基于双层解码的多轮情感对话生成模型
2024-07-31罗红陆海俊陈娟娟慎煜杰王丹
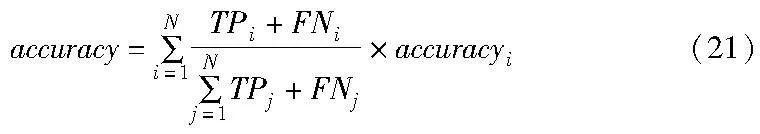
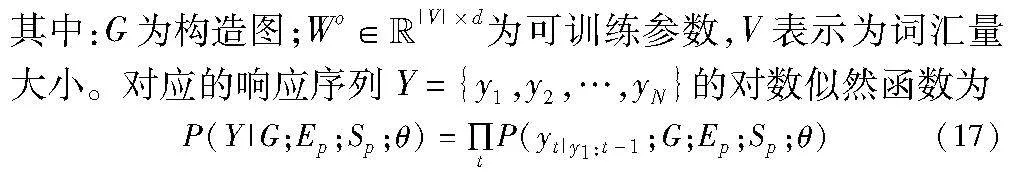
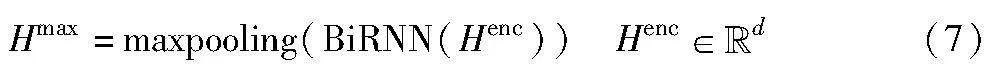




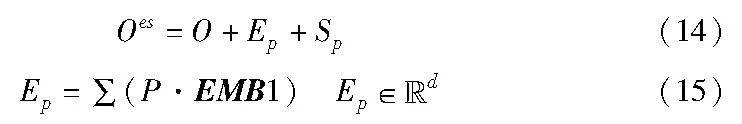

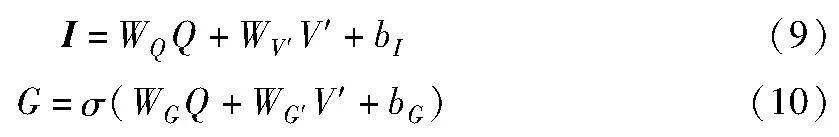
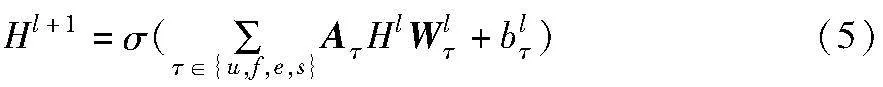
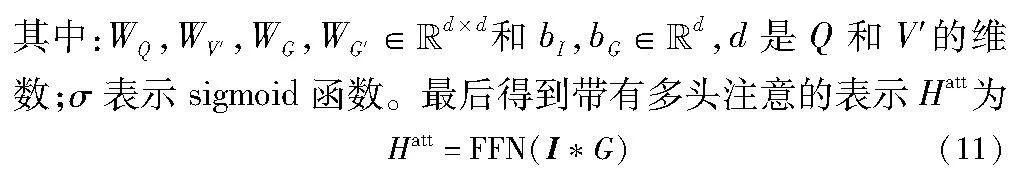

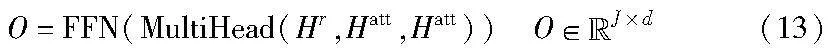
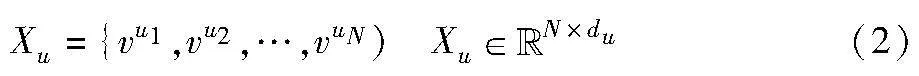
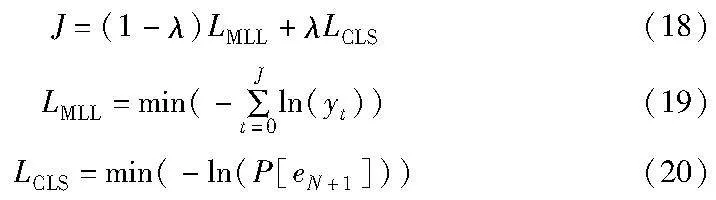
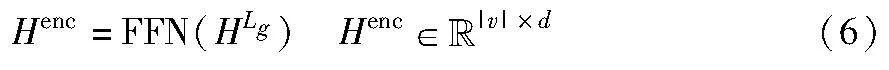
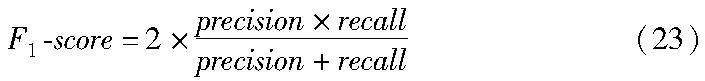

摘 要:情感对话系统的成功取决于语言理解、情感感知和表达能力,同时面部表情和个性等也能提供帮助。然而,尽管这些信息对于多轮情感对话至关重要,但是现有系统既未能够充分利用多模态信息的优势,又忽略了上下文相关性的重要性。为了解决这个问题,提出了一种基于双层解码的多轮情感对话生成模型(MEDG-DD)。该模型利用异构的图神经网络编码器将历史对话、面部表情、情感流和说话者信息进行融合,以获得更加全面的对话上下文。然后,使用基于注意力机制的双层解码器,以生成与对话上下文相关的富含情感的言辞。实验结果表明,该模型能够有效地整合多模态信息,实现更为准确、自然且连贯的情感话语。与传统的ReCoSa模型相比,该模型在各项评估指标上均有显著的提升。
关键词:图神经网络编码器; 注意力机制; 双层解码; 对话生成
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)06-025-1778-06
doi:10.19734/j.issn.1001-3695.2023.10.0519
Multi-turn emotion dialogue generation model based on dual-decoder
Abstract:The success of emotional dialogue systems relies on the ability to comprehend, perceive, and express emotions, while facial expressions and personality can also help. However, despite the crucial importance of this multi-modal information in multi-turn emotional dialogues, existing systems still need to be improved to leverage multi-modal information’s advantages and overlook the significance of contextual relevance. To address this issue, this paper proposed a multi-turn emotional dialogue generation model based on a dua-decoding method(MEDG-DD). The model utilized a heterogeneous graph neural network encoder to integrate historical dialogue, facial expressions, emotion flow, and speaker information, obtaining a more comprehensive dialogue context. Subsequently, it employed a dual-decoding mechanism based on attention to generate emotionally rich expressions relevant to the dialogue context. Experimental results demonstrate that the proposed model effectively integrates multi-modal information, achieving more accurate, natural, and coherent emotional expressions. Compared to the traditional ReCoSa model, this model exhibits significant improvements across various evaluation metrics.
