区块链预言机节点选择的深度强化学习中间件
2024-07-31徐莉程梁培利
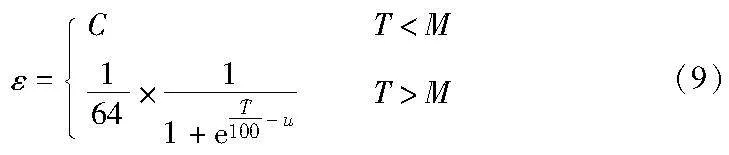

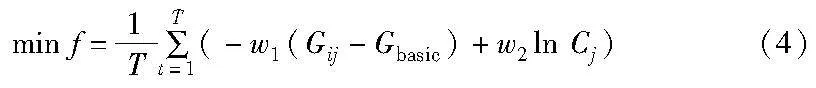

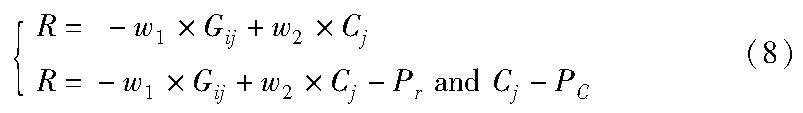
摘 要:优化区块链环境中现有预言机方案中的节点选择问题,以提高预言机节点选择的准确性和可靠性。引入了基于深度强化学习的区块链预言机节点选择中间件ORLM(oracle reinforcement learning model)。该中间件考虑了不同服务需求下多个节点的消耗,并建立了预言机节点的声誉值模型来评估预言机数据提供节点的声誉值,从而尽可能避免对具有恶意历史的节点的选择。通过深度强化学习DQN(deep Q network)算法,中间件能够对选择节点的过程进行优化,以在保证安全性的情况下进行更好的节点选择。实验结果表明,所提出的中间件能够更好地满足用户的服务请求,且具有较高的可扩展性和可用性,证明了引入深度强化学习来优化预言机节点选择是一个可行的方向。
关键词:区块链;深度强化学习;预言机;DQN
中图分类号:TP399 文献标志码:A文章编号:1001-3695(2024)06-005-1635-05
doi: 10.19734/j.issn.1001-3695.2023.10.0516
Deep reinforcement learning middleware for blockchain oracle node selection
Abstract:This paper aimed to optimize the node selection problem in existing oracle machine schemes in the blockchain environment in order to improve the accuracy and reliability of oracle machine node selection. This paper introduced ORLM, a deep reinforcement learning based middleware for blockchain prophecy machine node selection. This middleware considered the consumption of multiple nodes under different service demands and modeled the reputation value of the prophecy machine nodes to sick the reputation value of the oracle machine data-providing nodes, thus avoiding the selection of nodes with malicious history as much as possible. With the deep reinforcement learning DQN algorithm, the middleware is able to optimize the process of selecting nodes for better node selection with security. The experimental results show that the oracle middleware is able to better satisfy the service requests of users. And it has high scalability and availability. It proves that the introduction of deep reinforcement learning to optimize the oracle node selection is a feasible direction.
