基于双层图注意力网络的邻域信息聚合实体对齐方法
2024-07-31王键霖张浩张永爽马超伟齐珂张小艾


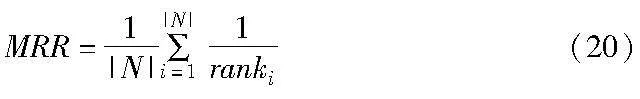
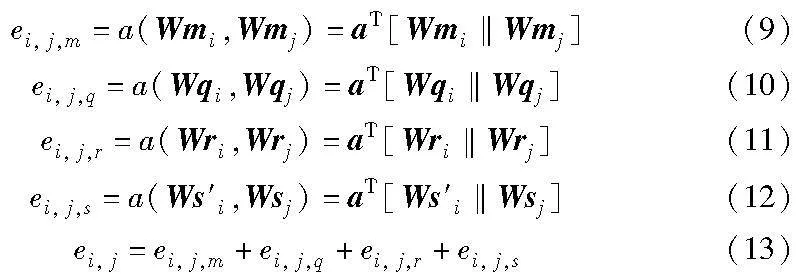



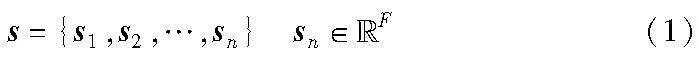
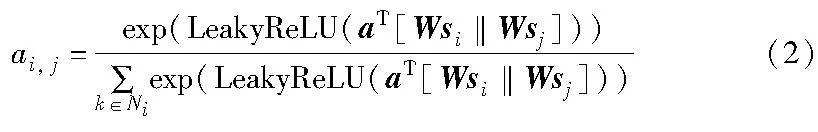
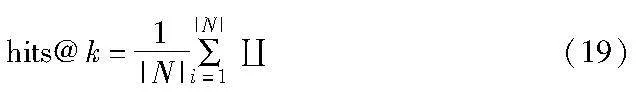

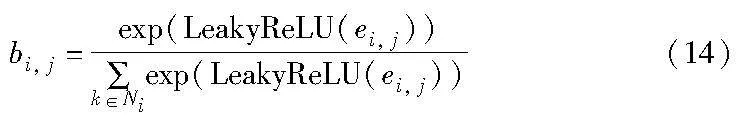
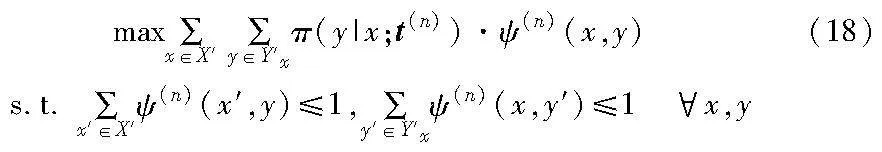
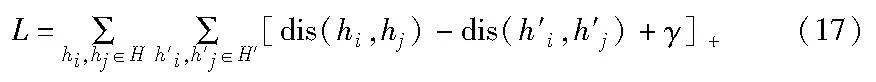
摘 要:针对知识图谱中存在部分属性信息对实体对齐任务影响程度不一致以及实体的邻域信息重要程度不一致的问题,提出了一种结合双层图注意力网络的邻域信息聚合实体对齐(two-layer graph attention network entity alignment,TGAEA)方法。该方法采用双层图神经网络,首先利用第一层网络对实体属性进行注意力系数计算,降低无用属性对实体对齐的影响;随后,结合第二层网络对实体名称、关系和结构等信息进行特征加权,以区分实体邻域信息的重要性;最后,借助自举方法扩充种子实体对,并结合邻域信息相似度矩阵进行实体距离度量。实验表明,在DWY100K数据集上,TGAEA模型相较于当前基线模型,hit@1、hit@10和MRR指标分别提升了4.18%、4.81%和5%,证明了双层图注意力网络在邻域信息聚合实体对齐方面的显著效果。
关键词:知识图谱;实体对齐;图注意力网络;属性信息;邻域信息聚合
中图分类号:TP391 文献标志码:A文章编号:1001-3695(2024)06-012-1686-07
doi: 10.19734/j.issn.1001-3695.2023.10.0520
Neighborhood information aggregation entity alignment method based on double layer graph attention network
Abstract: This paper proposed the TGAEA algorithm, which combined neighborhood information aggregation with two layers of graph attention networks to tackle challenges in entity alignment tasks within knowledge graphs. Initially, the method utilized the first-layer graph neural network to calculate attention coefficients for entity attribute embedding vectors, aiming to mitigate the impact of irrelevant attributes on entity alignment outcomes. Based on the attribute embedding, the second-layer graph neural network was employed to weight the embedding vectors of entity names, relationships, and structural information, thereby distinguishing the importance of various information within the entity’s neighborhood. Additionally, it utilized the bootstrap method to iteratively expand the seed entity pair, and completed the entity distance measurement by