基于行为轮廓矩阵增强的业务流程结果预测方法
2024-07-31刘恒方贤文卢可



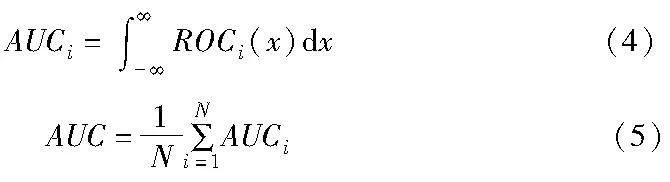
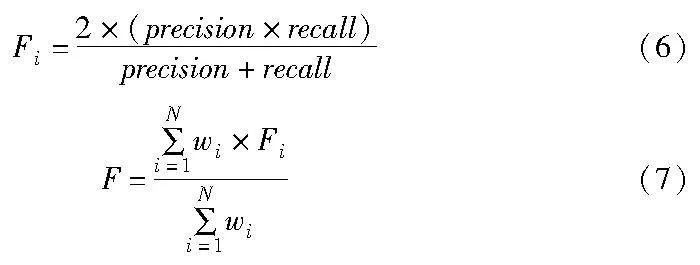
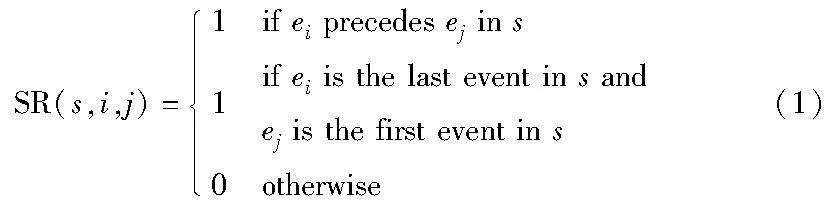
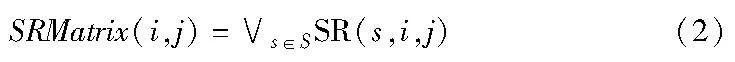
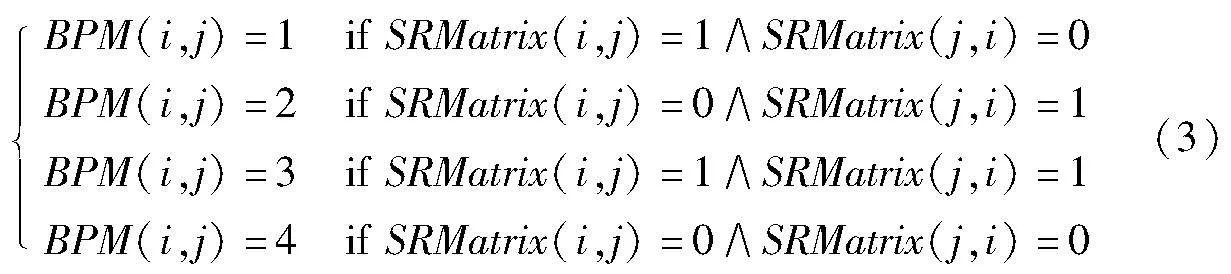
摘 要:预测性过程监控依赖于预测效果,针对如何增强预测性过程监控预测效果的问题,提出了一种基于行为轮廓矩阵增强的业务流程结果预测方法。首先,通过分析活动间的行为关系提取行为轮廓矩阵,并将其与事件序列一同输入到模型中。随后,结合卷积神经网络(CNN)和长短期记忆网络(LSTM)分别学习矩阵图像特征和序列特征。最后,引入注意力机制以整合图像特征和序列特征进行预测。通过真实事件日志进行验证,在预测事件日志结果方面,提出的增强方法对比基准的LSTM预测方法提高了预测效果,验证了方法的可行性。该方法结合行为轮廓矩阵增强了预测模型对事件日志中行为之间关系的理解,进而提升了预测效果。
关键词:行为轮廓; 预测性过程监控; 业务流程; 结果预测
中图分类号:TP311 文献标志码:A
文章编号:1001-3695(2024)06-023-1762-07
doi:10.19734/j.issn.1001-3695.2023.11.0524
Method for business process outcome prediction based onbehavior profile matrix enhancement
Abstract:Predictive process monitoring(PPM) relies on predictive effectiveness, and to address the challenge of improving predictive performance in PPM, this paper proposed a novel approach called behavior profile matrix enhanced business process outcome prediction. Initially, this approach extracted the behavior profile matrix by analyzing the interactions among activities and incorporated it into the model along with event sequences. Then, it used convolutional neural networks(CNN) and long short-term memory networks(LSTM) to independently capture image features from the matrix and sequence features. Finally, this approach integrated an attention mechanism to seamlessly combine both image and sequence features for predictive purposes. Validation using real event logs demonstrates that the proposed enhancement method significantly enhances predictive performance compared to the baseline LSTM prediction methods when forecasting event log outcomes, confirming the feasibility of this approach. This approach combines the behavior profile matrix to enhance the predictive model’s understanding of relationships between behaviors in event logs, consequently leading to an improvement in predictive performance.
Key words:behavior profile; predictive process monitoring; business process; outcome prediction
0 引言