Key words:blockchain; deep reinforcement learning; oracle; DQN
0 引言
当前,智能合约在区块链中的应用越来越广泛,它能够自动执行双方事先约定的逻辑和交易。因为区块链去中心化和透明的特性,越来越多的去中心化应用通过智能合约在链上建立,涉及传统行业物联网[1]、医疗领域[2]和供应链[3]等诸多领域。然而,要实现这些现实世界中的逻辑,首先需要获取现实世界中的数据。由于区块链的数据可用性[4],链上的智能合约无法直接访问链下的数据。所以,获取外部数据,对于链上智能合约的执行至关重要。预言机解决了这一问题,链上智能合约可以通过预言机来获取链外的数据[5],从而打破链上和链下之间的隔阂,使智能合约能够更好地为现实世界服务。预言机充当了区块链与现实世界之间的桥梁,将外部数据引入链上,供智能合约使用。
预言机[6]是区块链中十分重要的一部分。它被用来为区块链网络提供服务,满足不同的链上应用对于链下数据的需求[7],帮助链上的智能合约获取区块链网络之外的数据。预言机可以通过多种方式获取外部数据[8],包括外部API进行交互、监控传感器数据、网络数据等。获取到的数据预言机会将其签名并传输到区块链上,以保证数据在传输的过程中不可被窜改。
一个预言机通常会采用多个预言机节点来为自己提供数据,这是因为在预言机系统当中,通过使用多个预言机节点,可以整体提高系统的可靠性和容错性,如果一个节点发生故障或者受到攻击,其他节点能够继续提供服务[9],可以确保系统的连续性和稳定性。一个预言机节点不止提供一项服务,每个预言机数据提供节点提供的服务可能是多样的,这引发的问题是对于同一个节点提供的不同服务可能存在差异性,不同节点的相同服务存在不同的成本。
深度强化学习(deep reinforcement learning)[10]是一种结合了深度学习和强化学习[11~14]的方法,用于解决具有高维状态和动作空间的复杂任务,而伴随着声誉值不断变化的预言机节点选择,其本身就具备这一特性。因此深度强化学习能够较好地适应预言机节点的选择问题。
本文相关工作如下:
a)提出了帮助区块链预言机节点进行选择的链下中间件,链上的用户请求会发送到链下的中间件当中,根据不同的服务请求,中间件在考虑gas消耗和声誉值信用的情况下选择最优的节点来满足服务请求,再将结果返回至链上,由链上被选择的该节点来提供此次服务的数据。总体上能够节约gas手续费的消耗,并且尽可能地避免具有恶意历史的节点再次对服务进行作恶的可能性。在下文将称为ORLM。
b)基于预言机节点信用量化的声誉值模型,能够帮助节点选择中间件更好地评判一个节点的信用和作恶的可能性。
c)基于深度强化学习DQN,本文将不同节点不同服务以及节点各自的声誉值定义为马尔可夫决策过程。在gas和动态的声誉值信用的情况下能够快速地进行决策,针对不同的服务为其选择衡量安全性和手续费消耗下最优的节点。
1 研究现状
