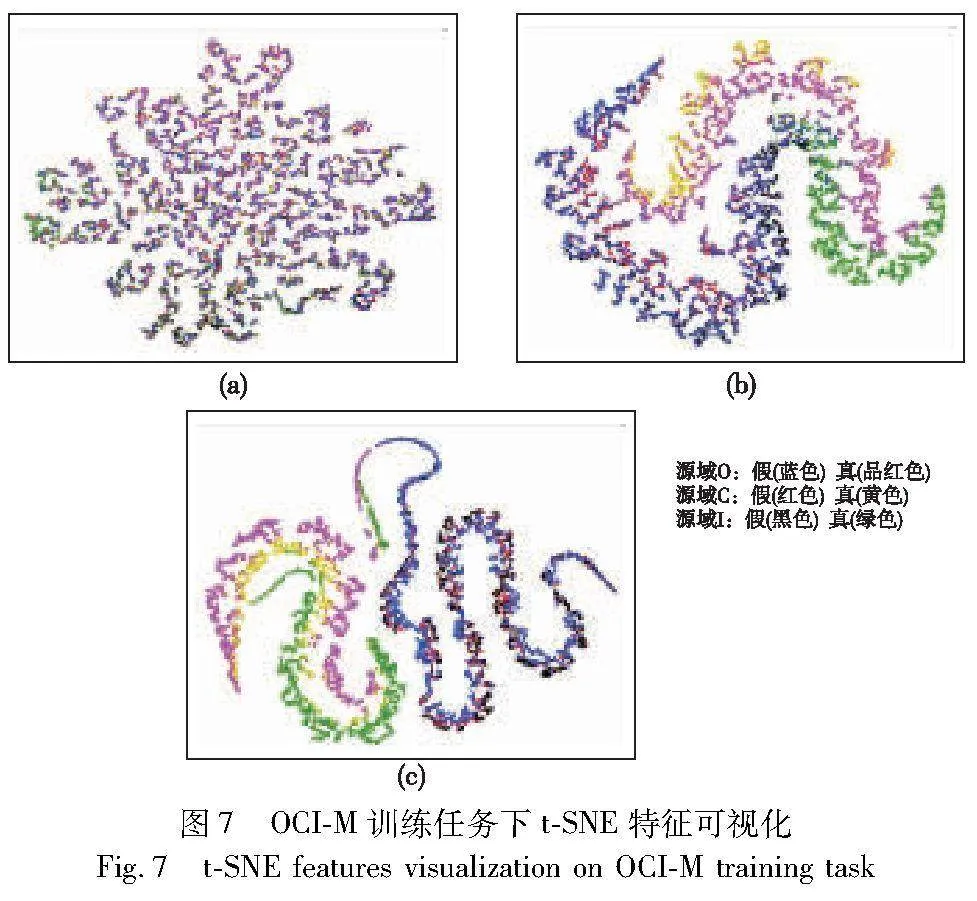
3.2 特征可视化
为了分析通过本文方法学习的特征空间,使用t-SNE [34]可视化不同情况下的特征分布。图7是以OULU-NPU、CASIA-FASD 和REPLAY-ATTACK作为源域训练模型时的t-SNE 特征可视化图。实验从每个源域分别选择2 000个真实人脸样本和2 000个伪造人脸样本。图7(a)表示原始特征的t-SNE 特征可视化图,图7(b)表示不使用平均负样本的半难样本三元组挖掘的模型训练完成后的t-SNE 特征可视化图,图7(c)表示使用平均负样本的半难样本三元组挖掘的模型训练完成后的t-SNE 特征可视化图。可以看出,相较于图7(a)(b),图7(c)表示的模型在平均负样本的半难样本三元组挖掘下,不同领域的同类真实人脸样本和同类伪造人脸样本在特征空间中的分布更加紧凑,而真实人脸样本与伪造人脸样本的类与类之间的分布差异更大。这表明平均负样本的半难样本三元组挖掘能够有效提升类内紧凑性和类间区分性,使得模型的决策边界更加清晰和准确。这样的优化能够显著提升模型的分类准确性,为整个人脸活体检测方法带来了实质性的性能提升。
4 结束语
本文提出了一种基于内容风格增强和特征嵌入优化的人脸活体检测方法。该方法首先将多个源域的特征通过两个独特注意力机制的内容自适应模块和风格自适应模块,有效地进行内容和风格表示自适应分离,增强内容特征和风格特征的相关性并提升了它们的表征能力;其次,通过对抗训练提取多个源域真实人脸的领域共享特征,从而提高跨数据集测试时的模型泛化性能;最后,引入一种平均负样本的半难样本三元组挖掘方法,通过这种方法对特征嵌入进行优化,进一步提升了模型的分类准确率。为了验证上述方法的有效性,本文在四个广泛应用人脸活体检测研究的公开数据集上进行了跨库测试和消融实验。实验结果充分证明了该方法的优良性能。但需要注意的是,特定的内容和风格特征可能会包含领域特有的信息,它们有可能限制模型在不同领域中的泛化性能,因此,后续工作可以考虑引入约束条件进一步增强方法的性能。
参考文献:
[1]Raghavendra R, Raja K B, Busch C. Presentation attack detection for face recognition using light field camera[J]. IEEE Trans on Image Processing, 2015,24(3): 1060-1075.
[2]Galbally J, Marcel S, Fierrez J. Image quality assessment for fake biometric detection: application to iris, fingerprint, and face recognition[J]. IEEE Trans on Image Processing, 2013,23(2): 710-724.
[3]Wang Shunyi, Yang Shihung, Chen Yonping, et al. Face liveness detection based on skin blood flow analysis[J]. Symmetry, 2017,9(12): 305.
