图文语义增强的多模态命名实体识别方法
2024-07-31徐玺王海荣王彤马赫
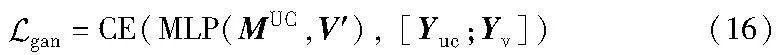

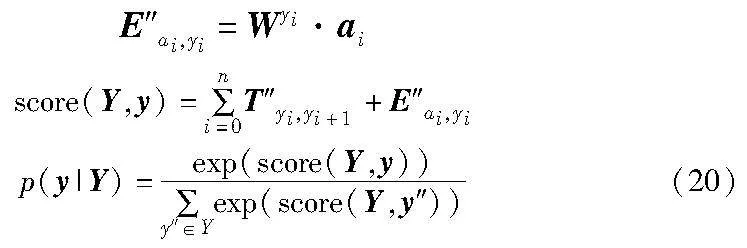

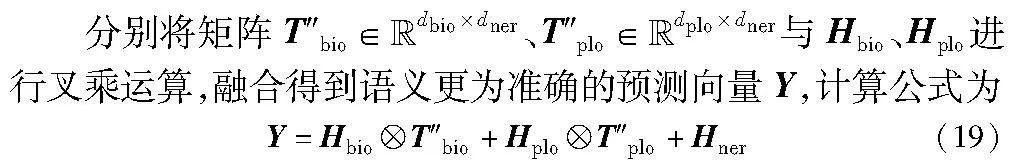


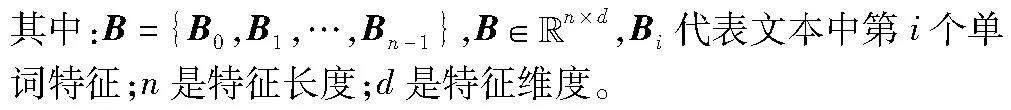
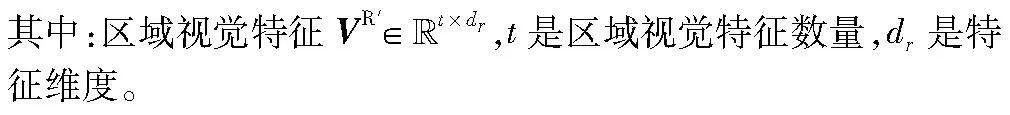


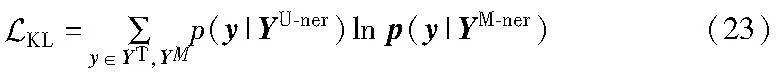
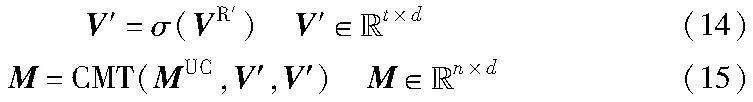


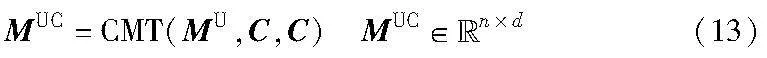

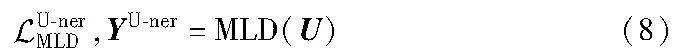

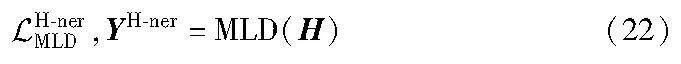

摘 要:为了解决多模态命名实体识别方法中存在的图文语义缺失、多模态表征语义不明确等问题,提出了一种图文语义增强的多模态命名实体识别方法。其中,利用多种预训练模型分别提取文本特征、字符特征、区域视觉特征、图像关键字和视觉标签,以全面描述图文数据的语义信息;采用Transformer和跨模态注意力机制,挖掘图文特征间的互补语义关系,以引导特征融合,从而生成语义补全的文本表征和语义增强的多模态表征;整合边界检测、实体类别检测和命名实体识别任务,构建了多任务标签解码器,该解码器能对输入特征进行细粒度语义解码,以提高预测特征的语义准确性;使用这个解码器对文本表征和多模态表征进行联合解码,以获得全局最优的预测标签。在Twitter-2015和Twitter-2017基准数据集的大量实验结果显示,该方法在平均F1值上分别提升了1.00%和1.41%,表明该模型具有较强的命名实体识别能力。
关键词:多模态命名实体识别;多模态表示;多模态融合;多任务学习;命名实体识别
中图分类号:TP391.1 文献标志码:A文章编号:1001-3695(2024)06-011-1679-07
doi: 10.19734/j.issn.1001-3695.2023.09.0439
Textual-visual semantics-enhanced multimodal named entity recognition method
Abstract: To address the issues of missing textual-visual semantics and unclear multimodal representation semantics in multimodal named entity recognition methods, this paper proposed a method of textual-visual semantic enhancement for multimodal named entity recognition. In this method, it used various pre-trained models to extract text features, character features, regional visual features, image keywords and visual labels, in order to comprehensively describe the semantic information of image-text data. It adopted the Transformer and cross-modal attention mechanism to mine the complementary semantic relationships between image-text features, guiding feature fusion, thereby generating semantically complete text representations and semantically enhanced multimodal representations. By integrating boundary detection, entity type detection, and named entity recognition tasks, it constructed a multi-task label decoder, which could perform fine-grained semantic decoding of input features, to improve the semantic accuracy of predicted features. It used this decoder to jointly decode text representations and multimodal representations to obtain globally optimal predicted labels. A large number of experimental results on the Twitter-2015 and Twitter-2017 benchmark datasets show that the proposed method has increased the average F1 score by 1.00% and 1.41% respectively, which indicates that the model has a strong capability for named entity recognition.