学界针对预言机节点选择优化的相关研究大致分为安全和性能这两个方向。从安全性方面来说,为智能合约提供未被窜改的精准的链下数据。根本问题在于无论是中心化还是去中心化的预言机系统,预言机节点在链外所获取的信息都是中心化的,并不具备区块链所具有的通过共识算法来保证数据安全的特性,因此存在被攻击或者恶意操控的可能性。这个时候就需要构建一个相对安全的预言机系统在预言机节点发送的数据被智能合约执行之前,筛选出不作恶的节点或者保证发送的数据的准确性。Pasdar等人[15]提出了基于声誉值和基于投票的预言机,由用户组成一组投票者或者验证者,双方进行质押之后来对数据的正确性进行验证。结果正确的一方将会分配失败一方的质押来作为奖励。Chainlink[16]是链上著名的去中心化预言机,它通过多个预言机提供的数据进行比较后聚合,聚合采用不同的方法,例如选择中位数、平均值或加权平均值作为最终结果,来防止恶意数据的提供,并且通过数字签名来保证数据来源的真实性,防止在传播的过程中出现数据窜改的情况。在性能方面,提供相同服务的预言机节点存在信用、成本以及时延之类具有差异的数值,如何在考虑这些数值的情况下帮助用户选择需要服务的最优节点,便是关于预言机性能方面的问题。Almi’Ani等人[17]提出了一种基于图的分析方法来确定区块链预言机的可信度,以预言机的数据有效性和准确性的累计平均差异作为边的权重,以此来区分值得信赖的预言机,并且该方案在链上及链下都可以进行实现。
Goswami等人[18]转换并证明区块链节点选择问题是一个NP难问题,并提出了一种启发式算法来解决该NP难问题。尽管Goswami所构建的NP难问题当中也同时考虑了gas的消耗以及其他相关成本问题,但这些成本大多数会随着链上网络状况以及用户使用情况而变动。因此该算法对于长期维持预言机节点选择的鲁棒性并不乐观。Taghavi等人[19]提出了一个基于链上的多臂老虎机算法的预言机节点选择策略,在权衡预言机消耗和信用值的情况下选择最优的预言机节点,并将恶意行为的可能性降至最低。但该多臂老虎机通过智能合约来进行模型的构建并对预言机作出选择。尽管很大程度上保证了模型的安全性和不可窜改性,但每次和模型交互都需要通过智能合约来进行计算,这在速度和成本上的牺牲都过高。在Taghavi等人[19]的模型的基础之上,考虑gas消耗和信誉值的同时,本文将决策节点选择的模型移至链外。通过DQN算法结合链上信息训练出的模型和链上合约进行交互[20],帮助用户进行节点的选择,以在保证安全性的同时,节省更多的链上资源且响应更快。
强化学习是一种通过智能体与环境不断交互、不断试错,以达到在不同环境中选择最佳行动并最大化期望的行为策略方法。 强化学习的过程属于马尔可夫决策过程(MDP),通常将MDP用一个六元组进行定义(S,A,P,R,γ,done)。其中:st∈S是状态集,表示智能体在t时刻的状态;at∈A是动作集,表示智能体在t时刻进行的动作;P(st+1|at,st)表示在st状态之后执行到st状态的概率;r∈R是及时奖励,表示智能体在t时刻所获得的奖励;γ是折扣函数,当γ→1时,该智能体会更加关注未来的一个总体奖励,当γ→0时,智能体只会更加关注当下的一个奖励;done代表环境的终止状态。
目前强化学习主要可分为基于价值和基于策略两种方法。其中,Q-learning是一种著名的基于价值的强化学习算法。该算法通过构建一个表格,将状态和动作进行关联,以表示在不同状态下执行不同动作所产生的Q值。通过选择具有最高Q值的动作来进行决策。
Q(s,a)=r+γmaxQ(s′,a′)(1)
Q值的更新如下:
Q(s,a)←Q(s,a)+a[r+γmaxQ(s′,a′)-Q(s,a)](2)
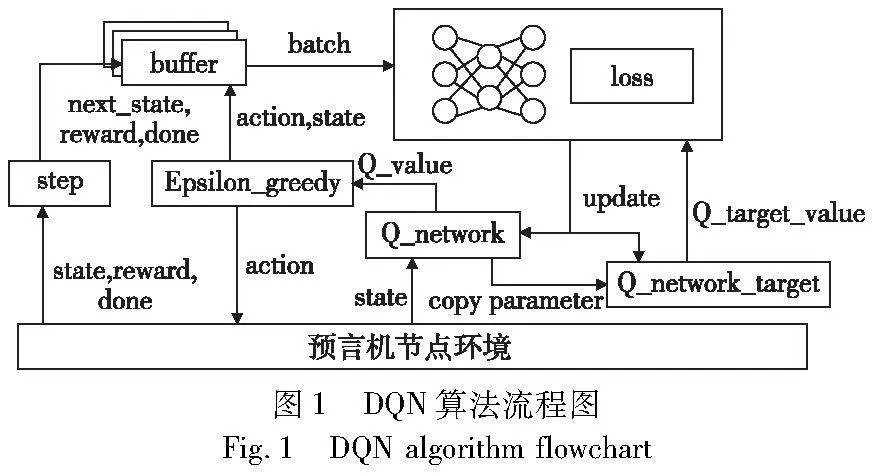