combining the neighborhood information similarity matrix. The experimental results show that the TGAEA model is significantly superior to the current advanced baseline models in the DWY100K dataset, compared to the best method, hit@1, hit@10 and MRR indicators increased by 4.18%, 4.81%, and 5%. These findings emphasize the substantial impact of the two-layer graph attention network on aggregating neighborhood information for entity alignment.
Key words:knowledge graph(KG); entity alignment; graph attention network; attribute information; neighborhood information aggregation
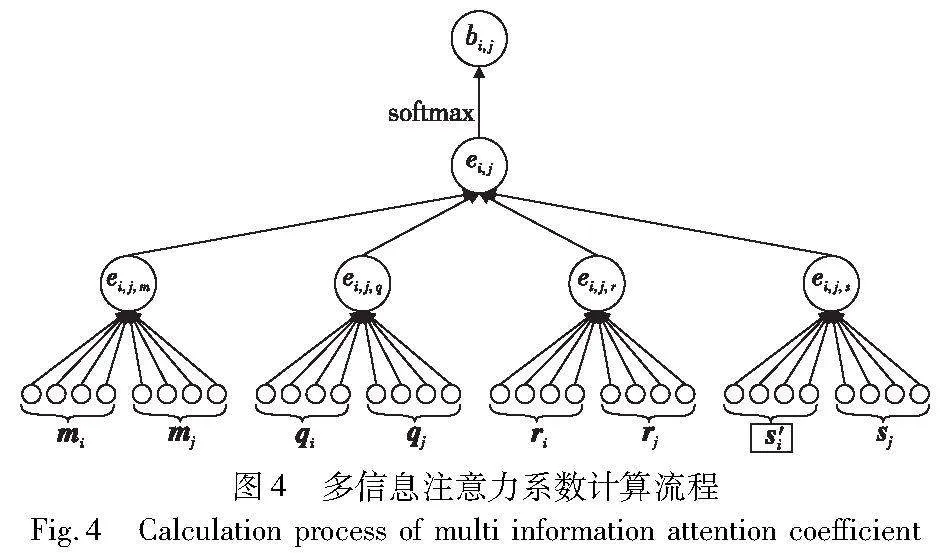
0 引言
近年来,知识图谱(KG)已在人工智能、自然语言处理和语义网等领域展露锋芒。知识图谱是高效利用可视化技术描述知识资源的重要载体,其构建了一个计算机和人类都能理解的关系网络[1]。随着深度学习和表示模型的迅猛发展,知识图谱在知识推理[2]、推荐系统[3]、知识问答[4]等领域得到广泛应用。然而,随着数据量的持续增长,知识图谱愈发呈现跨领域、知识逐渐细分的特性,如何在不同数据源知识图谱中查找等效实体,是进行知识大规模整合及利用的难点。
实体对齐(entity alignment,EA)旨在从不同来源的知识图谱中找到指向现实世界的同一实体,该任务是完成知识融合的关键步骤。最早的实体对齐工作大多集中在句法和结构上[5],主要由符号特征[6]和关系推理[7]来实现对齐,但是这些方法忽略了多方面隐含的语义信息(如属性之间的关联语义和结构信息等),使得对齐效果有限。
近年来基于知识嵌入[8]的实体对齐技术应运而生,这类技术旨在捕获实体之间的语义关联关系,提高对齐的准确性和鲁棒性。知识嵌入的方法主要使用TransE[9]和GCN(graph convolutional networks)[10]等作为编码器,将实体信息表示为低维向量并计算相似性,以找到对齐实体对。但这些模型大多只关注实体关系信息,也有一些模型[11]尝试使用GAT(graph attention)[12]网络,结合知识图谱中的结构表示与实体自身的属性特征加权表示进行实体对齐,但大多都只针对单个属性内部信息的字符序列信息进行学习,忽略了不同属性对实体重要程度不一致的问题,且实体名称、属性、关系以及结构等邻域信息对实体表示的重要程度也不一。因此,本文提出一种基于双层注意力网络的实体对齐方法,利用两层注意力网络分别对属性信息内部和实体的不同信息之间进行注意力加权,消除不同信息对实体对齐工作影响程度不一的问题。本文的主要贡献如下:
a)在属性嵌入模块,使用BERT(bidirectional encoder re-presentations from transformers)预训练模型[13]学习实体的属性及属性值表示,根据表示结果,引入GAT网络进行注意力系数的计算,然后形成加权的属性表示向量矩阵。
b)基于实体表示模块,使用GCN分别将实体名称、实体的关系信息以及实体的结构信息进行向量化表示,并将加入注意力系数后的属性表示向量和其他多类信息特征向量进行注意力系数计算,最终形成由双层图注意网络计算输出的实体多信息相似度矩阵。
c)使用嵌入空间的距离计算相似度得分,并最终在真实数据集上评估该方法,本文模型相比于最优基线模型,hit@1、hit@10和MRR指标分别提升了4.18%、4.81%和5%,验证了双图注意力网络在实体邻域信息聚合工作方面的优异表现。
1 相关工作
