基于深度学习的融合流程多视角行为分析:预测业务流程监控
2024-07-31袁永旺方贤文卢可

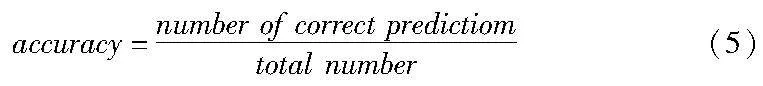




摘 要:预测性业务流程监控(PBPM)是业务流程管理(BPM)中的一个重要研究领域,旨在准确预测未来的行为事件。目前,PBPM研究中广泛引用了深度学习方法,但大多数方法只考虑单一的事件-控制流视角,无法将属性-数据流视角与之结合进行流程预测。针对这一问题,提出了一种基于双层BERT神经网络和融合流程多视角行为分析方法(简称FMP框架)。首先,基于第一层BERT学习属性-数据流信息;接着,基于第二层BERT学习事件-行为控制流信息;最后,通过FMP框架融合数据流和控制流实现多维视角流程预测。在真实的事件日志中的实验结果表明,相比其他研究方法,基于FPM框架预测下一个事件的活动精度更高。这证明融合流程多视角的FMP框架能够更全面、更深层次地分析复杂的流程行为,并提高预测的性能。
关键词:业务流程管理; 业务流程预测监控; 深度学习; 注意力机制; 数据流视角; 控制流视角
中图分类号:TP39 文献标志码:A
文章编号:1001-3695(2024)06-027-1790-07
doi:10.19734/j.issn.1001-3695.2023.10.0526
Multi-perspective behavior analysis of fusion processes based ondeep learning: predictive business process monitoring
Abstract:Predictive business process monitoring(PBPM) represents a vital research field within BPM that aims to accurately predict future behavioral events. At present, deep learning methods are widely used in PBPM research. However, most of these methods consider only a single event-control flow perspective and do not fuse the attribute-data flow perspective for process prediction. To address this issue,this paper proposed a method called the fusion multi-perspective(FMP) framework based on a two-layer BERT neural network. Firstly, the first layer of BERT was used to learn attribute-data flow information. Subsequently, the second layer of BERT learnt event-behavior control flow information. Finally, the FMP framework combined data flow and control flow to achieve multi-perspective process prediction. Experimental results on real event logs demonstrate that, compared to other research methods, the FPM framework yields higher accuracy in predicting the next event activity. This validates that the FPM framework, which merges multi-perspective views of processes, enables a more comprehensive and in-depth analysis of complex process behaviors while enhancing predictive performance.
Key words:business process management(BPM); business process prediction monitoring; deep learning; attention mechanism; data flow perspective; control flow perspective
0 引言
业务流程管理BPM通常由事务信息系统监控,这些系统生成大量的事件日志数据集。预测性业务流程监控PBPM是业务流程管理BPM中一项关键而重要的工作。PBPM从事件日志的历史数据中对过程行为进行分析,旨在通过预测运行流程实例的未来行为,来避免业务流程案例中的资源冲突和执行超时[1],从而提高业务流程的质量和效率。例如,帮助管理者了解企业内部的重要交易或流程(贷款申请、纳税申报、保险索赔等),通过数据和行为找出关键业务问题。