预测性过程监控[1]是过程挖掘的一个重要分支,其主要目标是对正在进行但尚未完成的过程执行进行未来状态的预测。这些预测可能涉及到过程执行的结果、剩余时间以及未来活动的顺序。在许多领域和场景中,提前预测过程执行的结果[2~9]、案例的剩余时间[10,11]以及下一步活动[2,7,12,13],对于机构与个体都具有极高的价值。例如,在生产流程中,预测性过程监控可以帮助组织预防不良结果、问题和延迟的发生[14~16]。与传统的反映式业务流程监控[17]不同,预测性过程监控[18]的目标是在问题发生之前就能够预测违规或问题的发生,并采取相应的预防措施。这种预测性的方法可以帮助用户和组织更好地预防潜在的问题,并提高整体的工作效率。在数据科学、预测性分析和数据驱动的人工智能技术的推动下,预测性过程监控技术在过程挖掘领域迅速发展,并成为创新组织环境和过程挖掘工具中的重要功能。
在实际的业务生产中,往往会通过记录事件日志来跟踪和监控不同业务流程的执行情况。比如,在一个企业的生产过程中,可能会存在需要从第三方供应商采购原材料、制造产品、运输产品等多个环节,每个环节都会涉及到各种业务活动和交互。如果能够对这些事件日志进行预测性过程监控,就能更好地了解和优化整个生产流程的效率和质量。例如,可以通过预测未来事件序列的发展趋势,及时发现潜在的问题并作出相应的调整。同时,也可以通过分析事件之间的关系和活动之间的交互,挖掘生产过程中的瓶颈环节和优化点,以提高生产效率和减少成本。
在预测性过程监控的许多领域和场景中,本文主要讨论预测过程执行的结果,该任务是典型的多分类预测任务。已有学者尝试使用不同的方法进行结果预测,并取得了不错的效果。Teinemaa等人[2]定义了PBPM结果预测任务的时间稳定性概念,评估了现有方法的时间稳定性和准确性,实验证明,对比基于迹索引的XGBoost和LSTM方法具有最高的时间稳定性。受可解释人工智能(XAI)领域的启发,Galanti等人[4]提出了一个完全可解释的结果预测模型,以平衡预测性能和可解释性。Pasquadibisceglie等人[5]使用的前缀迹的图像增强表示扩展了文献[7]中的方法,利用图像中相邻像素标识前缀迹的顺序特征,从而能够准确地预测病例结果。上述方法采用深度学习技术进行实验,通过使用事件的独热(one-hot)编码和长短期记忆网络(LSTM)来执行多个业务流程预测任务,包括案例过程执行的结果、下一个活动,以及案例的剩余时间,形成了一个黑盒模型,这使得预测结果难以解释文献[7]的FOX模型。此外,Wickramanayake等人[9]利用不同的特征向量连接模式,提出了两种不同的预测模型,即基于共享注意的模型和专门的基于注意的模型,这两种模型通过事件注意和属性注意,将可解释性直接应用于预测模型来解释预测结果。文献[8]基于使用BERT(来自Transformers的双向编码器表示)对许多未标记的迹执行自我监督的预训练任务的掩盖预测活动模型(MAM),利用Transformers中的注意机制获得了活动之间的长期依赖关系,并使用迁移训练实现多任务预测。
在特征增强方法上,文献[12]尝试使用行为向量编码,将行为信息进行词向量编码输入到深度神经网络模型中,使预测下一个活动的效果获得了显著提升。文献[19]提出了一种基于批量迹与过程模型多视角对齐方法,结合了数据与资源视角实现对齐方法。
传统的行为轮廓的目的在于捕获活动之间的序列关系,并提取过程模型中的基本行为约束。然而,现有的过程模型挖掘方法对于生成复杂事件日志的模型可读性较低,不利于使用过程模型生成行为轮廓。同时,目前应用机器学习方法进行结果预测时较少考虑结合活动之间的复杂行为关系来增强预测效果。
为了解决上述问题,提出了一种基于行为轮廓矩阵增强的业务流程结果预测方法。该方法通过直接从日志中提取行为轮廓矩阵来表示活动之间的复杂行为关系,将复杂的过程模型简化为行为轮廓矩阵,从而增加了行为关系的可读性。与此同时,行为轮廓矩阵的数据结构便于机器学习的应用,结合行为轮廓矩阵将序列信息输入到结果预测任务的模型的训练和预测中,增强模型对活动之间的序列关系信息的学习,从而提高预测效果。
相较于前人工作,本文的主要贡献为:
a)提出了一种基于行为轮廓矩阵增强的业务流程结果预测方法。通过提取日志行为轮廓矩阵进行特征学习,结合原有的序列预测模型进行结果预测。即通过迹序列中活动之间的行为特征学习以增强预测效果。
b)使用真实案例的数据进行仿真实验,实验结果与现有的结果预测研究实验进行对比,预测效果达到领先水平。
1 基本概念
1.1 事件日志
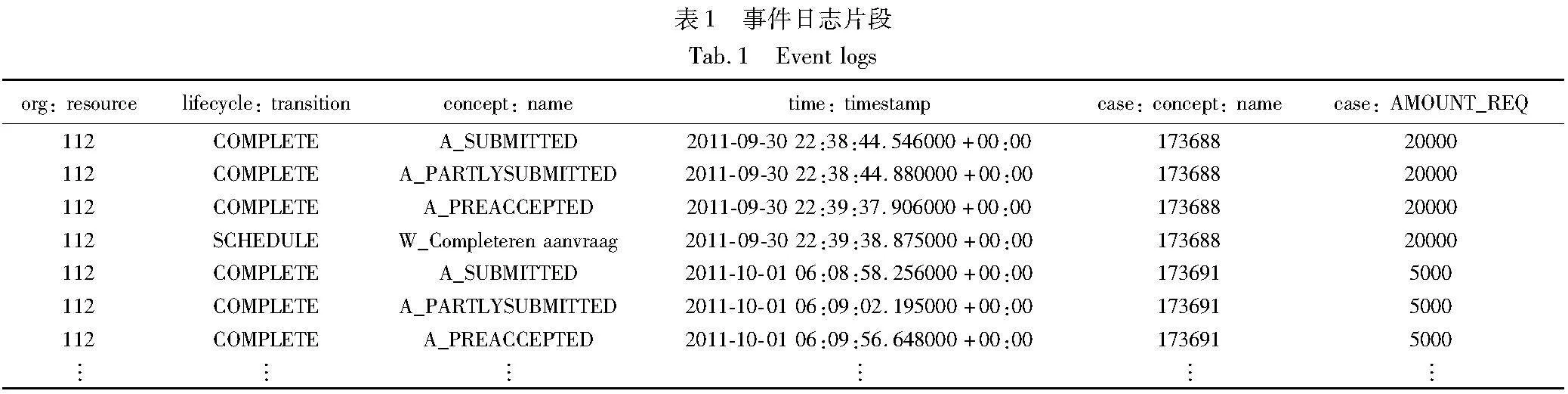
事件日志是一组迹的集合,每一条迹代表一次业务流程的执行。每条迹包含一系列事件,每个事件表示一个活动的执行。每个活动代表业务流程中的一个步骤。
定义1 事件event。假设事件空间E为所有事件标识符的合集,事件e∈E通常指活动a∈A的一次执行,可以由各种属性attr来表征,可以记作e=attr1,attr2,…,attrn。例如,事件可以具有时间戳time: timestamp、与活动相对应的名称concept:name、事件所属流程实例名称case:concept:name和生命周期lifecycle:transition等属性。
