认知诊断模型研究综述
2024-07-24过珺

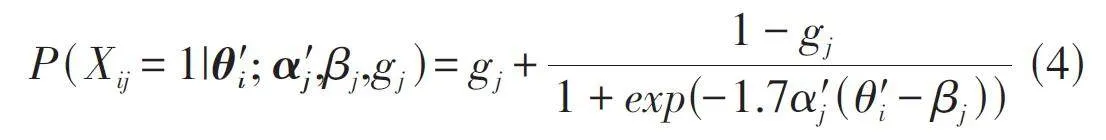


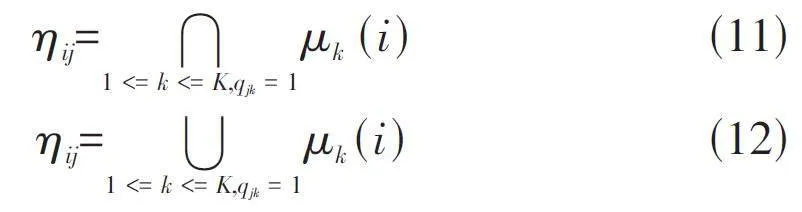
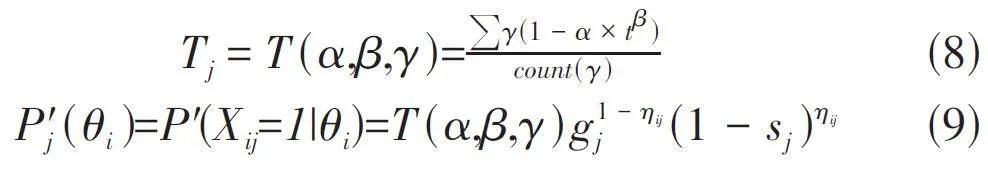
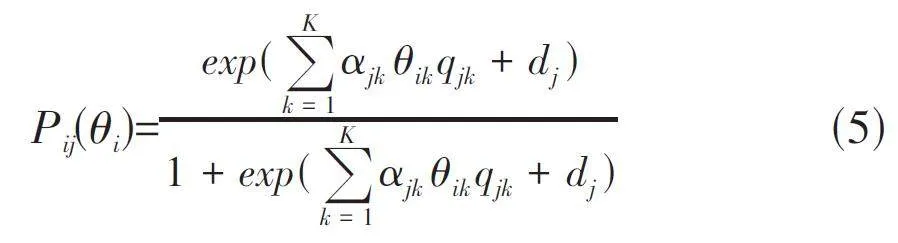



摘要:信息技术的发展,尤其是信息技术与教育的结合,使得教育领域一直提倡的因材施教成为可能。认知诊断通过分析学习者的学习数据,进而挖掘学习者的认知状态,为教师实施针对性教学提供支持。认知诊断的常规模型有传统模型、模糊诊断模型、基于神经网络模型和基于深度学习模型。文章首先对当前各类模型的常规算法及其优化算法进行了详细的阐述,然后总结了各类模型的优缺点,最后对未来可能的研究方向进行了预测。
关键词:认知诊断;IRT;DINA;Fuzzy CDF;神经网络认知诊断;深度学习
中图分类号:TP301 文献标识码:A
文章编号:1009-3044(2024)17-0001-05 开放科学(资源服务)标识码(OSID) :
0 引言
两千多年前,孔子提出了“有教无类,因材施教”的教育理念,而我们也一直在尝试如何能有效做到因材施教。在日常教学中,教师教学任务繁重,班级学生人数众多,教师利用常规的信息化手段已无法高效、准确地找出每个学习者的知识盲点,无法给予学习者精准化、个性化的学习指导。
随着信息技术的深入发展,数字技术已经成为引领未来的新支柱,数字与教育的结合,为目前教育中出现的困局,提出了新的解题思路。认知诊断通过分析学习者答题结果,挖掘学习者对题目所涉及的知识点的掌握情况,为教师在教学活动中实现针对性的辅导提供依据。
1 认知诊断概述
认知诊断是指对学习者认知过程、加工技能或知识结构进行的诊断和评估。可通过采集、分析学习者的测试数据,借助概率统计模型或机器学习算法,获得学习者在问题解决过程中所用到的知识技能,及其对知识技能的掌握状态[1]。随着人工智能的发展,认知诊断模型不断丰富,它的诊断精确度不断提升,应用场景不断扩大。认知诊断最开始仅限于线上学习的使用,但在“智学网”等一批线上学习平台在中小学进行推广使用后,平台的线上、线下数据有效结合、不断扩充,给线下教学提供了很好的数据支撑和教学依据;同时认知诊断的应用领域也从最开始的仅用于学习者的答题预测,到现在应用于对学习者认知状态的评估、对学习者学习心理因素的分析等。
目前认知诊断模型主要分为传统模型、模糊认知诊断模型和基于神经网络的认知诊断模型等。
2 传统的认知诊断理论
2.1 项目反应理论(Item Response Theory, IRT)
IRT是常用的单维连续型认知诊断模型,模型认为学习者对某一知识点的掌握程度可以用一种非线性函数来拟合,学习者对知识点的掌握程度是自身学习因素、试题区分度、试题难度等多因素共同影响的结果;模型中的单维,表示试题测量的是学习者的一种潜在特质;连续是指学习者能力值是连续型数据;该模型假设学习者对试题的作答结果服从独立同分布[2]。
当模型考虑试题的区分度、试题难度、试题的猜测度时,模型即变为三参数模型,如公式(1)所示。公式1表示学习者i 正确回答试题j 的概率。该理论根据参数的不同及其应用场景的变化,还有双参数模型和单参数模型。双参数模型为不考虑猜测系数时的函数状态,如公式(2)所示;单参数模型为不考虑猜测系数和试题区分度时的函数状态,如公式(3)所示。为了更好地对模型解释,模型所用参数的数学符号和含义如表1所示。