然而,目前的PBPM研究领域大多侧重于从单一视角进行分析,无法确保预测过程从全局视角出发,进而导致预测结果存在偏差或局限性。例如,在最近的研究中,Hinkka等人[2]提出了一种新的基于RNN神经网络模型的聚类技术。在特定情况下,通过将原始事件的属性数据值相结合,可以提高预测精度。在另一项工作中,Evermann等人[3]也使用RNN来预测下一个事件。该方法的核心是通过连接属性数据值和在嵌入空间中的编码来构造RNN输入,以提高过程模型的预测精度。然而,在上述研究中,只基于属性数据流的单一视角进行了过程预测,而忽略了控制流视角中的过程行为和逻辑关系。Tax等人[4]将LSTM网络应用于业务流程预测,其方法可以预测下一个活动和运行案例的继续,直到其完成。但是,它们只使用控制流来表示整个事件日志,而忽略了数据流中的其他重要属性值,并不能确保事件日志的完整性。
上述方法都有着突出的局限性:a)仅从单一视角(控制流或数据流)分析流程行为,忽视了其他视角的数据信息对预测性能的影响,因而无法同时考虑所有视角;b)采用RNN或LSTM神经网络会带来梯度爆炸和缺乏并行处理能力等关键问题。
本文注意到多视角技术在BPM应用中取得了较好的性能,例如Guzzo等人[5]通过基于LSTM模型和多视角方法,极大地提高了两个数据集的分类和聚类任务的性能。
因此,针对上述方法在PPBM领域的局限性,本文提出了一种基于双层BERT和多视角数据融合的方法(简称FMP框架),以克服这些独特的挑战。与之前的方法不同,FMP框架通过独特的分层BERT网络,有效地融合了数据流视角和控制流视角,实现了全面的多维视角分析。此外,它还解决了神经网络中 RNN 和 LSTM 存在的严重梯度爆炸问题。本文的贡献如下:a)来自五个真实事件日志的实验结果表明,本文FMP框架显著提高了BPM的预测性能,预测精度超过了目前最先进的研究方法;b)本文FPM框架通过双层BERT,能够解决PPBM仅从单一视角进行过程预测的问题。(a)第一层BERT模型,学习属性-数据流视角中不同类别属性在事件中的分配权重,确定哪些属性及数据对事件的影响权重占比更大。(b)第二层BERT模型,在事件控制流视角中,当多个连续事件发生时,学习不同的事件对预测未来即将发生事件之间的相关性,自动识别每个事件对未来预测事件的影响程度及优先关系。
1 相关工作
关于分析事件日志中的过程行为所产生的数据和在线预测性业务流程管理监控在学术界是一个热点。传统方法依赖于隐马尔可夫模型或状态转换系统中的显式过程模型。Lakshmanan等人[6]提出一个特定实例的隐马尔可夫模型。Letham等人[7]提出一种基于贝叶斯规则列表的生成模型。尽管以上方法具有较好的预测结果,但只适用于短而简单的过程情况。当出现过程情况长且复杂时,预测结果的准确性就会明显降低。
随着深度学习技术的出现,这个问题得到了改进。Rama-Maneiro等人[8]对使用深度学习技术解决预测任务的方法进行了系统的回顾。文献[9]基于初始CNN模型对事件的活动进行预测,目的是研究使用一维CNN是否能与RNN作比较。Pasquadibisceglie等人[10]利用卷积神经网络为业务流程的执行场景提供了一种预测运行迹中的下一个活动的方法。文献[11]使用基于RNN的预测模型,将多个属性编码为事件的附加信息,以预测下一个事件及其属性;通过每个属性的相关权重值的高低,来了解每个属性对事件的重要性。然而,由于上述方法中(CNN和RNN)的神经网络存在梯度消失问题,其处理长篇文本序列的能力受限,这与事件日志的性质相悖。
相比之下,LSTM已被证明对于学习未知长度的长期序列模式具有一定的优势,因为它可以保持一定范围内的长期依赖。Tax等人[4]选择了LSTM网络来预测运行案例的下一个活动及其时间戳和剩余时间。他们使用一次独热编码对活动属性进行编码,还使用事件的其他属性时间戳作为输入。然而使用one-hot编码方式时,数据之间关联度不高,会忽略很多由过程行为产生复杂但有价值的信息。Camargo等人[12]针对这些局限性,提出了利用LSTM神经网络从事件日志中建立和使用生成模型的新的前后处理方法和体系结构。后来的研究中,Pasquadibisceglie等人[13]用embedding的编码方式也很好地解决了维度灾难问题,提出了多视角的深度学习方法预测业务流程监控,对事件的多个不同类型属性进行编码,将这些属性简单地加起来输入到LSTM网络学习并设计了一层注意力机制来预测下一个事件活动。类似地,文献[14]提出在LSTM之上使用了两层注意力机制,去解释不同类别属性和每个事件的重要程度,但忽略了事件的发生时间,在某些情况下,时间视角也被认为是一个进一步的数据维度,但是LSTM缺乏并行处理能力,这是关键问题。随着NLP领域不断发展,文献[15]提出基于注意力机制的Transformer网络模型架构,很多NLP任务表明Transformer的特征提取能力强于LSTM。Bukhsh等人[16]提出了利用Transformer网络进行预测性业务流程监控,该模型可以实现并行处理,并且可以提取特征向量,学习更多关联性。Chen等人[17]在利用BERT模型的同时引入迁移学习思想,提出了基于BERT和迁移学习的业务流程多任务预测方法,该方法可以快速有效地应用到下一个活动预测任务和案例结果预测任务,但是其仅从控制流视角进行预测,忽略了数据流造成预测结果的影响。