1.2 行为轮廓
为了获取过程模型的基本行为约束信息,本节引入模型行为轮廓的概念(简称行为轮廓)。
2 基于行为轮廓矩阵增强的业务流程结果预测方法
2.1 行为轮廓矩阵的识别
鉴于传统行为轮廓的不足,在传统行为轮廓的基础上重新定义一组行为轮廓关系概念,以更准确地描述事件之间的关系。为了识别事件之间的行为轮廓关系,本文需要借助事件之间的顺序关系进行提取,即直接通过控制流信息提取行为轮廓。
定义4 顺序关系。设S为一组序列,每个序列由事件组成。所有可能的事件集合为E,包含n个独特的事件,记作e1,e2,…,en。
对于S中的每个序列s和其中的任意事件ei和ej(其中i,j∈{1,2,…,n}),定义顺序关系SR如下:
定义5 顺序关系矩阵。设序列顺序关系矩阵SRMatrix为一个n×n的矩阵,其中每个元素SRMatrix(i,j)表示ei和ej在S中所有序列的顺序关系的累积结果。具体来说:
其中:∨表示逻辑或操作。若ei在任何序列s中直接位于ej之前,或ei是s的最后一个事件且ej是s的第一个事件,则结果为1,否则为0。
定义6 行为轮廓矩阵。设S为一组序列,每个序列由事件组成。所有可能的事件集合为E ,包含 n个独特的事件,记作(e1,e2,…,en)。其基于已经定义的顺序关系SR。
为了描述两个事件间的行为关系,定义行为轮廓矩阵BPM为一个n×n的矩阵。其中,对于矩阵的任意元素BPM(i,j),根据以下规则从序列关系矩阵SRMatrix计算而来:
严格序关系(strictly succession):如果事件ei在所有序列中总是出现在事件ej之前,并且事件ej从不出现在事件ei之前,则称ei对ej存在严格序关系。
严格逆序关系(strictly precedence):如果事件ej在所有序列中总是出现在事件ei之前,并且事件ei从不出现在事件ej之前,则称ei对ej存在严格逆序关系。
交叉序关系(interleaving):如果事件ei在某些序列中出现在事件ej之前,而在其他序列中出现在之后,则称ei对ej之间存在交叉序关系。
排他序关系(exclusively succession):如果事件ei和ej在所有序列中都无顺序关系,则称它们之间存在排他序关系。
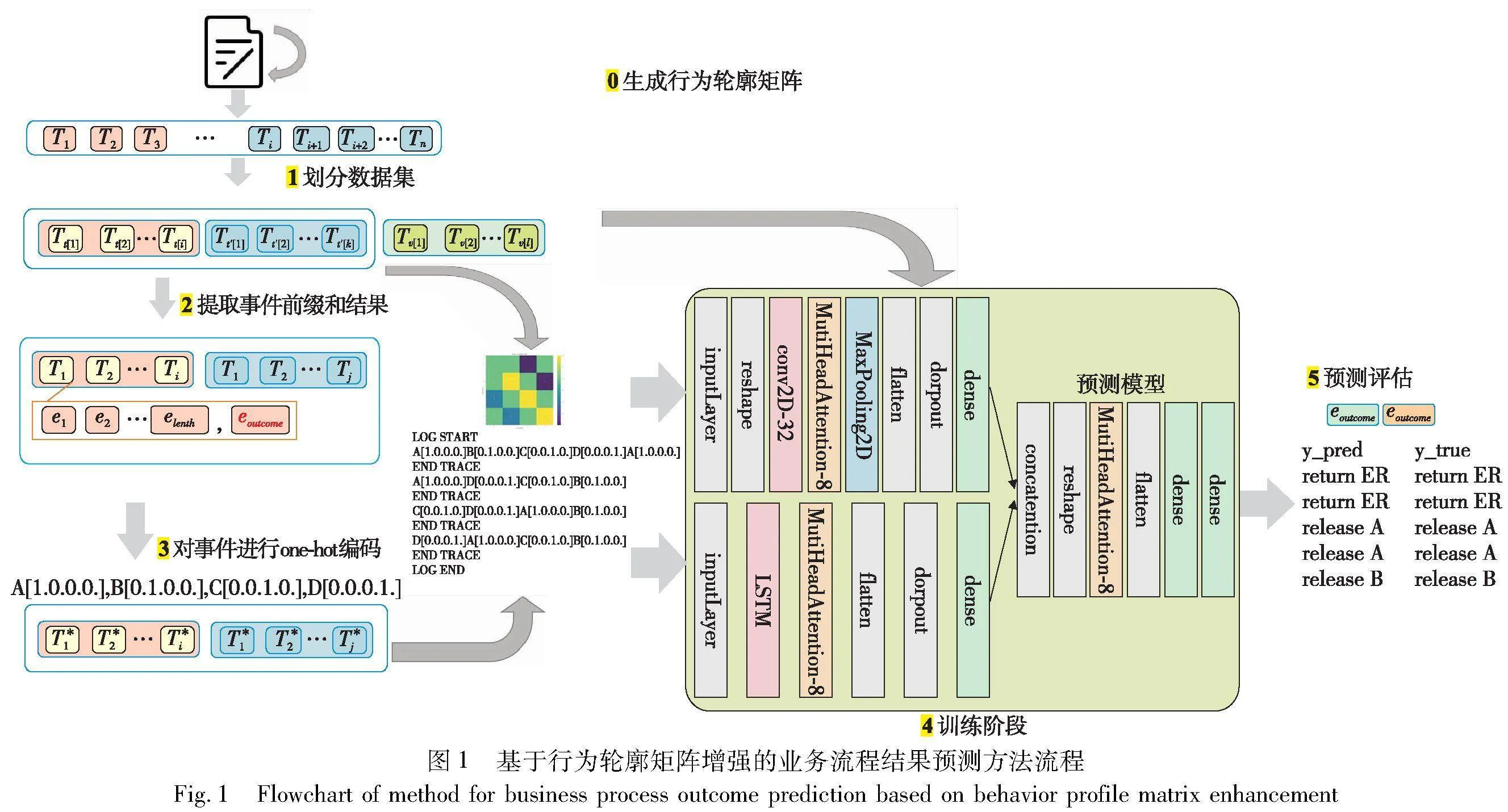
依据以上定义,行为轮廓矩阵BPM可以完整地反映序列集合S中各事件间的行为关系。基于行为轮廓矩阵增强的业务流程结果预测方法过程如图1所示。
2.2 基于行为轮廓增强的事件日志结果预测
基于行为轮廓增强的事件日志结果预测方法BPME主要包括三个阶段:数据处理阶段,包括划分数据集以及提取前缀迹和结果两个步骤;训练模型阶段,主要通过尝试不同参数提升模型效果;模型评估阶段,主要进行模型预测效果的评估。
a)数据处理阶段。通过算法1对事件日志的行为轮廓进行提取。并将数据分割为训练集、测试集、验证集,对应比例为0.5∶0.2∶0.3。对事件日志进行处理,首先将事件日志的迹提取出来,再将迹切割或填充为指定固定长度的事件序列,同时将每一条迹的结果进行提取作为预测标签。将获得的事件序列和结果标签用统一的one-hot编解码器进行编码。
b)训练模型阶段。通过将处理好的指定长度one-hot编码的事件序列输入到LSTM子模型以提取序列信息,将行为轮廓矩阵输入到CNN子模型中以提取图像信息。同时模型的分类特征编码为one-hot编码。神经网络构建预测模型的超参数设置如下:优化算法选用Adam,针对不同的事件日志设置调整学习率{0.01,0.001,0.0001}、批处理大小{256,128,64,32}、模型迭代次数{50,100,200}。
c)模型评估阶段。通过将训练好的模型用测试集数据进行预测,对比真实值和预测值,并计算AUC和F-score。
2.3 行为轮廓矩阵的生成
算法1提出了一种推导事件日志中的行为关系并生成行为轮廓矩阵的方法。该算法的目标是从事件序列中捕获事件之间的顺序关系,并将这些关系表示为一个行为轮廓矩阵。
算法1 推导事件日志行为关系生成行为轮廓矩阵
输入:事件序列组sequence_group。
输出:行为轮廓矩阵BPM。
为了得到在窗口内每个事件日志活动的行为轮廓矩阵,对不同行为轮廓类比给出不同的值。BP={→,←-1,‖,+}中的各个关系,将行为轮廓矩阵中的值设置为{1,2,3,4}。
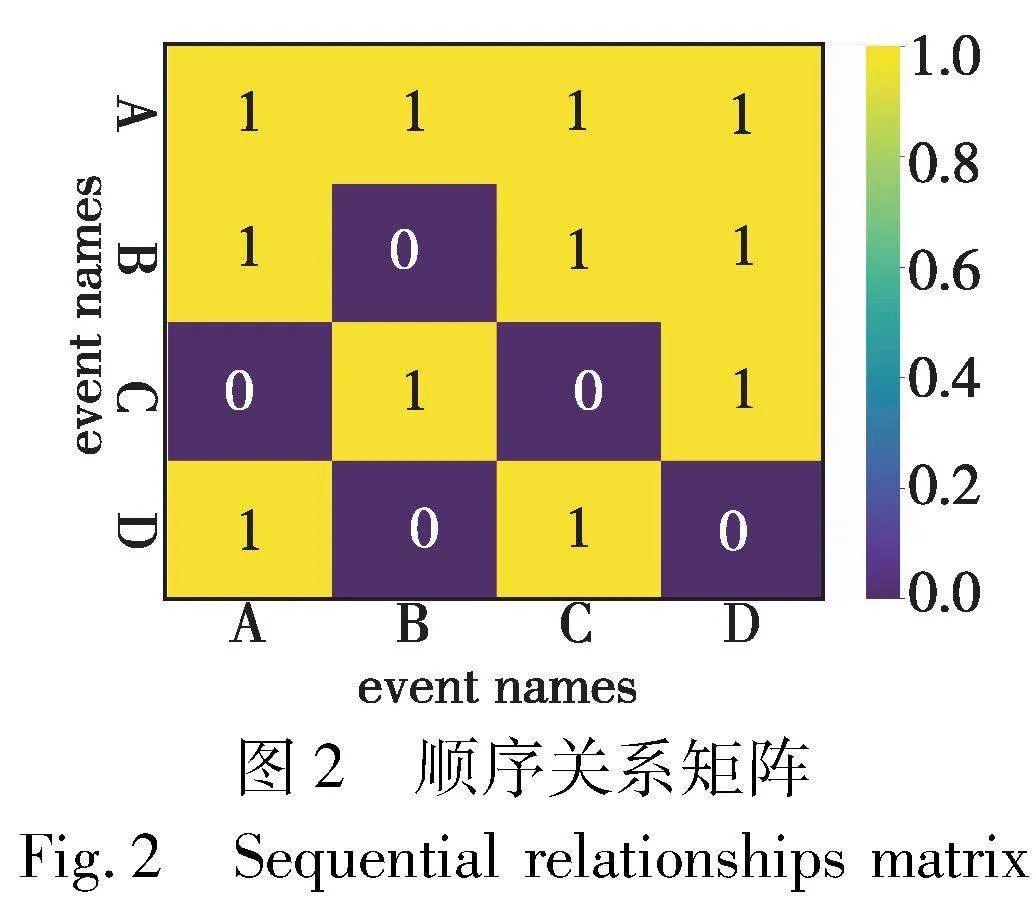
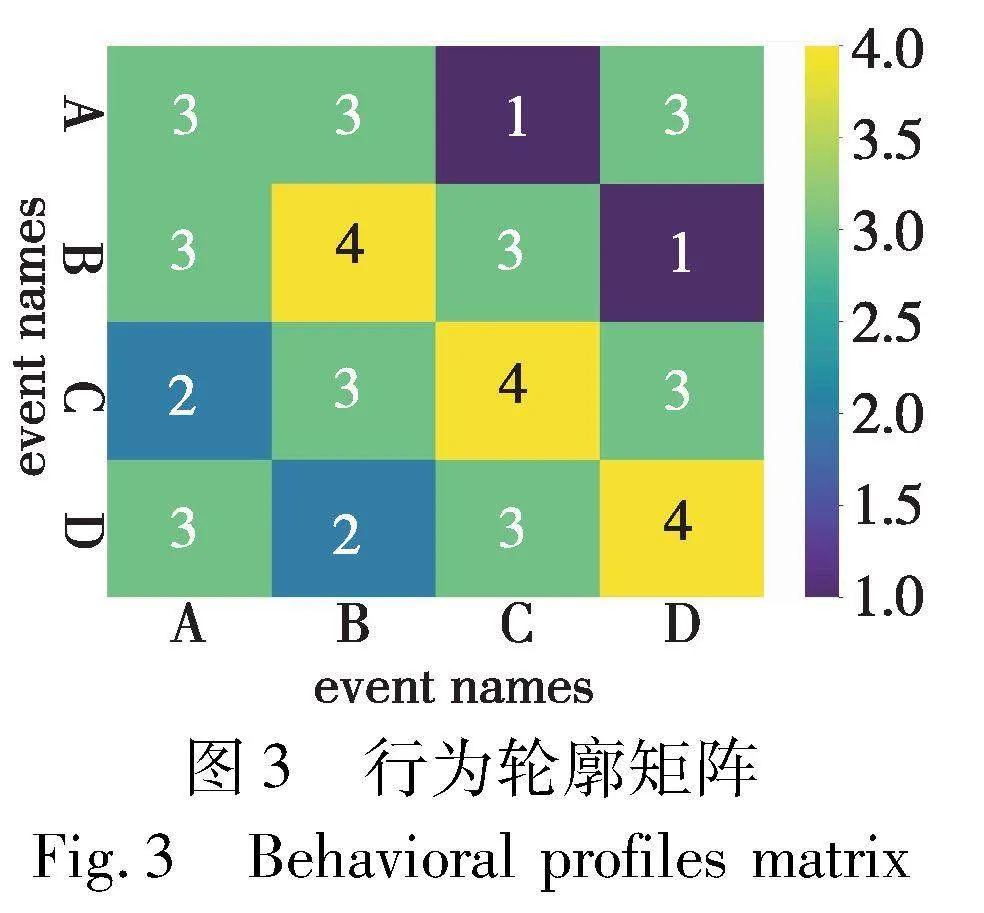
为了验证行为轮廓矩阵,给出序列组数据[′A′, ′B′, ′C′, ′D′,′A′],[′A′, ′D′, ′C′, ′B′], [′C′, ′D′, ′A′, ′B′],[′D′, ′A′, ′C′, ′B′],通过对上述人工数据运行算法1中的代码,先得到如图2所示的顺序关系矩阵,然后得到如图3所示的行为轮廓矩阵。
