基于深度强化学习的边缘网络内容协作缓存与传输方案研究
2024-07-31周继鹏李祥
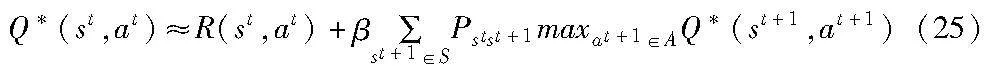
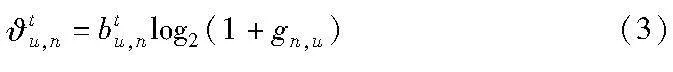
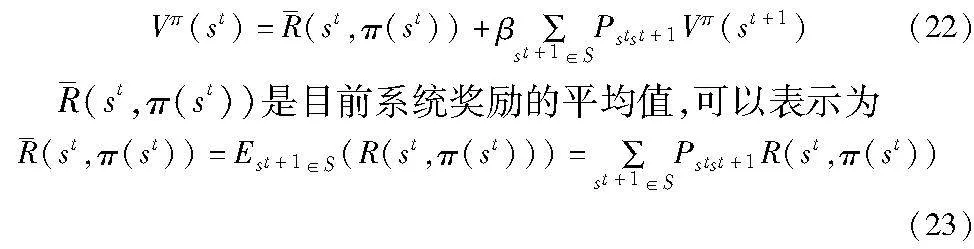
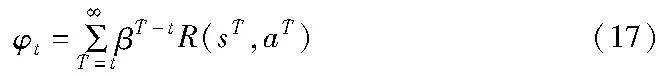
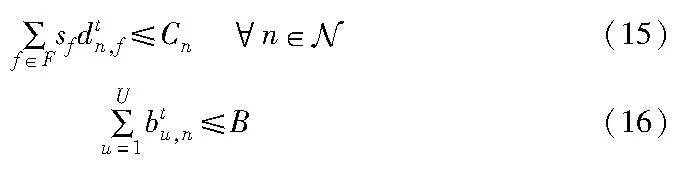


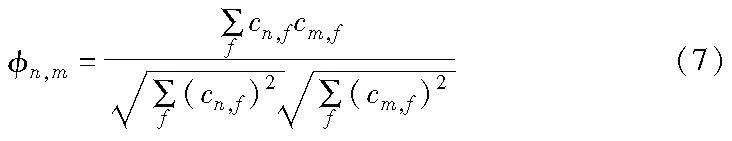
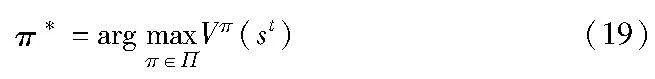
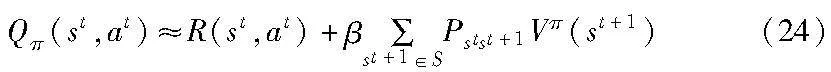
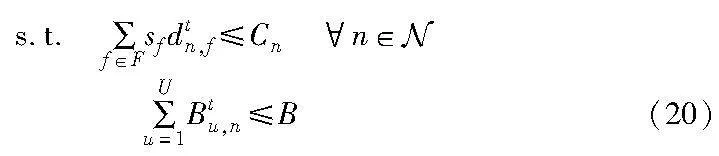



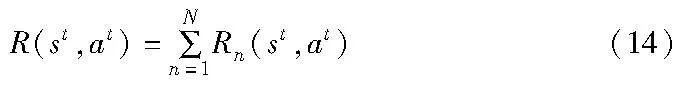
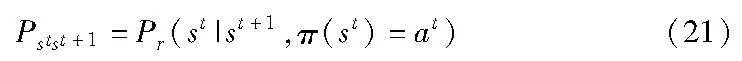
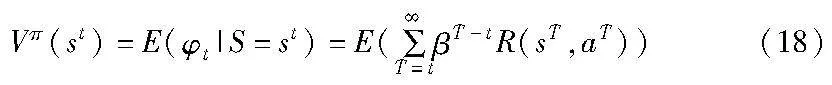

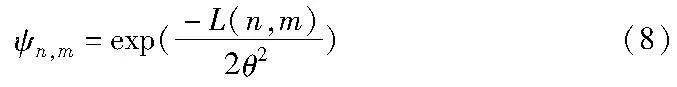
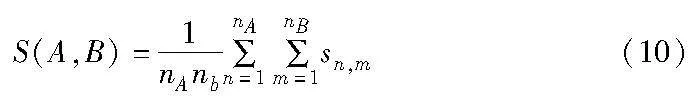
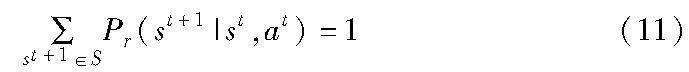
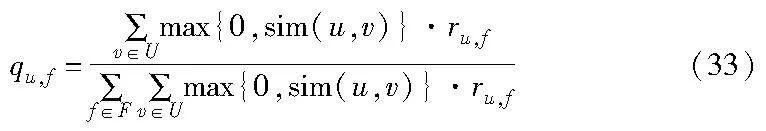

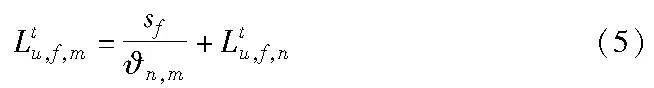
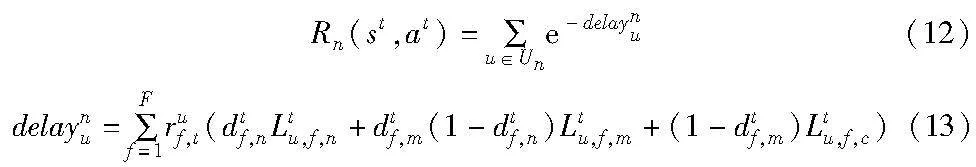



摘 要:为了应对第五代无线通信网络中数据吞吐量急剧增加的问题,移动边缘缓存成为了一种有效的解决方案。它通过在边缘设备上存储网络内容,减轻回程链路和核心网络的负担,缩短服务时延。到目前为止,大多数边缘缓存研究主要优化协作内容缓存,忽略了内容传输的效率。研究超密集网络的内容协作边缘缓存与无线带宽资源的分配问题,通过余弦相似度和高斯相似度求解基站之间总的相似度,将网络中的小基站根据总相似度进行分组,把缓存和无线带宽分配问题建模成一个长期混合整数的非线性规划问题(LT-MINLP),进而将协作边缘缓存与带宽分配问题转换为一个带约束的马尔可夫决策过程,并利用深度确定性策略梯度DDPG模型,提出了一种基于深度强化学习的内容协作边缘缓存与带宽分配算法CBDDPG。提出的基站分组方案增加了基站之间文件共享的机会,提出的CBDDPG算法的缓存方案利用DDPG双网络机制能更好地捕捉用户的请求规律,优化缓存部署。将CBDDPG算法与三种基线算法(RBDDPG、LCCS和CB-TS)进行了对比实验,实验结果表明所提方案能够有效地提高内容缓存命中率,降低内容传递的时延,提升用户体验。
关键词:移动边缘计算; 协同边缘缓存; 无线带宽分配; 深度强化学习
中图分类号:TP393 文献标志码:A
文章编号:1001-3695(2024)06-033-1825-08
doi:10.19734/j.issn.1001-3695.2023.10.0435
Deep reinforcement learning based-edge network contentcooperative caching and transmission scheme
Abstract:In order to address the problem of rapid increase of data throughput in fifth-generation wireless communication networks, mobile edge caching has become a useful solution. It can reduce the burden on the backhaul link and core network, cut down service latency by storing network content on edge devices. So far, most edge caching solutions have mainly focused on optimizing cooperative content caching, and ignored the efficiency of content transmission. This paperstudied cooperative edge caching and wireless bandwidth allocation problems in ultra-dense networks, calculated the overall similarity between the base stations by using cosine similarity and Gaussian similarity, and grouped the small base stations according to total similarity in the network. The caching and radio bandwidth allocation problems were modeled as a long-term mixed-integer non-linear programming(LT-MINLP). Then, the cooperative edge caching and wireless bandwidth allocation problem were transformed into a constrained Markov decision process. Finally,itproposed cooperative edge caching and radio resource allocation scheme by using the DDPG model. And it proposed deep reinforcement learning based-edge content cooperative caching and bandwidth allocation algorithm CBDDPG. The proposed base station group strategy increased the file sharing opportunity among base stations, the cache scheme of the proposed CBDDPG algorithm used DDPG dual-network mechanism, which could better capture the regularity of user requests and optimize cache deployment. The proposed CBDDPG algorithm was compared to three baseline algorithms, sach as RBDDPG, LCCS and CB-TS in experiments. Experimental results show that the proposed strategy can effectively enhance the content cache hit ratio, reduce the delay of content delivery and improve the user experience.
