基于深度强化学习的电子政务云动态化任务调度方法
2024-07-31龙宇杰修熙黄庆黄晓勉李莹吴维刚

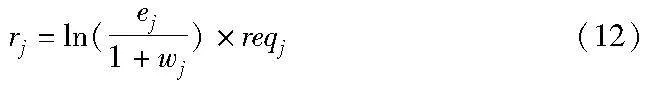

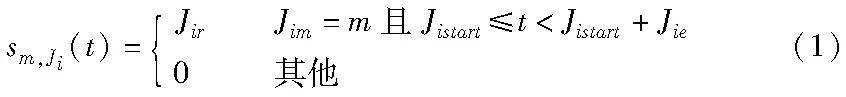
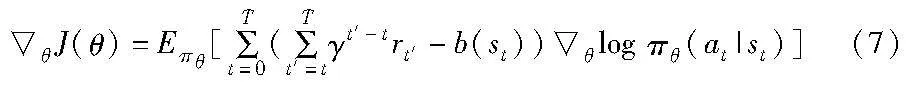
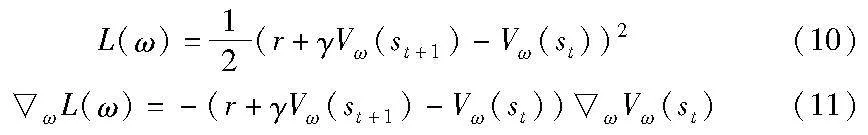

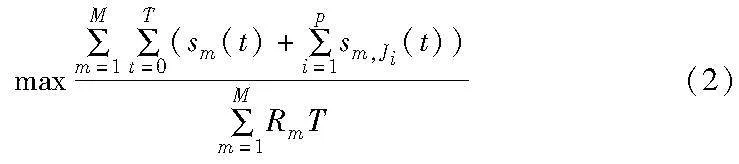
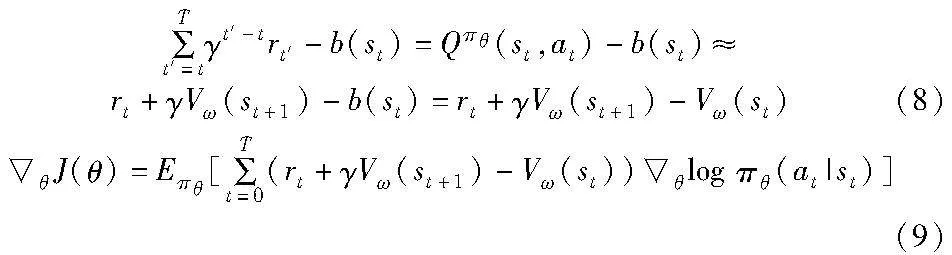

摘 要:电子政务云中心的任务调度一直是个复杂的问题。大多数现有的任务调度方法依赖于专家知识,通用性不强,无法处理动态的云环境,通常会导致云中心的资源利用率降低和服务质量下降,任务的完工时间变长。为此,提出了一种基于演员评论家(actor-critic,A2C)算法的深度强化学习调度方法。首先,actor网络参数化策略根据当前系统状态选择调度动作,同时critic网络对当前系统状态给出评分;然后,使用梯度上升的方式来更新actor策略网络,其中使用了critic网络的评分来计算动作的优劣;最后,使用了两个真实的业务数据集进行模拟实验。结果显示,与经典的策略梯度算法以及五个启发式任务调度方法相比,该方法可以提高云数据中心的资源利用率并缩短离线任务的完工时间,能更好地适应动态的电子政务云环境。
关键词:电子政务; 云计算; 任务调度; 深度强化学习; 演员评论家算法
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)06-028-1797-06
doi:10.19734/j.issn.1001-3695.2023.10.0527
Scheduling of dynamic tasks in e-government clouds usingdeep reinforcement learning
Abstract:The task scheduling of e-government cloud center has always9TdnChA4fnls8NrqKYBRLQ== been a complex problem. Most existing task scheduling solutions rely on expert knowledge and are not versatile enough to deal with dynamic cloud environment, which often leads to low resource utilization and degradation of quality-of-service, resulting in longer makespan. To address this issue,this paper proposed a deep reinforcement learning(DRL) scheduling algorithm based on the actor-critic(A2C) mechanism. Firstly, the actor network parameterized the policy and chose scheduling actions based on the current system state, while the critic network assigned scores to the current system state. Then, it updated the actor policy network using gradient ascent, utilizing the scores from the critic network to determine the effectiveness of actions. Finally,it conducted simulation experiments using real data from production datacenters. The results show that this method can improve resource utilization in cloud datacenters and reduce the makespan in comparison to the classic policy gradient algorithm and five commonly used heuristic task scheduling methods. This evidence suggests that the proposed method is superiorly adapted for the dynamic e-government clouds.
