基于优化感受野策略的图像修复方法
2024-07-31刘恩泽刘华明王秀友毕学慧
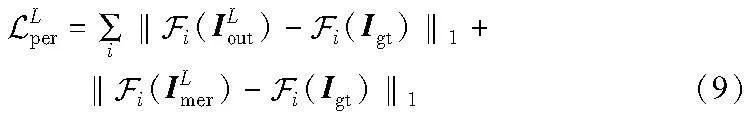




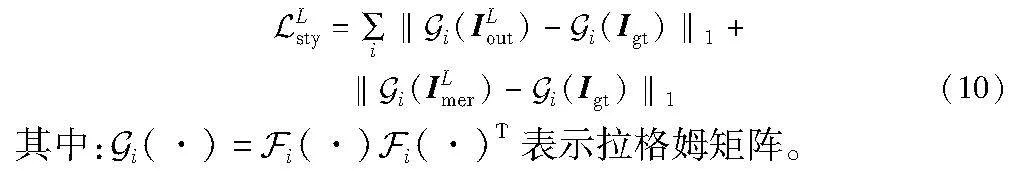
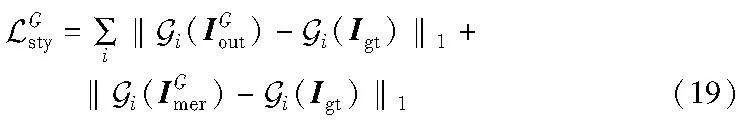
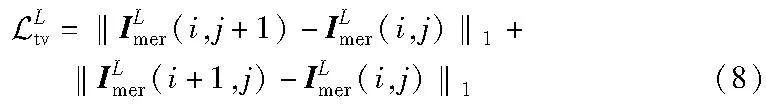
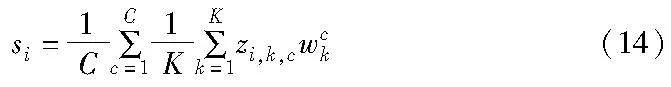
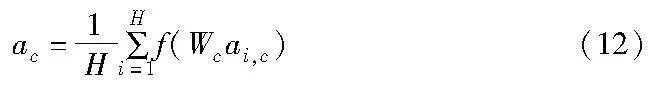
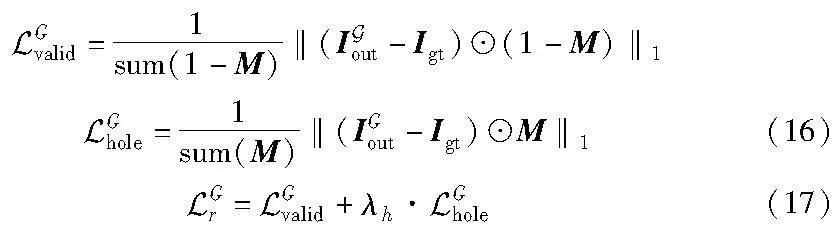
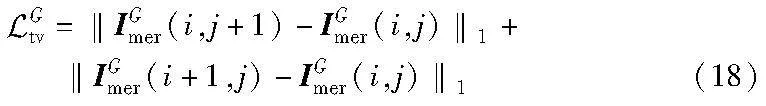

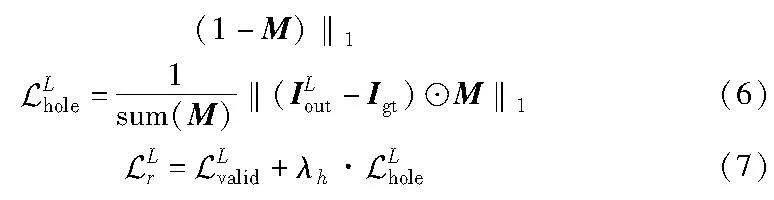
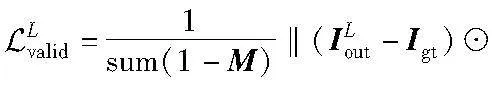
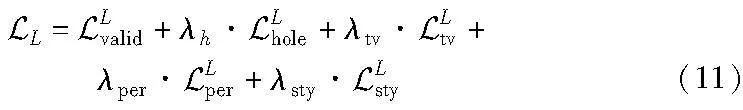
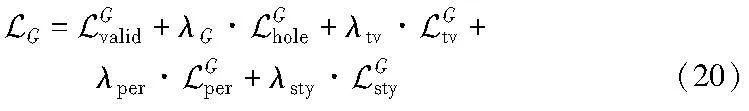
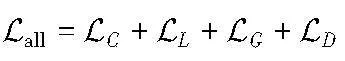
摘 要:当前流行的基于深度神经网络的图像修复方法,通常使用大感受野的特征提取器,在修复局部图案和纹理时,会产生伪影或扭曲的纹理,从而无法恢复图像的整体语义和视觉结构。为了解决这个问题,提出了一种基于优化感受野策略的图像修复方法(optimized receptive field,ORFNet),将粗糙修复与精细修复相结合。首先,使用具有大感受野的生成对抗网络获得初始的粗略修复结果;然后,使用具有小感受野的模型来细化局部纹理细节;最后,使用基于注意力机制的编码器-解码器网络进行全局精炼修复。在CelebA、Paris StreetView和Places2数据集上进行验证,结果表明,ORFNet与现有具有代表性的修复方法进行对比,PSNR和SSIM分别平均提升1.98 dB和2.49%,LPIPS平均下降2.4%。实验证明,所提图像修复方法在不同感受野的引导下,在修复指标上表现更好,在视觉上也更加真实自然,验证了该修复方法的有效性。
关键词:自编码网络; 语义一致; 感受野; 注意力; 粗修复和细修复
中图分类号:TP391.41 文献标志码:A
文章编号:1001-3695(2024)06-043-1893-08
doi:10.19734/j.issn.1001-3695.2023.09.0406
Deep neural network inpainting method based on optimized receptive field strategy
Abstract:The currently popular image inpainting methods based on deep neural network typically employ large receptive field feature extractors. However, when restoring local patterns and textures, they often generate artifacts or distorted textures, thus failing to recover the overall semantic and visual structure of the image. To address this issue,this paper proposed a novel image inpainting method, called ORFNet, which combined coarse and fine inpainting by employing an optimized receptive field strategy. Initially, it obtained a coarse inpainting result by using a generative adversarial network with a large receptive field. Subsequently, it used a model with a small receptive field to refine local texture details. Finally, it performed a global refinement inpainting by using an encoder-decoder network based on attention mechanisms. Validation on the CelebA, Paris StreetView, and Places2 datasets demonstrates that ORFNet outperforms existing representative inpainting methods. It leads to 1.98 dB increase in PSNR and 2.49% improvement in SSIM, along with average 2.4% reduction in LPIPS. Experimental results confirm the effectiveness of the proposed image inpainting method, showcasing superior performance across various receptive field settings and achieving more realistic and natural visual outcome.