Key words:mobile edge computing(MEC); cooperative edge caching; wireless bandwidth allocation; deep reinforcement learning(DRL)
0 引言
随着移动网络的不断升级和发展,以及大量的流媒体视频、物联网、增强现实、无人驾驶、工业互联网、智慧城市等技术的广泛应用,移动通信网络的业务在过去十多年期间急速增加,数据流量对无线网络的需求呈爆炸式增长。为了应对如此巨大的无线流量增长,将服务资源迁移至网络边缘侧被认为是解决该问题的应对方案之一,可以有效地降低时延和提供高可靠的连接。尤其是针对5G 网络的应用,移动边缘计算强调接近移动用户,并且专注于将计算资源、存储资源和其他服务资源部署于网络的边缘侧,以至于移动边缘计算(MEC)[1]问题成为当今比较热门的研究方向。
在无线网络的场景下,热点内容经常被大量用户反复访问,并且在当前的网络架构中,用户需要通过基站来发送请求内容,基站从远端服务器获取所访问的内容,再回传给用户,这样会导致网络中反复传输一个相同的文件内容,造成巨大的资源浪费。为了解决这个问题,边缘缓存技术应运而生,其主要目的是将热点内容缓存至网络的边缘侧,以此来给用户提供更快的访问速率、更低的访问时延。边缘缓存技术涉及到缓存资源管理、用户请求分析、传输资源分配等一系列技术,需要解决什么时间缓存什么内容,怎么传输内容以及怎么更新内容等。对于边缘缓存问题,由于边缘存储容量的限制,边缘基站需要频繁进行缓存决策或缓存替换的操作,需要消耗自身的计算资源,如果策略出现问题也会给用户带来糟糕的体验,所以,如何在有限的资源下尽快确定相应的缓存策略是MEC缓存相关研究的重点内容。
深度强化学习(DRL)技术在网络资源调配方面表现突出[2]。由于DRL方法的特征,其适用于在线场景的网络研究,与此同时,深度强化学习方法的结果波动性可能会导致应用的结果在最坏情况下无法满足相关性能的要求。所以,如何改善DRL结果在最坏情况下的表现或者尽量减少最坏情况的出现是DRL研究的一个重要方向。
在移动边缘计算中,由于问题的本身具有复杂性,难以直接求解,所以,将深度强化学习方法应用于移动边缘计算是一个值得研究的方向。在一个动态系统中,优化目标可以抽象建模成马尔可夫链模型,即状态环境与动作之间的交互模型[3]。同时,DRL的主要应用场景就是在不同状态下采取不同行动,从而获取相应的收益值,再通过收益使得智能体朝着收益较大的方向执行动作,来尝试获取一种更好的策略[4]。在边缘缓存场景中,文件的上传、放置、分发服务等行为都可以描述成相似的模型。所以,在面对更为复杂的任务场景和目标需求时,使用深度强化学习方法来研究和解决这些问题具有实际意义。
在边缘缓存场景下考虑超密集网络[5]中微基站之间的缓存协作[6]和文件传输问题是一个待研究的问题,其中,微基站的缓存策略是由用户的偏好或者用户请求的内容流行度驱使的,所以提前预知用户的请求内容流行度也是解决问题的关键所在。在大多数工作中,都是根据Zipf分布来假设内容的流行度,并且规定内容流行度是已知的。但大部分情况下,内容流行度未知且较难评估,所以文献[7]通过神经网络来预测内容的流行度,提升主动缓存的命中率,文献[8]使用预测的内容流行度模型来设计缓存策略。而且大多数场景下,超密集网络部署了大量的微基站,微基站之间的相似度很高,通常处于一定的区域内,有较强的地域特性,其所服务的用户也有较强的相似性,因此,将相似性较高的基站进行聚簇能有效提高缓存的空间利用率。一旦文件已被缓存,如何有效地将其传输给用户也是一个尚待解决的问题。在文件传输过程中,无线电资源的分配对下行链路的传输速率起到关键作用,无线电资源的合理分配可以有效减少内容检索时延,这也是评价缓存性能的一个关键点。
本文利用小型蜂窝基站缓存流行文件,并且给用户分配适合的无线带宽资源来减少通向核心网络的回程流量以及访问文件的请求时延,以满足移动数据需求的迅猛增长,考虑到不同基站之间的历史请求内容会有较高的重合度,结合基站的相似性对小基站进行聚类,提升基站存储空间的利用率。本文把缓存决策和无线资源分配问题建模为一个长期混合整数的非线性规划问题(LT-MINLP),将协作边缘缓存与传输问题转换成一个带约束的马尔可夫决策过程。为了解决该问题,本文利用确定性策略梯度DDPG(deep deterministic policy gradient)模型,提出了一种基于深度强化学习的协作边缘缓存及信道资源分配方案。
本文的主要贡献在于:a)将内容缓存问题与通信资源分配问题统一建模求解,将网络中的小基站根据总相似度进行分组,能有效地提高缓存的命中率,同时降低内容传输的时延;b)提出的缓存方案利用DDPG双网络机制能更好地捕捉用户的请求规律,实现在动态环境下缓存部署和带宽分配的在线决策;c)对比实验结果表明,深度强化学习方法在动态环境中进行在线决策的有效性,解决了内容缓存中动态因素的不可预测性问题。
1 相关工作
当前,移动边缘缓存[9]已经成为解决超密集网络下回程链路过载的有效解决方案,该技术能够使用户从启用缓存的边缘节点直接获取内容,无须通过回程链路或者核心网络传输[10],可以有效地缓解回程链路和移动核心网络的压力[11]。然而,单个边缘节点的储存性能是有限的[12],协作边缘缓存能够使多个边缘节点相互共享其缓存内容,可以极大地提高缓存容量以及增强缓存文件的多样性[13]。通过对内容缓存和内容传输的描述,进行以下几种分类。
1)主动缓存和反应式缓存