Key words:graph neural network encoder; attention mechanism; dual-decoder; dialogue generation
0 引言
响应生成(response generation,RG)指的是在对话系统中为给定的输入生成合适的响应,被广泛应用于智能助手、车载系统、智能家居等多种场景,显著提升了用户体验的品质。然而,用户更愿意将对话模型看作情感伴侣,而不只是执行任务的文件[1]。因此,为了满足用户的情感需求,生成相应情感反应成为个性化对话系统的关键。人机对话可以分为单回合和多回合两种形式[2]。单回合对话生成是在每一轮对话中,系统生成一次性的回复,不依赖之前的对话历史或上下文信息。这种对话模型主要关注当前输入,而不涉及跨多轮对话的上下文保持。相比之下,多回合对话生成的目标是在连续的对话中保持上下文一致性,提供有意义、连贯且富有逻辑性的回复,以实现更自然、有效的人机交互体验。研究者在多回合对话系统的响应生成方面取得了令人满意的研究效果。例如,文献[3]首先利用注意力机制对每个时刻隐藏层的状态进行加权求和,以获得加权向量,然后将其作为Intention RNN模型的输入。这种加权向量能够更好地表示每个时刻的重要信息,从而提高了意图识别的准确性。文献[4]进一步采用层次模型来执行上下文编码和解码,以生成响应。
然而,上述研究并未充分考虑多回合对话中的情感信息。许多人认为多回合对话可以满足用户的情感需求,促进拟人化响应的生成。然而,在解决对话系统中的情感因素方面仍然存在挑战。首先,情感分类是一项主观的任务,因此在对话数据集中获得高质量的情感标注是很困难的[5]。与一些常见的自然语言处理任务不同,情感分类受到许多因素的影响,例如语言、面部表情和说话者性格等。这些因素的差异会导致同一句话在不同情境下被赋予不同的情感标签,因此很难获得一致性的情感标注。其次,人们如何在句子中平衡语法和情感表达方面仍然没有得到很好地研究,因为获得语义一致的反应是具有挑战的[6]。在对话系统中,生成的反应不仅需要表达正确的情感,还需要符合语法和语义规则。这种平衡需要对句子的结构和意义进行全面分析,是一个非常具有挑战的任务。
为了应对这些挑战,文献[7]提出了一种情绪聊天机(emotion chat machine,ECM),旨在以自然而连贯的方式考虑情感,并且根据不同的情绪标签自动生成话语。文献[8]提出了情感捕捉聊天机器(emotion-capturing chat machine,ECCM),该模型能够捕捉上下文中显式和潜在的情绪信号。文献[9]提出了基于异构图的情感会话生成模型(heterogeneous graph neural network,HGNN),将多模态信息融入到情感对话系统。
总的来说,在情感感知情境下的多回合对话中,有些研究忽略了面部表情和说话者性格对情感对话领域的影响,而其他一些则缺乏对句子上下文相关性的充分响应。因此,为了解决上述问题,本文提出了一种基于双层解码的多轮情感对话生成模型MEDG-DD,它能够充分地感知来自多模态信息的情感,从而增强了生成的句子之间的相关性。具体来说,首先,该模型通过异构的图编码器将历史对话、面部表情、对话的情感流和说话者进行融合,旨在充分地感知对话过程中说话者的情感,并获得恰当的情感反馈。其次,该模型使用基于注意力机制的双层解码器,使得生成的响应更具相关性且情感丰富。为了验证本文模型的有效性,在MELD数据集上进行了实验,并通过自动评估和人工评估将本文模型与其他多个模型进行了比较。结果表明,本文模型在充分感知情感并作出恰当反馈的同时,所生成的响应具有连贯性且富有情感。此外,本文模型在评价指标方面表现出了出色的性能,优于其他实验模型。
