应对过滤气泡:算法策展对用户信息消费行为选择性和态度极端化的影响
2024-07-01姜婷婷吕妍傅诗婷
姜婷婷 吕妍 傅诗婷


关键词: 过滤气泡; 算法策展; 排序方式; 行为选择性; 态度极端性
DOI:10.3969 / j.issn.1008-0821.2024.07.003
〔中图分类号〕G252.0 〔文献标识码〕A 〔文章编号〕1008-0821 (2024) 07-0022-12
个性化推荐系统已被广泛应用于购物、新闻和流媒体等在线服务平台, 其本质是通过对用户行为痕迹数据的分析, 预测用户可能感兴趣的内容并进行推荐。然而, 这种“定制化” 的信息服务往往因为引发了“过滤气泡” 问题而饱受诟病[1] 。以往研究认为, 个性化推荐算法使得人们只能接收到符合自身偏好的内容, 难以接触到多元化信息, 长此以往, 用户将身处“窄化的信息世界” 中[2] 。尽管人类本身就具有趋近与自身兴趣和观点一致的信息、回避不一致信息的倾向[3] , 但过滤气泡的形成会加剧这一趋势, 身处其中的人们只能听到与自己立场和偏好一致的声音, 逐渐产生极端化态度, 进而促使不同立场的人群之间更加割裂, 甚至导致社会的两极分化[4-6] 。
为了避免这些负面影响, 如今的个性化推荐系统不再盲目追求推荐信息与用户偏好的高度一致性,而是倾向于在推荐算法的准确性和多样性之间寻求平衡, 比如在推荐过程中引入意外发现(Serendipi?ty)机制, 以提供更广泛的信息源和更多的异质信息[7] 。需要注意的是, 尽管信息异质性得到提升,但不一致的信息仍有可能被用户所忽略。这是因为个性化推荐算法对信息的策展过程是多阶段的, 除了基础的信息选择之外, 还包括了对信息的排序、分类和组织呈现[8] 。其中, 信息的排序被证明是能否吸引用户点击与注意的决定性因素[9-10] 。目前的个性化推荐系统排序方式综合考虑了多个因素, 其中最常见的因素包括信息内容与用户个人偏好的匹配度、信息质量与发布时间等[11-12] 。为了实现准确性与多样性平衡的信息消费, 算法开发者需要对不同的排序指标分配合理的权重, 而其实现基础则是需要理解这些排序指标对于过滤气泡是否存在以及存在怎样的促进或者缓解作用。
此外, 本研究认为用户对于算法的感知和理解,即算法素养(Algorithm Literacy)[13] , 也会影响其对于算法推荐内容的心理与行为反应。以往研究表明,高算法素养的人群会对于推荐信息作出更多批判性思考并基于此做出正确决策[14] , 推荐系统排序方式的改变对其行为态度的影响可能会被削弱。然而已有的过滤气泡研究往往聚焦于算法本身, 而忽视了用户算法素养的调节作用。因此, 本研究还进一步检验了用户算法素养在不同排序方式对信息消费选择性、态度极端性变化情况的影响过程中是否存在调节作用。
综上, 尽管已有大量研究致力于改进个性化推荐系统算法, 以促进用户对多元立场信息的接触,缓解过滤气泡的负面影响。但这些研究都忽视了信息排序方式的重要性。关于信息排序指标是否以及如何影响过滤气泡, 以及不同人群之间这一影响是否存在差异, 目前仍然缺乏实证研究证据。因此,本研究通过开展受控实验, 观察3 种排序方式下参与者的信息消费行为选择性及态度极端性变化情况,同时考虑到用户算法素养的调节作用, 旨在解决以下研究问题: ①个性化推荐系统的信息排序方式如何影响用户信息消费行为的选择性? ②个性化推荐系统的信息排序方式如何影响用户态度的极端性的变化? ③用户算法素养是否以及如何在上述过程中起到调节作用?
