市民热线智能化系统中大数据技术的应用探析
2024-07-24冯景森

摘要:大数据技术的不断发展和广泛应用,正在对各个领域的发展产生着深刻的影响。为了更准确及时地了解市民的诉求,需要提高市民热线系统效率,提高系统的服务质量,可以利用大数据的技术,让系统更加快捷地辅助话务人员来处理市民诉求。本文通过市民热线系统来介绍大数据技术在软件系统中的应用,来分析有关大数据模型的构建方法,从而更深的理解大数据技术,为应用大数据的信息化系统建设提供更多的参考案例。
关键词:大数据;市民热线系统;智能推荐;Python
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2024)17-0082-03 开放科学(资源服务)标识码(OSID) :
0 引言
市民热线系统也是指“12345 市长热线电话平台”,是用来帮助诉求人解决生活、生产中所遇困难和问题,是市委、市政府关注民生、倾听民意的平台。市民通过市民热线反馈的数据,或者微信公众号、微博等多渠道反馈数据,系统将转入为文本类型的工单数据,对于这些数据具备:1) 话务量大,数据沉积丰富;2) 信息来源渠道多;3) 数据复杂,数据维度多等特点。但同时这些数据具有价值高的特点,因为该热线是全市人民反馈日常问题的最直接窗口,其所收集到的问题也是市民日常所最关心的事件,因此其数据所包含的价值非常高,是各级领导有效了解市民心声的重要途径。因此需要采用大数据手段对工单数据进行深度分析挖掘,协助坐席工作人员更加高效地处理工单,以便及时准确地向市领导及各部门提供分析结果,为城市管理决策提供辅助支撑。
1 市民热线系统的大数据技术应用场景介绍
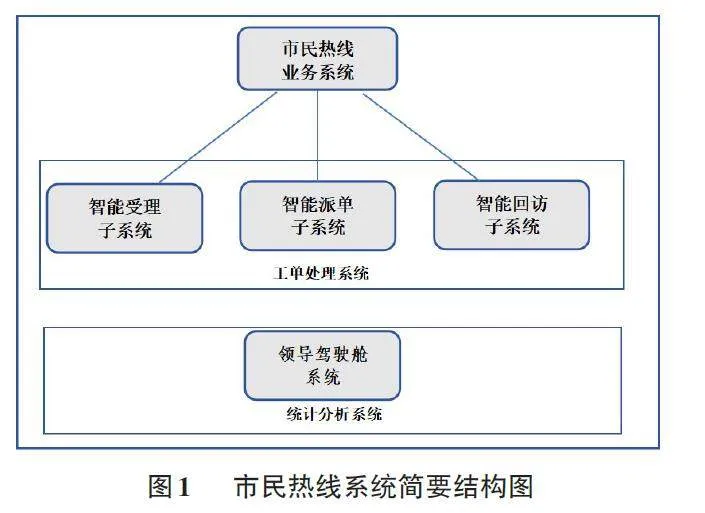
由于市民热线系统所包含的工作职责复杂,需处理工单数量多、内容杂,在实际的业务工作中,严重依赖业务人员以人工的方式处理各类工单,造成业务人员培训成本高、效率低、处置标准不一致等问题。针对于以上问题,我们对已有系统进行升级改造,对原有单一的工单管理系统升级为智能受理子系统、智能派单子系统,智能回访子系统及领导驾驶舱系统等。结构如图1所示。
1.1 智能受理子系统
在智能受理子系统中,实现坐席员接听市民电话时智能填写工单的相关功能。通过智能地址校准、智能问题分类推荐、智能承办单位推荐与历史工单查询等功能,为话务人员进行服务引导,方便坐席准确受理、填报诉求[2]。在此子系统中,我们建立了“问题分类推荐”模型,主要是通过KMeans聚类分析方法,对已有的历史工单自动进行语义分析并归类,该模型具备学习特性,可通过循环训练实现对工单的理解和分析。从而对工单作出准确的推断,实现对工单不同维度的归类。
1.2 智能派单子系统
在该子系统中,实现工单承办单位智能推荐功能,结合历史工单分析、诉求分类类别、诉求问题点位等关键信息内容系统自动提示推荐承办单位。该功能实现基于系统建立的“承办单位匹配模型”,可智能推荐高匹配度的处置部门,协助区中心派单人员进行高效、精准地派单。
1.3 智能回访子系统
智能回访子系统主要功能包括多渠道回访功能、自动回访功能等。实现回访标准管理功能,对回访内容进行设定,如办事人员是否与您联系、是否解决问题、您是否满意等;实现回访渠道管理功能,支持语音回访、短信回访、微信回访等回访渠道配置功能;实现自动回访管理功能,支持将已办结工单自动设置回访次数、回访时间,到指定时间自动发起回访。实现回访分派管理功能,支撑按办结时间、按承办单位、按来源渠道、按问题分类进行回访任务的分派,提高回访效率,增强群众满意度。该系统中建立了“回访内容推荐”模型,此模型根据诉求内容来自动抽取时间、关键词等,组成言简意赅的回访内容,根据工单来源途径对诉求人进行相应渠道的回访,通过模型推荐的回访内容,能让诉求人准确地定位到相应的诉求工单。
1.4 领导驾驶舱系统
以图表结合的形式清晰地、生动直观地展示各种指标,展示选定时间段内的市民反映的各类问题、数量、区域等。通过多维度、多视角地分析数据,形象化、直观化、具体化实时反映市民的各种问题,辅助领导决策支持。领导驾驶舱的各项展示指标能够通过系统的计算,让在线流动的数据反映真实问题,为各级领导的决策指挥提供准确的依据[3]。
2 市民热线系统应用大数据技术的实现过程
2.1 大数据分析系统开发环境