Key words:e-government; cloud computing; task scheduling; deep reinforcement learning; actor-critic
0 引言
经过近20年的发展,云计算[1]已经成为主流的计算模式,为大数据、人工智能、5G等新技术提供算力支持。相应地,国内外机构、实体也建设了大量的云数据中心,为各种各样的计算场景和服务提供基础设施。电子政务云就是面向电子政务应用场景的云计算系统,承载政务信息与数据的分析处理任务,并提供相应的服务功能[2]。
在云计算中,任务调度是分配服务器的计算资源以满足任务请求的过程。高效的调度方法不仅可以提高服务质量,还可以提高数据中心的资源利用率,以降低能耗和成本。因此,设计云数据中心任务调度的解决方案是有意义的,但这是一项具有挑战性的任务。首先,不同的任务具有不同的持续时间和异构的资源需求;其次,云数据中心的可用资源和任务负载都会随时间而变化[3],这些因素增加了任务调度问题的复杂性。
与一般的互联网应用云场景相比,电子政务云的计算任务更多样,用户需求更复杂,因此其数据中心的任务调度更具有挑战性。具体来说,电子政务云中会运行各种在线服务和离线任务,是一种典型的混部形态[4]。
在线服务运行周期较长,对时延要求较高,而且资源使用情况会受到使用习惯的影响,相应地计算需求会呈现比较大的波动性。而离线任务通常是对时延不敏感的计算密集型任务,会尽可能地利用计算资源,对时效性要求不高,通常支持失败重启。两类任务共同部署可以形成互补效应,提高资源的整体效率。但是,由于在线和离线任务的相互干扰,混部形态使得电子政务云的计算任务调度变得更加复杂。
传统的基于规则、启发式、元启发式[5]和控制理论[6]的任务调度方法有很多经典的解决方案。Pradhan等人[7]提出了一种改进的循环资源分配算法,目标是减少任务的等待时间。文献[8]通过为数据中心网络设计能源感知模块和地理负载平衡方案来减少数据中心的能源消耗。文献[9]提出了一种解决Web服务组合问题的线性编程方法,在地理分布式云环境中为每个任务请求选择最高效的服务,以提高QoS标准。文献[10]使用基于规则的控制方法来设计功率感知作业调度程序,以提高功率效率并满足功率限制。受粒子群算法的启发,Kumar等人[11]提出了PSO-COGENT算法,不仅优化了执行成本和时间,还降低了云数据中心的能耗。文献[12]使用了一种受自然启发的元启发式方法,通过关闭闲置的主机来保持云环境中性能和能耗之间的平衡。
尽管这些解决方案可以在一定程度上解决任务调度问题,但它们在很大程度上依赖于先验知识来制定相应的策略。因此,这些解决方案可能在特定场景下运行良好,却无法适应动态的计算场景和环境,例如复杂性较高的电子政务云环境。
以上传统的任务调度方法中,基于控制理论的方法和元启发式方法在得到任务调度方案前,需要经过大量的迭代计算,计算复杂度很高,开销很大。所以此类方法只适用于静态的调度环境,也就是待执行任务都是已知且固定的情况,并不适用于请求任务会不断到达的电子政务云环境。基于规则的方法或者启发式方法,则会根据固定的规则或流程进行计算选择,最后得到调度方案。但这些规则和流程是专家基于云的各种特点而设计出来的,比如对请求任务进行分类,相互干扰比较强的任务不部署在同一台机器等。电子政务云中同时部署了在线任务和离线任务,在线任务长期在云中并且占用的资源会随时间进行波动,离线任务的到达也具有随机性,这种情况下,想要设计一个总体效果较好的启发式算法非常困难。但强化学习(reinforcement learning)[13]的思想能很好地解决此类问题。强化学习的模型能够与环境交互并且给出决策。通过优化机制,模型在与环境交互的过程中,能够学习和理解环境的信息,作出越来越优的决策。在使用强化学习方法的整个过程中,并不需要对环境拥有先验知识,模型是在训练中自动地获取这些知识。
传统的强化学习方法已经成为解决低复杂性的调度问题的一种有效方法。然而,传统的强化学习方法在高维状态空间中并不有效,譬如云数据中心的调度场景。为了解决这个问题,深度强化学习[14]使用了深度神经网络来表示高维信息。目前已经有一些基于 DRL 的方法专注于任务调度问题,其中大多数可以分为基于价值的 DRL[15~18]和基于策略的DRL [19,20]两类。