IRT实现了对学习者单个能力特质的诊断,但无法实现对学习者多个能力特质的测量。因此有学者将IRT理论进行多维度改进,即将学习者的能力值以向量的形式呈现。如公式(4)所示:
公式中θ'i =(θi1,θi2,θi3 ...θik )′表示学习者i 的k 维能力向量;α'j =(αj1,αj2,αj3 ... αjk )′表示试题j 的k 维区分度向量。
胡心颖[3]认为多维的IRT理论依然无法将学习者的能力与具体的知识点一一对应,因此她将Q矩阵引入模型,使得改进后的IRT模型实现了对学习者具体知识点掌握情况的判断,如公式(5) 所示。公式中qjk表示试题j 是否考察了知识点k;如果qjk=1,表示试题j考察了知识点k;qjk=0,表示没有考查知识点k;d 是k维的截距参数。
2.2 确定性输入噪音与门模型(Deterministic Inputs Noisy And Gate,DINA)
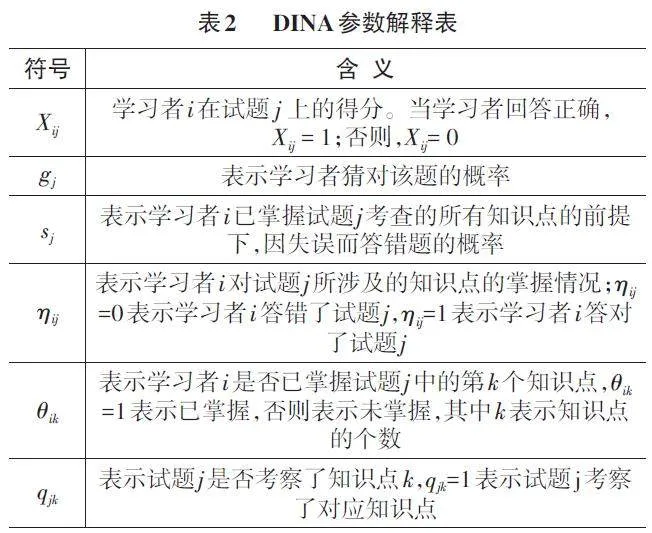
DINA模型是常用的多维离散型认知诊断模型,模型假设学习者只有掌握了试题考查的所有知识点才能答对该试题。为了模拟真实场景中答题者可能因为侥幸,在不掌握相关知识点的前提下,答对题;或因为失误而答错了会做的题,模型引入了猜测参数和失误参数。模型的项目特征函数如公式(6)、公式(7)所示。Pj (θi )表示当学习者的知识点掌握情况为 θi 的前提下,学习者答对试题 j 的概率。为方便对模型进行阐述,模型所用参数的数学符号和含义如表2所示。
DINA模型通过引入Q矩阵,很好地诠释了试题和知识点之间的关系,使模型不仅实现了对学习者学习能力的多维测量,同时也让模型具有更好的解释性。但是DINA模型对于大规模在线数据的处理存在收敛速度较慢的问题,虽然有学者试图通过增加超参来提升收敛速度,但这影响了模型的可解释性。为此王超[4]尝试了三种方案以提升数据的收敛速度。一是增量DINA模型,它是将学习者数据进行分组,每次只对其中一组学习者的数据进行遍历;二是最大熵DINA模型,它尝试将数据分为对参数贡献大的变化集Xc 和对参数贡献小的懒惰集Xl,在完整遍历时对数据不断筛选,确定变化集和懒惰集。在部分遍历时,只对变化集进行遍历;三是增量最大熵DINA模型,它在数据遍历时不仅考虑变化集和懒惰集,而且在变化集中还对学习者进行分组。实验证明三种方法都有效提升了数据的处理速度,但由于方法三集方法一和方法二的优势,因此方法三对算法的稳定性和快速性贡献度最大。
除了对算法的速度有改进之外,也有学者从实际应用角度对DINA模型提出了改进。汤成[5]将学习者在学习中的遗忘因素和答题次数对正确答题的影响引入到DINA模型中,对DINA模型的正确回答率进行了完善。Tj 是时间函数,用于模拟学习者学习过程中的遗忘效果和做题次数对于正确回答试题的巩固效果。α,β 是拟合艾宾浩斯遗忘曲线的常量参数;γ 为学习者回答试题j 的情况,当学习者正确作答时γ 为1,否则为0。Count(γ)为学习者回答试题j 的次数。算法如公式(8)、公式(9)所示。
3 模糊认知诊断理论(Fuzzy Cognitive Diag⁃nostic Framework, Fuzzy CDF)
传统的认知诊断模型对客观题的预测有较好的效果,但在处理主观题时效果不理想,因此又产生了基于模糊集理论的模糊认知诊断模型;并且各位学者基于教学实际场景又在模糊认知诊断模型的基础上进行了各种完善。