Key words:autoencoder network; semantic consistency; receptive field; attention; coarse-fine inpainting
0 引言
图像修复[1]是图像处理的重要应用之一,用于填补受损区域和移除目标物并生成视觉一致性的内容。目前,该技术在破损照片修复[2]、古迹修复[3]和目标移除[4]等领域得到广泛关注。现有的图像修复方法可分为基于传统的方法和基于深度学习的方法。传统的图像修复方法主要有基于扩散的方法[5]和基于补丁[6]的方法。基于扩散方法利用图像受损边缘的信息逐步渗透到被污损的区域,主要有偏微分和变分修复技术。Getreuer[7]使用分裂Bregman迭代算法进行求解,该方法能够有效地处理各种类型的噪声、缺失和去除物体等图像修复问题,但是这种修复方法只能填补小面积区域,修复大面积区域时容易造成图像模糊。为了解决这个问题,Criminisi等人[8]提出了一种优先权填充顺序的方法,从污损区域的邻域寻找相似的补丁,复制到污损的区域与其融合,使得原有图像结构信息得以更好的传播,其本质是使用相似的纹理块对孔洞进行填充,从像素级填补提升到图像块填充,更有利于保持图像的纹理和结构信息,在寻找样本块时面临耗时严重的问题。Barnes等人[9]利用Patchmatch技术进行随机搜索提高了搜索样本块的时间,已经应用于Photoshop软件中,当缺少样本资源时,无法实现内容的修补。尽管这些修复方法取得了不错的修复效果,但是也存在着一些局限性,例如当填补面积较大、旋转、缩放、阴影、光照不均等复杂背景条件下,很难得到满意的填充效果(图1)。
为了解决此问题,学者们将深度学习引入图像修复,如使用卷积神经网络(CNN)[10]和生成对抗网络(GAN)[11]。根据网络模型的设计可将其分为单阶段模型[11,12]、双阶段模型[13,14]和多阶段模型[15,16]。单阶段的模型如Pathak等人[11]提出的一种基于自编码器的图像修复方法。通过一种无监督的学习方法,它可以从输入数据中学习到数据的特征表示,并在输出时将特征表示转换回输入数据的形式,与传统方法相比,它可以更好地利用遮挡区域之外的信息进行修复,但是由于没有将纹理信息与整体结构分开考虑,对于边缘信息还原得不够细致,所以在大规模缺失的情况下容易产生伪影等不正确的修复结果。为此,Yu等人[14]提出了从粗糙到精细的双阶段修复模型,首先从生成边缘保留的平滑图像作为全局结构信息,再从具有相似结构的区域中采样特征。该方法可以很好地再生成完整结构的前提下还原逼真的纹理信息。然而在修复完成后,该方法未能很好地处理下一阶段的子网络对上一阶段修复结果的语义认知缺失问题,缺乏对整个修复过程的精炼过程。因此,Zhang等人[16]提出了一种渐进式的图像修复方法,首先将待修复图像划分为多个重叠的区域,再使用语义分割对各个区域进行标记,最后利用区域中的语义信息来生成修复图像,但由于各阶段采用的感受野过大,对局部语义信息掌握不足,所以一些局部的纹理细节没有得到很好的还原。
综上所述,目前图像修复的深度学习网络模型需要在局部继续加强训练,例如纹理、背景图案等细节位置。受相关文献启发,本文提出了一种三阶段修复网络,由粗到细再到全局修复,各阶段采用不同大小的感受野,具体如下:a)第一阶段采用新型滤波以加深修复区域的边缘差异,提高鉴别器对缺失部分的鉴别能力,保持图像整体一致性;b)第二阶段采用上下文特征采集模块,避免普通残差块获取特征不充分,忽略上下文语义;c)第三阶段整体修复过程中,引入外部注意力机制,通过两个外部单元隐式地学习特征,考虑到不同样本之间的联系,保持语义一致性。
本文主要工作如下:a)通过边缘高斯滤波加大了修复图像两侧边缘的差异,增强了鉴别器的鉴别能力,使得修复效果更加逼真;b)强调了小的感受野在局部修复中的作用,小感受野在修复局部卓有成效,可以很好地修复图案纹理等;c)在图像修复完成后使用了基于注意力机制的全局精练网络用于消除前两个子网络之间的语义冲突。在大的结构和长距离文本信息上有着显著的效果,加强了图像生成的质量和语义一致性。
1 相关工作
1.1 单阶段修复方法
Pathak等人[11]首次将深度学习用在了图像修复中,提出了上下文编码器,基于上下文像素预测驱动的无监督的视觉特征的学习方法,利用周围的图像信息来推断缺失的部分,但是对掩膜区域的处理不足,因此不能保持局部一致性。Rumelhart等人[17]基于自编码器提出了encoder-decoder模型结构。该模型由编码器和解码器构成,编码器将输入的数据压缩成潜在空间表示,解码器学习特征并进行重构输出。这样保证了图像修复的连贯性,但是却忽略了图像的全局区域。Xie等人[18]提出了一种基于卷积神经网络的图像修复方法,使用了一个深度编码器和一个全连接解码器,使用像素周围的信息来预测缺失的像素。该方法能够在处理大量数据时实现高质量的图像修复,但在处理大的缺失区域时可能会出现一些问题。Yang等人[19]提出了一种使用卷积神经网络进行高分辨率图像修复的方法,使用多尺度神经网络来合成缺失区域的纹理,由于模型采用的是多尺度处理,所以会产生一些不连续的边缘和瑕疵,这会影响图像的质量。