在深度强化学习中[11],DQN[21]是一种结合了Q-learning和深度神经网络的算法,它是一种基于离线策略的方法。如图1所示,DQN的核心是利用神经网络来近似Q值函数的计算。在DQN中有两个神经网络结构,即Q_network和Q_network_target,它们具有相同的网络结构,但参数b不同。Q_network的参数会复制到Q_network_target当中,实现目标网络的更新。
每次模型训练神经网络时,DQN会从经验回放缓冲区中随机采样一个批次的数据进行梯度下降。这种经验回放能够满足独立假设,与直接从环境中交互获取的数据不同,环境中直接交互而来的数据会使神经网络拟合到最近训练的数据上,从而导致在训练过程中倾向于过度拟合最近的训练样本,忽略之前的经验。而采用经验回放可以解决这一问题。
DQN使用均方损失函数计算当前Q值和目标Q值之间的损失,并通过反向传播和梯度下降算法来更新神经网络的权重,以最小化损失值,使得Q值逼近目标Q值。
Loss=(r+γ max Q(s′,a′)-Q(s,a))2(3)
2 ORLM介绍
2.1 ORLM架构
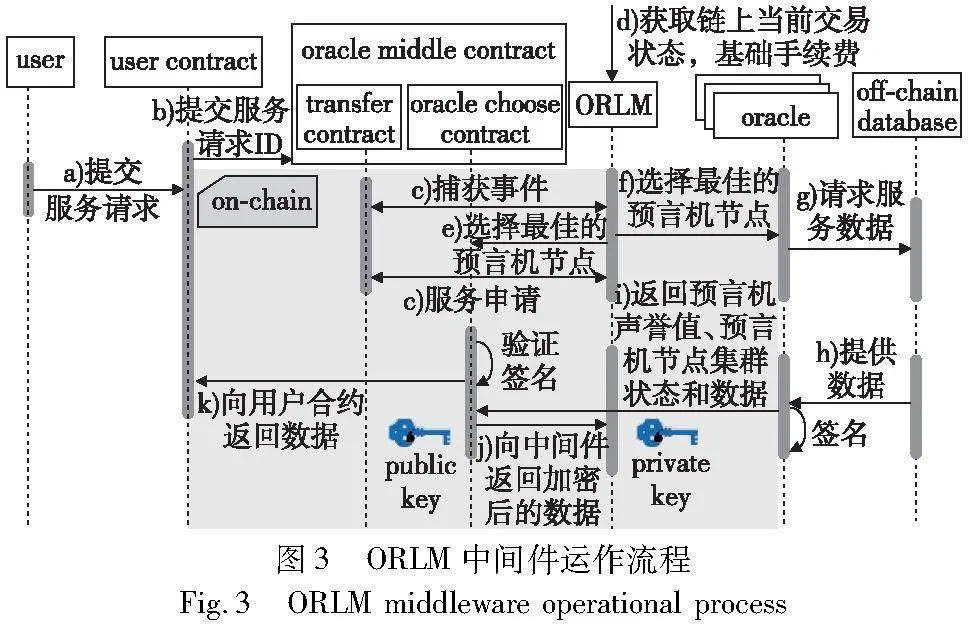
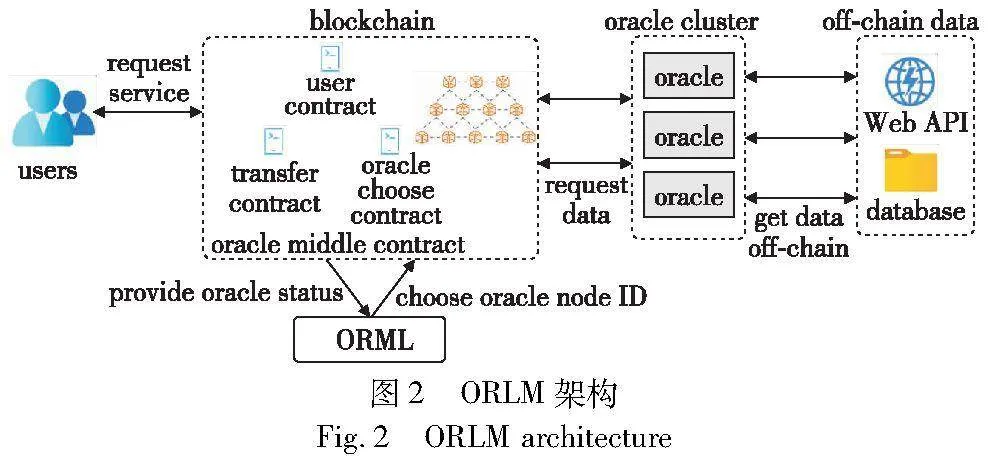
图2展示了链上预言机的架构,包括预言机合约和预言机集群两个部分。预言机合约作为一个中间桥梁,集合了相关数据预言机提供商的节点地址,并且保存了预言机节点的密钥对,以防止数据在传输过程中被窜改。用户合约只需要向预言机合约提交自己需要的数据请求,预言机合约从自己集合的预言机节点地址中选择一个节点。预言机集群由众多预言机节点组成。这些预言机向链下获取链外数据,并将数据返回给用户合约。然而,相同服务的不同预言机节点消耗的gas是存在差异的,并且提供的数据不一定全是可以完全信任的。为了解决这些问题,本文提出了ORLM模型的区块链预言机合约中间件架构,在图3中,该中间件的运作流程包括以下步骤:
a)用户参与到用户合约中。b)该用户合约向预言机中间件合约提交自己所需数据的服务需求,将请求服务的类型用ID进行表示,起到一个索引的作用。c)当需要数据的服务请求发送到预言机中间件的智能合约中后,由ORLM在链下对该智能合约服务请求序列的事件(event)进行抓捕,用来获取该合约队列中最新的需要的预言机服务;并且通过智能合约的事件进行抓捕,能够保证请求的顺序,使用户对预言机进行请求的顺序和ORLM根据服务进行预言机节点选择的顺序是相同的。ORLM通过基于DQN的深度强化学习算法,将整个预言机集群的状态转换成一个马尔可夫决策过程,并基于声誉模型的信用值和gas消耗找到一个能提供该服务的最优节点。d)ORLM需要获取该预言机所在链上的基础gas值,基础gas值对于不同的链和该链不同段的交易量会产生不同的数值,这将作为不同预言机节点不同服务的差异性之外的基础数值。减掉basic gas的基础数值,对于ORLM,能使模型gas消耗更加敏感,从而更好地在不同状态下探索到每种服务的最优选择。e)在选择最优的节点之后,该节点将被返回给预言机中间件合约,将选择的节点再返回给预言机中间件合约,由该合约对预言机节点群组进行选取。f)预言机节点在获取到请求之后。g)会从链上调用链下的数据。h)调用数据之后,再将数据发送到链上合约之前,预言机会对即将要发送的数据进行签名,这是为了防止在数据传输的过程当中出现数据被窜改或者替换的情况。之后将调用后的预言机声誉值更新并将预言机当前的状态返回给预言机合约。i)由预言机中间件合约验证签名以及判断数据真实性和是否作恶之后,将相关数据通过公钥进行加密,以密文的形式返回给ORLM模型,ORLM得到数据之后再通过私钥进行解密,以保证传输过程当中数据的安全性。j)帮助ORLM中的模型进行及时更新,ORLM会动态地进行预言机选择决策权重的更新。k)预言机中间件合约会将从预言机节点获得的数据传送给用户调用的合约,完成本次服务的请求。