模型首先考虑了学习者自身的潜在特质,认为潜在特质的存在会影响学习者对知识点的掌握情况;其次,模型考虑到学习者对技能已形成的认知状态;第三,模型结合专家标注的Q矩阵将主观题和客观题分别建模。客观题利用联结型知识点假设,使用模糊交建模,而主观题使用补偿型知识点假设,采用模糊并建模。因为客观题如果要正确,需要学习者完全掌握试题中涉及的所有知识点,因此采用联结型假设,而主观题对学习者来说只要掌握部分知识点即可得分,因此采用补偿型假设;第四,模型还考虑了失误参数和猜测参数对分值的影响。模型所用参数的数学符号和含义如表3所示。
模型假设每个知识点k 都有一个模糊集(I,μk)与之对应(I为学习者集合,μk 为知识点k 对应的隶属度函数),集合I中的每个学习者i 在知识点k 上的认知水平αik 就是学习者i 在模糊集(I,μk)中的隶属度,如公式(10)所示。
学习者i 在试题j 上的掌握程度为ηij,其中qjk = 1表示试题j 中考察了知识点k;qjk = 0表示试题j 没有考查知识点k;当表示学习者i 对客观题j 的掌握程度如公式(11)所示;当表示学习者i 对主观题j 的掌握程度如公式(12)所示。
学习者i 在试题j 上的得分,如果考虑到猜测参数(gj)和失误参数(sj)时,对于客观题得分预测如公式(13)所示,其中客观题的得分为伯努利分布;主观题得分预测如公式(14)、公式(15)所示,主观题采用高斯分布,σ2为主观题得分的方差。
P (Xij = 1|ηij,gj,sj )=(1-sj)ηij+gj (1 - ηij ) (13)
P (Xij|ηij,gj,sj )=N(Xij|[(1-sj)ηij+gj (1 - ηij )],σ2) (14)
Xij=Σk = 1Kαik qjk (15)
李忧喜[6]认为主观题中知识点的重要性影响着知识点在试题中的出现次数,知识点高频次的出现会提升学习者答题的正确率,因此他在模型中以知识点出现的比例来模拟知识点的重要性。将学习者对知识点的掌握程度αik 修改为αik = 1/1 + exp [-1.7 ∝ ik (θi - βik × nm) ] ,其中n 为知识点在试题集中出现的次数,m 为试题集的总数;同时基于主观题是补偿型知识点假设,随着知识点掌握的数量增多,正确回答试题的概率会增加,因此他又将学习者i 对主观题j 的掌握程度改为了ηij= αik/Σk = 1Kqjk,取值范围是0到1的连续值,qjk=1,1≤ k ≤ K。
4 基于深度学习的认知诊断理论
4.1 神经网络认知诊断模型
传统认知模型是利用学习者的历史答题数据来训练参数,用简单线性模型来模拟学习者与学习资源的交互。但是学习者在与学习资料的交互中,其认知状态是动态提升的,因此随着深度神经网络的不断发展,以深度学习为基础的神经网络认知诊断框架(Neu⁃ral Cognitive Diagnose, Neural CD)[7]诞生了。它不仅可以解决数据稀疏问题,而且对不规则数据、稀疏回答记录也具有较好的预测能力[8]。模型伴随式地挖掘学习者的各类参数,建立学习者、知识、学习资源之间的联系,达到对学习者进行成绩预测的目的。
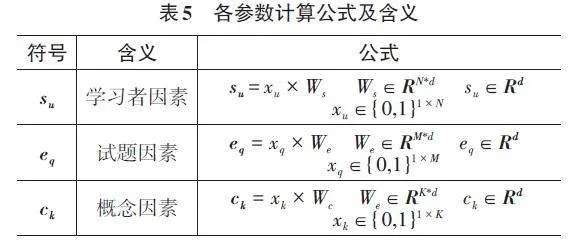
模型用一个连续变量hs 表示学生对相关知识点的熟练掌握程度,hs=sigmoid (xs × A)。其中xs 为学生答题记录的one-hot向量,A 为学生能力矩阵的待训练参数,A ∈ RN × K;N 为学生数,K 为知识点数。