2.3.1 顺序关系矩阵
首先,算法1接受一个事件序列组作为输入。第1行通过遍历所有的事件序列,将其中出现的事件名称收集起来,形成一个事件名称的集合。这个集合的大小即为事件的种类数目,记为N。
然后,算法1第2~5行创建一个大小为N×N的顺序关系矩阵SRMatrix和行为轮廓矩阵BPM,初始值都设为0。顺序关系矩阵SRMatrix用于记录临近事件之间的行为关系,行为轮廓矩阵BPM则用于表示行为轮廓。
接下来,算法1第6行对于每个事件序列进行处理。对于序列中的每个事件,分别记录当前事件和下一个事件,并根据它们在事件名称集合中的索引,更新顺序关系矩阵中相应位置的值为1,表示存在行为关系。
以活动C为例:在顺序矩阵中活动C总是发生在活动A后面且不会重复出现;但是活动B和D均可能在活动C前后发生。因此,活动C的顺序矩阵行的值为[0,1,0,1],列的值为[1,1,0,1]。
2.3.2 行为轮廓矩阵
生成顺序关系矩阵SRMatrix后,算法1第7行,根据以下规则将顺序关系矩阵转换为行为轮廓矩阵的值:
如果顺序关系矩阵SRMatrix中的某个位置(i,j)为1且位置(j,i)为0,则将行为轮廓矩阵中对应位置的值设为1,表示严格序列行为轮廓(strict sequence events)。
如果顺序关系矩阵SRMatrix中的某个位置(i,j)为0且位置(j,i)为1,则将行为轮廓矩阵中对应位置的值设为2,表示严格逆序列行为轮廓关系。
如果顺序关系矩阵SRMatrix中的某个位置(i,j)为1且位置(j,i)也为1,则将行为轮廓矩阵BPM中对应位置的值设为3,表示排他序列行为轮廓关系。
如果顺序关系矩阵SRMatrix中的某个位置(i,j)为0且位置(j,i)也为0,则将行为轮廓矩阵BPM中对应位置的值设为4,表示交叉序列行为轮廓关系。
以活动C为例:更进一步,可以分析出活动A、B、C、D之间的行为轮廓关系,例如,BP(A,C)=→, BP(C,A)=←-1, BP(C,B)=‖,BP(C,C)=+,BP(A,A)=‖,对应到行为轮廓矩阵中的值为BPM(A,C)=1,BPM(C,A)=2,BPM(C,B)=3,BPM(C,C)=4,BPM(A,A)=3。
在行为轮廓矩阵中,由于行为轮廓中的严格序和严格逆序是互逆的,值1(严格序→)和2(严格逆序←-1)的关系在矩阵中成对角线对称。对于对角线中的值,如果同样的活动在同一迹中重复发生则将赋值为3(交叉序‖),相反活动在同一迹中只发生唯一一次则将被赋值为4(排他序+)。
最后,算法返回生成的行为轮廓矩阵BPM作为输出结果。这个行为轮廓矩阵可以帮助理解事件日志中不同事件之间的行为关系,并根据行为轮廓来分析和挖掘事件序列中的行为模式。通过这种方式,可以获得对事件行为更深入的认识,并从中发现隐藏的规律和趋势。
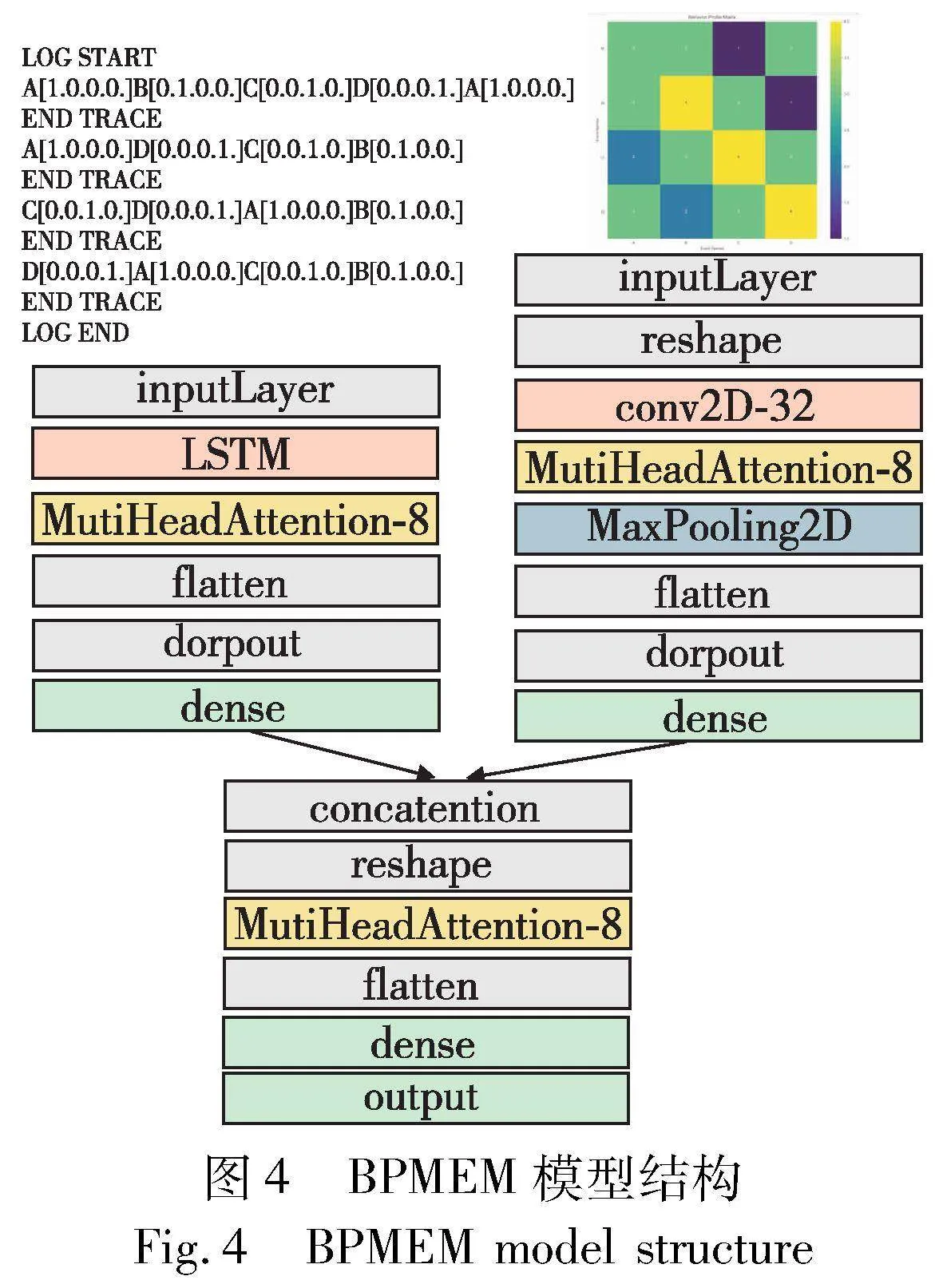
2.4 BPMEM模型
行为轮廓矩阵增强模型(behavioral profile matrix enhancement model,BPMEM)是一个基于深度学习的模型,其中结合了LSTM、CNN以及多头注意力机制(multi-head attention)。通过将日志生成行为轮廓矩阵信息和事件序列信息作为输入,用于预测事件日志事件执行的结果。BPMEM模型结构如图4所示。
1)模型输入
输入1:编码后的序列X,其形状为(length,num_events),其中length是序列长度,num_ events是事件数量,该张量表示一个长度为length、one-hot编码长度为num_events的序列。
输入2:行为配置矩阵(behavior_profile_matrix),形状为(num_events,num_events)。
2)LSTM子模型
在输入X上使用一个LSTM层,其中有512个单元,并返回序列。
LSTM的输出传递给一个多头注意力层,此处使用8个头,并设置key_dim为512。
注意力机制的输出被扁平化。
3)CNN子模型
输入行为配置矩阵经过一个reshape层,增加一个维度以适应Conv2D。
使用Conv2D层,其中有32个过滤器,大小为(3,3),激活函数为ReLU。
Conv2D的输出传递给一个多头注意力层,此处使用8个头,并设置key_dim为32。
注意力机制的输出传递给一个MaxPooling2D层。
最后,pooling的输出被扁平化。
4)dropout与dense层
在CNN与LSTM的输出后都添加了dropout层,减少过拟合风险,其中dropout的比例为0.5。
使用dense层调整CNN与LSTM的输出形状。
5)拼接与注意力
LSTM与CNN的输出进行拼接。
拼接后的输出经过reshape层调整形状,然后传递给一个多头注意力层,此处使用8个头,并设置key_dim为1 088。
扁平化注意力机制的输出。
6)输出
使用一个dense层调整拼接后的输出形状,其中有1 024个单元,激活函数为ReLU。