2.28lzDw/0Qqp/gzKH2vg9uKA== ORLM模型介绍
区块链预言机节点选择是一个序贯的过程,因为gas值会根据链上交易的网络情况进行波动,且调用次数的多少会导致预言机节点之间信用的相对排序产生变化。本文将预言机节点之间的选择问题转换成马尔可夫决策过程,其中包括状态空间、选择空间和奖励函数,以及为了避免恶意节点的声誉值模型。预言机节点选择的优化问题为
其中:w1和w2是gas消耗和信用值之间的权重;Gij是第j个预言机节点中的第i个服务所消耗的gas;Gbasic为该链目前网络状况所产生的费用;Cj是第j个节点的信用值,信用值越高代表该节点作恶的可能性越小。
2.2.1 状态空间
假设系统中拥有n个已知的预言机, j∈{1,…, j},并且每个预言机都同时提供i种服务,那么对应的预言机i服务就表示为ji,Gji表示j节点对应的i服务所需要消耗的gas。状态函数为St,由于这里的t表示不同时间的状态,但在链上不同状态的时间难以统一量化,所以t表示每次节点进行选择的次数。状态的表示为
St={Gij,Cj}(5)
2.2.2 动作空间
ORLM可以进行的动作空间是A,但这只是该模型在面对每个St状态时可以进行的动作空间,每次进行动作选择的时候还要受限于当时选择的服务和预言机节点的数量,要在特定的服务i中进行动作ai的选择。
A∈{a1,…,aj}(6)
2.2.3 奖励函数
ORLM模型会从两个方面来权衡节点的选择:一个是当前预言机n面对K服务所需消耗的gas,gas消耗得越少,预言机就更应该对该节点进行选择;另一个则是不同节点的声誉值信用,这表示一个节点的历史信用,通过该声誉值模型,能够更好地了解该节点的信用以及是否进行作恶、数据准确和及时提供的可能性。因此本文设置了两个权重w1和w2来调整gas消耗以及节点之间对于奖励函数的比例。奖励函数如下:
R=-w1×Gij+w2×Cj(7)
以上是没有节点作恶或者节点提供的数据实时性准确的情况下的奖励函数,当该节点提供的数据被判定为无效或者作恶的情况下,奖励函数如下:
其中:Pr和PC分别对应的是对奖励值的惩罚和对该节点信用的惩罚。PC是一个动态数据,总的来说,如果节点声誉值信用越高,那么该PC的数值就会越大。这样设计的初衷是因为声誉值信用越高的节点被选择的概率也会越大,所以需要较大的惩罚才能有效地降低该节点作恶后再次被选择的概率。
2.2.4 声誉值模型
声誉值可以表示一个预言机节点的历史信用和该节点作恶的可能性。本文分下面两种情况进行声誉值的介绍。一个是节点的历史信用节点,每次对一个节点进行请求,该节点的信用就会进行一个常数H的线性固定增长,但对于奖励函数来说,常数H的线性增长会导致奖励函数对于信用的比重增加,导致奖励函数对于gas消耗不敏感,因此本文提出Cj为该节点的信用值,T为该节点被调用的次数,这样能够避免信誉值奖励函数爆炸,从而影响模型对于gas变得不敏感的情况。并且,如果该节点作恶或者发送了不准确的数值,除了对奖励函数进行惩罚之外,本文还对该节点的声誉值信用进行减少。
2.3 探索策略设计