Key words:multimodal named entity recognition; multimodal representation; multimodal fusion; multi-task learning; named entity recognition
0 引言
传统的命名实体识别方法从词汇、语法等句子内部特征或从知识图谱、Web等外部文本数据中挖掘语义信息来支撑信息抽取。随着多媒体技术的广泛应用,文本、图片、音频等多模态数据不断涌现,且这些数据蕴涵着丰富的语义信息,也因此从多模态数据中挖掘语义信息,进行多模态信息抽取的方法逐渐得到越来越多的关注,多模态命名实体识别(multimodal named entity recognition,MNER)作为其中一项关键任务,已逐渐成为研究热点。
自2018年Moon等人[1]首次提出MNER后,Lu等人[2]也使用注意力机制融合文本特征和区域视觉特征,实现多模态特征过滤和多模态特征融合。然而在这两个方法中,文本特征和视觉特征之间存在语义不对称的问题。这是由于使用GloVe表示单词特征时,仅可以获得微弱的实体语义。为此,Zhang等人[3]提出首先聚合上下文信息来增强文本特征语义的MNER方法。随后,Wu等人[4,5]也使用双向长短记忆神经网络(bi-directional long short-term memory,BiLSTM)来聚合文本特征中的上下文信息,以增强单词的实体语义,再通过注意力机制对图像特征与文本特征进行融合。为了进一步缩小文本与图像特征的语义差距,2020年,基于Transformer的MNER方法首次被Yu等人[6]提出。随后Chen等人[7]在这几个MNER模型中使用BERT模型代替GloVe模型来表示文本特征,进一步验证了单词语义的重要性。此后的多模态命名实体识别方法均利用BERT模型表示文本特征,并采用Transformer模型对多模态特征进行编码、融合或对齐处理,以解决文本特征和图像特征难以挖掘语义交互关系的问题。例如,Asgari-Chenaghlu等人[8]采用Transformer模型对文本和图像的类标签进行联合编码来生成多模态表征。Zhang等人[9]采用基于Transformer的跨模态门控机制来引导对文本特征和区域视觉特征融合来输出多模态表征。钟维幸等人[10]堆叠跨模态注意力机制来融合图文特征。Xu等人[11]采用跨模态注意力机制来计算图文特征的语义对齐关系后,再利用该关系引导图文特征融合,以输出多模态表征。Wang等人[12]提出了一个精细化的注意力模型来挖掘图文特征间的双向语义关系,从而得到了更好的多模态特征。但这些方法由于视觉语义离散的影响,导致生成的多模态特征与文本特征的整体语义存在偏差。为此,引入了多任务学习的方法,通过协同处理文本特征和多模态表示上的两个子任务来增强识别能力。Yu等人[6]提出在文本特征上构建边界检测任务来辅助命名实体识别,从而解决视觉偏差的问题。类似的方法如Wang等人[13]和Liu等人[14]均在文本特征上构建命名实体识别任务,通过标签融合来解决该问题。此外也可以引入辅助任务来共同训练多模态表征,以提高模型的性能。例如:李晓腾等人[15]使用聚类任务统一特征空间促进特征融合;Chen等人[16]使用关系抽取任务训练多模态表示实现命名实体识别;Xu等人[17]提出了一个数据鉴别器,用于确定是使用多模态命名实体识别模型还是文本模态命名实体识别模型进行信息提取;范涛等人[18]引入迁移学习策略,在地方志多模态数据集中进一步训练多模态命名实体识别方法;Jia等人[19]对多模态数据集中的视觉特征进行细粒度的人工标注,并构建为视觉查询任务来过滤视觉噪声和优化视觉特征的语义,与命名实体识别任务一起训练。
针对上述问题,本文提出的应对策略如下:
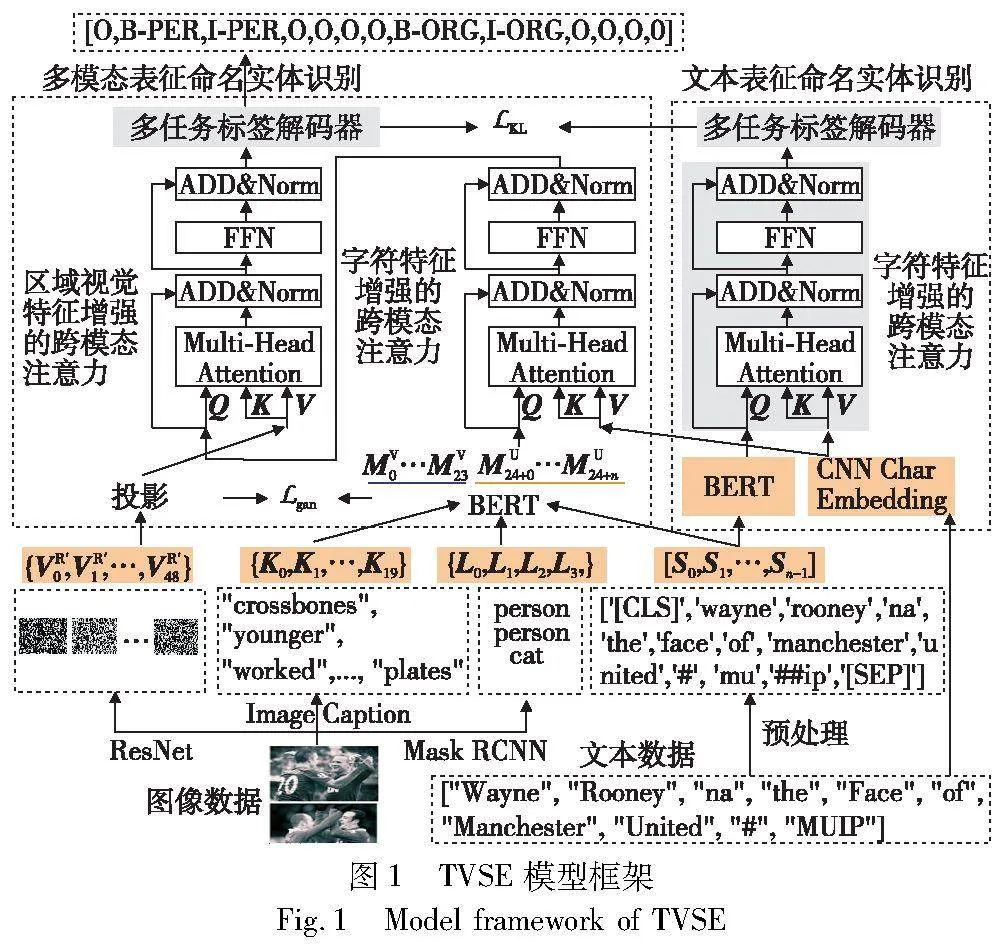
a)文本语义缺失。BERT在自然语言处理领域表现出色。然而,在社交媒体中,由于用户的书写不规范或随意性,存在着大量的(out of vocab, OoV)单词,它们没有出现BERT中的词表。此时,可能导致该单词语义缺失,从而导致预测错误。例如,在图1特征提取中,将单词“MUIP”拆分为“mu”和“##ip”,此外,网络地址单词等也会被识别为OOV单词。而由于字符特征具有表示单词形态的能力,为此,构建了字符特征增强的跨模态注意力模块来融合文本特征和字符特征,以生成语义补全的文本表征。