单阶段图像修复通常通过局部的信息来进行修复,无法处理大范围的缺失区域,尤其处理复杂场景时,由于全局信息的缺失,算法的表现可能会受到影响。而在第一阶段选择较大的感受视野和边缘高斯滤波有助于获取和处理全文的语义信息及纹理结构。
1.2 双阶段修复方法
Yu等人[14]提出了由粗到细的修复方法,克服了从远处区域提取特征困难这一问题,在复杂纹理生成的问题上取得了成就。Peng等人[20]在分层VQ-VAE的基础上提出了multiple-solution图像修复方法。通过在离散的因变量上学习自回归分布,再将纹理和结构分开,针对结构的分布学习设计了一个条件自回归网络,针对纹理生成,提出了一个结构注意力模块。该方法在结构的一致性和纹理的真实性上得到了提升。Zheng等人[21]将修复过程分成两个步骤,先用Transformer进行全局结构和纹理的粗修复,再用CNN对细节纹理补全。该方法修复大面积缺失图像的同时很好地还原了细节的纹理结构。Zheng等人[22]又在此基础上提出了限制性卷积块来提出特征并提出了新颖的注意力感知层来自适应地平衡对可见内容和生成内容的注意力,改进后的模型在图像的保真度上得到了提高。Nazeri等人[13]提出了由边缘引导的两阶段图像修复过程,在第一阶段修复了受损区域的边缘,再将此边缘与不完整的图像一起当作下一阶段的输入。
这些由粗及细的修复方法仅仅考虑两个阶段自身的修复效果,忽略了它们之间的协同作用。在第一阶段,生成的低分辨率图像可能会存在一些不自然的细节或失真,这些问题可能会被第二阶段的修复过程所弥补,但有时也可能会导致最终生成的图像质量不够自然或真实。因此第三阶段基于注意力机制的全局精炼网络可用于消除前两个网络之间可能存在的语义冲突问题。
1.3 多阶段修复方法
Zhou等人[23]提出了一种三阶段的多同域转换的融合方法。通过参考与目标图像共享场景内容的另一个源图像来填补这个洞。该方法在宽基线和颜色差异上都实现了最先进的性能。Zhang等人[16]提出了将修复任务分成四个阶段并且使用LSTM结构来控制递进过程中的信息流通。然而这种方法不能很好地解决不规则的缺失。Guo等人[15]便在此基础上提出了全分辨率残差网络,这一设计加强了模型的泛化能力。 Li等人[24]提出的渐进式图像修复方法具有较好的修复效果和高效的修复策略,该方法使用了渐进式的修复策略,可以在生成修复图像时更加高效地利用上下文信息,提高修复效率,由于该方法是基于单张图像的修复,无法处理视频或多个相关图像的修复任务。
这些方法很少关注不同尺寸的感受野在修复过程中的影响,只关注具有大接受场的编码器-解码器生成器。然而,具有小接受域的网络对于图像绘制也十分重要,本文网络使用不同膨胀率的空洞卷积捕获不同范围内的上下文信息,使得修复的局部部分在纹理细节上更加逼真。
本文提出的三阶段网络修复采用粗到细的过程。与现有由粗到细的网络只关注接受野大的编码解码器不同,本文强调了小的感受野在图像修复中的作用。第一阶段是大感受野的全局粗修复网络,第二阶段是小感受野的局部修复网络,两者相结合在修复局部结构、纹理、长距离文本图案等场景中更加适用。第三阶段引入注意力机制以加强网络鲁棒性。
2 模型
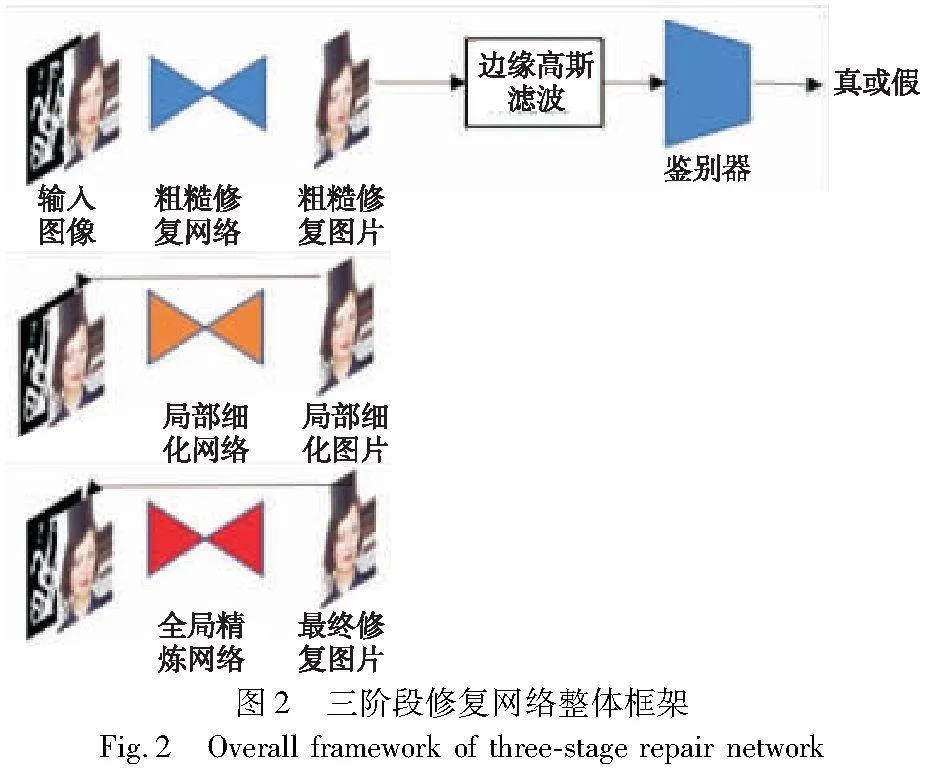
2.1 网络整体模型
本文提出的三阶段网络整体框架如图2所示。整体框架包含粗糙修复网络、局部精细网络和全局精炼网络,这三个阶段被依次连接。该框架旨在通过注重不同的修复目标,生成具有更合理的纹理结构和视觉效果的图像。
首先,使用大型U-Net生成缺失部分的整体结构,辅以对边缘更为敏感的鉴别器,使生成结果具有更自然的边缘特征和更真实的表现效果,为后续修复奠定真实前提。接下来,采用卷积神经网络在小接收域的基础上在小范围内对局部纹理进行细节化处理,以获得更真实的细节效果。最后,使用带有注意力机制的U-Net对整张图像进行全局精炼和结构调整,以达到最佳的修复效果。
2.2 融合边缘高斯滤波的粗糙修复网络
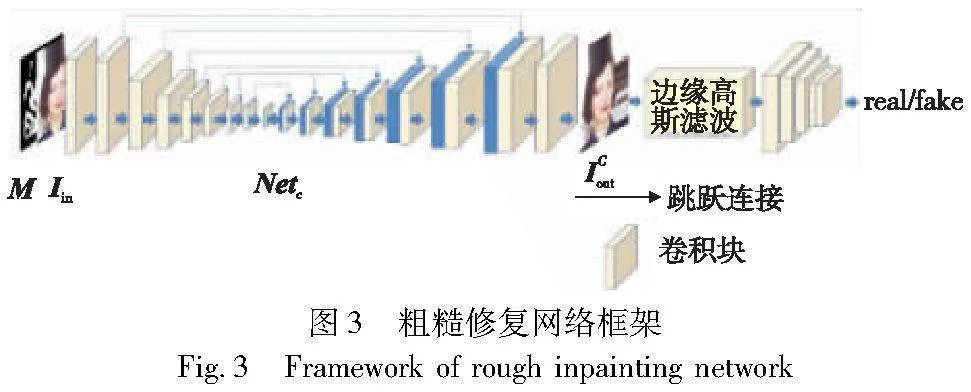
修复方法的第一阶段采用生成对抗网络(Netc)作为粗糙修复网络。该网络生成器由八个下采样层和上采样层组成。下采样层逐步减小图像尺寸,并提取高层次特征;上采样层则通过插值或反卷积操作将特征图的尺寸恢复到原始输入图像的尺寸,并生成高分辨率的图像。在多次下采样和上采样操作中,卷积神经网络逐渐提取抽象特征,生成高质量的重建图像或生成图像。编码器中的高层特征通过跳连接传递给解码器,有助于解码器更好地还原原始图像的细节信息。该方法整体框架如图3所示。通过采用大感受野,有利于保持整体结构的完整性。
该网络使用二进制掩码M描述缺失区域,并且将输入的图像记为Iin,修复后的图像记为ICout。为了增强图像的真实性并减少滤波的影响,采用基于补丁的鉴别器进行频谱归一化。该鉴别器区分每个元素的真伪,其输入包括原始图像和修复后的图像。为了优化边缘的平滑性,针对生成的图像进行了边缘高斯滤波处理。具体而言,首先生成一个大小为kernel_size且标准差为sigma的高斯核。其过程是通过创建一个从0到kernel_size-1的一维数组,并对每个值应用高斯函数来完成。所得结果数组经过除以值之和的归一化。此过程在x和y维度上重复执行,进而再生成一个二维高斯核。通过函数get_gaussian_kernel获取输入图像、核大小和x、y维度的sigma值,并创建二维高斯核,使其通道数量与输入图像相同。最后,将修复后的图像与高斯核进行卷积,将卷积后的结果输入到鉴别器中进行判别。