强化学习在与环境进行交互的过程当中,完全的贪婪算法在每一时刻采用期望奖励估值最大的动作,而没有探索。利用ε-greedy贪心算法能够在期望奖励估值最大的时候,同时对环境进行随机探索。在传统的ε-greedy贪心算法当中,ε值是固定的,如果它设置得过高,会导致模型在最优的情况下依然对周围环境进行随机探索,可能会触发之前已经有恶意历史的预言机节点,并且让已经训练好的神经网络模型拟合困难。如果这个值太小,会导致模型对于环境的探索不充分,陷入局部最优,错过当前情况下的更优解。面对本文的实际情况,理想情况下,模型对预言机节点在早期的训练探索阶段进行充分的探索,而在充分探索过后,应该逐渐降低ε的值来帮助模型更好地进行收敛。因此本文采用根据训练回合而进行动态调整的ε-greedy方法。训练早期进行充分的探索,在训练达到一定的次数之后,ε值开始降低,减少探索的概率,以此来帮助神经网络更好地进行收敛。ε-greedy改进后的公式如下:
T为训练次数,当T<M时,此时的ε 为自定义的一个常数,当T>M之后,ε 会随着训练次数进行动态衰减。
2.4 ORLM的智能体训练
算法1 DQN训练算法
本文通过上述算法来进行智能体的训练,训练开始前需要初始化用于训练神经网络的经验回放buffer,用于存放智能体在环境中进行交互产生的经验样本,每回合训练开始前需要消耗所有节点的gas以及重置该节点的声誉值信用。
算法刚开始阶段,当buffer中存储的经验还没有达到一定数目时,智能体通过与环境交互来进行学习,根据ε-greedy执行动作,在动作执行完成之后,不断地将交互产生的(st, at, rt,it)以及执行完动作产生的st+1等经验存入经验回放buffer当中。在buffer存储了足够多的数据之后,从中随机取出小批样本用来训练神经网络。计算每个样本的TD差,之后对网络执行梯度下降法,每隔W步之后将Q_network的参数更新到Q_network_target中去。
3 仿真实验
由于并没有查找到相关链上数据及测试集,本文在本地进行预言机模拟。在实验中,本文参考文献[19],假设每个预言机节点被选择的消耗是固定的,并且呈正态分布,平均值为0.54,标准差为0.17。为了模拟针对不同节点预言机中间件的节点选择情况,本文模拟了三种不同的服务。通过请求不同的服务来观察ORLM预言机中间件对于不同服务的节点选择情况,且在每回合中,每个服务的请求数量都是平均的。
对于用户请求的响应速率而言,此次实验通过本地快速模拟一条链来和模型进行交互,从而仿真该模型收到的用户合约请求,将这个请求发送给模型后,模型再作出决策发送到链上的时间,通过Ganache工具部署一条本地的链,并在上面部署预言机的测试合约。本实验忽略了链的出块时间,设定为有交易就及时出块,每次请求的仿真结果均小于1 s,平均值为0.443 s。相比于目前主流的链的出块时间,这个速度并不会给用户造成延迟体验。
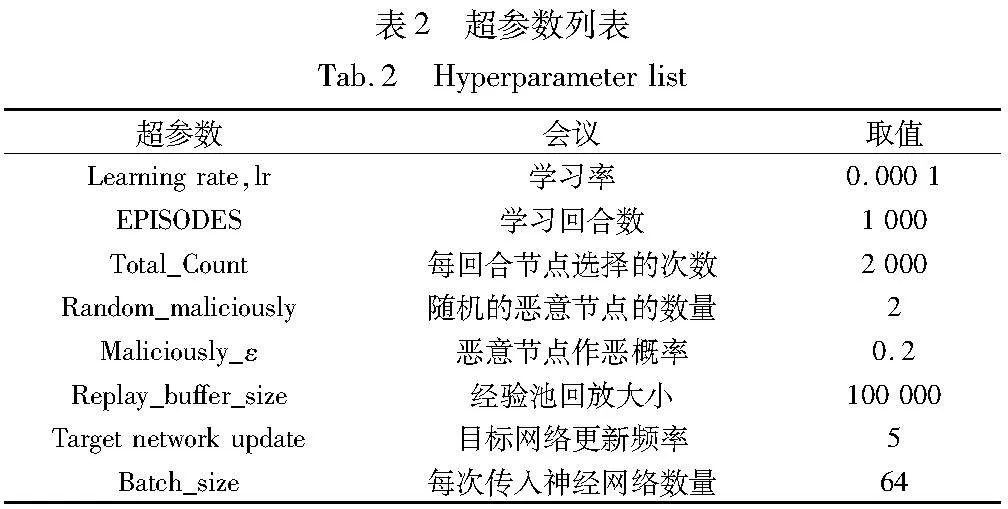
更多的实验数据如表1、2所示。在实验中随机加入两个节点来模拟链上预言机将数据判断为恶意或不准确的情况。在该仿真实验中,当预言机选择该节点的任何服务时,该节点触发时,有Maliciously_ε的概率被判定为恶意的,从而模拟ORLM模型面对恶意节点时的处理情况和后续选择。
3.1 对比策略
本文分别采用DDQN[22]算法、随机分配算法、DQN算法,以及基于贪婪策略的多臂老虎机算法[19]来模拟链上的预言机节点选择。从以下三个方面来评估该中间件面对预言机节点选择的性能:
a)不同算法每回合的选择总和所消耗的全部gas;
b)在每回合的节点选择中,三种服务选取总数是平均的,观察每种服务在每回合中所消耗的gas;
c)每回合中触发恶意节点的次数,以此来展示面对具有恶意行为历史的节点的选择情况。
在实验过程中发现,通过调节折扣函数能够明显改变ORLM模型的训练结果,因此选取折扣因子为0.9、0.5及0.1进行对比。
3.2 测试