b)视觉语义缺失。视觉特征携带的语义信息量主要由采用的预训练视觉模型所决定。例如图1中的图像特征示例,视觉描述中包含“younger”等有益的单词,但也有许多与文本语义无关的单词,如“plates”。在视觉标签中包含一个重复的标签“person”,却缺少了实体类型为组织(ORG)的语义信息,同时,引入了其他实体语义,如“cat”。由于区域视觉特征可视化后没有特定形象的语义,但它着重描述视觉对象的形态信息,且与文本特征处于异构空间,特征融合较为困难。为此,提出了多模态特征融合模块,该模块利用各个视觉特征来分别表达图像中不同方面的语义,再通过协同表示来描述完整图像语义,然后调用Transformer模型融合自然语言形式的图文特征。针对字符特征、区域视觉特征与BERT编码的特征空间异构的问题,调用跨模态注意力机制来挖掘文本表示和字符特征、区域视觉特征间的语义互补关系,引导特征融合,生成图文语义增强的多模态表征。
c)多模态表征细粒度语义挖掘。现有多模态命名实体识别方法通常仅利用一个全连接层归纳实体语义,往往导致边界预测错误或实体类别预测错误的情况。为此,聚合命名实体识别、实体边界检测和实体类别检测三个任务来分别提取细粒度的语义后,以增强最终预测特征的语义准确性,进而提升命名实体识别准确性,并构建为多任务标签解码器。
d)为了消除多个视觉特征中复杂语义带来的负面影响,进一步调用多任务标签解码器对文本表征和多模态表征进行解码,并利用标签对齐模块来对齐这两个解码得到的预测特征,从而解决多模态表征融合错误的视觉语义导致的语义偏差问题。
综上所述,本文提出了一种图文语义增强的多模态命名实体识别方法(textual-visual semantics-enhanced multimodal named entity recognition method,TVSE),通过Transformer和跨模态注意力机制来挖掘特征间的语义互补关系,分别融合两种文本中的特征和三种视觉特征,得到语义补全的文本表征和语义增强的多模态表征,并调用共享的多任务标签解码器对文本表征和多模态表征进行联合解码,实现命名实体识别。
1 TVSE方法模型
TVSE方法使用跨模态注意机制将字符特征的语义信息与文本特征进行整合,解决文本语义缺失问题,得到语义增强的文本表示,并调用多任务标签解码器对文本表征进行解码,从而得到文本表征的预测标签,构成文本表征命名实体识别模块;多模态表征命名实体识别模块中,首先采用BERT对视觉描述、视觉标签、文本进行联合编码,以充分融合图文语义。再分别利用两种跨模态注意机制逐步挖掘字符特征、区域视觉特征与多模态文本特征之间的语义交互关系,以进一步增强图文语义,生成图文语义增强的多模态表征。调用多任务标签解码对多模态表征进行细粒度语义解码,得到多模态表征的预测标签,这也是TVSE的最终预测标签序列。然而,这也加剧了多模态表征中的视觉语义偏差问题。为此,使用KL散度函数来构建标签对齐模块,将文本表征的预测向量和多模态表征的预测向量进行对齐,从而监督多模态表征的语义学习,使其更加准确,进一步提升模型性能。
为了解决由于区域视觉特征与文本特征分属两个不同的特征空间导致的图文语义融合困难的问题,本文引入一个对抗学习策略来对区域视觉特征的投影函数进行优化,使其尽可能与文本特征的语义分布相似,即优化目标是使得由多层感知机组成的模态分类网络不能区分特征属于文本模态特征或区域视觉特征。
TVSE模型由文本表征命名实体识别模块、多模态表征命名实体识别模块组成,如图1所示。
图1(左下)是区域视觉特征、视觉描述和视觉标签的示例,用红色标记有用的单词;图1(右下)是文本特征、字符特征的示例,用红色标识句子中的实体;图1(左中)是多模态融合模块,包含Transformer模型和两个跨模态注意力机制;图1(右中)是使用跨模态注意机制补全文本特征语义的过程;图1(上)是使用共享的多任务标签解码器分别对文本表征和多模态表征进行序列标注,并通过对齐预测特征向量的过程。预测标签与输入的单词一一对应,实体标签使用红色标识(参见电子版)。
2 文本表征命名实体识别模块
使用语言模型BERT、CNN提取文本特征、字符特征,调用跨模态注意力机制将字符特征语义信息传递到文本特征上,获得文本语义增强的文本表征,调用多任务标签解码器挖掘文本表征中的细粒度实体语义,从而对文本表征进行序列标注,获得第一个预测标签,并标识为TVSE-U。
2.1 文本特征表示
对于给定的文本S′={S′0,S′1,…,S′m-1},将S′转换为BERT编码层的嵌入,表示为S={S0,S1,…,Sn-1} ,它是token 嵌入、position 嵌入、segment 嵌入的组合。S′i 是文本中的第i个单词, m代表句子中单词的长度。Si 是第i个嵌入,n是嵌入的长度。将S输入BERT模型,文本特征表示如下:
B=BERT(S)(1)
使用自然语言处理工具包fastNLP(https://fastnlp.readthedocs.io/zh/latest/)读取原始文本中所有句子的单词,以构建为词表。调用fastNLP中的CNNCharEmbedding模型表示原始文本S′i的字符特征,来表示单词的形态信息和语义信息,特征提取如下:
C=CNNCharEmbedding(S′)(2)
2.2 文本特征增强层
跨模态注意力(cross modal attention,CMT)的计算过程如式(3)~(6)所示。
使用跨模态注意力机制将字符特征中的形态信息和语义信息传递到文本特征中,以补全单词语义,挖掘文本特征内的语义来获得文本语义增强的文本表征U,计算如下:
其中:跨模态注意力调用时,令Q=B,K=C,V=C。
2.3 多任务标签解码
其中:MLD() 是多任务标签解码器,将在4.1节介绍。当损失进行反向传播时,多任务标签解码器将引导文本表征学习文本的细粒度实体语义。
3 多模态表征命名实体识别模块
多模态表征命名实体识别模块是在文本表征命名实体识别基础上进行扩展形成的,它使用三种不同的视觉模型来表示完备的图像语义。针对每种视觉特征表达图像中不同语义信息的特点,该文分别利用Transformer和跨模态注意力机制来挖掘特定视觉特征与文本特征的语义交互关系,从而将图像的完整语义传递到文本特征中,以输出图文语义增强的多模态表征。通过使用共享的多任务标签解码器挖掘多模态表征中的细粒度实体语义,得到第二个预测标签。
3.1 图像特征提取
为了解决单种视觉特征中的语义缺失问题,分别提取了视觉描述和视觉标签,它们是使用自然语言描述的视觉特征,表示不同两种粒度的视觉对象信息。此外还提取了多层形态语义的区域视觉特征。
对于输入的图像特征I,视觉标签使用Mask R-CNN[20]提取,表示图像全局粒度实体语义,可表示为
L=Mask-RCNN(I)(9)
其中:L={L0,L1,L2,L3},包含4个标签单词的嵌入。
视觉描述,使用图像字幕模型IC[21]提取,表示图像细粒度实体语义,可表示为
K=IC(I)(10)
其中:K={K0,K1,…,K19},包含20个单词的嵌入。
区域视觉特征,使用ResNet[22]提取,表示图像特征的形态信息和隐藏的关系信息,可表示为
VR′=ResNet(I)(11)
3.2 多模态特征融合
使用BERT模型对文本、视觉描述、视觉标签进行联合编码,挖掘文本特征S与视觉描述K、视觉标签L之间的语义交互关系,实现图文特征的充分融合,计算公式为
[MV;MU]=BERT([K;L;S])(12)
调用跨模态注意力机制来挖掘MU与字符特征的语义互补关系,补全MT的文本语义,计算公式如下:
其中:CMT()是跨模态注意力机制;C是字符特征。
将区域视觉特征投影到MUC的特征空间后,调用跨模态注意力机制来挖掘MUC与区域视觉特征的语义交互关系,利用区域视觉特征中的形态语义或潜在的关系语义来矫正或增强MUC的实体语义,得到图文语义增强的多模态表征,计算公式如下:
其中:σ()是投影函数,将特征维度为dr的区域视觉特征VR′投影到BERT的编码维度;n是特征长度;d是文本特征维度。
由于VR′与MUC分属两个不同的特征空间,不利于融合两者间的语义。为此,使用对抗学习优化投影函数σ(),使得投影后的特征V′与MUC分布相似。对抗学习是一个基于多层感知机的模态分类模型,其计算公式可表示为
其中:多层感知机MLP()将V′与MUC投影到分类空间。使用交叉熵函数CE()计算模态分类损失,它将MUC中的特征节点的标签设置为Ymuc=[0,…,0],V′的特征节点标签设置为Yv=[1,…,1],其标签掩码是V′与MUC的特征掩码。当模型不能准确区分V′与MUC的类别时,说明这两个特征处于语义分布相似的特征空间中。
3.3 多任务标签解码
当损失进行反向传播时,多任务标签解码器也将引导多模态表征学习图文数据中的细粒度实体语义。
4 标签解码
本章将详细介绍多任务标签解码器、标签对齐任务。
4.1 多任务标签解码器
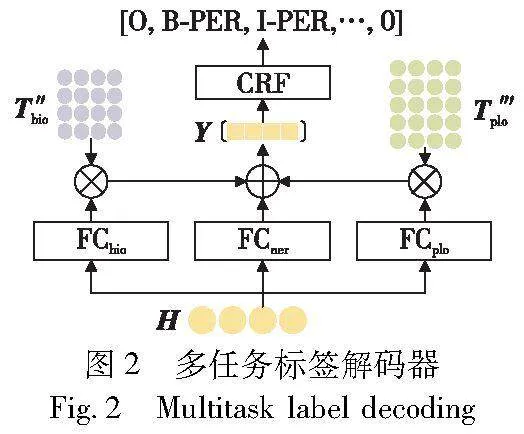
多任务标签解码器(multitask label decoding,MLD)将命名实体识别、实体边界检测和实体类别检测的预测向量聚合在一起,协同挖掘特征中的细粒度实体语义,进而提高了条件随机场中输入特征的质量,提升命名实体识别的准确性。MLD模型结构如图2所示。