本研究结论不仅揭示了不同推荐算法排序方式对过滤气泡的影响, 为过滤气泡相关研究提供了新的研究视角与方法论, 还为算法开发者进行个性化推荐系统的排序指标设计提供了实践启示。
1 文献回顾
1.1 过滤气泡: 行为选择性与态度极端性
过滤气泡这一概念最初是由Pariser E[1] 在TheFilter Bubble: What the Internet Is Hiding from You 一书中提出, 是指个性化推荐算法可以随时捕捉用户的偏好, 并据此自动过滤信息, 以向用户提供个性化的信息服务, 这会使得每个人都身处一个独有的信息世界。虽然过滤气泡有助于缓解信息过载等问题[15] , 但它在公共议题讨论、信息传播等方面仍存在不利影响[5,16] 。因此, 如何有效应对过滤气泡一直都是研究人员关注的重点。例如, 利用信息过滤可视化、优化个性化推荐算法等方式降低过滤气泡的影响[7,17] 。
然而, 要评估对过滤气泡的应对效果, 关键在于选择适当的方式对过滤气泡进行测量。目前, 尚缺乏通用的过滤气泡度量手段, 因此, 如何在现实世界与实验室中捕捉该现象一直是一项难题。部分研究通过观察不同用户在同一平台所接触信息的相似性来测量过滤气泡的程度, 即用户间的信息相似性越小, 说明他们被过滤气泡所隔离的程度越大[18-19] 。另一部分研究则侧重于观察用户信息消费内容的多样性, 将个体信息消费的低多样性和高选择性视为过滤气泡的表现形式[7,20] 。本研究认为, 过滤气泡的本质是推荐算法对个体的信息选择性接触行为的强化[21] , 与其探究不同用户间的差异, 聚焦于单个用户的信息消费模式会具有针对性。因此, 本研究选择第二种方法对过滤气泡进行测量。
信息消费是指用户使用信息来满足自身需求的过程, 如对信息的获取、理解、使用等[22-23] 。信息的选择性消费行为则是指用户对于信息的接触存在立场偏向性, 这一行为模式在立场多元化的社交媒体上普遍存在[24] 。行为的选择性可以体现在标题点击与文章阅读两种情况: 一方面, 用户更倾向于点击符合自身立场的新闻[25] ; 另一方面, 用户更愿意花费更多时间去阅读与其观点一致的信息[3] 。
用户态度也是过滤气泡产生和发展的关键动力。一方面, 具有极端态度的个体为避免认知失调, 倾向于更多地选择消费与其观点一致的信息[26] , 而这种交互痕迹数据将被算法用于预测其立场与偏好, 进而形成过滤气泡[27] ; 另一方面, 处于过滤气泡中的个体长期接触与其观点一致的信息, 对于该观点的认可和信任程度进一步强化, 同时缺乏对异质信息的了解[16] , 对于该问题的认识会越来越偏激, 进而加剧用户的选择性接触行为[5] , 久而久之, 用户行为的选择性与态度的极端性在个性化推荐算法的作用下不断放大, 最终形成恶性循环。鉴于用户行为和态度之间的复杂关系, 本研究认为,过滤气泡的观测还应考虑到与信息选择性消费行为相关的态度变化, 用户态度极端性的增加可以被视为过滤气泡的体现[28] 。让用户接触更为多样化的信息内容、接触更为平衡的信息观点, 态度极端性才有可能降低[29-30] , 进而缓解过滤气泡带来的负面影响。
1.2 个性化推荐中的信息排序方式
信息在流向用户的过程中会经过算法的层层过滤, 包括信息源选择与收集、信息选择与优先级排序、信息展示等多个技术环节[8] 。以往研究认为,过滤气泡是由于推荐系统仅推送与用户观点一致的信息所导致的[18] , 因而重点关注“应选择哪些信息推荐给用户”, 旨在通过提升推荐信息的多样性来扩展用户对于不一致信息的接触, 避免过滤气泡所带来的负面影响[7] 。然而实际上, “如何对推荐信息进行排序” 同样重要, 因为用户与信息的交互会受到顺序效应的影响, 当不一致信息被赋予较低的呈现优先级时, 就难以吸引用户的注意与选择。以往研究发现, 在搜索结果页面上, 用户更倾向于点击与注视位于顶部(尤其是前3 条)的结果条目[9] ;在旅游预定平台上, 排名靠前的酒店会获得更高的预定量[10] 。因此, 异质信息的排序方式决定了用户是否能够真正接触到这类推荐信息。