该系统采用Python编程语言,选用Python 3.11版本进行开发;借助VS code开发工具,提供代码编写、调试、测试等功能;利用Pandas数据处理工具,进行数据清洗、处理和分析;选用Git版本控制系统,用于管理和追踪代码版本;利用conda虚拟环境,管理Python 环境和包。
2.2 Flask 框架
Flask的设计理念是简单、轻量级和灵活,它提供了一些基本的功能和结构,但留下了足够的自由度,使开发者可以根据自己的需求进行定制。程序员可以使用Python语言的Flask框架快速实现一个Web服务。各模块以Flask/Python的设计理念,使用Flask提供的蓝图(Blueprints)来组织,便于将来改进和扩展[4]。在Flask框架中,路由用于将请求的URL映射到相应的视图函数,从而实现不同URL对应不同的处理逻辑。Flask 框架使用@app.route()装饰器来定义路由,其中参数为要映射的URL路径。Flask框架还支持通过request对象来获取请求参数、请求头、请求方法等信息,从而实现更复杂的请求处理。在市民热线系统的大数据处理的子系统中,需要根据请求内容提供相应的数据处理结果,应用到的场景业务并不是特别复杂,所以选用Flask这一轻量级框架,运用起来比较合适。
2.3 市民热线系统的“问题分类推荐”模型举例说明
市民热线系统的“问题分类推荐”模型的数据处理过程遵循大数据处理的几个步骤:1) 数据收集;2) 数据准备;3) 数据分析;4) 数据展现。以下作步骤详解。
2.3.1 数据收集
收集数据是训练模型的第一步,这一步需要收集与之相关的大量的多样的数据,数据的质量和多样性对训练的效果有至关重要的作用。在“问题分类推荐”模型中,我们将话务系统的历史工单数据的工单内容和对应的问题分类从线上库导出,然后作为该模型的训练数据源,主要为文本数据。这些文本在导出的过程中,依照要求筛选出高价值的字段信息,以保证数据的高价值的性质。这样,数据收集步骤就完成了。
2.3.2 数据准备
在将数据输入模型进行训练之前,一般需要对收集到的数据进行预处理,包括数据清洗,噪声去除等操作,以提高模型训练的准确性。大数据技术通过数据清洗、数据预处理和数据挖掘等技术,可以处理这些复杂的数据,并从中挖掘出有价值的信息[5]。此模型的开发中导入数据后,使用处理中文文本的jieba 库,来进行分词、去除停用词等操作,以此来根据需求来清洗处理历史工单数据,Python代码示例如下:
import jieba
import pandas as pd
# 读取历史数据
history_tickets = pd. read_csv(′historical_orders.csv′)
# 定义停用词列表
stop_words = [′的′, ′是′, ′和′, ′了′, ′有′, ′中′]
# 定义一个函数,用于去除停用词以此进行数据清洗
def preprocess_text_jieba(text):
# 分词
tokens = jieba.cut(text)
# 去除停用词
tokens = [token for token in tokens if token not in stop_words]
return tokens
# 提取问题文本和分类标签
questions = [ticket["question"] for ticket in his⁃tory_tickets]
categories = [ticket["category"] for ticket in his⁃tory_tickets]
# 对问题进行分词和去停用词处理:
all_questions = [preprocess_text_jieba(ticket["ques⁃tion"]) for ticket in history_tickets]
以上代码就清洗好了训练“问题分类推荐”模型的数据源。
2.3.3 数据分析
数据分析是该模型开发的重要环节,包括统计分析、数据挖掘和机器学习等技术。统计分析帮助揭示数据的分布、关联和趋势;数据挖掘可以从数据中发现隐藏的模式和关联规则;机器学习可以通过训练模型来预测未来的趋势和行为。首先将清洗过的数据源进行向量化表示,同时使用Python的Sklearn机器学习工具包构建TF-IDF向量矩阵[6]。然后根据数据特征,应用KMeans聚类方法,对数据进行分类。KMeans 聚类方法的原理是最小化每个数据点到其所属聚类的质心的平方距离之和。其中,TF-IDF,即词频-逆文档频率(Term Frequency-Inverse Document Fre⁃quency) ,是一种用于信息检索与文本挖掘的常用加权技术[7]。它通过统计一个词在文档中的出现次数以及在整个文档集合中的出现情况,来评估一个词对于一个文档集或一个语料库中的其中一份文件的重要程度。TF-IDF向量矩阵是一种将文本数据转换为数值形式的方法,以便可以使用机器学习算法进行处理。在TF-IDF向量矩阵中,每个文档都被表示为一个向量,向量的每个维度对应于文档集合中的一个词。向量的值通常是该词在文档中的TF-IDF值。