受到上述工作的启发,本文发现多视角能够更全面学习过程行为,减少单一视角造成的偏见,以及Transformer、BERT网络能更好地处理长序列和全局信息。因此,本文针对应用在业务流程预测中的深度学习模型(如CNN[9,10]、RNN[11]、LSTM[12~14])方法中的局限性,提出了一种全新的方法(FMP框架)来改进业务流程的预测性能。FMP框架使用双层BERT网络,可以有效地融合数据流视角和控制流视角。此外,BERT通过多头注意力机制能够并行处理以及克服梯度爆炸的问题。这使FMP框架能够进行全面的多维视角分析,结合了不同视角的信息有助于提高预测的准确性和全局性。
2 背景知识
2.1 基本定义
事件日志[18]的结构:过程是由案例组成的,案例是由事件组成的,且每个事件仅属于一个案例。案例中的事件用迹(trace)的形式来表示,即(唯一的)事件的序列。事件具有属性,典型的属性名称包括活动、时间戳、案例和资源。
定义1 事件和属性。事件与业务过程中的活动相关联。为了方便理解,假设事件E=a、c、t这些属性表示,其中a∈A是与执行中的事件相关的活动属性,c∈N是案例属性,t∈N是事件的时间戳属性。
迹是事件的一个有限序列σ=E1,E2,…,E|σ|,其中每个事件只发生一次,即1≤i<j≤|σ|。
事件日志(表1)是案例c的集合L,其中每个事件在整个日志中最多发生一次,即对任意的c1,c2∈L,有c1≠c2。
定义3 前缀迹。前缀迹σk是从迹σ的开始事件开始的第一个k个事件的子序列,即σk=E1,E2,…,Ek(1≤k≤|σ|)。因此,迹是一个完整的案例,包括开始事件和结束事件。
定义4 预测下一个事件活动。需要结合事件日志中发生的前缀迹,例如预测E3,需要前缀迹event1、event2,预测event4需要event1、event2、event3,因此对事件日志先进行处理,设置前缀迹中一个最小长度L(L:≥2)和所有的迹小于L的值将被忽略,L长度值是通过实验得到的最佳值,L长度值太大会导致训练数据集的样本减少。
2.2 深度神经网络
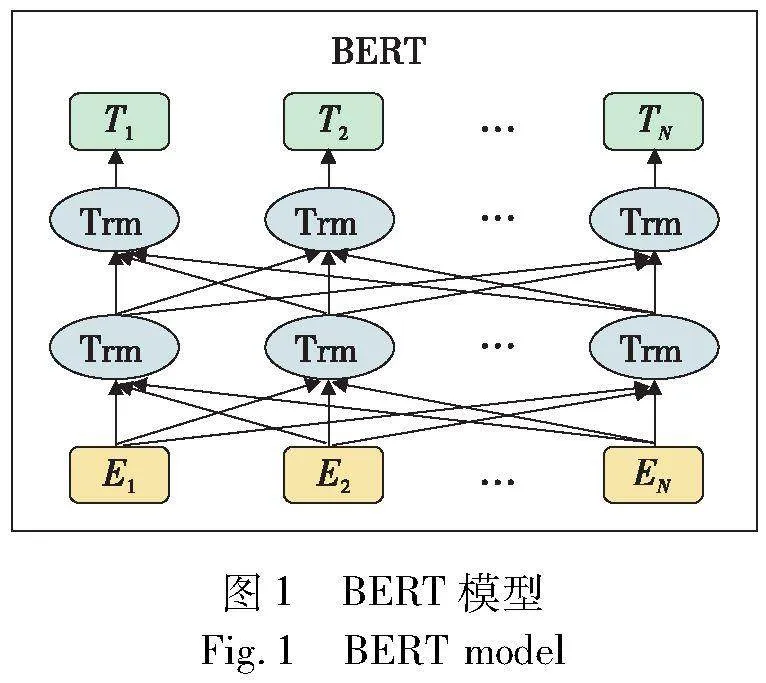
Transformer[15]是一个序列到序列的模型,核心在于自注意力机制,它放弃了常规的递归和卷积方法。此模型利用自注意力机制在序列中构建各个位置间的联系。其主要由编码器与解码器两部分构成,这两部分都是由重复的层堆叠而成。该机制使得序列中的词能与其他位置的词相互作用,有效地理解上下文,并对长距离的关联关系有出色的表现,为自然语言处理赋予了高效的处理能力。BERT[19]基于Transformer构建,是一个预训练的语言模型。与常规模型不同,BERT的亮点在于它的双向预训练设计考虑到了单词左右两边的上下文。预训练阶段,BERT采用了掩码语言模型(MLM)和下一句预测(NSP)策略。这两种策略赋予了BERT深厚的语言识别和上下文描绘力。在实际应用时,预训练过的BERT可以进行特征提取或微调,从而适应多种任务。它在文本表达和NLP任务上展现了卓越的表现,确立了其在NLP领域的关键地位。本文采用BERT进行事件日志的特征提取,并将其转换为向量形式,进而用于专业任务领域的学习与预测。BERT模型如图1所示。
3 提出的融合流程多视角框架
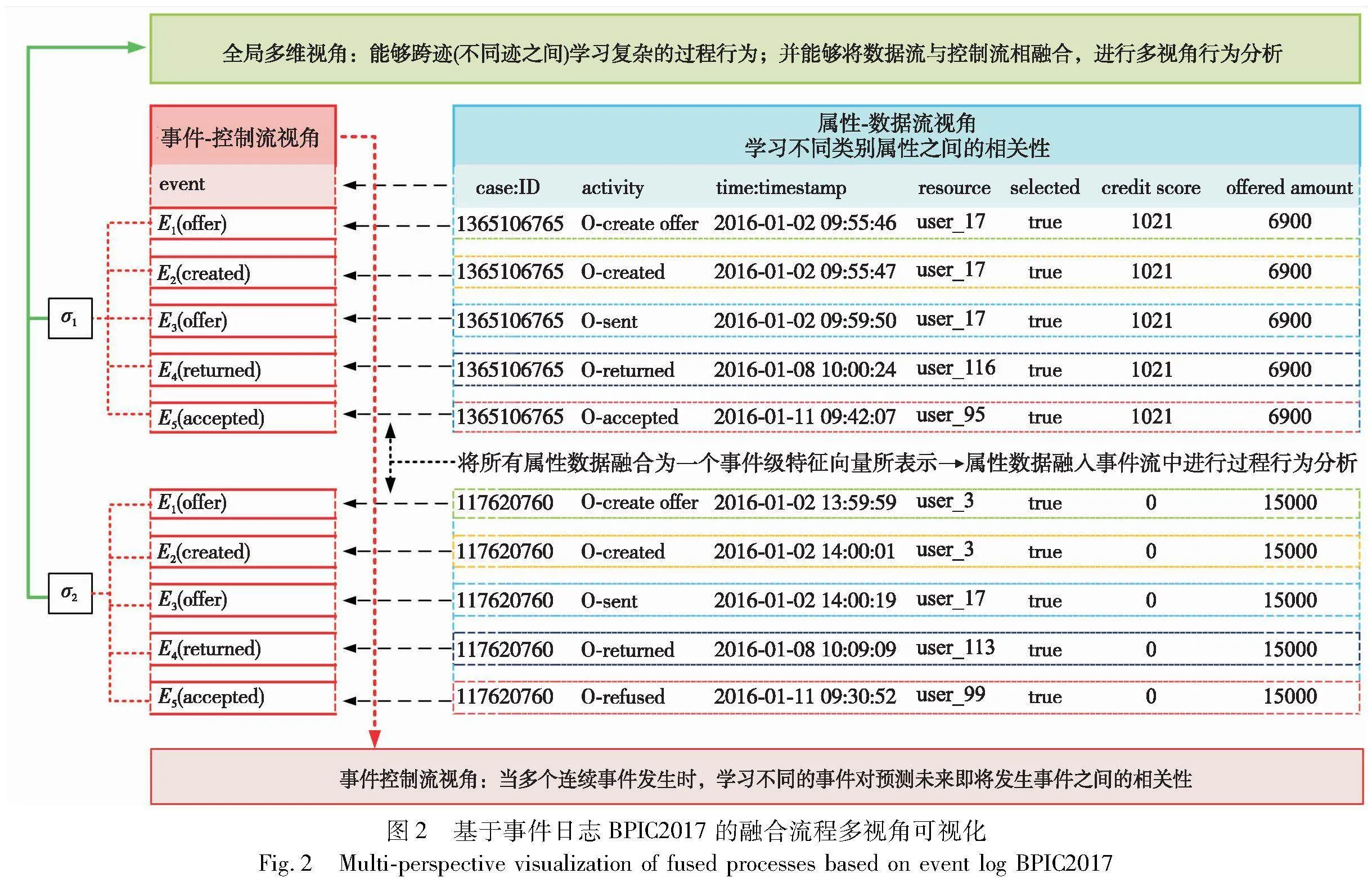
与已有方法中仅局限地考虑单一的视角相比,本文框架最大限度地保留了事件日志的完整性,能够从全局视角分析过程行为产生的数据信息。例如,图2是事件日志BPIC2017提供涉及一个荷兰金融机构的贷款申请流程。图2中每个事件包含了不同类别的属性case:id、activity、resource、credit score、offered amount、accepted等,以及其他没有列出的属性,每个迹中都包含了连续序列的事件σi={E1,E2,…,En}。因此,不能只考虑以活动名称为表示的控制流视角,事件中的属性-数据流也非常重要,例如credit score信用评分的高低,offered amount申请金额的大小,都会影响最终的流程执行贷款申请是接受还是拒绝。
下文将详细介绍融合流程多视角框架的高级视图(图3)和其每个技术模块及作用。最后,本文的重点是评估FMP框架能够为预测下一个事件活动提供的增益(与目前最先进的预测下一个事件活动的方法相比)。
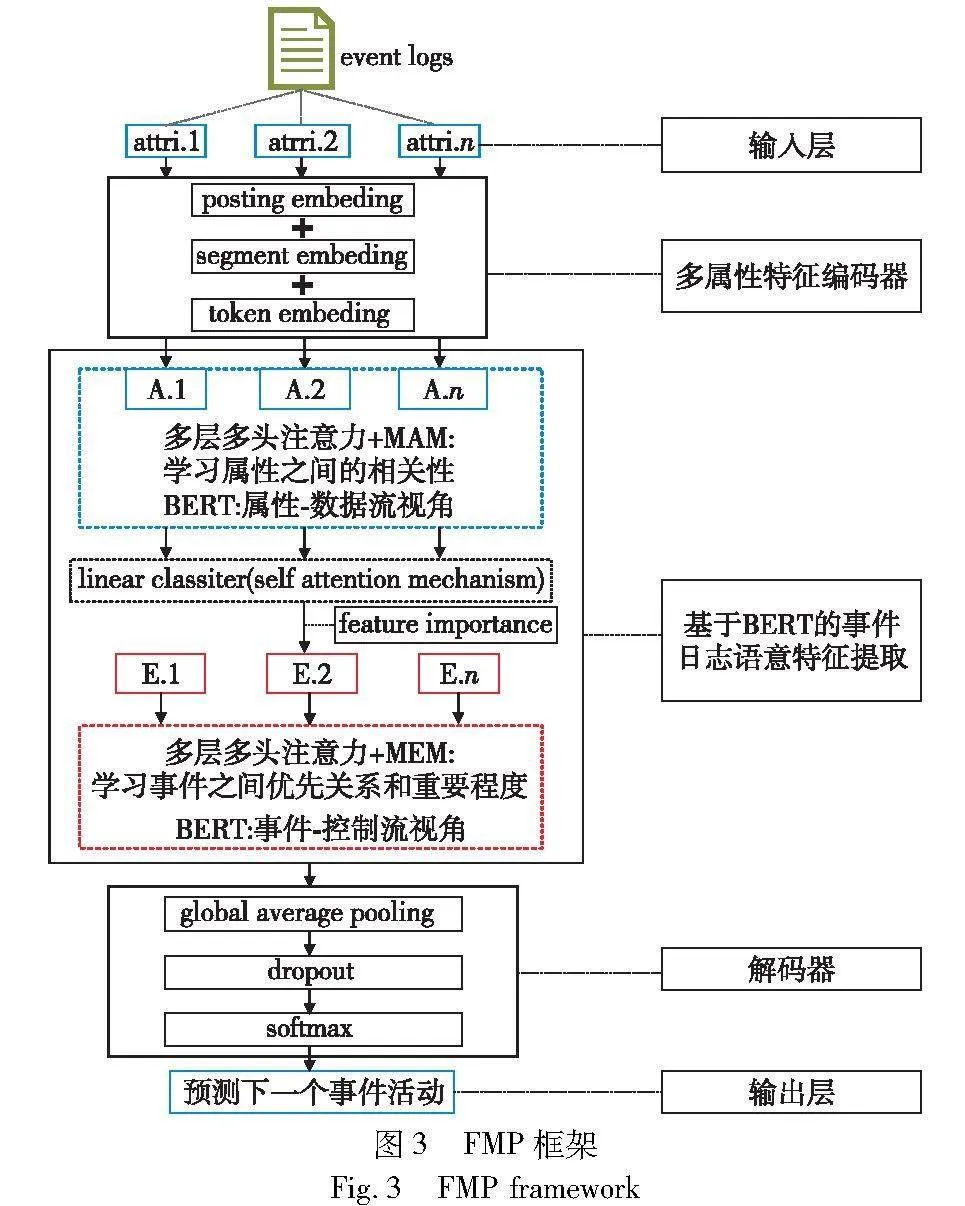
3.1 多属性特征编码器
对事件日志进行预处理,将其转换成XES数据文件的数据集,再将数据集划分为两部分:80%的数据集作为预训练专业领域BERT模型的预测任务,20%的数据集作为测试验证集。
a)输入层。对事件日志中的(表1)不同类别属性作特征提取,作为框架的输入。X={att1,att2,…,attn},其中每个atti都是事件中的一个属性,这些属性有case ID、activity、timestamp、resource、credit score、selected、offered amount等。
b)多属性特征编码器。将事件中的不同类别属性atti作特征提取后输入到这一层中。
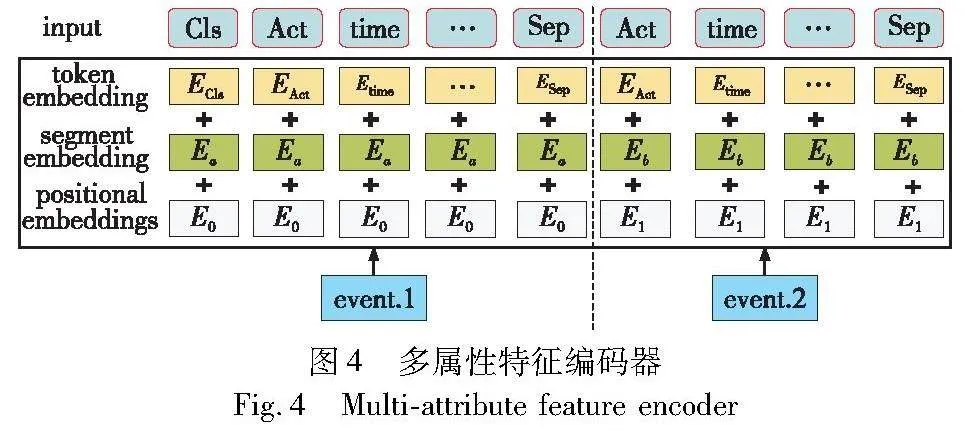
图4是多属性特征编码器具体的编码方式。
a)token embeddings(1,n,128):将各个属性转换成固定维度的向量,在预训练专业领域的BERT模型中,每个属性被转换成128维的向量表示(维度经过训练后得到最佳值)。此外,两个特殊的token会被插入到tokenization结果的开头 ([CLS])和结尾 ([SEP]) ,它们是为后面的分类任务和划分不同事件服务的。