Qe 是试题因素,表示试题与知识点的关联向量,Qe=xe×Q,其中xe为试题的one-hot向量。
试题的难度系数:hdiff=sigmoid(xe × B) B ∈ RM × KM为练习数,hdiff 表示每道试题所涉及知识点的难度系数矩阵。
试题的区分度系数:hdisc = sigmoid (xe × D)D ∈ RM × 1
模型用三层全连接网络来表示学生与题目间的交互,y = Qe × (hs - hdiff)×hdisc,y 为预测学生答对试题的概率。
4.2 基于深度项目反应理论的静态认知诊断方法(Deep RIT,DRIT)
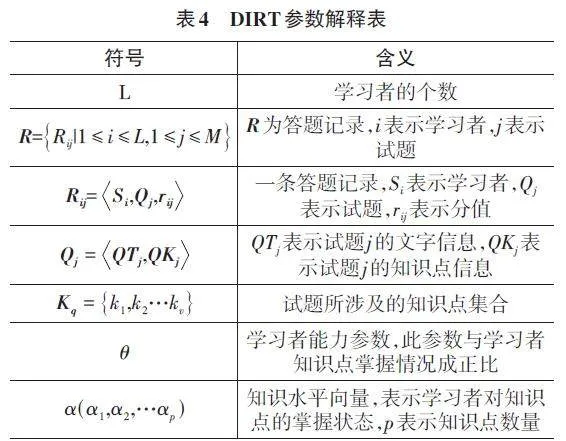
程松[9]基于深度学习和项目反应理论(IRT) 提出了基于深度项目反应理论的静态认知诊断方法(DRIT)。模型通过给学习者初始化知识点掌握向量,利用深度神经网络来挖掘学习者的认知状态和试题的区分度;采用注意力机制和循环神经网络挖掘试题难度;最后利用模型函数预测学习者得分,模型所用参数的数学符号和含义如表4所示。
对于试题Qj,用word2vec模型将试题中所包含的数量为U 的单词转化为同一维度的向量,即QTj= {w1,w2...w } u ,假设每个词都有d0 维向量;对试题中的每个知识点v 用一个p 维的onehot 向量来表示即Kv ∈ {0,1}p,因此QKj={K1,K2...K } v ;接着利用kv = KvWk将kv变成一个全连接的d1维向量。
学习者认知状态及试题区分度:学习者认知状态和试题区分度都是通过深度神经网络自行习得。认知状态是通过给每个学习者初始化一个知识水平向量α;然后用Kq 乘以α,得到一个向量Φ,使其作为深度神经网络的输入,θ = DNNθ(Φ),即可求出学习者的能力参数θ;试题区分度是对试题所考察的知识点进行累加求和,得到一个结果向量A,然后以A 作为深度神经网络DNNa 的输入,即A=Σkv ∈ Kvkv,其后系统将自动学习试题的区分度。由于IRT模型对试题区分度的要求是在[-4,4]之间,因此在系统得出A 值之后,再通过数学缩放,将A 值调整到规定范围之内。
试题的难度系数:试题的难度系数由试题文本信息的难度和试题所考查的知识点共同决定。试题文本信息具有时间序列性,为此DIRT模型使用循环神经网络来学习试题文本难度数据;试题所考察的知识点难度可通过试题文本信息与知识点之间的相似度衡量,因此系统使用基于注意力机制的循环神经网络来计算试题的难度。
首先,根据试题文本信息向量QTj={w1,w2...w } u 与试题里所包含的每个知识点Kq = {k1,k2...k } v ,求出它们的相似性以表示试题的难度,即ξj = wTtkv。
然后,再利用试题文本信息向量QTj={w1,w2...w } u与试题里所包含的知识点向量Kq = {k1,k2...k } v ,根据自注意机制的注意力值计分函数xt =Σkv ∈ Kqsoft max( ξj/根号下d0 ) kv + wt(xt 是指每个时刻的输入)得到序列x =(x1,x2...xN)。
最后将(x1,x2...xN)作为输入导入到循环神经网络中,循环神经网络输出具有难度特征的隐向量h=(h1,h2...hN)。再将h 进行池化和缩放,即b = 8×(sigmoid(averagepooling(hN)) -0.5) 使难度系数b 被控制在[-4,4]中。