下面是实现该过程的Python代码示例:
from sklearn. feature_extraction. text import Tfidf⁃Vectorizer
from sklearn.cluster import KMeans
# 使用 TF-IDF 进行特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(questions)
# 使用 K-means 算法进行聚类
kmeans = KMeans(n_clusters=len(set(categories)))
kmeans.fit(X)
# 指定的问题
specified_question = "网络连接"
# 使用指定问题进行预测
specified_question_vector = vectorizer. transform([specified_question])
predicted_cluster = kmeans.predict(specified_ques⁃tion_vector)[0]
# 根据预测结果推荐问题分类
recommended_categories = [categories[i] for i, label in enumerate(kmeans.labels_) if label == predicted_clus⁃ter]
# 打印指定问题的推荐出的问题分类名称
print("推荐的问题分类是:", recommended_catego⁃ries)
2.3.4 数据展现
在数据分析完成后,我们需要将问题推荐的结果以Json的格式返回给业务系统,然后业务系统将结果展现到用户的坐席页面上,坐席根据推荐的问题分类选项来选择合适的问题分类进行工单录入。我们将以上代码,通过Flask框架进行封装,并做一个API的访问接口,支持页面与分析模型进行交互。其中,Flask的路由(Routing) 用装饰器(如@app.route) 来定义URL路由和处理函数(视图函数)之间的映射关系。这使得开发人员可以定义如何响应特定的URL请求。Flask提供了处理HTTP请求的功能,包括获取请求数据(如查询参数、表单数据、JSON数据等)、处理请求头、处理文件上传等。Flask的 响应处理允许开发人员自定义响应,包括设置响应状态码、添加响应头、返回JSON、XML 或其他格式的数据等。在Flask 框架中,蓝图(Blueprint) 是一种用于组织和管理应用程序组件的重要工具。蓝图允许开发者将大型应用程序拆分成多个小的、可重用的组件,从而使代码更加模块化、易于维护和扩展,使用蓝图(Blueprint) 来创建API可以使得代码结构更加清晰,并且有助于模块化地组织API接口路径。
代码实现如下:
首先,需要创建一个蓝图对象。蓝图对象通常被定义在一个单独的Python模块中,该模块负责处理与特定功能或模块相关的路由。假设方法名称为re⁃quest_classify。
from flask import Blueprint, jsonify
# Blueprint 构造函数接受两个参数:蓝图的名称以及蓝图所在的模块或包
q_c_blueprint=Blueprint(′question_classify′,__name__)
# 此方法的路由地址
@r_c_blueprint. route(′/classify/<String: question> ′,methods=[′GET′])
def classify(question):
# 这里是从以上代码封装好的名为question_cat⁃egories(question)方法中获取的问题分类。
categories= question_categories(question)
# 返回分析后的问题分类结果
return jsonify(categories) 接下来,需要在主应用文件中注册这个蓝图
from flask import Flask