知识表示学习也被称为知识嵌入,是目前应用较为广泛的实体对齐方法,主要研究对象是知识图谱嵌入。这种嵌入方法的机制是将多个知识图谱中的实体映射到低维向量空间,通过向量空间的几何结构来捕获实体之间的语义关联性,同时也能隐性地降低不同知识图谱间的异构性问题。目前主流的知识嵌入方法分为基于翻译、基于路径和基于图神经网络方法三类。
1.1 基于翻译的实体对齐方法
翻译模型以TransE[9]、TransH[14]和TransR[15]及其扩展模型为主,这类模型的主要工作机制是将关系视为头实体到尾实体的翻译。MTransE[16]首次将TransE的思想用于实体对齐工作中,其首先使用TransE学习单个知识图谱的嵌入表示,然后提出三种跨知识图谱的变换方法,将两个知识图谱映射到相同的嵌入空间中,最后对齐不同知识图谱中的实体;BootEA[17]采用TransE作为编码模块,并在MTransE模型基础之上引入“参数交换”策略,通过相互交换已对齐的实体对来扩充有效的事实三元组;JAPE[18]将两个知识图谱的结构联合嵌入到一个统一的向量空间中,并利用知识图谱中的属性相关性来进一步完善实体嵌入;KDCoE[19]在翻译模型的编码模块基础上增加了实体描述编码模块,以进行半监督跨语言学习,通过协同训练来优化两个嵌入模型;NTAM[20]提出了一种非平移方法,旨在通过概率模型为对齐任务提供更强大的解决方案,通过探索结构属性以及利用锚点在学习单个网络表示的过程,将每个网络投影到相同的向量空间。然而,上述模型多数仅关注实体之间的单跳关系,并主要以三元组的角度对实体进行建模,因此此类模型常因损失较多的多跳邻居信息而导致精度不够。
1.2 基于路径的实体对齐方法
不同于翻译模型只关注实体间单跳信息的特点,基于路径的模型将实体间的关系路径进行建模,包含实体之间的传播路径,对于一些远邻居实体信息的利用更加充分。其中IPTransE[21]最早尝试从路径的视角解决实体对齐问题,与MTransE模型类似,IPTransE同样在相互独立的编码空间内分别表示两个知识图谱的实体,RSNs[22]使用循环跳跃网络来弥合实体之间的差距。RSN将递归神经网络(RNN[23])与残差学习集成在一起,有效地捕获单个KG内部和不同KG之间的长期关系依赖。但是目前多数基于路径的模型不能解决因三元组数量增多而导致路径变长的问题,进而影响训练效率。
1.3 基于图神经网络的实体对齐方法
基于图神经网络的模型可以很好地解决因路径过长导致对齐效果差的问题。此类模型将邻近节点视为根节点的信息,使用图神经网络作为编码器,以捕获子图结构,并对实体的信息进行聚合,最终转换为向量表示。GCN-Align[24]是首个提出使用图神经网络来完成实体对齐任务的模型,该模型使用图卷积网络GCN结合结构信息和属性信息来共同学习实体表示;NAEA[25]提出使用TransE和图注意力网络获得实体的关系信息和邻域信息;HMAN[26]使用GCN和全连接网络来分别组合实体的多方面信息,包括实体的拓扑连接、关系和属性,以学习实体嵌入。
以上工作主要从知识嵌入的不同表达方式出发,具体又可以分为局部嵌入和整体嵌入两个方面。按照这些方法在处理不同实体对齐任务的结果来看,从整体嵌入的方法处理实体对齐工作表现得更加优异,但是随着数据规模的增大,整体嵌入会导致不同信息对实体对齐工作影响程度不一的问题。因此本文基于GAT网络,提出了一种利用双层图注意力网络来学习实体邻域信息的嵌入,以提升实体对齐工作的效率。
2 问题定义
实体对齐任务可以描述为两个待对齐的知识图谱G1=(E1,R1,V1,A1,T1),G2=(E2,R2,V2,A2,T2),给定的种子实体对S={(e1,e2)∈E1×E2|e1≡e2},其中:E、R、V、A、T分别代表知识图谱内的实体、关系、属性、属性值以及三元组的集合,≡表示现实中指向同一事实的实体[27],实体对齐任务的目的是利用S中的先验知识,找到G1、G2中的相同实体。
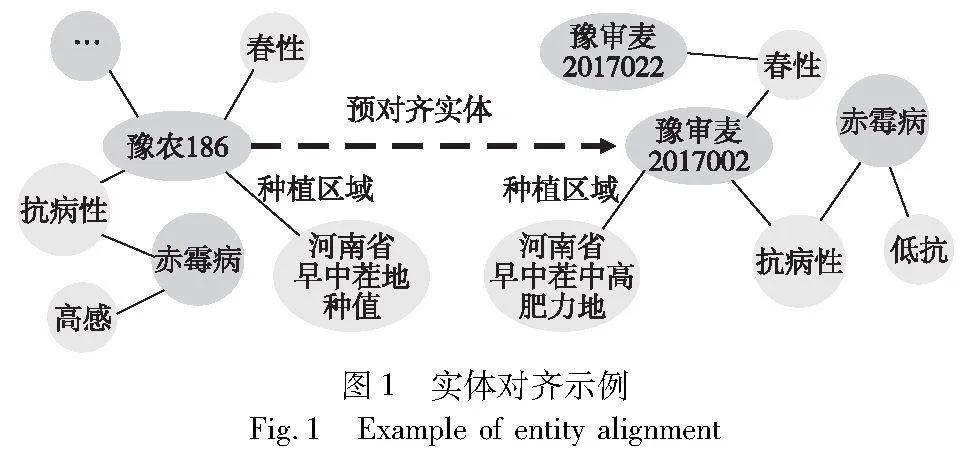
如图1所示,品种名称为“豫农186”的小麦在另一个数据源的名称可能为“豫审麦2017002”小麦品种国家审定编号,两个不同来源的实体都有“春性”的属性,但是其他小麦品种也可能有相同的属性,同时两个实体都有适宜播种区域为“河南省早中茬中高肥力地”的属性值,不难发现,更常见的属性值在表示实体特征重要程度方面会变弱;同时观察两个实体的结构相似程度和实体与邻居节点的关系特征等信息可以发现,名称信息与其他信息相比,在实体对齐的重要程度会更低。因此,实体对齐工作应从单个信息内的重要程度和信息间的重要程度分别开展。
