临床病案数据模块化策略和数据抽取实践
2024-07-07陈召霞黄雪群雷永健刘道文季东刘雯姗沈恩璐渠田田冯铁男
陈召霞 黄雪群 雷永健 刘道文 季东 刘雯姗 沈恩璐 渠田田 冯铁男

[摘要] 目的 设计一种更有效的方法提升临床数据中非结构数据的提取率以供临床应用。方法 基于真实的病案数据,设计病案数据模块化解析法结合混合算法抽取指标集结果,通过人工与自动化校验相结合的方法验证抽取结果。结果 该方法已在专病库数据平台实现,10份患者病案的指标集一致率(召回率)为99%,填充率为91.8%。结论 该方法提升了非结构化病案数据提取率和一致率,相较纯算法效果明显。
[关键词] 临床病案数据模块化;构建语义标签确定模型;语料库;填充率
[中图分类号] N37 [文献标识码] A [DOI] 10.3969/j.issn.1673-9701.2024.17.021
病程记录、手术记录等非结构化数据中包含大量诊疗信息,但这些数据无法直接用于研究分析,需要进行数据清洗和提取才能使用[1]。但准确、全面提取这些信息费时费力,即使引入算法仍然很难达到研究所需数据标准[2]。如何高效高质从非结构化数据中提取符合研究标准的数据是提升临床研究效率的关键技术[3]。本研究参考现有的临床数据采集协调标准(clinical data acquisition standards harmonization,CDASH)模块定义,结合临床病案数据分布规律,提出了一种将临床病案数据从非结构化到结构化的方法。现以宫颈癌病案为研究对象,进行策略验证和效用评估,为非结构病案中的数据抽取提供参考。
1 资料与方法
1.1 非结构临床数据解析现况分析
目前主流非结构临床数据提取方法是将以自然语言方式记录的医疗文档按照医学术语的要求进行系统分析,最终以关系型(或者面向对象的)结构将这些语义数据输入到数据库中[4]。目前已有大量语义分析大模型(如Convolutional Neural Network,Binary Neural Networks等),但都很难直接用于医疗数据解析[5]。主要原因在于医疗文字描述有很强的特异性,常规的语义分析大模型缺少病案文本训练,对医疗文档的提取率和一致率都非常低。为进一步发挥算法,则需要医疗专业人员对数据进行预处理,并进一步构建符合疾病特性的“语料库”,参考标准临床研究体系,形成专业性更强的数据治理流程[6]。
1.2 非结构临床数据解析方案
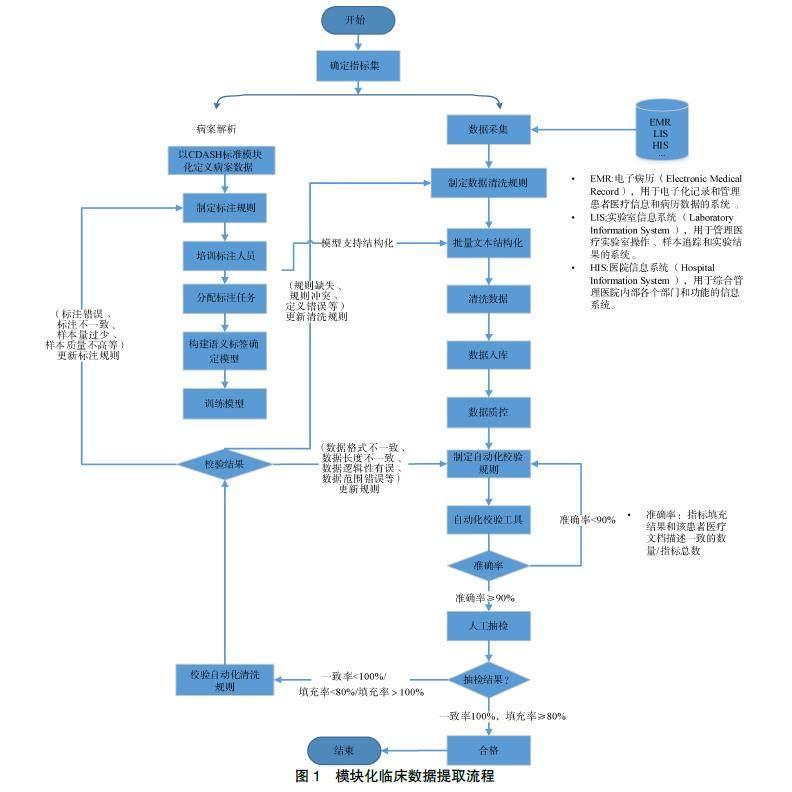
为解决数据提取率和一致率低的问题,本方法设计了一种提升数据提取率的策略:参考CDASH标准模块对现有病案数据进行模块化标记,即模块化病案解析法,先按照CDASH标准模块标注数据在病案中对应的模块,再对每个模块中的样本病案信息进行标注,构建语义标签确定模型,从而提升数据提取率。CDASH是临床数据交换标准协会(Clinical Data Interchange Standards Consortium,CDISC)建立的标准之一,定义了临床试验数据采集的基本标准,用于简化并规范临床研究中的数据采集过程。具体流程见图1。