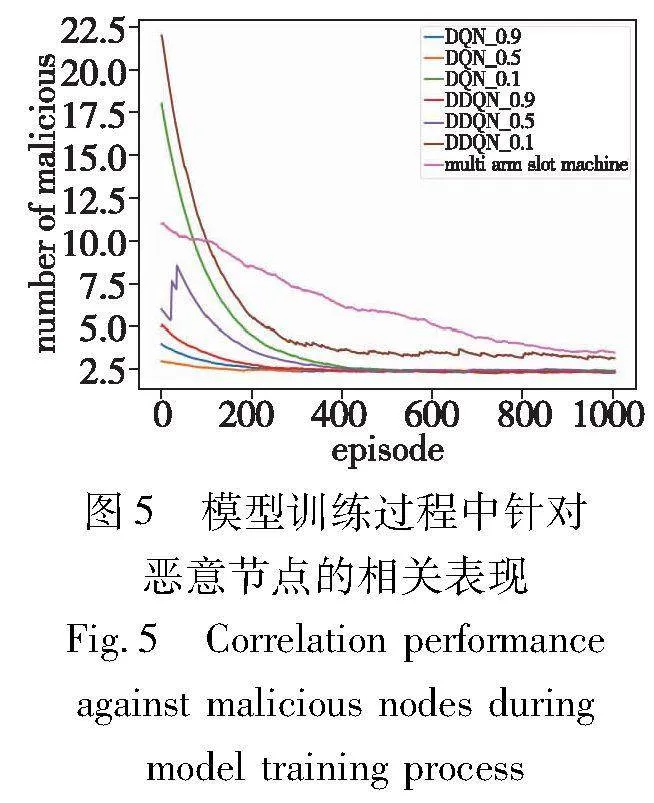
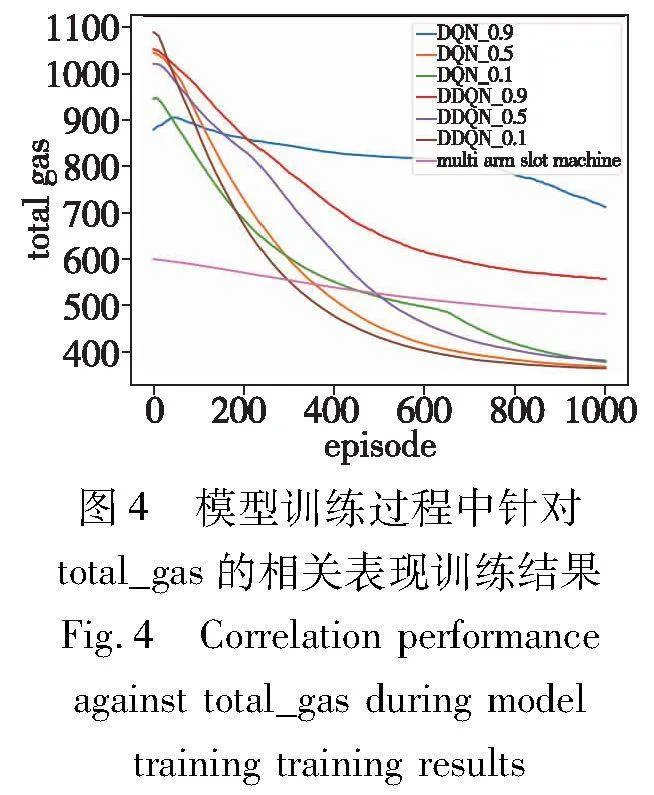
模型训练过程中针对total_gas的相关表现训练结果、针对恶意节点的相关表现如图4、5所示。
图4中横坐标为训练的回合数,纵坐标为每回合中所消耗的gas的总量。从实验中可以明显看到,较高的折扣因子并不能很好地得到最优的决策。从gas总体消耗对比来说,折扣因子为0.5和0.1时,都表现出了较好的针对gas较少的节点进行选择的决策,但在恶意节点的数目当中,折扣因子为0.1和0.5产生了差别。可以从图5中看到,DDQN折扣因子为0.1时,直到训练结束,对于恶意节点的触发次数仍然高于其他的对照组,而DQN为0.1时,对于恶意节点的触发次数则下降得比其他对照组更缓慢一些。这样的原因是当对未来考虑较低的时候,模型决策本质上更接近于贪婪决策,更偏向于考虑当前情况下能获得奖励最大的决策,因此触发恶意节点的概率相对折扣因子为0.5和0.9的模型来说要大一些。基于贪婪算法的多臂老虎机在与DQN和DDQN[22]的对比中可以看到,多臂老虎机算法一直在更新优化自己的决策,初始开始时,在多臂老虎机遍历完所有的行为动作之后,能够找到相对于DDQN和DQN在gas消耗方面更优的决策。但在数量相对庞大的预言机节点和服务当中,相比DDQN和DQN算法,其向着更优决策的速度相对更为缓慢一些。
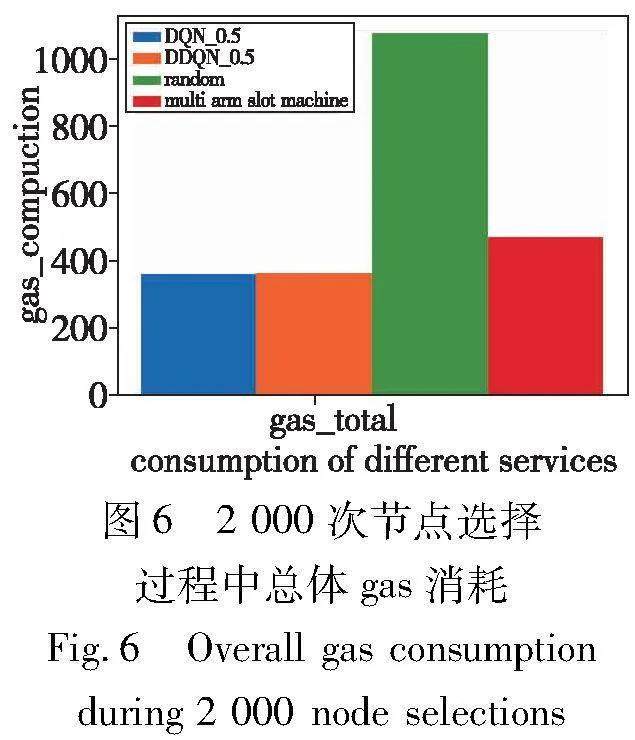
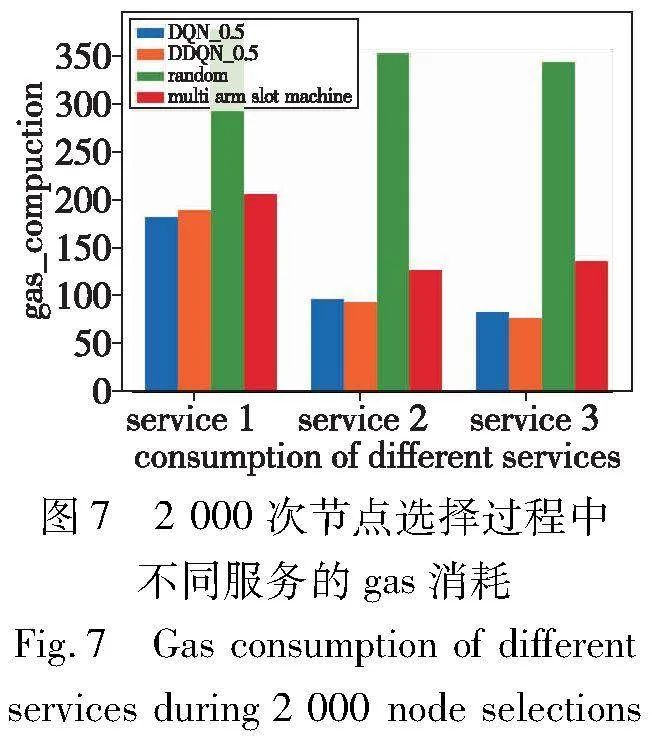
在环境中进行测试,由于在之前的实验中已经确定了折扣因子为0.5在预言机整体决策上具有更好的效果,所以本文列举出了DQN_0.5、DDQN_0.5、随机分配算法以及多臂老虎机算法来进行总体gas消耗和不同服务的预言机进行2 000次选择的gas消耗对比,如图6、7所示。三种服务被请求的次数是平均的。
从图6中可以看到,DQN和DDQN模型在1 000回合的训练之后,总体消耗gas相差不大。在当前平均数0.51,标准差0.17的预言机节点环境下,只占了随机分配算法所消耗的gas的33%左右,相较于多臂老虎机,只占了该算法消耗的77%左右。从图7可以看出,在相同服务的请求下,service 1的差异较小,DQN和DDQN算法只占随机分配算法和多臂老虎机算法的50%和90%左右,service 2和service 3的差异较大。
4 结束语
本文提出了链下的区块链预言机节点选择的深度强化学习中间件,基于DQN算法,用深度强化学习的中间件获取链上的数据,将预言机节点决策的问题抽象成为了一个马尔可夫过程,根据不同的服务需求通过模型抉择后,帮助链上的预言机合约进行最优的节点选择,进而优化了预言机中间件合约的消耗和性能问题。实验结果表明,通过深度强化学习的模型相对于链上随机进行分配和基于贪心算法的多臂老虎机性能有较大的提升。由于时间和精力有限,本文在研究中还存在以下三个可以进一步改进的地方:a)服务的类型过少,可以探究更多服务下深度强化学习在预言机节点集群中的选择效果;b)去中心化不足,因为本模型是基于链下进行的中间件,该中间件的去中心化性还有待商榷;c)可以尽可能地尝试更多的深度强化学习模型(如DQN的其他变体,TRPO、PPO等)。
参考文献:
[1]Novo O. Blockchain meets IoT: an architecture for scalable access management in IoT [J]. IEEE Internet of Things Journal,2018,5(2): 1184-1195.