在目前的个性化系统中, 例如今日头条、腾讯新闻等, 算法通常根据用户的基础属性信息及其历史行为数据, 为用户推荐更符合其偏好的信息, 并基于推荐内容与用户偏好的一致程度对信息进行排序[31-32] 。此外, 新闻网站和社交媒体还致力于寻找用户偏好和多样性的平衡, 将更多的因素纳入算法排序的考虑之中, 其中考虑最多的是时间和质量因素[33-34] 。例如, Facebook 中提供了两种帖子排序方式, 第一种是最新(Most Recent), 即将所有新闻按照时间倒序的方式进行排序, 人们接触到的是最新的新闻, 而时效性不足的新闻则会淡出人们的视线。第二种则是热门新闻(Top Stories), 即综合考虑点评赞数量、用户粉丝数等因素衡量帖子质量,并据此将帖子按照质量从高到低的顺序进行排列,人们首先接触到的均是高质量的文章[35] 。综上, 目前常见的排序指标主要分为以下3 类: 基于用户偏好的排序、基于信息发布时间的排序、基于信息质量的排序。
基于用户偏好的排序将与用户兴趣相符的信息赋予更高的权重[31-32] , 与用户偏好匹配程度更高的态度一致信息往往会被排在前列, 吸引用户的点击与阅读[36] 。基于信息发布时间的排序是指推荐算法倾向于为发布时间更近的信息赋予更高的排序权重[12,37] 。这在新闻推荐系统中尤为常见, 因为时效性是新闻的“生命”。Jiang T 等[38] 的研究发现,时效性越强的新闻的价值性越高, 更容易引起用户的阅读兴趣, 即用户会更多的点击新近新闻, 并且更加信任其内容。而基于信息质量的排序是指推荐算法倾向于为高质量内容的信息赋予更高的排序权重[11,39] , 这种排序可以帮助过滤低质量信息、推广优质信息, 进而影响用户偏好。例如, Lu H 等[40] 发现, 优质信息有效提升用户的新闻阅读时长, 并且提升用户对信息内容的信任度, 从而使用户更加客观地了解多方面的信息, 缓解用户的极端态度。
综上, 这3 种排序指标对用户对于信息的选择、使用和对信息内容的感知会产生不同的效果。但现有的关于个性化推荐算法的排序方式的研究多是从算法技术角度出发, 旨在通过纳入不同的因素来提升个性化推荐系统的性能, 如准确性、效率等指标[12,41] 。而较少的从用户行为视角出发, 比较用户在不同排序方式下与算法的交互行为的差异。哪种排序指标对于过滤气泡的影响更大, 尚不得而知。
1.3 算法素养
在算法时代, 人们所接触的大部分信息是由推荐算法控制的, 人们在享受其提供的便捷的同时,也面临着算法带来的负面影响, 如过滤气泡、算法偏见等。人们对于推荐算法的理解与认知程度在很大程度上决定了人们是否能与算法开展良性互动、避免负面影响[42] 。算法素养这一概念应运而生, 是指用户对于算法的了解程度, 包括算法意识(Algo?rithm Awareness)和算法知识(Algorithm Knowledge)两个维度[13] 。算法素养被认为是影响人与算法交互的重要因素之一, 算法素养能有效帮助人们理解推荐算法的内在逻辑, 意识到推荐算法的潜在风险, 进而为规避这些风险采取有效手段[43-44] 。