非结构临床数据解析方案共分为4步。第1步,根据近5年相关临床研究的文献、指南、专家共识等确定指标集;第2步,医疗团队和技术团队共同参与,进行病案解析和采集数据。即医学团队开启样本病案模块和语义标注,构建语义标签确定模型。技术团队同步采集数据,制定数据清洗规则;第3步,技术团队批量结构化病案、清洗数据,结合混合算法抽取指标集结果;第4步,自动化校验工具验证抽取结果的准确率(一致率=指标自动填充结果与人工抽取结果一致的数量/人工抽取总数,填充率=指标自动填充数量/人工抽取数量),人工抽检验证召回率和填充率。根据每次的抽检结果回溯问题,直至数据质量合格(应填指标填充率>80%,一致率为100%)后结束评估。人工质控方法:①对照组抽样:人工随机抽取10份样本,统计抽取结果;②实验组抽样:从数据库导出同样10份样本数据;③质控合格标准:实验组结果与对照组结果一致率(召回率)达100%(偏差≤–5%,偏差仅适用于自然语言类描述性指标集结果),应填指标填充率≥80%。
2 结果
2.1 CDASH模块和临床数据模块的映射关系
以CDASH为基础构建临床病案数据模块,探索指标集在病案中的分布规律,建立指标集和CDASH域之间的映射关系,见表1。
2.2 梳理语料库和语义结构树
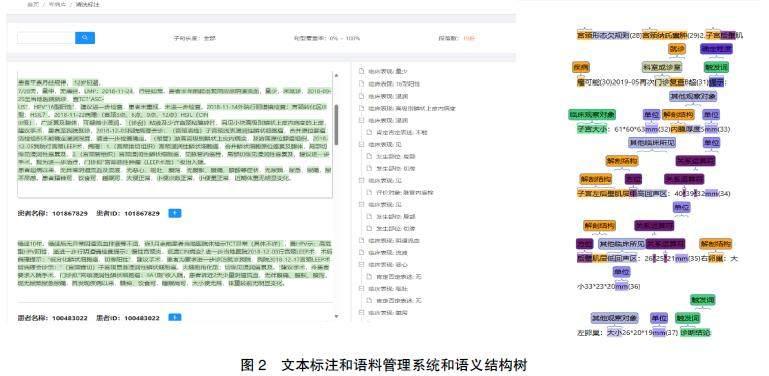
映射关系建立后,需要进一步对非结构化文本数据进行解析,构建病种语料库,为统计语言学模型做语言加工准备,用来提高程序解读病案中相关词汇和语义的能力,为后续数据提取做准备。首先,在基于领域本体的语义分类框架基础上,对病案语料进行深层次语义加工,建立语义结构树,见图2。其次,根据病种特征总结术语和常见句式,标记语义标签。最终,确定病种代表性叙述、文本断句标志等特征,从而发现可能的规律构造等价抽取规则。语料库不能直接套用模板,因为病案的主体内容一般采用自然语言记录,不同词可表达相同意思,同一个词在不同领域也会有不同意思[7]。每个专科和每种疾病有共性,又具有不同的特性,每个课题组的研究方向也相对独立,对数据收集也各有其特殊要求[8]。直接套用模板只会降低匹配度,因此需要结合病种特征和所属医院真实病案进行分析标记,才能构建出匹配项目需求的语料库。
语义归纳结果直接影响语义映射效果,从而影响数据填充率和一致率。以宫颈癌病种为例,病案中术语会出现简称、全称或医疗行业通用描述,也可能是仅在该院内使用的简称。因此术语、句式等的归纳一定要详尽规范。
2.3 优化数据提取结果
以宫颈癌病种为例,运用纯算法提取数据时,提取率不足50%,经过策略优化之后,提取率超过了90%。这是因为纯算法只适用于部分结构化病案的数据提取,病案中涉及诊疗细节的主体内容大都以自然语言方式记录,很难做到基于统一、严格的表格形式来结构化[9]。其次中文语义复杂和个人表达习惯不同等因素,造成机器抓取数据的精准率不高,这就需要更多人工参与病案解析去辅助构建病案文本语义模型[4]。
2.4 结果分析与验证
人工抽取10份样本做全量质控,每个样本397个指标,理论抽取总数3970个,实际抽取1537个。首次人工质控结果:数据库导出1251个结果,抽取率为81.3%,一致率为97.7%(小部分数据识别不全)。第2次人工质控结果:经过对首次抽取结果的分析和方案修改,此次导出1401个结果,抽取率为91.1%,一致率为99.0%。第3次人工质控结果:针对第2次出现的问题修改方案,此次导出1411个结果,抽取率为91.8%,一致率为99.0%。由于部分指标提取结果识别不全或是无法直接提取,导致填充率略低于人工提取率。