主动缓存策略决定在内容请求前应该缓存哪些内容,通常利用机器学习和统计分析方法来预测内容流行度和用户偏好,然后使用预测模型来设计适当的内容缓存方案,但是该方法很大程度上取决于预测精度。文献[14]利用上下文意识和社交网络来预测内容流行度和用户偏好。文献[8]利用基站和用户社会关系之间的流量相关性设计主动缓存策略。文献[15]提出了一种基于移动性预测的主动缓存方案,该方案利用序列预测算法,即基于序列预测的主动缓存,来预测车辆路径上的下一个可能的RSU并预先定位相关内容。同样文献[16]提出了一种基于学习的方式来评估文件内容流行度,并且基于欧洲动量项目提供的真实数据集,验证了缓存方案的有效性。
反应缓存方案决定在接收内容请求后应该缓存哪些内容。该方案直接利用内容请求来评估内容流行度,而不需要预测内容流行度的模型。目前的反应缓存方案通常采用RL算法从历史数据中学习最佳缓存策略,更适合复杂动态的边缘缓存环境。例如,文献[17]提出了一种基于DRL的算法,该算法使用各种关键特征,以不断发展的方式训练DRL模型,以便为具有流行度波动和爆发的请求提供服务。文献[18]通过内容请求计算内容流行度,并设计了基于深度确定性策略梯度的协作缓存框架。文献[19]使用了一个异步优势Actor-Critic算法来决定是否应该缓存请求的内容。
2)协作缓存和非协作内容缓存
到目前为止,对非协作内容的缓存方案已有大量研究,非协作缓存基站只能为其本地用户提供缓存服务并且缓存不能在多个基站之间共享。而在超密集网络中,单个微基站的缓存容量有限,协作缓存对于增加缓存多样性和提高缓存命中率至关重要。在文献[20]中,所有的基站合作执行内容缓存且相互共享其缓存内容。文献[21]提出了一个多代理Actor-Critic框架,该框架同时优化从本地基站、附近的基站和远程服务器获取内容的成本,提高了缓存储存利用率。
3)集中式缓存与分布式缓存
在许多现有的研究中,集中的内容缓存方案最为常见。文献[22]提出了一个集中式计算中心,该中心定期收集每个基站的内容请求率并为每个基站作出最佳缓存决策。在文献[18]中,中心宏小区基站接收多个车辆的内容请求,然后在每个缓存阶段时间,更新所有缓存节点的内容缓存决策。然而,集中式方案需要集中式控制器收集所有基站的本地参数来作出内容缓存决策。集中式方案的计算复杂度随着基站的数量呈指数增长。因此,一些研究证实了分布式内容缓存方案的有效性,在文献[20]中,每个基站都被视为可以在本地作出缓存决策的代理。文献[21]提出了一种基于多智能体协作内容缓存策略,每个边缘服务器被认为是一个在本地作出缓存决策的参与者,通过中心服务器来评估更新每个边缘服务器的参数。
4)内容传输优化
根据所需的优化目标,现有的内容缓存和无线资源分配研究分为三类。第一类重点放在内容缓存优化上,而不考虑无线电资源分配。第二类研究考虑了无线电资源分配。例如,在文献[2,23]中,假设分配给不同用户的带宽资源是等效的,但是,上述两种类型的研究都会导致更高的内容下载延迟。在第三类研究中,文献[18]研究了联合优化内容缓存,车辆调度和带宽资源分配以提高缓存性能的问题,但只适用于车载边缘计算环境。文献[24]分析了联合优化内容缓存和无线电频谱分配以最小化无线接入网络中网络延迟的问题,但它只能用于D2D设备的通信,不能用于一般的蜂窝移动网络。
总而言之,现存研究没有考虑边缘环境动态不可预测性的多变性的影响和资源分配方法自适应,在动态环境中内容协作缓存需要考虑全局的边缘网络资源分配情况,提出的共同优化内容缓存和无线资源分配的反应式分布缓存方案,将网络中的小基站根据总相似度进行分组,利用深度强化学习DDPG双网络机制能够更好地捕捉用户请求的规律,以适应边缘计算环境的动态变化, 有效地进行在线决策,以提高缓存命中率, 同时降低内容传输的时延。
2 系统模型
2.1 网络模型
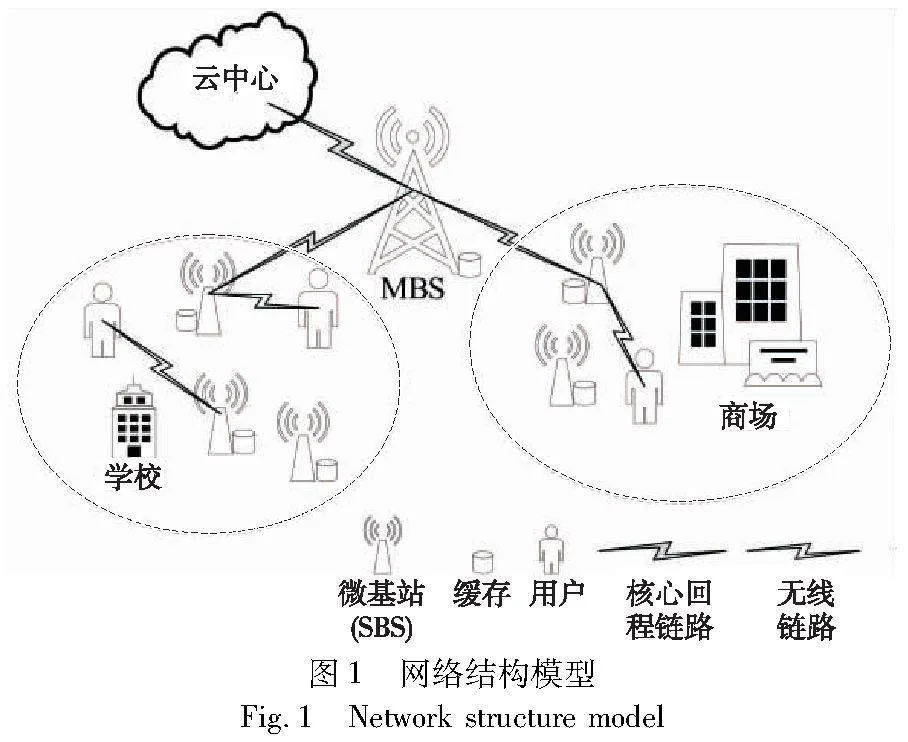
网络架构模型如图1所示,包括一个中心的宏基站MBS(macro base station)、多个小型基站SBS(small base station)以及在每个小型基站分组中的服务网关。假设相邻SBS之间的干扰已经通过不相邻小区的频率复用被消除,回程链路和无线链路主要用于上下行的数据传输,黑色虚线范围的基站代表同一分组SBS,同一聚类分组的SBS通过服务网关进行相连,MBS集中管理和控制网络下的SBS为其进行决策部署计算。
供文件传输服务。
2.2 文件请求模型
本文将时间划分为离散的时间隙t=1,2,…,∞,内容缓存和传输在每个时间隙实施,且假设时隙足够大,使得内容的检索和传递在一个时隙内完成。在每个时隙结束时,基站更新缓存内容以便于在后续的时隙内进行传输。
在大多数现有的研究中,假设内容流行度遵循移动社交网络中的Zipf分布,内容流行度配置文件表示该区域用户在一段时间内对不同内容在不同时间的需求,这对于基站作出缓存决策起着重要作用,但内容流行度是变化的,且较难估计,因此内容流行度的建模需要在密集网络中作进一步研究。为此,本文从内容请求率导出的全局内容流行度,设在缓存周期开始的时候,基于小基站SBS的内容请求率导出的内容流行度作为当前时隙的一个文件流行度。在每个时隙,由小基站SBS用户的内容请求信息计算出该基站的内容流行度,表示为
设stn,f表示在时隙t下基站n处文件f被用户请求的次数,stn表示在该时隙基站n处所有用户总的请求次数,基站n下各个文件f的局部内容流行度为 Ptn=(ptn,1,ptn,2,…,ptn,f,…,ptn,F),并且每个用户在一个时隙周期内请求文件的数量服从泊松分布,平均速率为ωu。
2.3 通信模型
