基于可逆神经网络的神经辐射场水印
2024-07-31孙文权刘佳董炜娜陈立峰钮可
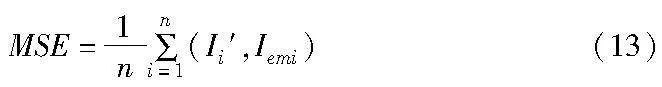
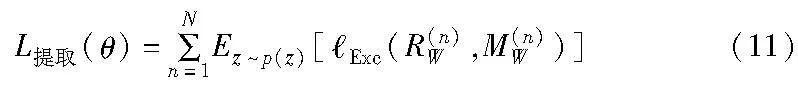

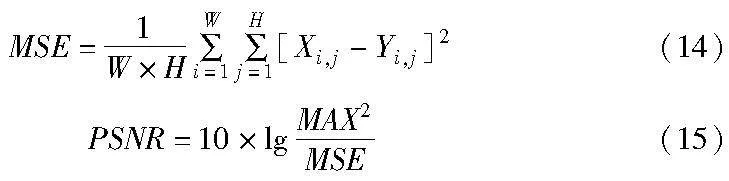
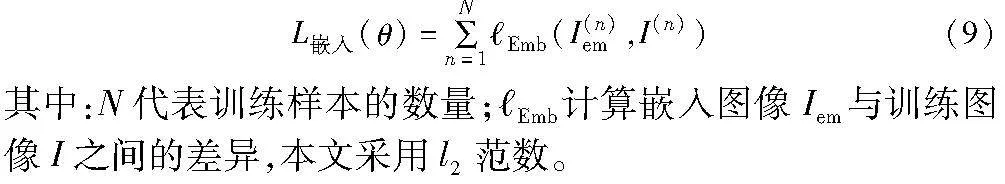
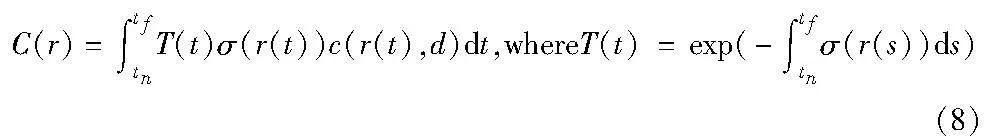
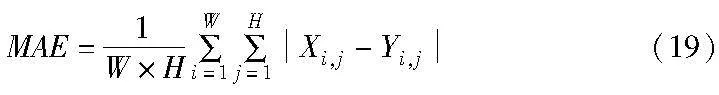



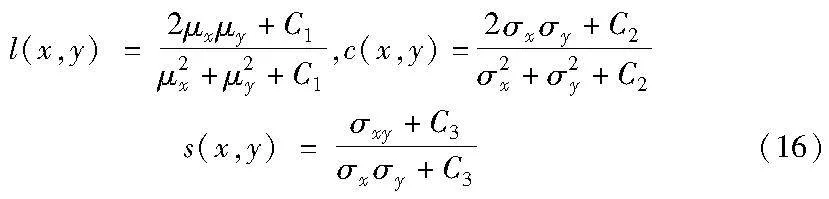
摘 要:针对面向隐式表达的神经辐射场的3D模型的版权问题,将神经辐射场水印的嵌入与提取视为一对图像变换的逆问题,提出了一种利用可逆神经网络水印保护神经辐射场版权方案。利用二维图像的水印技术以实现对三维场景的保护,通过可逆网络中的正向过程在神经辐射场的训练图像中嵌入水印,利用逆向过程从神经辐射场渲染出的图像提取水印,实现对神经辐射场以及三维场景的版权保护。但神经辐射场在渲染过程中会造成水印信息丢失,为此设计了图像质量增强模块,将渲染图像通过神经网络进行恢复然后再进行水印提取。同时在每个训练图像中均嵌入水印来训练神经辐射场,实现在多个视角下均可提取水印信息。实验结果表明了提出的水印方案达到版权保护的目的,证明方案的可行性。
关键词:可逆神经网络; 数字水印; 神经辐射场; 渲染
中图分类号:TP309.2 文献标志码:A
文章编号:1001-3695(2024)06-035-1840-05
doi:10.19734/j.issn.1001-3695.2023.10.0433
Watermarking for neural radiation fields by invertible neural network
Abstract:Aimin at the copyright problem surrounding 3D models of neural radiation fields focused on implicit representation, this paper tackled this issue by considering the embedding and extraction of neural radiation field watermarks as inverse problems of image transformations,and proposed a scheme for protecting the copyright of neural radiation fields using invertible neural network watermarking. This scheme utilized 2D image watermarking technology to safeguard 3D scenes. In the forward process of the invertible network, the watermark was embedded in the training image of the neural radiation field. In the reverse process, the watermark was extracted from the image rendered by the neural radiation field. This ensured copyright protection for both the neural radiation field and the 3D scene. However, the rendering process of the neural radiation field may result in the loss of watermark information. To address this, the paper introduced an image quality enhancement module. This module utilized a neural network to recover the rendered image and subsequently extract the watermark. Simultaneously, the watermark was embedded in each training image to train the neural radiation field. This enabled the extraction of watermark information from multiple viewpoints. Experimental results demonstrate that the watermarking scheme outlined in this paper effectively achieves copyright protection and highlights the feasibility of the proposed approach.