3 实体对齐方法
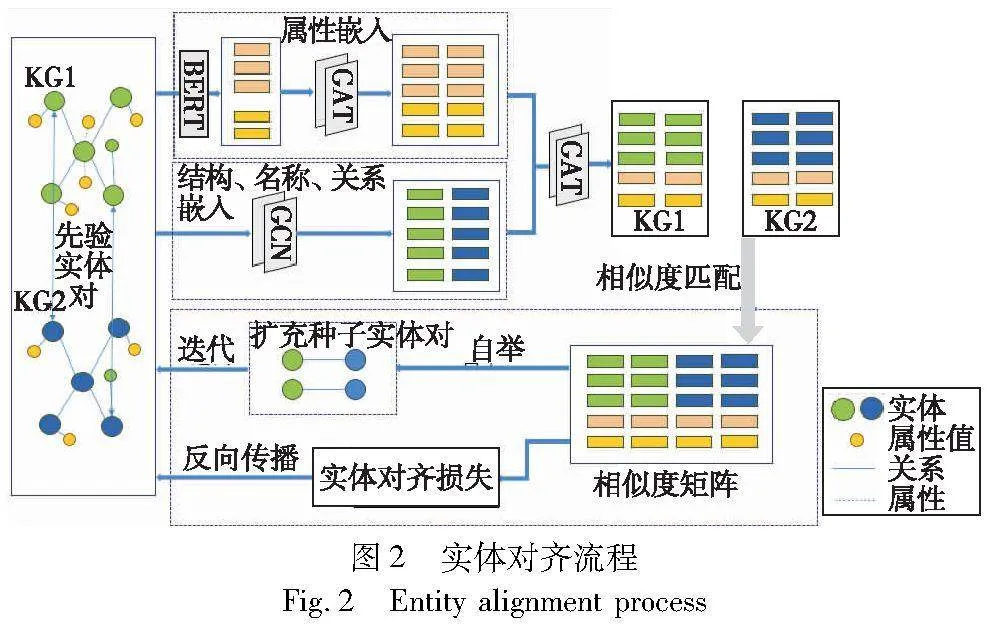
实体对齐方法分为属性嵌入、多信息注意力加权嵌入以及实体对齐算法三个模块。其中属性嵌入模块使用预训练模型BERT进行属性向量化表示,消除由属性单位及数据源表示方法不统一造成的知识噪点,在获得属性特征向量的初始矩阵后,利用第一层图注意网络进行单个信息内的特征向量加权,消除不同属性对实体对齐工作的影响程度不一的问题;多信息注意力加权嵌入模块首先使用GCN对实体的结构、名称以及关系进行卷积表达操作,目的是获取实体其余信息的特征向量表示,在获得实体的所有邻域信息向量表示后,使用第二层图注意网络对所有信息进行加权,消除实体不同信息对对齐工作的影响程度不一的问题;实体对齐算法模块中将获得加权后的特征向量相似度矩阵使用嵌入空间的距离计算相似度得分,针对实体对齐工作中存在的先验知识不足的问题,在此模块中使用一种基于自举的方法迭代地将每一轮若干高置信度对齐实体(全局最高)迭代地添加到训练集中,达到扩充种子实体对的目的。最后在基准数据集上评估了该方法的实验效果。实体对齐方法流程如图2所示。
3.1 属性嵌入模块
同一属性在不同数据源中表达形式可能不一。如表1所示,“麦红吸浆虫”的成虫体长在“中原农村信息港”的表达单位为“毫米”,在“河南省小麦栽培管理措施”中为“mm”,为了使特征向量化的时候能区分出两者为同一表达内容,本文在属性特征表达上提出了区别于神经网络进行向量表达的方法,即使用预训练语言模型对属性信息进行特征向量表示。
为了降低属性的单位等信息对实体表示的影响,本文使用预训练模型BERT对属性信息进行嵌入表示,这样既可以统一属性的表达形式,同时得到的属性向量可以用于和GCN模型学习的实体其他信息进行拼接和注意力系数计算。本节首先将属性信息进行嵌入表达,初始词嵌入向量表示为
其中:sn表示单个实体中属性的特征向量表示,n为实体个数;F为节点的F维特征集合。
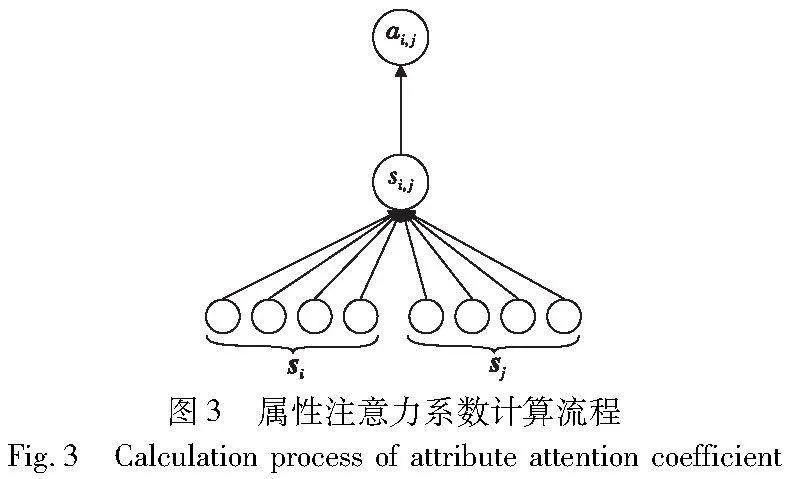
为了更好地为节点的属性信息分配权重,需要将目标节点的所有邻居属性向量进行归一化处理,这里使用softmax函数归一化和使用LeakyReLU作为非线性激活函数计算权重,计算过程如图3所示。
注意力系数计算公式为
其中:s是节点的特征;a表示一个单层的前馈神经网络;W为参数矩阵;‖表示为两个节点向量进行拼接;si, j为归一化之前的注意力系数,该系数计算流程为
si, j=a(Wsi,Wsj)=aT[Wsi‖Wsj](3)
获得邻居节点属性的注意力系数ai, j后,需要对邻域内节点的特征进行聚合,得到的即为节点属性的特征向量,公式为
3.2 多信息37a1be1e17c7e8e62380ac9ef394d5efe727b612cf9219d7bd5bcc88b1f84991注意力加权嵌入模块
实体的邻域信息多样且多维,具体取决于应用场景和任务需求。实体邻域信息涵盖实体描述、名称、结构、关系以及属性等诸多方面,这些信息能够更全面地捕捉实体的语义含义,如何充分利用实体的邻域信息是目前实体嵌入的难点。Chen等人[16]将关系三元组对齐任务描述为利用实体的结构信息进行嵌入。同样,文献[18]根据关系三元组得到结构嵌入,且根据属性三元组得到属性嵌入。文献[28]使用实体的结构信息、属性信息和实体名信息来完成实体邻域信息嵌入。但是以往的工作都是围绕着部分实体信息进行嵌入,没有充分利用实体的邻域信息,且不同信息对实体的重要程度也不一致。为此,本文结合通用知识图谱属性三元组较多的特点,选择包括实体名称、结构、关系以及在上一节中计算后加权的属性信息,利用第二层图注意力网络对实体多信息进行加权嵌入表达。
具体思路是首先根据不同的信息内容,使用GCN对节点的名称、结构及与邻居节点的关系分别进行嵌入表达,然后根据获得的特征向量进行第二次注意力加权。其中,多类信息的嵌入表达公式为
其中:m为经过GCN输出的节点名称的特征向量表示;q为节点结构的特征向量表示;r为节点的邻居关系特征向量表示。
然后对获取到的不同信息的特征向量进行注意力系数计算,其中也包含了经过第一层图注意力网络计算过的属性嵌入向量。具体地,第二层GAT的输入需要通过共享线性变换增强特征,由权重矩阵W进行参数初始化,每一种的信息注意力系数计算分别如下:
其中:ei, j,m 、ei, j,q、 ei, j,r分别为实体名称、结构、关系的注意力系数;ei, j,s为二次加权后属性的注意力系数;ei, j为四种信息注意力系数的求和。为了使不同实体之间的注意力系数易于区分,同样使用共享权重矩阵、自注意变换以及LeakyReLU函数对求和后的注意力系数进行归一化,计算流程如图4所示。
多信息注意力系数计算公式如下:
得到注意力系数后,计算实体名称、结构、关系以及属性的特征进行加权求和:
多信息嵌入的实现代码如算法1所示。
算法1 计算加入双层图注意力机制的多信息嵌入向量矩阵
3.3 基于邻居距离的实体对齐
确定实体的最终向量化表示后,以往的做法是根据实体ei和ej之间的距离确定是否可以对齐,但是这种度量一般是局部最优,忽略了可能存在的其他实体和原本实体的对齐结果。
本文根据实体的向量相似度预测可能对齐的实体对,具体通过测量实体嵌入表示之间的距离实现。知识图谱嵌入模块的输出为t′={t′1,t′2,…,t′n},对于两个实体ei∈G1,ej∈G2,根据式(16)计算实体对(ei,ej)距离。
d(ei,ej)=ti′-tj′L1(16)
其中:d表示L1范数。训练的目标是使损失函数的值尽可能小。使用基于边际的排序损失函数来训练以下目标函数:
其中:γ为超参数;H和H′分别表示正负样本的集合;[x]+表示修剪函数(rectified linear unit,ReLU),确保只有正值会对损失函数有贡献,负值被视为零。正样本通过数据集的种子实体对信息获取,负样本采用均匀负采样的方法。
基于嵌入的实体对齐工作常受到不充分的先验对齐知识的影响。为了解决这类问题,本文采用自举的方法迭代地将置信度高的对齐实体对标记为训练数据,使用这些知识进一步改进实体嵌入的对齐结果,在第n轮迭代中,新增的实体对齐按照式(18)选择。
其中:X′表示x未对齐实体集合;Y′表示y未对齐实体集合;t(n)表示第n轮迭代中实体的嵌入向量;ψ(n)(x,y)为指示函数,指示x和y是否对齐;Y′x表示x的候选集合,Y′x={y|y∈Y′ and π(y|x;t(n))>ξ},ξ为相似度阈值,由式(16)计算的实体距离度量超过该值,则选入候选集合。
4 实验与分析
4.1 实验数据
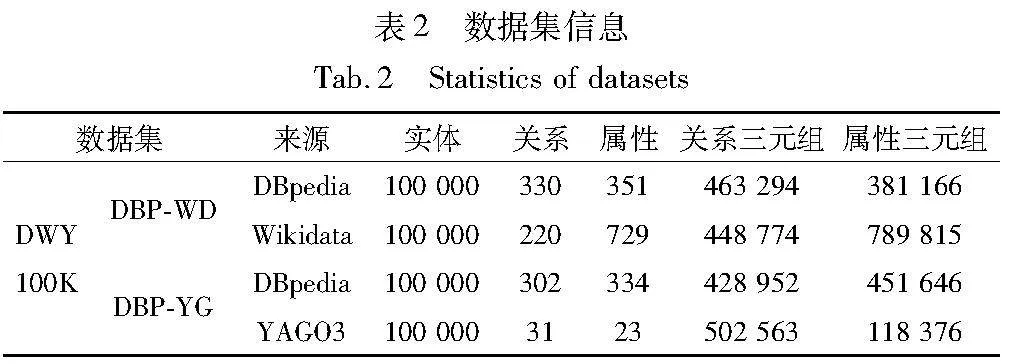
为了在包含属性三元组等在内的多种实体工作场景下评估TGAEA模型,实验选择使用DWY100K数据集。该数据集包含从DBpedia、Wikidata和YAGO3提取出的三元组,用DBP-WD和DBP-YG表示。数据集具体信息如表2所示。
4.2 评估指标
本文选择了三种常用的实体对齐的评价指标,即hits@1、hits@10以及MRR[29]。hits@k表示对于所有目标实体,与其所对应的前k个备选实体中存在正确对齐实体的有效实体对所占比例。记N为三元组集合,|N|为三元组集合的个数,Euclid ExtraCAp(·)为indicator函数,条件为真,函数值为1,若为假,则函数值为0。计算公式如下:
MRR为匹配到正确实体的排名倒数的平均值,计算公式如下:
其中:ranki表示对齐到正确实体的排名;N为对齐实体对的数量。
4.3 实验环境及参数设置
本文的所有实验均在个人工作站进行,该工作站配有Intel i5-12490F 3.00 GHz CPU、NVIDIA GeForce GTX 3080 GPU和1 TB内存,通过深度学习框架TensorFlow实现,编译环境为Python 3.8。其中属性嵌入的BERT预训练模型包括12层,768个隐单元,12个attention head,110 M参数,学习率初始值为0.01,相似度阈值ξ设置为0.8。
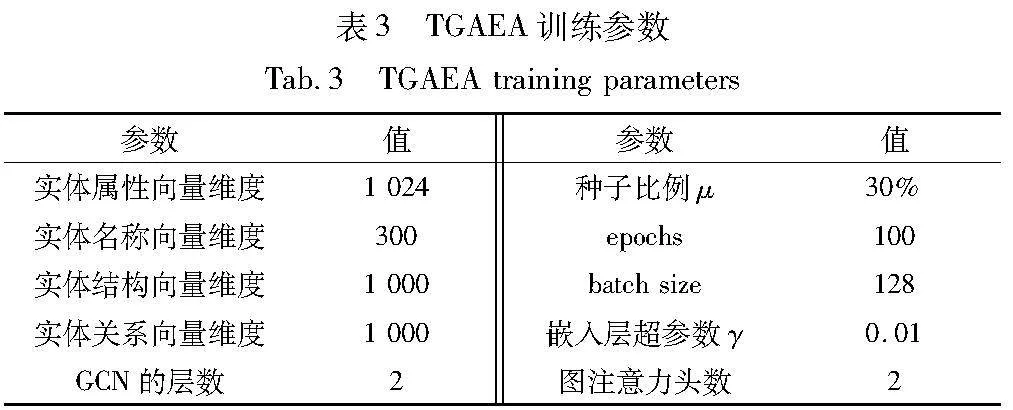
训练过程中采用 Adam优化器进行参数优化,负样本采样数设置为25,训练负样本采用正样本,按照[1,50]比例均匀随机生成完成,根据计算机资源训练迭代轮数设置为100,每进行10轮训练迭代,进行一次基于自举的迭代,这样可以适度使用训练出的预对齐实体对而不会引起过拟合情况,实体的各个信息维度设置及其余具体实验参数如表3所示。