其中:ρn是基站n的传输功率;h-αu,n是用户u到基站的n路径损失;vu,n是信道的功率增益;σ2代表着噪声功率。所以在时隙t对于用户u在基站n的下行链路的传输速度为
2.4 协作缓存模型
a)用户u于时隙t直接在本地基站n服务下得到请求文件内容,该时延可以表示为
b)如果用户u的本地基站n在时隙t下没有缓存文件f,但基站n下该分组Gg的其他基站m下缓存了文件f,那么用户的请求访问时延可以表示为
c)如果用户u的本地基站n和该基站分组Gg的其他基站m在时隙t下都没有缓存文件f,那么用户u于时隙t通过MBS在云端服务下得到请求文件内容,该时延可以表示为
3 基站分组与问题建模
内容协作缓存和基站聚簇旨在降低用户请求下载内容的平均时延,以提高用户的服务质量。本文提出一种基于基站之间的内容相似度和距离的分组方案,通过增加基站之间协作共享文件的机会,进一步提高系统的性能,降低用户请求时延。协作缓存是利用多个小型基站之间的合作缓存,提高用户服务质量的一种策略。为了实现这一策略,首先需要将基站进行聚类,以基站间的距离和内容相似度作为依据,将网络中的所有小型基站进行分组,每一组中的基站都连接到同一个服务网关,每个基站可以通过其对应的服务网关,从同一分组中的其他基站获取其缓存的内容。用户在每个时隙t内,连接到唯一的基站,每个基站为用户分配一定的带宽资源btu,n传输所请求的内容文件。
3.1 基站分组
对小基站分组的关键在于如何去计算量化两个基站之间的相似度,而对于基站,距离和其历史的下载信息是两个较为关键的因素,因为距离影响着两个基站之间的协作缓存的效益,历史下载信息反映基站用户的兴趣偏好,如果历史下载集合重复较多,则表明两个基站下的用户偏好相近。
1)基站的内容相似度
为了更好地识别在请求内容上彼此相似的SBS,分组算法需要找到一个衡量基站相似度的指标,本文以推荐理论中的余弦相似度来衡量两个基站之间的内容相似性,反映基站文件的受欢迎程度,SBS之间的内容相似度可以表示为
其中:cn,f表示文件f在基站n处的总访问次数。很明显n,m∈[0,1],n,m越大,说明两基站之间的内容相似度越高,最终可以得到一个N×N的内容相似度矩阵ΦN×N,表示基站之间的下载内容相似度。
2)基站的距离相似度
为了减小用户的访问内容时延,提高基站之间的通信效能,计算基站之间的距离相似性,用L(n,m)表示基站n和m之间的距离,两个基站之间的距离相似度为
由此可得,如果两个基站之间的距离越小,ψn,m的值越大,并且ψn,m∈[0,1],这里θ为一个常数。最终可以得到一个矩阵ΨN×N,代表基站之间的距离相似度,只有在基站之间的距离小于一定值时,两基站间才能保证良好的通信能力,若基站间的距离较远,传输时延变大,协作收益将得不到保证。最终基站n和m之间的相似度表示为
Sn,m=n,mq×ψn,m1-q q∈[0,1](9)
根据sn,m通过层次聚类算法来进行小基站的分簇,两个分组之间的相似度可以描述为
其中:A和B分别为两个聚类基站分组;S(A,B)代表分组A和B之间的相似度;nA、nB分别代表分组A和B中小基站的个数。
本文采用相似度作为考虑因素,并设定了阈值K,使用了层次聚类算法,对基站进行分组。具体分组步骤如下:
a)移动边缘网络中SBS的数量为N,将每个SBS视为一个单独的实体,形成N个独立的分组,每个分组中只包含一个SBS;
b)根据相似度最大的准则,找到所有分组中相似度最大的两个分组,将这两个分组合并成一个新的分组,此时总的分组数量减少了一个;
c)使用式(10)计算新合并的分组与每个旧分组之间的相似度;
d)重复执行步骤b)c),直到两个最近的分组基站之间的相似度小于规定的阈值K。
所有小型基站通过上述步骤进行分组,最终得到H个基站分组,为后续的协作缓存提供支持。
3.2 问题建模
协作边缘缓存是一个离散变量问题,但是对用户的无线资源分配是一个连续资源分配问题。而对于解决联合协作边缘缓存和无线资源分配问题,强化学习是一种可以通过最大化累计期望或回报,使得智能体能够在动态环境中学习来获得最优策略的方法。本文结合这两个问题以及强化学习的特性,通过优化总的内容传输延迟,采用深度确定性策略梯度算法(DDPG)求解,根据环境状态作出缓存决策和无线资源分配,给每个基站的文件部署。
将协作边缘缓存和无线资源分配转换为离散时间的马尔可夫链来进行联合优化,设计一种在线缓存和传输方案,该方案可以在时变用户请求模式下,最大限度地减少用户对文件的访问时延,以最大化用户的QoS质量。马尔可夫链式是一种顺序决策的典型形式化,其中智能体可以通过学习与环境交互来实现目标。受限的马尔可夫决策过程可以表示为一个五元组(S,A,r,Pr,C),其中,S表示状态空间,A表示动作空间,r表示奖励,Pr表示状态的转换概率,C表示约束条件。
1)系统状态空间
令S为状态空间,在每个时隙t开始时,智能体感知环境状态,具体包括以下信息:
Vt=[Vt1,Vt2,…,Vtn,…,VtN]表示在时隙t每个基站的用户所需传输的数据量,其中Vtn表示基站n下的每个用户u所需传输数据量大小vtu,n,根据请求文件大小和用户的请求数量ωu计算,Vtn=[vt1,n,vt2,n,…,vtu,n,…,vtU,n]。Pt=[Pt1,Pt2,…,Ptn,…,PtN]表示基站n在时隙t下的文件局部流行度状态,也就是每个时隙下基站SBS根据内容请求率导出的文件流行度,st=(Vt,Pt)表示系统在时隙t的状态。
2)系统动作空间
3)系统转移概率
状态转移概率Pr(st+1|st,at)表示在采取动作at之后,预测状态从st转换到状态st+1的概率,满足