Key words:invertible neural network; digital watermarking; neural radiation field(NeRF); rendering
0 引言
隐式神经表示(implicit neural representation,INR)也称为基于坐标的表示,是一种对各种信号进行参数化的方法。传统的信号表示通常是离散的,而隐式神经表示将信号参数化为一个连续函数。当前,INR最典型的应用是神经辐射场(NeRF)[1] ,NeRF是一种面向三维隐式空间建模的深度学习模型,使用神经网络隐式地表示3D场景中每个点的颜色和密度函数。目前NeRF的研究致力于3D内容表示更高质量[2~5]、更快渲染[6~8]和稀疏视图重建[9~12]等工作。随着NeRF在3D内容表示方面的不断进步,面向隐式表达的神经辐射场3D模型的版权保护问题也成为一个亟需解决的课题。
传统3D模型的水印主要分为基于3D网格模型水印算法[13~17]和基于3D点云模型的水印算法。基于3D网格模型水印算法,采用多分辨率框架对目标三角形或多边形网格进行小波分解或傅里叶变换,然后通过修改网格模型的拓扑或几何特征或者在网格顶点之间建立相关性函数实现水印嵌入。基于3D点云模型水印算法[18]首先建立点云之间同步关系,然后根据径向半径将模型分成球环,并将水印重复插入到每个球环的顶点中以实现水印的嵌入。NeRF的3D模型表示与传统的3D模型不同,NeRF没有使用传统意义上的几何结构,而是通过神经网络直接学习并生成逼真的渲染结果,它本质上是对3D场景进行隐式表达的神经网络。因此传统的3D模型水印算法无法应用于对神经辐射场的水印。实际上,针对神经网络的版权保护,即神经网络水印已经成为安全领域一个重要的研究方向。神经网络的水印主要分为白盒水印、黑盒水印、无盒水印和脆弱神经网络水印四种。在白盒水印方案中[19],验证者在验证网络的版权时可以进入网络的内部并访问权重等信息;黑盒水印方案[20]适用于验证者无法进入网络内部而只能通过远程API接口调用网络的情况;无盒水印[21]主要用于生成式网络的版权认证,其策略是训练网络使得所生成的图像包含水印信息,验证者可以直接从生成的图像验证版权;脆弱水印[22]不同于以上三种,它根据水印被破坏的情况来检测网络的功能是否被恶意窜改,例如是否有注入后门等行为。
未来人们将会类似分享图像与视频一样,通过网络分享自己捕获的3D内容,为了保护作者在网络分享供他人欣赏的NeRF及3D场景的版权,防止他人在未经作者本人允许的情况下以自己的名义发布到网络上,StegaNeRF[23]首次建立起神经辐射场和信息隐藏的关系。采用两步训练法将秘密信息嵌入在网络不重要的权重参数中,确保从NeRF渲染出的图像包含水印信息,利用提取网络对渲染图像进行水印信息的提取。但StegaNeRF直接修改网络参数的方法会影响NeRF自身的3D内容表示能力,降低渲染出的图像质量。目前游戏、电影制作和平面设计等新媒体,需要从3D模型的2D渲染中检索信息,因此保证渲染图像的质量尤为重要。针对此问题本文提出了一种全新的利用可逆神经网络水印保护神经辐射场的方案,该方案不对NeRF网络进行修改,即不会影响网络的3D内容表示能力。而是通过借助图像水印技术,实现对NeRF模型的保护。该方案首先利用可逆神经网络的正向网络水印算法对用于训练NeRF的训练集中的每个图像分别嵌入水印信息。接着利用NeRF模型进行3D建模。版权验证方可以利用一个训练好的图像质量增强网络对将NeRF渲染出的图像进行图像恢复,以抵消NeRF渲染带来的图像质量的影响。最后验证方利用可逆网络的逆向过程,即提取网络提取出嵌入的水印信息。在黑盒场景下,一旦怀疑3D模型未经授权被他人使用,只要与训练集相同角度下验证方均可提取出水印信息验证网络版权。