模型求解:根据以上算法,在求出学生的认知状态、试题区分度、试题的难度系数之后,将其带入项目反应理论中,求得学生在某题上的得分情况。
4.3 基于注意力的概念提升认知诊断模型
苑冬雪[10]等针对目前大部分认知诊断模型还不能有效挖掘概念之间隐含关系对正确答题的影响,因此尝试对学生因素、试题因素、概念因素分别建模,设计出基于注意力机制的概念提升认知诊断模型。模型分为嵌入层、概念提升层、诊断层。
嵌入层将学习者、试题、概念的one-hot向量转变为d 维的特征向量,各参数计算公式及含义如表5所示;再针对每个知识点会对应不同难度的试题,设计了试题的区分度函数hdisc ∈ [ 0,1],hdisc = sigmoid (xq ×D) D ∈ RM × 1 D 为可训练矩阵。
概念提升层是通过自注意力机制,自动学习各概念间的隐含关系,即各概念之间的权重。然后再根据各概念的权重,将它们整合,形成一个增强型概念模型。首先k 个概念经过线性变化得到三个矩阵:
Q =C× Wq、K =C × Wk、V =C × Wv,其中 Wq、Wk、Wv均为可通过学习而自动更新的权重矩阵。然后通过A = soft max((Q × KT ) × 1d ) 获得各概念间的隐含关系。最后通过C' = sigmoid (AV )获得整合后的增强型概念模型。
诊断层通过全连接神经网络,得到学习者对概念的掌握程度hs 和试题的难度向量hdiff;同时利用试题因素和概念因素的交互来代替Q矩阵,使Q矩阵可以自动变化,以此来降低传统认知诊断模型中人工标注Q矩阵的误差。⨀代表对应元素相乘。
hs = sigmoid (Wsc × (su⨁C′) + bsc ) Wsc ∈ R2d × 1
hdiff = sigmoid (Wec × (eq⨁C′) + bec Wec ∈ R2d × 1
Q′q = soft max(eq × C′T ) x = Q′q⊙(hs - hdiff)×hdisc
最后通过sigmoid函数实现对学习者在试题上的答题预测:
f1 = sigmoid (W1 × xT + b1 )
f2 = sigmoid (W2 × f1 + b2 )
y = sigmoid (W3 × f2 + b3 )
5 结论
传统认知诊断解决了对学习者进行能力值的预测;模糊认知诊断解决了对学习者主、客观题的分别建模;神经网络则摆脱了人工标记的问题,利用神经网络的自我学习功能,挖掘试题的难度系数、区分度系数等参数,进而求出学习者答对试题的概率。
早期认知诊断主要是除了对传统认知诊断的算法进行改进外,更多的是对其进行的应用改进。孙晨辉[11]将学习者对知识点的掌握情况分为知道、运用、综合难度三个层次,使得DINA更贴合学习场景;齐斌[12] 等以PH-DINA(Polytomous Hierarchical DINA)模型结合协同过滤算法在同时考虑了个体的知识属性和种群的知识共性的前提下,实现了试题的精准推荐。
近年认知诊断主要是对基于模糊概念、神经网络的认知诊断模型的应用研究。张雨婷[13]等针对编程课程,提出了基于模糊认知诊断的P-FuzzyCDF(Programming-performance-based fuzzy cognitive diag⁃nosis framework)的认知模型;王炼红[14]等考虑到学习者努力因素对知识点掌握的影响程度,提出了在模糊认知诊断的基础上,基于能力特征与努力特征相融合的特征参数来建模学习者知识水平。另外还构建了知识点弱项特征参数来提升模型预测准确性的认知反应模型(Cognitive and Response Model,C&RM)。张所娟[15]等针对当前各类模型中并未考虑知识点间相互关系的问题,构想出基于多个知识点的权重学习,并结合深度神经网络构建认知诊断模型,即融合知识交互的认知诊断模型。