b)segment embedding(1,n,128):让BERT能够处理输入不同事件的分类任务。这类任务类似于判断迹中的两个事件是否是相似的。事件日志迹中的两个事件被简单地拼接在一起后送入到模型中。如图3所示,事件n的不同类别属性都是Ea,如果在输入其他事件n+1时,那么对应的不同类别属性就是Eb。类似地,segment embedding也能够区分出事件日志中不同迹,L={σ1,σ2,…,σn},其中每个σi是一个完整的迹。
c)position embeddings:让BERT模型记录输入的每个属性的位置信息向量,去学习输入的事件流中的属性-数据信息。最后,编码地合成表示:token embeddings(1,n,128) ,属性-数据的向量表示;segment embeddings(1,n,128),辅助BERT区别迹中事件流的不同事件的向量表示;position embeddings(1,n,128) ,让BERT学习输入的顺序属性。
这些表示会被按元素相加,得到一个大小为(1,n,128)的合成向量表示,类似的X′={A1,A2,…,An},其中每一个Ai都是对应的属性embedding向量,这一表示就是属性特征编码器的输出。这种编码方式在输入到其他层神经网络的计算中依旧能够保留每个属性的token、positing、segment的数据信息。接着将embedding后的属性向量Ai输入到下一层。
3.2 基于双层BERT方法对事件日志语意特征提取
由于训练过程中需要进行反向传播和梯度计算,将注意力分数置为零会导致无法进行有效的梯度传递。所以,将注意力
BERT的掩码机制(masked attribute modeling,MAM)能够学习不同类别属性对事件的重要程度。掩码机制 [MASK] 遮盖的操作如下:M={A1,A2,…,An},随机把一个事件15%的token(属性)替换成以下内容:80%的几率被替换成[MASK];10%的几率被替换成任意一个其他的token;10%的几率原封不动,之后让模型预测和还原被遮盖掉或替换掉的部分。计算损失的时候,只计算在第一步被随机遮盖或替换的部分,其余部分不计算损失,无论输出什么都不影响。
这种机制可以强迫模型在编码当前序列属性的时候不太依赖当前的属性,而是考虑它的上下文(其他不同类别属性),甚至根据上下文进行纠错。最后,把学习后的不同类别的属性A′i={A′1,A′2,…,A′n}输出到下一层。
b)微调+自注意力机制层。BERT的微调只需要对下游任务进行改造(自注意力机制)。因此,将经过第一层BERT模型训练和学习后不同类别的属性Ai作为输入,输入到自注意力机制层,在这一层中进行特征选择,并更加关注占比权重更高的属性,对其重要性进行加权。需要注意的是,本文不会干涉确定每个属性的占比权重。因此,这个过程是完全自动化的。自注意力公式如式(1)所示,经过第一层BERT模型对复杂过程行为所产生的属性-数据进一步分析和学习后,输出得到一个事件向量Ei,其是由所有类别属性权重组成的。类似地,迹中其他事件向量σi={E1,E2,…,En}也是这样得到的,这些向量作为该事件的特征向量被输入到下一层中。
c)第二层BERT模型。在事件控制流视角中,当多个连续事件发生时,学习不同的事件对预测未来即将发生事件之间的相关性,自动识别每个事件对未来预测事件的影响程度及优先关系。
将上一层BERT模型训练和微调后输出的事件向量σi={E1,E2,…,En}作为本层的输入。以类似的方式创建迹中其他所有的事件向量,如图2的Ei中包含了不同类别属性的特征信息,其中时间戳属性记录了事件的时间序列。所有的上下文事件向量Ei并行地输入到第二层BERT中。同样地,掩码机制(masked event modeling,MEM)同第一层BERT类似,M={E1,E2,…,En},将一个完整的迹中15%的事件进行掩码操作,经过预训练后BERT模型能够自动学习迹中事件的优先顺序、并发、异步、循环等逻辑关系。例如,当多个连续事件发生时,学习不同的事件对预测未来即将发生事件之间的相关性,并自动分配每个事件在迹中的不同占比权重。它们能反映出不同事件的重要程度,并解释不同的事件对预测未来事件的影响程度及优先关系。
3.3 (解码器)微调层+预测下一个事件的活动
最终的输出层是把第二层BERT的输出传递给下一个活动预测模块(下一个事件预测模块由全局平均池化层、退出层和softmax层组成)。
En+1(activity)=softmax(M,WE)(4)
选择概率最高的活动作为最终输出,即运行迹的下一个事件的活动,WE是迹中事件的权重矩阵。提出的双层BERT模型把事件-控制流作为架构,属性-数据流作为流转载体。事件流中包含着多属性数据特征信息,实现了控制流和数据流相互融合的多视角行为分析。最终的输出是预测的下一个事件En+1(activity)用活动名称代替,而不是预测出事件的所有属性。它能大大减少训练时间,从而更高效、精准地实现过程监控预测任务。
4 实验
本章将说明用于评估本文方法有效性的实验设置,实验中五个数据集均来自4TU研究数据中心的公开真实事件日志,然后讨论实验活动的结果,目标是提供以下研究问题的答案:
RQ1 F-M-P框架在预测下一个事件活动的性能如何?
RQ2 F-M-P框架是如何将属性-数据流与事件-控制流融合的?