通常,训练数据量越大,模型性能越好。但在实体对齐工作中,需要选择较小的训练集比例验证模型在未知实体对上的性能,且模型在先验知识为30%的训练值能使数据利用效率最大化,大多数现有实体对齐模型的训练和测试数据比例为3∶7。因此为了与其他现有模型进行公平比较,本文也设置了30%的预对齐实体对用于训练,其余用于测试。
4.4 实验结果及分析
4.4.1 对比实验
为了验证本文所提双层图注意网络嵌入方法的优越性,实验选择了不同模块引入注意力机制的实体对齐方法进行对比。按照嵌入方法分为基于TransE和基于GCN的方法两大类。其中,TransE系列有KECG[30]采用给相关实体分配注意力权重的方法,同时BootEA[17]对具有较多属性三元组的实体对齐任务具有较好的处理效果。基于GCN的方法中,GCN-Align[24]是第一个提出使用图神经网络来完成实体对齐任务的模型。该模型采用两个GCN,通过共享权重矩阵,将来自不同知识图谱的实体嵌入到一个统一的向量空间中,它借助实体之间的结构来传播对齐关系;RDGCN[31]采用图注意力机制,给邻接实体分配权重;AliNet[32]运用了注意力机制来为远距离实体分配权重,NMN[33]则利用跨图注意力机制为相邻的实体分配权重,SelfAttention-GCN(SA-GCN)[34]采用了多头注意力机制,以赋予具有较远关联的实体相应的权重;ESEA[35]提出一种将嵌入模型与基于符号的模型相结合的方法,通过混合嵌入获得向量相似度高的实体。
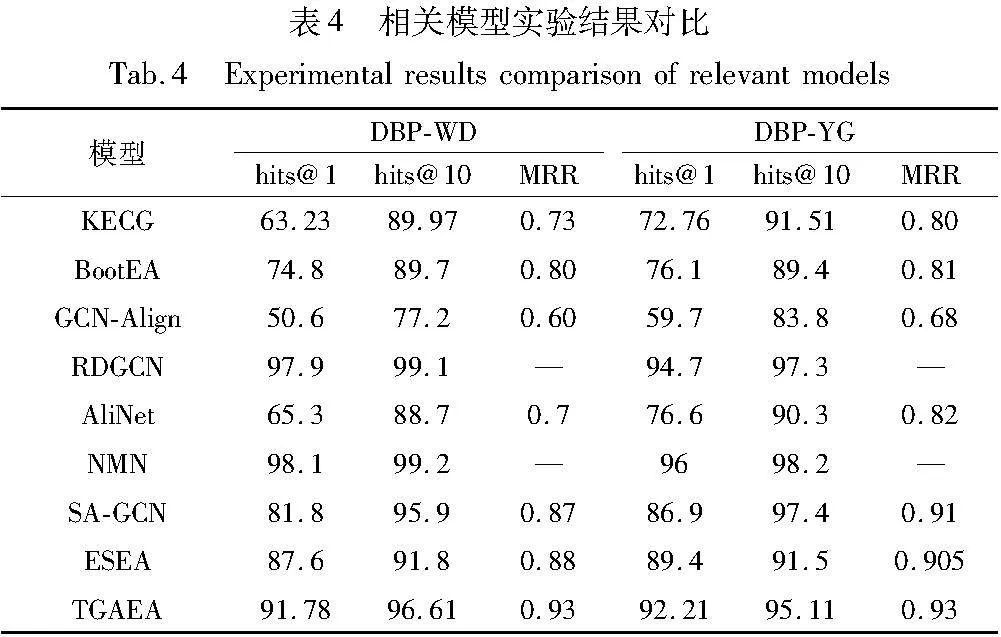
对比实验均采用结合原模型代码及相关论文在相同实验平台进行复现,得到相关模型实验结果对比如表4所示。
基于TransE为编码器的实体对齐模型在整体上效果表现较差,主要原因是使用TransE的嵌入方法构建关系三元组,但忽略了实体的整体结构信息;基于GCN为编码器的模型从知识图谱整体结构上面进行嵌入,取得了较好的效果。本文模型在两个基准数据集上取得了优异的效果,其hits@1、hits@10和MRR较目前主流的模型提升3%~20%,与本文对照的最优基准模型ESEA在两个数据集的比较中,本文模型分别在hits@1上提升了4.18%和2.81%,在hits@10上提升了4.81%和3.61%,在MRR上提升了0.05和0.025。RDGCN与 NMN使用由图神经网络计算的局部节点嵌入,证明了图卷积网络能够有效融合图之间局部邻域的匹配特征,在两种数据集上都明显优于其他基准模型,其hits@10值在两个数据集上分别在 97%~99%。可以看出,关系邻域特征对于实体对齐任务有着明显的帮助,然而这两种模型更聚焦于处理关系三元组的知识图谱,并未处理具有属性特征的实体对齐工作,因此单看两种模型的表现不具备普适性。
观察TGAEA模型在DBP-WD和DBP-YG数据集上的表现不难看出,相比于同样使用图神经网络对实体结构信息嵌入的GCN-Align模型,正文显示属性、名称、关系等信息嵌入策略对实体对齐任务的精准度有显著提升。本文模型在属性特征向量更多的情况下表现得更加优异,证实了优化后的属性信息能够提升实体对齐模型的性能,验证了此模型更偏向处理属性信息丰富的邻域实体对齐工作。
4.4.2 消融实验
为了验证本文方法的有效性,在实验过程中采用了不加图注意网络的方法(TGAEA-a)、在属性模块加入单注意力网络的方法(TGAEA-b)、在联合嵌入时加入单注意力网络的方法(TGAEA-c)以及本文的双层图注意力网络嵌入下的实体对齐模型(TGAEA)四种方法,在DWY100K上进行消融实验,得出不同注意力加权下的模型hits@1、hits@10以及MRR的值,如表5所示。
根据以上四种在不同位置加入图注意网络模型的得分情况可知, TGAEA-b模型在DBP-WD数据集上的评估指标性能优于DBP-YG数据集,这与单层图注意力网络更关注属性信息对实体的贡献程度有关,而TGAEA-c与TGAEA-b模型分别关注实体单个信息和实体间不同信息。结果在两种不同数据集上的模型评估指标说明,单层图注意力网络虽然能使模型性能有所提升,但提升效果远差于两层图注意力网络相结合的模型性能。加入双注意力机制的嵌入方法要明显区别于没有加入任何注意力机制的方法,且精确度提升在25%~35%,说明双层注意力机制能够明显提升模型性能;同时观察可知,加入双层注意力机制的方法要比加入单层注意力机制的方法在对齐得分上提升10%~15%,结果符合本文提出的注意力机制能够显著提升嵌入时信息聚合的质量。