对于基于价值的 DRL,经典的算法就是深度Q网络(deep Q network,DQN)[21],它根据状态值和转移概率学习策略。文献[15]使用DQN算法来处理云环境中有向无环图(DAG)任务的调度问题。文献[18]基于DQN算法,通过设计与作业的成本、响应时间、执行时间有关的奖励函数来实现高QoS。然而,在电子政务云数据中心中,任务不断到达,状态空间可能相当大且是动态变化的。因此基于价值的深度强化学习模型很难快速收敛到较优解。相比之下,基于策略的DRL,如策略梯度算法(policy gradinet,PG)[22],可以直接输出动作的概率分布,能更好地学习到大动作空间中的优化策略。文献[19]利用基于策略的DRL算法来处理云数据中心的资源分配问题。文献[20]基于PG算法开发了QoS感知调度器,旨在提高云计算中执行深度神经网络推理工作任务时的QoS。但经典的策略梯度方法在估计策略梯度时会产生较高的方差,从而影响训练效率,甚至导致模型不收敛。
作为基于价值和基于策略的DRL算法的综合应用,演员评论家算法(actor-critic,A2C)旨在解决上述问题。在A2C中,actor是基于策略的模型,critic是基于价值的模型,actor根据critic评估的结果去更新参数,以减少策略梯度的方差[23]。受A2C的启发,本文设计了一种基于A2C的数据中心任务调度方法(actor-critor task scheduling,AC-TS),以适应电子政务云的动态性。为了体现电子政务云环境的动态性,仿真实验中的集群环境会同时处理在线任务和离线任务。在线任务是指那些需要长时间占用服务器资源的任务,通常不会终止。这类任务对服务时延比较敏感,数据中心往往需要在短时间内作出响应,而且资源使用情况容易产生波动。例如各种政务信息公开网站提供的检索服务、各种业务办理系统或者应急系统的后台管理服务等。而离线任务通常不需要立刻将结果或消息返回给用户,如果任务失败,还可以接受任务重启,对时效性的要求相对较低,比如舆情分析任务等。这类任务大多是一些计算密集型任务,例如 MapReduce 任务。在线任务一直在服务器上运行,不同时间、不同任务的资源使用模式不同,使得在线任务的负载具有较大波动性。因而集群保留给离线任务的资源量也时时刻刻处于变化之中,这一定程度上体现了云环境的动态性。
由于离线任务不能挤占在线任务的资源,所以在调度时,除了要考虑当前数据中心内资源的可用情况,还要考虑在线任务未来的负载变化,保留一部分资源以应对在线任务的突发负载,尽量减少离线任务被杀掉重启的状况。本文所提方法解决的问题是,在云数据中心运行着一定量在线任务的情况下,对资源需求和资源占用时间已知的离线任务进行调度,以提高数据中心的资源利用率。本文针对具有动态性的电子政务云环境(受在线任务影响)和异构需求的用户任务(不同的离线任务)设计系统调度模型,以CPU利用率、内存利用率和完工时间为优化目标。基于A2C算法,定义了所提调度模型中相关的状态空间、动作空间和奖励函数,并利用电子政务云产生的真实数据集进行了仿真实验,验证其有效性。
1 系统模型描述
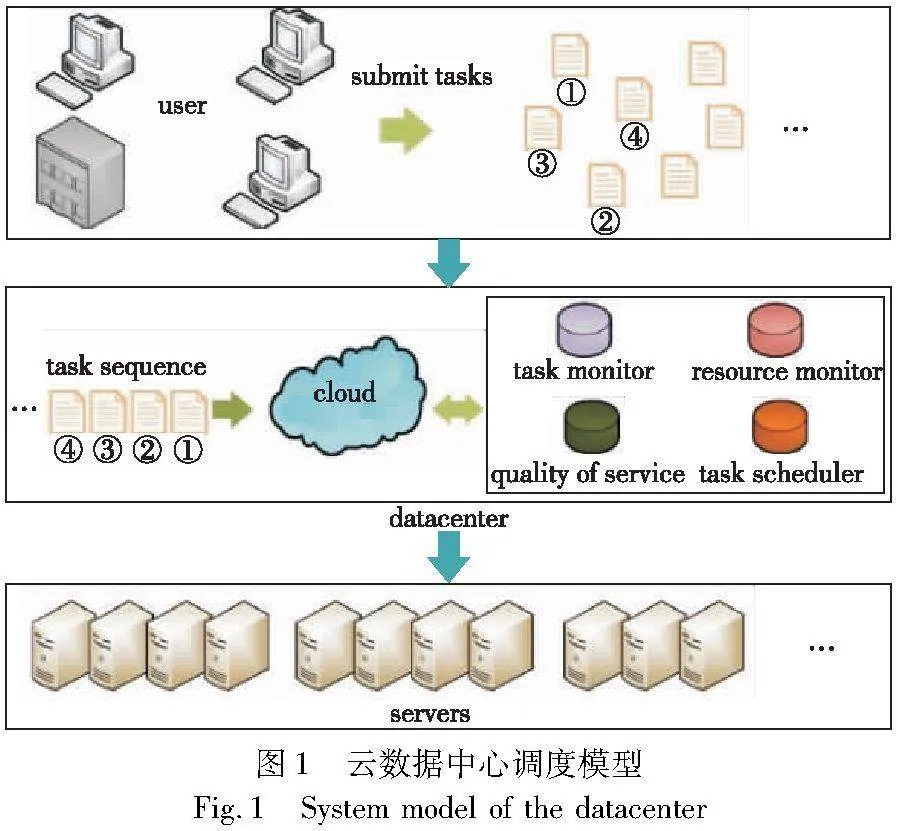
本文抽象出了一种电子政务云数据中心的任务调度系统,该仿真系统的目标是提高集群资源利用率、缩短完工时间。系统模型结构如图1所示。
用户按照自己的需求将任务提交给数据中心。如果是在线任务,就需要长时间占用数据中心的资源;离线任务则需要在任务队列中进行排队,等待数据中心的调度。数据中心有多个模块,它们共同协作,一起负责任务的调度。通过任务监控模块,数据中心可以实时了解用户所提交的任务的信息,包括任务的执行时间、资源需求量等;通过资源监控模块,数据中心可以了解当前集群的资源使用情况,比如当前集群的资源利用率、每台服务器的资源清单、剩余资源量等;服务管理模块需要对用户所提交的任务进行监测,尤其是对在线任务,要保证服务的质量不受影响。任务调度器是一个基于DRL的代理,它接收到集群的状态信息后,生成调度决策并将任务序列中的任务分配给服务器。
为了阐明系统模型,本文考虑具有多个服务器的云数据中心。云数据中心的服务器数量为M,第m台服务器所拥有的资源量为Rm,如果服务器有多种类型的资源可供使用,比如资源类型数为N,则服务器上的资源清单可以表示为Rm=[R1,R2,…,RN],本文只考虑CPU资源和内存资源,因此N=2。