本文的主要贡献如下:a)提出异构的图编码器,将历史对话、面部表情、对话的情感流和说话者进行融合,以在对话过程中更充分地感知说话者的情感;b)采用基于注意力机制的双层解码器,使生成的响应更加相关和情感丰富;c)通过在两个数据集上的实验表明,本文模型在情感对话生成方面展现了先进的性能,这也验证了其良好的泛化能力,能够轻松适应不同数据集的信息源。
1 相关工作
尽管已有许多关于单回合对话生成的研究工作,但越来越多的关注开始集中在多回合对话生成领域。其中一个原因是它更符合真实的应用场景,例如聊天机器人和客户服务。更重要的是,生成过程更复杂,因为有更多的上下文信息和约束需要考虑,这对该领域的研究人员提出了巨大的挑战。
文献[10]提出了分层递归编码器-解码器(hierarchical recurrent encoder-decoder,HRED)框架,用于对所有上下文句子进行建模。自提出以来,HRED已在各种多回合对话生成任务中得到了广泛应用,并提出了许多不变量。例如,Serban等人[11]提出了一种名为变量分层递归编码器-解码器(variable hierarchical recurrent encoder-decoder,VHRED)的改进模型,以及一种名为多分辨率递归神经网络(multiresolution recurrent neural network,MrRNN)[12]的模型。这些模型通过引入潜在变量,改进了中间状态的生成方式,从而增加了生成响应的多样性。这些模型为对话生成任务的发展和改进提供了重要的思路和方法。随着Transformer[13]在建模长距离依赖关系方面表现出强大的能力,越来越多的研究者开始将其应用于多回合对话模型中。其中,文献[14]提出了一种名为ReCoSa的模型,该模型采用Transformer作为上下文级编码器,可以有效地处理对话中的长依赖关系。之后,文献[15]提出了名为分层自注意力的网络HSAN(hierarchical self-attention network),在多回合对话建模中进一步应用Transformer替代了字级别的编码器,构建了多级自注意力机制。
针对以往的研究中只有有限的工作关注提高对话的情感质量这一问题,文献[16]提出了一种情感对话生成模型,将情感信息纳入对话生成模型,根据情感类别生成相应的回复句。文献[17]认为同情心反应通常在不同程度上模仿用户的情感,这取决于它的积极或消极以及内容。因此,研究者提出的MIME模型考虑了基于极性的情感集群和情感模仿,可改善同理和反应的上下文相关性。为了解决由于缺乏对内容一致性的考虑,导致响应生成任务的共性问题,文献[18]提出了一种新双向学习模式框架,将情感可控的反应生成扩展为双重任务,以交替生成情感反应和情感查询。文献[19]提出了一个基于任务角色的共情对话的新任务,并提出了第一个关于人物角色对情感共鸣影响的实证研究。文献[20]采用带有注意力机制的编解码器框架,通过融合模块将情感因素和主题信息整合到对话系统中,以增加回复内容的多样性。虽然有一系列相关的工作对人机交互中的多轮情感对话生成系统作出贡献,但还是存在许多常见的限制。例如,在上述文献中,研究者们只从文本中感知情感,而忽略了其他来源的信息(例如面部表情和说话者),并且生成的响应缺乏上下文相关性。
与先前关注单一模态的多轮对话生成研究不同,本文强调面部表情和说话者对情感感知在多轮对话生成中的至关重要作用,并认为它们与生成的对话密切相关。因此,本文提出了一个基于双层解码的多轮情感对话生成模型,该模型不仅考虑了面部表情和说话者的影响,还通过引入双层解码器来考虑其与对话上下文的相关性。
2 模型与方法
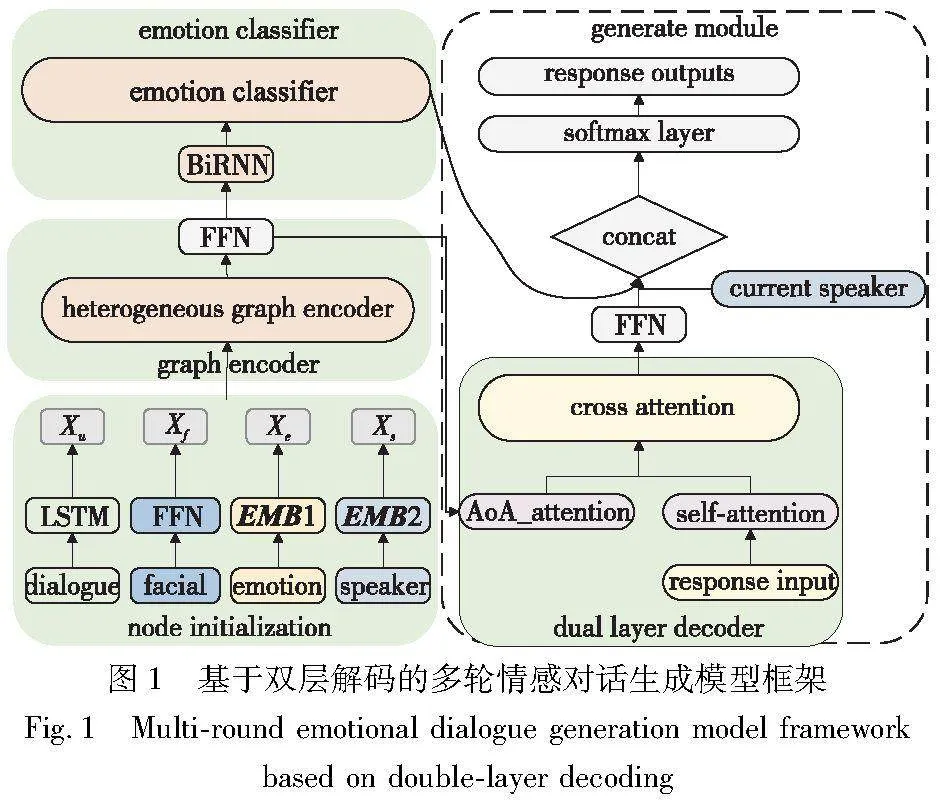