4)系统奖励
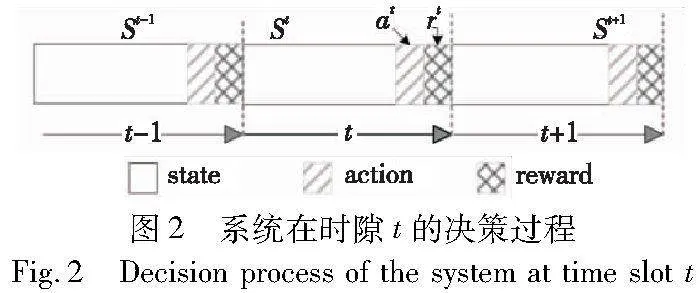
设R(s,a)为系统在状态s下执行动作a所得到的奖励,该奖励值由系统用户访问文件的时延决定。系统在时隙t的决策过程如图2所示,每一个时隙t被划分为决策阶段、状态获取阶段和奖励评估阶段三个阶段。在每个时隙下,SBS获取环境中每个用户对文件的访问请求并根据文件请求率导出局部流行度以及用户所需传输数据量大小,将信息传递给MBS进行决策,每个SBS更新其缓存内容,以便进行可能的传输,减少内容传递延迟。st=(Vt,Pt)作为系统在时隙t下的状态,依据在决策阶段采取的动作at,在时隙t下得到的系统奖励为R(st,at)。
策略π是一个状态到动作的映射函数,at=π(st)表示在状态s下产生动作a。在马尔可夫决策过程中,每次系统通过采取一个决策,计算当前时隙t下的文件传递时延所对应的奖励。
由于目标是减少内容传递延迟,用户u经历的内容获取延迟取决于基站中的内容缓存状况和下行链路的传输速率。对于基站n,在状态st下的缓存决策at作用于系统之后产生的系统奖励可以表示为Rn(st,at)。
delaynu表示用户u在一个时隙下从基站n获取所需文件的传输时延,允许每个用户在一个时隙访问多个文件,其中Un表示基站n中所有的用户,ruf,t表示用户u在时隙t下是否访问文件f,如果访问则值为1,否则为0。这里m∈Gg,Gg表示用户u所处基站n处分组中的基站集合。所以,系统在状态st下采取动作at,总的系统奖励表示为
5)系统约束
每个基站n总的缓存内容文件大小应该在可用的缓存容量Cn内,并且每个基站给用户分配的连续带宽之和不能超过B,系统的约束为
6)价值函数
为了找到最优的策略π*,设用φt来评估长期的系统奖励,也就是折扣回报,被定义为
这里0≤β≤1表示当前决策对未来奖励影响的折扣系数。给定一个策略π,决策的性能可以根据累积的状态价值函数Vπ(st)来衡量,它通过长期的系统奖励期望来计算,表示为
本文目标是找到最优策略π*,便于在任何状态下最大化长期的系统奖励:
这里的Π表示所有可能的策略,因此该缓存决策和无线资源分配策略的最优问题可以被表示成最大化长期的系统奖励期望。
problem(I)是一个时变参数的顺序决策问题,本文将问题转换为Bellman方程,并利用深度强化学习来获得最优策略。
4 内容协作缓存与无线带宽分配
4.1 问题转换
Bellman方程是一个动态规划方程,它为在顺序决策问题中获取最优策略提供了必要的条件。系统从目前的状态st到下一个状态st+1的概率表示为
在时间隙t下,problem(I)中的目标函数可以用迭代的方式写入Bellman方程里面:
最终通过顺序策略迭代来获得最优策略π*,策略π下的动作价值函数表示为
定义最优的动作价值函数为Q*(st,at),能够用Bellman方程表示为
因为系统的状态空间维度较高,无法利用Bellman方程计算所有的价值函数,本文把神经网络用作函数逼近器来近似强化学习RL(reinforcement learning)中的价值函数。RL算法有基于模型的方法和无模型方法两大类。前者主要用于自动控制领域,而后者可以被定义为一种数据驱动的方法,通过估计值函数或策略函数来获得最优策略。本文利用无模型学习方法中基于DDPG(deep deterministic policy gradient)模型,利用深度神经网络提供确定性策略函数π(s)和动作价值函数Qπ(s,a)的估计。该组合可用于实现本文提出的内容缓存和无线资源分配问题的联合优化。
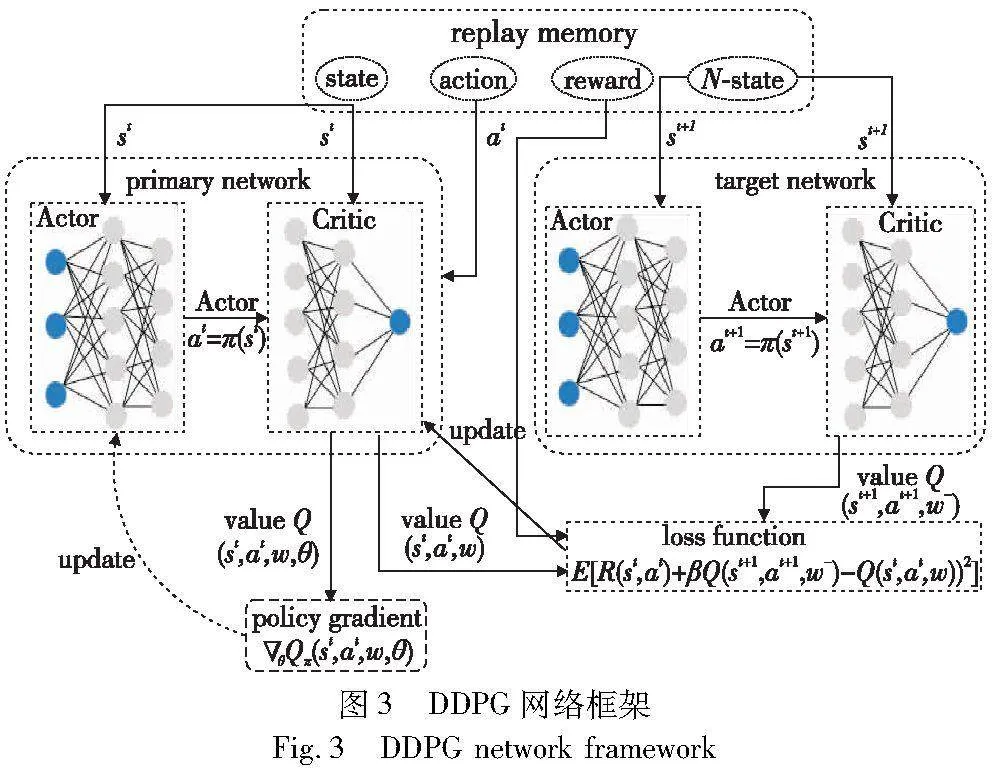
4.2 内容协作缓存和无线带宽分配算法
基于确定性的Actor-Critic模型,本文利用神经网络来近似策略函数π(s)和动作价值函数Qπ(s,a)。如图3所示,RL智能体由Actor和Critic网络组成,Actor网络的作用是根据观察到的环境状态产生动作行为,Actor就相当于策略π函数。而Critic网络通过从环境中得到的奖励来评估和更新当前的Actor网络。Actor网络使用Critic的输出来更新策略参数。Critic的输出与时间差分法成正比,能够判断当前执行的动作带来收益的好坏。通过时间差分法在每个时隙得到的奖励来更新Critic网络,使得Critic越来越准确,进一步使得Actor输出的动作往收益增大的方向靠拢。在网络刚开始学习过程中,为了避免陷入局部最优解,更好地兼顾探索过程,算法引入了随机噪声来为生成的动作增加随机性,随机性在刚开始训练时较大,随着迭代的次数增加,随机噪声减少,其中η为随机探索噪声,表示为
at= π(s)+η(26)
1)Critic网络更新过程
Critic网络使用DNN进行价值函数估计,Qπ(s,a)≈Qπ(s,a,ω),事实上,Actor-Critic神经网络会导致算法发散,所以本文采用了最近提出的经验回放和目标网络技术。由于在利用Actor-Critic神经网络训练时,会导致在真实的动作价值函数Qπ(s,a,ω)的近似中引入大量的方差,在训练过程中用回放缓冲区来存储之前的经验,然后随机抽样经验用于学习,以破坏训练样本的相关性,这种技术就是经验回放。使用target network来生成时间分差误差,能够使算法收敛更快稳定性更好。
经验回放缓冲区存放着训练记录元组(st,at,R(st,at),st+1),使用批量元组来更新网络参数ω,为了最小化损失函数,利用梯度下降更新参数ω,时间差误差为
δTD=R(st,at)+βQπ(st+1,at+1ω-)-Qπ(st,at,ω)(27)