之前研究发现, 不同人群的算法素养存在高低之分, 且提高算法素养有助于避免过滤气泡的负面影响[45-46] , 这主要体现在对算法推荐信息的识别与评估能力上。一方面, 相比于低算法素养用户,高算法素养用户更了解算法机制, 对过滤气泡表现出更高的认识, 从而更能准确地对推荐内容做出判断与筛选。具体表现为, 这类用户在浏览在线购物网站时, 更容易意识到算法在跟踪他们的购物行为,据此提供个性化的内容, 并对其中的精准营销广告作出甄别[47] ; 另一方面, 相比于低算法素养用户倾向于不加批判地全盘接受算法推荐的信息, 高算法素养用户往往会在决策前进行评估与思考[42] , 通过比较接受推荐信息的收益与风险, 进而作出更为明智的决策[48] 。因此, 高算法素养用户往往会对过滤气泡表现出更强的抵抗意图, 会有意识跳出算法的控制, 在与算法交互时表现出更高水平的自主性,包括但不限于调整平台的推荐机制, 阅读更多非个性化内容, 改变自身阅读习惯等[47,49-50] 。
综上所述, 不同算法素养水平的用户对于排序指标的认知与行为反应不同。因此, 本研究假设对于不同算法素养水平的用户而言, 排序方式对新闻点击行为与阅读行为的影响存在差异。
2 研究设计
鉴于过滤气泡的研究通常涉及围绕政党之争、食品安全等两极分化的争议性主题[5,51] , 本研究基于200 份问卷调查结果, 选择了目前在国内受到广泛讨论并且存在两级分化立场的话题之一———“转基因食品” 作为实验信息主题。本研究构建了模拟的新闻个性化推荐小程序, 通过开展被试间实验设计, 将参与者分到不同新闻排序方式的实验组(基于用户偏好/ 时间/ 质量的排序)。观察并记录用户对于不同立场的转基因食品相关新闻的浏览行为, 并在实验前后分别使用态度量表度量参与者对于“转基因食品” 的态度。
2.1 实验参与者
研究通过社交媒体发布招募广告进行实验参与者招募。研究人员提出了两项招募要求, 以确保参与者正处于过滤气泡之中: ①已经对转基因食品持有极端态度, 譬如非常支持或非常反对转基因食品;②在日常生活中获取转基因食品相关信息时存在选择性, 譬如明显倾向于浏览与自己态度立场一致的新闻。招募问卷通过7 点李克特量表分别测量了参与者对于转基因食品所持态度[52] 及相关新闻消费行为的选择性。其中态度得分≤3 分的代表反对态度, ≥5 分的代表支持态度, 得分处于3~5 分之间代表持中立态度; 同样, 行为得分≤3 或≥5 代表了参与者存在选择性新闻消费行为, 得分处于3~5之间则说明不存在选择性新闻消费行为。
研究者从70 份招募问卷中选取了38 名符合要求的参与者, 其中男性18 名, 女性20 名, 年龄均在18~25 岁之间, 持支持或反对转基因食品态度的各19 人。这些参与者被随机地分配到3 个实验组, 尽量确保每组中持两种态度的人数相仿, 具体分组情况如表1 所示。
2.2 实验材料
2.2.1 新闻文本设计
为了确保推送信息的真实性, 研究者从澎湃新闻、今日头条等主流新闻平台搜集了转基因食品相关新闻60 篇, 从中筛选出立场明确的28 篇新闻,其中对转基因食品持支持、反对、中立立场的新闻分别为12、12、4 篇。研究人员邀请了1 位专业新闻编辑对新闻进行改写, 其目的在于最大限度地控制与减少除排序方式之外的因素(比如文本长度、修辞特征等)对于实验结果的潜在影响。最终每篇新闻的标题长度均在10~15 个字符之间, 不包括任何标点符号和阿拉伯字母, 均采用陈述句式, 不涉及特殊语言风格(如夸张、煽情)等; 新闻正文长度均在300~ 350 字之间, 均使用通俗易懂、简单自然的语言表述。在推送界面中, 为了避免信息源权威性的干扰, 所有新闻的发布来源被隐去。新闻发布时间均控制在2022 年范围内, 并按照新闻的真实发布时间进行排序, 在后续实验中作为时间排序指标的取值。