这个阶段的网络损失由重建损失和对抗损失组成。在该阶段,使用L1损失作为重建损失的损失函数。
其中:λh代表平衡因子。
对于GAN损失,使用最小二乘法,粗糙修复网络的损失函数和鉴别器的损失函数定义如下:
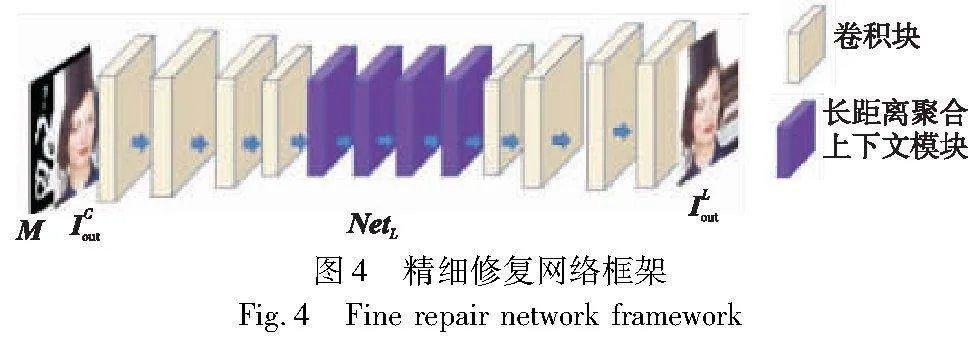
2.3 基于聚合长距离信息模块的局部精细网络
在局部细化阶段,采用卷积神经网络。局部精细网络(NetL)由两个下采样块、四个残差设计块和两个上采样块组成。由于网络的感受野较小,一些局部的结构和纹理可以通过周围的环境信息适当地修复,而不会受到远距离或未成功修复内容的影响。该方法的整体框架如图4所示。
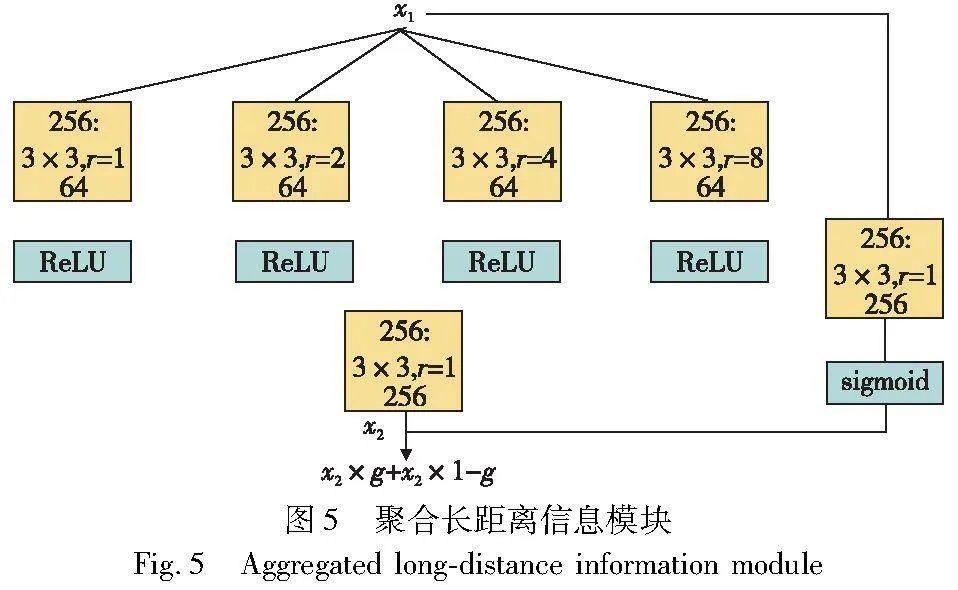
为了更好地提取上下文的信息,该阶段使用了一种新型的聚合长距离上下文信息块[18]。模型图较常用的卷积神经网络使用的残差块有如下改进:a)使用膨胀率分别为1、2、4、8的4组空洞卷积代替原残差块里固定的3×3的卷积层,这样就可以获取到不同层次的上下文特征聚集;b)使用了一组3×3的卷积层代替原本的跨层链接,并且在和聚合模块之间增加了gate门限,让模型可以自主选择是否使用聚合通道,该设计可以增加修复后图像的色彩一致性。模型图如图5所示。这个阶段的网络损失由重建损失(L1 loss)、总变分损失(TV loss)、感知损失(perceptual loss)和风格损失(style loss)组成。重建损失依然采用L1 loss,表示为
其中:λh代表平衡因子。
总变分损失(TV loss)使用的是平滑损失项,可以表示为
其中:ILmer代表ILout和M融合的图像。
感知损失和风格损失都是建立在VGG-16的基础上。VGG-16已经在ImageNet上进行了预训练,可以很好地恢复结构和纹理信息。这两种损失是作用在特征空间的层面上而非像素层面。感知损失可以表示为
其中:Euclid Math OneFApi表示特征图中第i层的预训练的VGG-16网络。
相似地,风格损失可以表示为
总的来说,精细修复阶段的损失函数为
其中:λh为6;λtv为0.1;λper为0.05;λsty为120。
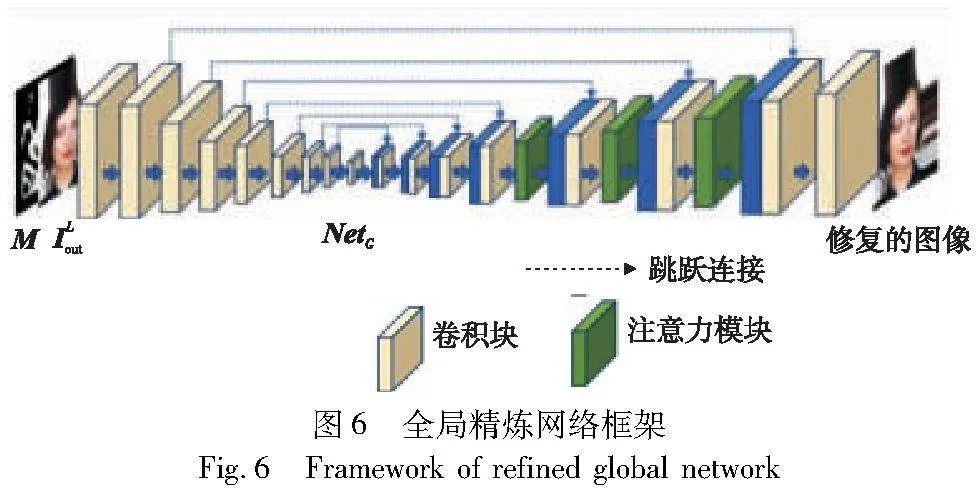
2.4 基于注意力机制的全局精炼网络
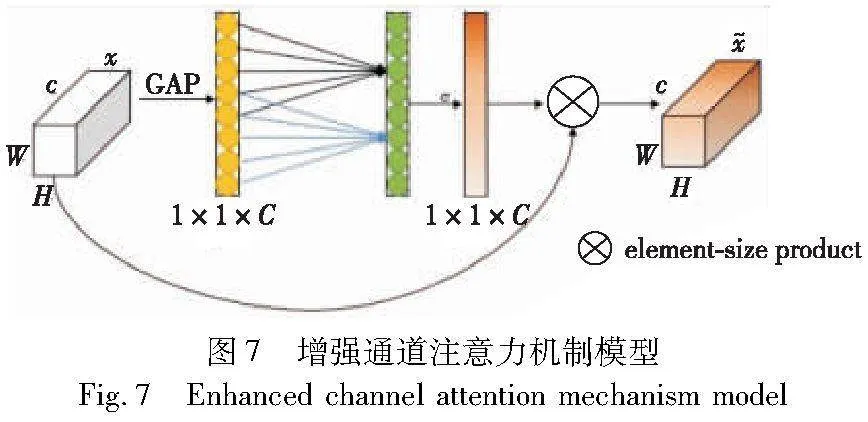
局部细化之后,复杂的纹理和结构可以得到适当修复,但是针对稍大的缺失区域,需要详细、远距离的信息进行更精细的修复。因此,本文提出了一种结合了注意力机制的全局修复网络。该网络基于U-Net的体系结构,在编码阶段与第一阶段粗糙修复相同,但在解码阶段之前每次都加入了注意力模块。该方法的整体框架如图6所示。
注意力机制在现有模型中被广泛使用,尤其是在构建上下文信息和缺失区域之间的联系时。使用的注意力机制为增强通道注意力机制(ECAAttention)[25],ECAAttention的关键思想是将通道间的信息流引导到关键通道,并且可以保留并强化每个通道的特征表达,同时过滤掉无关信息和噪声,从而提高分类和检测任务的准确性。ECAAttention通过引入可学习的一维卷积,可以自适应地调整每个通道的重要性,这使得模型可以更加准确地区分不同通道对于任务的贡献。ECAAttention同时还考虑了空间信息,以更好地捕获对象的空间分布特征。模型如图7所示。
ECAAttention模块首先使用一个1D卷积层来处理每个通道的特征,得到每个通道的重要性权重,具体公式如下:
其中:ai,c表示第c个通道上第i个空间位置的特征;Wc是1D卷积层的权重;f是激活函数;H是空间位置的个数。然后,将通道特征与权重相乘得到加权后的通道特征,具体公式如下:
zc=xc·σ(ac+ε)(13)
其中:xc是原始的通道特征;σ是sigmoid函数;ε是一个非常小的数,用于数值稳定。
为了提高通道之间的相关性,ECAAttention使用了一个自适应的扩张卷积层,即ECA模块,对加权后的通道特征进行处理,得到不同位置的加权值,具体公式如下:
其中:zi,k,c表示第c个通道上第i个空间位置经过加权后的特征;wck表示第c个通道上第k个位置的权重;K是卷积核的大小;C是通道数。
最后,将加权后的通道特征与空间注意力加权值相乘,得到最终的特征表示,具体公式如下:
yi=zi+γsizi(15)
其中:γ是可学习的缩放因子,用于控制注意力加权值的影响程度。
该网络的损失函数与精细修复阶段相同,重建损失表示为
其中:λh为平衡因子,值为6。
总变分损失为
其中:IGmer为IGout和M融合的图像。
风格损失为
全局精炼阶段的损失函数为
其中:λG为6;λtv为0.1;λper为0.05;λsty为120。
总的来说,整个网络的训练损失函数由三个子网络的损失和鉴别器的损失函数构成,可写为