1 本文方法
1.1 方案框架
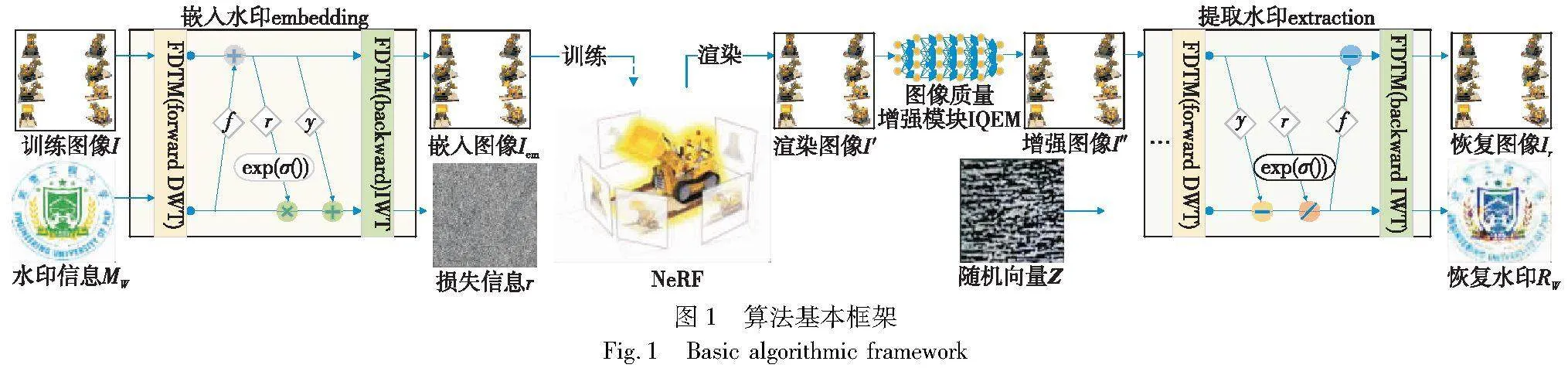
本文算法框架如图1所示,包含频域变换模块、可逆模块、神经辐射场和图像质量增强块组成。在可逆神经网络水印中嵌入与提取为一对逆过程:
Iem=H(I,MW)(1)
(Ir,RW)=H-1(QEM(NeRF(Iem)))(2)
其中:H(·)为正向嵌入水印过程;H-1(·)为反向提取水印过程。在正向嵌入水印过程中,训练图像I与水印信息MW作为输入,首先对其进行离散小波变换DWT将其分解成高频与低频小波子带输入进可逆神经网络中。经过可逆神经网络输出再次进行逆小波变换IWT生成嵌入图像Iem及损失信息r。其中需对所有用于训练NeRF的图像均执行上述操作,保证最终可以从训练集中的每个角度均可提取水印信息。将生成的嵌入图像Iem输入用于训练NeRF模型,生成渲染图像I′。在反向提取水印过程中,首先将渲染图像向输入图像质量增加模块IQEM中得到I″以抵消NeRF渲染过程中导致的失真影响。在反向提取水印过程中,由于网络的可逆性,反向提取过程需要引入一个随机向量Z。向量Z是从一个任意高斯分布中随机抽取的,该分布应与r的分布相同,通过在训练时从后面表示的提取损失学习得到。将随机向量Z及质量增强的渲染图像I″通过频域变换以及可逆神经网络处理生成恢复水印RW和恢复图像Ir。
1.2 网络结构
1.2.1 频域变换模块
水印图像嵌入在像素域容易导致纹理复制伪影和颜色失真[24,25]。相比于像素域,频域和高频域更适合于嵌入水印。本文采用频域变换模块(frequency domain transform module,FDTM)将图像在进行可逆变换前分成低频和高频小波子带,其中高频子带包含图像细节,低频子带则包含图像的整体特征,使网络能更好地将水印信息融合到载体图像中。相比于在原始图像域直接操作,小波变换具有较好的视觉保真度,只在少数子带中嵌入水印信息,对图像整体的影响相对较小,一般难以察觉。此外,小波良好的重构特性[26]有助于减少信息损失,提高水印嵌入能力。在图像进入可逆块之前,将其输入进FDTM,经过DWT将尺寸(B,C,H,W)的特征图转换为(B,4C,H/2,W/2),其中B为批量大小,H为高度,W为宽度,C为通道数。DWT可以降低计算成本,这有助于加速训练过程。在经过最后一个可逆块之后,将特征图(B,4C,H/2,W/2)输入进FDTM进行IWT将特征图大小恢复成(B,C,H,W)生成嵌入图像Iem。
1.2.2 可逆块
在一个可逆的网络结构中,将图像水印提取建模为图像水印嵌入的反向过程,只需对网络进行一次训练,就可以得到水印嵌入和提取的所有网络参数。利用可逆神经网络的优势,如图1所示,隐藏过程和恢复过程具有相同的子模块,共享相同的网络参数,只是信息流方向相反。本文网络结构有8个结构相同的可逆块,构造如下:对于正向过程中的第L个隐藏块,输