其中:dbio、dplo、dner分别是三个任务投影函数FCbio()、FCplo()、FCner()的投影维度;n是特征数量。
考虑到标签之间的依赖关系,使用条件随机场来标记Y中的预测序列y。
其中:T″yi,yi+1 是从标签yi到标签yi+1的过渡分数;E″ai,yi 是标签yi的发射分数;Wyi 是yi特有的权重参数。
使用最大条件似然函数损失函数计算作为多任务标签解码的损失,计算公式为
使用MLD()表示多任务标签解码器,则对于输入隐藏向量H,以上公式可表示为
4.2 标签对齐模块
多种视觉特征中语义更为丰富,但视觉语义和视觉噪声也更为复杂,这可能导致多模态表征语义出现偏差,从而导致预测错误。为此,使用KL散度损失函数来最小化文本表征、多模态表征的预测向量之间的差异,以消除视觉噪声,引导多模态表征学习到正确的语义,获得最优预测标签,计算公式为
其中:YU-ner、YM-ner是式(8)(17)得到的预测向量。
4.3 损失函数
使用损失求和的方法来将各个任务组合起来进行联合学习,并得到模型的最终预测标签YM-ner,损失表示如下:
5 方法验证及结果分析
利用PyTorch等技术搭建实验环境,通过AdamW[23]优化器调整模型参数,设置epoch=30、batch size=16、learning rate=5E-5。使用F1值(F1-score)作为评价指标,在Twitter-2015和Twitter-2017公共多模态数据集上进行实验来验证本文方法。
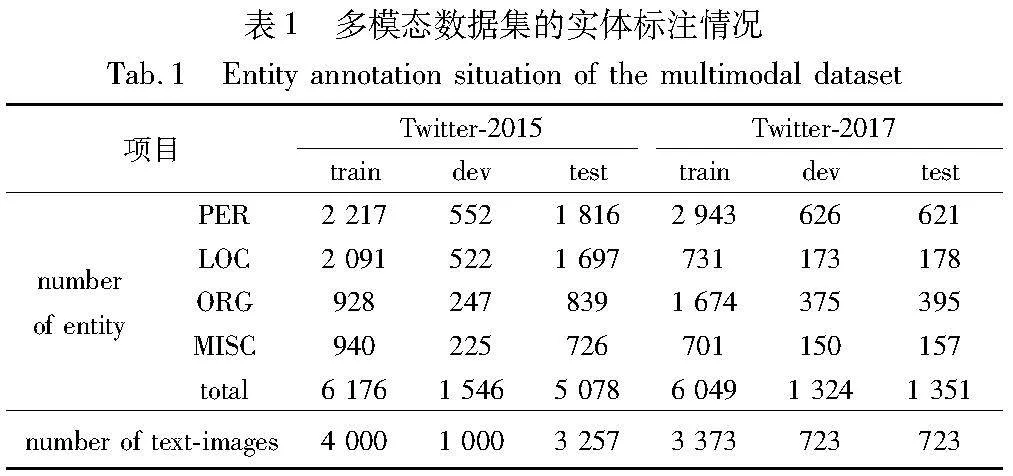
Twitter-2015[2]是从Twitter’s API提取的包含7 257个图文对的多模态命名实体识别数据集。Twitter-2017[4]是从Twitter posts提取的包含4 819个图文对的多模态命名实体识别数据集。数据集中每个文本仅和一张图片进行关联,将数据集拆分成训练集、验证集、测试集,其中图文对的数量如表1 (number of text-images)所示。此外,人名(PER)、地名(LOC)、组织名(ORG)、其他(MISC)的数据量统计详情如表1所示。
5.1 TVSE-U性能评价
将文本表征命名实体识别模块(TVSE-U)与BERT-CRF、MNER-QG-U等四种模型进行对比实验,结果如表2所示。
与对比模型中的最优模型MAF-U和MNER-QG-U相比,在Twitter-2015、Twitter-2017数据集上,TVSE-U模型的F1值分别提高了0.26%、0.64%。此外在Twitter-2017数据集上,相比最优模型MNER-QG-U,TVSE-U的PER、LOC、ORG、MISC的F1值分别提升1.2%、0.32%、1.38%、0.82%;在Twitter-2015数据集中,PER、ORG的F1值分别增长了1.19%、1.5%。其中一个原因是跨模态注意力机制将字符特征中的语义传递到文本特征中,补全了文本语义,获得了更有效的文本表征。
使用CRF模型作为实体标签解码器是有效的,但TVSE-U方法进一步融合实体边界检测、单词类属检测任务来挖掘特征中的语义,使得在Twitter-2017中,TVSE-U模型相比BERT-CRF,PER、LOC、ORG、MISC的F1值分别提高了2.28%、2.50%、2.00%、7.02%;相比UMT-U模型,TVSE-U的F1值在两个数据集上均有提升,其原因之一是多任务标签解码器中的实体边界检测、单词类属检测、命名实体识别任务都可以表征挖掘细粒度语义信息,以提高CRF模型的解码能力。
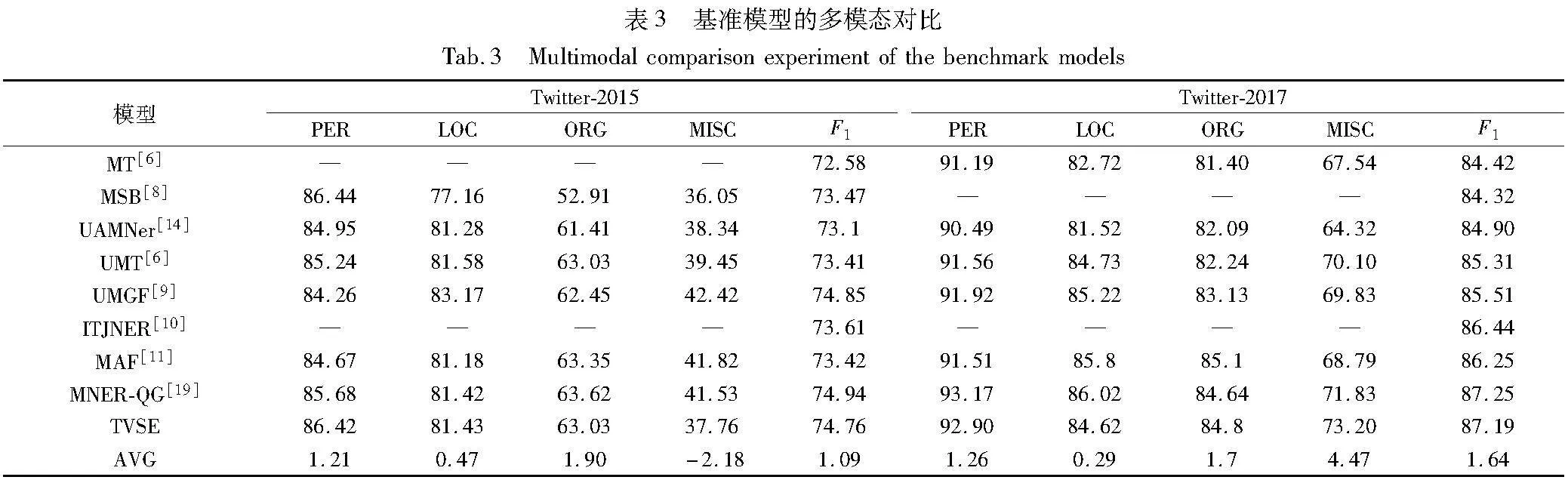
与表3中的MNER模型相比,TVSE-U仍然是先进的。在Twitter-2015数据集上,TVSE-U相比MT、UAMNer的F1值分别高出0.88%、0.36%,与基于图文联合编码的MSB、UMT、MAF模型持平(±0.05%);在Twitter-2017数据集上,TVSE-U的F1值增幅依次是MT(1.77%)、MSB(1.87%)、UAMNer (1.29%)、UMT (0.88%)、UMGF (0.68%)、MAF (-0.06%),实验证明了字符特征能补全文本表征的语义,且多任务标签解码模块可以提高标签解码的能力。
5.2 TVSE 方法性能评价
与近三年内八种主流MNER模型MT、UMT、MNER-QG等进行对比实验,实验结果如表3所示。