3次质控结果表明:每次方案调整,填充率都不断接近人工提取率。首次质控是为了验证指标集填充是否完全覆盖人工录入的指标集范围,填充结果是否与源数据一致,以及分析填充不全和填充错误的原因;第2次质控是为了验证修改方案是否可行以及是否还有其他问题;第3次质控是对第2次质控的查漏补缺,防止遗漏可填充指标集,或指标集填充结果不全。一般经过3轮人工抽样质控基本可以判定自动填充结果是否趋于稳定。若首轮质控不严谨,或第2轮方案调整不合理,则第3轮数据质量依然难以合格,就需要进行第4轮或多轮人工抽样质控,直至数据质量达标。建议根据填充实际情况制定质控方案,防止方案偏离导致无效质控。
3 讨论
本研究方法已达到质控合格标准,一致率为99.0%,填充率为91.8%。而未进行病案解析之前,自动填充率不足50.0%,一致率不足70.0%。在采用了模块化病案解析法与混合算法相结合的数据抽取方法后,实现了从结构化和非结构化病案文本中抽取符合科研需求的数据,与纯算法比对效果较好。此结论已在22家医院45个专病项目的数据质量调研中被证实。调研结果表明,开展过病案解析的项目数据质量远高于未进行病案解析或病案解析不充分的项目。45个项目中10个项目分别做了不同程度的病案解析,其数据质量与病案解析程度呈一致性[10]。
基于CDASH标准的模块化病案解析法,是根据每个病种的独特性对其进行量身定制的数据预处理方法,能更好地辅助数据解析、清洗过程[11]。该方法要求团队人员需具备专业医学背景和数据处理技术,目前大多数技术团队在数据解析过程中缺乏深层次的病案文本标记和临床医学专业人员,也无专业医学指导,这是该方法在实操中比较常见的的局限性。其次大多数团队纯靠算法进行提取,对自然语言类病案无法精准匹配指标集及有效质控,从而导致填充率和一致率普遍偏低的现象。该方法强调了质控的必要性和重要性,尤其需要注意人工质控的方案调整[12]。因此,本方法对结构化病案采用算法提取,对不能提取的部分结构化病案和非结构化病案使用模块化病案解析法辅助混合算法进行提取。
语料库无论在基于规则的数据抽取还是构建模型等机器学习方法中都不可或缺[13]。目前可用的标准化病案语料非常稀缺,这是目前非结构化病案数据不能被有效利用的关键因素。不管是作为主要使用者的医院,还是创建语料库的团队,双方均缺乏专业人员和资源构建丰富、全面的语料库。新医科建设倡导进行交叉学科研究,“医+工”甚至“医+文”交叉成为创建病案语料库的新型模式,通过技能互补,构建高质量病案语料库[14]。
综上所述,在方法实施中发现病案数据模块化标记可以为数据迁移、病案管理、疾病预测模型等提供参考。病案数据模块化标记参照CDASH标准,可以为将来数据迁移做准备[15]。模块化文本标记明确了病案管理和病案结构化的需求,既可以为临床制定结构化病案提供指导,又可以为技术人员设计结构化模板提供参考,同时辅助病案管理[16]。另外语料库还可以辅助建立疾病预测模型,达到辅助诊断的效果[17]。
利益冲突:所有作者均声明不存在利益冲突。
[参考文献]