在反向过程中,与正向过程信息流方向相反,先经过第l+1层再经过第l层。最后经过第一层可逆变换以后,再对其进行逆小波变换(IWT)得到恢复图像Ir和恢复水印RW。
1.2.3 神经辐射场
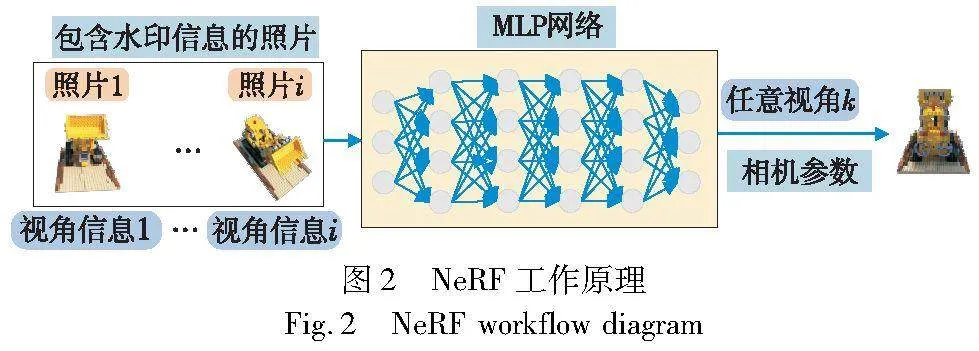
神经辐射场是一种用于生成三维场景的神经网络模型。它的网络结构由多层感知器构成,用于对场景的表面进行编码,如图2所示。
在神经辐射场模型中,输入图像的每个像素位置都可以表示为场景中的三维坐标点,从而准确地定位和渲染场景中的物体。NeRF中输入空间点的3D坐标位置x=(x,y,z)和方向d=(θ,),输出空间点的颜色c=(r,g,b)和对应位置(体素)的密度σ。
FΘ:(x(x,y,z),d(θ,Φ))→(c(r,g,b),σ)(7)
NeRF输入一系列有限的离散的图片和对应视角的相机参数生成一个连续的静态三维场景,并可以从无穷个角度来渲染生成新视角图片。体渲染是一个三维到二维的建模过程,利用三维重建得到的3D点的像素值c和体密度σ,沿着观测方向上的一条射线进行像素点采样加权叠加得到最终的2D图像像素值。
其中:r(t)为根据相机光心位置o及视角方向d得到的一条射线r(t)=o+td;T(t)表示该射线从近端tn到远端边界tf这段路径上的累计透光度。本文基于NeRF的这一特点,可以随机选择相机参数从任意视角提取水印,实现对NeRF版权的保护。
1.2.4 图像质量增强模块
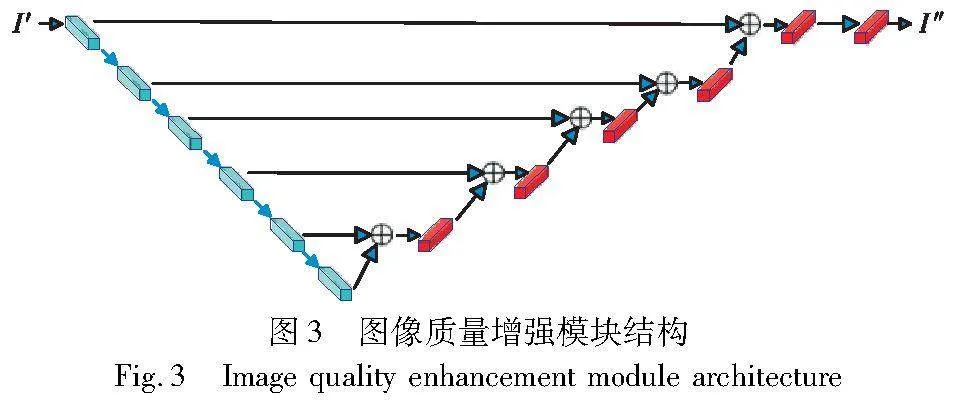
在反向过程提取水印之前,为了消除NeRF渲染过程中带来的失真变化的影响,本文设置了一个图像质量增强模块(image quality enhancement module,IQEM),采用残差卷积编解码网络[27],如图3左边6个是卷积编码器,提取失真的图像I′不同层次的特征信息,然后把特征输入右边的反卷积解码器同时输入的还有上一层传过来的残差,把最终结果叠加到原始图像上去就完成了图像的修复。通过在水印提取过程中加入IQEM,使得渲染图像I′在进入可逆神经网络之前被预处理确保向后传递的输入中能够与嵌入图像Iem足够相似,使可逆神经网络能够更完整地提取出水印信息。
1.3 损失函数
本文提出的与网络模型训练相关的损失主要由四部分组成:
a)嵌入损失L嵌入。嵌入损失的目的是保证生成的嵌入图像Iem与训练图像I不可区分:
b)低频小波损失L低频。文献[28]验证了嵌入在高频分量中的水印信息比嵌入在低频分量中的水印信息更不容易被察觉。为了保证更高的视觉保真度,最小化由于水印信息的嵌入对图像整体的影响,让水印信息尽可能嵌入在图像的高频区域,本文采用了训练图像I与嵌入图像Iem的低频子带的损失约束。
c)提取损失L提取。为保证提取出的恢复水印RW与嵌入的水印信息MW的一致性。最小化恢复水印RW与嵌入的水印信息MW之间的差异,提升模型的水印提取准确率。
其中:N代表训练样本的数量;Exc计算水印信息MW与恢复水印RW之间的差异。随机向量z采样的过程是随机的。
可逆神经网络的总损失函数是嵌入损失、低频小波损失和提取损失的加权求和:
L总计(θ)=λ1L嵌入+λ2L低频+λ3L提取(12)
在训练过程中,首先将λ2设为0,即不考虑L低频对网络的影响直接对网络模型进行预训练,使网络模型先获得基本的嵌入-提取能力。然后逐渐添加L低频约束项,进一步优化网络模型将水印信息嵌入在训练图像的高频区域,使得最小化由于水印信息的嵌入对图像整体的影响。