为了说明TVSE方法的有效性,与采用联合表示编码方法的MSB模型、采用跨模态注意力机制和联合解码方法的UMT、UAMNer模型进行对比,TVSE的性能均有较好的提升,即在Twitter-2015中,TVSE的F1值相比MSB、UMT、UAMNer分别提升1.29%、1.35%、1.66%;在Twitter-2017中,TVSE的F1值分别提升2.87%、1.88%、2.29%。其中一个原因可能是,TVSE利用多种视觉特征协同表达得到了更为完整的视觉语义,并有效挖掘了文本特征与这些视觉特征间的语义交互关系,进而获得了图文语义增强的多模态表征,而提高了命名实体识别的能力。
此外,如表3最后一行所示,是TVSE模型与八种主流MNER模型F1值的平均值差,TVSE模型均取得了更好的结果,其可能的原因是,TVSE模型有效地挖掘到了文本特征与字符特征、区域视觉特征、视觉标签、视觉描述间的语义互补性,从而得到了高质量的多模态表征。
在Twitter-2017数据集中,TVSE的F1值为87.19%,超过其中七种模型。与MNER-QG相比,F1值仅降低了0.06%,而在Twitter-2015数据集,TVSE模型的F1值高于5种基准模型,相比UMGF和MNER-QG的F1值仅降低了0.09%、0.18%,但TVSE在PER和LOC的F1中取得了更好的结果,导致该结果的原因可能是MNER-QG方法通过对图像进行细粒度的人工标注,从而获得了更加精确的视觉特征表示,进而提高了多模态表示质量。未来考虑在视觉特征上构建视觉语义约束任务来约束或过滤视觉特征的语义表示。
5.3 性能对比
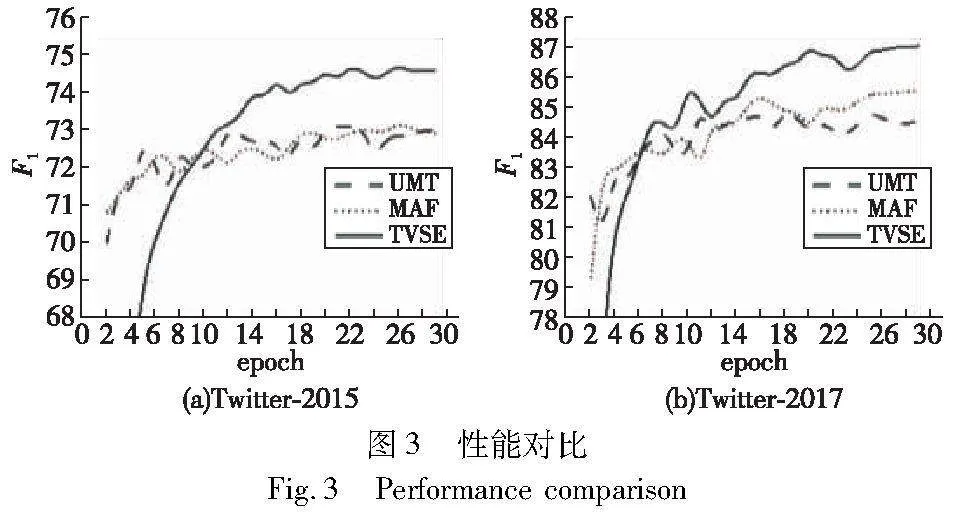
选择多模态对齐模型MAF、多任务跨模态注意力模型UMT作为对比模型,选取了这些方法在Twitter-2015和Twitter-2017数据集中第2~29个epoch的F1值数据进行可视化,F1值是在测试集上计算的。对比结果如图3所示。
从图3中可以看出,MAF模型的性能曲线稍高于UMT模型,这是因为它着重地利用视觉特征和文本特征的语义对齐关系来消除了错误的视觉语义。虽然UMT模型利用边界检测任务来辅助解码,但事实上在两个数据集中,基于文本特征的边界检测任务的F1值已经可以达到90%以上。因此,UMT模型在一定程度上解决了视觉语义偏差问题,最终性能的提升幅度较低。
TVSE的性能在第10轮后,其评估指标线(绿色线,参见电子版)均明显高于UMT和MAF模型。而TVSE模型一方面利用多种图文特征补全了图文特征语义,另一方面利用多任务标签解码挖掘文本表征和多模态表征中的细粒度语义来辅助解码。因此,生成了语义增强的多模态表征,从而使得TVSE模型的F1值上都超过了UMT和MAF模型,实现了识别效果的提升。
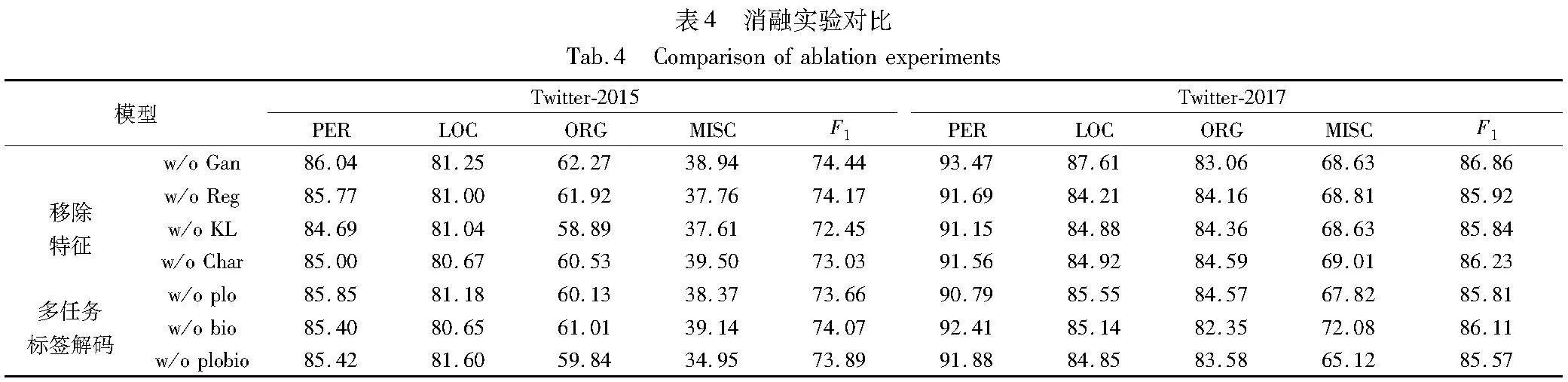
5.4 消融实验
为了验证TVSE模型中各组件的有效性,进行消融实验。首先移除对抗学习任务(Gan);在w/o Gan基础上分别移除一种引入的特征及其相关的特征融合层,组成如下对照组:字符特征(Char)、视觉标签和视觉描述(KL)、区域视觉特征(Reg)。
在表4的Twitter-2015、Twitter-2017数据集中,w/o Gan的F1值分别下降0.32%、0.43%,这说明失去对抗学习任务后,区域视觉特征和文本特征语义分布是不相似的,融合更为困难,从而降低了模型的实体识别能力。
继续移除区域视觉特征(Reg)或移除视觉标签、图像关键字(KL),即w/o Reg和w/o KL,此时模型仅融合一种图像特征。实验表明,在Twitter-2015数据集中,w/o Reg和w/o KL的F1值分别下降0.27%、1.99%;在Twitter-2017数据集中,w/o Reg和w/o KL的F1值分别下降0.94%、1.02%,这验证了单视觉特征中存在语义缺失的问题,且不同的图像特征仅能表示图像中一个侧面的语义;当使用多种视觉特征协同表示时,将得到更全面的图像语义。此外,本文在移除对抗学习任务(Gan)的基础上对文本表征进行消融实验,即w/o Char,在Twitter-2015、Twitter-2017数据集中,w/o Char的F1值分别下降1.41%、0.63%,这就表明当失去字符特征,文本特征存在语义缺失的情况,反之,语义补全后,文本表征和多模态表征的质量会得到提高,从而提高模型的性能。