对于在线任务,由于其需要长时间占用服务器的一部分资源,并且其使用的资源量随时间动态变化,所以每个在线任务的资源占用量是一条波动的曲线。在仿真系统中,本文假设每台服务器上部署的在线任务都是固定的(实际生产集群也是如此),并且每个在线任务的资源占用量曲线都是已知的(通过真实数据集的记录)。因此可通过相加,把第m台服务器上所有在线任务占用的资源抽象为一条已知的时间序列sm,每个时间点的数据项是N维的,对应不同的资源。
对于具有周期性的在线服务来说,通过一些预测算法可以预测其资源使用曲线。比如文献[24]通过使用整合移动平均自回归模型预测Web服务器的资源使用情况,谷歌的Borg系统使用指数平滑方法[25]对在线任务的资源需求进行预测。而近年来,深度学习方法的发展也带动了资源预测领域的进步[26]。因此使用时间序列sm作为第m台服务器上在线任务的资源使用曲线是合理的。
将服务器的可用资源量Rm减去在线服务的资源量sm后,就是离线任务可以使用的资源量。AC-TS算法主要解决的就是离线任务的调度问题,重点是如何调度离线8ad07d5a008e0d8f0db03e7aaa359d67任务,使得集群资源利用率尽可能高。假设整个仿真集群从0时刻开始运行,总运行时间为T(仿真实验中以最后一个离线任务完成的时间,即完工时间作为结束时间T),集群共有M台机器,第m台机器的总资源为Rm,该机器上在线任务资源占用曲线为sm。在时刻t,在线任务对服务器m的资源占有量为sm(t)。在整个集群的运行时间T内,用户提交的总的离线任务共有p个(从真实数据集中选择p个),记为Jobtotal={J1,J2,…,Jp}。
在数据中心中,用户提交的第i个离线任务Ji,会先在队列Q中等待被调度。每次调度时,调度器会从队列中取出决定调度的任务,部署到相应的服务器上。对于任务Ji,其具体信息包括到达时间Jia,运行时间Jie以及任务的资源需求情况Jir。在调度成功开始执行的时候,任务监控模块还会记录任务开始执行的时间Jistart和执行的机器Jim。
任务Ji在时刻t对服务器m占用的资源如式(1)所示。
调度的目标是最大化资源利用率,其本质上是一个最优化问题,所提算法要解决的调度问题可以定义为
受约束于以下条件:
超过除去在线任务后的资源剩余量Rm-sm(t)。
任务等待队列Q中等待的任务记为Jseq={J1,J2,…,Jq},其中q表示等待队列中作业的数量,有q≤p。当一个作业从Jobtotal到达时,它首先要进入任务等待队列。如果队列满了,则在任务到达缓存区等待(假定缓存区无限大)。任务进入等待队列Q后如果调度器决定调度此任务,该任务会立即开始执行;否则,它将在队列中等待。在该系统中,不考虑对任务的到达速率作出设置,调度器只能观察到指定长度的任务等待队列Q,当任务等待队列中的任务数量不足时,若任务到达缓存区还有多余的任务,则会对任务等待队列进行补齐,使其保持在固定长度。如果调度器在当前时刻能够大量调度任务,那么保持等待队列长度相当于任务的到达速率增加。当Jobtotal中的任务是固定的情况下,假定集群系统的运行时间T为执行完Jobtotal中所有任务的时间,即任务完工时间。那么提高集群的资源利用率,就相当于减少所有任务的最大完工时间,即最后一个任务的完成时间。
2 AC-TS算法设计
2.1 演员评论家算法
actor-critic算法主要由两个部分组成。 actor网络本质上是一个策略梯度模型,它可以在动作空间内选择一个合适的动作,从而使系统环境转移到下一个状态。但普通的策略梯度模型是基于一个完整的动作序列的奖励值来进行更新的,其学习效率很低。这时候使用一个基于价值的算法模型,如DQN,作为critic网络来进行辅助,就可以使用TD方法实现actor网络的单步更新,从而加快模型的训练速度。actor与critic两个网络相互协作就形成了actor-critic算法。Vπ(s)表示马尔可夫决策过程(Markov decision process,MDP)中的状态价值函数,它表示从状态s出发,遵循策略π能获得的期望反馈奖励。Qπ(s,a)表示MDP中的动作价值函数,表示对当前状态s执行动作a得到的期望奖励。假设当前时刻为t,根据定义有式(4):
Qπ(st,at)=rt+γVπ(st+1)(4)
其中:γ表示模型的折扣因子;at表示时刻t选择的动作;st表示时刻t的系统状态;rt表示动作at的反馈奖励。
假定策略网络πθ是一个神经网络模型,θ是对应的参数,s0是系统环境的初始状态,在普通的策略梯度方法中,策略学习的目标函数如式(5)所示。