[1] 包小源, 黄婉晶, 张凯, 等. 非结构化电子病历中信息抽取的定制化方法[J]. 北京大学学报: 医学版, 2018, 50(2): 8.
[2] 谢维佳, 王映涛. 电子病历系统中检验数据信息抽取研究[J]. 中国数字医学, 2015, 10(3): 3.
[3] N?V?OL A, ZWEIGENBAUM P. Clinical natural language processing in 2015: Leveraging the variety of texts of clinical interest[J]. Yearbook Med Inform, 2016, 25(1): 234–239.
[4] 韦玉芳, 施维, 尚于娟, 等. 基于电子病历数据的临床表型提取及其应用进展[J]. 医学信息学杂志, 2017, 38(8): 5.
[5] 王辰, 李明, 马金刚. 电子病历关系抽取综述[J]. 计算机工程与应用, 2023, 59 (16): 63–73.
[6] 李忆昕, 张颖, 王钰莹, 等. 电子病历历史数据的提取及在医学临床教学中的应用[J]. 中国信息技术教育, 2019(15): 3.
[7] 王灿辉, 张敏, 马少平. 自然语言处理在信息检索中的应用综述[J]. 中文信息学报, 2007, 21(2): 11.
[8] 李慧杰, 张晴晴, 刘瑞红, 等. 大数据背景下临床专病数据库建设实践与思考[J]. 中国卫生事业管理, 2020, 37(8): 4.
[9] 杜晋华, 尹浩, 冯嵩. 中文电子病历命名实体识别的研究与进展[J]. 电子学报, 2022, 50(12): 3030–3053.
[10] 牛承志, 骆鑫, 赵丹. 临床科研数据抽取研究[J]. 医学信息学杂志, 2020, 41(7): 25–28.
[11] 印冠锦, 张梦阳, 吴惠庶, 等. 真实世界数据相关标准体系研究与应用进展[J]. 医学信息学杂志, 2022, 43(6): 30–35.
[12] 崔博文, 金涛, 王建民. 自由文本电子病历信息抽取综述[J]. 计算机应用, 2021, 41(4): 1055–1063.
[13] 杨锦锋, 关毅, 何彬, 等. 中文电子病历命名实体和实体关系语料库构建[J]. 软件学报, 2016, 27(11): 2725–2746.
[14] 冷冰. 近二十年国内医药英语相关语料库建设回顾与展望[J]. 现代英语, 2023(3): 4.
[15] 杜宾, 王明文. 跨平台数据迁移的研究和实现[J]. 计算机与现代化, 2001(6): 6.
[16] 罗辉, 薛万国, 乔屾. 大数据环境下医院科研专病数据库建设[J]. 解放军医学院学报, 2019, 40(8): 6.
[17] WENBO D, SHILIANG S U N, MINZHI Y I N. Research and development of medical knowledge graph reasoning[J]. J Front Comput Sci Technol, 2022, 16(6): 1193.
(收稿日期:2023–12–11)
(修回日期:2024–04–16)