3 实验
3.1 实验环境
实验均在Ubuntu 20.04平台下进行。算法基于Python 3.9,PyTorch 1.12,CUDA 11.3和cuDNN 8.2。GPU为NVIDIA GeForce RTX 3090。使用Adam算法优化模型,动量衰减指数为β1=0.5和β2=0.999。训练批次共200轮,前100轮学习率为0.000 2,后100轮线性下降至零,批量大小为4。使用的训练集、测试集和掩膜图尺寸均为256×256。
3.2 数据集
使用的数据集为CelebA、Paris StreetView和Places2三个数据集。
CelebA数据集包含了高质量的人脸图像,其中包括一些复杂的特征,如戴帽子、眼睛等装饰物品。从中选取12 000张作为训练集,3 000张作为测试集。
Paris StreetView里的图像为街景图像,如灯塔、高楼等。从中选取14 900张作为训练集,100张作为测试集。
Places2是大尺寸的场景数据集。包含了365个种类的常用场景,具有更高的复杂度。从所有类别中选取14 600张作为训练集,3 650张作为测试集。
a)PICNet[26]:一种基于嵌入式特征推理的图像修复模型,通过逐层递归地推理图像嵌入式特征,利用这些特征来恢复丢失的图像内容。
b)CTSDG[27]:一种基于深度学习的图像修复方法,能够同时处理结构和纹理信息。
c)EdgeConnect[28]:一种基于生成对抗网络的图像修复算法,它可以自适应地捕捉图像中的边缘信息并利用上下文信息进行图像修复。
d)MADF[29]:一种多尺度自适应深度学习框架,可用于高效且精确的图像修复。
e)LGNet[30]:一种基于深度学习的图像修复方法,通过学习局部和全局信息之间的关系来实现高质量图像修复。
选用的掩码为不规则掩码,为了体现不同受损率下的修复效果,根据掩码的覆盖范围将掩码分为六类,分别为1%~10%,10%~20%,20%~30%,30%~40%,40%~50%,50%~60%,并且将与PICNet、CTSDG、EdgeConnect、MADF、LGNet五种现有方法进行比较。
3.3 定量实验
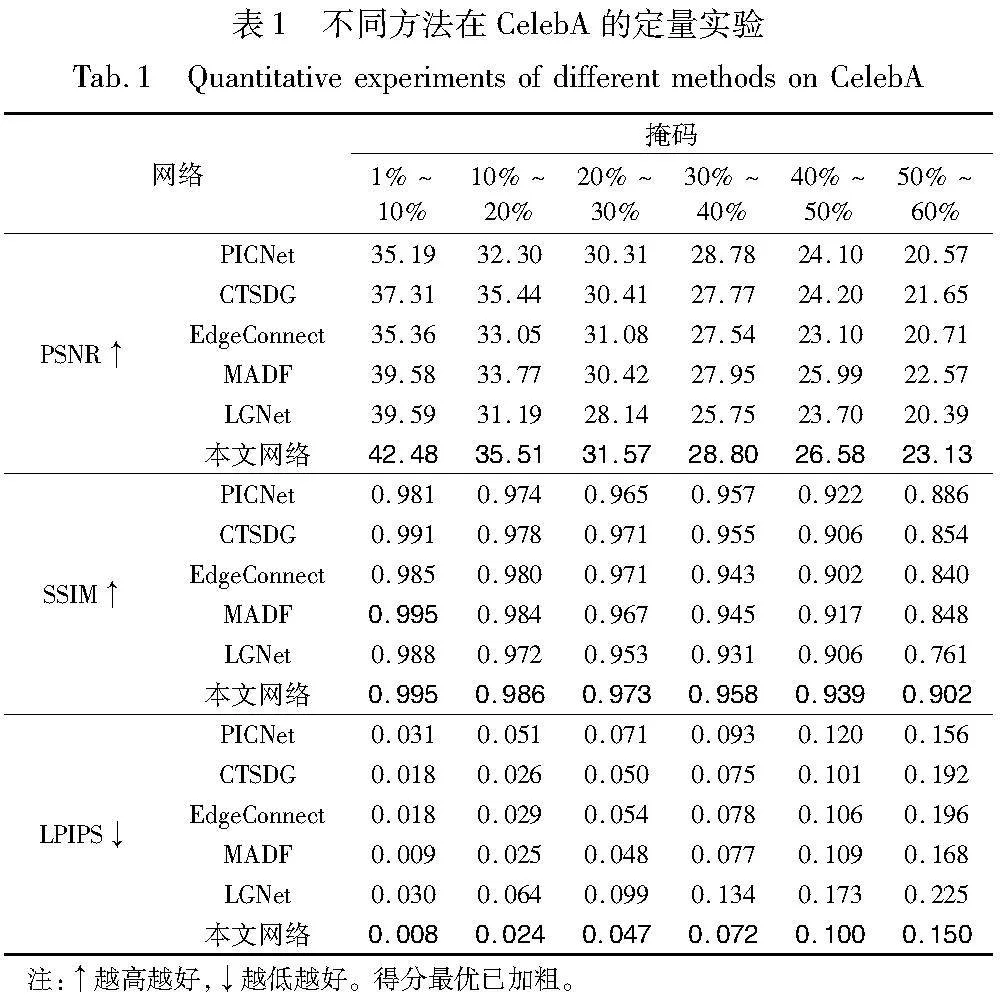
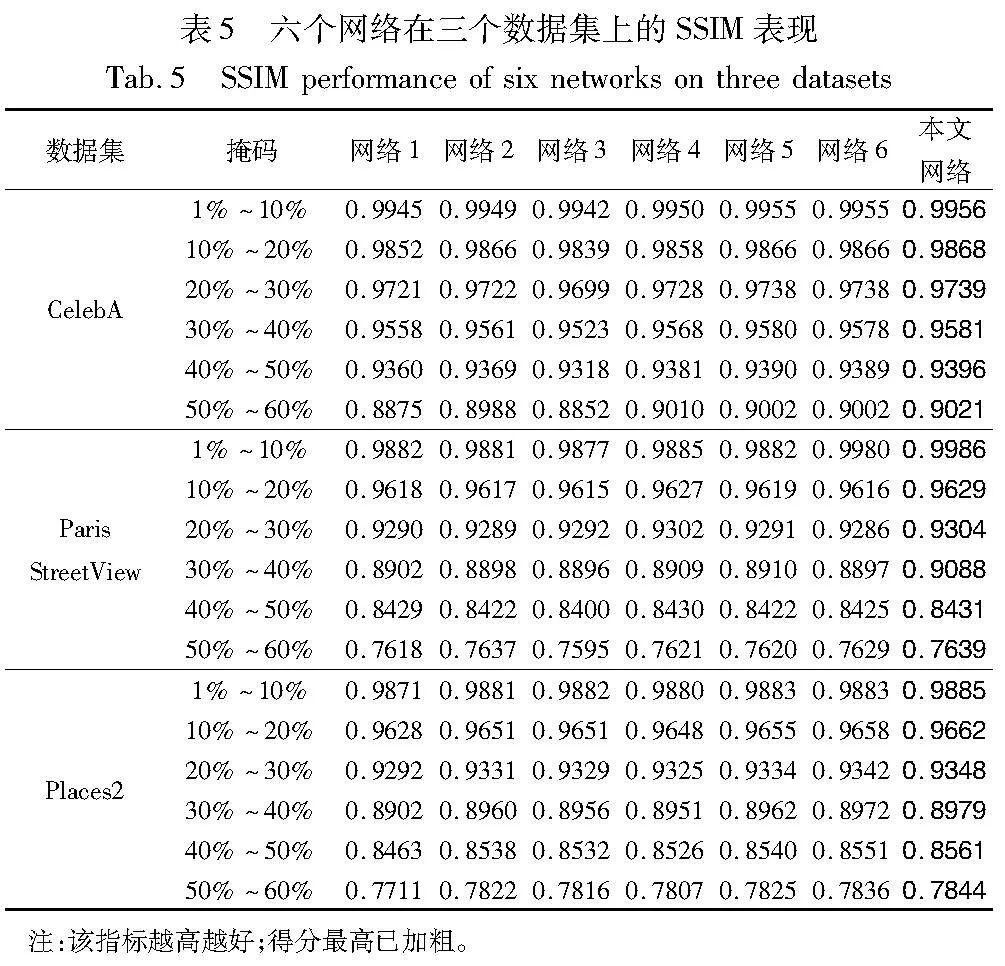
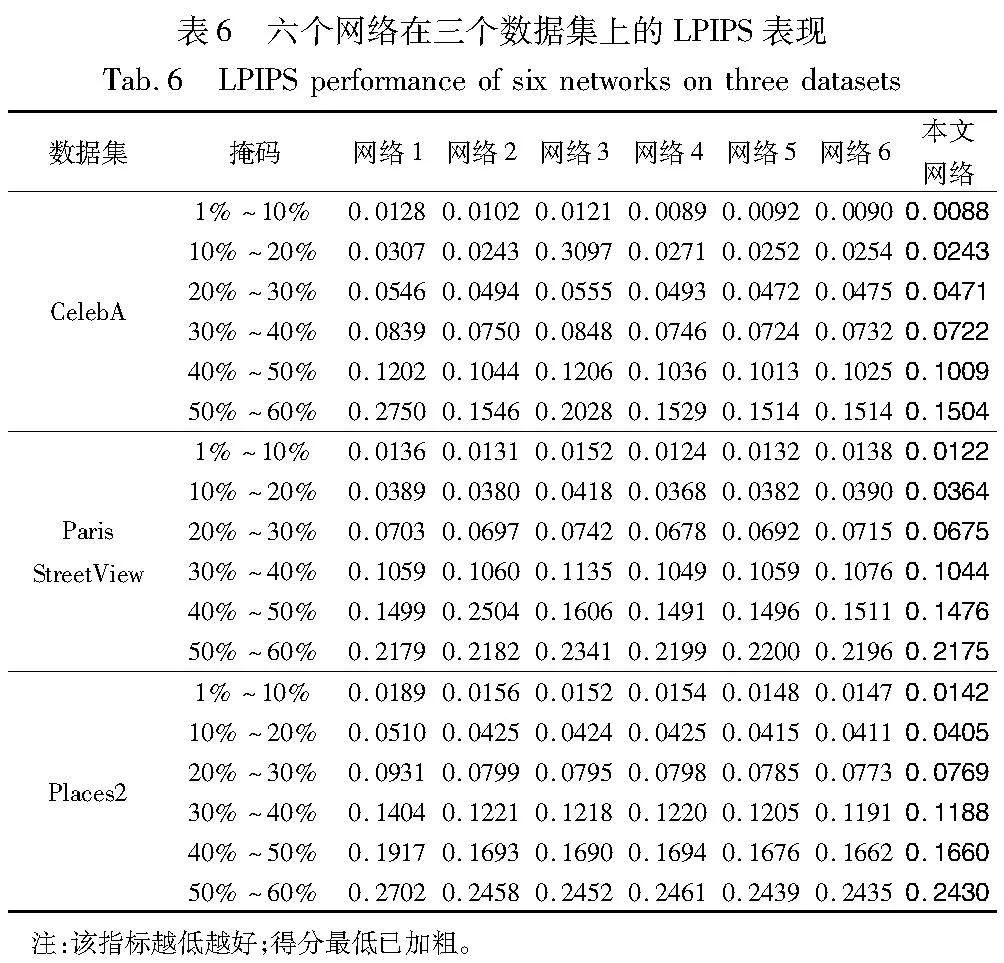
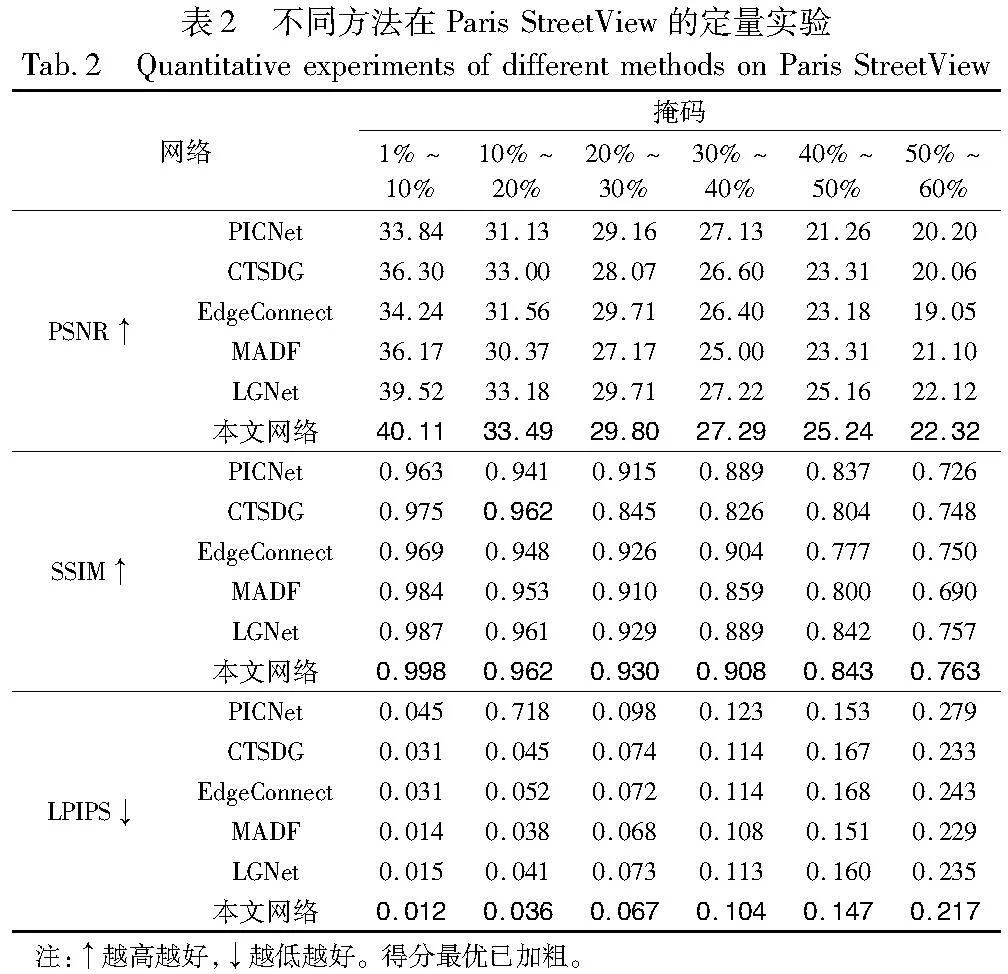
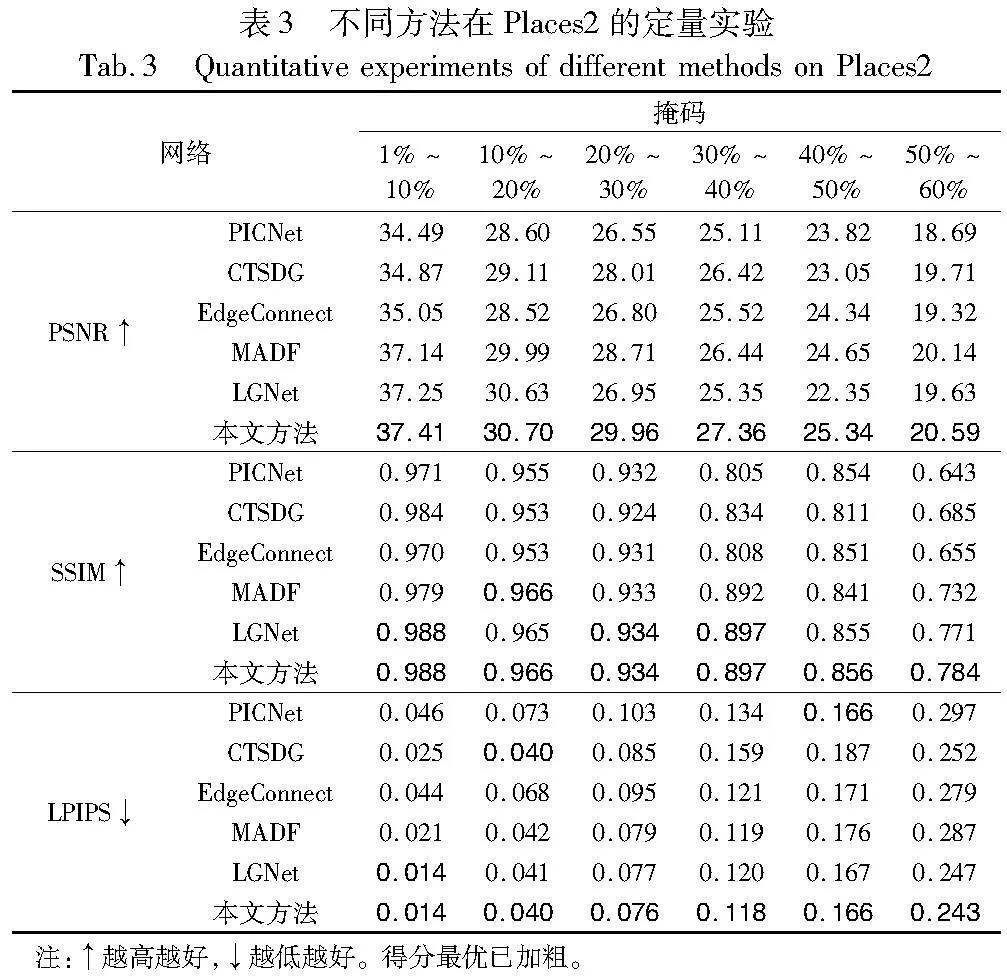
将峰值信噪比(peak signal to noise ratio,PSNR)、结构相似度(structure similarity,SSIM)和学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)作为评判标准。其中,PSNR和SSIM值越大表示修复效果越优, LPIPS值越小表示修复效果越优。CelebA、Paris StreetView和Places2数据集上的对比结果如表1~3所示。由表可见,本文网络在各项指标上的表现均优于其他网络,这说明本文网络在修复细节纹理和结构方面,及面对大面积缺失时均有良好的表现。
CelebA数据集中,各网络的修复效果均较好,其中CelebA风格效果最为统一。随着掩膜比例变大,各指标均下降,但本文网络始终表现最佳。在较简单的背景下,仅考虑边缘纹理的EdgeConnect相对于其他多阶段的网络表现较差。其中MADF是最具竞争力的网络,同样采用由粗糙到精细的架构,但缺乏最后的精炼阶段,因此与本文网络存在一定差距。
Paris StreetView数据集中,风格相对较为统一,但涵盖了更多的场景,因此具有较强的泛化性。从表中可以看出,与人脸数据集相比,各项指标均有所下降。其中同样作为三阶段修复的LGNet的竞争力最大,这验证了在面对较为复杂的纹理时,多阶段的方法更能还原一些细节。然而其在第二阶段上对上下文信息的捕获不够充分,因此修复效果不是最好。在捕获上下文信息时使用的聚合长距离上下文信息块则帮助捕获了更丰富的信息,使得其在修复效果上更胜一筹。
Places2涵盖了最多的场景,其纹理结构更加复杂,因此具有更强的泛化性。在掩膜面积较小时,LGNet表现最有竞争力;然而,当掩膜面积变大时,考虑到纹理引导的网络,例如EdgeConnect和CTSDG则表现更优。这说明在应对复杂背景时,需要充分考虑到边缘引导的作用。在第一阶段,首先通过高斯边缘滤波增强了边缘两侧的真实性,并因此在整个阶段中表现最优。
3.4 定性实验
图8展示了各个网络在CelebA、Paris StreetView和Places2(从左到右)对不规则掩膜的修复效果。从图8中可以看出,PICNet和EdgeConnect的人脸修复能力相对较差,这与表3中的相关数据相符。就面部修复结果而言,本文网络在修复鼻子、嘴巴等特征方面表现更出色。相比之下,本文网络在边缘处理方面的表现更好,例如可以恢复第三张图像中的英文以及第六张图像中的房屋结构。与MADF和LGNet相比,本文的多阶段修复更健壮、稳定。例如,可以很好地修复人脸的笑容、第四张图中栅栏后面的海报和第五张图像中高楼和电线杆的结构。