目前认知诊断模型的预测准确度比之前更高,各类应用研究也更贴近现实教学场景。但是在知识迁移和试题文本信息表示上还有一些工作可做。比如:很多课程之间是相互联系的,知识也是可以迁移的。但我们目前的研究更多的是针对一门课程进行的诊断。未来可以挖掘不同课程之间的知识迁移现象,以实现跨课程的认知状态分析;目前对于试题文本信息的研究,多从文本的角度去进行算法设计,并没有考虑到音视频、图片等题面信息的表示,未来可以更多地对试题信息的多元化表示进行研究,以丰富试题表示类型的研究。
参考文献:
[1] 李振,周东岱.基于学科知识图谱的智能化认知诊断评估方法[J].现代教育技术,2022,32(11):118-126.
[2] 刘淇,陈恩红,朱天宇,等.面向在线智慧学习的教育数据挖掘技术研究[J].模式识别与人工智能,2018,31(1):77-90.
[3] 胡心颖.基于认知诊断方法的计算机教育数据挖掘问题研究[D].合肥:中国科学技术大学,2021:54-56.
[4] 王超,刘淇,陈恩红,等.面向大规模认知诊断的DINA模型快速计算方法研究[J].电子学报,2018,46(5):1047-1055.
[5] 汤成.基于深度学习与认知诊断的教学资源推荐算法研究[D].广州:华南理工大学,2020:22-31.
[6] 李忧喜,文益民,易新河,等.一种改进的模糊认知诊断模型[J].数据采集与处理,2017,32(5):958-969.
[7] 陈恩红,刘淇,王士进,等.面向智能教育的自适应学习关键技术与应用[J].智能系统学报,2021,16(5):885-898.
[8] 田刚鸿.面向长周期测评的认知诊断方法研究及应用[D].武汉:华中师范大学,2022:16-17.
[9] 程松.基于深度学习的学生认知水平诊断方法与应用研究[D].合肥:中国科学技术大学,2021:18-20.
[10] 苑冬雪,孙权森,傅鹏.基于注意力机制的概念增强认知诊断模型[J].计算机科学,2023,50(11):241-247.
[11] 孙晨辉.基于知识图谱的JAVA自适应学习平台设计与实现[D].武汉:华中师范大学,2020:17-21.
[12] 齐斌,邹红霞,王宇,等.基于协同过滤和认知诊断的试题推荐方法[J].计算机科学,2019,46(11):235-240.
[13] 张雨婷,李征,刘勇,等.基于编程认知诊断模型的学生表现预测[J].计算机系统应用,2023,32(9):239-247.
[14] 王炼红,罗志辉,刘畅.面向慕课学习者评估的认知反应模型[J].电子学报,2023,51(1):18-25.
[15] 张所娟,余晓晗,陈恩红,等.融合知识交互关系的认知诊断深度模型[J].模式识别与人工智能,2023,36(1):22-33.
【通联编辑:王力】
基金项目:2022 校级自然科学重点项目《基于知识图谱的认知诊断研究》(项目编号:ZRKXZ202203);2020 年安徽省教育厅高校优秀青年骨干教师国内访问研修项目(项目编号:gxgnfx2020138)