[4]Wang Yan, Nian Fudong, Li Teng, et al. Robust face anti-spoofing with depth information[J]. Journal of Visual Communication and Image Representation, 2017,49: 332-337.
[5]Song Xiao, Zhao Xu, Fang Liangji, et al. Discriminative representation combinations for accurate face spoofing detection[J]. Pattern Recognition, 2019, 85: 220-231.
[6]Muhammad A, Zhu Ming, Javed M Y. CNN based spatio-temporal feature extraction for face anti-spoofing[C]//Proc of the 2nd International Conference on Image, Vision and Computing. Piscataway, NJ: IEEE Press, 2017: 234-238.
[7]Ur Rehman Y A, Po Laiman, Komulainen J. Enhancing deep discriminative feature maps via perturbation for face presentation attack detection[J]. Image and Vision Computing, 2020, 94: 103858.
[8]Yang Jianwei, Lei Zhen, Li S Z. Learn convolutional neural network for face anti-spoofing [EB/OL]. (2014-08-26). https://arxiv.org/abs/1408.5601.
[9]Liu Yaojie, Stehouwer J, Jourabloo A, et al. Deep tree learning for zero-shot face anti-spoofing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 4675-4684.
[10]郝瑾琳, 陈雪云. 结合对比学习与空间上下文的人脸活体检测[J]. 广西大学学报: 自然科学版, 2021,46(6): 1579-1591. (Hao Jinlin, Chen Xueyun. Face anti-spoofing based on spatial contex-taware contrastive learning[J]. Journal of Guangxi University: Na-tural Science Edition, 2021, 46(6): 1579-1591.)
[11]蔡体健, 尘福春, 刘文鑫. 基于条件对抗域泛化的人脸活体检测方法[J]. 计算机应用研究, 2022,39(8): 2538-2544. (Gai Tijian, Chen Fuchun, Liu Wenxin. Face anti-spoofing method based on conditional adversarial domain generalization[J]. Application Research of Computers, 2022,39(8): 2538-2544.)