本章将详细描述基于双层解码的多轮情感对话生成模型。如图1所示,该模型由节点初始化、基于异构的图神经网络编码器、情感预测和基于注意力机制的双层解码器构成。具体来说:a)节点初始化,初始化不同类型的节点;b)基于异构的图神经网络编码器,构建图结构以感知情绪,并对会话上下文进行表示;c)情感预测器,借助图表示,情感预测合适的情感,以获取反馈;d)基于注意力机制的双层解码器,将图表示、情感预测结果以及当前说话者作为输入,以产生适当的情绪反应。
2.1 节点初始化
在MEDG-DD中,每个节点都被表示为一个向量。初始阶段,这些向量会独立地进行初始化,不考虑图中的边缘关系。以一个对话为例,假设该对话已经进行了n轮,本节将阐述如何初始化四种类型的节点。这四种类型的节点分别是话语节点、面部表情节点、情感流节点和说话者节点。
1)话语节点
给定上下文集U={u1,u2,…,uN},U中的每个句子定义为ui={x1,x2,…,xM}。对于上下文中的每个话语ui,单词级别的编码器采用长短期记忆(long short-term memory,LSTM)网络,首先将每个输入上下文编码为一个固定的维度向量vM,具体计算公式如下:
it=σ(Wi[vt-1,wt]),ft=σ(Wf[vt-1,wt])
ok=σ(Wo[vt-1,wt]),lt=tanh(Wl[vt-1,wt])
ct=ftct-1+itlt,vi=ottanh(ct)(1)
其中:it、ft和ot分别代表输入、内存和输出门;wt是xt的单词嵌入;vt为LSTM在t时刻结合wt和vt-1计算出的向量;ct是t时刻的单元格;σ表示的是激活函数;Wi、Wf、Wo和Wl是超参数。用向量vM作为句子的表示,因此话语节点得到句子表示为
其中:将Xu作为话语节点的初始化表示。
2)面部表情节点
其中:df是面部表情节点所表示的维数。将Xf作为面部表情节点的初始化表示。
3)情感流节点与说话者节点
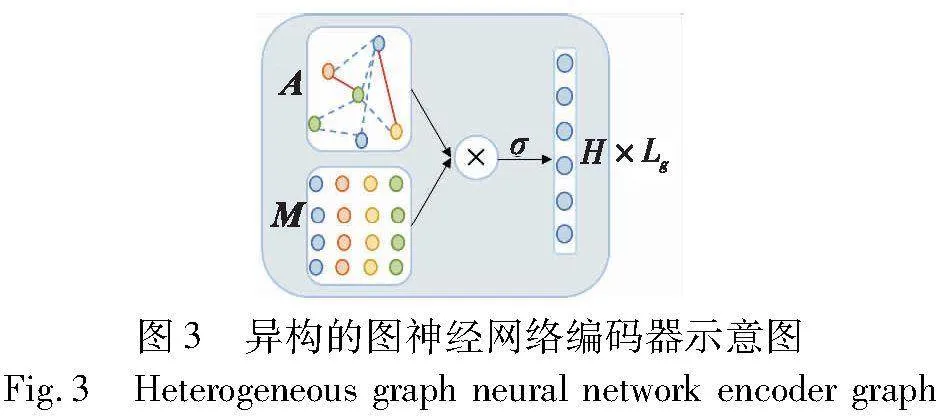
2.2 基于异构的图神经网络的编码器
异构的图编码器旨在捕获不同类型节点之间的关系,并输出异构图中所有节点的表示。这些节点的表示被馈送给解码器以生成响应。
2.2.1 图的构建
如图2所示,本文构造异构的图G=(V,S),其中V表示节点的集合,S表示相邻两节点之间的边。具体来说,本文考虑了四种类型的异质节点,分别为:a)对话历史U;b)面部表情F;c)情感类别E;d)说话者S。然后,在这些节点之间建立了边S,因为两个节点之间存在着紧密联系:a)同一说话者相邻或说的两个话语之间;b)在话语和相应的面部表情之间;c)话语和相应的情感之间;d)话语和相应的说话者之间;e)相邻说话者的两个面部表情之间;f)面部表情和相应的说话者之间;g)同一句话对应的面部表情和情绪之间。
2.2.2 异构的图编码
然后,在进行HGNN的处理过程中,该网络考虑各种不同类型的节点,并且通过使用可训练矩阵将这些节点映射到一个共同的隐式空间。这个共同的隐式空间是HGNN的核心,因为它能够将节点间的关系和相互作用转换为数学上可处理的形式,从而使得网络能够更好地进行学习和预测。
其中:σ是激活函数;Wlτ是变换矩阵;blτ为偏置;Hl为相邻节点的特征,初始H0=[Xu;Xf;Xe;Xs]。
2.2.3 聚合异构邻居节点
通过堆叠这样的Lg层,即多次对相邻节点进行特征聚合和变换,HGNN可以聚合来自各个节点的特征,并且HGNN包含所有节点的表示。因此,可以得到最终的输出Henc为
2.3 情感预测器
在充分感知来自多个不同来源的情绪后,异构的图编码器将表示存储在最后一层。情感预测通常需要考虑文本中的上下文信息,以更准确地预测情感,因此将双向循环神经网络(bidirectional recurrent neural network,BiRNN)集成到该模型,使其更好地捕捉文本中的上下文信息。为了将不同的表示向量转换为固定大小的向量,该模型采用了maxpooling的方式将表示Henc转换为固定大小的向量:
然后采用一个全连接层来预测合适的情感:
P=softmax(WpHmax)(8)
2.4 基于注意力机制的双层解码器
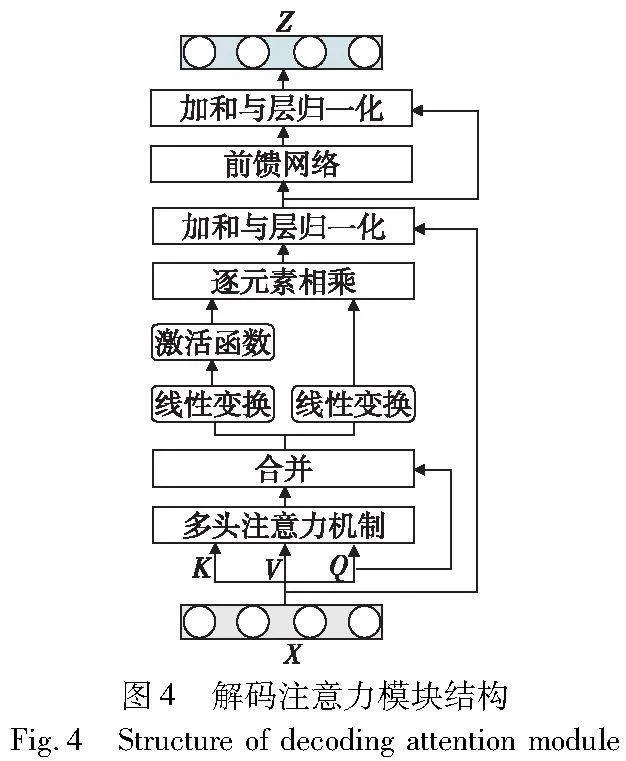
为了增强生成句子之间的相关性且富有情感,本文引入了双层的注意力解码器,逐词生成响应。对于第一层解码器,在异构的图编码器后融合一个解码注意力模块(AoA_attention),图4是解码注意力模块的结构。
如图4所示,在多头注意模块上引入了另一个注意函数来度量注意结果V′和Q之间的关系。通过两次单独的线性变换生成信息向量(I)和注意门(G),可以表示为
为了得到第t个单词yt,首先将前面的单词y1:t-1作为输入,得到带有多头注意的表示Hr:
Hr=MultiHead(R,R,R)(12)
其中:R为目标响应r已生成单词的嵌入序列。然后,采用另一个多头注意,再加上一个FFN层,以响应表示Hr为查询,以Hatt作为键和值输出表示O:
将预测的情感和说话者融入到生成过程中:
其中:Ep是由情感分布P与情感参数矩阵EMB1的加权和产生的混合情感表示;Sp是从说话者参数矩阵EMB2中检索到的当前说话者sN+1的特征。
最后,利用softmax层以情感-个性感知表示Oes作为输入,获取单词概率。因此,单词yt的概率计算如下:
P(yt|y1:t-1;G;Ep;Sp;θ)=softmax(WoOest)(16)
2.5 损失函数
该模型可以端到端训练,整个训练目标由响应生成损失LMLL和情感分类损失LCLS组成,如下所示。
其中:λ是平衡生成损失和分类损失的折现系数;eN+1是最佳标签。
3 实验结果与分析
3.1 实验环境介绍
本文算法通过使用Python包装在TensorFlow 2.5.0框架中实现。TensorFlow是由Google开发的一款开源软件库,广泛用于多种机器学习任务,包括图像分类、自然语言处理、语音识别等领域。它具有灵活性高、可移植性强、可扩展性好等特点。在使用TensorFlow框架的过程中,可以充分利用其强大的工具集,加速模型的训练过程,提升模型的精度和鲁棒性。本文的实验过程中,软硬件配置设计如下:a)处理器为Intel Core i7-10700 CPU;b)操作系统为64位的Ubuntu 20.04.1;c)显卡为NVIDIA GeForce RTX 3090 GPU。
3.2 对比模型
对MEDG-DD进行多模态情感对话生成实验,并与当前对话生成任务和情感对话生成任务主流的模型进行了比较,包括ReCoSa、HGNN、seq2seq、E-HRED等。
a)ReCoSa[14]。该模型采用了词级别LSTM编码对对话上下文进行编码,然后采用自注意力机制进一步捕获对话上下文表示,最后通过交叉注意力机制计算上下文和响应之间的关系。为了使比较更具说服力,本文扩展了该模型,通过将面部表情、情感类别和说话人的个性特征连接到对话历史表示来利用了多源信息,并使用了相同的损失函数进行训练。
b)HGNN[9]。该模型涵盖了异构的图编码器,通过异构的图卷积网络表达对话内容,以及情感-个性感知解码器,用于生成与对话上下文相关且带有情感的回应。
c)E-HRED[21]。它是一个分层的编码器-解码器网络,通过添加额外的编码器来表示对话的情感标签作为解码器的情感上下文,由于其上下文建模能力而表现良好。
d)BART[22]。它是基于当前最新文本生成器,该生成器在大规模文本数据上进行了预训练模型。
3.3 数据集
a)MELD数据集[23]。其源自电视剧《老友记》,包含了情感丰富的多轮对话数据,涵盖了多个发言者参与的对话,并分为训练集、验证集和测试集,分别包含1 039、114和280个对话。其中每个样本都包含对话视频、对话文本和响应的情感标签。数据集中共涵盖了愤怒、厌恶、悲伤、喜悦、中性、惊讶和恐惧七种情感标签。