其中:ω-是target network网络的参数,与当前的primary network相比,其参数相对固定。参数更新过程为
ω=ω-αcδTDωQπ(s,a,ω)(28)
其中:αc是神经网络的学习率,小的学习率可以避免振荡,但可能导致收敛的迭代次数变多。
2)Actor网络更新过程
Actor网络使用梯度上升来更新其参数θ,π(s)≈π(s,θ),该策略通过优化状态价值函数来改进,算法的状态价值函数就是策略π的绩效指标。训练的目的是使策略函数输出的动作能最大化动作价值函数的值,最终得到策略梯度的表达式为
因为要使状态价值函数达到最优,所以利用随机梯度上升来更新θ:
θ=θ+αaθQπ(s,a,ω,θ)(30)
此处αa>0是一个常数的学习速率。
3)target network网络更新
如图3所示,target network可以被视为primary network的近似副本,实际上,target network的架构(如层数和隐藏层单元数)需要与primary network保持一致,如果target network的策略函数和价值函数的参数更新相比于primary network较慢,则网络的学习性能稳定且健进。
此处使用指数加权平均来更新ω-和θ-,而不是直接复制primary network的参数。其更新过程可以表示为
θ-=τ1θ-+(1-τ1)θ(31)
ω-=τ2ω-+(1-τ2)ω(32)
其中:τ1,τ2∈[0,1],是各自网络更新的权重。可以由实验效果设置经过多少轮迭代来更新一次ω-和θ-。基于DDPG的内容协作缓存与无线带宽分配CBDDPG(DDPG-based content cooperative caching and bandwidth allocation)算法求解Actor网络参数θ,然后根据θ值得到缓存结果和无线带宽分配。
算法 CBDDPG算法
5 仿真实验与性能分析
5.1 仿真场景参数设置
对于提出的协作缓存与带宽分配方案,使用Python建立一个仿真模拟环境,利用MovieLens[25]等公共数据集进行仿真实验。为了简化仿真的过程,但不失随机性,此处抽取了数据集中的100个用户的电影评分,最高为5,最低为0,可以近似体现用户对内容的喜好程度,用ru,f表示用户u对内容f的评分,然后得到用户u对内容f的偏好程度[26]:
其中:sim(u,v)表示用户u和v的相似度,根据经典的基于用户的协同过滤算法可以得到[27]。根据不同基站下用户u对文件f的偏好进行随机访问,可以得到该基站下文件的历史请求率。在该系统中共有10个SBS基站随机覆盖着100个用户,每个小基站的覆盖半径为50 m,经过多次实验数据观察,设置基站分组阈值K为0.97,由于在超密集网络中,小型基站距离一般不大,设置q值为0.9。Actor网络的学习率为0.000 1,Critic网络的学习率为0.000 2,表1展示了所有的环境参数,另外本文设计了一个全连接的具有五个隐藏层的DNN网络,每个隐藏层有50个节点单元,激活函数为ReLU。
5.2 对比算法描述
对奖励的折扣系数设置为β=0.9,由于算法的训练性能随着次数的增加,在一定范围内表现出强烈的振荡,在模拟中取平均值以减少模拟中的随机性。为了评估本文缓存方案的性能,将本文方案与以下三种基线方案进行比较。三种基线方案概述如下:
a)基于随机信道分配的协作缓存方案(RBDDPG)。SBS的缓存决策部署根据DDPG来求解,信道分配采用随机的方式。
b)基于分层感知的协作缓存方案(LCCS)[28]。该方案是一种典型的协作算法,通过将所有节点的储存资源分成两部分来实现,一部分用于缓存全局最流行的内容,另一部分用于缓存局部最流行的内容。该算法使用分数来调整缓存资源的分配,LCCS算法是LCC的修改版本,其假设每个文件只有一层,这是因为本文的重点不是文件分层缓存,并且可以联合聚簇中的基站获取相应的请求文件,信道资源分配方式采用贪心分配。
c)基于汤普森采样的协作缓存方案(CB-TS)。在该方案的每一轮缓存中,缓存在SBS的内容根据上一轮的缓存命中数和未缓存命中数来进行更新[29],并且选择值最大的文件内容进行缓存,直到基站容量放满,信道资源分配采用贪心的方式。
5.3 仿真结果收敛对比及分析
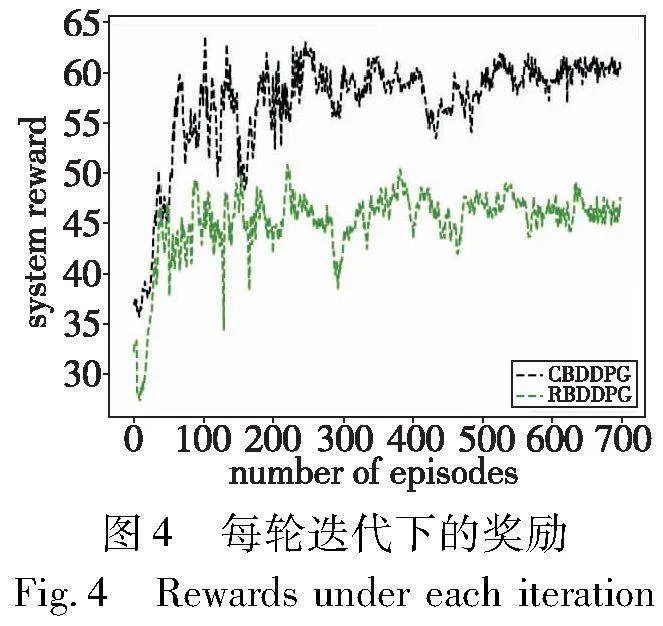
如图4所示,展示了RBDDPG方案和本文基于CBDDPG算法的方案(简称CBDDPG方案)训练过程中的收敛性能,此处的每一轮迭代包含200个时隙,每一个时隙的奖励为系统内的总奖励,之后对本次迭代的时隙奖励求平均值得到每一轮迭代的奖励情况。文件数量为100,每个SBS的缓存容量为600 MB。因为最开始采用自适应来调整η的值,智能体会以较大的概率探索动作空间,奖励值跳跃性比较大,以便智能体根据加入的噪声探索策略获得更好的奖励。可以看到两种方案在前100轮迭代的时候奖励增加的速度较快,随着迭代次数增加,η的值逐渐减小,网络逐渐收敛。可以观察到,CBDDPG方案最开始的系统奖励为35左右,随着迭代次数的增加,奖励值伴随着振荡,但总体的值呈上升趋势,最后的奖励均值在一定幅度内稳定,而RBDDPG方案由于信道的随机分配,在该方案下系统奖励较小,原因是用户总的内容获取时延较长,导致了奖励较低,但网络结构一致,还是会收敛至一定范围。所以在考虑信道分配问题之后,本文CBDDPG方案有着更好的收敛效果和更高的奖励。
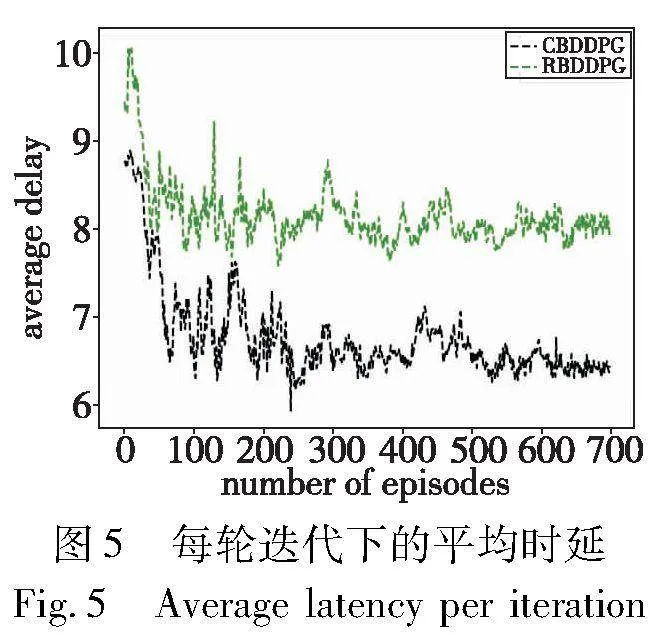