最后的输出形状为(num_events),使用softmax激活函数,得到对应结果的one-hot编码。
3 行为轮廓矩阵增强方法BPME实例分析
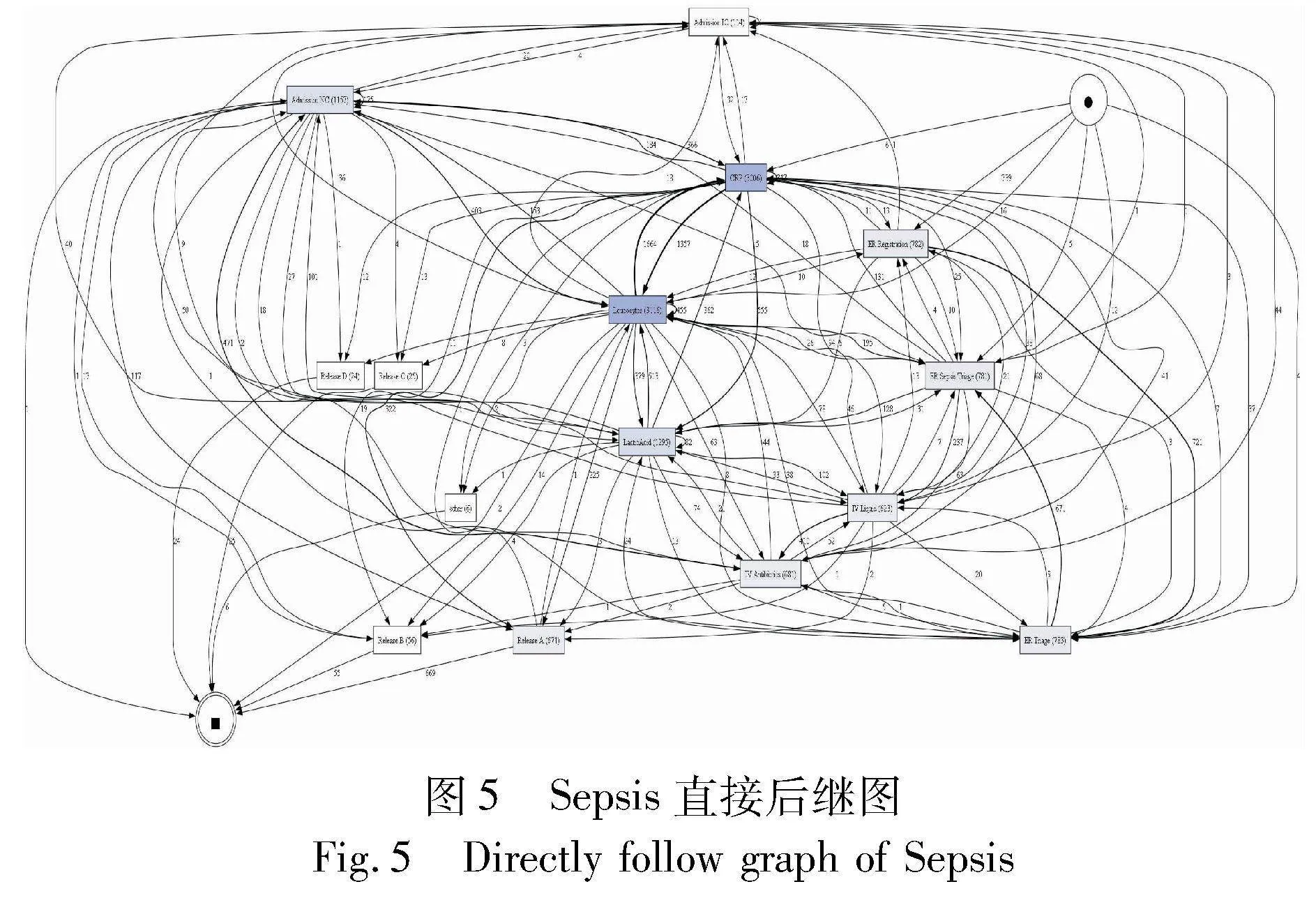
Sepsis是一份记录荷兰某医院中患有败血症的患者病例过程的事件日志。每个病例记录了从患者在急诊室登记到出院的事件过程。
在这个案例中,一条完整的事件序列是包含了一系列的治疗事件的过程。为了保护患者隐私,治疗事件过程的结果被处理为Release A,Release B,…。通过对事件日志数据的提取,一条患者病例的完整过程实例如下所示:ER Registration,Leucocytes,CRP,LacticAcid,ER Triage,ER Sepsis Triage,IV Liquid,IV Antibiotics,Admission NC,CRP,Leucocytes,Leucocytes,CRP,Leucocytes,CRP,CRP,Leucocytes,Leucocytes,CRP,CRP,Leucocytes,Release A。
通过对上述患有败血症的患者病例过程的事件日志进行过程挖掘,得到如图5所示的Sepsis直接后继图过程模型。可以看到,过程模型可以将事件间的行为关系进行展示,例如:治疗过程通常开始于ER Registration、Leucocytes、CRP等事件;结束于Release A、Release B等结果事件;所有结果事件发生前的序列可能通过Admission NC或者Admission IC进入循环,即重新诊疗。
但是由于事件之间的关系复杂,较难从过程模型直接推断出当前治疗过程的后续事件的发生顺序,更不要说预测结果。同时,过程模型的数据结构较难转换为机器学习方法常见的张量形式。
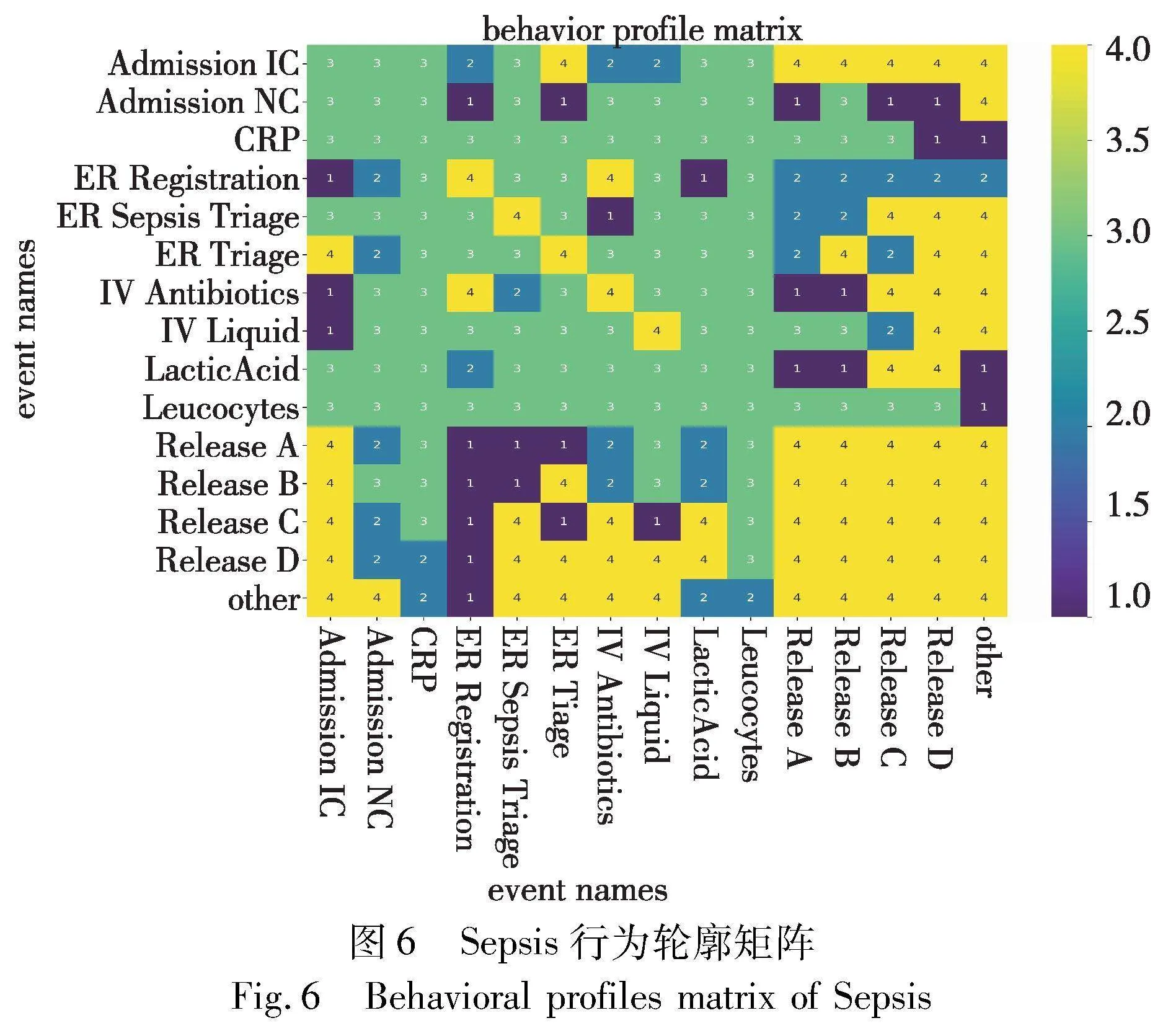
通过对上述患有败血症的患者病例过程的事件日志,应用推导事件日志行为关系生成行为轮廓矩阵的方法,生成对应的行为轮廓矩阵,如图6所示。
通过行为轮廓矩阵,对事件日志中的15种事件的行为关系进行了描述,如:Release A,Release B,…,other等结果事件,它们之间对应的行为轮廓矩阵值被赋值为4,属于排他序+,表明这些结果事件在一条病例过程中不会同时出现。
应用这些行为关系进行约束,甚至可以对后继活动的发生给出候选集。例如:对于BPM(LacticAcid,*)的赋值中,Release A,Release B,other对应的值为1(严格序→),而Release C,Release D为4(排他序+),所以诊疗过程中LacticAcid事件发生后,对应的案例的结果事件候选集只能是{Release A,Release B,other}。
通过应用行为轮廓矩阵,可以将复杂的过程模型转换为矩阵形式,能直接读取出事件间的行为关系。同时,矩阵形式的数据结构便于转换为张量,输入到神经网络模型中,通过行为轮廓矩阵提供的行为信息增强提高预测效果。通过结果预测模型,可以将患者诊疗过程作为输入,从而输出预测结果,如病人的疾病类型或者治疗方案。
在患者病例过程中进行结果预测,可以协助医生在诊疗过程中进行决策。当医生完成诊断,预测得到的患者病例的结果,可以协助医生进行诊断的核对和确认,减少误诊率。
4 实验与评估
本文基于上述BPME方法,使用Python实现对应的方法。使用开源的过程挖掘库pm4py对XES格式的事件日志进行读取,然后使用读取后的事件日志来进行方法的实验与验证。
本章针对所提出的基于行为轮廓的结果预测方法进行评估。第一部分为生成行为轮廓的验证,第二部分完成了对应的结果预测效果评估,通过对比未结合行为轮廓矩阵的预测结果来说明行为轮廓对预测结果的效果。
4.1 实验数据和设置
本文采用真实数据集进行实验。包括BPIC2012(https://doi.org/10.4121/uuid:3926db30-f712-4394-aebc-75976070e91f)和Sepsis(https://doi.org/10.4121/uuid:915d2bfb-7e84-49ad-a286-dc35f063a460)数据集,其数据特征如表2所示。
BPIC2012是一个数据集,最早于2012年在业务流程智能挑战赛(BPIC)中发布。该数据集包含了荷兰金融机构贷款申请流程的执行历史记录。每个案例都详细记录了与特定贷款申请相关的事件。为了进行分类研究,本文根据案例的结果确定了一些标签,即申请是否被接受、拒绝或取消。从直观上来说,这可以被视为一个多类别离散问题。然而,为了与之前关于结果导向预测过程监测的研究保持一致,本文将其作为三个独立的二进制分类任务,分别记作BPIC2012_1、BPIC2012_2和BPIC2012_3。
Sepsis是一份记录荷兰某医院中患有败血症的患者病例过程的事件日志。每个病例记录了从患者在急诊室登记到出院的事件过程。本文以Sepsis作为数据集,研究结果预测任务,本文还参考了文献[5],其中定义了该日志中的三个不同的病例,标记为Sepsis_1、Sepsis_2和Sepsis_3。