由式(6)可以看出,模型必须采样一条或者多条完整的轨迹后(和环境交互T步得到的轨迹),根据轨迹中的所有(st,at,rt)记录,计算出每一个状态动作对(st,at)的累计获得奖励,才能计算梯度,更新网络。但是在真实的训练过程中,无法完成足够数量的采样,而有限次的采样并不能很好地代表轨迹真实的期望,会引入较大的方差,这是蒙特卡罗方法的缺陷,没有偏差但是方差大。为了减少方差,可以引入基线函数b(st),b(st)最好是使用Vπ(st)。所以基于有限采样的情况下,一般选用st状态下取得的累计奖励的平均值作为基线函数值。此时式(6)可以转换为式(7)。
actor-critic算法的主要思想就是引入基于DQN的critic网络作为评分网络。actor网络是一个如上所述的策略梯度模型。actor网络每次计算梯度,更新网络,状态动作对(st,at)的累计奖励用critic网络输出的状态价值来表示。并且critic网络通过仿真系统反馈的真实rt值来训练自身,使得critic网络精度越来越高。
将critic价值网络表示为状态价值函数Vω,其中ω表示网络参数。Vω(st)表示在系统状态st下,critic网络输出该状态的期望价值。通过时序差分(temporal difference)[27]的方法,并且使b(st)=Vω(st),可以得到式(8)。此时式(7)可以转换为式(9),虽然引入了一定的估计偏差,但降低了采样数据的方差的影响。
在actor网络的优化更新过程中,critic网络也需要优化更新。critic网络可以直接使用均方误差作为损失函数,如式(10)所示。其中rt+γVω(st+1)作为真值,Vω(st)作为预测值。求导可得梯度计算的方式如式(11)所示,使用梯度下降方法来更新参数即可。
2.2 状态空间设置
假定云集群的服务器数量为M,集群内的可用资源种类为N,对于第m个服务器,在时刻t,其可用资源为Rmt=[r1t,r2t,…,rNt]。因此在时刻t,集群的服务器状态信息可以表示为sMt=[R1t,R2t,…,RMt]。假定时刻t,任务等待队列中的任务数为J,对于任务队列中的离线任务j,其任务的运行时间为ej,所需要的计算资源为reqj=[r1j,r2j,…,rNj],任务自提交到任务队列Q后,其等待时间为wj。则时刻t,所有离线任务状态信息为sJt=[req1,…,reqJ,w1,w2,…,wJ,e1,e2,…,eJ]。将所有服务器的状态信息和任务等待队列中所有任务的状态信息拼接起来就是整个系统的当前状态。所以在时刻t的系统状态表示为st=[sMt,sJt]。
2.3 动作空间
算法的状态空间是智能体所能执行的动作集合。在前面所述的调度系统模型中,智能体充当调度器的作用。智能体的动作是将任务和服务器进行匹配,所以输出的动作是任务和服务器的元组,即(n,m),表示将任务n分配至服务器m。在调度过程中,如果智能体要通过一次决策将所有N个任务调度到相应的服务器上,那么解空间的大小为NM,很明显,这一搜索空间的数量级是指数级的。对此,AC-TS将一个时间步的调度决策分解为一串序贯决策,也就是智能体的一次决策是为队列中某个任务从M个服务器中选择一个服务器进行运行。而在每次调度,智能体可以执行多次决策,对多个任务进行匹配,从而调度多个任务,直至无法调度。假设当前等待队列有J个任务,并且触发了调度,则该次调度过程中,强化学习模型实际上连续作出了J次动作决策,每次的动作at都是针对单个任务。此时调度动作的空间大小可以减小为M。
需要注意的是,在调度过程中,智能体可能不会把每个任务都选择调度到服务器上运行。出于对任务调度整体的考虑,可能会选择不调度当前的任务。所以在动作空间内需要加入一个维度,表示不执行调度的动作,因此动作空间可以表示为A={at|at∈[0,1,2,…,M]},at=0代表不执行调度,动作空间的大小为(M+1)。
2.4 奖励函数
2.1节中有说到每次智能体作出一次决策,仿真环境必须给出一个实时的动作反馈奖励r。该奖励是根据具体任务、优化目标等因素,由人工设计的,目的是指导智能体更好地学习。
实时动作反馈奖励一般由函数给出,该函数称作奖励函数。为了智能体代理能学习到更好的任务调度策略,对奖励函数进行设计时,要考虑到整个调度过程。可以预想到,对数据中心的资源利用率来说,如果能够将任务尽早地调度到服务器上进行处理,那么集群内的资源碎片就会尽可能少,从而提高集群的资源利用率。那么,为了提高集群的资源利用率,要使整个调度过程的时间尽可能缩短,也就是缩短任务的等待时间。同时要考虑到任务所需资源量的影响,因为智能体可能会将资源需求量大、执行时间长的任务放置在任务队列中持续等待,所以应该提高调度大任务的动作的反馈奖励,从而使得智能体代理考虑调度等待时间较长的大任务。