为了说明多任务解码器中各个子任务对标签解码的作用,进行消融实验如下:移除实体边界检测任务(bio)用于表示多任务解码器引导多模态表征学习实体语义、实体类别语义时的性能;移除实体类别检测任务(plo)用于表示仅引导多模态表征学习实体语义、实体边界语义时的性能;移除两种任务(plo bio) 用于表示仅引导多模态表征学习实体语义时的性能。
表4的实验结果显示了在Twitter-2015、Twitter-2017数据集中, w/o bio的F1值分别下降0.37%、0.75%,w/o plo的F1值分别下降0.78%、1.05%,单类F1值也有不同程度的下降。其原因在于实体边界检测任务能通过确定实体的边界,来辅助识别命名实体;实体类别检测任务能通过确定实体的类别,来辅助识别命名实体。进一步地,移除这两种任务(w/o plobio)后,此时多任务解码是CRF解码模型,在Twitter-2015、Twitter-2017数据集中, F1值分别下降0.55%、1.29%,其他指标也进一步下降,这表明实体边界检测任务、实体类别检测任务、命名实体识别任务可以相互协作,共同提升命名实体识别的准确性。
此外在Twitter-2015数据集中,w/o plobio模型相比MT、MSB、UAMNer、UMT、ITJNER、MAF等模型仍有竞争力,而在Twitter-2017数据集,F1值也高于MT、MSB、UAMNer、UMT、UMGF等模型,其可能的原因是TSVE方法通过图文语义增强,获得了高质量的多模态表征,从而提高了命名实体识别的解码准确性。
5.5 案例分析
在Twitter-2015的测试数据集上,选取UMT、MAF、TVSE-U、TVSE四种方法的预测结果和多模态数据进行可视化,结果如表5所示。图中[#1,#2,#3]分别表示单词、预测标签和真实标签,当预测错误时使用红色字体进行标识, 真实标签使用绿色进行标识(参见电子版)。
从表5中可以看出,TVSE-U通过聚合字符特征和文本特征的语义信息,使其生成了相对准确的文本表征,因此能准确识别UMT、MAF方法无法识别的实体。例如,准确预测了单词“To”“Em”的实体标签。TVSE通过Transformer模型和跨模态注意力机制融合字符特征、文本特征和三种视觉特征的语义信息,以纠正单词的形态语义和实体语义,从而得到了较高质量的多模态文本表征。同时,引入的多任务标签解码模块进一步辅助明确单词的实体类别和边界分隔。因此,TVSE能准确地生成单词“To”“Em”“Getty ”和单词组“Mac Book pro”的多模态文本表示,并理解其中每个单词的实体类别语义和边界语义信息,从而正确地识别这些实体,使得TVSE模型对图文数据具有信息抽取的能力。
6 结束语
本文提出了图文语义增强的多模态命名实体识别方法,分别通过图文模态内特征协同来补全文本语义和图像语义;分别构建文本特征命名实体识别模块和多模态命名实体识别模块,来得到文本语义补全的文本表征、图文语义增强的多模态表征;分别使用共享的多任务标签解码器对文本表征和多模态表征进行细粒度语义挖掘和细粒度实体标注,来得到文本表征、多模态表征的预测向量,并通过最小化预测向量间的差异,引导多模态表征准确地融合视觉语义,从而有效地识别实体。
通过在Twitter-2015、Twitter-2017数据集上进行了实验,与BERT-CRF、MNER-QG-U等四种模型进行对比,文本表征命名实体识别方法的平均F1值分别提升了0.84%、1.90%;与MAF、UMT、MNER-QG等八种主流多模态命名实体识别模型对比,本文方法的平均F1值分别提升了1.00%、1.41%,实验结果证明了TVSE能有效识别社交多模态数据中的命名实体。
在未来的工作中,针对TVSE在语义弱相关的Twitter-2015数据集中性能不足的问题:a)通过构建视觉语义约束任务,引导挖掘视觉特征中更为准确的细粒度语义,再对多模态特征之间的语义关系进行建模,来增强多模态特征的语义表示;b)利用图文语义相似关系,消除视觉噪声和过滤视觉特征中的无关实体语义;c)利用语音生成、图文检索等技术增加输入的模态信息,提升多模态表征的语义的全面性和通用性,进而训练一个更健壮的多模态命名实体识别模型。
参考文献:
[1]Moon S,Neves L,Carvalho V. Multimodal named entity recognition for short social media posts [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S.l.]: NAACL Press,2018: 852-860.