d)图像质量增强模块的损失MSE。为了保证水印的嵌入不对原始的2D图像内容产生破坏,本文的图像质量增强模块与可逆神经网络的训练是独立的,图像质量增加模块的损失采用MSE来约束,目的是保证由NeRF渲染出的图像I′能够恢复成由可逆神经网络生成的嵌入图像Iem来抵抗渲染过程中导致的图像水印破坏与丢失。
其中:I′i为第i个渲染图像;Iemi为第i个水印图像。
2 实验结果及分析
2.1 实验设置
本文网络模型使用PyTorch平台,CUDA版本为11.6,GPU为NVIDIA GeForce RTX2070。本实验使用NeRFSynthetic的Lego、hotdog、chair等数据集,引用NeRF[1]源代码进行训练得到3D场景。其中利用可逆神经网络只对训练的数据集进行水印嵌入,本文采用的可逆神经网络结构在HiNet[29]基础上进行修改。由于DIV2K数据集是一个具有多样性、高分辨率、真实性的数据集。使用DIV2K[30]训练数据集(800张图像,分辨率1024×1024)用于训练可逆神经网络模型。使用DIV2K验证数据集(100张图像,分辨率1024×1024)用于验证网络模型的效果。使用DIV2K测试数据集(100张图像,分辨率1024×1024)用于测试网络模型的效果。使用Adam优化器,λ1=5,λ2=0.5,λ3=1,learning rate=1×10-4.5,batch size=2来训练网络模型。整个网络模型可逆块数量为8,每个块分别使用3个包含7层卷积块的DenseNet块作为f(·)、r(·)和y(·)。
2.2 评价指标
本文采用峰值信噪比(peak signal to noise ratio,PSNR)、结构相似性(structural similarity,SSIM)、均方根误差(root mean square error,RMSE)和平均绝对值误差(mean absolute error,MAE)四个度量标准来衡量网络模型的水印嵌入以及提取能力。
PSNR通过均方差(mean square error,MSE)进行定义,给定两个图像大小为W×H的图像X、Y:
其中:Xi,j和Yi,j指的是图像X、Y分别在(i,j)位置的像素值;MAX代表图像点的最大像素值;PSNR值越大表示失真越小。
SSIM也是一种图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。
其中:μx、σx分别为图像X的均值和方差;μy、σy分别为图像Y的均值和方差;σxy为X和Y的协方差;C1、C2、C3为常数,通常取C1=(K1×L)2,C2=(K2×L)2,C3=C2/2,一般地K1=0.01,K2=0.03,L=255,则
SSIM(X,Y)=l(x,y)×c(x,y)×s(x,y)(17)
SSIM取值为[0,1],其数值越大图像失真越小。
RMSE表示预测值和观测值之间差异(称为残差)的样本标准差,相当于L2范数,对数据中的异常值较为敏感。
MAE表示预测值和观测值之间绝对误差的平均值,相当于L1范数。
2.3 嵌入图像的不可感知性
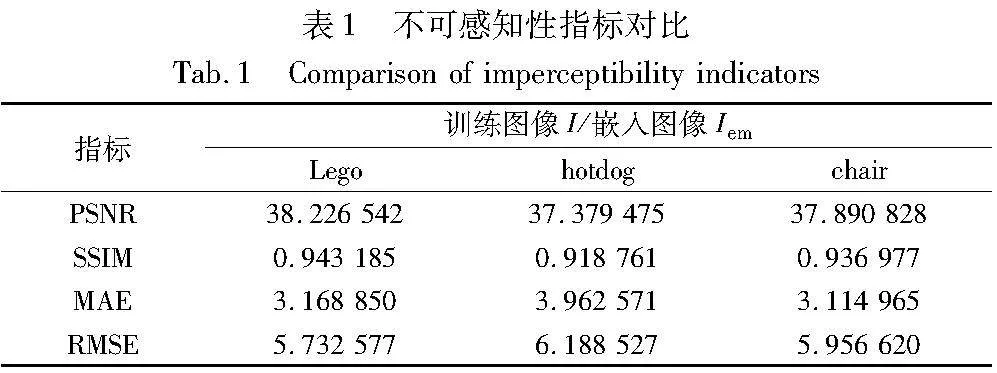