[2]Xie Yi,Zhang Jiayao,Wang Honglin,et al. Applications of blockchain in the medical field: narrative review [J]. Journal of Medical Internet Research,2021,23(10): e28613.
[3]Pournader M,Shi Yangyan,Seuring S,et al. Blockchain applications in supply chains,transport and logistics: a systematic review of the li-terature[J]. International Journal of Production Research,2020,58(7): 2063-2081.
[4]Hassan N U,Yuen C,Niyato D. Blockchain technologies for smart energy systems: fundamentals,challenges,and solutions [J]. IEEE Industrial Electronics Magazine,2019,13(4): 106-118.
[5]Wang Yanhua,Liu Heming,Wang Jianhua,et al. Efficient data interaction of blockchain smart contract with oracle mechanism [C]// Proc of the 9th IEEE Joint International Information Technology and Artificial Intelligence Conference.Piscataway,NJ:IEEE Press,2020:1000-1003.
[6]Caldarelli G. Real-world blockchain applications under the lens of the oracle problem: a systematic literature review [C]// Proc of IEEE International Conference on Technology Management,Operations and Decisions. Piscataway,NJ: IEEE Press,2020: 1-6.
[7]Woo S,Song J,Park S. A distributed oracle using Intel SGX for blockchain-based IoT applications [J]. Sensors,2020,20(9): 2725.
[8]Adler J,Berryhill R,Veneris A,et al. Astraea: a decentralized blockchain oracle [C]// Proc of IEEE International Conference on Internet of Things (IThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber,Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData). Piscataway,NJ: IEEE Press,2018: 1145-1152.
[9]Cai Yuxi,Fragkos G,Tsiropoulou E E,et al. A truth-inducing sybil resistant decentralized blockchain oracle [C]// Proc of the 2nd Conference on Blockchain Research & Applications for Innovative Networks and Services. Piscataway,NJ: IEEE Press,2020: 128-135.
[10]Li Yuxi. Deep reinforcement learning: an overview [EB/OL]. (2018-11-26). https://arxiv.org/abs/1701.07274.
[11]刘全,翟建伟,章宗长,等. 深度强化学习综述 [J]. 计算机学报,2018,41(1): 1-27. (Liu Quan,Zhai Jianwei,Zhang Zongzhang,et al. A survey on deep reinforcement learning [J]. Chinese Journal of Computers,2018,41(1):1-27.)
[12]阎世宏,马为之,张敏,等. 结合用户长短期兴趣的深度强化学习推荐方法 [J]. 中文信息学报,2021,35(8):106-117. (Yan Shihong,Ma Weizhi,Zhang Min,et al. Reinforcement learning with user long-term and short-term preference for personalized recommendation [J]. Journal of Chinese Information Processing,2021,35(8):106-117.)
[13]刘建伟,高峰,罗雄麟. 等. 基于值函数和策略梯度的深度强化学习综述 [J]. 计算机学报,2019,42(6):1406-1438. (Liu Jianwei,Gao Feng,Luo Xionglin,et al. Survey of deep reinforcement learning based on value function and policy gradient [J]. Chinese Journal of Computers,2019,42(6):1406-1438.)
[14]逄金辉,冯子聪. 基于不确定性的深度强化学习探索方法综述 [J]. 计算机应用研究,2023,40(11): 3201-3210. (Pang Jinhui,Feng Zicong. Exploration approaches in deep reinforcement learning based on uncertainty:a review [J]. Application Research of Computers,2023,40(11): 3201-3210.)
[15]Pasdar A,Dong Zhongli,Lee Y C. Blockchain oracle design patterns [EB/OL]. (2021-06-17). https://arxiv.org/abs/2106.09349.
[16]Breidenbach L,Cachin C,Chan B,et al. Chainlink 2.0: next steps in the evolution of decentralized oracle networks [J]. Chainlink Labs,2021,1: 1-136.
[17]Almi’Ani K,Lee Y C,Alrawashdeh T,et al. Graph-based profiling of blockchain oracles [J]. IEEE Access,2023,11: 24995-5007.
[18]Goswami S,Danishan S M,Zhang Kaiwen. Towards a middleware design for efficient blockchain oracles selection [C]// Proc of the 4th International Conference on Blockchain Computing and Applications. Piscataway,NJ: IEEE Press,2022: 55-62.
[19]Taghavi M,Bentahar J,Otrok H,et al. A reinforcement learning model for the reliability of blockchain oracles [J]. Expert Systems with Applications,2023,214: 119160.
[20]Salah K,Rehman M H U,Nizamuddin N,et al. Blockchain for AI: review and open research challenges [J]. IEEE Access,2019,7: 10127-10149.
[21]Mnih V,Kavukcuoglu K,Silver D,et al. Human-level control through deep reinforcement learning [J]. Nature,2015,518(7540): 529-533.
[22]Van Hasselt H,Guez A,Silver D. Deep reinforcement learning with double Q-learning [EB/OL]. (2015-12-08). https://arxiv.org/abs/1509.06461.