4.1 数据集
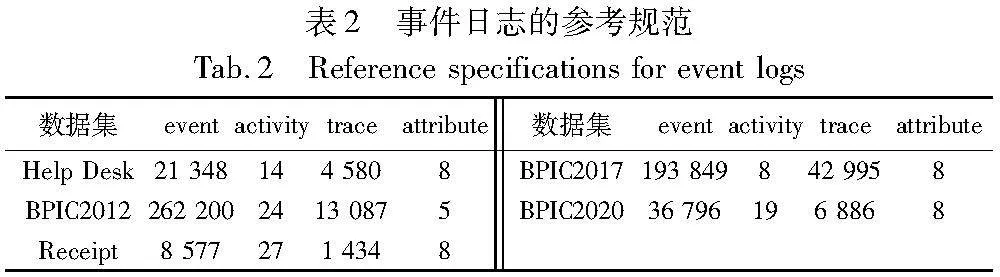
本文方法在五个不同的真实数据集上进行了评估,分别对这些来自不同领域的数据集进行讨论,表2提供了事件日志的参考规范。
a)Help Desk。其包含了一个意大利软件公司的帮助台票务管理过程。
b)BPIC2012。其涉及到一个由荷兰金融机构管理的全球融资机构内的个人贷款或透支的申请过程。本文主要采用了BPI2012WComplete(它包含了子进程W的迹,但保留了这些迹的已完成事件)。
c)Receipt。其来源于在NWO项目编号638.001.211下执行的CoSeLoG项目。该日志收集了在一个匿名的市政当局进行的建筑许可申请过程的接收阶段的执行记录。
d)BPIC2017。其提供涉及一个荷兰金融机构的贷款申请过程。
e)BPIC2020。其包含与付款请求相关的事件,这些事件与旅行无关。各种许可和申报文件(国内和国际申报、预付旅费和付款请求)遵循过程。
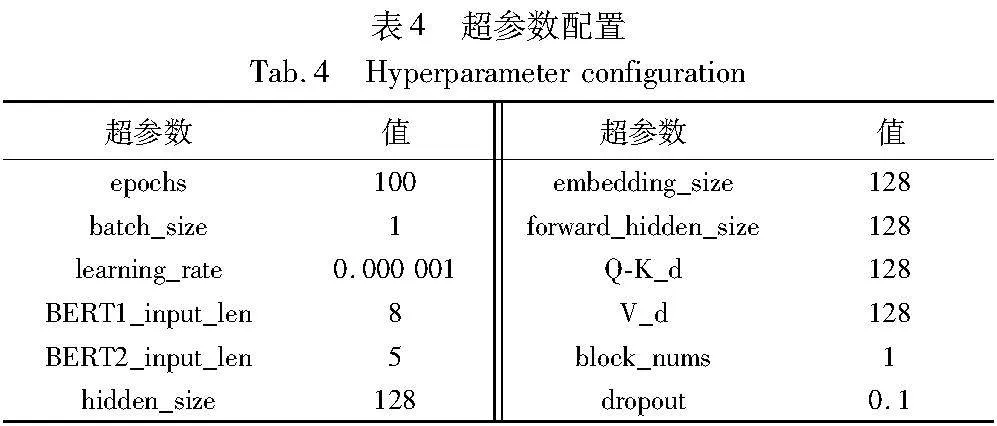
预测下一个事件活动,需要结合事件日志中发生的前缀迹,例如预测Event3,需要前缀迹Event1,Event2,预测Event4需要Event1,Event2,Event3,因此对事件日志先进行处理,设置前缀迹中一个最小长度L (L:≥2)和所有的迹小于L的值将被忽略,L长度值是通过实验得到的最佳值,L长度值太大会导致训练数据集的样本减少,具体内容如表3所示(表3中每个Event中都包含了不同类别的属性)。本文在Python 3.8中实现FMP方法,表4是实验的超参数配置。
4.2 基于属性-数据流视角分析
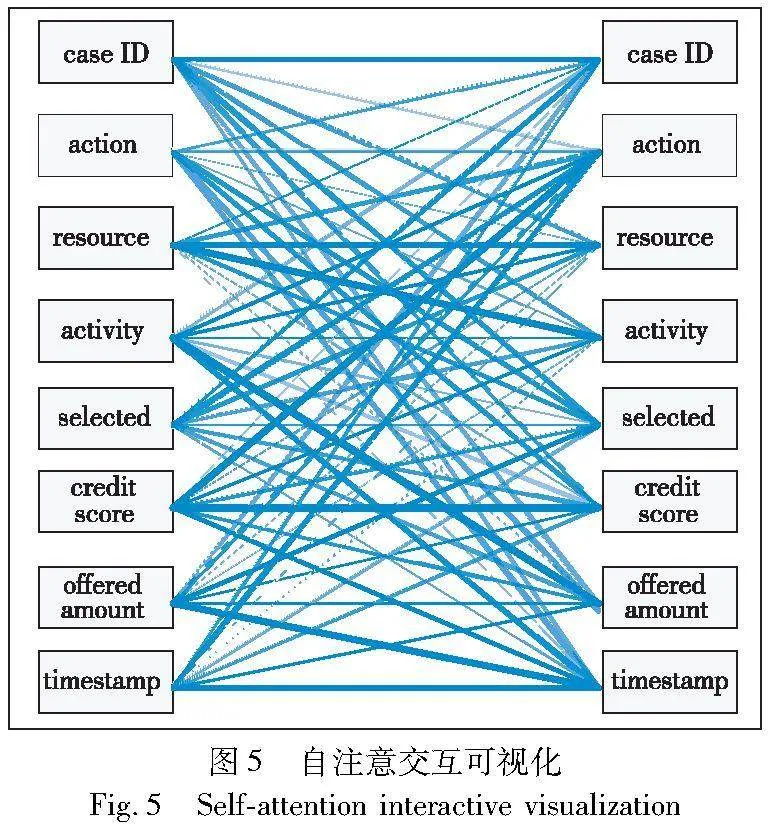
过程行为由连续的事件组成,而每个事件是由不同类别的属性-数据组成的。首先对属性-数据流分析,对每个事件的不同类别属性进行多属性特征编码,再输入到第一层BERT模型中训练学习。 本文通过BERT的多头自注意力可视化,呈现框架内部结构的数据信息交互,例如不同类别属性数据之间的关联性和交互性。
输入的事件流中,E1、E2、E3通过第一层BERT多头注意力机制去学习不同类别属性的关联性,图5是FMP框架中E1的其中一个头部的自注意力交互可视化[20]。图5能够观察到属性之间相互的连接线,线的粗细和透明程度是属性之间关联性大小的判别标准,连接线越粗,透明度越小,代表两个属性间的自注意力评分越高,反之,连接线越细,透明度越大代表两个属性的自注意力评分低。需要注意的是,模型里的自注意力是完全自动分配评分权重的,本文不会去刻意设置某些值的高低。
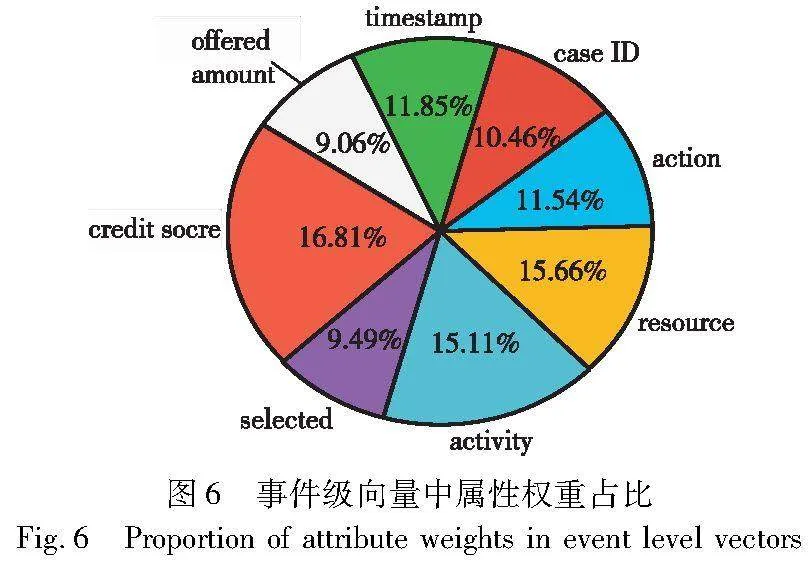
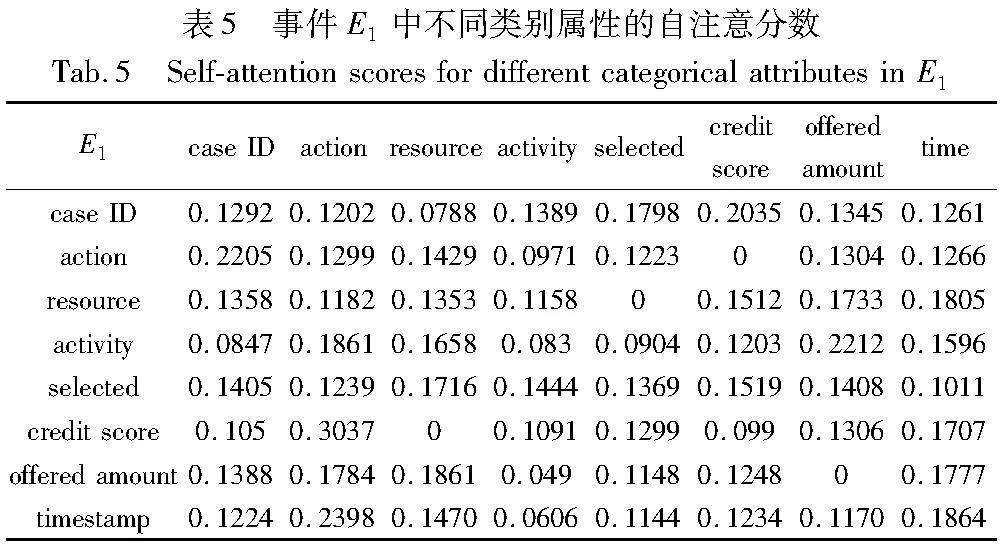
再将事件E1转换为由不同类别属性组成的向量去对比。表5是每个事件中不同类别属性的自注意力评分,以BERT模型中一个头的自注意力表示为例,能够明显观察到E1事件中不同类别属性之间的自注意力评分权重都各不相同,这是因为在不同的事件中会关注不同类别的属性,以判定哪些属性-数据影响程度更高。多层多头注意力能够从多个视角学习属性-数据之间的关联性。BERT模型输出这些经训练学习后的不同类别属性数据,输入到下一层的自注意力机制加权求和,得到事件中不同属性在事件中的占比权重关系,如图6所示,以判别哪些属性的权重占比更高和影响程度更大。
图6中能观察到credit score属性的注意力权重为0.168,resource为0.156 6和activity为0.151 1,说明这三个属性在事件中得到了更多的关注,它们对未来即将发生的事件影响权重也更大;反之,其他属性注意力权重较小,关注越少。这也证明了FMP模型的有效性,因为在贷款申请中credit score的高低直接影响最终申请的成功与否;activity是贷款申请的活动流程,不同的activity也会直接影响下一个发生的事件。事件流中属性-数据会直接影响未来即将发生的事件,从而间接地影响流程最终结果。
4.3 基于事件-控制流视角分析
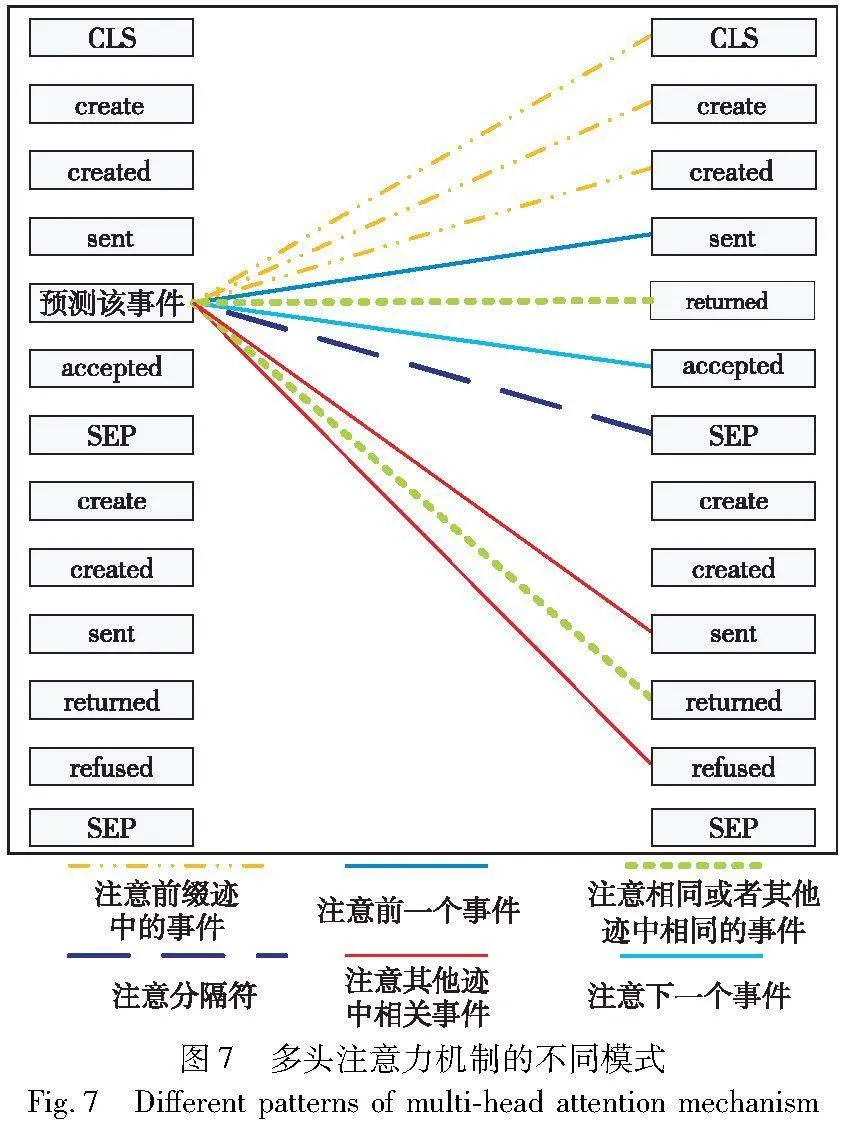
将属性-数据融入事件中,再对控制流视角进行过程行为分析。第二层BERT通过多层、多头自注意机制,能够捕获事件流是如何在不同迹之间交互的,如图7所示。图7中主要有以下几种主要的注意力模式:
注意前一个事件:有助于捕获上文中提供的行为信息。
注意下一个事件:有助于捕获迹的流程和预测下一个事件的可能性。
注意前缀迹中的事件:帮助模型理解迹的上下文,学习迹的背景信息,提供长距离的上下文联系。
注意相同或者相关的事件:捕捉迹中的语义关系或者事件之间的同义关系。