可逆网络水印方案(IWNeRF),能够实现盲水印,即训练图像I应与嵌入图像Iem之间的失真率尽可能小。本文采用四种指标PSNR、SSIM、MAE和RMSE,来评价本文方法的不可感知性。将100张训练图像I与生成的嵌入图像Iem进行对比,如表1所示,实验数据表明IWNeRF能够实现盲水印。同时根据图4显示说明通过对三个数据集Lego、hotdog和chair的图像嵌入水印,对比训练图像I与嵌入图像Iem发现在视觉效果上无法感知是否在训练图像中嵌入过水印信息,实验表明通过本文方法嵌入的水印是不可感知的,达到实现盲水印的目的。
2.4 水印提取的准确性
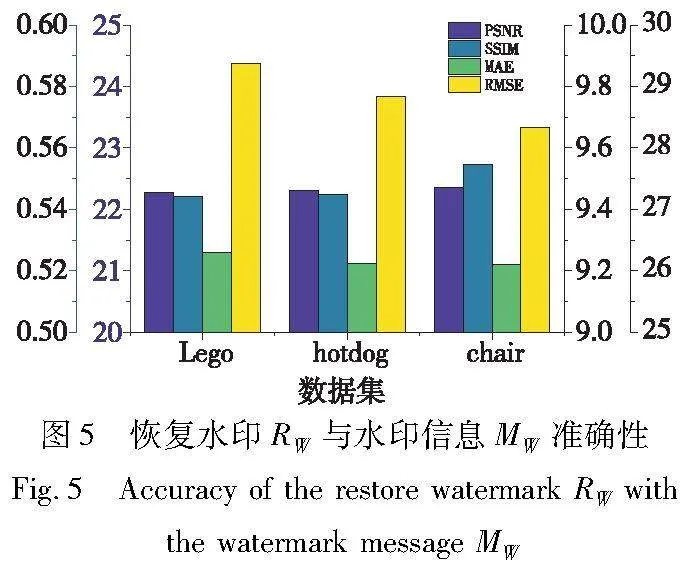
IWNeRF通过正向可逆神经网络对Lego、hotdog和chair三个数据集将水印信息MW嵌入,然后利用NeRF进行训练,接着对三维场景进行渲染以得到该视角下的图像,而后将渲染出的图像经过图像质量增强模块处理,最后通过反向可逆神经网络提取出恢复水印RW。提取出的水印信息RW与原始水印信息MW采用四种指标评价准确性。如图5所示,100张图像每个指标的平均值、PSNR均达到22 dB以上,SSIM约为0.55,MAE约为9.2,RMSE约为29。
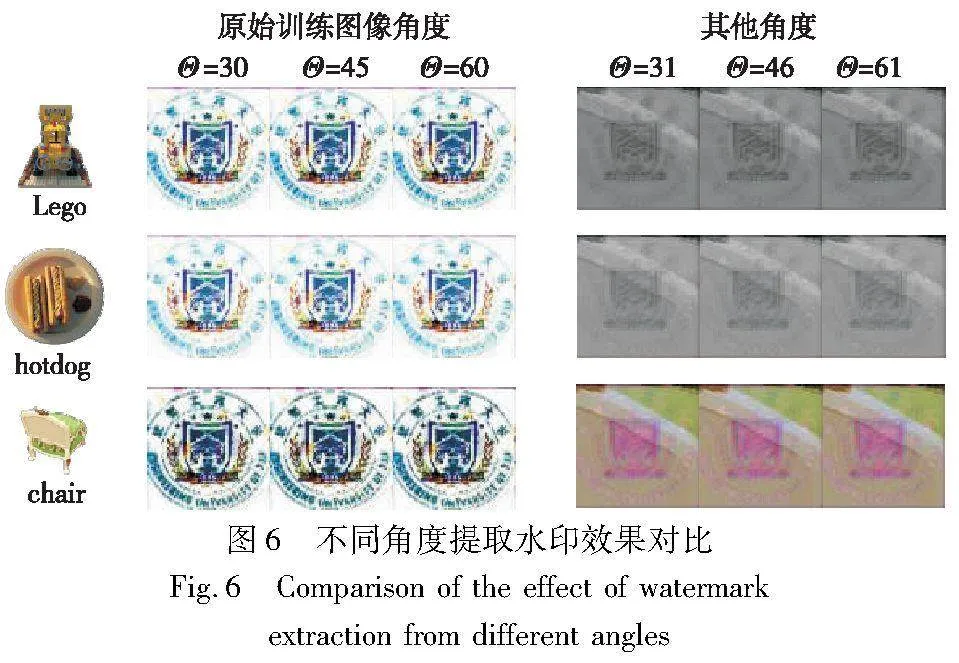
IWNeRF在Lego、hotdog和chair三个数据集对原始训练图像角度及非原始训练图像角度分别进行了水印提取。影响图像角度的两个参数Θ和Φ,本文通过固定Φ调整Θ来控制角度变化。在原始角度Θ=30、Θ=45和Θ=60的基础上对视角+1进行偏移,验证选择角度与原始训练角度不同时是否可以提取出水印信息。实验结果如图6所示,当选取角度与原始训练图像角度相同时,可以提取水印信息,但选取角度为非原始训练图像角度即其他角度则无法准确提取水印信息。
2.5 图像质量增强模块
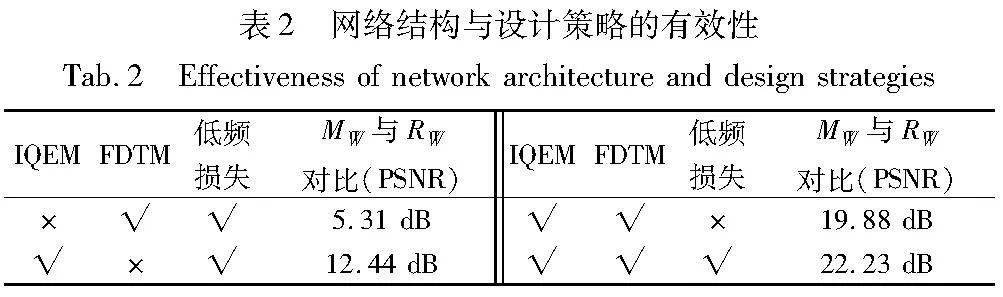
传统的深度学习图像鲁棒水印技术,如HiNet[29]、ISN[31]等不能直接适用于本文的任务,它们依赖可逆性且没有考虑图像在NeRF渲染过程中图像中嵌入的水印容易被破坏,因此IWNeRF在提取水印操作之前增加了图像质量增强模块,以抵消NeRF渲染带来的影响。通过增加IQEM结构,使得MW和RW的PSNR从5.31 dB增加到22.23 dB,如表2所示,实验结果表明了IQEM对水印信息的成功提取具有重要价值。
2.6 渲染图像质量对比
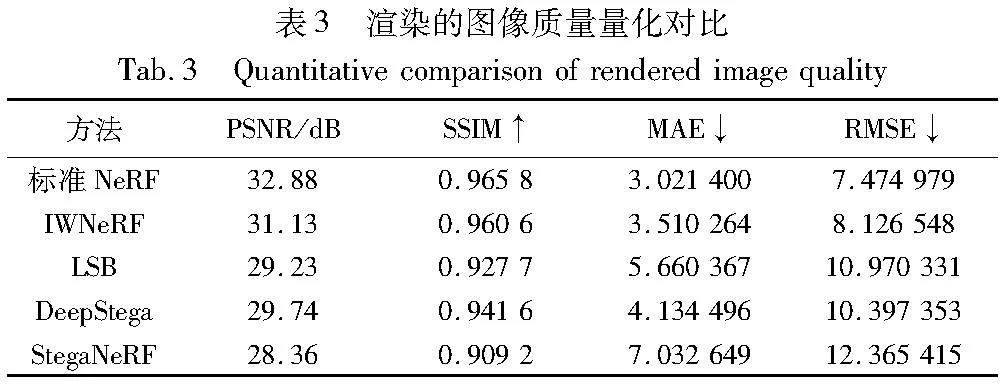
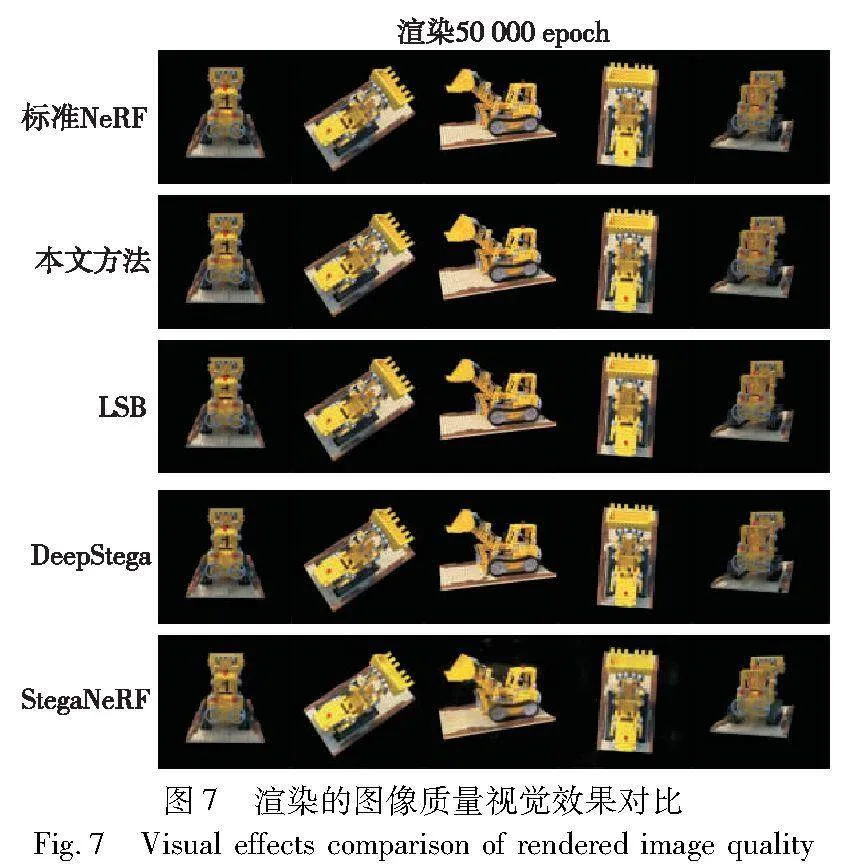
IWNeRF采取可逆神经网络水印的方法来保护NeRF,通过对用于训练NeRF的2D图像利用正向网络进行水印嵌入以及从渲染的图像中通过逆向网络提取水印来证实NeRF的版权。相比于StegaNeRF直接修改MLP结构将会影响网络结构本身的渲染能力,IWNeRF采用的方法由于没有更改网络结构,而是通过间接的方法实现版权的保护,所以不会影响NeRF自身的能力。同时由于可逆神经网络水印优异的性能,相比于传统水印算法LSB以及基于深度学习的其他2D水印算法对原始训练图像进行水印嵌入后影响较小,通过实现发现训练相同的Epoch(50 000),从主观视觉上看,IWNeRF渲染出的图像质量高于LSB、DeepStega和StegaNeRF渲染的图像,如图7所示。