基于以上的考量,每成功调度一个任务j,得到的反馈奖励rj如式(12)所示。
用等待时间wj来反映完工时间的重要性。智能体代理需要学会让完工时间尽可能短,因此每个任务的等待时间越小越好,奖励与任务的等待时间wj呈负相关。为了避免智能体代理倾向于分配少资源且执行时间短的任务,将执行时间ej放在括号里面分子位置上,括号里面是执行时间和等待时间的比值,通过一个对数计算,使得该值映射到实数域。最后再乘以资源需求reqj。本文考虑CPU和内存资源,因此该值具体计算时为CPU资源需求乘以内存资源需求,为一个标量。反馈奖励与执行时间ej、资源需求reqj正相关。智能体会选择调度具有更多奖励的任务,而不仅仅是资源需求少、执行时间短的任务。当智能体选择不执行调度或调度失败时,反馈奖励为0。
2.5 模型训练
基于第1章所述的仿真环境,使用AC-TS作为仿真环境中的调度器,在调度过程中对其进行训练。每次调度的时间间隔是一个超参数。本文对数据集中的离线任务数据进行了分析,发现90%的离线任务执行时间处于几秒到几百秒的区间内,所以选择了每30 s进行一次调度。
每次宏观的调度中,智能体根据当前系统状态st,针对当前所选任务,选择一个动作at,如果该动作表示不执行调度,则反馈奖励为0。如果执行调度,则仿真系统会尝试把任务调度到对应机器上。如果调度成功,则反馈奖励由式(12)计算。如果服务器资源不足调度失败,反馈奖励则为0,并且该任务重新返回等待队列。接着系统进入下一个状态st+1,智能体针对下一个任务作出动作at+1。当智能体对当前等待队列中的所有任务都作出决策动作后,仿真系统会进入到下一次调度,也就是30 s后,此时集群资源和等待队列都会有新的状态。
基于所选用的状态空间、动作空间及奖励函数,AC-TS算法的步骤如算法1所示。其中:epoch为训练轮数,每一轮为一次完整的执行所有离线任务的过程;J代表每一次触发调度时,等待队列中的离线任务个数。第10、11步的更新网络公式具体如式(9)(11)所示。
算法1 基于A2C的调度算法流程
3 实验验证
3.1 系统模型参数
本文的仿真实验基于真实电子政务云集群上记录的两个日志数据集。其中在线应用包括各种政府信息公开网站、政务服务网站、政务服务小程序的后台服务程序,还有一些政府内部的管理系统、业务办理系统等。而离线应用则有舆情分析、政务大数据搜索任务、政务大数据的数据挖掘任务等。
日志数据集中,对于在线任务,数据集记录了2万多个时间点的在线任务资源占用量。对于离线任务,则记录了大量的任务信息,包括任务的执行时间、所需资源量等, 一般离线任务的运行时间有限,所以过滤了运行时间大于1 000 s的离线任务。对于服务器集群,本文设置10台同构模拟服务器,为计算任务提供CPU和内存两种资源,智能体所能观察到的任务队列的长度为200,每台服务器的CPU数量为10,内存大小为4。
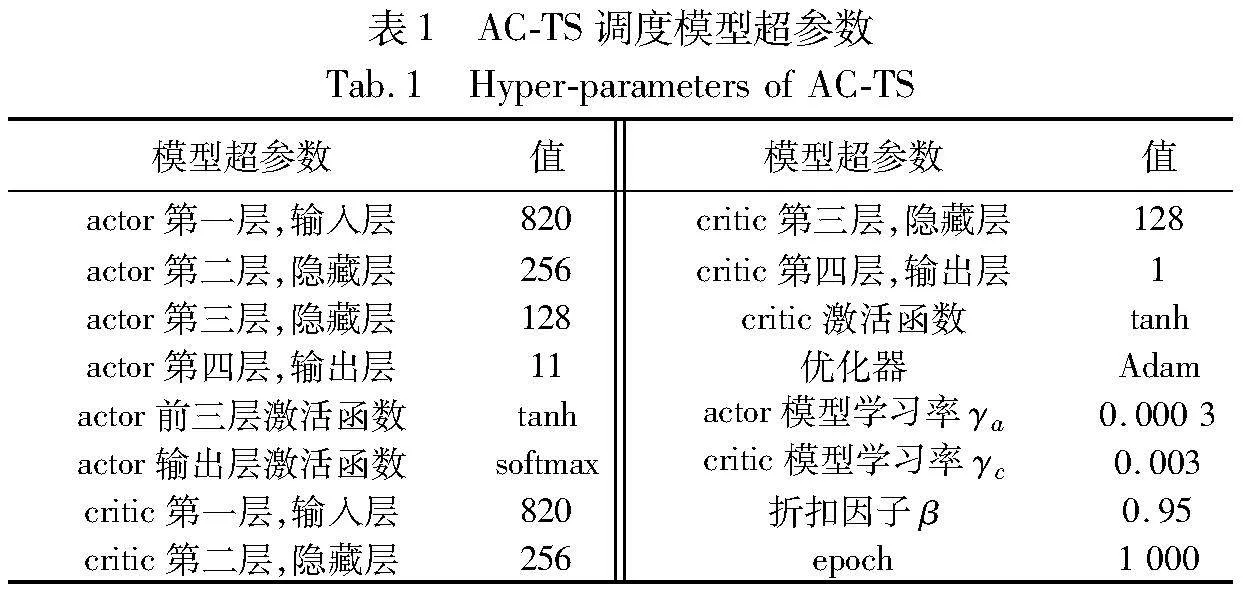
而A2C调度模型中,一些相关的超参数如表1所示。基于这些设置,本文进行了大量的模拟实验来评估所提算法的性能。
3.2 实验环境
本实验所使用的硬件和软件配置如下:CPU为12核Intel CoreTM i7-8700K 3.70 GHz CPU;内存为32 GB DDR4内存;Python版本为3.8.5;算法模型由PyTorch 1.12.1实现,使用CPU进行训练。
3.3 对比算法介绍
为了评估云数据中心任务调度算法,在同一系统中采用了几种启发式方法和经典的策略梯度算法。a)首次适应(first fit):将任务分配给第一个满足资源需求的服务器;b)随机调度(random):调度器从所有满足任务资源需求的服务器中,随机选择一个服务器来执行任务;c)最短任务优先(shortest first):优先执行等待队列中执行时间最短的任务;d)最小成本优先(mincost first):将任务的执行时间与所需资源量相乘得到成本值,再更具成本值排序,优先执行成本小的任务;e)循环执行(round robin):各个机器循环地执行等待队列中的任务;f)策略梯度(policy gradient)[28]:基于深度强化学习的方法,调度动作由策略神经网络输出的概率分布确定,通过蒙特卡罗方法采样数据进行更新。