图5展示了CBDDPG和RBDDPG方案在迭代过程中系统的每个用户的平均内容获取时延,最开始CBDDPG方案的平均内容获取时延为
9 s左右,随着网络的迭代,最终平均时延稳定在6.5~6.6 s。因为CBDDPG方案会根据环境的状态,也就是用户的请求信息,优先缓存用户偏好更高的内容,每个用户请求数量不同,所以会导致每个用户所需传输的数据量不同,网络经过学习为不同用户分配适合的信道带宽,而RBDDPG方案虽然也会优先缓存用户偏好更高的内容,但是在内容传输过程中,其无线带宽资源是随机分配的,所以会导致需要传输数据量多的用户分配的带宽更少,这会增加用户的内容获取时延。
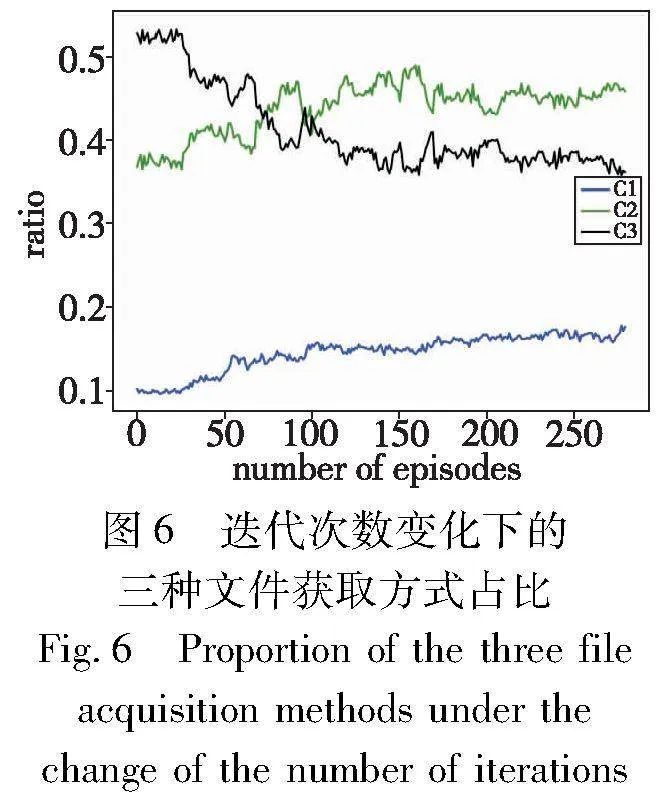
图6展示了CBDDPG方案随着迭代次数增加后,系统中请求用户分别从本地基站、簇内分组基站和通过MBS经核心网获取文件的比例,其中C1表示用户在本地基站获取文件的比例,C2表示用户在簇内分组基站获取文件的比例,C3表示用户通过MBS经核心网获取文件的比例。最开始超过一半的文件是从MBS获取的,随着迭代次数增加,从本地基站和簇内基站获取文件的比例逐渐增加,在250轮迭代之后趋于稳定。其中,C1最开始占比10%左右,稳定之后达到18%的比例,有较明显的提升,对C2从37%提升到了近46%,而C3从刚开始的超一半比例下降到36%左右。实验结果表明,CBDDPG方案能够促使用户感兴趣的文件内容缓存至离用户更近的位置,极大地缩短了用户的请求时延,在实际场景中可以得到较好的应用。
5.4 方案长期性能分析
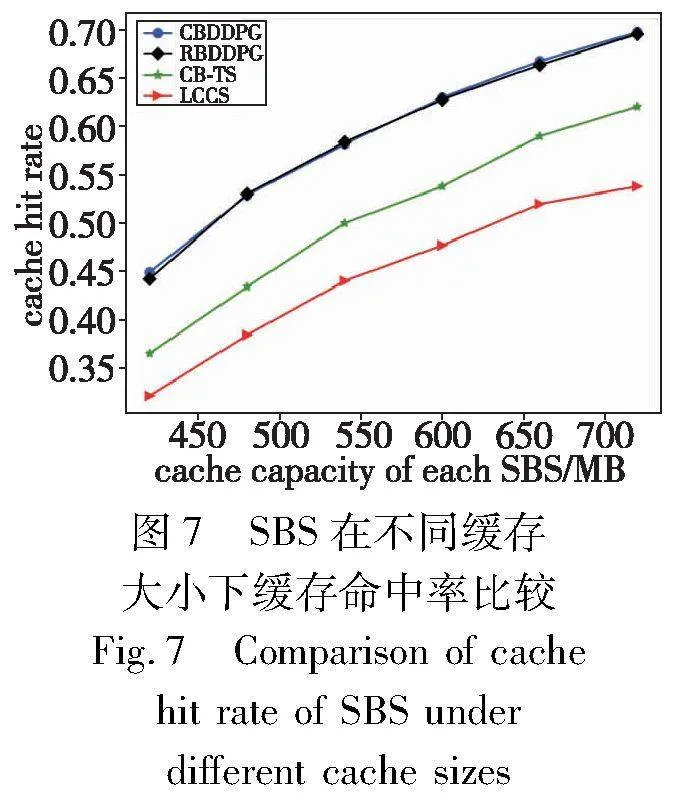
图7展示了四种缓存方案在不同的基站容量下的缓存命中率,文件数量为100。因为通过邻居基站获取文件可以适当地减少时延,所以本文将通过邻居基站中获取文件的情况下也视为缓存命中。可以观察到所有方案的缓存命中率随着基站容量的增大而增加。本文CBDDPG方案的命中率与RBDDPG方案相近,但优于其他两种方案,这是因为RBDDPG方案也会根据用户请求信息来缓存用户偏好较高的文件。CBDDPG方案相对于LCCS和CB-TS方案有更高的缓存命中率,这是因为DDPG算法能够学习用户的请求习惯,在缓存部署时更好地放置利于用户的文件,提高基站缓存的空间利用率,而在LCCS方案中,SBS之间不必要的内容冗余会导致储存利用率降低,从而降低缓存命中的性能。而CB-TS方案通过用户的请求过程不断地修正文件的分布,相对于LCCS方案会有一个探索的过程,从后验分布中采样出来,分层的贪心算法缺乏主动探索。
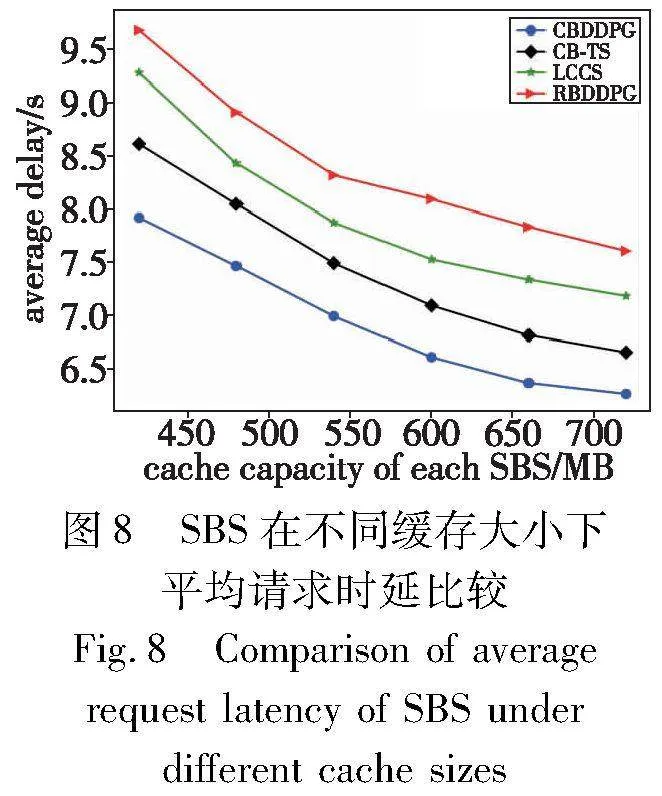
图8展示了四种缓存方案在不同的基站容量下的系统时延,随着基站容量的增大,四种方案的系统时延逐渐减小,因为更高的缓存命中率可以将更多的请求从核心网卸载到本地或者聚簇网络,可以看到RBDDPG方案虽然在缓存命中率上较优,但是会导致更长的内容获取时延,其中最主要的原因是为传输数据量较多的用户分配了较少的无线资源,从而加大了内容获取时延。
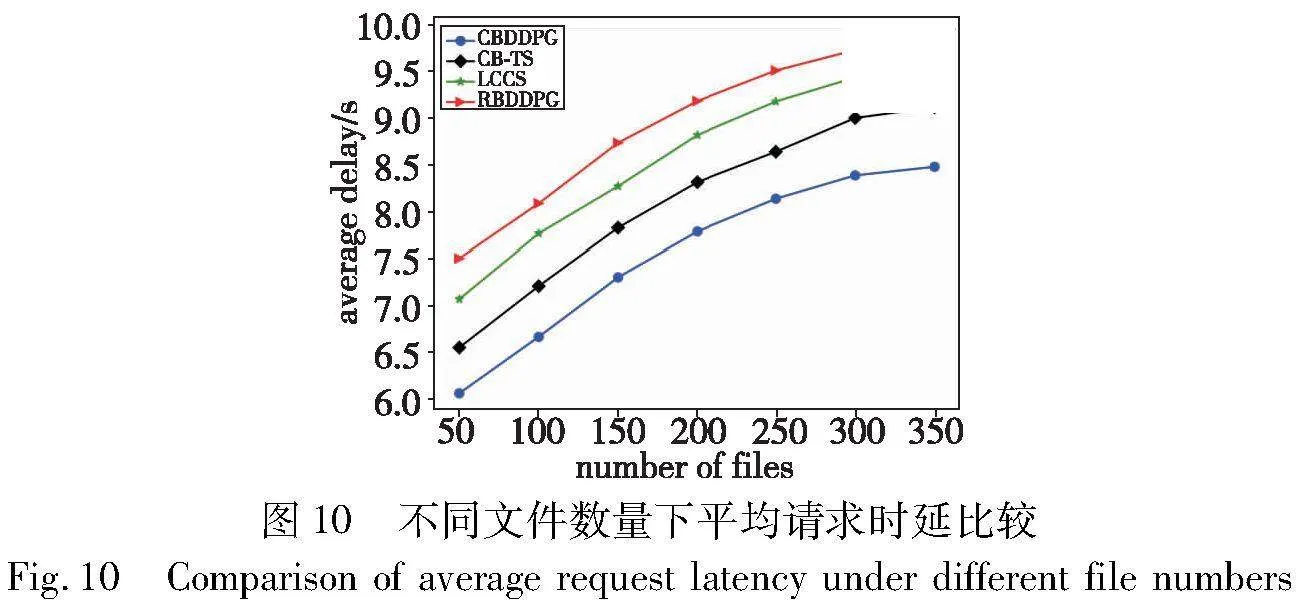
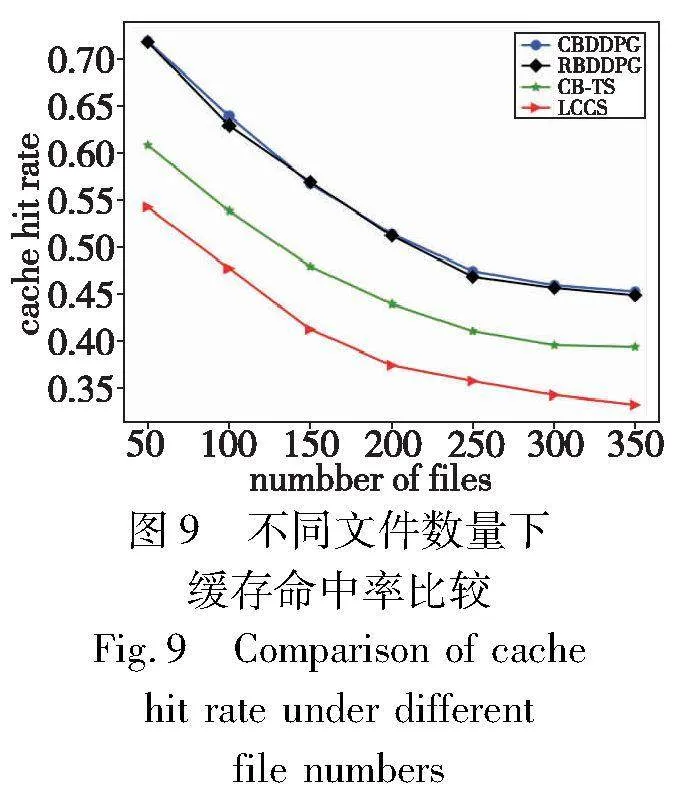
图9和10展示了系统缓存命中率和文件传输的平均时延在不同的文件数量下的性能对比,模拟的文件总数在50~350,基站容量大小为600 MB。
如图9所示,当系统内的文件数量较少时(范围在50~150),与没有缓存相比,CBDDPG方案至少贡献了55%的命中率,当系统内文件数量增加时,所有缓存方案的命中率都会减少,这是因为文件数量增加,用户请求分布更广,热门的内容很大概率被稀释了,然而SBS的缓存容量太有限,无法包含更多的流行文件,导致更多的缓存未命中,这也能进一步地解释随着文件数量增加,命中率减少变缓的原因。
如图10所示,所有方案的系统总时延随着文件数量的增加而增加,与上文命中率分析结果一致,未命中的文件肯定会增加获取时延,在文件数量越来越多时,系统的总时延增加开始变的缓慢,这是因为文件的热度更大程度被稀释,相比于前期文件数量较少时,文件被请求概率差距不大,随后再增加文件数量,系统总的传输时延增加变缓慢。可以看出CBDDPG方案还是明显优于其他三种方案。实验结果表明,本文方案在不同的网络规模下始终能够保持良好的性能,且具有稳定性。
6 结束语
本文主要研究了密集网络中联合缓存放置和内容传输问题,提出方案结合小基站下用户的内容请求特征,利用小基站之间的内容相似性以及基站之间的距离来对小基站进行聚簇,使用层次聚类算法将网络中的所有小型基站进行分组,在分组中采取分布式的协作缓存为用户提供服务。本文将问题建模成一个联合优化长期混合整数的非线性规划问题,并且提出了一种基于深度强化学习的协作边缘缓存和无线资源分配方案来进行决策部署和无线资源分配。仿真结果表明,本文提出的协作缓存与无线资源分配的方案在降低用户请求文件的平均时延方面体现了良好的性能,相比于分层感知的协作缓存方案和汤普森采样的协作缓存算法具有一定的优势。本文没有考虑用户的移动性,也没有研究用户访问文件的潜在规律,这两方面可以作为未来的研究内容。
参考文献:
[1]Mao Yuyi, You Changsheng, Zang Jun, et al. A survey on mobile edge computing: the communication perspective[J]. IEEE Communications Surveys & Tutorials, 2017,19(4): 2322-2358.