分别将通过四种方案渲染得到的13个角度图像与相同角度的原始训练图像进行对比,得到四种评价指标的量化结果如表3所示。第一行的标准NeRF为由未经嵌入水印的NeRF渲染出的图像质量作为渲染图像质量的上限。IWNeRF渲染出的图像与原始图像在四种评价指标上与标准NeRF接近且均优于其他方法,表明IWNeRF能够实现在不影响NeRF渲染能力的情况下实现版权保护。
3 结束语
本文首次提出利用可逆神经网络水印保护神经辐射场的方案(IWNeRF),实现了对NeRF的版权保护。IWNeRF采用可逆神经网络对2D图像进行水印的嵌入和提取,将水印的嵌入和提取建模为可逆网络的正向和反向过程,同时在中间过程中增加了图像质量增强模块,以弥补NeRF渲染过程中造成的水印信息丢失,实现对神经辐射场表示的3D模型的保护。实验结果表明IWNeRF能够实现水印的嵌入与提取,但是水印的提取质量还有待进一步提高。
参考文献:
[1]Mildenhall B, Srinivasan P P, Tancik M, et al. NeRF: representing scenes as neural radiance fields for view synthesis[EB/OL]. (2020). https://arxiv.org/abs/2003.08934.
[2]Barron J T, Mildenhall B, Tancik M, et al. Mip-NeRF: a multiscale representation for anti-aliasing neural radiance fields[C]//Proc of IEEE/CVF International Conference on Computer Vision. Pisca-taway,NJ:IEEE Press, 2021: 5835-5844.
[3]Tanik M, Casser V, Yan X, et al. Block-NeRF: scalable large scene neural view synthesis[EB/OL]. (2022-02-11). https://arxiv.org/abs/2202.05263.
[4]范腾, 杨浩, 尹稳, 等. 基于神经辐射场的多尺度视图合成研究[J]. 图学学报,2023,44(6):1140-1148. (Fan Teng,Yang Hao,Yin Wen, et al. Survey of residual network[J].Journal of Graphics,2023,44(6):1140-1148.)
[5]马汉声, 祝玉华, 李智慧, 等. 神经辐射场多视图合成技术综述[J]. 计算机工程与应用, 2024,60(4):21-38. (Ma Hansheng, Zhu Yuhua, Li Zhihui, et al. Survey of neural radiance fields for multi-view synthesis technologies[J]. Computer Engineering and Applications, 2024,60(4):21-38.)