3.5 消融实验
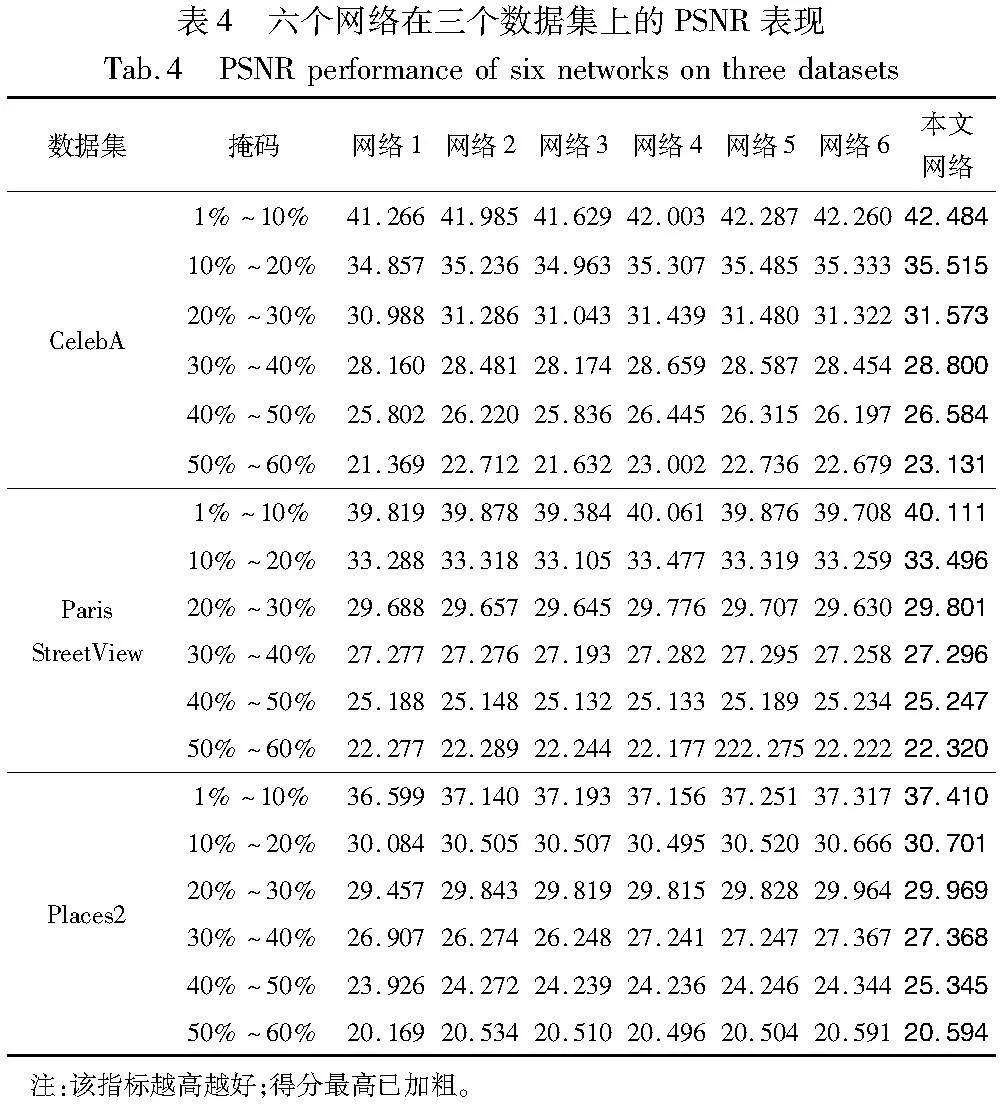
为了验证提出的三个模块的有效性,设计了如下六个网络。网络1:仅添加增强鉴别器对图像鉴别能力的滤波模块;网络2:仅添加能更好地捕获特征的聚合长距离上下文信息块的模块;网络3:仅添加能更好地集中周围信息的局部注意力机制的模块;网络4:添加滤波和聚合长距离上下文信息块的组合模块;网络5:添加滤波和局部注意力机制的组合模块;网络6:添加聚合长距离上下文信息块和局部注意力机制的组合模块。
各个网络的消融实验结果如表4~6所示。由表可见,网络4~6均与最终的网络有差距,也就是说单独的每个模块均能提升网络的整体修复结果。网络4与2相比PSNR指标显著提高,这说明引入高斯边缘滤波后,网络的修复能力可以更好地处理背景噪声。网络6与3相比SSIM得到了提高,说明聚合上下文长距离信息块可以更好地捕获周围的语义信息,使得修复完成的图像有更好的视觉效果。网络5和1对比LPIPS指标有所下降,验证了通道注意力可以使得生成的图像在感知上得到提升。
图9展示了各网络的修复可视化对比。从图像中可以看出,边缘高斯滤波在整体修复方面有着积极作用。在局部纹理结构中,聚合上下文长距离信息块的表现比较突出,例如头发、嘴角和建筑拐角落等。同时,在全局精炼阶段中,通道注意力机制也能够很好地修复前面两个阶段中的语义冲突现象。各个阶段修复的结果验证了表4~6中各项指标的变化。
4 结束语
本文提出了一种三阶段的由粗糙到精细图像修复方法。首先,在第一阶段使用具有大感受野的U-Net进行粗糙修复,并且设计了可以通过滤波增强鉴别能力的鉴别器来监督生成整体完整性更好的图像。其次,在第二阶段使用了融入聚合上下文长距离信息块的CNN模块,该阶段对图像的局部纹理和结构进行了进一步的细化。最后,在第三阶段使用了在解码阶段融入局部注意力的U-Net来提升图像的整体完整性。对比实验表明,该三阶段的修复方法与现有网络对比可以生成质量更好的图像,效果更加逼真。同时,消融实验也表明了各个模块的有效性。
在实验过程中,当图像包含多个复杂对象或者多个图像层次结构时,图像修复就变得更加困难。而且图像修复需要大量的图像数据,这些数据应该具有高质量和广泛的分布,以便算法能够学习到足够的信息。未来的工作重心在于解决这些挑战,提高图像修复算法的性能和可靠性。为此,可以将多个传感器或来源的数据进行整合,实现多模态的图像修复,从而提高修复的准确度和可靠性。也可以通过使用更少的人工标注数据,采用弱监督学习的方法来提高图像修复算法的性能。还可以针对不同的应用场景设计不同的图像修复算法,未来可以开发面向特定应用场景的图像修复算法。
参考文献:
[1]Bertalmio M, Sapiro G, Caselles V, et al. Image inpainting[C]//Proc of the 27th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 2000: 417-424.
[2]Wan Ziyu, Zhang Bo, Chen Dong, et al. Old photo restoration via deep latent space translation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2022,45(2): 2071-2087.
[3]徐辉, 康金梦, 张加万. 基于特征感知的数字壁画复原方法[J]. 计算机科学, 2022,49(6): 217-223. (Xu Hui, Kang Jinmeng, Zhang Jiawan. Digital mural inpainting method based on feature perception[J]. Computer Science, 2022, 49(6): 217-223.)
[4]Zeng Yanhong, Fu Jianlong, Chao Hongyang, et al. Aggregated contextual transformations for high-resolution image inpainting[J]. IEEE Trans on Visualization and Computer Graphics, 2023,29(7): 3266-3280.
[5]Li Haodong, Luo Weiqi, Huang Jiwu. Localization of diffusion-based inpainting in digital images[J]. IEEE Trans on Information Forensics and Security, 2017,12(12): 3050-3064.