为了验证本文方法对于事件日志结果预测的有效性和性能,对比了部分传统的神经网络结果预测方法,如SVM[3]、LR[3]、RF[3]、XGB[3]、LSTM[2],也选取了结合其他方式增强模型效果的结果预测方法,如ORANGE[5]、FOX[7]、BERT[8]。其中ORANGE应用了基于前缀迹的图像增强方法增强预测效果,BERT基于Transform模型应用了预训练、掩盖训练方法增强预测效果。通过对比传统的神经网络预测方法,研究对于事件日志结果预测的有效性和提升效果。通过对比结合其他方式增强模型效果的方法,研究对于事件日志结果预测性能的提升是否较其他增强方法有优势。
在预测结果方法的对比上,由于准确度效果对比不够明显,多采用AUC(area under the curve)和F-score进行对比。
AUC是一种用于评估二分类模型性能的指标。AUC值为0.5~1,其中0.5表示模型预测性能等同于随机猜测,而1表示模型完全准确地预测了正负样本。AUC通过绘制ROC曲线(receiver operating characteristic curve)来计算得出。ROC曲线是以真阳性率(true positive rate,也称为召回率或灵敏度)为纵轴,假阳性率(false positive rate)为横轴绘制的,反映了在不同分类阈值下模型的性能。
对于多分类问题,通常会将每个类别作为正例,其他类别作为负例,计算每个类别的AUC值,并对这些AUC值进行平均得到平均AUC。它可以衡量模型在区分各个类别之间的性能。
F-score是一种用于评估分类模型性能的指标,主要用于非平衡数据集中的二分类问题。F-score结合了准确度(precision)和召回率(rec1sxZtwoIzPvsxmAycMMEug==all),既考虑了模型的准确性,也考虑了模型找到所有正例的能力。
精确率定义为真阳性数除以真阳性数加假阳性数,召回率定义为真阳性数除以真阳性数加假阴性数,对于每个类别,可以计算其精确率和召回率,计算每个类别的F-score值,最后对这些类别的F-score值进行平均,得到这个数据集的F-score。F-score能够评估模型在多个类别上的整体性能。
4.2 预测迹的结果
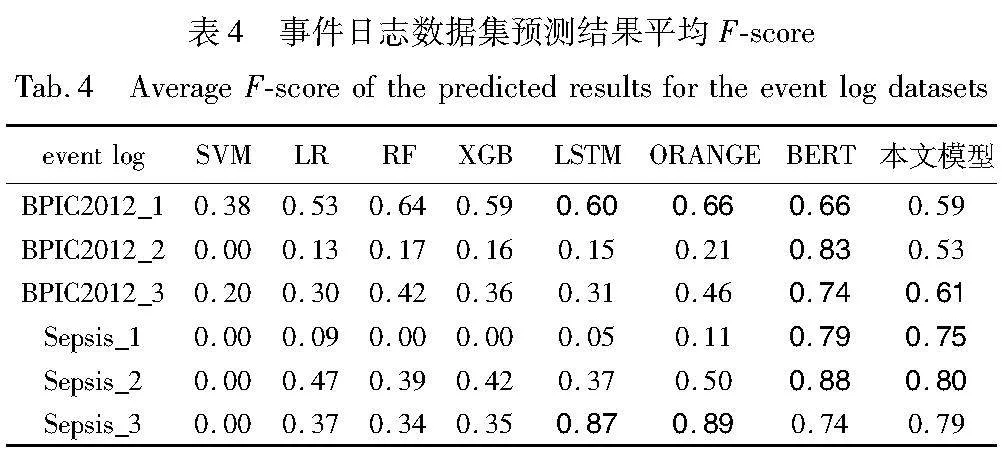
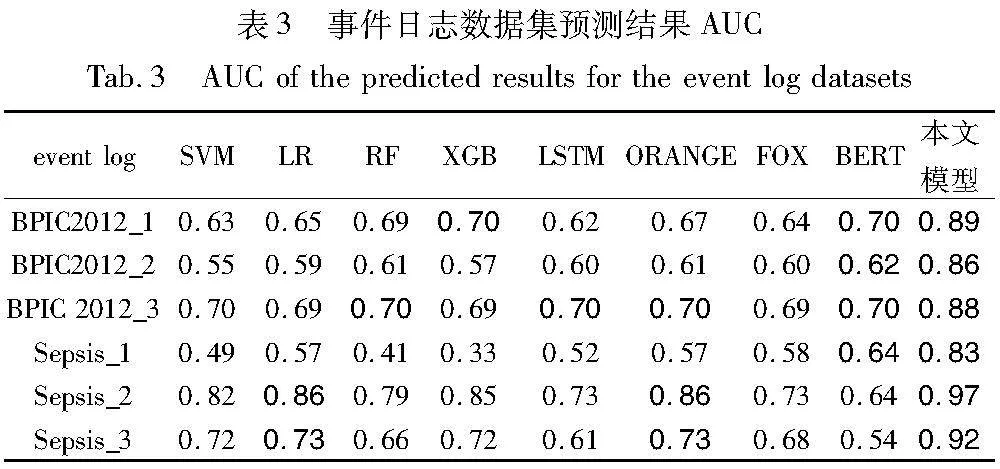
通过实验比较了上述机器学习算法和深度学习模型在事件日志数据集上的性能,结果如表3、4所示。
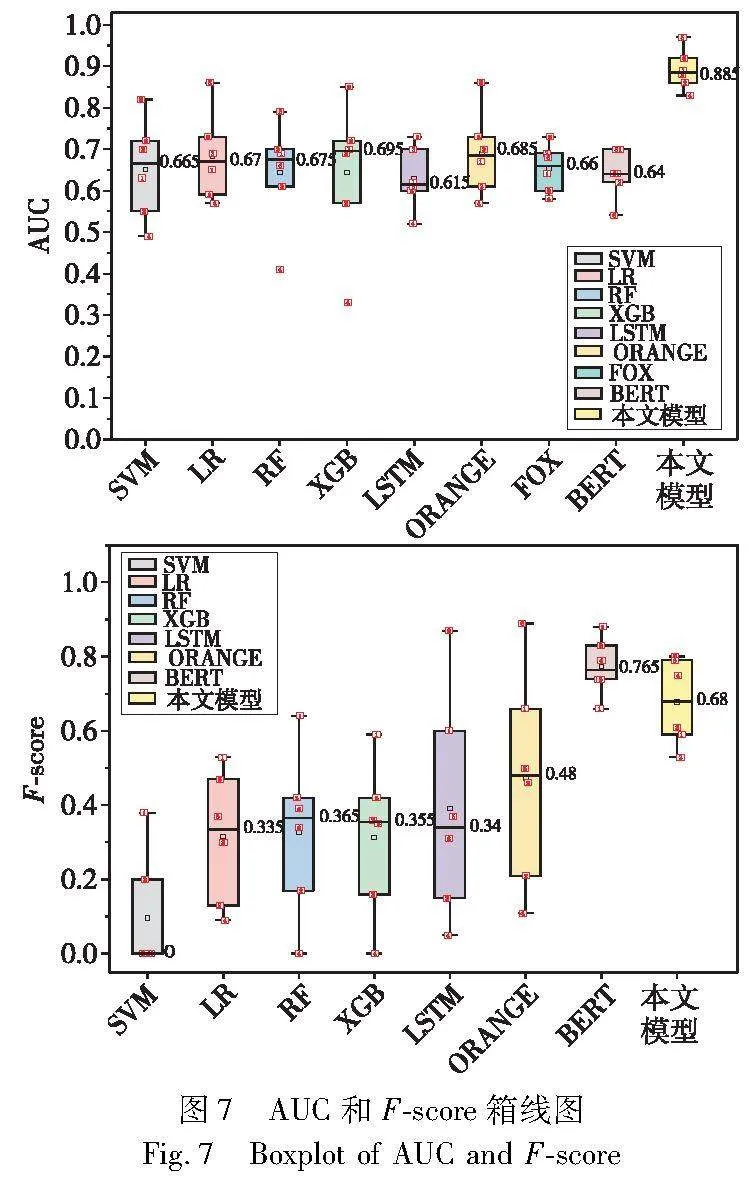
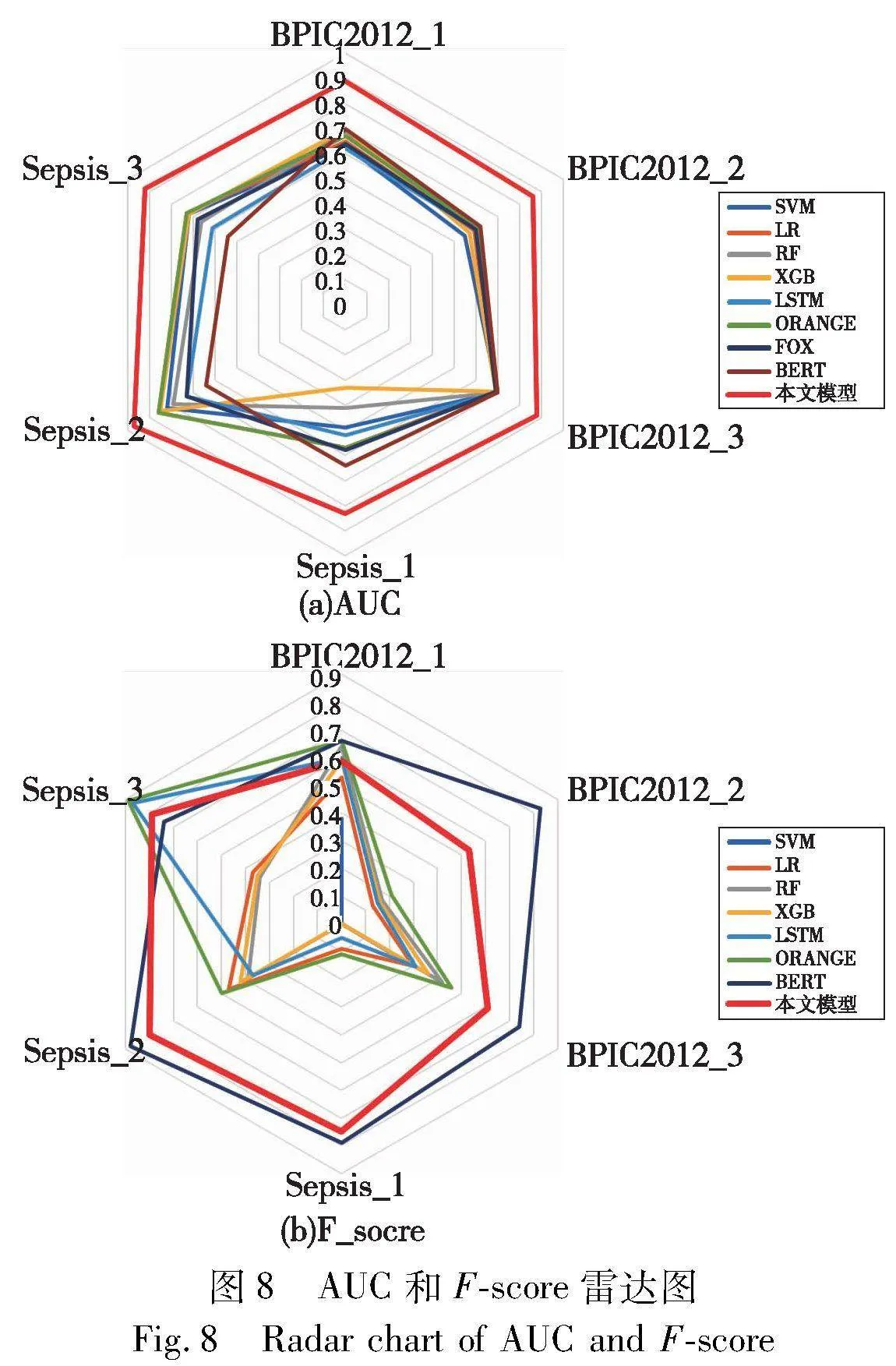
为了方便对比,本文将结果最优值进行加粗显示。实验结果表明,在AUC值的比较中,本文方法在多个数据集上表现良好,尤其在Sepsis_2数据集上取得了显著的性能提升,AUC值达到了0.97。
表4表明,在F_score值的比较中,本文方法在多个数据集上表现出良好的性能,尤其在BPIC2012_1和Sepsis_2数据集上取得了较高的F-score。
为了对各个方法的效果分布进行研究,通过设置箱体范围为25%~75%,得到AUC和F-score箱线图。如图7所示,本文方法的AUC分数综合效果最好,且预测效果最稳定,F-score分数综合效果排名第二且预测效果比大多数方法稳定。
综上所述,BPME在多个数据集上优于对比方法。如图8所示,在AUC值和F-score上,BPME在所有数据集中优于绝大部分方法,在绝大多数数据集上的F-score仅次于ORANGE和BERT方法。
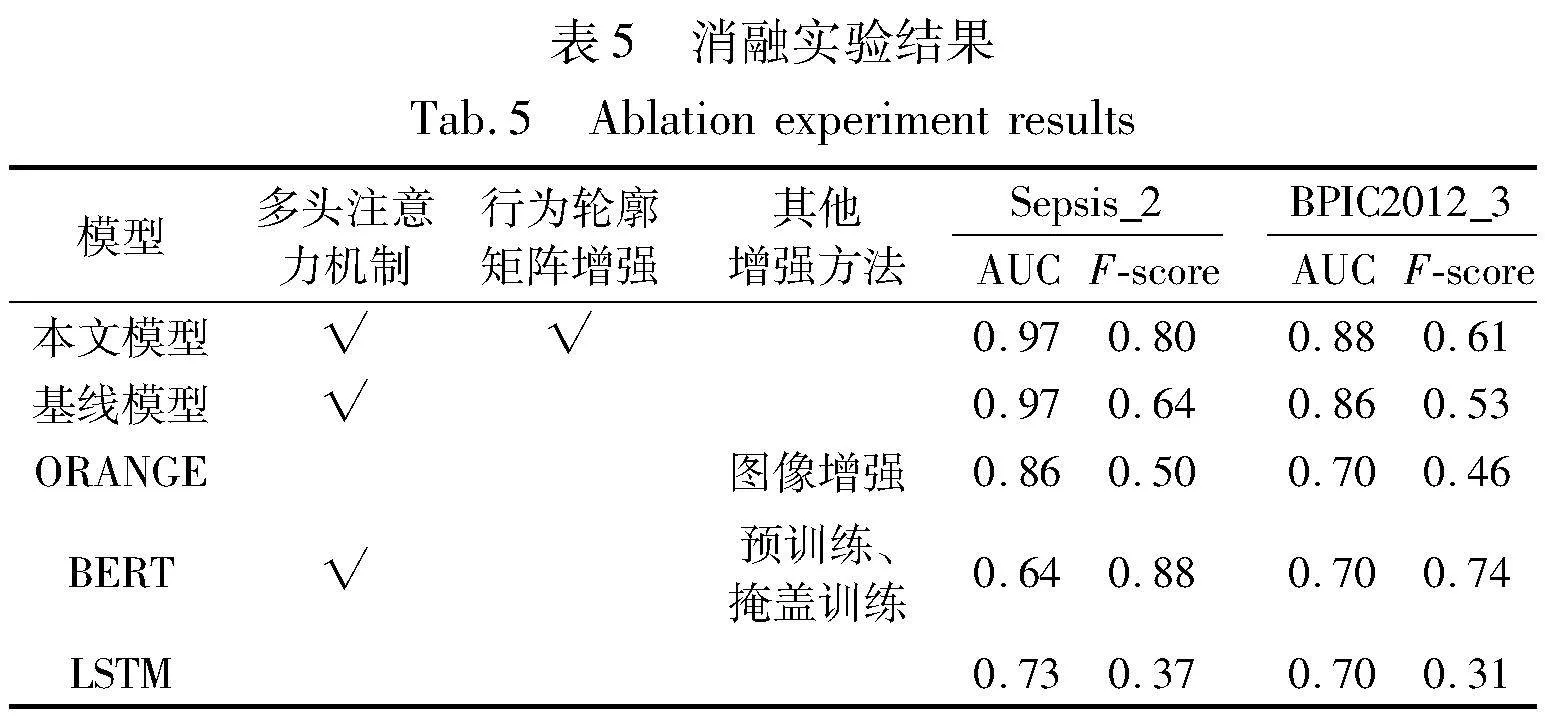
4.3 行为轮廓矩阵增强方法BPME消融实验
为了验证行为轮廓对于实验结果的增强程度,进行了消融实验。实验将在框架和模型中的行为轮廓矩阵增强模块删去作为基线模型。从基于对真实数据集的实验得到的表5可知,结合行为轮廓矩阵增强的模型效果优于基线模型和LSTM模型,AUC分数较基线模型持平,F-score分数较基线模型提升12%。同时,本文提出的增强模型的AUC和F-score比基准的LSTM预测模型平均提升了21%和36.5%。AUC提升表示模型分类能力提高,F-score提升表示分类模型性能更好了。
相较于其他增强方法,本文中基于行为轮廓矩阵增强方法BPME比ORANGE应用的图像增强方法和BERT中的预训练、掩盖训练方法对AUC提升效果要好。而对于F-score的提升优于ORANGE中应用的图像增强方法,略次于BERT中的预训练、掩盖训练方法。
5 结束语
本文从事件日志提取生成行为轮廓矩阵,并与事件日志中的事件序列信息一起通过CNN和LSTM子模型进行特征学习,将结合的特征用于增强预测模型对事件日志中行为之间关系的理解,优化预测效果。通过对比实验,结合行为轮廓矩阵增强的预测模型预测效果优于传统的预测模型。