随后, 10 位新闻传播领域的专业人士被邀请对改写后的新闻进行评估。在阅读完每篇新闻的标题和内容之后, 10 位专业人士需要填写对新闻立场(Q1)、标题吸引力(Q2)、新闻质量(Q3~5)的评估量表(略)。其中, 新闻立场、标题吸引力由单一测量项构成, 均为7 点李克特量表。结果表明,每篇新闻的立场均具有明显偏向并且符合初始分类,任意两组之间的独立t 样本检验结果表明, 不同立场新闻在标题吸引力方面不存在显著差异(t(22)=0.206, p = 0.839; t (14) = 1.560, p = 0.141; t(14)= 0.946, p = 0.360)。新闻质量则包括可读性、逻辑性和可信度3 个测量维度[53-54] , 用3 个维度的均值进行表示, 并与以往研究保持一致, 采用了5 点李克特量表。新闻质量的得分存在明显的高低差异(t(27)= 11.042, p = 0.000), 作为基于质量排序的实验组的排序依据。
2.2.2 系统界面设计
通过模仿主流新闻推送平台的界面设计, 本研究设计并开发了名为“转基因食品小科普” 的新闻推荐平台。平台首页呈现了以特定方式排序的20 条新闻标题, 每条新闻标题文本下显示该新闻的发布时间与质量评分, 当参与者点击任一新闻标题之后,即可进入新闻内容详情页。
根据以往过滤气泡相关研究, 个性化推荐算法所推荐的信息中与用户立场一致的信息往往占据了较高比例[5,55] 。为了确定这一比例的具体数字, 本研究开展了预实验, 观察当一致新闻推送占比分别为50%、60%、70%、80%、90%时, 参与者对于算法个性化程度的感知及其新闻消费体验。本研究一共招募了15 名参与者分别对不同页面进行评价。结果表明, 除了50%占比的对照组之外, 其余组均被参与者识别为个性化推荐情景, 并且大部分参与者(N=12,80%)认为当一致新闻占比为60%时最贴近于日常新闻消费体验, 因此, 本研究采取60%作为一致新闻的推送比例。最终, 在模拟新闻推荐系统所推送的20篇新闻中, 有12 篇(60%)新闻与参与者的立场相一致, 4篇(20%)新闻立场相反, 4篇(20%)新闻持中立立场。换而言之, 对于前测态度为支持转基因食品的参与者, 为其推送的新闻中包括12篇支持转基因食品、4 篇反对转基因食品、4篇对此持中立立场的新闻, 反之亦然。
尽管在不同实验组中, 持有相同前测态度的参与者被推送的20 篇新闻内容是相同的, 但每组的新闻排序方式存在差异: 在基于偏好排序组中, 根据专家对每篇新闻的立场评分与用户自身立场分数的一致性程度(其分数相减绝对值为一致性得分, 得分越高则表示该条新闻与用户偏好越不一致), 将参与者所接触到的新闻按照态度一致程度从非常一致到非常不一致进行排序, 如图1(a)所示; 在基于时间排序组中, 新闻将根据发布时间从近到远进行排序, 如图1(b)所示; 在基于质量排序组中,新闻将根据专家质量评分从高到低进行排序, 如图1(c)所示。
2.3 变量的测量
信息消费行为的选择性。行为选择性是指用户行为的偏向性, 本研究将通过参与者对于一致新闻与不一致新闻的点击或阅读行为差异进行度量。通过微信小程序的后台日志文件, 研究者获取了用户对新闻标题的点击次数以及新闻文章阅读时长。一方面, 本研究通过用户对一致新闻标题的点击量与不一致新闻标题的点击量之差测量新闻点击行为的选择性; 另一方面, 本研究通过用户对于一致与不一致新闻的平均阅读时长之差测量新闻文章阅读行为的选择性。
态度极端性的变化。态度极端性(Attitude Ex?tremity)是指用户态度偏离中立的程度, 通过用户态度取值与态度量表中点(4) 差距的绝对值进行测量[56] 。研究者在实验前后使用同一量表分别测量了参与者对于转基因食品的态度, 并且将二者相减,以反映参与者的态度极端性变化情况, 如式(1)所示。
其中AEpost表示用户后测态度的极端性, AEpiror表示用户前测态度的极端性; ATpost表示用户后测态度, ATpiror表示用户前测态度。根据参与者在实验前后的态度变化情况, 可以将其分为3 类: 当该值大于0 时, 表示参与者态度的极端性在接触推送新闻之后有所增强, 即“态度极化”; 当该值小于0 时, 表示参与者态度的极端性有所下降, 即“态度缓和”; 当该值等于0 时, 表示参与者态度的极端性保持不变, 即“态度不变”。