b)DailyDialog数据集[24]。为了验证本文模型在数据集上的泛化性,在DailyDialog上进行了实验。该数据集包含13 118个多回合对话,反映了日常交流方式。每个对话的参与者平均进行了约8个回合,且只包含与MELD数据集相同情感类别的文本话语。为了使本文模型适应DailyDialog,在构建的图中删除了面部表情和说话者节点。
3.4 评价指标与参数设置
本实验使用了多种评价指标来对模型的性能进行评估,其中包括三种评价情感性能的指标(accuracy、recall和weight F1-score)及两种自动评价对话生成质量的指标(BLEU和distinct)。
a)accuracy。其指分类器正确分类的样本数占总样本数的比例,公式如下:
其中:TP表示真正例(true positive);FN表示假反例(false negative)。
b)recall。其指分类器正确分类为正例的样本数所占真正例样本数的比例,公式如下:
c)F1-score。其指precision和recall的调和平均数,用于综合评价分类器的性能,公式如下:
d)BLEU。其使用一种改进的词组匹配方法来衡量生成的回复与一个或多个参考答案之间的相似度。
e)distinct。本文实验使用与文献[25]相同的方法,将不同字母的数据除以总字母数和总单词数。本实验中分别用distinct-1和distinct-2表示这两个度量指标。
f)人工评价。本实验中采用了文献[15]的人工评分标准作为参考。人工评价过程中邀请三名研究自然语言处理的同学作为人工注释。
在MELD数据集上实验的超参数设置如表1所示。
3.5 实验结果与分析
1)自动评价结果
MELD数据集上的自测评价指标结果如表2所示。
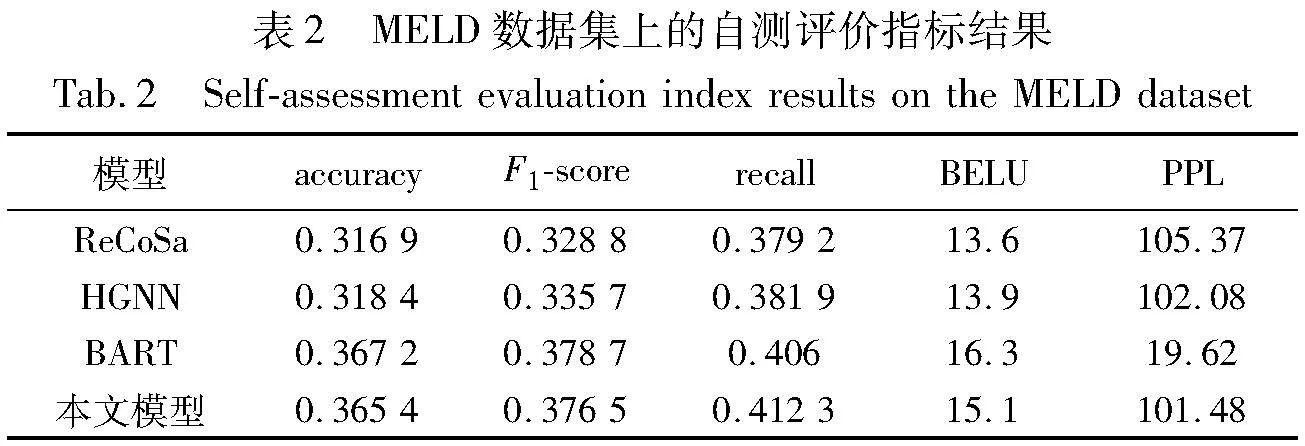
表2的结果显示,在MELD数据集上,通过异构的图神经网络编码和双层解码,MEDG-DD在情感对话生成方面表现优于当前最新的基线模型。由表2可以得出以下结论:
a)在情感预测指标中,与ReCoSa相比,本文模型的accuracy提高了4.85%,F1-score提高了4.77%,recall提升了3.31%;与HGNN相比,本文模型的accuray提高了4.7%,F1-score提高了4.08%,recall提升了3.04%。从表2的结果可以看出,通过利用异构的图神经网络,本文模型能够更充分地感知不同说话者之间的情感,从而获得更恰当的情感反馈。
b)在生成对话指标中,与ReCoSa相比,本文模型在BELU上提升了1.5%,PPL降低了3.89;与HGNN相比,本文模型在BELU上提升了1.2%,PPL降低了0.6。与预训练模型BART相比,本文模型在性能上稍微逊色一些,主要是因为BART在大规模无标注文本数据上进行了预训练,学习到了丰富的语言表示和上下文信息。表2的结果进一步表明,将多模态知识融入到多轮情感对话中,可以更充分地感知不同说话者之间的情感,并且表明使用双层解码器可以生成更相关的响应。
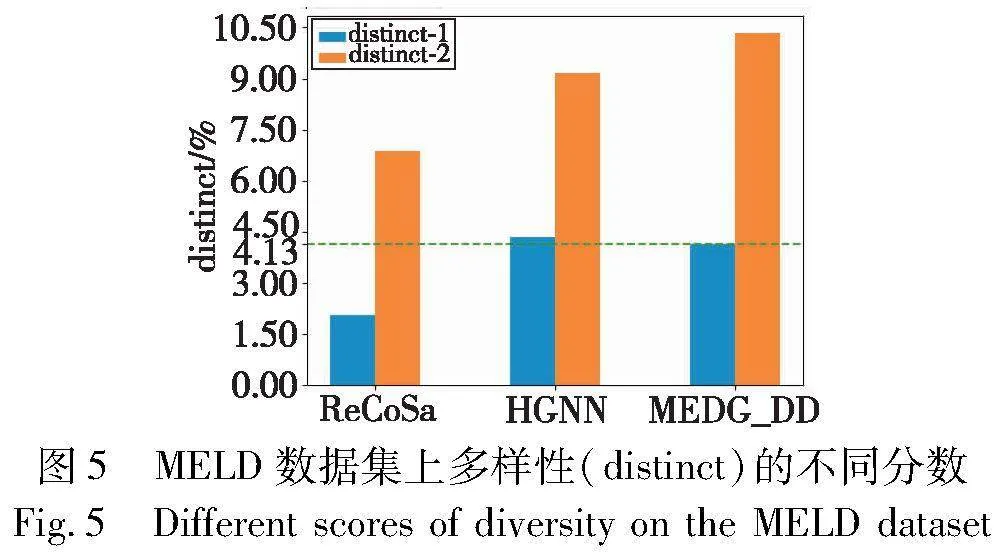
为了进一步测试生成句子的多样性,本实验利用distinct-1和distinct-2在MELD数据集上评估生成的句子。实验结果如图5所示。与ReSoCa相比,本文模型在distinct-1和distinct-2上分别提升了2.06%和3.45%;与HGNN相比,本文模型在distinct-1上降低了0.21%,但是在distinct-2上提高了1.18%。实验证实,本文模型不仅能够准确地捕捉语义和上下文信息,还能够生成多样性丰富的句子。
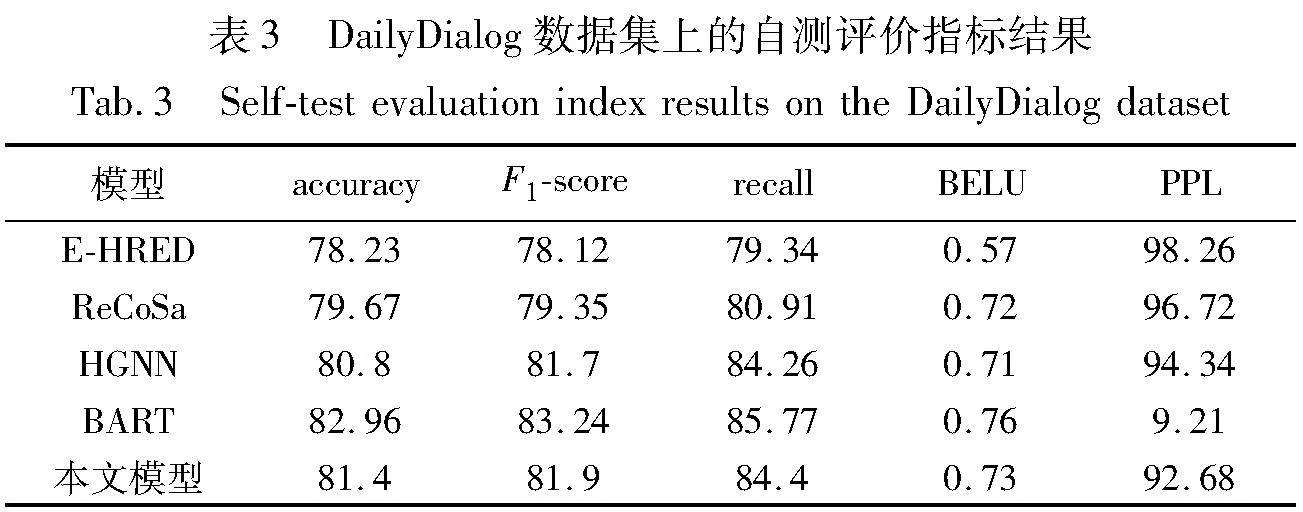