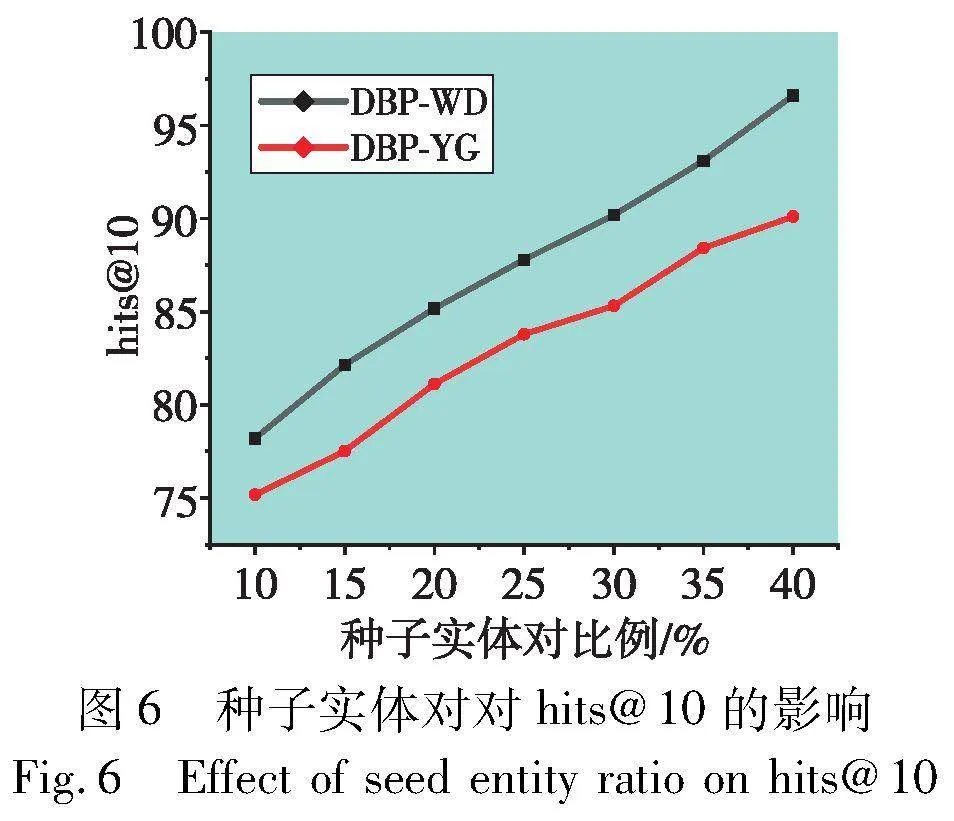
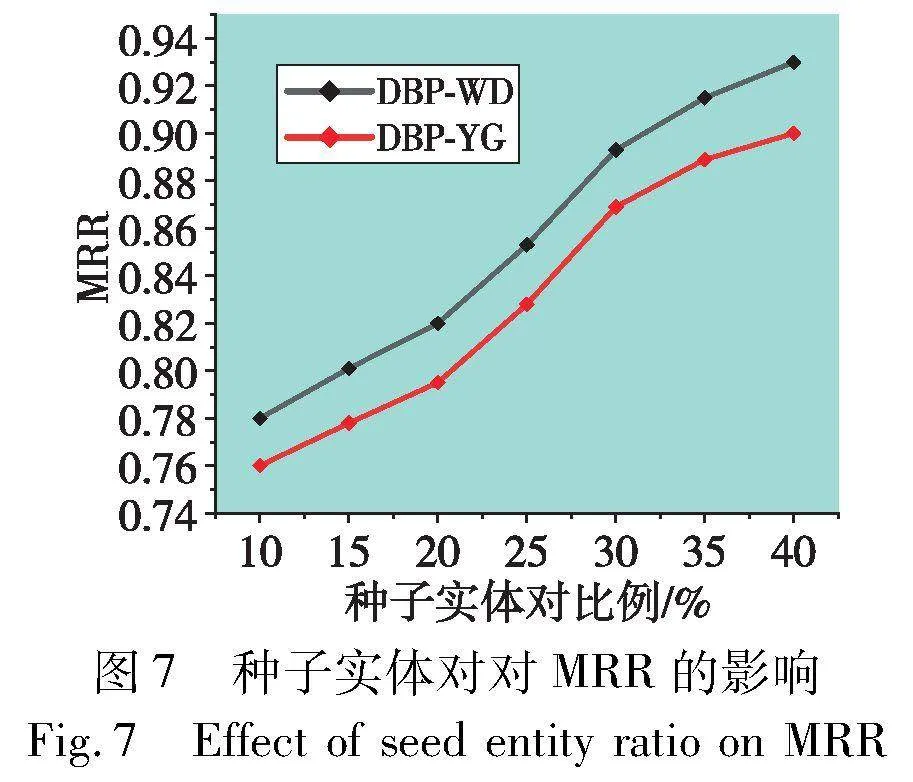
4.4.3 种子比例对模型的影响
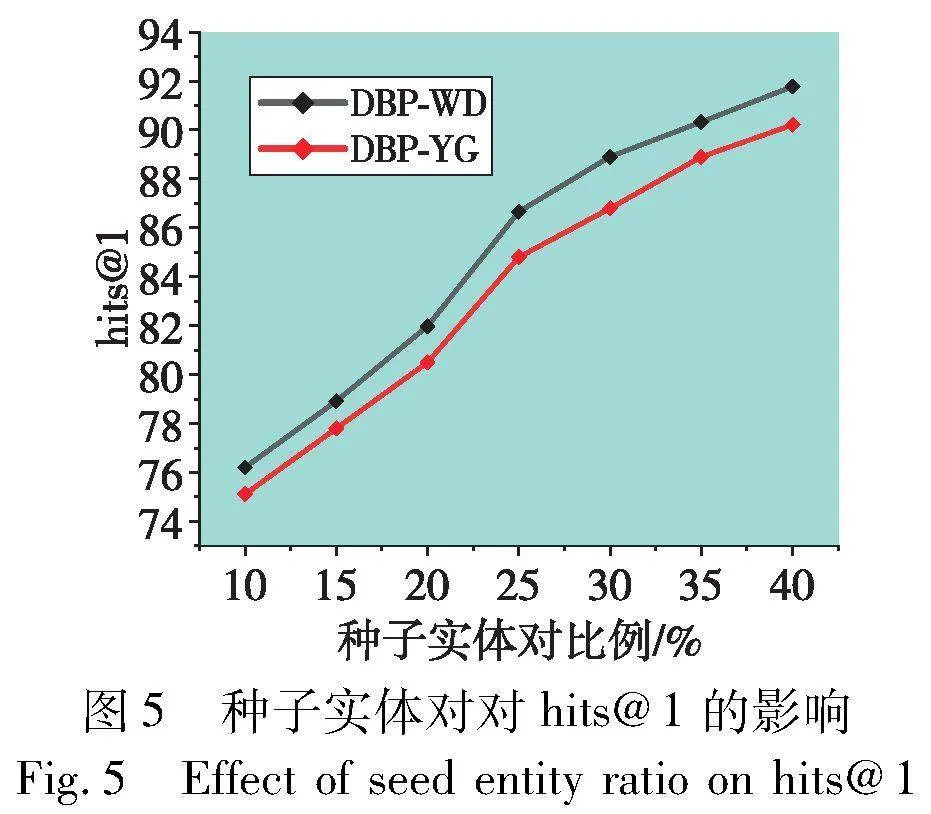
通常,模型性能受先验知识训练数据比例影响较大。为了探讨种子实体对对模型性能的影响,选择种子实体对比例为10%~40%来观察模型性能变化,间隔为5%。图5~7分别显示了不同种子实体对比率在DWY100K数据集上对模型性能的影响。在三个种子实体对影响折线图中,横坐标表示种子实体对的比例,纵坐标表示模型性能,观察可知,随着种子集的比例增加,模型性能在种子集比例为10%~25%期间提升较大,在25%~40%提升较小,原因是随着种子实体对的增加,模型在学习先验知识的过程渐趋饱和,模型精度随着种子实体对的增加会趋于稳定,最终使模型具有较高性能。
4.4.4 实例验证
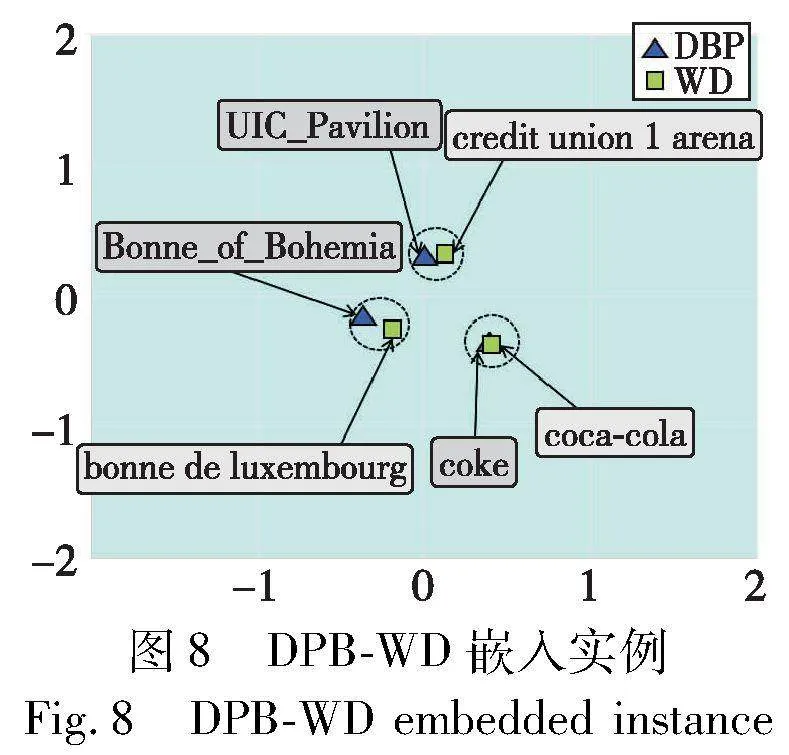
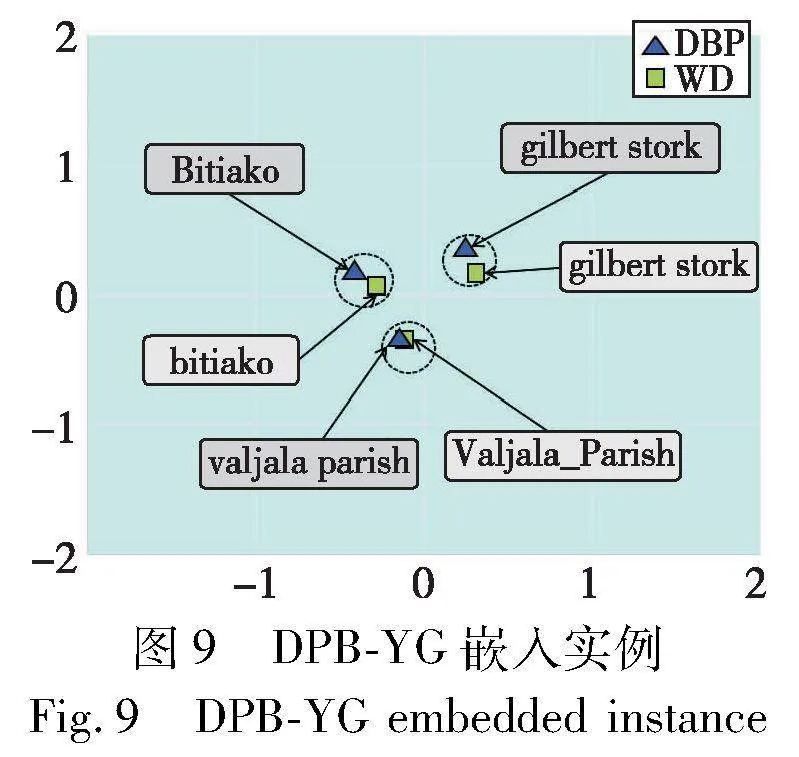
本文从数据集DWY100K的DBP-WD和DBP-YG中分别随机选择三个等价实体对,使用主成分分析(PCA)算法将实体嵌入映射到二维中。图8显示了DWY100K实体对的对齐可视化,图例颜色显示不同数据源实体。观察二维表可以发现,数据源为DBP的“Bonne_of_Bohemia”实体可能对应数据源为WD的“Bonne de Luxembourg”实体,两者都作为波希米亚国王约翰的次女名称描述;数据源为DBP的“UIC_Pavilion”实体可能对应数据源为WD的“Credit Union 1 Arena”实体,“Credit Union 1 Arena”为多功能竞技场,虽然和“UIC_Pavilion”名称不同,但它们指向同一个地点;数据源为DBP的“Coke”实体可能对应数据源为WD的“Coca-Cola”实体,“Coke” 是“Coca-Cola”的简称,虽然名称不同,但它们指向同一个公司。在两个数据集上,等价实体彼此接近,在二维图中,不相关的实体相距遥远,更相关的两个实体距离相近甚至重合,证实了以实体距离判断相似性的方法可行,符合模型设计的预期,图9同样展示了数据源为DBP和YG映射后的等价实体对。
5 结束语
本文提出了一种基于双层图注意网络的邻域信息聚合表示模型TGAEA,使用双层图注意力网络分别对实体单个信息内和多种信息间的向量进行双层实体邻域信息聚合,解决了实体对齐工作中部分信息对实体的影响程度不一致的问题。该模型设计了一种可以进行双层图注意网络特征加权的模式,可以更好地细分不同信息在实体对齐工作中的作用。在DWY100K数据集上分别进行了与基线模型的对比实验和单层或不加GTA模型的消融实验以及实例应用,分别验证了本文模型在处理单模态知识下不同数据来源和属性三元组较多的实体对齐工作的显著效果。
为了更好地提升图注意机制对特征向量表示的作用,未来还可以从如下两个方面进行研究:a)考虑进行多层注意力机制分别对实体的不同信息进行特征学习,进一步细化知识的作用;b)在未来,多模态实体对齐将是知识融合的重点和难点,如何利用图注意力机制细分不同模态的知识对实体对齐的影响,将是接下来工作的研究方向之一。
参考文献:
[1]赵丹,张俊. 基于双重注意力和关系语义建模的实体对齐方法[J]. 计算机应用研究,2022,39(1): 64-69,79. (Zhao Dan,Zhang Jun. Entity alignment method based on dual attention and relational semantic modeling [J]. Application Research of Compu-ters,2022,39(1): 64-69,79.)
[2]Pan Yudai,Liu Jun,Zhang Lingling,et al. Incorporating logic rules with textual representations for interpretable knowledge graph reaso-ning[J]. Knowledge-Based Systems,2023,277: 110787.