[2]李斌, 彭思聪, 费泽松. 基于边缘计算的无人机通感融合网络波束成形与资源优化[J]. 通信学报, 2023,44(9): 228-237. (Li Bin, Peng Sicong, Fei Zesong. Beamforming and resource optimization in UAV integrated sensing and communication network with edge computing[J]. Journal on Communications, 2023,44(9): 228-237.)
[3]Dai Yueyue, Xu Du, Lu Yunlong, et al. Deep reinforcement learning for edge caching and content delivery in Internet of Vehicles[C]//Proc of IEEE/CIC International Conference on Communications in China. Piscataway, NJ: IEEE Press, 2019: 134-139.
[4]李斌. 基于多智能体强化学习的多无人机边缘计算任务卸载[J]. 无线电工程, 2023,53(12): 2731-2740. (Li Bin. Multi-agent reinforcement learning-based task offloading for multi-UAV edge computing[J]. Radio Engineering, 2023,53(12): 2731-2740.)
[5]Zhang Zhengming, Chen Hongyang, Hua Meng, et al. Double coded caching in ultra dense networks: caching and multicast scheduling via deep reinforcement learning[J]. IEEE Trans on Communications, 2020,68(2): 1071-1086.
[6]Zhang Shan, He P, Suto K, et al. Cooperative edge caching in user-centric clustered mobile networks[J]. IEEE Trans on Mobile Computing, 2018,17(8): 1791-1805.
[7]Ale L, Zhang Ning, Wu Huici, et al. Online proactive caching in mobile edge computing using bidirectional deep recurrent neural network[J]. IEEE Internet of Things Journal, 2019, 6(3): 5520-5530.
[8]Hou Tingting, Feng Gang, Qin Shuang, et al. Proactive content ca-ching by exploiting transfer learning for mobile edge computing[J]. International Journal of Communication Systems, 2018, 31(11): e3706.
[9]Yao Jingjing, Han Tao, Ansari N. On mobile edge caching[J]. IEEE Communications Surveys & Tutorials, 2019, 21(3): 2525-2553.
[10]Chang Qi, Jiang Yanxiang, Zheng F C, et al. Cooperative edge ca-ching via multi agent reinforcement learning in fog radio access networks[C]//Proc of IEEE International Conference on Communications. Piscataway, NJ: IEEE Press, 2022: 3641-3646.
[11]Zhang Ke,Leng Supeng, He Yejun, et al. Cooperative content ca-ching in 5G networks with mobile edge computing[J]. IEEE Wireless Communications, 2018, 25(3): 80-87.
[12]Zhou Bo, Cui Ying, Tao Meixia. Stochastic content-centric multicast scheduling for cache-enabled heterogeneous cellular networks[J]. IEEE Trans on Wireless Communications, 2016,15(9): 6284-6297.
[13]Amer R, Butt M M, Bennis M, et al. Inter-cluster cooperation for wireless D2D caching networks[J]. IEEE Trans on Wireless Communications, 2018, 17(9): 6108-6121.
[14]Bastug E, Bennis M, Debbah M. Living on the edge: the role of proactive caching in 5G wireless networks[J]. IEEE Communications Magazine, 2014, 52(8): 82-89.
[15]Wang Qiao, Grace D. Sequence prediction-based proactive caching in vehicular content networks[C]//Proc of the 3rd Connected and Automated Vehicles Symposium. Piscataway, NJ: IEEE Press, 2020: 1-6.
[16]Chang Zheng, Lei Lei, Zhou Zhenyu, et al. Learn to cache: machine learning for network edge caching in the big data era[J]. IEEE Wireless Communications, 2018,25(3): 28-35.
[17]Wu Pingyang, Li Jun, Shi Long, et al. Dynamic content update for wireless edge caching via deep reinforcement learning[J]. IEEE Communications Letters, 2019,23(10): 1773-1777.
[18]Qiao Guanhua, Leng Supeng, Maharjan S, et al. Deep reinforcement learning for cooperative content caching in vehicular edge computing and networks[J]. IEEE Internet of Things Journal, 2020,7(1): 247-257.
[19]Zhu Hao, Cao Yang, Wang Wei, et al. Deep reinforcement learning for mobile edge caching: review, new features, and open issues[J]. IEEE Network, 2018, 32(6): 50-57.
[20]Zhong Chen, Gursoy M C, Velipasalar S. Deep multi-agent reinforcement learning based cooperative edge caching in wireless networks[C]//Proc of IEEE International Conference on Communications. Piscataway, NJ: IEEE Press, 2019: 1-6.
[21]Chen Shuangwu, Yao Zhen, Jiang Xiaofeng et al. Multi-agent deep reinforcement learning-based cooperative edge caching for ultra-dense next-generation networks[J]. IEEE Trans on Communications, 2021, 69(4): 2441-2456.
[22]Lin Peng, Song Qingyang, Jamalipour A. Multidimensional cooperative caching in CoMP-integrated ultra-dense cellular networks[J]. IEEE Trans on Wireless Communications, 2020,19(3): 1977-1989.
[23]Li Ding, Han Yiwen, Wang Chenyang, et al. Deep reinforcement learning for cooperative edge caching in future mobile networks[C]//Proc of IEEE Wireless Communications and Networking Conference. Piscataway, NJ: IEEE Press, 2019: 1-6.
[24]Hsu H, Chen K. A resource allocation perspective on caching to achieve low latency[J]. IEEE Communications Letters, 2016, 20(1): 145-148.
[25]Harper F M, Konstan A J. The MovieLens datasets: history and context[J]. ACM Trans on Interactive Intelligent Systems, 2015,5(4): 1-19.
[26]Ke Zhihui, Cheng Meng, Zhou Xiaobo, et al. Joint cooperative content caching and recommendation in mobile edge-cloud networks[C]//Proc of the 4th International Joint Conference. Cham: Springer, 2020: 424-438.
[27]Ekstrand M D, Riedl J T, Konstan J A. Collaborative filtering recommender systems[M]. [S.l.]: Now Foundations and Trends, 2011: 81-173.
[28]Poularakis K, Iosifidis G, Argyriou A, et al. Caching and operator cooperation policies for layered video content delivery[C]//Proc of the 35th Annual IEEE International Conference on Computer Communications. Piscataway, NJ: IEEE Press, 2016: 1-9.
[29]Cui Laizhong, Su Xiaoxin, Ming Zhongxing, et al. CREAT: blockchain-assisted compression algorithm of federated learning for content caching in edge computing[J]. IEEE Internet of Things Journal, 2022, 9(16): 14151-14161.