3.4 模型收敛效果
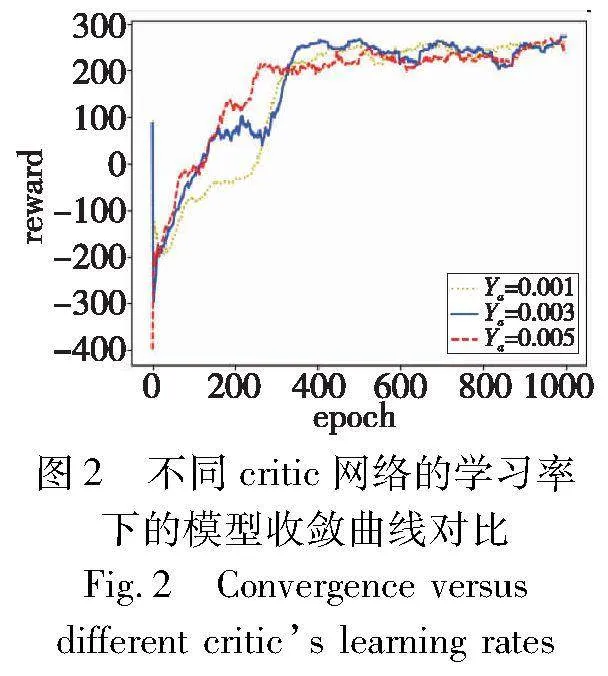
如果所提模型经过多轮训练依旧不能收敛到一个较优的结果,则说明该模型不适合处理该任务,无法通过训练自主学习到处理该任务的相关知识。此外,不能收敛还有可能是模型之外的一些超参数配置所导致。为了评估所提调度算法的收敛性,即算法的有效性,本文通过实验观察了模型的收敛效果,如图2、3所示。横坐标为每一次仿真所得到的总体奖励得分,也就是调度完所有离线任务得到的总分。可以看出,模型最终都能收敛到稳定的结果。
本文还分析了两个基本参数对模型收敛的影响,包括actor网络的学习率γa和critic网络的学习率γc,通过实验,最终选择了两个效果较优的数值进行后续实验。
首先,将γa固定设置为0.000 3,γc的值分别设置为0.001、0.003和0.005。如图2所示,虽然当γc为0.005时曲线收敛得更快,但在400个epoch后,总体来看,γc为0.003时调度过程的累积奖励略高。由于γc为0.003时奖励较高且较稳定,所以在后续的实验中把γc的值固定设置为0.003。几条不同γc值的曲线,都在训练开始时呈下降趋势,但经过几个epoch后,趋势发生逆转,累计奖励慢慢提升。这意味着智能体可以通过更新网络参数来探索更高的调度奖励,AC-TS算法在该场景下是有效的。
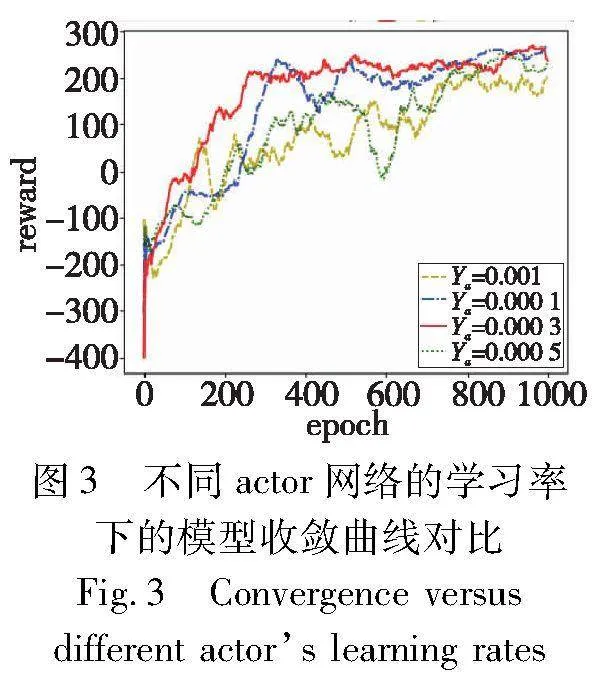
接下来,把γc的值固定为0.003,γa分别设置为0.001、0.000 1、0.000 3、0.000 5。如图3所示,与其他值相比,当γa为0.000 3时,奖励曲线收敛得最快,而且可以获得较高的奖励且比较稳定。当γa为0.001时,曲线需要很长时间才能收敛,并且最终奖励比任何其他值都小。因此,接下来的实验选用0.000 3作为γa的值。
3.5 不同任务数量下的调度过程比较
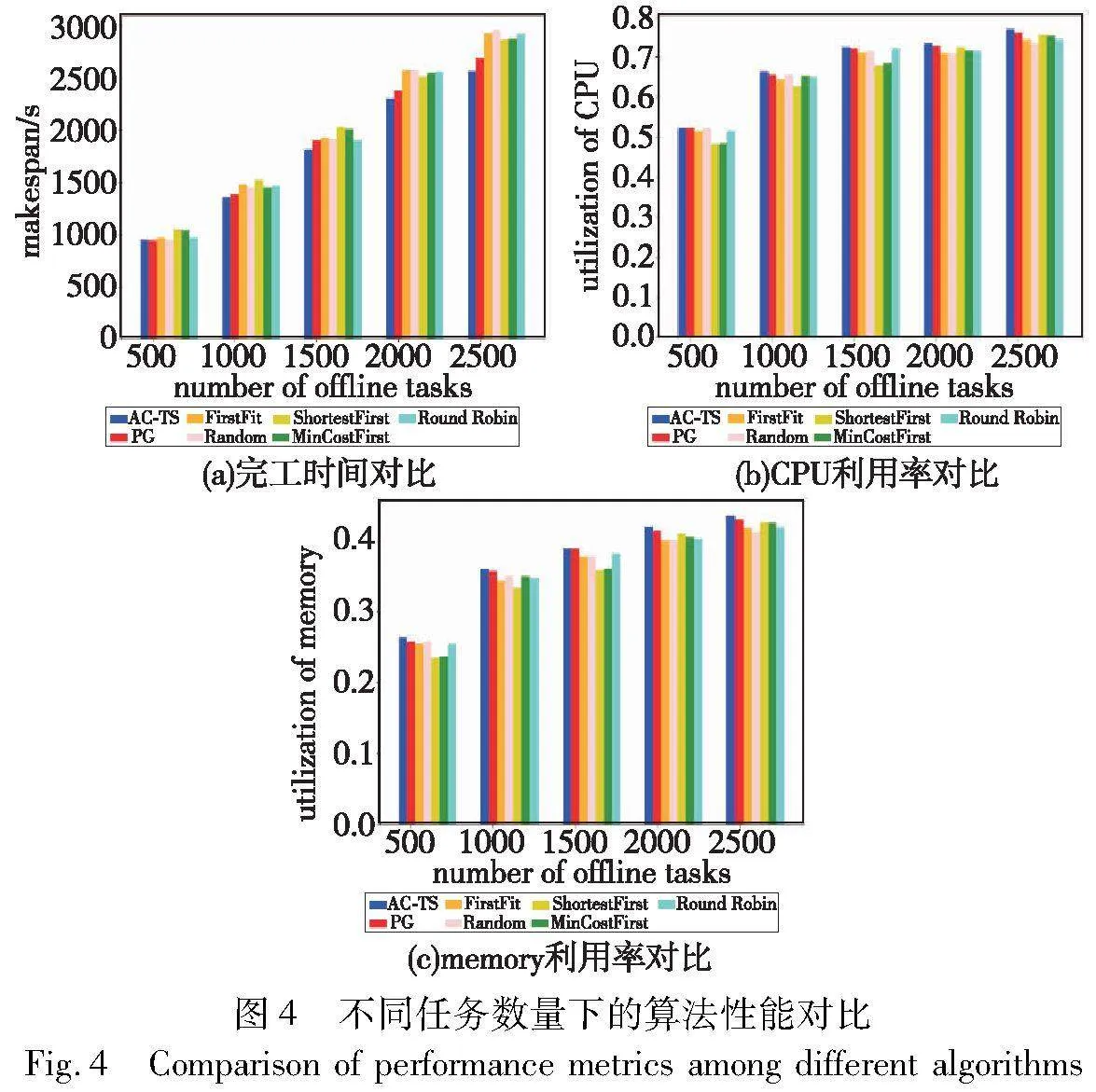
所提A2C任务调度算法性能将通过以下几个指标进行评估:完工时间、CPU利用率和内存利用率。实验过程中改变调度过程的总任务数量,并将所提算法与3.3节提到的其他方法进行比较。从图4(a)可以看出,在任务量为500时, AC-TS和其他算法的最大完工时间相差不大,甚至略大于策略梯度算法,其原因是任务队列中的任务量较少,集群资源相对充足,调度过程的优化也有限。
随着任务数量的增加,AC-TS可以考虑到整体任务之间的影响,总是能达到这些方法中最低的完工时间。当任务数大于1 500时,AC-TC的完工时间明显小于其他方法;尤其是任务量从2 000增加到2 500时,其最大完工时间的上升幅度较其他算法明显下降。
图4(b)(c)中CPU和内存的利用率随着任务数量的增加而升高,而所提AC-TS算法的资源利用率总是这些方法里面最高的,体现了AC-TS对这种动态性的云调度场景的有效性。
4 结束语
为了解决电子政务云数据中心的计算任务调度问题,抽象出了一种含有动态性的任务调度系统,并且提出了一种基于深度强化学习的AC-TS方法用于调度。对于该方法,在不同的任务数量规模下进行实验验证并和其他方法对比,结果表明:AC-TS在动态云环境中的任务调度优于几种经典的启发式方法和普通强化学习算法,并且任务数量规模越大,优化效果越好。本文合理地把单个时间片内的任务调度过程抽象为MDP中多次决策的过程,有效地减少了算法的动作空间大小,并且在奖励函数的设置中,综合考虑多个与调度目标有关的因素,使得AC-TS算法可以有效地进行训练,获得较好的性能。
除了在线任务导致的电子政务云环境的动态变化,还有其他多种影响任务调度的因素。比如多云的任务调度,除了考虑任务所需要的资源,还需要考虑一些其他因素比如数据中心的异构资源、负载均衡等。此外,还有更复杂的任务类型,比如工作流任务。工作流任务的子任务之间是有依赖关系的,它们的调度问题复杂性更高,在动态环境下调度它们具有更大的挑战性,这些都是进一步研究的方向。
参考文献:
[1]Rahimikhanghah A, Tajkey M, Rezazadeh B, et al. Resource sche-duling methods in cloud and fog computing environments: a systematic literature review[J]. Cluster Computing, 2022,25: 1-35.