注意分隔符:这种模型将迹的事件流状态传播到单个事件上,并且能够将全局的上下文信息传播到各个事件上。
注意其他迹中相关的事件:有助于捕获上下文中提供的线索,并通过上下文进行过程预测。
这些模式可以学习事件-控制流中的逻辑关系,如顺序、递归、并发性、冲突和其他类型的关联。
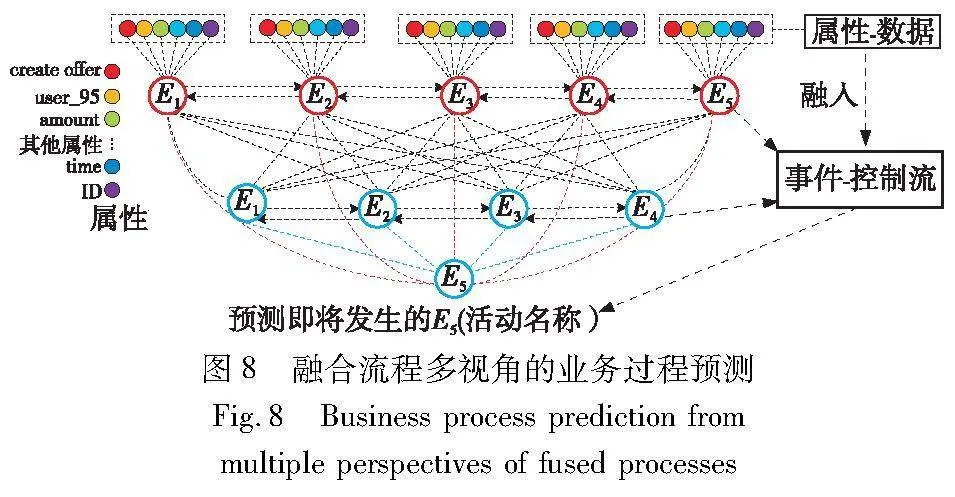
在预训练任务中,FMP框架通过多头注意力机制,能够结合上下文自动识别哪些事件的重要程度更高,并影响将发生的下一个事情活动,进而作出最终的决策结果,如图8所示。
4.4 多视角框架分析和实验评估
为了评估FMP在预测事件日志的下一个事件活动,本文使用了accuracy度量。因此,在训练阶段结束后,将测试集中的部分迹逐一给模型,并将模型预测的下一个事件活动与其他近期先进的方法进行比较, accuracy公式如下:
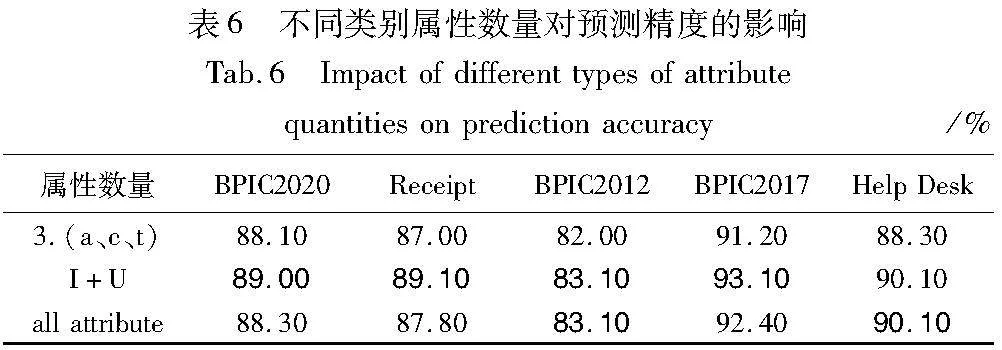
本文探讨了在事件日志中,通过输入不同类别属性的个数对预测性能的影响进行对比。为了保持事件日志的完整性(integrity)和属性-数据数值的唯一性(uniqueness),删除了数据集中重复出现的属性-数据,数据集BPIC2012采用了全部的的不同类别属性,属性个数为5,BPIC2017的属性个数为8,BPIC2020的数据集不同类别属性个数为7,Help Desk的属性个数为7,Receipt的属性个数为8。由表6能够明显观察到,属性数量为3时,预测的性能效果最低,其原因是给定关键属性-数据信息太少;数据集中随着属性的数量增加,预测的精度也在增加,可以证明保留事件日志中的属性-数据完整性是至关重要的。然而,当事件日志中的所有属性全部作为输入时,反而会增加框架内部计算的复杂度以及产生更多噪声,导致预测精度下降。
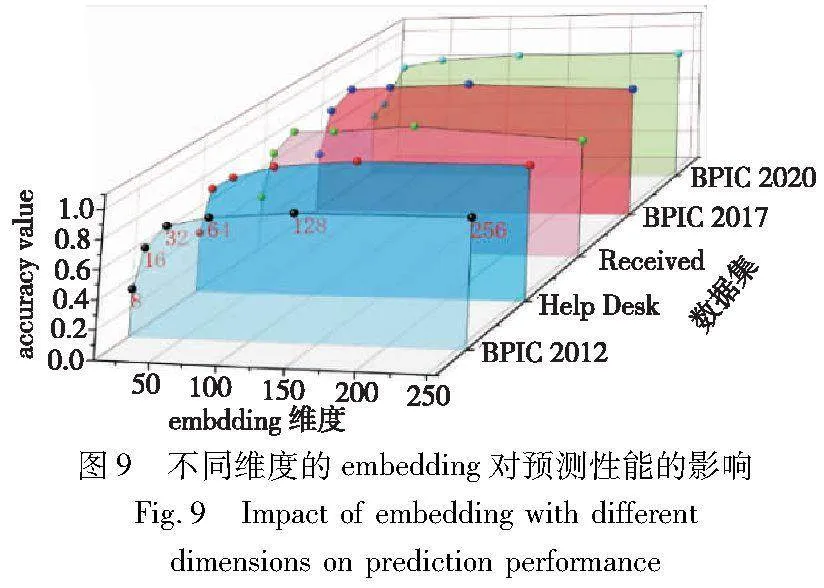
为了区分embedding维数对预测准确度的影响,使用256、128、64、32、16和8维的嵌入空间重复实验,保持其他参数不变。图9显示了数据集对不同维度数量的验证精度。能够明显观察到,降低嵌入的维数通常会对预测精度产生消极影响。然而,只要嵌入空间的维数大于词汇表的大小,这种效应就可以忽略不计。当维数从64降到32时,预测精度都没有显著降低。然而,当维数降低到16和8时,所有数据集的精度降低都更明显。BPIC 2020数据集显示,当维数从128降低到64时,精度显著降低。其他具有大词汇量的数据集也表现出相同的行为。将维度增加到256,表明会发生显著的过拟合,特别是对于具有大词汇量的数据集。
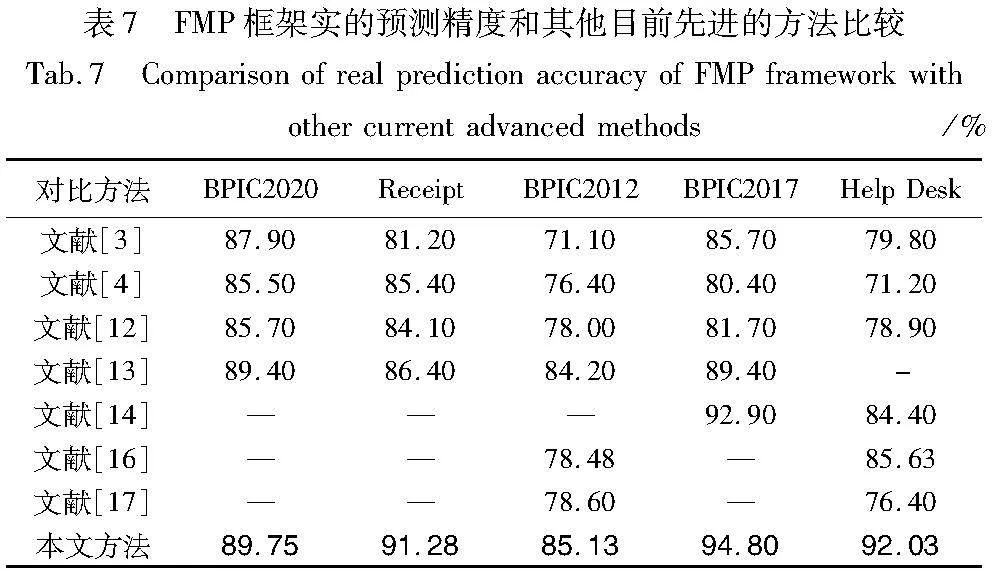
如图9所示,BPIC2012和BPI2017数据集的精度随着embedding维数的增加而降低,这些趋势是过拟合的明显迹象。从图9可以看出,选择128个维度的基线接近于所有数据集的最佳验证精度,没有明显的过拟合。最后,为了证明FMP框架能够更全面地分析复杂的过程行为,以及在预测下一个事件活动的任务上呈现出更高的精度,本文和已有的最先进方法进行了对比。如表7所示,与单一的控制流(或者数据流)视角相比,基于FMP在预测下一个事件活动的准确数性能更高。进一步证明了基于多视角行为分析的有效性,而不能仅考虑单一视角。
4.5 结论性讨论
本文总结了4.3节的主要实验结果,以便为本节开头定义的研究问题提供明确的答案。
RQ1:与先进的方法相比,FMP框架在预测下一个事件活动精度的性能表现更好。通过真实公开的数据集实验结果,证明基于BERT模型的多视角FMP框架能够更全面、更深层次地分析复杂的过程行为。
RQ2:FMP框架利用多个层次的技术组件(多属性特征编码器、基于双层BERT模型的事件日志语意特征提取、自注意力机制)实现融合流程多视角。并且通过每个技术组件的功能和相互作用,可以呈现整个框架内部运转。并通过层次的自注意力交互可视化和数据可视化、逐层分析,来实现流程多视角之间的融合。
5 结束语
目前,事件日志中存储着大量的数据和过程行为信息。使用过程挖掘技术和深度学习相结合的方法对这些行为信息和数据进行分析,以便学习和提取有价值的知识来分析流程的各种特征。然而,现有的先进技术主要侧重于控制流视角或不能有效地将数据流视角和控制流视角相结合。为了解决这些问题,本文提出了FPM框架,将属性-数据流与事件-控制流进行融合,实现了真正意义上的多视角行为分析。采用了双层BERT网络模型来学习属性-数据流之间的关联性和事件-控制流中不同事件的逻辑顺序关系,从而进行更全面、更有价值的过程行为分析。FMP框架能够更准确地预测下一个事件活动,并及时识别事件日志中的偏差,以避免更大的损失。通过自注意力权重可视化和数据流转可视化,可以识别事件中的占比关系和事件在迹中的优先次序关系。实验结果表明,FMP框架在预测精度的性能优于最先进的研究方法。