[12]Jia Yunpei, Zhang Jie, Shan Shiguang, et al. Single-side domain generalization for face anti-spoofing[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 8481-8490.
[13]Wang Zhuo, Wang Zezheng, Yu Zitong, et al. Domain generalization via shuffled style assembly for face anti-spoofing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway, NJ: IEEE Press, 2022: 4113-4123.
[14]Wang Chienyi, Lu Yuding, Yang Shangta, et al. PatchNet: a simple face anti-spoofing framework via fine-grained patch recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press, 2022: 20249-20258.
[15]Wang Jiong, Zhou Zhao, Jin Weike, et al. VLAD-VSA: cross-domain face presentation attack detection with vocabulary separation and adaptation[C]//Proc of the 29th ACM International Conference on Multimedia. New York: ACM Press, 2021: 1497-1506.
[16]Lyu Yihao, Gu Youzhi, Liu Xinggao. The dilemma of trihard loss and an element-weighted trihard loss for person re-identification[C]//Proc of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 17391-17402.
[17]Shao Rui, Lan Xiangyuan, Li Jiawei, et al. Multi-adversarial discriminative deep domain generalization for face presentation attack detection[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 10015-10023.
[18]Huang Xun, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 1510-1519.
[19]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 770-778.
[20]Ganin Y, Lempitsky V. Unsupervised domain adaptation by backpropagation[C]//Proc of the 32nd International Conference on International Conference on Machine Learning.[S.l.]: JMLR.org, 2015: 1180-1189.
[21]Zhang Zhiwei, Yan Junjie, Liu Sifei, et al. A face antispoofing database with diverse attacks [C]//Proc of the 5th IAPR International Conference on Biometrics. Piscataway, NJ: IEEE Press, 2012: 26-31.
[22]Chingovska I, Anjos A, Marcel S. On the effectiveness of local binary patterns in face anti-spoofing[C]//Proc of International Conference of Biometrics Special Interest Group. Piscataway, NJ: IEEE Press, 2012: 1-7.
[23]Wen Di, Han Hu, Jain A K. Face spoof detection with image distortion analysis[J]. IEEE Trans on Information Forensics and Security, 2015, 10(4): 746-761.
[24]Boulkenafet Z, Komulainen J, Li Lei, et al. OULU-NPU: a mobile face presentation attack database with real-world variations[C]//Proc of the 12th IEEE International Conference on Automatic face & Gesture Recognition. Piscataway,NJ:IEEE Press, 2017: 612-618.
[25]Zhang Kaipeng, Zhang Zhanpeng, Li Zhifeng, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[26]Wang Guoqing, Han Hu, Shan Shiguang, et al. Cross-domain face presentation attack detection via multi-domain disentangled representation learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 6677-6686.
[27]Shao Rui, Lan Xiangyuan, Yuen P C. Regularized fine-grained meta face anti-spoofing[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 11974-11981.
[28]Yu Zitong, Wan Jun, Qin Yunxiao, et al. NAS-FAS: static-dynamic central difference network search for face anti-spoofing[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2020,43(9): 3005-3023.
[29]Chen Zitong, Yao Taiping, Sheng Kekai, et al. Generalizable representation learning for mixture domain face anti-spoofing[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 1132-1139.
[30]Wang Jingjing, Zhang Jingyi, Bian Ying, et al. Self-domain adaptation for face anti-spoofing[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 2746-2754.
[31]Liu Shubao, Zhang Keyue, Yao Taiping, et al. Dual reweighting domain generalization for face presentation attack detection [EB/OL]. (2021-06-30). https://arxiv.org/abs/2106.16128.
[32]Liu Shuhao, Zhang Keyue, Yao Taiping, et al. Adaptive normalized representation learning for generalizable face anti-spoofing[C]//Proc of the 29th ACM International Conference on Multimedia. New York: ACM Press, 2021: 1469-1477.
[33]Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 618-626.
[34]van der Maaten L, Hinton G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008,9: 2579-2605.