[2]王会金, 刘国城. 大数据时代电子政务云安全审计策略构建研究[J]. 审计与经济研究, 2021,36(4): 1-9. (Wang Huijin, Liu Guocheng. Research on the construction of e-government cloud secu-rity audit strategy in the era of big data[J]. Audit and Economic Research, 2021,36(4): 1-9.)
[3]Chen Zheyi, Hu Jia, Min Geyong, et al. Towards accurate prediction for high-dimensional and highly-variable cloud workloads with deep learning[J]. IEEE Trans on Parallel and Distributed Systems, 2019,31(4): 923-934.
[4]Zhan Yong, Ghamkhari M, Akhavan-Hejazi H, et al. Cost-aware traffic management under demand uncertainty from a colocation data center user’s perspective[J]. IEEE Trans on Services Computing, 2018,14(2): 400-412.
[5]Nekooei-Joghdani A, Safi-Esfahani F. Dynamic scheduling of independent tasks in cloud computing applying a new hybrid metaheuristic algorithm including Gabor filter, opposition-based learning, multi-verse optimizer, and multi-tracker optimization algorithms[J]. The Journal of Supercomputing, 2022,78(1): 1182-1243.
[6]Avgeris M, Dechouniotis D, Athanasopoulos N, et al. Adaptive resource allocation for computation offloading: a control-theoretic approach[J]. ACM Trans on Internet Technology, 2019,19(2): 1-20.
[7]Pradhan P, Behera P K, Ray B N B. Modified round robin algorithm for resource allocation in cloud computing[J]. Procedia Computer Science, 2016,85: 878-890.
[8]Chen Tianyi, Marques A G, Giannakis G B. DGLB: distributed stochastic geographical load balancing over cloud networks[J]. IEEE Trans on Parallel and Distributed Systems, 2016,28(7): 1866-1880.
[9]Ghobaei-Arani M, Souri A. LP-WSC: a linear programming approach for Web service composition in geographically distributed cloud environments[J]. The Journal of Supercomputing, 2019,75(5): 2603-2628.
[10]Wang Jun, Han Dezhi, Wang Rruijun. A new rule-based power-aware job scheduler for supercomputers[J]. The Journal of Supercomputing, 2018,74: 2508-2527.
[11]Kumar M, Sharma S C. PSO-COGENT: cost and energy efficient scheduling in cloud environment with deadline constraint[J]. Sustainable Computing: Informatics and Systems, 2018,19: 147-164.
[12]Medara R, Singh R S. Energy-aware workflow task scheduling in clouds with virtual machine consolidation using discrete water wave optimization[J]. Simulation Modelling Practice and Theory, 2021,110: 102323.
[13]Daoun D, Ibnat F, Alom Z, et al. Reinforcement learning: a friendly introduction[C]//Proc of International Conference on Deep Lear-ning, Big Data and Blockchain. Cham: Springer International Publishing, 2021: 134-146.
[14]Franois-Lavet V, Henderson P, Islam R, et al. An introduction to deep reinforcement learning[J]. Foundations and Trends in Machine Learning, 2018,11(3-4):219-354.
[15]Bi Jing, Yu Zhou, Yuan Haitao. Cost-optimized task scheduling with improved deep Q-learning in green data centers[C]//Proc of IEEE International Conference on Systems, Man, and Cybernetics. Pisca-taway,NJ:IEEE Press, 2022: 556-561.
[16]Tong Zhao, Chen Hongjian, Deng Xiaomei, et al. A scheduling scheme in the cloud computing environment using deep Q-learning[J]. Information Sciences, 2020,512: 1170-1191.
[17]Ding Ding, Fan Xiaocong, Zhao Yihuan, et al. Q-learning based dynamic task scheduling for energy-efficient cloud computing[J]. Future Generation Computer Systems, 2020, 108: 361-371.
[18]Cheng Long, Kalapgar A, Jain A, et al. Cost-aware real-time job scheduling for hybrid cloud using deep reinforcement learning[J]. Neural Computing and Applications, 2022,34(21): 18579-18593.
[19]Mao Hongzi, Alizadeh M, Menache I, et al. Resource management with deep reinforcement learning[C]//Proc of the 15th ACM Workshop on Hot Topics in Networks. New York:ACM Press,2016: 50-56.
[20]Fang Zhou, Yu Tong, Mengshoel O J, et al. QoS-aware scheduling of heterogeneous servers for inference in deep neural networks[C]//Proc of ACM on Conference on Information and Knowledge Management. New York:ACM Press,2017: 2067-2070.
[21]Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533.
[22]Sutton R S, McAllester D, Singh S, et al. Policy gradient methods for reinforcement learning with function approximation[C]//Proc of the 12th Internation Conference on Neural Information Processing System. Cambridge, MA:MIT Press, 1999:1057-1063.
[23]Cui Haoran, Wang Dongyu, Li Qi, et al. A2C deep reinforcement learning-based MEC network for offloading and resource allocation[C]//Proc of the 7th International Conference on Computer and Communications. Piscataway,NJ:IEEE Press,2021: 1905-1909.
[24]Calheiros R N, Masoumi E, Ranjan R, et al. Workload prediction using ARIMA model and its impact on cloud applications’QoS[J]. IEEE Trans on Cloud Computing, 2014,3(4): 449-458.
[25]Rzadca K, Findeisen P, Swiderski J, et al. Autopilot: workload autoscaling at Google[C]//Proc of the 15th European Conference on Computer Systems. New York:ACM Press, 2020: 1-16.
[26]Liu Minhao, Zeng Ailing, Xu Zhijian, et al. Time series is a special sequence: forecasting with sample convolution and interaction[EB/OL]. (2021). https://arxiv.org/abs/2106.09305.
[27]Sutton R S. Learning to predict by the methods of temporal differences[J]. Machine Learning, 1988, 3: 9-44.
[28]陈中柘, 刘宇, 朱顺鹏,等. 基于深度强化学习的柔性车间动态调度方法及仿真[J]. 实验室研究与探索, 2023,42(4): 107-111,117. (Chen Zhongzhe, Liu Yu, Zhu Shunpeng et al. Flexible workshop dynamic scheduling method and simulation based on deep reinforcement learning[J]. Laboratory Research and Exploration, 2023,42(4): 107-111,117.)