未来的工作目标是将该方法作为分析事件日志过程行为的框架,应用于业务流程管理的其他相关任务。例如在事件日志模型修复中,修复事件日志迹中缺失的属性,以及用于基于多视角的异常行为检测[21,22]。本文利用深度神经网络方法对过程行为进行分析,神经网络通常被认为是黑盒模型,导致无法提供可解释性,这也是BPM领域中的难点,未来研究工作将对本文FMP框架进行可解释性分析。
参考文献:
[1]Metzger A, Franklin R, Engel Y. Predictive monitoring of heterogeneous service-oriented business networks: the transport and logistics case[C]//Proc of Annual SRII Global Conference. Piscataway, NJ: IEEE Press, 2012: 313-322.
[2]Hinkka M, Lehto T, Heljanko K. Exploiting event log event attri-butes in RNN based prediction[EB/OL]. (2020-01-15). https://arxiv.org/abs/1904.06895.
[3]Evermann J, Rehse J R, Fettke P. Predicting process behavior using deep learning[J]. Decision Support Systems, 2017, 100:129-140.
[4]Tax N, Verenich I, La Rosa M, et al. Predictive business process monitoring with LSTM neural networks[C]//Proc of International Conference on Advanced Information Systems Engineering. Cham: Springer, 2017: 477-492.
[5]Guzzo A, Joaristi M, Rullo A, et al. A multi-perspective approach for the analysis of complex business processes behavior[J]. Expert Systems with Applications, 2021,177: 114934.
[6]Lakshmanan G T, Shamsi D, Doganata Y N, et al. A Markov prediction model for data-driven semi-structured business processes[J]. Knowledge and Information Systems, 2015,42(1): 97-126.
[7]Letham B, Rudin C, Tyler H, et al. Interpretable classifiers using rules and Bayesian analysis: building a better stroke prediction model[J]. The Annals of Applied Statistics, 2015,9(3): 1350-1371.
[8]Rama-Maneiro E, Vidal J C, Lama M. Deep learning for predictive business process monitoring: review and benchmark[J]. IEEE Trans on Services Computing, 2023,16(1): 739-756.
[9]Al-Jebrni A, Cai Hongming, Jiang Lihong. Predicting the next process event using convolutional neural networks[C]// Proc of IEEE International Conference on Progress in Informatics and Computing. Pisca-taway, NJ: IEEE Press, 2018: 332-338.
[10]Pasquadibisceglie V, Appice A, Castellano G, et al. Using convolutional neural networks for predictive process analytics[C]//Proc of International Conference on Process Mining. Piscataway, NJ: IEEE Press, 2019: 129-136.