算法素养。本研究所采用的算法素养量表改编自Dogruel L 等[13] 的算法素养量表(Cronbachs α =0 734), 包括算法意识和算法知识两个维度, 各维度均包含11 道判断题(略)。每个题项都是一个或真或假的表述, 参与者需要判断这一表述是否正确或错误, 或者选择“不知道”。参与者判断正确则计1 分, 判断错误或者选择“不知道” 则不加分。所有题项的累计总分反映了参与者的算法素养水平。本研究中, 38 名参与者的算法素养得分在10~22 之间, 平均得分为15 68, 得分的中位数为16。参照Neter E 等[57] 的研究, 本研究使用中位数作为分类基准, 当参与者的算法素养得分低于中位数时, 被划分为低算法素养人群, 当得分等于或高于中位数时被划分为高算法素养人群。在本研究所招募的38 位参与者中, 低算法素养参与者共18人, 高算法素养参与者共20 人。
2.4实验流程
整个实验过程由4个阶段组成。首先, 在招募过程中, 研究者采集参与者的人口统计学信息、转基因食品新闻的日常消费行为、对于转基因食品的前测态度, 筛选符合要求的参与者进入正式实验;其次, 参与者在到达实验室后, 需要签署知情同意书并阅读相应的实验操作指南, 以了解整体实验流程, 熟悉实验平台的界面操作与基本功能, 并填写算法素养量表。随后, 参与者被分配到不同实验组,需要按照日常新闻阅读习惯, 浏览所分配的模拟新闻推送平台中的新闻, 在浏览过程中, 研究者并不会给予具体任务或时间限制, 并且整个交互过程将记录在系统日志文件中; 最后, 参与者在实验结束之后会填写一份后测问卷, 报告此时自身对于转基因食品的态度。整个实验将持续30分钟左右, 每位参与者获得价值30元礼品作为实验报酬。
3 研究结果
3.1 排序方式对于点击行为选择性的影响
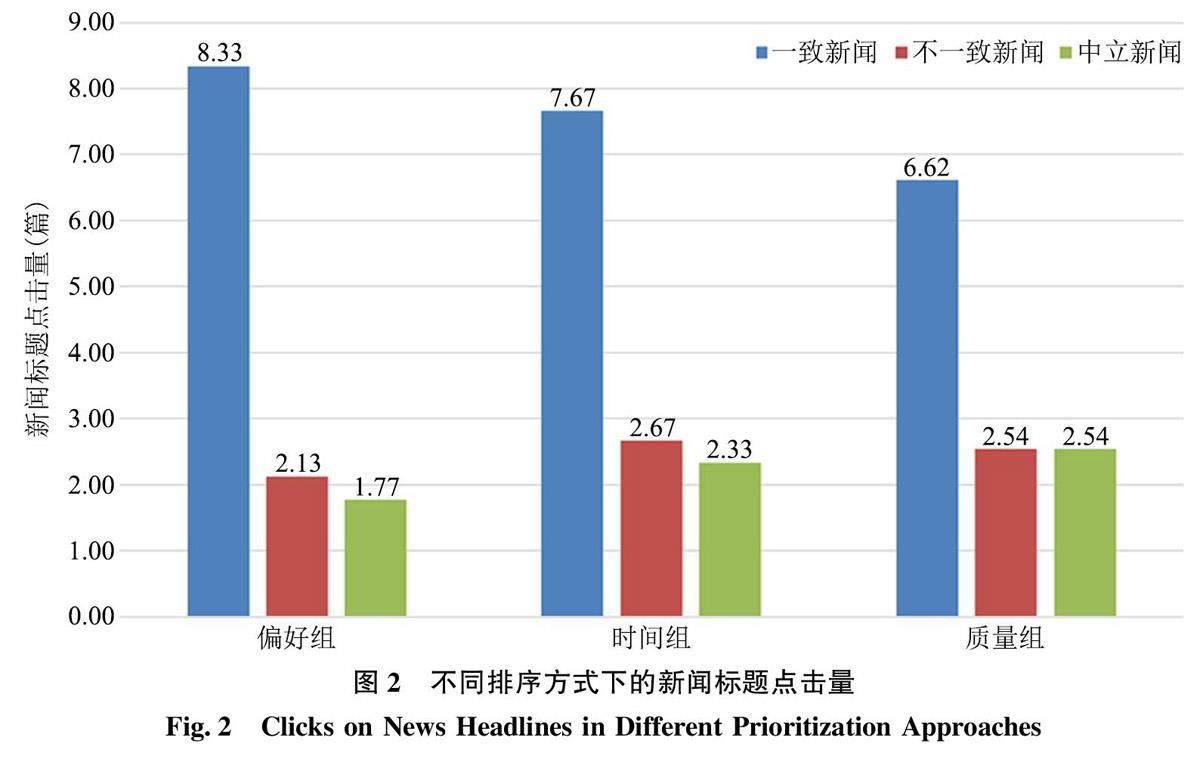
在整个实验过程中, 平均每位参与者点击了12.18 篇系统推送的新闻, 其中包括7.53 篇立场与其态度一致的新闻(SD=3.162, Range=2~12),2.44 篇立场与其态度不一致的新闻(SD = 1.191,Range= 1 ~ 4), 2.21 篇持中立立场的新闻(SD =1.234,Range= 0~4)。如图2 所示, 所有实验组参与者的新闻点击行为均具有选择性。
单因素方差分析(ANOVA)结果表明, 排序方式对于点击行为选择性不存在显著影响(F(2,36)=2.487, p= 0.098)。即无论在哪一种排序方式下,参与者始终会更多地点击一致新闻而非不一致新闻。
3.2 排序方式对于阅读行为选择性的影响
在整个实验过程中, 每位参与者平均花费22.88s阅读每篇新闻, 其中一致新闻的平均阅读时长为23.12s(SD = 12.12, Range = 7.40 ~ 49.41), 不一致新闻的平均阅读时长为22.53s (SD=10.70,Range=4.86~ 49.92), 中立新闻的平均阅读时长为20.19s(SD= 14.87, Range = 0~62.89)。如图3所示, 不同实验组参与者的新闻阅读行为选择性存在差异。
单因素方差分析(ANOVA)结果表明, 排序方式对于参与者的阅读行为选择性存在显著影响(F(2,36)= 18.639, p =0.000)。根据事后检验(Posthoc)结果, 基于偏好排序组的阅读行为选择性显著高于基于时间排序组(M偏好= 9.019±8.556>M时间=0.841±4.351, p=0.007), 而基于时间排序组又显著高于基于质量排序组(M时间=0.841±4.35>M质量=-8.07±7.620, p=0.004)。