[3]Shokrzadeh Z,Feizi-Derakhshi M R,Balafar M A,et al. Knowledge graph-based recommendation system enhanced by neural collaborative filtering and knowledge graph embedding[J]. Ain Shams Enginee-ring Journal,2023,15(1): 102263.
[4]Bi Xin,Nie Haojie,Zhang Xiangguo,et al. Unrestricted multi-hop reasoning network for interpretable question answering over knowledge graph[J]. Knowledge-Based Systems,2022,243: 108515.
[5]张富,杨琳艳,李健伟,等. 实体对齐研究综述[J]. 计算机学报,2022,45(6): 1195-1225. (Zhang Fu,Yang Linyan,Li Jianwei,et al. Review of solid alignment[J]. Chinese Journal of Computers,2022,45(6): 1195-1225.)
[6]Cohen W W,Richman J. Learning to match and cluster large high-dimensional data sets for data integration[C]// Proc of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press,2002: 475-480.
[7]Halpin H,Hayes P J,McCusker J P,et al. When owl: sameAs isn’t the same: an analysis of identity in linked data[C]// Proc of the 9th International Semantic Web Conference. Berlin: Springer,2010: 305-320.
[8]徐有为,张宏军,程恺,等. 知识图谱嵌入研究综述[J]. 计算机工程与应用,2022,58(9): 30-50. (Xu Youwei,Zhang Hongjun,Cheng Kai,et al. Review of knowledge graph embedding[J]. Computer Engineering and Applications,2022,58(9): 30-50.)
[9]Bordes A,Usunier N,Garcia-Duran A,et al. Translating embeddings for modeling multi-relational data[C]// Proc of the 26th International Conference on Neural Information Processing Systems. 2013: 2787-2795.
[10]Kipf T N,Welling M. Semi-supervised classification with graph con-volutional networks [EB/OL]. (2017-02-22). https://arxiv.org/abs/1609.02907.
[11]莫少聪,陈庆锋,谢泽,等. 基于动态图注意力与标签传播的实体对齐[J]. 计算机工程,2024,50(4): 150-159. (Mo Shaocong,Chen Qingfeng,Xie Ze,et al. Entity alignment based on dynamic graph attention and label propagation[J]. Computer Engineering,2024,50(4): 150-159.
[12]Velickovic P,Cucurull G,Casanova A,et al. Graph attention networks [EB/OL]. (2017-10-30). https://arxiv.org/abs/1710.10903.
[13]Kim M,Kim G,Lee S W,et al. St-BERT: cross-modal language model pre-training for end-to-end spoken language understanding[C]// Proc of IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway,NJ: IEEE Press,2021: 7478-7482.
[14]Wang Zhen,Zhang Jianwen,Feng Jianlin,et al. Knowledge graph embedding by translating on hyperplanes[C]// Proc of the 28th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2014: 1112-1119.
[15]Lin Hailun,Liu Yong,Wang Weiping,et al. Learning entity and relation embeddings for knowledge resolution[J]. Procedia Computer Science,2017,108: 345-354.
[16]Chen Muhao,Tian Yingtao,Yang Mohan,et al. Multilingual know-ledge graph embeddings for cross-lingual knowledge alignment [C]// Proc of the 28th International Joint Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2017: 1511-1517.
[17]Sun Zequn,Wei Hu,Zhang Qingheng,et al. Bootstrapping entity alignment with knowledge graph embedding[C]// Proc of the 27th International Joint Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: 4396-4402.
[18]Sun Zequn,Hu Wei,Li Chengkai. Cross-lingual entity alignment via joint attribute-preserving embedding[C]// Proc of the 16th International Semantic Web Conference. Cham: Springer,2017: 628-644.
[19]Chen Muhao,Tian Yingtao,Chang K W,et al. Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment[EB/OL]. (2018-06-18). https://arxiv.org/abs/1806.06478.
[20]Li Shengnan,Li Xin,Ye Rui,et al. Non-translational alignment for multi-relational networks[C]// Proc of the 27th International Joint Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: 4180-4186.
[21]Zhu Hao,Xie Ruobing,Liu Zhiyuan,et al. Iterative entity alignment via joint knowledge embeddings[C]// Proc of the 26th International Joint Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2017: 4258-4264.
[22]Guo Lingbing,Sun Zequn,Hu Wei. Learning to exploit long-term relational dependencies in knowledge graphs[C]// Proc of the 36th International Conference on Machine Learning. [S.l.]: PMLR,2019: 2505-2514.
[23]Grossberg S. Recurrent neural networks[J]. Scholarpedia,2013,8(2): 1888.
[24]Wang Zhichun,Lyu Qingsong,Lan Xiaohan,et al. Cross-lingual knowledge graph alignment via graph convolutional networks[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2018: 349-357.
[25]Zhu Qiannan,Zhou Xiaofei,Wu Jia,et al. Neighborhood-aware attentional representation for multilingual knowledge graphs[C]// Proc of the 28th International Joint Conference on Artificial Intelligence Main Track. [S.l.]: International Joint Conferences on Artificial Intelligence Organization,2019:1943-1949.
[26]Yang H W,Zou Yanyan, Shi Peng,et al. Aligning cross-lingual entities with multi-aspect information [C]// Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019: 4422-4432.
[27]李凤英,黎家鹏. 联合三元组嵌入的实体对齐[J]. 计算机工程与应用,2023,59(24): 70-77. (Li Fengying,Li Jiapeng. Entity alignment for joint triple embedding[J]. Computer Engineering and Applications,2023,59(24): 70-77.)
[28]Zhang Qingheng,Sun Zequn,Hu Wei,et al. Multi-view knowledge graph embedding for entity alignment[C]// Proc of the 28th International Joint Conference on Artificial Intelligence. [S.l.]: International Joint Conferences on Artificial Intelligence Organization,2019: 5429-5435.
[29]魏忠诚,张洁滢,连彬,等. 基于双向GCN和CVm的实体对齐模型研究[J]. 计算机应用研究,2021,38(9): 2716-2720. (Wei Zhongcheng,Zhang Jieying,Lian Bin,et al. Research on entity alignment model based on bidirectional GCN and CVm[J]. Computer Application Research,2021,38(9): 2716-2720.)
[30]Li Chengjiang,Cao Yixin,Hou Lei,et al. Semi-supervised entity alignment via joint knowledge embedding model and cross-graph mo-del[C]// Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2019: 2723-2732.
[31]Wu Yuting,Liu Xiao,Feng Yansong,et al. Relation-aware entity alignment for heterogeneous knowledge graphs[C]// Proc of the 28th International Joint Conference on Artificial Intelligence Main Track. [S.l.]: International Joint Conferences on Artificial Intelligence Organization,2019: 5278-5284.
[32]Sun Zequn,Wang Chengming,Hu Wei,et al. Knowledge graph alignment network with gated multi-hop neighborhood aggregation[C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2020: 222-229.
[33]Wu Yuting,Liu Xiao,Feng Yansong,et al. Neighborhood matching network for entity alignment[C]// Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2020: 6477-6487.
[34]Chen Jia,Li Zhixu,Zhao Pengpeng,et al. Learning short-term diffe-rences and long-term dependencies for entity alignment[C]// Proc of the 19th International Semantic Web Conference. Cham: Springer,2020: 92-109.
[35]Jiang Tingting,Bu Chenyang,Zhu Yi,et al. Combining embedding-based and symbol-based methods for entity alignment[J]. Pattern Recognition,2022,124: 108433.