本文BPME方法仅考虑了最基础的one-hot编码方法,未采用更复杂的编码方法。同时,本文中的行为轮廓增强模块仅应用在LSTM模型增强结果预测效果,未尝试更复杂的神经网络模型以及其他的预测任务。这导致本文方法在实际应用推广中缺少对事件附加属性信息的考虑,而导致预测效果在某些情况下可能出现偏差,并且由于本文方法仅提供结果预测,导致可用于辅助决策的信息有限。
在未来工作中,可以考虑结合多视角的编码方法和更复杂的神经网络模型以提升效果,或尝试应用到其他预测任务。通过提升预测效果,可以提高相关行业应用本文方法进行预测性过程监控的可行性和可靠性。同时,通过拓展其他预测任务,可以提供更多预测性信息应用于辅助决策。
参考文献:
[1]Maggi F M, Di Francescomarino C, Dumas M, et al. Predictive monitoring of business processes[C]//Proc of Advanced Information Systems Engineering. Cham: Springer, 2014: 457-472.
[2]Teinemaa I, Dumas M, Leontjeva A, et al. Temporal stability in predictive process monitoring[J]. Data Mining and Knowledge Discovery, 2018,32(5): 1306-1338.
[3]Teinemaa I, Dumas M, Rosa M L, et al. Outcome-oriented predictive process monitoring: review and benchmark[J]. ACM Trans on Knowledge Discovery from Data, 2019,13(2): 1-57.
[4]Galanti R, Coma-Puig B, Leoni M D, et al. Explainable predictive process monitoring[C]//Proc of the 2nd International Conference on Process Mining. Piscataway, NJ: IEEE Press, 2020: 1-8.
[5]Pasquadibisceglie V, Appice A, Castellano G, et al. ORANGE: outcome-oriented predictive process monitoring based on image encoding and CNNs[J]. IEEE Access, 2020,8: 184073-184086.
[6]Aringhieri R, Boella G, Brunetti E, et al. Leveraging structured data in predictive process monitoring: the case of the ICD-9-CM in the scenario of the home hospitalization service[C]//Proc of SMARTERCARE Workshop.[S.l.]: CEUR-WS Press, 2021: 48-60.
[7]Pasquadibisceglie V, Castellano G, Appice A, et al. FOX: a neuro-fuzzy model for process outcome prediction and explanation[C]//Proc of the 3rd International Conference on Process Mining. Piscataway, NJ: IEEE Press, 2021: 112-119.
[8]Chen Hang, Fang Xianwen, Fang Huan. Multi-task prediction me-thod of business process based on BERT and transfer learning[J]. Knowledge-Based Systems, 2022,254: 109603.
[9]Wickramanayake B, He Zhipeng, Ouyang Chun, et al. Building interpretable models for business process prediction using shared and specialised attention mechanisms[J]. Knowledge-Based Systems, 2022, 248: 108773.