为了验证MEDG-DD的泛化性,在一个更大的数据集DailyDialog上进行了实验,实验结果如表3所示,显示了本文模型的泛化性。在DailyDialog数据集上,通过异构的图神经网络编码和双层解码,MEDG-DD在情感对话方面表现优于当前最新的基线模型。其中,本文模型在accuracy上可以达到81.4%,BELU达到了0.73,这意味着它在识别和回答情感对话中的相关信息时更加准确和全面。
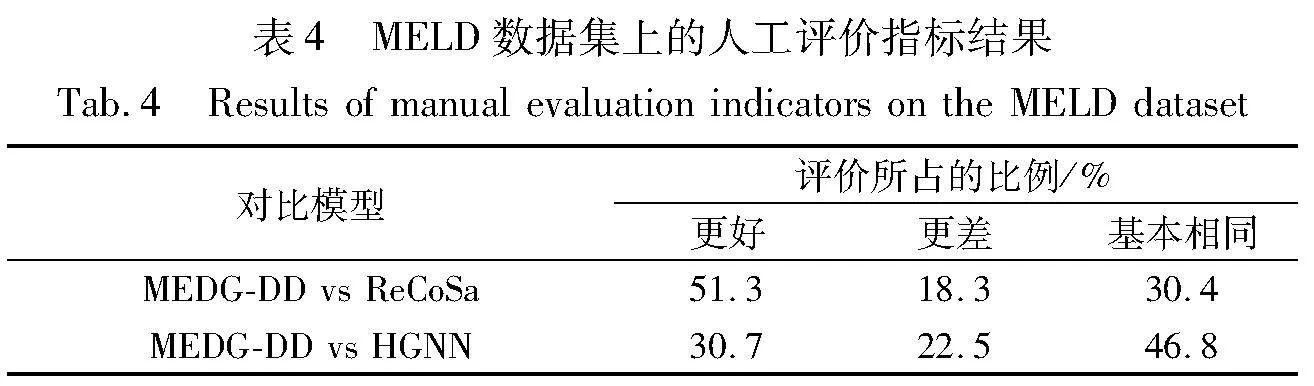
2)人工评价结果
在表4中,更佳的百分比始终高于较差的百分比,这表明MEDG-DD能够生成更加连贯和自然的响应。在MELD数据集上,与ReCoSa和HGNN相比,MEDG-DD的偏好增益(更佳相对较差)分别为33%和8.2%。
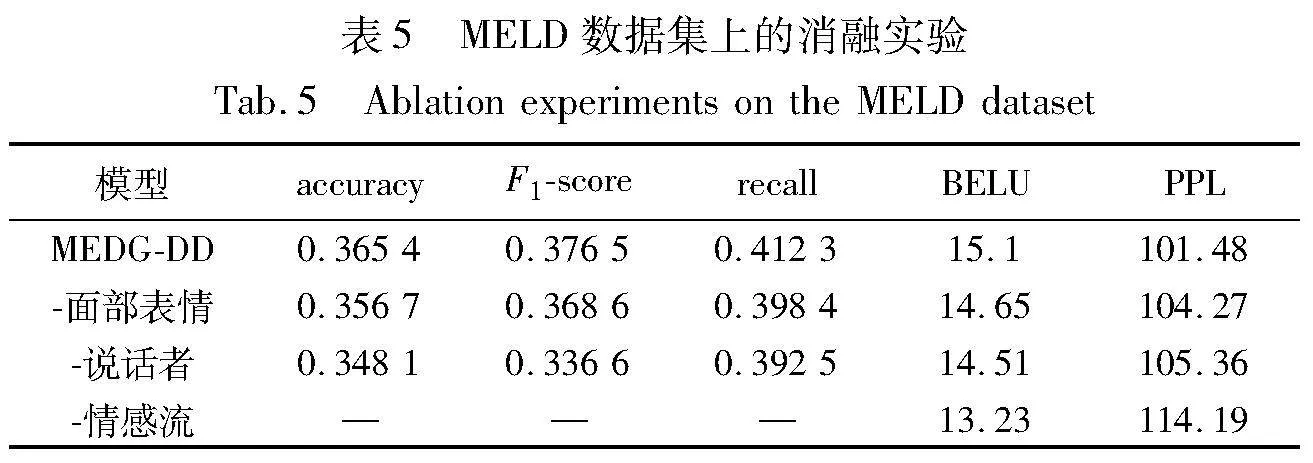
3)消融实验
为了更好地说明多种模态对对话生成的影响,本文在多模态情感会话数据集MELD上进行了实验。表5展示了MEDG-DD在MELD数据集上进行消融实验的结果。在实验过程中,本文每次删除一个模态,考察模型在不同条件下的表现。完整模型包含对话历史、情感流、面部表情(图像)和说话者信息。表5的第2~4行呈现了删除相应节点信息后的实验结果。通过对第1和第2~4行的实验结果进行比较,可以得出以下结论:在去除每个异构节点信息后,内容和情感的反馈质量都会不同程度地降低,这表明面部表情、情感流和说话者对于理解内容、情感感知和表达,尤其是情感流的重要性不可忽视。
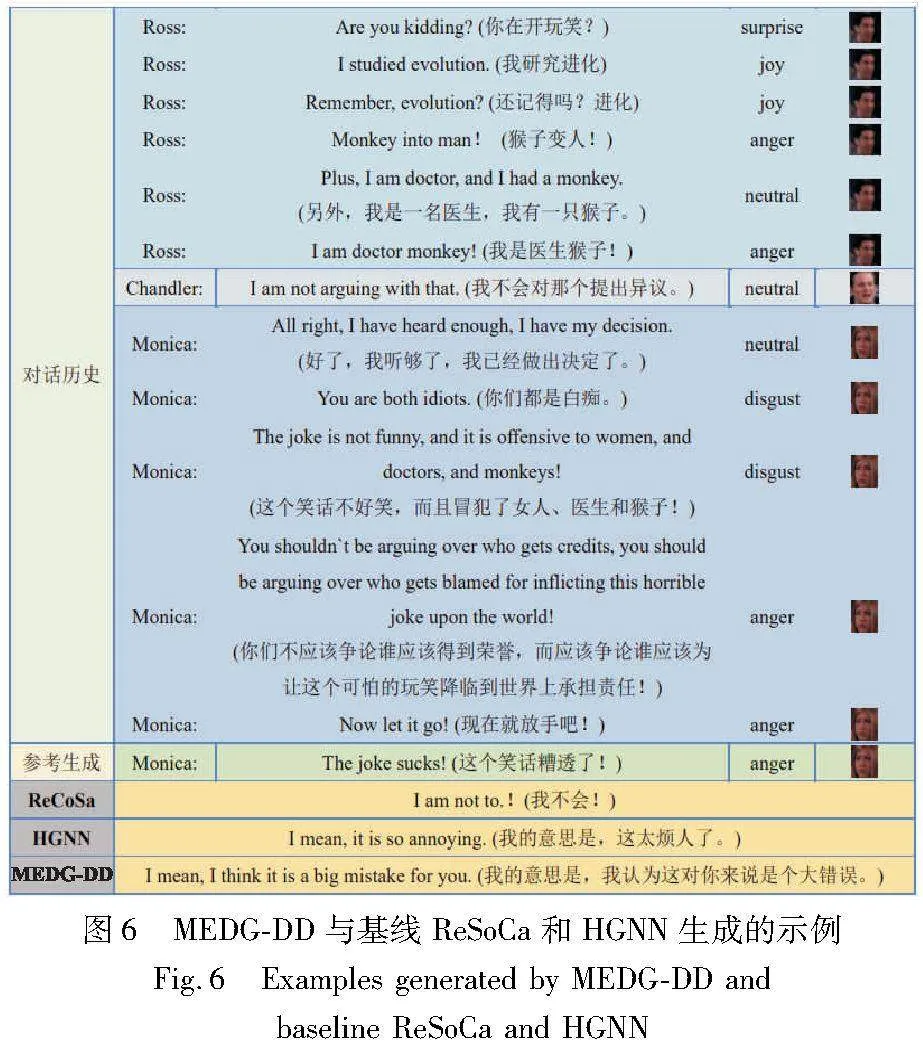
4)案例分析
为了更加深入地了解生成的响应是否相关和连贯,以及情感是否得到恰当的表达,本文提供了MELD测试数据集的示例,如图6所示。从结果来看,HSAN的性能明显优于其他两个模型,在图6中,说话者们正在讨论有关猴子进化成人的话题,所有基线模型都可以生成相关的响应。然而,相比于ReCoSa生成的响应“I am not to!(我不会!)”,MEDG-DD生成的响应在情感表达上更为恰当且更与话题相关;相比于HGNN生成的响应“I mean, it is so annoying. (我的意思是,这太烦人了。)”,MEDG-DD生成的响应则成功地捕捉了对话历史中说话者们的情感和话题的连贯性。综上所述,MEDG-DD可以像人类一样生成恰当情感并具有连贯性的响应,同时更多关注上下文中的重要部分。
4 结束语
本文提出了一种基于双层解码的多轮情感对话生成模型,该模型主要由异构的图神经网络编码器模块和基于注意力机制的双层解码器模块组成。异构的图神经网络编码器模块用于理解对话内容,并从对话历史、面部表情、说话者个性和情感流中充分感知复杂和微妙的情感,然后预测合适的情感进行反馈。基于注意力机制的双层解码器模块通过将当前说话者和预测情感融入作为输入,可以生成一个响应,它不仅与对话上下文相关,而且具有恰当的情感表达。实验结果表明,MEDG-DD不仅可以从多模态的知识中充分地感知说话者们的情感,而且可以生成更有吸引力和更令人满意的响应。在未来的工作中,首先希望从更多的模态中感知说话者们的情感,例如肢体动作、突然地打断插话等。此外,还计划优化这一模型,并将其应用于中文数据集。
参考文献:
[1]Li Mei, Zhang Jiajun, Lu Xiang, et al. Dual-view conditional variational auto-encoder for emotional dialogue generation[J]. Trans on Asian and Low-Resource Language Information Processing, 2021,21(3): 1-18.