from api.question_classify import q_c_blueprint
app = Flask(__name__)
# 注册蓝图,并指定URL前缀
app. register_blueprint(q_c_blueprint, url_prefix= ′/api′)
if __name__ == ′__main__′:
app.run(debug=True)
在app.py中,导入q_c_blueprint并使用app.regis⁃ter_blueprint()方法将其注册到应用中。url_prefix参数用于为蓝图中的所有路由添加一个公共的前缀,这在组织API时非常有用。
最后,运行Flask应用,定义好的API就会开始监听定义的路由。
python app.py
此时,问题分类的API可以通过访问http://local⁃host:5000/api/classify(或其他定义的路由)来访问了。模型分析后的相应结果,经过前端页面的渲染,就呈现在系统坐席的屏幕上,这就是数据展现的主要步骤。
在领导驾驶舱系统中,数据的展现要更加全面、直观。比如事件热力图、各类问题的数量及排名、反映区的数量及排名、每小时工单的频率等,都是以图表、地图等形式展现给用户,让使用者更容易看出各维度的数据变化和演变趋势,从而让决策者能够依据此数据对未来的相关诉求安排做出准确的判断。领导驾驶舱系统是一种将热线服务与城市治理、领导决策相结合的创新模式,通过数据驱动和智能分析,提高政府服务效率和市民满意度,推动城市治理体系和治理能力现代化。
2.4 市民热线系统的其他模型及应用
以上步骤提供了“问题分类推荐”模型的实现的示例过程,其实在开发实现中,要比以上示例复杂很多,比如数据清洗的维度、数据分词后的权重调整、数据模型参数的调整等。基于以上实现过程,我们还依次实现了智能派单子系统的承办单位匹配模型”,智能回访子系统的“回访内容推荐”模型以及领导驾驶舱系统的数据统计分析等。其中,有些数据模型应用了LangChain 编程框架,它帮助在应用程序中使用大型语言模型(LLM) ,LangChain可以将语言模型与其他数据源连接起来,使模型不仅能理解和生成文本,还能访问和利用其他类型的数据。通过大数据技术的应用,市民热线系统在业务处理上有了更多智能化的体验,让坐席能够更高效地处理工单,实现工单的快速处理和流转,也通过大数据统计分析,让数据更加丰富、直观、生动地展现在决策者的面前,让决策者对实时的数据有了更可靠的掌握,也对未来事态的发展的预测提供了依据。
3 结束语
大数据技术在市民热线系统的应用还远不止以上这些功能,随着大数据技术的广泛普及,热线系统中还能利用大数据技术的自然语言处理和机器学习技术,实现这一领域的智能客服机器人,减轻人工客服的压力;还可以对诉求的文本或者语音进行分析,判断诉求者的情感状态;还能通过对反映的问题进行深入分析,进行未来一段时间的呼叫量及热点问题作出预测,从而让政府更好的理解民意,制定有针对性的决策。因而,大数据技术在市民热线系统各场景中起着重要的作用。大数据技术在各行各业的发展及其应用的前景非常广阔,随着大数据技术在互联网各类系统中的应用,通过大数据的分析,企业可以更准确地挖掘市场趋势、客户需求等信息,从而做出更明智的决策;还能依靠它解决系统目前在业务流程中的瓶颈和问题,然后进行优化,从而改善用户的体验;未来随着技术的不断进步和应用场景的不断拓展,大数据将成为推动社会经济发展的重要力量。
参考文献:
[1] 冀冰.政务服务热线数据分析系统的设计与实现[D].石家庄:河北师范大学,2021:3-4.
[2] 更高站位更新理念更大力度更实举措辽宁12345热线平台完成升级改造[J].民心,2022(8):21-24.
[3] 张蔚文,金晗,冷嘉欣.智慧城市建设如何助力社会治理现代化?:新冠疫情考验下的杭州“城市大脑”[J].浙江大学学报(人文社会科学版),2020,50(4):117-129.
[4] 王译庆.Flask框架下成品油销售系统设计与实现[D].西安: 西安电子科技大学,2015.
[5] 何媛媛.大数据技术在工业经济统计中的应用[J].现代工业经济和信息化,2023,13(12):166-168.
[6] 曹树金,孙立宝,曹茹烨.基于文本和回归分析的中国城市科技创新发展的政策因素影响研究[J].科技情报研究,2023,5(3):49-66.
[7] 李阔.中国近代农业团体专题数据库系统的研究与实现[D]. 石家庄:河北师范大学,2020.
【通联编辑:王力】