[6]Ghorai M, Samanta S, Mandal S, et al. Multiple pyramids based image inpainting using local patch statistics and steering kernel feature[J]. IEEE Trans on Image Processing, 2019,28(11): 5495-5509.
[7]Getreuer P. Total variation inpainting using split Bregman[J]. Image Processing on Line, 2012, 2: 147-157.
[8]Criminisi A, Pérez P, Toyama K. Region filling and object removal by exemplar-based image inpainting[J]. IEEE Trans on Image Processing, 2004,13(9): 1200-1212.
[9]Barnes C, Shechtman E, Finkelstein A, et al. PatchMatch: a randomized correspondence algorithm for structural image editing[J]. ACM Trans on Graphics, 2009,28(3): article No. 24.
[10]Chan T F, Shen Jianhong. Variational image inpainting[J]. Communications on Pure and Applied Mathematics, 2005,58(5): 579-619.
[11]Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders: feature learning by inpainting[C]//Proc of Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEOQplTBmtrkHQdeVU+sls4umGuDALjQFebdvKE98uAU=EEE Press, 2016: 2536-2544.
[12]Zeng Yanhong, Fu Jianlong, Chao Hongyang, et al. Learning pyramid-context encoder network for high-quality image inpainting[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 1486-1494.
[13]Nazeri K, Ng E, Joseph T, et al. EdgeConnect: structure guided image inpainting using edge prediction[C]//Proc of IEEE/CVF International Conference on Computer Vision Workshops. Piscataway, NJ: IEEE Press, 2019: 3265-3274.
[14]Yu Jiahui, Lin Zhe, Yang Jimei, et al. Generative image inpainting with contextual attention[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 5505-5514.
[15]Guo Zongyu, Chen Zhibo, Yu Tao, et al. Progressive image inpain-ting with full-resolution residual network[C]//Proc of the 27th ACM International Conference on Multimedia. New York: ACM Press, 2019: 2496-2504.
[16]Zhang Haoran, Hu Zhenhen, Luo Changzhi, et al. Semantic image inpainting with progressive generative networks[C]// Proc of the 26th ACM International Conference on Multimedia. New York: ACM Press, 2018: 1939-1947.
[17]Rumelhart D E, McClelland J L. Parallel distributed processing: explorations in the microstructure of cognition: foundations[M]. Cambridge, MA: MIT Press, 1987: 318-362.
[18]Xie Junyuan, Xu Linli, Chen Enhong. Image denoising and inpain-ting with deep neural networks[C]//Proc of the 25th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2012: 341-349.