[2]Lu Di,Neves L,Carvalho V,et al. Visual attention model for name tagging in multimodal social media [C]// Proc of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2018: 1990-1999.
[3]Zhang Qi,Fu Jinlan,Liu Xiaoyu,et al. Adaptive co-attention network for named entity recognition in tweets [C]// Proc of the 32nd AAAI Conference on Artificial Intelligence and the 30th Innovative Applications of Artificial Intelligence Conference and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: 5674-5681.
[4]Wu Zhiwei,Zheng Changmeng,Cai Yi,et al. Multimodal representation with embedded visual guiding objects for named entity recognition in social media posts [C]// Proc of the 28th ACM International Conference on Multimedia. New York: ACM Press,2020: 1038-1046.
[5]Zheng Changmeng,Wu Zhiwei,Wang Tao,et al. Object-aware multimodal named entity recognition in social media posts with adversarial learning [J]. IEEE Trans on Multimedia,2021,23: 2520-2532
[6]Yu Jianfei,Jiang Jing,Yang Li,et al. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer [C]// Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2020: 3342-3352.
[7]Chen Shuguang,Aguilar G,Neves L,et al. Can images help recognize entities? A study of the role of images for multimodal NER [C]// Proc of the 7th Workshop on Noisy User-generated Text. Stroudsburg,PA: Association for Computational Linguistics,2021: 87-96.
[8]Asgari-Chenaghlu M,Feizi-derakhshi M R,Farzinvash L,et al. CWI: a multimodal deep learning approach for named entity recognition from social media using character,word and image features [J]. Neural Computing and Applications,2022,34(3): 1905-1922.
[9]Zhang Dong,Wei Suzhong,Li Shoushan,et al. Multi-modal graph fusion for named entity recognition with targeted visual guidance [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2021: 14347-14355.
[10]钟维幸,王海荣,王栋,等. 多模态语义协同交互的图文联合命名实体识别方法 [J]. 广西科学,2022,29(4): 681-690. (Zhong Weixing,Wang Hairong,Wang Dong,et al. Image-text joint named entity recognition method based on multi-modal semantic interaction[J]. Guangxi Sciences,2022,29(4): 681-690.)
[11]Xu Bo,Huang Shizhou,Sha Chaofeng,et al. MAF: a general matching and alignment framework for multimodal named entity recognition [C]// Proc of the 15th ACM International Conference on Web Search and Data Mining. New York:ACM Press,2022: 1215-1223.
[12]Wang Xuwu,Ye Jiabo,Li Zhixu,et al. CAT-MNER: multimodal named entity recognition with knowledge-refined cross-modal attention [C]// Proc of IEEE International Conference on Multimedia and Expo. Piscataway,NJ: IEEE Press,2022: 1-6.
[13]Wang Xinyu,Min Gui,Yong Jiang,et al. ITA: image-text alignments for multi-modal named entity recognition [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: Association for Computational Linguistics,2022: 3176-3189.
[14]Liu Luping,Wang Meiling,Zhang Mozhi,et al. UAMNer: uncertainty-aware multimodal named entity recognition in social media posts [J]. Applied Intelligence,2022,52(4): 4109-4125.
[15]李晓腾,张盼盼,勾智楠,等. 基于多任务学习的多模态命名实体识别方法 [J]. 计算机工程,2023,49(4): 114-119. (Li Xiaoteng,Zhang Panpan,Gou Zhinan,et al. Multimodal named entity recog-nition based on multi-task learning [J]. Computer Engineering,2023,49(4): 114-119.)
[16]Chen Xiang,Zhang Ningyu,Li Lei,et al. Good visual guidance make: a better extractor: hierarchical visual prefix for multimodal entity and relation extraction [C]// Proc of Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2022: 1607-1618.
[17]Xu Bo,Huang Shizhou,Du Ming,et al. Different data,different modalities! Reinforced data splitting for effective multimodal information extraction from social media posts [C]// Proc of the 29th International Conference on Computational Linguistics. Stroudsburg,PA: Associa-tion for Computational Linguistics,2022: 1855-1864.
[18]范涛,王昊,陈玥彤. 基于深度迁移学习的地方志多模态命名实体识别研究 [J]. 情报学报,2022,41(4): 412-423. (Fan Tao,Wang Hao,Chen Yuetong. Research on multimodal named entity recog-nition of local history based on deep transfer learning [J]. Journal of the China Society for Scientific and Technical Information,2022,41(4): 412-423.)
[19]Jia Meihuizi,Shen Lei,Shen Xin,et al. MNER-QG: an end-to-end MRC framework for multimodal named entity recognition with query grounding [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2023: 8032-8040.
[20]He Kaiming,Gkioxari G,Dollár P,et al. Mask R-CNN [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 2980-2988.
[21]Vinyals O,Toshev A,Bengio S,et al. Show and tell: a neural image caption generator [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2015: 3156-3164.
[22]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 770-778.
[23]Loshchilov I,Frank H. Decoupled weight decay regularization [EB/OL]. (2019-01-04). https://arxiv.org/abs/1711.05101.