为了进一步揭示排序方式对不同类型新闻的阅读时长的具体影响, 研究者分别对一致新闻平均阅读时长、不一致新闻的平均阅读时长开展单因素方差分析(ANOVA)。结果表明, 排序方式对于一致新闻的平均阅读时长不存在显著影响(F(2,36)=1.100,p=0.344), 但对于不一致新闻的平均阅读时长存在显著影响(F(2,36)= 3.393, p = 0.045)。对于后者, 事后检验(Post-hoc)结果表明, 基于质量排序组参与者的不一致新闻平均阅读时长要显著高于基于偏好排序组(M质量= 28.071±9.95<M偏好=17.901±8.83, p=0.014), 而基于时间排序组与其余两组均没有显著差异(M时间= 21.549±11.397,M偏好= 17.901 ± 8.83, p = 0.373; M时间= 21.549 ±11.397, M质量=28.071±9.95, p=0.115)。这一结果表明, 基于质量的排序方式主要是通过增加用户对于不一致新闻的阅读时长来降低用户阅读行为的选择性。
3.3 个性化推荐排序方式对态度极端性变化的影响
图4展示了参与者在实验前后的态度变化情况, 其中近一半参与者的态度在浏览新闻后更为缓和(N=18, 47.37%); 5 名参与者从支持态度和反对态度转变为中立态度(N=5, 13.16%); 12 名参与者的态度立场虽然未发生改变, 但态度的极端程度有所降低(N = 13, 34.21%)。然而, 也有28%的参与者在浏览新闻之后态度更为极端(N = 11,28.95%)。此外, 23%的参与者的态度没有发生任何变化(N= 9,23.68%), 其中包括了初试态度为支持(N=3,7.89%)或反对(N=6,15. 79%)的人群。
单因素方差分析(ANOVA)结果表明, 排序方式对于态度极端性变化程度存在显著影响(F(2,36)= 7.073, p = 0.003)。事后检验(Post-hoc)结果表明, 基于质量排序组参与者的态度极端性变化程度显著高于基于偏好排序组(M质量= -0.666 ±0.527<M偏好=-0.333±0.653, p=0.001); 而基于时间排序组参与者的态度极端性变化程度与其余两组(M时间= -0.139±0.834,M偏好=-0.333±0.653,p= 0.091; M时间= -0.139±0.834, M质量=-0.666±0.527,p=0.060)均没有显著差异。
3.4 算法素养的调节作用
多因素方差分析(MANOVA)结果表明, 算法素养在排序方式对用户点击行为选择性的影响中并不存在显著的调节作用(F(2,32)= 0.096, p=0.909),如图5 所示。这一结果表明, 对于不同算法素养水平的参与者而言, 排序方式对于用户点击行为选择性的影响不存在显著差异。
此外, 算法素养在排序方式对用户阅读行为选择性的影响中也不存在显著调节作用(F(2,32)=0.156, p= 0.856), 如图6 所示。这一结果表明,对于不同算法素养水平的参与者而言, 排序方式对于用户阅读行为选择性的影响不存在显著差异。
4讨论
本研究首次通过实证研究揭示了新闻推荐系统的排序方式对于新闻阅读行为选择性、态度极端性变化程度存在显著影响, 并且这一影响对于不同算法素养水平的人群而言均存在, 并不存在群体差异。
首先, 本研究证明了排序方式并不影响点击行为的选择性, 所有参与者都更倾向于点击与自身态度一致的新闻。这打破了以往研究认为用户偏好排序靠前信息的固有观点[9] 。这可能是由于以往研究结论往往针对传统信息搜索情景, 此时排序靠前代表信息的高度相关性, 进而吸引更多点击行为[58] 。然而, 新闻浏览行为作为一种无定向的信息搜寻行为[59] , 往往由兴趣驱动, 此时用户的目的不是寻找最准确的答案, 而是挑选出符合自身兴趣或喜好的新闻[20] 。因此, 无论采取何种排序方式, 用户对于新闻的选择偏好仍然会保持稳定。