[10]郭娜, 刘聪, 李彩虹, 等. 支持增量日志的业务流程剩余时间预测方法[J/OL]. 计算机集成制造系统. (2023-03-23)[2023-11-08]. https://kns.cnki.net/kcms/detail/11.5946.TP.20230322.1638.008.html. (Guo Na, Liu Cong, Li Caihong, et al. Process remaining time prediction approach supporting incremental logs[J/OL]. Computer Integrated Manufacturing Systems. (2023-03-23)[2023-11-08]. https://kns.cnki.net/kcms/detail/11.5946.TP.20230322.1638.008.html.)
[11]Van Der Aalst W M P, Schonenberg M H, Song M. Time prediction based on process mining[J]. Information Systems, 2011,36(2): 450-475.
[12]卢可, 方贤文, 方娜. 基于行为向量的在线事件流预测[J]. 计算机集成制造系统, 2022, 28(10): 3052-3063. (Lu Ke, Fang Xianwen, Fang Na. Online event stream prediction based on behavior vectors[J]. Computer Integrated Manufacturing Systems, 2022, 28(10): 3052-3063.)
[13]宫子优, 方贤文. 基于时间卷积网络的业务流程预测监控[J]. 安徽理工大学学报 :自然科学版, 2021, 41(5): 64-70. (Gong Ziyou, Fang Xianwen. Predictive business process monitoring using temporal convolutional networks[J]. Journal of Anhui University of Science and Technology: Natural Science, 2021,41(5): 64-70.)
[14]Sarno R, Sinaga F, Sungkono K R. Anomaly detection in business processes using process mining and fuzzy association rule learning[J]. Journal of Big Data, 2020,7(1): 5.
[15]Nolle T, Luettgen S, Seeliger A, et al. BINet: multi-perspective business process anomaly classification[J]. Information Systems, 2022,103: 101458.
[16]Gyunam P, Minseok S. Predicting performances in business processes using deep neural networks[J]. Decision Support Systems, 2020,129: 113191.
[17]Ly L T, Maggi F M, Montali M, et al. Compliance monitoring in business processes: functionalities, application, and tool-support[J]. Information Systems, 2015,54: 209-234.
[18]Pasquadibisceglie V, Appice A, Castellano G, et al. A multi-view deep learning approach for predictive business process monitoring[J]. IEEE Trans on Services Computing, 2022,15(4): 2382-2395.
[19]孙晋永, 邓文伟, 许乾, 等. 事件日志的批量迹与过程模型的多视角对齐方法[J]. 计算机应用研究, 2023,40(7): 2045-2052,2059. (Sun Jinyong, Deng Wenwei, Xu Qian, et al. Multi-perspective alignment between batch traces of event log and process model[J]. Application Research of Computers, 2023,40(7): 2045-2052,2059.)