[6]Yu A, Fridovich-keil S, Tancik M, et al. Plenoxels: radiance fields without neural networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2022: 5491-5500.
[7]Myuller T, Evans A, Schied C, et al. Instant neural graphics primitives with a multiresolution hash encoding[EB/OL]. (2022-01-16). https://arxiv.org/abs/2201.05989.
[8]Wang Liao, Zhang Jiakai, Liu Xinhang, et al. Fourier PlenOctrees for dynamic radiance field rendering in real-time[EB/OL]. (2022-02-17). https://arxiv.org/abs/2202.08614.
[9]Xu Dejia, Wang Peihao, Jiang Yifan, et al. Signal processing for implicit neural representations[EB/OL]. (2022-10-17).https://arxiv.org/abs/2210.08772.
[10]Chen Di, Liu Yu, Huang Lianghua, et al. GeoAug: data augmentation for few-shot NeRF with geometry constraints[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2022: 322-337.
[11]Chen Anpei, Xu Zexia, Zhao Fuqiang, et al. MVSNeRF: fast gene-ralizable radiance field reconstruction from multi-view stereo[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2021: 14104-14113.
[12]Zhang Jian, Zhang Yuanqing, Fu Huan, et al. Ray priors through reprojection: improving neural radiance fields for novel view extrapolation[EB/OL]. (2022-05-12). https://arxiv.org/abs/2205.05922.
[13]Qin Chuan, Zhang Xinpeng. Effective reversible data hiding in encrypted image with privacy protection for image content[J]. Journal of Visual Communication and Image Representation, 2015,31: 154-164.
[14]Liao Xin, Shu Changwen. Reversible data hiding in encrypted images based on absolute mean difference of multiple neighboring pixels[J]. Journal of Visual Communication and Image Representation, 2015, 28: 21-27.
[15]Hou J U, Kim D G, LEE H K. Blind 3D mesh watermarking for 3D printed model by analyzing layering artifact[J]. IEEE Trans on Information Forensics and Security, 2017, 12: 2712-2725.
[16]Son J, Kim D, Choi H Y, et al. Perceptual 3D watermarking using mesh saliency[C]//Proc of Information Science and Applications. Singapore: Springer, 2017: 315-322.
[17]Hamidi M, Chetouani A, El Haziti M, et al. Blind robust 3-D mesh watermarking based on mesh saliency and QIM quantization for copyright protection[C]//Proc of Pattern Recognition and Image Analysis. Cham: Springer International Publishing, 2019: 170-181.
[18]Liu Jing, Yang Yajie, Ma Douli, et al. A novel watermarking algorithm for three-dimensional point-cloud models based on vertex curvature[J]. International Journal of Distributed Sensor Networks, 2019,15(1):155014771982604.
[19]Uchida Y, Nagai Y, Sakazawa S, et al. Embedding watermarks into deep neural networks[C]//Proc of ACM on International Conference on Multimedia Retrieval, New York:ACM Press,2017.
[20]Adi Y, Baum C, Cisse M, et al. Turning your weakness into a strength: watermarking deep neural networks by backdooring[EB/OL]. (2018-08-15). https://arxiv.org/abs/1802.04633.
[21]Wu Hanzhou, Liu Gen, Yao Yuwei, et al. Watermarking neural networks with watermarked images[J]. IEEE Trans on Circuits and Systems for Video Technology, 2021,31(7): 2591-2601.
[22]Guan Xiquan, Feng Huamin, Zhang Weiming, et al. Reversible watermarking in deep convolutional neural networks for integrity authentication[EB/OL]. (2021-04-09). https://arxiv.org/abs/2104.04268.
[23]Li Chenxin, Feng B Y, Fan Zhiwen, et al. StegaNeRF: embedding invisible information within neural radiance fields[EB/OL]. (2022-12-03). https://arxiv.org/abs/2212.01602.
[24]Fridrich J, Goljan M, Du R. Detecting LSB steganography in color, and gray-scale images[J]. IEEE MultiMedia, 2001,8(4): 22-28.
[25]Weng Xinyu, Li Yongzhi, Chi Lu, et al. High-capacity convolutional video steganography with temporal residual modeling[C]//Proc of International Conference on Multimedia Retrieval. New York:ACM Press, 2019:87-95.
[26]Mallat S G. A theory for multiresolution signal decomposition: the wavelet representation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 1989,11(7): 674-693.
[27]郭玥秀, 杨伟, 刘琦, 等. 残差网络研究综述[J]. 计算机应用研究, 2020,37(5): 1292-1297. (Guo Yuexiu,Yang Wei,Liu Qi, et al. Survey of residual network[J]. Application Research of Computers, 2020,37(5): 1292-1297.)
[28]Baluja S. Hiding images in plain sight: deep steganography[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Piscataway,NJ:IEEE Press, 2017:2066-2076.
[29]Jing Junpeng, Deng Xin, Xu Mai, et al. HiNet: deep image hiding by invertible network[C]//Proc of IEEE/CVF International Confe-rence on Computer Vision. Piscataway,NJ:IEEE Press, 2021: 4713-4722.
[30]Agustsson E. Challenge on single image super-resolution: dataset and study ( supplementary material )[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway,NJ:IEEE Press, 2017:1122-1131.
[31]Lu Shaoping, Wang Rong, Zhong Tao, et al. Large-capacity image steganography based on invertible neural networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2021: 10811-10820.