其次, 本研究证明了排序方式对于用户的阅读行为选择性存在影响, 具体表现为在基于用户偏好的排序组中呈现出较高的阅读行为选择性, 基于时间的排序组次之, 基于质量的排序组最低。并且,这一差异主要体现在用户对于不一致新闻而非一致新闻的平均阅读时长差异上。具体来说, 相较于基于偏好排序组, 基于质量排序组中的用户在不一致新闻上花费的时间更多。其原因可能在于, 人们通常倾向于对不一致新闻投入较少的认知努力[60] , 不愿意花费过多时间处理不一致信息。而在基于质量的排序方式中, 用户更容易接触到那些排在前面的高质量新闻, 即使这些新闻与用户观点不一致, 其较高的感知说服力也会提升用户的阅读时间[61-62] 。
此外, 本研究还证明了不同排序方式对于用户态度极端性变化程度存在显著影响, 即相比于基于用户偏好的排序组, 基于质量的排序组参与者阅读新闻后的态度极端性会有更大程度的削弱。这可能是由于在基于质量的排序组中, 不一致信息的呈现次序会比基于偏好的排序组更靠前。而用户往往对于排名靠前的新闻更为信任[63] , 更倾向于采纳排名靠前的信息观点[64] , 因此用户更容易接纳不一致信息的观点, 削弱自身态度的极端性。
最后, 本研究证明了上述影响在不同算法素养水平的人群中均普遍存在, 且没有显著差异。这说明无论用户是否具备丰富的算法知识, 是否对推荐系统有着全面理解或深层次思考, 都不可避免地会受到影响。因此, 排序方式对过滤气泡的影响更像是一种隐性的“助推(Nudge)” 形式[65] , 潜移默化地影响着人们对于推荐信息的行为反应与心理活动。
5结语
本研究首次通过受控实验验证了推荐算法排序方式不影响用户点击行为选择性, 但会影响阅读行为选择性与态度极端性变化程度。具体而言, 相较于基于偏好的排序方式, 在基于质量的排序中, 用户阅读行为选择性会显著降低、自身态度极端性会更大程度地削弱。而基于时间的排序对用户行为选择性和态度极端性变化的影响与基于偏好的排序之间没有显著差异。
本研究的理论意义在于: ①提出了过滤气泡干预策略的新研究视角。以往研究聚焦于优化推荐信息的“选择” 策略, 但本研究通过实证研究证明“排序” 策略也同样重要, 并从行为选择性与态度极端性两个维度揭示了不同排序方式对于过滤气泡的干预效果, 为后续开展相关研究提供了新的方向;②为过滤气泡实证研究提供了方法论启示。目前,大部分过滤气泡研究并未开展实验研究, 或仅仅采用了定性研究方法。本研究首次通过实证研究, 验证了用行为选择性与态度极端性量化过滤气泡程度的可行性, 打破了该研究领域的方法论瓶颈。
本研究结果还为实践提供了指导。①从平台角度而言, 根据本研究结果, 算法开发与设计人员应对基于质量的排序指标赋予更高的权重, 并在不损害用户体验的前提下适当降低基于用户偏好的排序指标, 从而缓解过滤气泡的负面影响。然而, 在面对浩渺的信息流, 算法如何准确判断信息内容的质量高低, 仍然是个严峻的挑战。除了利用点赞、播放等初级指标之外, 还需要人类参与其中进行监督与判断, 让算法实现类似于人类专家的信息质量评估策略, 构建起内容推荐机制的“人在回路” (Hu?man-in-the-Loop)机制; ②从用户角度来说, 尽管算法素养的调节作用不显著, 但其高低仍会影响用户的态度改变, 因而在打破过滤气泡的过程中还需要注意用户算法素养的提升, 加强个性化推荐算法相关知识的教育, 提高用户对于推荐算法的意识,从而有能力辨别所推荐信息的价值, 不被个性化推荐算法所左右。