[2]曹亚如, 张丽萍, 赵乐乐. 多轮任务型对话系统研究进展[J]. 计算机应用研究, 2022, 39(2): 331-341. (Cao Yaru, Zhang Liping, Zhao Lele. Research progress on multi-turn task-based dialogue systems[J]. Application Research of Computers, 2022,39(2): 331-341.)
[3]Serban I, Sordoni A, Bengio Y, et al. Building end-to-end dialogue systems using generative hierarchical neural network models[C]//Proc of the 30th AAAI Conference on Artificial Intelligence. Palo Alto,CA:AAAI Press, 2016:3776-3783.
[4]Poria S, Majumder N, Mihalcea R, et al. Emotion recognition in conversation: research challenges, datasets, and recent advances[J]. IEEE Access, 2019,7: 100943-100953.
[5]Li Yang, Wang Yuanzhi, Cui Zhen. Decoupled multimodal distilling for emotion recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2023: 6631-6640.
[6]谭晓聪, 郭军军, 线岩团, 等. 基于一致性图卷积模型的多模态对话情绪识别[J]. 计算机应用研究, 2023, 40(10): 3100-3106. (Tan Xiaocong, Guo Junjun, Xian Yantuan, et al. Multimodal dialogue emotion recognition based on consistency graph convolution model[J]. Application Research of Computers, 2023,40(10): 3100-3106.)
[7]Wei Wei, Liu Jiayi, Mao Xianling, et al. Emotion-aware chat machine: automatic emotional response generation for human-like emotional interaction[C]//Proc of the 28th ACM International Confe-rence on Information and Knowledge Management. New York:ACM Press,2019: 1401-1410.
[8]Mao Yanying, Cai Fei, Guo Yupu, et al. Incorporating emotion for response generation in multi-turn dialogues[J]. Applied Intelligence, 2021,52: 1-12.
[9]Liang Yunlong, Meng Fandong, Zhang Ying, et al. Infusing multi-source knowledge with heterogeneous graph neural network for emotional conversation generation[C]//Proc of the 35th AAAI Confe-rence on Artificial Intelligence. Palo Alto,CA:AAAI Press, 2021: 13343-13352.
[10]Sordoni A, Bengio Y. A hierarchical recurrent encoder-decoder for generative context-aware query suggestion[C]//Proc of the 24th ACM International Conference on Information and Knowledge Management. New York:ACM Press, 2015:553-562.
[11]Serban I, Sordoni A, Lowe R, et al. A hierarchical latent variable encoder-decoder model for generating dialogues[C]//Proc of the 31st AAAI Conference on Artificial Intelligence. Palo Alto,CA:AAAI Press, 2017:3295-3301.
[12]Serban I, Klinger T, Tesauro G, et al. Multiresolution recurrent neural networks: an application to dialogue response generation[C]//Proc of the 31st AAAI Conference on Artificial Intelligence. Palo Alto,CA:AAAI Press, 2017:3288-3294.
[13]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc., 2017:6000-6010.
[14]Zhang Hainan, Lan Yanyan, Pang Liang, et al. ReCoSa: detecting the relevant contexts with self-attention for multi-turn dialogue generation[EB/OL]. (2019). https://arxiv.org/abs/1907.05339.
[15]Kong Yawei, Zhang Lu, Ma Can, et al. HSAN: a hierarchical self-attention network for multi-turn dialogue generation[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2021: 7433-7437.
[16]Zhou Hao, Huang Minlie, Zhang Tianyang, et al. Emotional chatting machine: emotional conversation generation with internal and external memory[C]//Proc of the 32nd AAAI Conference on Artificial Intel-ligence. Palo Alto,CA:AAAI Press, 2018:730-738.
[17]Majumder N, Hong Pengfei, Peng Shanshan, et al. MIME: MIMicking emotions for empathetic response generation[EB/OL]. (2020). https://arxiv.org/abs/2010. 01454.
[18]Shen Lei, Feng Yang. CDL: curriculum dual learning for emotion-controllable response generation[EB/OL].(2020).https://arxiv.org/abs/2005.00329.
[19]Zhong Peixiang, Zhang Chen, Wang Hao, et al. Towards persona-based empathetic conversational models[EB/OL].(2020).https://arxiv.org/abs/2004. 12316.
[20]杨丰瑞, 霍娜, 张许红, 等. 基于注意力机制的主题扩展情感对话生成[J]. 计算机应用, 2021, 41(4): 1078-1083. (Yang Fengrui, Huo Na, Zhang Xuhong, et al. Topic-extended emotional dialogue generation based on attention mechanism[J]. Journal of Computer Applications, 2021,41(4): 1078-1083.)
[21]Lubis N, Sakti S, Yoshino K, et al. Eliciting positive emotion through affect-sensitive dialogue response generation: a neural network approach[C]//Proc of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto,CA:AAAI Press, 2018:5293-5300.
[22]Lewis M, Liu Yinhan, Goyal N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[EB/OL].(2019).https://arxiv.org/abs/1910.13461.
[23]Poria S, Hazarika D, Majumder N, et al. MELD: a multimodal multi-party dataset for emotion recognition in conversations[EB/OL].(2018). https://arxiv.org/abs/1810.02508.
[24]Li Yanran, Su Hui, Shen Xiaoyu, et al. DailyDialog: a manually labelled multi-turn dialogue dataset[C]//Proc of the 8th International Joint Conference on Natural Language Processing.[S.l]: Asian Federation of Natural Language Processing, 2017: 986-995.
[25]Li Jiwei, Monroe W, Ritter A, et al. Deep reinforcement learning for dialogue generation[EB/OL].(2016).https://arxiv.org/abs/1606.01541.