[11]Lin Li, Wen Lijie, Wang Jianmin. MM-Pred: a deep predictive model for multi-attribute event sequence[C]//Proc of SIAM International Conference on Data Mining.[S.l.]: Society for Industrial and Applied Mathematics, 2019: 118-126.
[12]Camargo M, Dumas M, González-Rojas O, et al. Learning accurate LSTM models of business processes management[C]//Proc of International Conference on Business Process Management. Cham: Springer, 2019: 286-302.
[13]Pasquadibisceglie V, Appice A, Castellano G, et al. A multi-view deep learning approach for predictive business process monitoring[J]. IEEE Trans on Services Computing, 2022, 15(4): 2382-2395.
[14]Jalayer A, Kahani M, Pourmasoumi A, et al. HAM-Net: predictive business process monitoring with a hierarchical attention mechanism[J]. Knowledge-Based Systems, 2022, 236(C): 107722.
[15]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[EB/OL]. (2023-08-02). https://arxiv.org/abs/1706.03762.
[16]Bukhsh Z A, Saeed A, Dijkman R M. Process Transformer: predictive business process monitoring with transformer network[EB/OL]. (2021-04-01). https://arxiv.org/abs/2104.00721.
[17]Chen Hang, Fang Xianwen, Fang Hua. Multi-task prediction method of business process based on BERT and transfer learning[J]. Knowledge-Based Systems, 2022,254: 109603.
[18]Van Der Aalst W M P. Process mining: discovery, conformance and enhancement of business processes[M]. Berlin: Springer, 2011.
[19]Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2019-05-24). https://arxiv.org/abs/1810.04805.
[20]Abnar S, Zuidema W. Quantifying attention flow in transformers[EB/OL]. (2020-05-31). https://arxiv.org/abs/2005.00928.
[21]Nolle T, Luettgen S, Seeliger A, et al. BINet: multi-perspective business process anomaly classification[J]. Information Systems, 2022, 103: 101458.
[22]Fang Na, Fang Xianwen, Lu Ke. Anomalous behavior detection based on the isolation forest model with multiple perspective business processes[J]. Electronics, 2022, 11(21): 3640.