[19]Yang Chao, Lu Xin, Lin Zhe, et al. High-resolution image inpainting using multi-scale neural patch synthesis[C]//Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 4076-4084.
[20]Peng Jialun, Liu Dong, Xu Songcen, et al. Generating diverse structure for image inpainting with hierarchical VQ-VAE[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 10770-10779.
[21]Zheng Chuanxia, Song Guoxian, Cham T J, et al. High-quality pluralistic image completion via code shared VQGAN[EB/OL]. (2022-04-05). https://arxiv.org/abs/2204.01931.
[22]Zheng Chuanxia, Cham T J, Cai Jianfei, et al. Bridging global context interactions for high-fidelity image completion[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 11502-11512.
[23]Zhou Yuqian, Barnes C, Shechtman E, et al. TransFill: reference-guided image inpainting by merging multiple color and spatial transformations[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 2266-2267.
[24]Li Jingyuan, He Fengxiang, Zhang Lefei, et al. Progressive reconstruction of visual structure for image inpainting[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 5961-5970.
[25]Wang Qilong, Wu Banggu, Zhu Pengfei, et al. ECA-NET: efficient channel attention for deep convolutional neural networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 11531-11539.
[26]Zheng Chuanxia, Cham T J, Cai Jianfei. Pluralistic image completion[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 1438-1447.
[27]Guo Xiefan, Yang Hongyu, Huang Di. Image inpainting via conditional texture and structure dual generation[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 14114-14123.
[28]Nazeri K, Ng E, Joseph T, et al. EdgeConnect: generative image inpainting with adversarial edge learning[EB/OL]. (2019-01-11). https://arxiv.org/abs/1901.00212.
[29]Zhu Manyu, He Dongliang, Li Xin, et al. Image inpainting by end-to-end cascaded refinement with mask awareness[J]. IEEE Trans on Image Processing, 2021, 30: 4855-4866.
[30]Quan Weize, Zhang Ruisong, Zhang Yong, et al. Image inpainting with local and global refinement[J]. IEEE Trans on Image Processing, 2022,31: 2405-2420.
